first commit
This commit is contained in:
46
Seg_All_In_One_MMSeg/projects/Adabins/README.md
Normal file
46
Seg_All_In_One_MMSeg/projects/Adabins/README.md
Normal file
@@ -0,0 +1,46 @@
|
||||
# AdaBins: Depth Estimation Using Adaptive Bins
|
||||
|
||||
## Reference
|
||||
|
||||
> [AdaBins: Depth Estimation Using Adaptive Bins](https://arxiv.org/abs/2011.14141)
|
||||
|
||||
## Introduction
|
||||
|
||||
<a href="https://github.com/shariqfarooq123/AdaBins">Official Repo</a>
|
||||
|
||||
<a href="https://github.com/open-mmlab/mmsegmentation/tree/dev-1.x/projects/Adabins">Code Snippet</a>
|
||||
|
||||
## <img src="https://user-images.githubusercontent.com/34859558/190043857-bfbdaf8b-d2dc-4fff-81c7-e0aac50851f9.png" width="25"/> Abstract
|
||||
|
||||
We address the problem of estimating a high quality dense depth map from a single RGB input image. We start out with a baseline encoder-decoder convolutional neural network architecture and pose the question of how the global processing of information can help improve overall depth estimation. To this end, we propose a transformer-based architecture block that divides the depth range into bins whose center value is estimated adaptively per image. The final depth values are estimated as linear combinations of the bin centers. We call our new building block AdaBins. Our results show a decisive improvement over the state-of-the-art on several popular depth datasets across all metrics.We also validate the effectiveness of the proposed block with an ablation study and provide the code and corresponding pre-trained weights of the new state-of-the-art model.
|
||||
|
||||
Our main contributions are the following:
|
||||
|
||||
- We propose an architecture building block that performs global processing of the scene’s information.We propose to divide the predicted depth range into bins where the bin widths change per image. The final depth estimation is a linear combination of the bin center values.
|
||||
- We show a decisive improvement for supervised single image depth estimation across all metrics for the two most popular datasets, NYU and KITTI.
|
||||
- We analyze our findings and investigate different modifications on the proposed AdaBins block and study their effect on the accuracy of the depth estimation.
|
||||
|
||||
<div align="center">
|
||||
<img src="https://github.com/open-mmlab/mmsegmentation/assets/15952744/915bcd5a-9dc2-4602-a6e7-055ff5d4889f" width = "1000" />
|
||||
</div>
|
||||
|
||||
## <img src="https://user-images.githubusercontent.com/34859558/190044217-8f6befc2-7f20-473d-b356-148e06265205.png" width="25"/> Performance
|
||||
|
||||
### NYU and KITTI
|
||||
|
||||
| Model | Encoder | Training epoch | Batchsize | Train Resolution | δ1 | δ2 | δ3 | REL | RMS | RMS log | params(M) | Links |
|
||||
| ------------- | --------------- | -------------- | --------- | ---------------- | ----- | ----- | ----- | ----- | ----- | ------- | --------- | ----------------------------------------------------------------------------------------------------------------------- |
|
||||
| AdaBins_nyu | EfficientNet-B5 | 25 | 16 | 416x544 | 0.903 | 0.984 | 0.997 | 0.103 | 0.364 | 0.044 | 78 | [model](https://download.openmmlab.com/mmsegmentation/v0.5/adabins/adabins_efficient_b5_nyu_third-party-f68d6bd3.pth) |
|
||||
| AdaBins_kitti | EfficientNet-B5 | 25 | 16 | 352x764 | 0.964 | 0.995 | 0.999 | 0.058 | 2.360 | 0.088 | 78 | [model](https://download.openmmlab.com/mmsegmentation/v0.5/adabins/adabins_efficient-b5_kitty_third-party-a1aa6f36.pth) |
|
||||
|
||||
## Citation
|
||||
|
||||
```bibtex
|
||||
@article{10.1109/cvpr46437.2021.00400,
|
||||
author = {Bhat, S. A. and Alhashim, I. and Wonka, P.},
|
||||
title = {Adabins: depth estimation using adaptive bins},
|
||||
journal = {2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
|
||||
year = {2021},
|
||||
doi = {10.1109/cvpr46437.2021.00400}
|
||||
}
|
||||
```
|
||||
@@ -0,0 +1,4 @@
|
||||
# Copyright (c) OpenMMLab. All rights reserved.
|
||||
from .adabins_backbone import AdabinsBackbone
|
||||
|
||||
__all__ = ['AdabinsBackbone']
|
||||
@@ -0,0 +1,141 @@
|
||||
import timm
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.nn.functional as F
|
||||
from mmcv.cnn import ConvModule, build_conv_layer
|
||||
from mmengine.model import BaseModule
|
||||
|
||||
from mmseg.registry import MODELS
|
||||
|
||||
|
||||
class UpSampleBN(nn.Module):
|
||||
""" UpSample module
|
||||
Args:
|
||||
skip_input (int): the input feature
|
||||
output_features (int): the output feature
|
||||
norm_cfg (dict, optional): Config dict for normalization layer.
|
||||
Default: dict(type='BN', requires_grad=True).
|
||||
act_cfg (dict, optional): The activation layer of AAM:
|
||||
Aggregate Attention Module.
|
||||
"""
|
||||
|
||||
def __init__(self,
|
||||
skip_input,
|
||||
output_features,
|
||||
norm_cfg=dict(type='BN'),
|
||||
act_cfg=dict(type='LeakyReLU')):
|
||||
super().__init__()
|
||||
|
||||
self._net = nn.Sequential(
|
||||
ConvModule(
|
||||
in_channels=skip_input,
|
||||
out_channels=output_features,
|
||||
kernel_size=3,
|
||||
stride=1,
|
||||
padding=1,
|
||||
bias=True,
|
||||
norm_cfg=norm_cfg,
|
||||
act_cfg=act_cfg,
|
||||
),
|
||||
ConvModule(
|
||||
in_channels=output_features,
|
||||
out_channels=output_features,
|
||||
kernel_size=3,
|
||||
stride=1,
|
||||
padding=1,
|
||||
bias=True,
|
||||
norm_cfg=norm_cfg,
|
||||
act_cfg=act_cfg,
|
||||
))
|
||||
|
||||
def forward(self, x, concat_with):
|
||||
up_x = F.interpolate(
|
||||
x,
|
||||
size=[concat_with.size(2),
|
||||
concat_with.size(3)],
|
||||
mode='bilinear',
|
||||
align_corners=True)
|
||||
f = torch.cat([up_x, concat_with], dim=1)
|
||||
return self._net(f)
|
||||
|
||||
|
||||
class Encoder(nn.Module):
|
||||
""" the efficientnet_b5 model
|
||||
Args:
|
||||
basemodel_name (str): the name of base model
|
||||
"""
|
||||
|
||||
def __init__(self, basemodel_name):
|
||||
super().__init__()
|
||||
self.original_model = timm.create_model(
|
||||
basemodel_name, pretrained=True)
|
||||
# Remove last layer
|
||||
self.original_model.global_pool = nn.Identity()
|
||||
self.original_model.classifier = nn.Identity()
|
||||
|
||||
def forward(self, x):
|
||||
features = [x]
|
||||
for k, v in self.original_model._modules.items():
|
||||
if k == 'blocks':
|
||||
for ki, vi in v._modules.items():
|
||||
features.append(vi(features[-1]))
|
||||
else:
|
||||
features.append(v(features[-1]))
|
||||
return features
|
||||
|
||||
|
||||
@MODELS.register_module()
|
||||
class AdabinsBackbone(BaseModule):
|
||||
""" the backbone of the adabins
|
||||
Args:
|
||||
basemodel_name (str):the name of base model
|
||||
num_features (int): the middle feature
|
||||
num_classes (int): the classes number
|
||||
bottleneck_features (int): the bottleneck features
|
||||
conv_cfg (dict): Config dict for convolution layer.
|
||||
"""
|
||||
|
||||
def __init__(self,
|
||||
basemodel_name,
|
||||
num_features=2048,
|
||||
num_classes=128,
|
||||
bottleneck_features=2048,
|
||||
conv_cfg=dict(type='Conv')):
|
||||
super().__init__()
|
||||
self.encoder = Encoder(basemodel_name)
|
||||
features = int(num_features)
|
||||
self.conv2 = build_conv_layer(
|
||||
conv_cfg,
|
||||
bottleneck_features,
|
||||
features,
|
||||
kernel_size=1,
|
||||
stride=1,
|
||||
padding=1)
|
||||
self.up1 = UpSampleBN(
|
||||
skip_input=features // 1 + 112 + 64, output_features=features // 2)
|
||||
self.up2 = UpSampleBN(
|
||||
skip_input=features // 2 + 40 + 24, output_features=features // 4)
|
||||
self.up3 = UpSampleBN(
|
||||
skip_input=features // 4 + 24 + 16, output_features=features // 8)
|
||||
self.up4 = UpSampleBN(
|
||||
skip_input=features // 8 + 16 + 8, output_features=features // 16)
|
||||
|
||||
self.conv3 = build_conv_layer(
|
||||
conv_cfg,
|
||||
features // 16,
|
||||
num_classes,
|
||||
kernel_size=3,
|
||||
stride=1,
|
||||
padding=1)
|
||||
|
||||
def forward(self, x):
|
||||
features = self.encoder(x)
|
||||
x_block0, x_block1, x_block2, x_block3, x_block4 = features[
|
||||
3], features[4], features[5], features[7], features[10]
|
||||
x_d0 = self.conv2(x_block4)
|
||||
x_d1 = self.up1(x_d0, x_block3)
|
||||
x_d2 = self.up2(x_d1, x_block2)
|
||||
x_d3 = self.up3(x_d2, x_block1)
|
||||
x_d4 = self.up4(x_d3, x_block0)
|
||||
out = self.conv3(x_d4)
|
||||
return out
|
||||
@@ -0,0 +1,32 @@
|
||||
dataset_type = 'NYUDataset'
|
||||
data_root = 'data/nyu'
|
||||
|
||||
test_pipeline = [
|
||||
dict(dict(type='LoadImageFromFile', to_float32=True)),
|
||||
dict(dict(type='LoadDepthAnnotation', depth_rescale_factor=1e-3)),
|
||||
dict(
|
||||
type='PackSegInputs',
|
||||
meta_keys=('img_path', 'depth_map_path', 'ori_shape', 'img_shape',
|
||||
'pad_shape', 'scale_factor', 'flip', 'flip_direction',
|
||||
'category_id'))
|
||||
]
|
||||
|
||||
val_dataloader = dict(
|
||||
batch_size=1,
|
||||
num_workers=4,
|
||||
persistent_workers=True,
|
||||
sampler=dict(type='DefaultSampler', shuffle=False),
|
||||
dataset=dict(
|
||||
type=dataset_type,
|
||||
data_root=data_root,
|
||||
test_mode=True,
|
||||
data_prefix=dict(
|
||||
img_path='images/test', depth_map_path='annotations/test'),
|
||||
pipeline=test_pipeline))
|
||||
test_dataloader = val_dataloader
|
||||
|
||||
val_evaluator = dict(
|
||||
type='DepthMetric', max_depth_eval=10.0, crop_type='nyu_crop')
|
||||
test_evaluator = val_evaluator
|
||||
val_cfg = dict(type='ValLoop')
|
||||
test_cfg = dict(type='TestLoop')
|
||||
@@ -0,0 +1,15 @@
|
||||
default_scope = 'mmseg'
|
||||
env_cfg = dict(
|
||||
cudnn_benchmark=True,
|
||||
mp_cfg=dict(mp_start_method='fork', opencv_num_threads=0),
|
||||
dist_cfg=dict(backend='nccl'),
|
||||
)
|
||||
vis_backends = [dict(type='LocalVisBackend')]
|
||||
visualizer = dict(
|
||||
type='SegLocalVisualizer', vis_backends=vis_backends, name='visualizer')
|
||||
log_processor = dict(by_epoch=False)
|
||||
log_level = 'INFO'
|
||||
load_from = None
|
||||
resume = False
|
||||
|
||||
tta_model = dict(type='SegTTAModel')
|
||||
@@ -0,0 +1,35 @@
|
||||
# model settings
|
||||
norm_cfg = dict(type='SyncBN', requires_grad=True)
|
||||
data_preprocessor = dict(
|
||||
type='SegDataPreProcessor',
|
||||
mean=[123.675, 116.28, 103.53],
|
||||
std=[58.395, 57.12, 57.375],
|
||||
bgr_to_rgb=True,
|
||||
pad_val=0,
|
||||
seg_pad_val=255)
|
||||
model = dict(
|
||||
type='DepthEstimator',
|
||||
data_preprocessor=data_preprocessor,
|
||||
# pretrained='open-mmlab://resnet50_v1c',
|
||||
backbone=dict(
|
||||
type='AdabinsBackbone',
|
||||
basemodel_name='tf_efficientnet_b5_ap',
|
||||
num_features=2048,
|
||||
num_classes=128,
|
||||
bottleneck_features=2048,
|
||||
),
|
||||
decode_head=dict(
|
||||
type='AdabinsHead',
|
||||
in_channels=128,
|
||||
n_query_channels=128,
|
||||
patch_size=16,
|
||||
embedding_dim=128,
|
||||
num_heads=4,
|
||||
n_bins=256,
|
||||
min_val=0.001,
|
||||
max_val=10,
|
||||
norm='linear'),
|
||||
|
||||
# model training and testing settings
|
||||
train_cfg=dict(),
|
||||
test_cfg=dict(mode='whole'))
|
||||
@@ -0,0 +1,15 @@
|
||||
_base_ = [
|
||||
'../_base_/models/Adabins.py', '../_base_/datasets/nyu.py',
|
||||
'../_base_/default_runtime.py'
|
||||
]
|
||||
custom_imports = dict(
|
||||
imports=['projects.Adabins.backbones', 'projects.Adabins.decode_head'],
|
||||
allow_failed_imports=False)
|
||||
crop_size = (416, 544)
|
||||
data_preprocessor = dict(size=crop_size)
|
||||
norm_cfg = dict(type='SyncBN', requires_grad=True)
|
||||
model = dict(
|
||||
data_preprocessor=data_preprocessor,
|
||||
backbone=dict(),
|
||||
decode_head=dict(),
|
||||
)
|
||||
@@ -0,0 +1,12 @@
|
||||
_base_ = ['../_base_/models/Adabins.py']
|
||||
custom_imports = dict(
|
||||
imports=['projects.Adabins.backbones', 'projects.Adabins.decode_head'],
|
||||
allow_failed_imports=False)
|
||||
crop_size = (352, 704)
|
||||
data_preprocessor = dict(size=crop_size)
|
||||
norm_cfg = dict(type='SyncBN', requires_grad=True)
|
||||
model = dict(
|
||||
data_preprocessor=data_preprocessor,
|
||||
backbone=dict(),
|
||||
decode_head=dict(min_val=0.001, max_val=80),
|
||||
)
|
||||
@@ -0,0 +1,4 @@
|
||||
# Copyright (c) OpenMMLab. All rights reserved.
|
||||
from .adabins_head import AdabinsHead
|
||||
|
||||
__all__ = ['AdabinsHead']
|
||||
@@ -0,0 +1,179 @@
|
||||
from typing import List, Tuple
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.nn.functional as F
|
||||
from mmcv.cnn import build_conv_layer
|
||||
from torch import Tensor
|
||||
|
||||
from mmseg.registry import MODELS
|
||||
|
||||
|
||||
class PatchTransformerEncoder(nn.Module):
|
||||
"""the Patch Transformer Encoder.
|
||||
|
||||
Args:
|
||||
in_channels (int): the channels of input
|
||||
patch_size (int): the path size
|
||||
embedding_dim (int): The feature dimension.
|
||||
num_heads (int): the number of encoder head
|
||||
conv_cfg (dict): Config dict for convolution layer.
|
||||
"""
|
||||
|
||||
def __init__(self,
|
||||
in_channels,
|
||||
patch_size=10,
|
||||
embedding_dim=128,
|
||||
num_heads=4,
|
||||
conv_cfg=dict(type='Conv')):
|
||||
super().__init__()
|
||||
encoder_layers = nn.TransformerEncoderLayer(
|
||||
embedding_dim, num_heads, dim_feedforward=1024)
|
||||
self.transformer_encoder = nn.TransformerEncoder(
|
||||
encoder_layers, num_layers=4) # takes shape S,N,E
|
||||
|
||||
self.embedding_convPxP = build_conv_layer(
|
||||
conv_cfg,
|
||||
in_channels,
|
||||
embedding_dim,
|
||||
kernel_size=patch_size,
|
||||
stride=patch_size)
|
||||
self.positional_encodings = nn.Parameter(
|
||||
torch.rand(500, embedding_dim), requires_grad=True)
|
||||
|
||||
def forward(self, x):
|
||||
embeddings = self.embedding_convPxP(x).flatten(
|
||||
2) # .shape = n,c,s = n, embedding_dim, s
|
||||
embeddings = embeddings + self.positional_encodings[:embeddings.shape[
|
||||
2], :].T.unsqueeze(0)
|
||||
|
||||
# change to S,N,E format required by transformer
|
||||
embeddings = embeddings.permute(2, 0, 1)
|
||||
x = self.transformer_encoder(embeddings) # .shape = S, N, E
|
||||
return x
|
||||
|
||||
|
||||
class PixelWiseDotProduct(nn.Module):
|
||||
"""the pixel wise dot product."""
|
||||
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
|
||||
def forward(self, x, K):
|
||||
n, c, h, w = x.size()
|
||||
_, cout, ck = K.size()
|
||||
assert c == ck, 'Number of channels in x and Embedding dimension ' \
|
||||
'(at dim 2) of K matrix must match'
|
||||
y = torch.matmul(
|
||||
x.view(n, c, h * w).permute(0, 2, 1),
|
||||
K.permute(0, 2, 1)) # .shape = n, hw, cout
|
||||
return y.permute(0, 2, 1).view(n, cout, h, w)
|
||||
|
||||
|
||||
@MODELS.register_module()
|
||||
class AdabinsHead(nn.Module):
|
||||
"""the head of the adabins,include mViT.
|
||||
|
||||
Args:
|
||||
in_channels (int):the channels of the input
|
||||
n_query_channels (int):the channels of the query
|
||||
patch_size (int): the patch size
|
||||
embedding_dim (int):The feature dimension.
|
||||
num_heads (int):the number of head
|
||||
n_bins (int):the number of bins
|
||||
min_val (float): the min width of bin
|
||||
max_val (float): the max width of bin
|
||||
conv_cfg (dict): Config dict for convolution layer.
|
||||
norm (str): the activate method
|
||||
align_corners (bool, optional): Geometrically, we consider the pixels
|
||||
of the input and output as squares rather than points.
|
||||
"""
|
||||
|
||||
def __init__(self,
|
||||
in_channels,
|
||||
n_query_channels=128,
|
||||
patch_size=16,
|
||||
embedding_dim=128,
|
||||
num_heads=4,
|
||||
n_bins=100,
|
||||
min_val=0.1,
|
||||
max_val=10,
|
||||
conv_cfg=dict(type='Conv'),
|
||||
norm='linear',
|
||||
align_corners=False,
|
||||
threshold=0):
|
||||
super().__init__()
|
||||
self.out_channels = n_bins
|
||||
self.align_corners = align_corners
|
||||
self.norm = norm
|
||||
self.num_classes = n_bins
|
||||
self.min_val = min_val
|
||||
self.max_val = max_val
|
||||
self.n_query_channels = n_query_channels
|
||||
self.patch_transformer = PatchTransformerEncoder(
|
||||
in_channels, patch_size, embedding_dim, num_heads)
|
||||
self.dot_product_layer = PixelWiseDotProduct()
|
||||
self.threshold = threshold
|
||||
self.conv3x3 = build_conv_layer(
|
||||
conv_cfg,
|
||||
in_channels,
|
||||
embedding_dim,
|
||||
kernel_size=3,
|
||||
stride=1,
|
||||
padding=1)
|
||||
self.regressor = nn.Sequential(
|
||||
nn.Linear(embedding_dim, 256), nn.LeakyReLU(), nn.Linear(256, 256),
|
||||
nn.LeakyReLU(), nn.Linear(256, n_bins))
|
||||
self.conv_out = nn.Sequential(
|
||||
build_conv_layer(conv_cfg, in_channels, n_bins, kernel_size=1),
|
||||
nn.Softmax(dim=1))
|
||||
|
||||
def forward(self, x):
|
||||
# n, c, h, w = x.size()
|
||||
tgt = self.patch_transformer(x.clone()) # .shape = S, N, E
|
||||
|
||||
x = self.conv3x3(x)
|
||||
|
||||
regression_head, queries = tgt[0,
|
||||
...], tgt[1:self.n_query_channels + 1,
|
||||
...]
|
||||
|
||||
# Change from S, N, E to N, S, E
|
||||
queries = queries.permute(1, 0, 2)
|
||||
range_attention_maps = self.dot_product_layer(
|
||||
x, queries) # .shape = n, n_query_channels, h, w
|
||||
|
||||
y = self.regressor(regression_head) # .shape = N, dim_out
|
||||
if self.norm == 'linear':
|
||||
y = torch.relu(y)
|
||||
eps = 0.1
|
||||
y = y + eps
|
||||
elif self.norm == 'softmax':
|
||||
return torch.softmax(y, dim=1), range_attention_maps
|
||||
else:
|
||||
y = torch.sigmoid(y)
|
||||
bin_widths_normed = y / y.sum(dim=1, keepdim=True)
|
||||
out = self.conv_out(range_attention_maps)
|
||||
|
||||
bin_widths = (self.max_val -
|
||||
self.min_val) * bin_widths_normed # .shape = N, dim_out
|
||||
bin_widths = F.pad(
|
||||
bin_widths, (1, 0), mode='constant', value=self.min_val)
|
||||
bin_edges = torch.cumsum(bin_widths, dim=1)
|
||||
|
||||
centers = 0.5 * (bin_edges[:, :-1] + bin_edges[:, 1:])
|
||||
n, dim_out = centers.size()
|
||||
centers = centers.view(n, dim_out, 1, 1)
|
||||
|
||||
pred = torch.sum(out * centers, dim=1, keepdim=True)
|
||||
return bin_edges, pred
|
||||
|
||||
def predict(self, inputs: Tuple[Tensor], batch_img_metas: List[dict],
|
||||
test_cfg, **kwargs) -> Tensor:
|
||||
"""Forward function for testing, only ``pam_cam`` is used."""
|
||||
pred = self.forward(inputs)[-1]
|
||||
final = torch.clamp(pred, self.min_val, self.max_val)
|
||||
|
||||
final[torch.isinf(final)] = self.max_val
|
||||
final[torch.isnan(final)] = self.min_val
|
||||
return final
|
||||
92
Seg_All_In_One_MMSeg/projects/CAT-Seg/README.md
Normal file
92
Seg_All_In_One_MMSeg/projects/CAT-Seg/README.md
Normal file
@@ -0,0 +1,92 @@
|
||||
# CAT-Seg
|
||||
|
||||
> [CAT-Seg: Cost Aggregation for Open-Vocabulary Semantic Segmentation](https://arxiv.org/abs/2303.11797)
|
||||
|
||||
## Introduction
|
||||
|
||||
<!-- [ALGORITHM] -->
|
||||
|
||||
<a href="https://github.com/KU-CVLAB/CAT-Seg">Official Repo</a>
|
||||
|
||||
<a href="https://github.com/SheffieldCao/mmsegmentation/blob/support-cat-seg/mmseg/models/necks/cat_aggregator.py">Code Snippet</a>
|
||||
|
||||
## Abstract
|
||||
|
||||
<!-- [ABSTRACT] -->
|
||||
|
||||
Existing works on open-vocabulary semantic segmentation have utilized large-scale vision-language models, such as CLIP, to leverage their exceptional open-vocabulary recognition capabilities. However, the problem of transferring these capabilities learned from image-level supervision to the pixel-level task of segmentation and addressing arbitrary unseen categories at inference makes this task challenging. To address these issues, we aim to attentively relate objects within an image to given categories by leveraging relational information among class categories and visual semantics through aggregation, while also adapting the CLIP representations to the pixel-level task. However, we observe that direct optimization of the CLIP embeddings can harm its open-vocabulary capabilities. In this regard, we propose an alternative approach to optimize the imagetext similarity map, i.e. the cost map, using a novel cost aggregation-based method. Our framework, namely CATSeg, achieves state-of-the-art performance across all benchmarks. We provide extensive ablation studies to validate our choices. [Project page](https://ku-cvlab.github.io/CAT-Seg).
|
||||
|
||||
<!-- [IMAGE] -->
|
||||
|
||||
<div align=center >
|
||||
<img alt="CAT-Seg" src="https://github.com/open-mmlab/mmsegmentation/assets/49406546/d54674bb-52ae-4a20-a168-e25d041111e8"/>
|
||||
CAT-Seg model structure
|
||||
</div>
|
||||
|
||||
## Usage
|
||||
|
||||
CAT-Seg model training needs pretrained `CLIP` model. We have implemented `ViT-B` and `ViT-L` based `CLIP` model. To further use `ViT-bigG` or `ViT-H` ones, you need additional dependencies. Please install [open_clip](https://github.com/mlfoundations/open_clip) first. The pretrained `CLIP` model state dicts are loaded from [Huggingface-OpenCLIP](https://huggingface.co/models?library=open_clip). **If you come up with `ConnectionError` when downloading CLIP weights**, you can manually download them from the given repo and use `custom_clip_weights=/path/to/you/folder` of backbone in config file. Related tools are as shown in [requirements/optional.txt](requirements/optional.txt):
|
||||
|
||||
```shell
|
||||
pip install ftfy==6.0.1
|
||||
pip install huggingface-hub
|
||||
pip install regex
|
||||
```
|
||||
|
||||
In addition to the necessary [data preparation](https://github.com/open-mmlab/mmsegmentation/blob/main/docs/en/user_guides/2_dataset_prepare.md), you also need class texts for clip text encoder. Please download the class text json file first [cls_texts](https://github.com/open-mmlab/mmsegmentation/files/11714914/cls_texts.zip) and arrange the folder as follows:
|
||||
|
||||
```none
|
||||
mmsegmentation
|
||||
├── mmseg
|
||||
├── tools
|
||||
├── configs
|
||||
├── data
|
||||
│ ├── VOCdevkit
|
||||
│ │ ├── VOC2012
|
||||
│ │ ├── VOC2010
|
||||
│ │ ├── VOCaug
|
||||
│ ├── ade
|
||||
│ ├── coco_stuff164k
|
||||
│ ├── coco.json
|
||||
│ ├── pc59.json
|
||||
│ ├── pc459.json
|
||||
│ ├── ade150.json
|
||||
│ ├── ade847.json
|
||||
│ ├── voc20b.json
|
||||
│ ├── voc20.json
|
||||
```
|
||||
|
||||
```shell
|
||||
# setup PYTHONPATH
|
||||
export PYTHONPATH=`pwd`:$PYTHONPATH
|
||||
# run evaluation
|
||||
mim test mmsegmentation ${CONFIG} --checkpoint ${CHECKPOINT} --launcher pytorch --gpus=8
|
||||
```
|
||||
|
||||
## Results and models
|
||||
|
||||
### ADE20K-150-ZeroShot
|
||||
|
||||
| Method | Backbone | Crop Size | Lr schd | Mem (GB) | Inf time (fps) | Device | mIoU | mIoU(ms+flip) | config | download |
|
||||
| ------- | ------------- | --------- | ------- | -------: | -------------- | ------- | ---- | ------------: | ------------------------------------------------------------------------------------------: | --------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| CAT-Seg | R-101 & ViT-B | 384x384 | 80000 | - | - | RTX3090 | 27.2 | - | [config](./configs/cat_seg/catseg_vitb-r101_4xb1-warmcoslr2e-4-adamw-80k_ade20k-384x384.py) | [model](https://download.openmmlab.com/mmsegmentation/v0.5/cat_seg/catseg_vitb-r101_4xb1-warmcoslr2e-4-adamw-80k_ade20k-384x384-54194d72.pth) |
|
||||
|
||||
Note:
|
||||
|
||||
- All experiments of CAT-Seg are implemented with 4 RTX3090 GPUs, except the last one with pretrained ViT-bigG CLIP model (GPU Memory insufficient, you may need A100).
|
||||
- Due to the feature size bottleneck of the CLIP image encoder, the inference and testing can only be done under `slide` mode, the inference time is longer since the test size is much more bigger that training size of `(384, 384)`.
|
||||
- The ResNet backbones utilized in CAT-Seg models are standard `ResNet` rather than `ResNetV1c`.
|
||||
- The zero-shot segmentation results on PASCAL VOC and ADE20K are from the original paper. Our results are coming soon. We appreatiate your contribution!
|
||||
- In additional to zero-shot segmentation performance results, we also provided the evaluation results on the `val2017` set of **COCO-stuff164k** for reference, which is the training dataset of CAT-Seg. The testing was done **without TTA**.
|
||||
- The number behind the dataset name is the category number for segmentation evaluation (except training data **COCO-stuff 164k**). **PASCAL VOC-20b** defines the "background" as classes present in **PASCAL-Context-59** but not in **PASCAL VOC-20**.
|
||||
|
||||
## Citation
|
||||
|
||||
```bibtex
|
||||
@inproceedings{cheng2021mask2former,
|
||||
title={CAT-Seg: Cost Aggregation for Open-Vocabulary Semantic Segmentation},
|
||||
author={Seokju Cho and Heeseong Shin and Sunghwan Hong and Seungjun An and Seungjun Lee and Anurag Arnab and Paul Hongsuck Seo and Seungryong Kim},
|
||||
journal={CVPR},
|
||||
year={2023}
|
||||
}
|
||||
```
|
||||
@@ -0,0 +1,2 @@
|
||||
from .models import * # noqa: F401,F403
|
||||
from .utils import * # noqa: F401,F403
|
||||
@@ -0,0 +1,10 @@
|
||||
# Copyright (c) OpenMMLab. All rights reserved.
|
||||
from .cat_aggregator import (AggregatorLayer, CATSegAggregator,
|
||||
ClassAggregateLayer, SpatialAggregateLayer)
|
||||
from .cat_head import CATSegHead
|
||||
from .clip_ovseg import CLIPOVCATSeg
|
||||
|
||||
__all__ = [
|
||||
'AggregatorLayer', 'CATSegAggregator', 'ClassAggregateLayer',
|
||||
'SpatialAggregateLayer', 'CATSegHead', 'CLIPOVCATSeg'
|
||||
]
|
||||
@@ -0,0 +1,763 @@
|
||||
# Copyright (c) OpenMMLab. All rights reserved.
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.nn.functional as F
|
||||
from mmcv.cnn import build_norm_layer
|
||||
from mmcv.cnn.bricks.transformer import FFN, build_dropout
|
||||
from mmengine.model import BaseModule
|
||||
from mmengine.utils import to_2tuple
|
||||
|
||||
from mmseg.registry import MODELS
|
||||
from ..utils import FullAttention, LinearAttention
|
||||
|
||||
|
||||
class AGWindowMSA(BaseModule):
|
||||
"""Appearance Guidance Window based multi-head self-attention (W-MSA)
|
||||
module with relative position bias.
|
||||
|
||||
Args:
|
||||
embed_dims (int): Number of input channels.
|
||||
appearance_dims (int): Number of appearance guidance feature channels.
|
||||
num_heads (int): Number of attention heads.
|
||||
window_size (tuple[int]): The height and width of the window.
|
||||
qkv_bias (bool, optional): If True, add a learnable bias to q, k, v.
|
||||
Default: True.
|
||||
qk_scale (float | None, optional): Override default qk scale of
|
||||
head_dim ** -0.5 if set. Default: None.
|
||||
attn_drop_rate (float, optional): Dropout ratio of attention weight.
|
||||
Default: 0.0
|
||||
proj_drop_rate (float, optional): Dropout ratio of output. Default: 0.
|
||||
init_cfg (dict | None, optional): The Config for initialization.
|
||||
Default: None.
|
||||
"""
|
||||
|
||||
def __init__(self,
|
||||
embed_dims,
|
||||
appearance_dims,
|
||||
num_heads,
|
||||
window_size,
|
||||
qkv_bias=True,
|
||||
qk_scale=None,
|
||||
attn_drop_rate=0.,
|
||||
proj_drop_rate=0.,
|
||||
init_cfg=None):
|
||||
|
||||
super().__init__(init_cfg=init_cfg)
|
||||
self.embed_dims = embed_dims
|
||||
self.appearance_dims = appearance_dims
|
||||
self.window_size = window_size # Wh, Ww
|
||||
self.num_heads = num_heads
|
||||
head_embed_dims = embed_dims // num_heads
|
||||
self.scale = qk_scale or head_embed_dims**-0.5
|
||||
|
||||
# About 2x faster than original impl
|
||||
Wh, Ww = self.window_size
|
||||
rel_index_coords = self.double_step_seq(2 * Ww - 1, Wh, 1, Ww)
|
||||
rel_position_index = rel_index_coords + rel_index_coords.T
|
||||
rel_position_index = rel_position_index.flip(1).contiguous()
|
||||
self.register_buffer('relative_position_index', rel_position_index)
|
||||
|
||||
self.qk = nn.Linear(
|
||||
embed_dims + appearance_dims, embed_dims * 2, bias=qkv_bias)
|
||||
self.v = nn.Linear(embed_dims, embed_dims, bias=qkv_bias)
|
||||
self.attn_drop = nn.Dropout(attn_drop_rate)
|
||||
self.proj = nn.Linear(embed_dims, embed_dims)
|
||||
self.proj_drop = nn.Dropout(proj_drop_rate)
|
||||
|
||||
self.softmax = nn.Softmax(dim=-1)
|
||||
|
||||
def forward(self, x, mask=None):
|
||||
"""
|
||||
Args:
|
||||
x (tensor): input features with shape of (num_windows*B, N, C),
|
||||
C = embed_dims + appearance_dims.
|
||||
mask (tensor | None, Optional): mask with shape of (num_windows,
|
||||
Wh*Ww, Wh*Ww), value should be between (-inf, 0].
|
||||
"""
|
||||
B, N, _ = x.shape
|
||||
qk = self.qk(x).reshape(B, N, 2, self.num_heads,
|
||||
self.embed_dims // self.num_heads).permute(
|
||||
2, 0, 3, 1,
|
||||
4) # 2 B NUM_HEADS N embed_dims//NUM_HEADS
|
||||
v = self.v(x[:, :, :self.embed_dims]).reshape(
|
||||
B, N, self.num_heads, self.embed_dims // self.num_heads).permute(
|
||||
0, 2, 1, 3) # B NUM_HEADS N embed_dims//NUM_HEADS
|
||||
# make torchscript happy (cannot use tensor as tuple)
|
||||
q, k = qk[0], qk[1]
|
||||
|
||||
q = q * self.scale
|
||||
attn = (q @ k.transpose(-2, -1))
|
||||
|
||||
if mask is not None:
|
||||
nW = mask.shape[0]
|
||||
attn = attn.view(B // nW, nW, self.num_heads, N,
|
||||
N) + mask.unsqueeze(1).unsqueeze(0)
|
||||
attn = attn.view(-1, self.num_heads, N, N)
|
||||
attn = self.softmax(attn)
|
||||
|
||||
attn = self.attn_drop(attn)
|
||||
|
||||
x = (attn @ v).transpose(1, 2).reshape(B, N, self.embed_dims)
|
||||
x = self.proj(x)
|
||||
x = self.proj_drop(x)
|
||||
return x
|
||||
|
||||
@staticmethod
|
||||
def double_step_seq(step1, len1, step2, len2):
|
||||
"""Double step sequence."""
|
||||
seq1 = torch.arange(0, step1 * len1, step1)
|
||||
seq2 = torch.arange(0, step2 * len2, step2)
|
||||
return (seq1[:, None] + seq2[None, :]).reshape(1, -1)
|
||||
|
||||
|
||||
class AGShiftWindowMSA(BaseModule):
|
||||
"""Appearance Guidance Shifted Window Multihead Self-Attention Module.
|
||||
|
||||
Args:
|
||||
embed_dims (int): Number of input channels.
|
||||
appearance_dims (int): Number of appearance guidance channels
|
||||
num_heads (int): Number of attention heads.
|
||||
window_size (int): The height and width of the window.
|
||||
shift_size (int, optional): The shift step of each window towards
|
||||
right-bottom. If zero, act as regular window-msa. Defaults to 0.
|
||||
qkv_bias (bool, optional): If True, add a learnable bias to q, k, v.
|
||||
Default: True
|
||||
qk_scale (float | None, optional): Override default qk scale of
|
||||
head_dim ** -0.5 if set. Defaults: None.
|
||||
attn_drop_rate (float, optional): Dropout ratio of attention weight.
|
||||
Defaults: 0.
|
||||
proj_drop_rate (float, optional): Dropout ratio of output.
|
||||
Defaults: 0.
|
||||
dropout_layer (dict, optional): The dropout_layer used before output.
|
||||
Defaults: dict(type='DropPath', drop_prob=0.).
|
||||
init_cfg (dict, optional): The extra config for initialization.
|
||||
Default: None.
|
||||
"""
|
||||
|
||||
def __init__(self,
|
||||
embed_dims,
|
||||
appearance_dims,
|
||||
num_heads,
|
||||
window_size,
|
||||
shift_size=0,
|
||||
qkv_bias=True,
|
||||
qk_scale=None,
|
||||
attn_drop_rate=0,
|
||||
proj_drop_rate=0,
|
||||
dropout_layer=dict(type='DropPath', drop_prob=0.),
|
||||
init_cfg=None):
|
||||
super().__init__(init_cfg=init_cfg)
|
||||
|
||||
self.window_size = window_size
|
||||
self.shift_size = shift_size
|
||||
assert 0 <= self.shift_size < self.window_size
|
||||
|
||||
self.w_msa = AGWindowMSA(
|
||||
embed_dims=embed_dims,
|
||||
appearance_dims=appearance_dims,
|
||||
num_heads=num_heads,
|
||||
window_size=to_2tuple(window_size),
|
||||
qkv_bias=qkv_bias,
|
||||
qk_scale=qk_scale,
|
||||
attn_drop_rate=attn_drop_rate,
|
||||
proj_drop_rate=proj_drop_rate,
|
||||
init_cfg=None)
|
||||
|
||||
self.drop = build_dropout(dropout_layer)
|
||||
|
||||
def forward(self, query, hw_shape):
|
||||
"""
|
||||
Args:
|
||||
query: The input query.
|
||||
hw_shape: The shape of the feature height and width.
|
||||
"""
|
||||
B, L, C = query.shape
|
||||
H, W = hw_shape
|
||||
assert L == H * W, 'input feature has wrong size'
|
||||
query = query.view(B, H, W, C)
|
||||
|
||||
# pad feature maps to multiples of window size
|
||||
pad_r = (self.window_size - W % self.window_size) % self.window_size
|
||||
pad_b = (self.window_size - H % self.window_size) % self.window_size
|
||||
query = F.pad(query, (0, 0, 0, pad_r, 0, pad_b))
|
||||
H_pad, W_pad = query.shape[1], query.shape[2]
|
||||
|
||||
# cyclic shift
|
||||
if self.shift_size > 0:
|
||||
shifted_query = torch.roll(
|
||||
query,
|
||||
shifts=(-self.shift_size, -self.shift_size),
|
||||
dims=(1, 2))
|
||||
|
||||
# calculate attention mask for SW-MSA
|
||||
img_mask = torch.zeros((1, H_pad, W_pad, 1), device=query.device)
|
||||
h_slices = (slice(0, -self.window_size),
|
||||
slice(-self.window_size,
|
||||
-self.shift_size), slice(-self.shift_size, None))
|
||||
w_slices = (slice(0, -self.window_size),
|
||||
slice(-self.window_size,
|
||||
-self.shift_size), slice(-self.shift_size, None))
|
||||
cnt = 0
|
||||
for h in h_slices:
|
||||
for w in w_slices:
|
||||
img_mask[:, h, w, :] = cnt
|
||||
cnt += 1
|
||||
|
||||
# nW, window_size, window_size, 1
|
||||
mask_windows = self.window_partition(img_mask)
|
||||
mask_windows = mask_windows.view(
|
||||
-1, self.window_size * self.window_size)
|
||||
attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
|
||||
attn_mask = attn_mask.masked_fill(attn_mask != 0,
|
||||
float(-100.0)).masked_fill(
|
||||
attn_mask == 0, float(0.0))
|
||||
else:
|
||||
shifted_query = query
|
||||
attn_mask = None
|
||||
|
||||
# nW*B, window_size, window_size, C
|
||||
query_windows = self.window_partition(shifted_query)
|
||||
# nW*B, window_size*window_size, C
|
||||
query_windows = query_windows.view(-1, self.window_size**2, C)
|
||||
|
||||
# W-MSA/SW-MSA (nW*B, window_size*window_size, C)
|
||||
attn_windows = self.w_msa(query_windows, mask=attn_mask)
|
||||
|
||||
# merge windows
|
||||
attn_windows = attn_windows.view(-1, self.window_size,
|
||||
self.window_size,
|
||||
self.w_msa.embed_dims)
|
||||
|
||||
# B H' W' self.w_msa.embed_dims
|
||||
shifted_x = self.window_reverse(attn_windows, H_pad, W_pad)
|
||||
# reverse cyclic shift
|
||||
if self.shift_size > 0:
|
||||
x = torch.roll(
|
||||
shifted_x,
|
||||
shifts=(self.shift_size, self.shift_size),
|
||||
dims=(1, 2))
|
||||
else:
|
||||
x = shifted_x
|
||||
|
||||
if pad_r > 0 or pad_b:
|
||||
x = x[:, :H, :W, :].contiguous()
|
||||
|
||||
x = x.view(B, H * W, self.w_msa.embed_dims)
|
||||
|
||||
x = self.drop(x)
|
||||
return x
|
||||
|
||||
def window_reverse(self, windows, H, W):
|
||||
"""
|
||||
Args:
|
||||
windows: (num_windows*B, window_size, window_size, C)
|
||||
H (int): Height of image
|
||||
W (int): Width of image
|
||||
Returns:
|
||||
x: (B, H, W, C)
|
||||
"""
|
||||
window_size = self.window_size
|
||||
B = int(windows.shape[0] / (H * W / window_size / window_size))
|
||||
x = windows.view(B, H // window_size, W // window_size, window_size,
|
||||
window_size, -1)
|
||||
x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)
|
||||
return x
|
||||
|
||||
def window_partition(self, x):
|
||||
"""
|
||||
Args:
|
||||
x: (B, H, W, C)
|
||||
Returns:
|
||||
windows: (num_windows*B, window_size, window_size, C)
|
||||
"""
|
||||
B, H, W, C = x.shape
|
||||
window_size = self.window_size
|
||||
x = x.view(B, H // window_size, window_size, W // window_size,
|
||||
window_size, C)
|
||||
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous()
|
||||
windows = windows.view(-1, window_size, window_size, C)
|
||||
return windows
|
||||
|
||||
|
||||
class AGSwinBlock(BaseModule):
|
||||
"""Appearance Guidance Swin Transformer Block.
|
||||
|
||||
Args:
|
||||
embed_dims (int): The feature dimension.
|
||||
appearance_dims (int): The appearance guidance dimension.
|
||||
num_heads (int): Parallel attention heads.
|
||||
mlp_ratios (int): The hidden dimension ratio w.r.t. embed_dims
|
||||
for FFNs.
|
||||
window_size (int, optional): The local window scale.
|
||||
Default: 7.
|
||||
shift (bool, optional): whether to shift window or not.
|
||||
Default False.
|
||||
qkv_bias (bool, optional): enable bias for qkv if True.
|
||||
Default: True.
|
||||
qk_scale (float | None, optional): Override default qk scale of
|
||||
head_dim ** -0.5 if set. Default: None.
|
||||
drop_rate (float, optional): Dropout rate. Default: 0.
|
||||
attn_drop_rate (float, optional): Attention dropout rate.
|
||||
Default: 0.
|
||||
drop_path_rate (float, optional): Stochastic depth rate.
|
||||
Default: 0.
|
||||
act_cfg (dict, optional): The config dict of activation function.
|
||||
Default: dict(type='GELU').
|
||||
norm_cfg (dict, optional): The config dict of normalization.
|
||||
Default: dict(type='LN').
|
||||
init_cfg (dict | list | None, optional): The init config.
|
||||
Default: None.
|
||||
"""
|
||||
|
||||
def __init__(self,
|
||||
embed_dims,
|
||||
appearance_dims,
|
||||
num_heads,
|
||||
mlp_ratios=4,
|
||||
window_size=7,
|
||||
shift=False,
|
||||
qkv_bias=True,
|
||||
qk_scale=None,
|
||||
drop_rate=0.,
|
||||
attn_drop_rate=0.,
|
||||
drop_path_rate=0.,
|
||||
act_cfg=dict(type='GELU'),
|
||||
norm_cfg=dict(type='LN'),
|
||||
init_cfg=None):
|
||||
super().__init__(init_cfg=init_cfg)
|
||||
self.norm1 = build_norm_layer(norm_cfg, embed_dims)[1]
|
||||
self.attn = AGShiftWindowMSA(
|
||||
embed_dims=embed_dims,
|
||||
appearance_dims=appearance_dims,
|
||||
num_heads=num_heads,
|
||||
window_size=window_size,
|
||||
shift_size=window_size // 2 if shift else 0,
|
||||
qkv_bias=qkv_bias,
|
||||
qk_scale=qk_scale,
|
||||
attn_drop_rate=attn_drop_rate,
|
||||
proj_drop_rate=drop_rate,
|
||||
dropout_layer=dict(type='DropPath', drop_prob=drop_path_rate),
|
||||
init_cfg=None)
|
||||
|
||||
self.norm2 = build_norm_layer(norm_cfg, embed_dims)[1]
|
||||
self.ffn = FFN(
|
||||
embed_dims=embed_dims,
|
||||
feedforward_channels=embed_dims * mlp_ratios,
|
||||
num_fcs=2,
|
||||
ffn_drop=drop_rate,
|
||||
dropout_layer=dict(type='DropPath', drop_prob=drop_path_rate),
|
||||
act_cfg=act_cfg,
|
||||
add_identity=True,
|
||||
init_cfg=None)
|
||||
|
||||
def forward(self, inputs, hw_shape):
|
||||
"""
|
||||
Args:
|
||||
inputs (list[Tensor]): appearance_guidance (B, H, W, C);
|
||||
x (B, L, C)
|
||||
hw_shape (tuple[int]): shape of feature.
|
||||
"""
|
||||
x, appearance_guidance = inputs
|
||||
B, L, C = x.shape
|
||||
H, W = hw_shape
|
||||
assert L == H * W, 'input feature has wrong size'
|
||||
|
||||
identity = x
|
||||
x = self.norm1(x)
|
||||
|
||||
# appearance guidance
|
||||
x = x.view(B, H, W, C)
|
||||
if appearance_guidance is not None:
|
||||
x = torch.cat([x, appearance_guidance], dim=-1).flatten(1, 2)
|
||||
|
||||
x = self.attn(x, hw_shape)
|
||||
|
||||
x = x + identity
|
||||
|
||||
identity = x
|
||||
x = self.norm2(x)
|
||||
x = self.ffn(x, identity=identity)
|
||||
|
||||
return x
|
||||
|
||||
|
||||
@MODELS.register_module()
|
||||
class SpatialAggregateLayer(BaseModule):
|
||||
"""Spatial aggregation layer of CAT-Seg.
|
||||
|
||||
Args:
|
||||
embed_dims (int): The feature dimension.
|
||||
appearance_dims (int): The appearance guidance dimension.
|
||||
num_heads (int): Parallel attention heads.
|
||||
mlp_ratios (int): The hidden dimension ratio w.r.t. embed_dims
|
||||
for FFNs.
|
||||
window_size (int, optional): The local window scale. Default: 7.
|
||||
qk_scale (float | None, optional): Override default qk scale of
|
||||
head_dim ** -0.5 if set. Default: None.
|
||||
init_cfg (dict | list | None, optional): The init config.
|
||||
Default: None.
|
||||
"""
|
||||
|
||||
def __init__(self,
|
||||
embed_dims,
|
||||
appearance_dims,
|
||||
num_heads,
|
||||
mlp_ratios,
|
||||
window_size=7,
|
||||
qk_scale=None,
|
||||
init_cfg=None):
|
||||
super().__init__(init_cfg=init_cfg)
|
||||
self.block_1 = AGSwinBlock(
|
||||
embed_dims,
|
||||
appearance_dims,
|
||||
num_heads,
|
||||
mlp_ratios,
|
||||
window_size=window_size,
|
||||
shift=False,
|
||||
qk_scale=qk_scale)
|
||||
self.block_2 = AGSwinBlock(
|
||||
embed_dims,
|
||||
appearance_dims,
|
||||
num_heads,
|
||||
mlp_ratios,
|
||||
window_size=window_size,
|
||||
shift=True,
|
||||
qk_scale=qk_scale)
|
||||
self.guidance_norm = nn.LayerNorm(
|
||||
appearance_dims) if appearance_dims > 0 else None
|
||||
|
||||
def forward(self, x, appearance_guidance):
|
||||
"""
|
||||
Args:
|
||||
x (torch.Tensor): B C T H W.
|
||||
appearance_guidance (torch.Tensor): B C H W.
|
||||
"""
|
||||
B, C, T, H, W = x.shape
|
||||
x = x.permute(0, 2, 3, 4, 1).flatten(0, 1).flatten(1, 2) # BT, HW, C
|
||||
if appearance_guidance is not None:
|
||||
appearance_guidance = appearance_guidance.repeat(
|
||||
T, 1, 1, 1).permute(0, 2, 3, 1) # BT, HW, C
|
||||
appearance_guidance = self.guidance_norm(appearance_guidance)
|
||||
else:
|
||||
assert self.appearance_dims == 0
|
||||
x = self.block_1((x, appearance_guidance), (H, W))
|
||||
x = self.block_2((x, appearance_guidance), (H, W))
|
||||
x = x.transpose(1, 2).reshape(B, T, C, -1)
|
||||
x = x.transpose(1, 2).reshape(B, C, T, H, W)
|
||||
return x
|
||||
|
||||
|
||||
class AttentionLayer(nn.Module):
|
||||
"""Attention layer for ClassAggregration of CAT-Seg.
|
||||
|
||||
Source: https://github.com/KU-CVLAB/CAT-Seg/blob/main/cat_seg/modeling/transformer/model.py#L310 # noqa
|
||||
"""
|
||||
|
||||
def __init__(self,
|
||||
hidden_dim,
|
||||
guidance_dim,
|
||||
nheads=8,
|
||||
attention_type='linear'):
|
||||
super().__init__()
|
||||
self.nheads = nheads
|
||||
self.q = nn.Linear(hidden_dim + guidance_dim, hidden_dim)
|
||||
self.k = nn.Linear(hidden_dim + guidance_dim, hidden_dim)
|
||||
self.v = nn.Linear(hidden_dim, hidden_dim)
|
||||
|
||||
if attention_type == 'linear':
|
||||
self.attention = LinearAttention()
|
||||
elif attention_type == 'full':
|
||||
self.attention = FullAttention()
|
||||
else:
|
||||
raise NotImplementedError
|
||||
|
||||
def forward(self, x, guidance=None):
|
||||
"""
|
||||
Args:
|
||||
x: B*H_p*W_p, T, C
|
||||
guidance: B*H_p*W_p, T, C
|
||||
"""
|
||||
B, L, _ = x.shape
|
||||
q = self.q(torch.cat([x, guidance],
|
||||
dim=-1)) if guidance is not None else self.q(x)
|
||||
k = self.k(torch.cat([x, guidance],
|
||||
dim=-1)) if guidance is not None else self.k(x)
|
||||
v = self.v(x)
|
||||
|
||||
q = q.reshape(B, L, self.nheads, -1)
|
||||
k = k.reshape(B, L, self.nheads, -1)
|
||||
v = v.reshape(B, L, self.nheads, -1)
|
||||
|
||||
out = self.attention(q, k, v)
|
||||
out = out.reshape(B, L, -1)
|
||||
return out
|
||||
|
||||
|
||||
@MODELS.register_module()
|
||||
class ClassAggregateLayer(BaseModule):
|
||||
"""Class aggregation layer of CAT-Seg.
|
||||
|
||||
Args:
|
||||
hidden_dims (int): The feature dimension.
|
||||
guidance_dims (int): The appearance guidance dimension.
|
||||
num_heads (int): Parallel attention heads.
|
||||
attention_type (str): Type of attention layer. Default: 'linear'.
|
||||
pooling_size (tuple[int] | list[int]): Pooling size.
|
||||
init_cfg (dict | list | None, optional): The init config.
|
||||
Default: None.
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
hidden_dims=64,
|
||||
guidance_dims=64,
|
||||
num_heads=8,
|
||||
attention_type='linear',
|
||||
pooling_size=(4, 4),
|
||||
init_cfg=None,
|
||||
):
|
||||
super().__init__(init_cfg=init_cfg)
|
||||
self.pool = nn.AvgPool2d(pooling_size)
|
||||
self.attention = AttentionLayer(
|
||||
hidden_dims,
|
||||
guidance_dims,
|
||||
nheads=num_heads,
|
||||
attention_type=attention_type)
|
||||
self.MLP = FFN(
|
||||
embed_dims=hidden_dims,
|
||||
feedforward_channels=hidden_dims * 4,
|
||||
num_fcs=2)
|
||||
self.norm1 = nn.LayerNorm(hidden_dims)
|
||||
self.norm2 = nn.LayerNorm(hidden_dims)
|
||||
|
||||
def pool_features(self, x):
|
||||
"""Intermediate pooling layer for computational efficiency.
|
||||
|
||||
Args:
|
||||
x: B, C, T, H, W
|
||||
"""
|
||||
B, C, T, H, W = x.shape
|
||||
x = x.transpose(1, 2).reshape(-1, C, H, W)
|
||||
x = self.pool(x)
|
||||
*_, H_, W_ = x.shape
|
||||
x = x.reshape(B, T, C, H_, W_).transpose(1, 2)
|
||||
return x
|
||||
|
||||
def forward(self, x, guidance):
|
||||
"""
|
||||
Args:
|
||||
x: B, C, T, H, W
|
||||
guidance: B, T, C
|
||||
"""
|
||||
B, C, T, H, W = x.size()
|
||||
x_pool = self.pool_features(x)
|
||||
*_, H_pool, W_pool = x_pool.size()
|
||||
|
||||
x_pool = x_pool.permute(0, 3, 4, 2, 1).reshape(-1, T, C)
|
||||
# B*H_p*W_p T C
|
||||
if guidance is not None:
|
||||
guidance = guidance.repeat(H_pool * W_pool, 1, 1)
|
||||
|
||||
x_pool = x_pool + self.attention(self.norm1(x_pool),
|
||||
guidance) # Attention
|
||||
x_pool = x_pool + self.MLP(self.norm2(x_pool)) # MLP
|
||||
|
||||
x_pool = x_pool.reshape(B, H_pool * W_pool, T,
|
||||
C).permute(0, 2, 3, 1).reshape(
|
||||
B, T, C, H_pool,
|
||||
W_pool).flatten(0, 1) # BT C H_p W_p
|
||||
x_pool = F.interpolate(
|
||||
x_pool, size=(H, W), mode='bilinear', align_corners=True)
|
||||
x_pool = x_pool.reshape(B, T, C, H, W).transpose(1, 2) # B C T H W
|
||||
x = x + x_pool # Residual
|
||||
|
||||
return x
|
||||
|
||||
|
||||
@MODELS.register_module()
|
||||
class AggregatorLayer(BaseModule):
|
||||
"""Single Aggregator Layer of CAT-Seg."""
|
||||
|
||||
def __init__(self,
|
||||
embed_dims=64,
|
||||
text_guidance_dims=512,
|
||||
appearance_guidance_dims=512,
|
||||
num_heads=4,
|
||||
mlp_ratios=4,
|
||||
window_size=7,
|
||||
attention_type='linear',
|
||||
pooling_size=(2, 2),
|
||||
init_cfg=None) -> None:
|
||||
super().__init__(init_cfg=init_cfg)
|
||||
self.spatial_agg = SpatialAggregateLayer(
|
||||
embed_dims,
|
||||
appearance_guidance_dims,
|
||||
num_heads=num_heads,
|
||||
mlp_ratios=mlp_ratios,
|
||||
window_size=window_size)
|
||||
self.class_agg = ClassAggregateLayer(
|
||||
embed_dims,
|
||||
text_guidance_dims,
|
||||
num_heads=num_heads,
|
||||
attention_type=attention_type,
|
||||
pooling_size=pooling_size)
|
||||
|
||||
def forward(self, x, appearance_guidance, text_guidance):
|
||||
"""
|
||||
Args:
|
||||
x: B C T H W
|
||||
"""
|
||||
x = self.spatial_agg(x, appearance_guidance)
|
||||
x = self.class_agg(x, text_guidance)
|
||||
return x
|
||||
|
||||
|
||||
@MODELS.register_module()
|
||||
class CATSegAggregator(BaseModule):
|
||||
"""CATSeg Aggregator.
|
||||
|
||||
This Aggregator is the mmseg implementation of
|
||||
`CAT-Seg <https://arxiv.org/abs/2303.11797>`_.
|
||||
|
||||
Args:
|
||||
text_guidance_dim (int): Text guidance dimensions. Default: 512.
|
||||
text_guidance_proj_dim (int): Text guidance projection dimensions.
|
||||
Default: 128.
|
||||
appearance_guidance_dim (int): Appearance guidance dimensions.
|
||||
Default: 512.
|
||||
appearance_guidance_proj_dim (int): Appearance guidance projection
|
||||
dimensions. Default: 128.
|
||||
num_layers (int): Aggregator layer number. Default: 4.
|
||||
num_heads (int): Attention layer head number. Default: 4.
|
||||
embed_dims (int): Input feature dimensions. Default: 128.
|
||||
pooling_size (tuple | list): Pooling size of the class aggregator
|
||||
layer. Default: (6, 6).
|
||||
mlp_ratios (int): The hidden dimension ratio w.r.t. input dimension.
|
||||
Default: 4.
|
||||
window_size (int): Swin block window size. Default:12.
|
||||
attention_type (str): Attention type of class aggregator layer.
|
||||
Default:'linear'.
|
||||
prompt_channel (int): Prompt channels. Default: 80.
|
||||
"""
|
||||
|
||||
def __init__(self,
|
||||
text_guidance_dim=512,
|
||||
text_guidance_proj_dim=128,
|
||||
appearance_guidance_dim=512,
|
||||
appearance_guidance_proj_dim=128,
|
||||
num_layers=4,
|
||||
num_heads=4,
|
||||
embed_dims=128,
|
||||
pooling_size=(6, 6),
|
||||
mlp_ratios=4,
|
||||
window_size=12,
|
||||
attention_type='linear',
|
||||
prompt_channel=80,
|
||||
**kwargs):
|
||||
super().__init__(**kwargs)
|
||||
self.num_layers = num_layers
|
||||
self.embed_dims = embed_dims
|
||||
|
||||
self.layers = nn.ModuleList([
|
||||
AggregatorLayer(
|
||||
embed_dims=embed_dims,
|
||||
text_guidance_dims=text_guidance_proj_dim,
|
||||
appearance_guidance_dims=appearance_guidance_proj_dim,
|
||||
num_heads=num_heads,
|
||||
mlp_ratios=mlp_ratios,
|
||||
window_size=window_size,
|
||||
attention_type=attention_type,
|
||||
pooling_size=pooling_size) for _ in range(num_layers)
|
||||
])
|
||||
|
||||
self.conv1 = nn.Conv2d(
|
||||
prompt_channel, embed_dims, kernel_size=7, stride=1, padding=3)
|
||||
|
||||
self.guidance_projection = nn.Sequential(
|
||||
nn.Conv2d(
|
||||
appearance_guidance_dim,
|
||||
appearance_guidance_proj_dim,
|
||||
kernel_size=3,
|
||||
stride=1,
|
||||
padding=1),
|
||||
nn.ReLU(),
|
||||
) if appearance_guidance_dim > 0 else None
|
||||
|
||||
self.text_guidance_projection = nn.Sequential(
|
||||
nn.Linear(text_guidance_dim, text_guidance_proj_dim),
|
||||
nn.ReLU(),
|
||||
) if text_guidance_dim > 0 else None
|
||||
|
||||
def feature_map(self, img_feats, text_feats):
|
||||
"""Concatenation type cost volume.
|
||||
|
||||
For ablation study of cost volume type.
|
||||
"""
|
||||
img_feats = F.normalize(img_feats, dim=1) # B C H W
|
||||
img_feats = img_feats.unsqueeze(2).repeat(1, 1, text_feats.shape[1], 1,
|
||||
1)
|
||||
text_feats = F.normalize(text_feats, dim=-1) # B T P C
|
||||
text_feats = text_feats.mean(dim=-2)
|
||||
text_feats = F.normalize(text_feats, dim=-1) # B T C
|
||||
text_feats = text_feats.unsqueeze(-1).unsqueeze(-1).repeat(
|
||||
1, 1, 1, img_feats.shape[-2], img_feats.shape[-1]).transpose(1, 2)
|
||||
return torch.cat((img_feats, text_feats), dim=1) # B 2C T H W
|
||||
|
||||
def correlation(self, img_feats, text_feats):
|
||||
"""Correlation of image features and text features."""
|
||||
img_feats = F.normalize(img_feats, dim=1) # B C H W
|
||||
text_feats = F.normalize(text_feats, dim=-1) # B T P C
|
||||
corr = torch.einsum('bchw, btpc -> bpthw', img_feats, text_feats)
|
||||
return corr
|
||||
|
||||
def corr_embed(self, x):
|
||||
"""Correlation embeddings encoding."""
|
||||
B = x.shape[0]
|
||||
corr_embed = x.permute(0, 2, 1, 3, 4).flatten(0, 1)
|
||||
corr_embed = self.conv1(corr_embed)
|
||||
corr_embed = corr_embed.reshape(B, -1, self.embed_dims, x.shape[-2],
|
||||
x.shape[-1]).transpose(1, 2)
|
||||
return corr_embed
|
||||
|
||||
def forward(self, inputs):
|
||||
"""
|
||||
Args:
|
||||
inputs (dict): including the following keys,
|
||||
'appearance_feat': list[torch.Tensor], w.r.t. out_indices of
|
||||
`self.feature_extractor`.
|
||||
'clip_text_feat': the text feature extracted by clip text
|
||||
encoder.
|
||||
'clip_text_feat_test': the text feature extracted by clip text
|
||||
encoder for testing.
|
||||
'clip_img_feat': the image feature extracted clip image
|
||||
encoder.
|
||||
"""
|
||||
img_feats = inputs['clip_img_feat']
|
||||
B = img_feats.size(0)
|
||||
appearance_guidance = inputs[
|
||||
'appearance_feat'][::-1] # order (out_indices) 2, 1, 0
|
||||
text_feats = inputs['clip_text_feat'] if self.training else inputs[
|
||||
'clip_text_feat_test']
|
||||
text_feats = text_feats.repeat(B, 1, 1, 1)
|
||||
|
||||
corr = self.correlation(img_feats, text_feats)
|
||||
# corr = self.feature_map(img_feats, text_feats)
|
||||
corr_embed = self.corr_embed(corr)
|
||||
|
||||
projected_guidance, projected_text_guidance = None, None
|
||||
|
||||
if self.guidance_projection is not None:
|
||||
projected_guidance = self.guidance_projection(
|
||||
appearance_guidance[0])
|
||||
|
||||
if self.text_guidance_projection is not None:
|
||||
text_feats = text_feats.mean(dim=-2)
|
||||
text_feats = text_feats / text_feats.norm(dim=-1, keepdim=True)
|
||||
projected_text_guidance = self.text_guidance_projection(text_feats)
|
||||
|
||||
for layer in self.layers:
|
||||
corr_embed = layer(corr_embed, projected_guidance,
|
||||
projected_text_guidance)
|
||||
|
||||
return dict(
|
||||
corr_embed=corr_embed, appearance_feats=appearance_guidance[1:])
|
||||
116
Seg_All_In_One_MMSeg/projects/CAT-Seg/cat_seg/models/cat_head.py
Normal file
116
Seg_All_In_One_MMSeg/projects/CAT-Seg/cat_seg/models/cat_head.py
Normal file
@@ -0,0 +1,116 @@
|
||||
# Copyright (c) OpenMMLab. All rights reserved.
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
from mmcv.cnn import ConvModule
|
||||
|
||||
from mmseg.models.decode_heads.decode_head import BaseDecodeHead
|
||||
from mmseg.registry import MODELS
|
||||
|
||||
|
||||
class UpBlock(nn.Module):
|
||||
"""Upsample Block with two consecutive convolution layers."""
|
||||
|
||||
def __init__(self, in_channels, out_channels, guidance_channels):
|
||||
super().__init__()
|
||||
self.up = nn.ConvTranspose2d(
|
||||
in_channels,
|
||||
in_channels - guidance_channels,
|
||||
kernel_size=2,
|
||||
stride=2)
|
||||
self.conv1 = ConvModule(
|
||||
in_channels,
|
||||
out_channels,
|
||||
3,
|
||||
padding=1,
|
||||
bias=False,
|
||||
norm_cfg=dict(type='GN', num_groups=out_channels // 16))
|
||||
self.conv2 = ConvModule(
|
||||
out_channels,
|
||||
out_channels,
|
||||
3,
|
||||
padding=1,
|
||||
bias=False,
|
||||
norm_cfg=dict(type='GN', num_groups=out_channels // 16))
|
||||
|
||||
def forward(self, x, guidance=None):
|
||||
"""Forward function with visual guidance."""
|
||||
x = self.up(x)
|
||||
if guidance is not None:
|
||||
T = x.size(0) // guidance.size(0)
|
||||
# guidance = repeat(guidance, "B C H W -> (B T) C H W", T=T)
|
||||
guidance = guidance.repeat(T, 1, 1, 1)
|
||||
x = torch.cat([x, guidance], dim=1)
|
||||
x = self.conv1(x)
|
||||
|
||||
return self.conv2(x)
|
||||
|
||||
|
||||
@MODELS.register_module()
|
||||
class CATSegHead(BaseDecodeHead):
|
||||
"""CATSeg Head.
|
||||
|
||||
This segmentation head is the mmseg implementation of
|
||||
`CAT-Seg <https://arxiv.org/abs/2303.11797>`_.
|
||||
|
||||
Args:
|
||||
embed_dims (int): The number of input dimensions.
|
||||
decoder_dims (list): The number of decoder dimensions.
|
||||
decoder_guidance_proj_dims (list): The number of appearance
|
||||
guidance dimensions.
|
||||
init_cfg
|
||||
"""
|
||||
|
||||
def __init__(self,
|
||||
embed_dims=128,
|
||||
decoder_dims=(64, 32),
|
||||
decoder_guidance_dims=(256, 128),
|
||||
decoder_guidance_proj_dims=(32, 16),
|
||||
**kwargs):
|
||||
super().__init__(**kwargs)
|
||||
self.decoder_guidance_projection = nn.ModuleList([
|
||||
nn.Sequential(
|
||||
nn.Conv2d(
|
||||
dec_dims,
|
||||
dec_dims_proj,
|
||||
kernel_size=3,
|
||||
stride=1,
|
||||
padding=1),
|
||||
nn.ReLU(),
|
||||
) for dec_dims, dec_dims_proj in zip(decoder_guidance_dims,
|
||||
decoder_guidance_proj_dims)
|
||||
]) if decoder_guidance_dims[0] > 0 else None
|
||||
|
||||
self.decoder1 = UpBlock(embed_dims, decoder_dims[0],
|
||||
decoder_guidance_proj_dims[0])
|
||||
self.decoder2 = UpBlock(decoder_dims[0], decoder_dims[1],
|
||||
decoder_guidance_proj_dims[1])
|
||||
self.conv_seg = nn.Conv2d(
|
||||
decoder_dims[1], 1, kernel_size=3, stride=1, padding=1)
|
||||
|
||||
def forward(self, inputs):
|
||||
"""Forward function.
|
||||
|
||||
Args:
|
||||
inputs (dict): Input features including the following features,
|
||||
corr_embed: aggregated correlation embeddings.
|
||||
appearance_feats: decoder appearance feature guidance.
|
||||
"""
|
||||
# decoder guidance projection
|
||||
if self.decoder_guidance_projection is not None:
|
||||
projected_decoder_guidance = [
|
||||
proj(g) for proj, g in zip(self.decoder_guidance_projection,
|
||||
inputs['appearance_feats'])
|
||||
]
|
||||
|
||||
# decoder layers
|
||||
B = inputs['corr_embed'].size(0)
|
||||
corr_embed = inputs['corr_embed'].transpose(1, 2).flatten(0, 1)
|
||||
corr_embed = self.decoder1(corr_embed, projected_decoder_guidance[0])
|
||||
corr_embed = self.decoder2(corr_embed, projected_decoder_guidance[1])
|
||||
|
||||
output = self.cls_seg(corr_embed)
|
||||
|
||||
# rearrange the output to (B, T, H, W)
|
||||
H_ori, W_ori = output.shape[-2:]
|
||||
output = output.reshape(B, -1, H_ori, W_ori)
|
||||
return output
|
||||
@@ -0,0 +1,293 @@
|
||||
# Copyright (c) OpenMMLab. All rights reserved.
|
||||
import json
|
||||
import os
|
||||
from typing import List
|
||||
|
||||
import torch
|
||||
import torch.nn.functional as F
|
||||
from huggingface_hub.utils._errors import LocalEntryNotFoundError
|
||||
from mmengine.model import BaseModule
|
||||
|
||||
from mmseg.registry import MODELS
|
||||
from mmseg.utils import ConfigType
|
||||
from ..utils import clip_wrapper
|
||||
from ..utils.clip_templates import (IMAGENET_TEMPLATES,
|
||||
IMAGENET_TEMPLATES_SELECT)
|
||||
|
||||
|
||||
@MODELS.register_module()
|
||||
class CLIPOVCATSeg(BaseModule):
|
||||
"""CLIP based Open Vocabulary CAT-Seg model backbone.
|
||||
|
||||
This backbone is the modified implementation of `CAT-Seg Backbone
|
||||
<https://arxiv.org/abs/2303.11797>`_. It combines the CLIP model and
|
||||
another feature extractor, a.k.a the appearance guidance extractor
|
||||
in the original `CAT-Seg`.
|
||||
|
||||
Args:
|
||||
feature_extractor (ConfigType): Appearance guidance extractor
|
||||
config dict.
|
||||
train_class_json (str): The training class json file.
|
||||
test_class_json (str): The path to test class json file.
|
||||
clip_pretrained (str): The pre-trained clip type.
|
||||
clip_finetune (str): The finetuning settings of clip model.
|
||||
custom_clip_weights (str): The custmized clip weights directory. When
|
||||
encountering huggingface model download errors, you can manually
|
||||
download the pretrained weights.
|
||||
backbone_multiplier (float): The learning rate multiplier.
|
||||
Default: 0.01.
|
||||
prompt_depth (int): The prompt depth. Default: 0.
|
||||
prompt_length (int): The prompt length. Default: 0.
|
||||
prompt_ensemble_type (str): The prompt ensemble type.
|
||||
Default: "imagenet".
|
||||
pixel_mean (List[float]): The pixel mean for feature extractor.
|
||||
pxiel_std (List[float]): The pixel std for feature extractor.
|
||||
clip_pixel_mean (List[float]): The pixel mean for clip model.
|
||||
clip_pxiel_std (List[float]): The pixel std for clip model.
|
||||
clip_img_feat_size: (List[int]: Clip image embedding size from
|
||||
image encoder.
|
||||
init_cfg (dict or list[dict], optional): Initialization config dict.
|
||||
Default: None.
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
feature_extractor: ConfigType,
|
||||
train_class_json: str,
|
||||
test_class_json: str,
|
||||
clip_pretrained: str,
|
||||
clip_finetune: str,
|
||||
custom_clip_weights: str = None,
|
||||
backbone_multiplier=0.01,
|
||||
prompt_depth: int = 0,
|
||||
prompt_length: int = 0,
|
||||
prompt_ensemble_type: str = 'imagenet',
|
||||
pixel_mean: List[float] = [123.675, 116.280, 103.530],
|
||||
pixel_std: List[float] = [58.395, 57.120, 57.375],
|
||||
clip_pixel_mean: List[float] = [
|
||||
122.7709383, 116.7460125, 104.09373615
|
||||
],
|
||||
clip_pixel_std: List[float] = [68.5005327, 66.6321579, 70.3231630],
|
||||
clip_img_feat_size: List[int] = [24, 24],
|
||||
init_cfg=None):
|
||||
super().__init__(init_cfg=init_cfg)
|
||||
# normalization parameters
|
||||
self.register_buffer('pixel_mean',
|
||||
torch.Tensor(pixel_mean).view(1, -1, 1, 1), False)
|
||||
self.register_buffer('pixel_std',
|
||||
torch.Tensor(pixel_std).view(1, -1, 1, 1), False)
|
||||
self.register_buffer('clip_pixel_mean',
|
||||
torch.Tensor(clip_pixel_mean).view(1, -1, 1, 1),
|
||||
False)
|
||||
self.register_buffer('clip_pixel_std',
|
||||
torch.Tensor(clip_pixel_std).view(1, -1, 1, 1),
|
||||
False)
|
||||
self.clip_resolution = (
|
||||
384, 384) if clip_pretrained == 'ViT-B/16' else (336, 336)
|
||||
# modified clip image encoder with fixed size dense output
|
||||
self.clip_img_feat_size = clip_img_feat_size
|
||||
|
||||
# prepare clip templates
|
||||
self.prompt_ensemble_type = prompt_ensemble_type
|
||||
if self.prompt_ensemble_type == 'imagenet_select':
|
||||
prompt_templates = IMAGENET_TEMPLATES_SELECT
|
||||
elif self.prompt_ensemble_type == 'imagenet':
|
||||
prompt_templates = IMAGENET_TEMPLATES
|
||||
elif self.prompt_ensemble_type == 'single':
|
||||
prompt_templates = [
|
||||
'A photo of a {} in the scene',
|
||||
]
|
||||
else:
|
||||
raise NotImplementedError
|
||||
self.prompt_templates = prompt_templates
|
||||
|
||||
# build the feature extractor
|
||||
self.feature_extractor = MODELS.build(feature_extractor)
|
||||
|
||||
# build CLIP model
|
||||
with open(train_class_json) as f_in:
|
||||
self.class_texts = json.load(f_in)
|
||||
with open(test_class_json) as f_in:
|
||||
self.test_class_texts = json.load(f_in)
|
||||
assert self.class_texts is not None
|
||||
if self.test_class_texts is None:
|
||||
self.test_class_texts = self.class_texts
|
||||
device = 'cuda' if torch.cuda.is_available() else 'cpu'
|
||||
self.tokenizer = None
|
||||
if clip_pretrained == 'ViT-G' or clip_pretrained == 'ViT-H':
|
||||
# for OpenCLIP models
|
||||
import open_clip
|
||||
name, pretrain = (
|
||||
'ViT-H-14',
|
||||
'laion2b_s32b_b79k') if clip_pretrained == 'ViT-H' else (
|
||||
'ViT-bigG-14', 'laion2b_s39b_b160k')
|
||||
try:
|
||||
open_clip_model = open_clip.create_model_and_transforms(
|
||||
name,
|
||||
pretrained=pretrain,
|
||||
device=device,
|
||||
force_image_size=336,
|
||||
)
|
||||
clip_model, _, clip_preprocess = open_clip_model
|
||||
except ConnectionError or LocalEntryNotFoundError as e:
|
||||
print(f'Has {e} when loading weights from huggingface!')
|
||||
print(
|
||||
f'Will load {pretrain} weights from {custom_clip_weights}.'
|
||||
)
|
||||
assert custom_clip_weights is not None, 'Please specify custom weights directory.' # noqa
|
||||
assert os.path.exists(
|
||||
os.path.join(custom_clip_weights,
|
||||
'open_clip_pytorch_model.bin')
|
||||
), 'Please provide a valid directory for manually downloaded model.' # noqa
|
||||
open_clip_model = open_clip.create_model_and_transforms(
|
||||
name,
|
||||
pretrained=None,
|
||||
device='cpu',
|
||||
force_image_size=336,
|
||||
)
|
||||
clip_model, _, clip_preprocess = open_clip_model
|
||||
|
||||
open_clip.load_checkpoint(
|
||||
clip_model,
|
||||
os.path.expanduser(
|
||||
os.path.join(custom_clip_weights,
|
||||
'open_clip_pytorch_model.bin')))
|
||||
clip_model.to(torch.device(device))
|
||||
|
||||
self.tokenizer = open_clip.get_tokenizer(name)
|
||||
else:
|
||||
# for OpenAI models
|
||||
clip_model, clip_preprocess = clip_wrapper.load(
|
||||
clip_pretrained,
|
||||
device=device,
|
||||
jit=False,
|
||||
prompt_depth=prompt_depth,
|
||||
prompt_length=prompt_length)
|
||||
|
||||
# pre-encode classes text prompts
|
||||
text_features = self.class_embeddings(self.class_texts,
|
||||
prompt_templates, clip_model,
|
||||
device).permute(1, 0, 2).float()
|
||||
text_features_test = self.class_embeddings(self.test_class_texts,
|
||||
prompt_templates,
|
||||
clip_model,
|
||||
device).permute(1, 0,
|
||||
2).float()
|
||||
self.register_buffer('text_features', text_features, False)
|
||||
self.register_buffer('text_features_test', text_features_test, False)
|
||||
|
||||
# prepare CLIP model finetune
|
||||
self.clip_finetune = clip_finetune
|
||||
self.clip_model = clip_model.float()
|
||||
self.clip_preprocess = clip_preprocess
|
||||
|
||||
for name, params in self.clip_model.named_parameters():
|
||||
if 'visual' in name:
|
||||
if clip_finetune == 'prompt':
|
||||
params.requires_grad = True if 'prompt' in name else False
|
||||
elif clip_finetune == 'attention':
|
||||
if 'attn' in name or 'position' in name:
|
||||
params.requires_grad = True
|
||||
else:
|
||||
params.requires_grad = False
|
||||
elif clip_finetune == 'full':
|
||||
params.requires_grad = True
|
||||
else:
|
||||
params.requires_grad = False
|
||||
else:
|
||||
params.requires_grad = False
|
||||
|
||||
finetune_backbone = backbone_multiplier > 0.
|
||||
for name, params in self.feature_extractor.named_parameters():
|
||||
if 'norm0' in name:
|
||||
params.requires_grad = False
|
||||
else:
|
||||
params.requires_grad = finetune_backbone
|
||||
|
||||
@torch.no_grad()
|
||||
def class_embeddings(self,
|
||||
classnames,
|
||||
templates,
|
||||
clip_model,
|
||||
device='cpu'):
|
||||
"""Convert class names to text embeddings by clip model.
|
||||
|
||||
Args:
|
||||
classnames (list): loaded from json file.
|
||||
templates (dict): text template.
|
||||
clip_model (nn.Module): prepared clip model.
|
||||
device (str | torch.device): loading device of text
|
||||
encoder results.
|
||||
"""
|
||||
zeroshot_weights = []
|
||||
for classname in classnames:
|
||||
if ', ' in classname:
|
||||
classname_splits = classname.split(', ')
|
||||
texts = []
|
||||
for template in templates:
|
||||
for cls_split in classname_splits:
|
||||
texts.append(template.format(cls_split))
|
||||
else:
|
||||
texts = [template.format(classname)
|
||||
for template in templates] # format with class
|
||||
if self.tokenizer is not None:
|
||||
texts = self.tokenizer(texts).to(device)
|
||||
else:
|
||||
texts = clip_wrapper.tokenize(texts).to(device)
|
||||
class_embeddings = clip_model.encode_text(texts)
|
||||
class_embeddings /= class_embeddings.norm(dim=-1, keepdim=True)
|
||||
if len(templates) != class_embeddings.shape[0]:
|
||||
class_embeddings = class_embeddings.reshape(
|
||||
len(templates), -1, class_embeddings.shape[-1]).mean(dim=1)
|
||||
class_embeddings /= class_embeddings.norm(dim=-1, keepdim=True)
|
||||
class_embedding = class_embeddings
|
||||
zeroshot_weights.append(class_embedding)
|
||||
zeroshot_weights = torch.stack(zeroshot_weights, dim=1).to(device)
|
||||
return zeroshot_weights
|
||||
|
||||
def custom_normalize(self, inputs):
|
||||
"""Input normalization for clip model and feature extractor
|
||||
respectively.
|
||||
|
||||
Args:
|
||||
inputs: batched input images.
|
||||
"""
|
||||
# clip images
|
||||
batched_clip = (inputs - self.clip_pixel_mean) / self.clip_pixel_std
|
||||
batched_clip = F.interpolate(
|
||||
batched_clip,
|
||||
size=self.clip_resolution,
|
||||
mode='bilinear',
|
||||
align_corners=False)
|
||||
# feature extractor images
|
||||
batched = (inputs - self.pixel_mean) / self.pixel_std
|
||||
return batched, batched_clip
|
||||
|
||||
def forward(self, inputs):
|
||||
"""
|
||||
Args:
|
||||
inputs: minibatch image. (B, 3, H, W)
|
||||
Returns:
|
||||
outputs (dict):
|
||||
'appearance_feat': list[torch.Tensor], w.r.t. out_indices of
|
||||
`self.feature_extractor`.
|
||||
'clip_text_feat': the text feature extracted by clip text encoder.
|
||||
'clip_text_feat_test': the text feature extracted by clip text
|
||||
encoder for testing.
|
||||
'clip_img_feat': the image feature extracted clip image encoder.
|
||||
"""
|
||||
inputs, clip_inputs = self.custom_normalize(inputs)
|
||||
outputs = dict()
|
||||
# extract appearance guidance feature
|
||||
outputs['appearance_feat'] = self.feature_extractor(inputs)
|
||||
|
||||
# extract clip features
|
||||
outputs['clip_text_feat'] = self.text_features
|
||||
outputs['clip_text_feat_test'] = self.text_features_test
|
||||
clip_features = self.clip_model.encode_image(
|
||||
clip_inputs, dense=True) # B, 577(24x24+1), C
|
||||
B = clip_features.size(0)
|
||||
outputs['clip_img_feat'] = clip_features[:, 1:, :].permute(
|
||||
0, 2, 1).reshape(B, -1, *self.clip_img_feat_size)
|
||||
|
||||
return outputs
|
||||
@@ -0,0 +1,10 @@
|
||||
# Copyright (c) OpenMMLab. All rights reserved.
|
||||
from .clip_templates import (IMAGENET_TEMPLATES, IMAGENET_TEMPLATES_SELECT,
|
||||
IMAGENET_TEMPLATES_SELECT_CLIP, ViLD_templates)
|
||||
from .self_attention_block import FullAttention, LinearAttention
|
||||
|
||||
__all__ = [
|
||||
'FullAttention', 'LinearAttention', 'IMAGENET_TEMPLATES',
|
||||
'IMAGENET_TEMPLATES_SELECT', 'IMAGENET_TEMPLATES_SELECT_CLIP',
|
||||
'ViLD_templates'
|
||||
]
|
||||
Binary file not shown.
@@ -0,0 +1,651 @@
|
||||
# Copyright (c) OpenMMLab. All rights reserved.
|
||||
from collections import OrderedDict
|
||||
from typing import Tuple, Union
|
||||
|
||||
import torch
|
||||
import torch.nn.functional as F
|
||||
from torch import nn
|
||||
|
||||
|
||||
class Bottleneck(nn.Module):
|
||||
"""Custom implementation of Bottleneck in ResNet."""
|
||||
expansion = 4
|
||||
|
||||
def __init__(self, inplanes, planes, stride=1):
|
||||
super().__init__()
|
||||
# all conv layers have stride 1.
|
||||
# an avgpool is performed after the second convolution when stride > 1
|
||||
self.conv1 = nn.Conv2d(inplanes, planes, 1, bias=False)
|
||||
self.bn1 = nn.BatchNorm2d(planes)
|
||||
|
||||
self.conv2 = nn.Conv2d(planes, planes, 3, padding=1, bias=False)
|
||||
self.bn2 = nn.BatchNorm2d(planes)
|
||||
|
||||
self.avgpool = nn.AvgPool2d(stride) if stride > 1 else nn.Identity()
|
||||
|
||||
self.conv3 = nn.Conv2d(planes, planes * self.expansion, 1, bias=False)
|
||||
self.bn3 = nn.BatchNorm2d(planes * self.expansion)
|
||||
|
||||
self.relu = nn.ReLU(inplace=True)
|
||||
self.downsample = None
|
||||
self.stride = stride
|
||||
|
||||
if stride > 1 or inplanes != planes * Bottleneck.expansion:
|
||||
# downsampling layer is prepended with an avgpool,
|
||||
# and the subsequent convolution has stride 1
|
||||
self.downsample = nn.Sequential(
|
||||
OrderedDict([('-1', nn.AvgPool2d(stride)),
|
||||
('0',
|
||||
nn.Conv2d(
|
||||
inplanes,
|
||||
planes * self.expansion,
|
||||
1,
|
||||
stride=1,
|
||||
bias=False)),
|
||||
('1', nn.BatchNorm2d(planes * self.expansion))]))
|
||||
|
||||
def forward(self, x: torch.Tensor):
|
||||
"""
|
||||
Args:
|
||||
x (torch.Tensor): the input feature.
|
||||
"""
|
||||
identity = x
|
||||
|
||||
out = self.relu(self.bn1(self.conv1(x)))
|
||||
out = self.relu(self.bn2(self.conv2(out)))
|
||||
out = self.avgpool(out)
|
||||
out = self.bn3(self.conv3(out))
|
||||
|
||||
if self.downsample is not None:
|
||||
identity = self.downsample(x)
|
||||
|
||||
out += identity
|
||||
out = self.relu(out)
|
||||
return out
|
||||
|
||||
|
||||
class AttentionPool2d(nn.Module):
|
||||
"""Attention Pool2d."""
|
||||
|
||||
def __init__(self,
|
||||
spacial_dim: int,
|
||||
embed_dim: int,
|
||||
num_heads: int,
|
||||
output_dim: int = None):
|
||||
super().__init__()
|
||||
self.positional_embedding = nn.Parameter(
|
||||
torch.randn(spacial_dim**2 + 1, embed_dim) / embed_dim**0.5)
|
||||
self.k_proj = nn.Linear(embed_dim, embed_dim)
|
||||
self.q_proj = nn.Linear(embed_dim, embed_dim)
|
||||
self.v_proj = nn.Linear(embed_dim, embed_dim)
|
||||
self.c_proj = nn.Linear(embed_dim, output_dim or embed_dim)
|
||||
self.num_heads = num_heads
|
||||
|
||||
def forward(self, x):
|
||||
"""
|
||||
Args:
|
||||
x (torch.Tensor): the input feature.
|
||||
"""
|
||||
x = x.flatten(start_dim=2).permute(2, 0, 1) # NCHW -> (HW)NC
|
||||
x = torch.cat([x.mean(dim=0, keepdim=True), x], dim=0) # (HW+1)NC
|
||||
x = x + self.positional_embedding[:, None, :].to(x.dtype) # (HW+1)NC
|
||||
x, _ = F.multi_head_attention_forward(
|
||||
query=x[:1],
|
||||
key=x,
|
||||
value=x,
|
||||
embed_dim_to_check=x.shape[-1],
|
||||
num_heads=self.num_heads,
|
||||
q_proj_weight=self.q_proj.weight,
|
||||
k_proj_weight=self.k_proj.weight,
|
||||
v_proj_weight=self.v_proj.weight,
|
||||
in_proj_weight=None,
|
||||
in_proj_bias=torch.cat(
|
||||
[self.q_proj.bias, self.k_proj.bias, self.v_proj.bias]),
|
||||
bias_k=None,
|
||||
bias_v=None,
|
||||
add_zero_attn=False,
|
||||
dropout_p=0,
|
||||
out_proj_weight=self.c_proj.weight,
|
||||
out_proj_bias=self.c_proj.bias,
|
||||
use_separate_proj_weight=True,
|
||||
training=self.training,
|
||||
need_weights=False)
|
||||
return x.squeeze(0)
|
||||
|
||||
|
||||
class ModifiedResNet(nn.Module):
|
||||
"""A ResNet class that is similar to torchvision's but contains the
|
||||
following changes:
|
||||
|
||||
- There are now 3 "stem" convolutions as opposed to 1, with an average
|
||||
pool instead of a max pool.
|
||||
- Performs anti-aliasing strided convolutions, where an avgpool is
|
||||
prepended to convolutions with stride > 1
|
||||
- The final pooling layer is a QKV attention instead of an average pool
|
||||
"""
|
||||
|
||||
def __init__(self,
|
||||
layers,
|
||||
output_dim,
|
||||
heads,
|
||||
input_resolution=224,
|
||||
width=64):
|
||||
super().__init__()
|
||||
self.output_dim = output_dim
|
||||
self.input_resolution = input_resolution
|
||||
|
||||
# the 3-layer stem
|
||||
self.conv1 = nn.Conv2d(
|
||||
3, width // 2, kernel_size=3, stride=2, padding=1, bias=False)
|
||||
self.bn1 = nn.BatchNorm2d(width // 2)
|
||||
self.relu1 = nn.ReLU(inplace=True)
|
||||
self.conv2 = nn.Conv2d(
|
||||
width // 2, width // 2, kernel_size=3, padding=1, bias=False)
|
||||
self.bn2 = nn.BatchNorm2d(width // 2)
|
||||
self.relu2 = nn.ReLU(inplace=True)
|
||||
self.conv3 = nn.Conv2d(
|
||||
width // 2, width, kernel_size=3, padding=1, bias=False)
|
||||
self.bn3 = nn.BatchNorm2d(width)
|
||||
self.relu3 = nn.ReLU(inplace=True)
|
||||
self.avgpool = nn.AvgPool2d(2)
|
||||
|
||||
# residual layers
|
||||
# this is a *mutable* variable used during construction
|
||||
self._inplanes = width
|
||||
self.layer1 = self._make_layer(width, layers[0])
|
||||
self.layer2 = self._make_layer(width * 2, layers[1], stride=2)
|
||||
self.layer3 = self._make_layer(width * 4, layers[2], stride=2)
|
||||
self.layer4 = self._make_layer(width * 8, layers[3], stride=2)
|
||||
|
||||
embed_dim = width * 32 # the ResNet feature dimension
|
||||
self.attnpool = AttentionPool2d(input_resolution // 32, embed_dim,
|
||||
heads, output_dim)
|
||||
|
||||
def _make_layer(self, planes, blocks, stride=1):
|
||||
"""Build resnet layers."""
|
||||
layers = [Bottleneck(self._inplanes, planes, stride)]
|
||||
|
||||
self._inplanes = planes * Bottleneck.expansion
|
||||
for _ in range(1, blocks):
|
||||
layers.append(Bottleneck(self._inplanes, planes))
|
||||
|
||||
return nn.Sequential(*layers)
|
||||
|
||||
def forward(self, x):
|
||||
"""
|
||||
Args:
|
||||
x (torch.Tensor): the input mini-batch images.
|
||||
"""
|
||||
|
||||
def stem(x):
|
||||
x = self.relu1(self.bn1(self.conv1(x)))
|
||||
x = self.relu2(self.bn2(self.conv2(x)))
|
||||
x = self.relu3(self.bn3(self.conv3(x)))
|
||||
x = self.avgpool(x)
|
||||
return x
|
||||
|
||||
x = x.type(self.conv1.weight.dtype)
|
||||
x = stem(x)
|
||||
x = self.layer1(x)
|
||||
x = self.layer2(x)
|
||||
x = self.layer3(x)
|
||||
x = self.layer4(x)
|
||||
x = self.attnpool(x)
|
||||
|
||||
return x
|
||||
|
||||
|
||||
class LayerNorm(nn.LayerNorm):
|
||||
"""Subclass torch's LayerNorm to handle fp16."""
|
||||
|
||||
def forward(self, x: torch.Tensor):
|
||||
"""
|
||||
Args:
|
||||
x (torch.Tensor): the input feature.
|
||||
"""
|
||||
orig_type = x.dtype
|
||||
ret = super().forward(x.type(torch.float32))
|
||||
return ret.type(orig_type)
|
||||
|
||||
|
||||
class QuickGELU(nn.Module):
|
||||
"""Wrapper of GELU activation layer."""
|
||||
|
||||
def forward(self, x: torch.Tensor):
|
||||
"""
|
||||
Args:
|
||||
x (torch.Tensor): the input feature.
|
||||
"""
|
||||
return x * torch.sigmoid(1.702 * x)
|
||||
|
||||
|
||||
class ResidualAttentionBlock(nn.Module):
|
||||
"""Attention block with residual connection."""
|
||||
|
||||
def __init__(self,
|
||||
d_model: int,
|
||||
n_head: int,
|
||||
attn_mask: torch.Tensor = None):
|
||||
super().__init__()
|
||||
|
||||
self.attn = nn.MultiheadAttention(d_model, n_head)
|
||||
self.ln_1 = LayerNorm(d_model)
|
||||
self.mlp = nn.Sequential(
|
||||
OrderedDict([('c_fc', nn.Linear(d_model, d_model * 4)),
|
||||
('gelu', QuickGELU()),
|
||||
('c_proj', nn.Linear(d_model * 4, d_model))]))
|
||||
self.ln_2 = LayerNorm(d_model)
|
||||
self.attn_mask = attn_mask
|
||||
self.mask_pre_mlp = True
|
||||
|
||||
def attention(self, x: torch.Tensor):
|
||||
"""Calculate mask multi-head-attention."""
|
||||
self.attn_mask = self.attn_mask.to(
|
||||
dtype=x.dtype,
|
||||
device=x.device) if self.attn_mask is not None else None
|
||||
return self.attn(
|
||||
x, x, x, need_weights=False, attn_mask=self.attn_mask)[0]
|
||||
|
||||
def forward(self, x: torch.Tensor):
|
||||
"""
|
||||
Args:
|
||||
x (torch.Tensor): the input feature.
|
||||
"""
|
||||
x = x + self.attention(self.ln_1(x))
|
||||
x = x + self.mlp(self.ln_2(x))
|
||||
return x
|
||||
|
||||
def forward_dense(self, x: torch.Tensor):
|
||||
"""Reinplementation of forward function for dense prediction of image
|
||||
encoder in CLIP model.
|
||||
|
||||
Args:
|
||||
x (torch.Tensor): the input feature.
|
||||
"""
|
||||
y = self.ln_1(x)
|
||||
y = F.linear(y, self.attn.in_proj_weight, self.attn.in_proj_bias)
|
||||
L, N, D = y.shape # L N 3D
|
||||
|
||||
y = y.reshape(L, N, 3, D // 3).permute(2, 1, 0,
|
||||
3).reshape(3 * N, L, D // 3)
|
||||
y = F.linear(y, self.attn.out_proj.weight, self.attn.out_proj.bias)
|
||||
|
||||
q, k, v = y.tensor_split(3, dim=0)
|
||||
v = v.transpose(1, 0) + x # L N D
|
||||
|
||||
v = v + self.mlp(self.ln_2(v))
|
||||
return v
|
||||
|
||||
|
||||
class Transformer(nn.Module):
|
||||
"""General Transformer Architecture for both image and text encoder."""
|
||||
|
||||
def __init__(self,
|
||||
width: int,
|
||||
layers: int,
|
||||
heads: int,
|
||||
attn_mask: torch.Tensor = None,
|
||||
prompt_length=0,
|
||||
prompt_depth=0):
|
||||
super().__init__()
|
||||
self.width = width
|
||||
self.layers = layers
|
||||
self.resblocks = nn.Sequential(*[
|
||||
ResidualAttentionBlock(width, heads, attn_mask)
|
||||
for _ in range(layers)
|
||||
])
|
||||
|
||||
self.prompt_length = prompt_length
|
||||
self.prompt_depth = prompt_depth
|
||||
self.prompt_tokens = nn.Parameter(
|
||||
torch.zeros(prompt_depth, prompt_length,
|
||||
width)) if prompt_length > 0 else None
|
||||
if self.prompt_tokens is not None:
|
||||
nn.init.xavier_uniform_(self.prompt_tokens)
|
||||
|
||||
def forward(self, x: torch.Tensor, dense=False):
|
||||
"""
|
||||
Args:
|
||||
x (torch.Tensor): input features.
|
||||
dense (bool): whether use reimplemented dense forward
|
||||
function in the last layer.
|
||||
"""
|
||||
for i, resblock in enumerate(self.resblocks):
|
||||
if self.prompt_length > 0 and i < self.prompt_depth:
|
||||
length = self.prompt_length + 1 if i > 0 else 1
|
||||
x = torch.cat((x[0:1, :, :], self.prompt_tokens[i].repeat(
|
||||
x.shape[1], 1, 1).permute(1, 0, 2), x[length:, :, :]))
|
||||
|
||||
if i == self.layers - 1 and dense:
|
||||
x = resblock.forward_dense(x)
|
||||
x = torch.cat((x[0:1, :, :], x[self.prompt_length + 1::, :]),
|
||||
dim=0)
|
||||
else:
|
||||
x = resblock(x)
|
||||
|
||||
return x
|
||||
|
||||
|
||||
class VisualTransformer(nn.Module):
|
||||
"""Visual encoder for CLIP model."""
|
||||
|
||||
def __init__(self, input_resolution: int, patch_size: int, width: int,
|
||||
layers: int, heads: int, output_dim: int, prompt_depth: int,
|
||||
prompt_length: int):
|
||||
super().__init__()
|
||||
self.output_dim = output_dim
|
||||
self.conv1 = nn.Conv2d(
|
||||
in_channels=3,
|
||||
out_channels=width,
|
||||
kernel_size=patch_size,
|
||||
stride=patch_size,
|
||||
bias=False)
|
||||
|
||||
scale = width**-0.5
|
||||
self.class_embedding = nn.Parameter(scale * torch.randn(width))
|
||||
self.positional_embedding = nn.Parameter(scale * torch.randn(
|
||||
(input_resolution // patch_size)**2 + 1, width))
|
||||
self.ln_pre = LayerNorm(width)
|
||||
|
||||
self.transformer = Transformer(
|
||||
width,
|
||||
layers,
|
||||
heads,
|
||||
prompt_depth=prompt_depth,
|
||||
prompt_length=prompt_length)
|
||||
|
||||
self.ln_post = LayerNorm(width)
|
||||
self.proj = nn.Parameter(scale * torch.randn(width, output_dim))
|
||||
|
||||
self.patch_size = patch_size
|
||||
self.input_resolution = input_resolution
|
||||
|
||||
def forward(self, x: torch.Tensor, dense=False):
|
||||
"""
|
||||
Args:
|
||||
x (torch.Tensor): input features.
|
||||
dense (bool): whether use reimplemented dense forward
|
||||
function in the last layer.
|
||||
"""
|
||||
x = self.conv1(x) # shape = [*, width, grid, grid]
|
||||
x = x.reshape(x.shape[0], x.shape[1],
|
||||
-1) # shape = [*, width, grid ** 2]
|
||||
x = x.permute(0, 2, 1) # shape = [*, grid ** 2, width]
|
||||
x = torch.cat([
|
||||
self.class_embedding.to(x.dtype) + torch.zeros(
|
||||
x.shape[0], 1, x.shape[-1], dtype=x.dtype, device=x.device), x
|
||||
],
|
||||
dim=1) # shape = [*, grid ** 2 + 1, width]
|
||||
|
||||
if dense and (x.shape[1] != self.positional_embedding.shape[0]):
|
||||
x = x + self.resized_pos_embed(self.input_resolution,
|
||||
x.shape[1]).to(x.dtype)
|
||||
else:
|
||||
x = x + self.positional_embedding.to(x.dtype)
|
||||
|
||||
x = self.ln_pre(x)
|
||||
|
||||
x = x.permute(1, 0, 2) # NLD -> LND
|
||||
x = self.transformer(x, dense)
|
||||
x = x.permute(1, 0, 2) # LND -> NLD
|
||||
|
||||
if dense:
|
||||
x = self.ln_post(x[:, :, :])
|
||||
else:
|
||||
x = self.ln_post(x[:, 0, :])
|
||||
|
||||
if self.proj is not None:
|
||||
x = x @ self.proj
|
||||
|
||||
return x
|
||||
|
||||
def resized_pos_embed(self, in_res, tgt_res, mode='bicubic'):
|
||||
"""Resize the position embedding."""
|
||||
# assert L == (input_resolution // self.patch_size) ** 2 + 1
|
||||
L, D = self.positional_embedding.shape
|
||||
|
||||
in_side = in_res // self.patch_size
|
||||
# tgt_side = tgt_res // self.patch_size
|
||||
tgt_side = int((tgt_res - 1)**0.5)
|
||||
|
||||
cls_pos = self.positional_embedding[0].unsqueeze(0) # 1 D
|
||||
pos_embed = self.positional_embedding[1:].reshape(
|
||||
1, in_side, in_side, D).permute(0, 3, 1, 2) # L-1 D -> 1 D S S
|
||||
resized_pos_embed = F.interpolate(
|
||||
pos_embed,
|
||||
size=(tgt_side, tgt_side),
|
||||
mode=mode,
|
||||
align_corners=False,
|
||||
) # 1 D S S -> 1 D S' S'
|
||||
resized_pos_embed = resized_pos_embed.squeeze(0).reshape(
|
||||
D, -1).T # L'-1 D
|
||||
|
||||
return torch.cat((cls_pos, resized_pos_embed), dim=0)
|
||||
|
||||
|
||||
class CLIP(nn.Module):
|
||||
"""Custom implementation of CLIP model.
|
||||
|
||||
Refer to: https://github.com/openai/CLIP
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
embed_dim: int,
|
||||
# vision
|
||||
image_resolution: int,
|
||||
vision_layers: Union[Tuple[int, int, int, int], int],
|
||||
vision_width: int,
|
||||
vision_patch_size: int,
|
||||
# text
|
||||
context_length: int,
|
||||
vocab_size: int,
|
||||
transformer_width: int,
|
||||
transformer_heads: int,
|
||||
transformer_layers: int,
|
||||
# prompt
|
||||
prompt_depth: int = 0,
|
||||
prompt_length: int = 0,
|
||||
):
|
||||
super().__init__()
|
||||
|
||||
self.context_length = context_length
|
||||
|
||||
self.image_resolution = image_resolution
|
||||
|
||||
if isinstance(vision_layers, (tuple, list)):
|
||||
assert prompt_length == 0 and prompt_depth == 0
|
||||
vision_heads = vision_width * 32 // 64
|
||||
self.visual = ModifiedResNet(
|
||||
layers=vision_layers,
|
||||
output_dim=embed_dim,
|
||||
heads=vision_heads,
|
||||
input_resolution=image_resolution,
|
||||
width=vision_width)
|
||||
else:
|
||||
vision_heads = vision_width // 64
|
||||
self.visual = VisualTransformer(
|
||||
input_resolution=image_resolution,
|
||||
patch_size=vision_patch_size,
|
||||
width=vision_width,
|
||||
layers=vision_layers,
|
||||
heads=vision_heads,
|
||||
output_dim=embed_dim,
|
||||
prompt_depth=prompt_depth,
|
||||
prompt_length=prompt_length,
|
||||
)
|
||||
|
||||
self.transformer = Transformer(
|
||||
width=transformer_width,
|
||||
layers=transformer_layers,
|
||||
heads=transformer_heads,
|
||||
attn_mask=self.build_attention_mask())
|
||||
|
||||
self.vocab_size = vocab_size
|
||||
self.token_embedding = nn.Embedding(vocab_size, transformer_width)
|
||||
self.positional_embedding = nn.Parameter(
|
||||
torch.empty(self.context_length, transformer_width))
|
||||
self.ln_final = LayerNorm(transformer_width)
|
||||
|
||||
self.text_projection = nn.Parameter(
|
||||
torch.empty(transformer_width, embed_dim))
|
||||
self.logit_scale = nn.Parameter(torch.ones([]))
|
||||
|
||||
def build_attention_mask(self):
|
||||
"""Create causal attention mask."""
|
||||
# lazily create causal attention mask, with full attention between
|
||||
# the vision tokens pytorch uses additive attention mask; fill with
|
||||
# -inf
|
||||
mask = torch.empty(self.context_length, self.context_length)
|
||||
mask.fill_(float('-inf'))
|
||||
mask.triu_(1) # zero out the lower diagonal
|
||||
return mask
|
||||
|
||||
@property
|
||||
def dtype(self):
|
||||
"""Return the dtype of the model."""
|
||||
return self.visual.conv1.weight.dtype
|
||||
|
||||
def encode_image(self, image, masks=None, pool_mask=None, dense=False):
|
||||
"""Image encoding."""
|
||||
if pool_mask is not None:
|
||||
return self.visual(
|
||||
image.type(self.dtype), mask=pool_mask, dense=dense)
|
||||
if masks is None:
|
||||
return self.visual(image.type(self.dtype), dense=dense)
|
||||
else:
|
||||
return self.visual(image.type(self.dtype), masks.type(self.dtype))
|
||||
|
||||
def encode_text(self, text):
|
||||
"""Texts encoding."""
|
||||
x = self.token_embedding(text).type(
|
||||
self.dtype) # [batch_size, n_ctx, d_model]
|
||||
|
||||
x = x + self.positional_embedding.type(self.dtype)
|
||||
x = x.permute(1, 0, 2) # NLD -> LND
|
||||
x = self.transformer(x)
|
||||
x = x.permute(1, 0, 2) # LND -> NLD
|
||||
x = self.ln_final(x).type(self.dtype)
|
||||
|
||||
# x.shape = [batch_size, n_ctx, transformer.width]
|
||||
# take features from the eot embedding (eot_token is the highest number
|
||||
# in each sequence)
|
||||
x = x[torch.arange(x.shape[0]),
|
||||
text.argmax(dim=-1)] @ self.text_projection
|
||||
|
||||
return x
|
||||
|
||||
def forward(self, image, text):
|
||||
"""
|
||||
Args:
|
||||
image (torch.Tensor): input images.
|
||||
text (torch.Tensor): input text.
|
||||
"""
|
||||
image_features = self.encode_image(image)
|
||||
text_features = self.encode_text(text)
|
||||
# import pdb; pdb.set_trace()
|
||||
# normalized features
|
||||
# image_features shape: [1, 1024]
|
||||
image_features = image_features / image_features.norm(
|
||||
dim=-1, keepdim=True)
|
||||
text_features = text_features / text_features.norm(
|
||||
dim=-1, keepdim=True)
|
||||
|
||||
# cosine similarity as logits
|
||||
logit_scale = self.logit_scale.exp()
|
||||
logits_per_iamge = logit_scale * image_features @ text_features.t()
|
||||
logits_per_text = logit_scale * text_features @ image_features.t()
|
||||
|
||||
# shape = [global_batch_size, global_batch_size]
|
||||
return logits_per_iamge, logits_per_text
|
||||
|
||||
|
||||
def convert_weights(model: nn.Module):
|
||||
"""Convert applicable model parameters to fp16."""
|
||||
|
||||
def _convert_weights_to_fp16(layer):
|
||||
if isinstance(layer, (nn.Conv1d, nn.Conv2d, nn.Linear)):
|
||||
layer.weight.data = layer.weight.data.half()
|
||||
if layer.bias is not None:
|
||||
layer.bias.data = layer.bias.data.half()
|
||||
|
||||
if isinstance(layer, nn.MultiheadAttention):
|
||||
for attr in [
|
||||
*[f'{s}_proj_weight' for s in ['in', 'q', 'k', 'v']],
|
||||
'in_proj_bias', 'bias_k', 'bias_v'
|
||||
]:
|
||||
tensor = getattr(layer, attr)
|
||||
if tensor is not None:
|
||||
tensor.data = tensor.data.half()
|
||||
|
||||
for name in ['text_projection', 'proj']:
|
||||
if hasattr(layer, name):
|
||||
attr = getattr(layer, name)
|
||||
if attr is not None:
|
||||
attr.data = attr.data.half()
|
||||
|
||||
model.apply(_convert_weights_to_fp16)
|
||||
|
||||
|
||||
def build_model(state_dict: dict, prompt_depth=0, prompt_length=0):
|
||||
"""Build a CLIP model from given pretrained weights."""
|
||||
vit = 'visual.proj' in state_dict
|
||||
|
||||
if vit:
|
||||
vision_width = state_dict['visual.conv1.weight'].shape[0]
|
||||
vision_layers = len([
|
||||
k for k in state_dict.keys()
|
||||
if k.startswith('visual.') and k.endswith('.attn.in_proj_weight')
|
||||
])
|
||||
vision_patch_size = state_dict['visual.conv1.weight'].shape[-1]
|
||||
grid_size = round(
|
||||
(state_dict['visual.positional_embedding'].shape[0] - 1)**0.5)
|
||||
image_resolution = vision_patch_size * grid_size
|
||||
else:
|
||||
counts: list = [
|
||||
len({
|
||||
k.split('.')[2]
|
||||
for k in state_dict if k.startswith(f'visual.layer{b}')
|
||||
}) for b in [1, 2, 3, 4]
|
||||
]
|
||||
vision_layers = tuple(counts)
|
||||
vision_width = state_dict['visual.layer1.0.conv1.weight'].shape[0]
|
||||
output_width = round(
|
||||
(state_dict['visual.attnpool.positional_embedding'].shape[0] -
|
||||
1)**0.5)
|
||||
vision_patch_size = None
|
||||
assert output_width**2 + 1 == state_dict[
|
||||
'visual.attnpool.positional_embedding'].shape[0]
|
||||
image_resolution = output_width * 32
|
||||
|
||||
embed_dim = state_dict['text_projection'].shape[1]
|
||||
context_length = state_dict['positional_embedding'].shape[0]
|
||||
vocab_size = state_dict['token_embedding.weight'].shape[0]
|
||||
transformer_width = state_dict['ln_final.weight'].shape[0]
|
||||
transformer_heads = transformer_width // 64
|
||||
transformer_layers = len({
|
||||
k.split('.')[2]
|
||||
for k in state_dict if k.startswith('transformer.resblocks')
|
||||
})
|
||||
|
||||
model = CLIP(
|
||||
embed_dim,
|
||||
image_resolution,
|
||||
vision_layers,
|
||||
vision_width,
|
||||
vision_patch_size,
|
||||
context_length,
|
||||
vocab_size,
|
||||
transformer_width,
|
||||
transformer_heads,
|
||||
transformer_layers,
|
||||
prompt_depth=prompt_depth,
|
||||
prompt_length=prompt_length,
|
||||
)
|
||||
|
||||
for key in ['input_resolution', 'context_length', 'vocab_size']:
|
||||
del state_dict[key]
|
||||
|
||||
convert_weights(model)
|
||||
model.load_state_dict(state_dict, strict=False)
|
||||
return model.eval()
|
||||
@@ -0,0 +1,204 @@
|
||||
# Copyright (c) OpenMMLab. All rights reserved.
|
||||
|
||||
# Source: https://github.com/openai/CLIP.
|
||||
|
||||
IMAGENET_TEMPLATES = [
|
||||
'a bad photo of a {}.',
|
||||
'a photo of many {}.',
|
||||
'a sculpture of a {}.',
|
||||
'a photo of the hard to see {}.',
|
||||
'a low resolution photo of the {}.',
|
||||
'a rendering of a {}.',
|
||||
'graffiti of a {}.',
|
||||
'a bad photo of the {}.',
|
||||
'a cropped photo of the {}.',
|
||||
'a tattoo of a {}.',
|
||||
'the embroidered {}.',
|
||||
'a photo of a hard to see {}.',
|
||||
'a bright photo of a {}.',
|
||||
'a photo of a clean {}.',
|
||||
'a photo of a dirty {}.',
|
||||
'a dark photo of the {}.',
|
||||
'a drawing of a {}.',
|
||||
'a photo of my {}.',
|
||||
'the plastic {}.',
|
||||
'a photo of the cool {}.',
|
||||
'a close-up photo of a {}.',
|
||||
'a black and white photo of the {}.',
|
||||
'a painting of the {}.',
|
||||
'a painting of a {}.',
|
||||
'a pixelated photo of the {}.',
|
||||
'a sculpture of the {}.',
|
||||
'a bright photo of the {}.',
|
||||
'a cropped photo of a {}.',
|
||||
'a plastic {}.',
|
||||
'a photo of the dirty {}.',
|
||||
'a jpeg corrupted photo of a {}.',
|
||||
'a blurry photo of the {}.',
|
||||
'a photo of the {}.',
|
||||
'a good photo of the {}.',
|
||||
'a rendering of the {}.',
|
||||
'a {} in a video game.',
|
||||
'a photo of one {}.',
|
||||
'a doodle of a {}.',
|
||||
'a close-up photo of the {}.',
|
||||
'a photo of a {}.',
|
||||
'the origami {}.',
|
||||
'the {} in a video game.',
|
||||
'a sketch of a {}.',
|
||||
'a doodle of the {}.',
|
||||
'a origami {}.',
|
||||
'a low resolution photo of a {}.',
|
||||
'the toy {}.',
|
||||
'a rendition of the {}.',
|
||||
'a photo of the clean {}.',
|
||||
'a photo of a large {}.',
|
||||
'a rendition of a {}.',
|
||||
'a photo of a nice {}.',
|
||||
'a photo of a weird {}.',
|
||||
'a blurry photo of a {}.',
|
||||
'a cartoon {}.',
|
||||
'art of a {}.',
|
||||
'a sketch of the {}.',
|
||||
'a embroidered {}.',
|
||||
'a pixelated photo of a {}.',
|
||||
'itap of the {}.',
|
||||
'a jpeg corrupted photo of the {}.',
|
||||
'a good photo of a {}.',
|
||||
'a plushie {}.',
|
||||
'a photo of the nice {}.',
|
||||
'a photo of the small {}.',
|
||||
'a photo of the weird {}.',
|
||||
'the cartoon {}.',
|
||||
'art of the {}.',
|
||||
'a drawing of the {}.',
|
||||
'a photo of the large {}.',
|
||||
'a black and white photo of a {}.',
|
||||
'the plushie {}.',
|
||||
'a dark photo of a {}.',
|
||||
'itap of a {}.',
|
||||
'graffiti of the {}.',
|
||||
'a toy {}.',
|
||||
'itap of my {}.',
|
||||
'a photo of a cool {}.',
|
||||
'a photo of a small {}.',
|
||||
'a tattoo of the {}.',
|
||||
# 'A photo of a {} in the scene.',
|
||||
]
|
||||
|
||||
# v1: 59.0875
|
||||
IMAGENET_TEMPLATES_SELECT = [
|
||||
'itap of a {}.',
|
||||
'a bad photo of the {}.',
|
||||
'a origami {}.',
|
||||
'a photo of the large {}.',
|
||||
'a {} in a video game.',
|
||||
'art of the {}.',
|
||||
'a photo of the small {}.',
|
||||
'A photo of a {} in the scene',
|
||||
]
|
||||
|
||||
# v9
|
||||
IMAGENET_TEMPLATES_SELECT_CLIP = [
|
||||
'a bad photo of the {}.',
|
||||
'a photo of the large {}.',
|
||||
'a photo of the small {}.',
|
||||
'a cropped photo of a {}.',
|
||||
'This is a photo of a {}',
|
||||
'This is a photo of a small {}',
|
||||
'This is a photo of a medium {}',
|
||||
'This is a photo of a large {}',
|
||||
'This is a masked photo of a {}',
|
||||
'This is a masked photo of a small {}',
|
||||
'This is a masked photo of a medium {}',
|
||||
'This is a masked photo of a large {}',
|
||||
'This is a cropped photo of a {}',
|
||||
'This is a cropped photo of a small {}',
|
||||
'This is a cropped photo of a medium {}',
|
||||
'This is a cropped photo of a large {}',
|
||||
'A photo of a {} in the scene',
|
||||
'a bad photo of the {} in the scene',
|
||||
'a photo of the large {} in the scene',
|
||||
'a photo of the small {} in the scene',
|
||||
'a cropped photo of a {} in the scene',
|
||||
'a photo of a masked {} in the scene',
|
||||
'There is a {} in the scene',
|
||||
'There is the {} in the scene',
|
||||
'This is a {} in the scene',
|
||||
'This is the {} in the scene',
|
||||
'This is one {} in the scene',
|
||||
'There is a masked {} in the scene',
|
||||
'There is the masked {} in the scene',
|
||||
'This is a masked {} in the scene',
|
||||
'This is the masked {} in the scene',
|
||||
'This is one masked {} in the scene',
|
||||
]
|
||||
|
||||
# v10, for comparison
|
||||
# IMAGENET_TEMPLATES_SELECT_CLIP = [
|
||||
# 'a photo of a {}.',
|
||||
#
|
||||
# 'This is a photo of a {}',
|
||||
# 'This is a photo of a small {}',
|
||||
# 'This is a photo of a medium {}',
|
||||
# 'This is a photo of a large {}',
|
||||
#
|
||||
# 'This is a photo of a {}',
|
||||
# 'This is a photo of a small {}',
|
||||
# 'This is a photo of a medium {}',
|
||||
# 'This is a photo of a large {}',
|
||||
#
|
||||
# 'a photo of a {} in the scene',
|
||||
# 'a photo of a {} in the scene',
|
||||
#
|
||||
# 'There is a {} in the scene',
|
||||
# 'There is the {} in the scene',
|
||||
# 'This is a {} in the scene',
|
||||
# 'This is the {} in the scene',
|
||||
# 'This is one {} in the scene',
|
||||
# ]
|
||||
|
||||
ViLD_templates = [
|
||||
'There is {article} {category} in the scene.',
|
||||
'There is the {category} in the scene.',
|
||||
'a photo of {article} {category} in the scene.',
|
||||
'a photo of the {category} in the scene.',
|
||||
'a photo of one {category} in the scene.', 'itap of {article} {category}.',
|
||||
'itap of my {category}.', 'itap of the {category}.',
|
||||
'a photo of {article} {category}.', 'a photo of my {category}.',
|
||||
'a photo of the {category}.', 'a photo of one {category}.',
|
||||
'a photo of many {category}.', 'a good photo of {article} {category}.',
|
||||
'a good photo of the {category}.', 'a bad photo of {article} {category}.',
|
||||
'a bad photo of the {category}.', 'a photo of a nice {category}.',
|
||||
'a photo of the nice {category}.', 'a photo of a cool {category}.',
|
||||
'a photo of the cool {category}.', 'a photo of a weird {category}.',
|
||||
'a photo of the weird {category}.', 'a photo of a small {category}.',
|
||||
'a photo of the small {category}.', 'a photo of a large {category}.',
|
||||
'a photo of the large {category}.', 'a photo of a clean {category}.',
|
||||
'a photo of the clean {category}.', 'a photo of a dirty {category}.',
|
||||
'a photo of the dirty {category}.',
|
||||
'a bright photo of {article} {category}.',
|
||||
'a bright photo of the {category}.',
|
||||
'a dark photo of {article} {category}.', 'a dark photo of the {category}.',
|
||||
'a photo of a hard to see {category}.',
|
||||
'a photo of the hard to see {category}.',
|
||||
'a low resolution photo of {article} {category}.',
|
||||
'a low resolution photo of the {category}.',
|
||||
'a cropped photo of {article} {category}.',
|
||||
'a cropped photo of the {category}.',
|
||||
'a close-up photo of {article} {category}.',
|
||||
'a close-up photo of the {category}.',
|
||||
'a jpeg corrupted photo of {article} {category}.',
|
||||
'a jpeg corrupted photo of the {category}.',
|
||||
'a blurry photo of {article} {category}.',
|
||||
'a blurry photo of the {category}.',
|
||||
'a pixelated photo of {article} {category}.',
|
||||
'a pixelated photo of the {category}.',
|
||||
'a black and white photo of the {category}.',
|
||||
'a black and white photo of {article} {category}.',
|
||||
'a plastic {category}.', 'the plastic {category}.', 'a toy {category}.',
|
||||
'the toy {category}.', 'a plushie {category}.', 'the plushie {category}.',
|
||||
'a cartoon {category}.', 'the cartoon {category}.',
|
||||
'an embroidered {category}.', 'the embroidered {category}.',
|
||||
'a painting of the {category}.', 'a painting of a {category}.'
|
||||
]
|
||||
@@ -0,0 +1,275 @@
|
||||
# Copyright (c) OpenMMLab. All rights reserved.
|
||||
# Referred to: https://github.com/KU-CVLAB/CAT-Seg/blob/main/cat_seg/third_party/clip.py # noqa
|
||||
import hashlib
|
||||
import os
|
||||
import urllib
|
||||
import warnings
|
||||
from typing import List, Union
|
||||
|
||||
import torch
|
||||
from PIL import Image
|
||||
from torchvision.transforms import (CenterCrop, Compose, Normalize, Resize,
|
||||
ToTensor)
|
||||
from tqdm import tqdm
|
||||
|
||||
from .clip_model import build_model
|
||||
from .tokenizer import SimpleTokenizer as _Tokenizer
|
||||
|
||||
__all__ = ['available_models', 'load', 'tokenize']
|
||||
_tokenizer = _Tokenizer()
|
||||
|
||||
_MODELS = {
|
||||
'RN50':
|
||||
'https://openaipublic.azureedge.net/clip/models/afeb0e10f9e5a86da6080e35cf09123aca3b358a0c3e3b6c78a7b63bc04b6762/RN50.pt', # noqa
|
||||
'RN101':
|
||||
'https://openaipublic.azureedge.net/clip/models/8fa8567bab74a42d41c5915025a8e4538c3bdbe8804a470a72f30b0d94fab599/RN101.pt', # noqa
|
||||
'RN50x4':
|
||||
'https://openaipublic.azureedge.net/clip/models/7e526bd135e493cef0776de27d5f42653e6b4c8bf9e0f653bb11773263205fdd/RN50x4.pt', # noqa
|
||||
'RN50x16':
|
||||
'https://openaipublic.azureedge.net/clip/models/52378b407f34354e150460fe41077663dd5b39c54cd0bfd2b27167a4a06ec9aa/RN50x16.pt', # noqa
|
||||
'RN50x64':
|
||||
'https://openaipublic.azureedge.net/clip/models/be1cfb55d75a9666199fb2206c106743da0f6468c9d327f3e0d0a543a9919d9c/RN50x64.pt', # noqa
|
||||
'ViT-B/32':
|
||||
'https://openaipublic.azureedge.net/clip/models/40d365715913c9da98579312b702a82c18be219cc2a73407c4526f58eba950af/ViT-B-32.pt', # noqa
|
||||
'ViT-B/16':
|
||||
'https://openaipublic.azureedge.net/clip/models/5806e77cd80f8b59890b7e101eabd078d9fb84e6937f9e85e4ecb61988df416f/ViT-B-16.pt', # noqa
|
||||
'ViT-L/14':
|
||||
'https://openaipublic.azureedge.net/clip/models/b8cca3fd41ae0c99ba7e8951adf17d267cdb84cd88be6f7c2e0eca1737a03836/ViT-L-14.pt', # noqa
|
||||
'ViT-L/14@336px':
|
||||
'https://openaipublic.azureedge.net/clip/models/3035c92b350959924f9f00213499208652fc7ea050643e8b385c2dac08641f02/ViT-L-14-336px.pt', # noqa
|
||||
}
|
||||
|
||||
|
||||
def _download(url: str, root: str = os.path.expanduser('~/.cache/clip')):
|
||||
"""Download clip pretrained weights."""
|
||||
os.makedirs(root, exist_ok=True)
|
||||
filename = os.path.basename(url)
|
||||
|
||||
expected_sha256 = url.split('/')[-2]
|
||||
download_target = os.path.join(root, filename)
|
||||
|
||||
if os.path.exists(download_target) and not os.path.isfile(download_target):
|
||||
raise RuntimeError(
|
||||
f'{download_target} exists and is not a regular file')
|
||||
|
||||
if os.path.isfile(download_target):
|
||||
if hashlib.sha256(open(download_target,
|
||||
'rb').read()).hexdigest() == expected_sha256:
|
||||
return download_target
|
||||
else:
|
||||
warnings.warn(
|
||||
f'{download_target} exists, but the SHA256 checksum does not\
|
||||
match; re-downloading the file')
|
||||
|
||||
with urllib.request.urlopen(url) as source, open(download_target,
|
||||
'wb') as output:
|
||||
with tqdm(
|
||||
total=int(source.info().get('Content-Length')),
|
||||
ncols=80) as loop:
|
||||
while True:
|
||||
buffer = source.read(8192)
|
||||
if not buffer:
|
||||
break
|
||||
|
||||
output.write(buffer)
|
||||
loop.update(len(buffer))
|
||||
|
||||
if hashlib.sha256(open(download_target,
|
||||
'rb').read()).hexdigest() != expected_sha256:
|
||||
raise RuntimeError(
|
||||
'Model has been downloaded but the SHA256 checksum does not not\
|
||||
match')
|
||||
|
||||
return download_target
|
||||
|
||||
|
||||
def available_models():
|
||||
"""Returns a list of available models."""
|
||||
return list(_MODELS.keys())
|
||||
|
||||
|
||||
def load(name: str,
|
||||
device: Union[str, torch.device] = 'cuda'
|
||||
if torch.cuda.is_available() else 'cpu',
|
||||
jit=True,
|
||||
prompt_depth=0,
|
||||
prompt_length=0):
|
||||
"""Load target clip model."""
|
||||
if name not in _MODELS:
|
||||
raise RuntimeError(
|
||||
f'Model {name} not found; available models = {available_models()}')
|
||||
|
||||
model_path = _download(_MODELS[name])
|
||||
model = torch.jit.load(
|
||||
model_path, map_location=device if jit else 'cpu').eval()
|
||||
n_px = model.input_resolution.item()
|
||||
|
||||
transform = Compose([
|
||||
Resize(n_px, interpolation=Image.BICUBIC),
|
||||
CenterCrop(n_px),
|
||||
lambda image: image.convert('RGB'),
|
||||
ToTensor(),
|
||||
Normalize((0.48145466, 0.4578275, 0.40821073),
|
||||
(0.26862954, 0.26130258, 0.27577711)),
|
||||
])
|
||||
|
||||
if not jit:
|
||||
model = build_model(model.state_dict(), prompt_depth,
|
||||
prompt_length).to(device)
|
||||
return model, transform
|
||||
|
||||
# patch the device names
|
||||
device_holder = torch.jit.trace(
|
||||
lambda: torch.ones([]).to(torch.device(device)), example_inputs=[])
|
||||
device_node = [
|
||||
n for n in device_holder.graph.findAllNodes('prim::Constant')
|
||||
if 'Device' in repr(n)
|
||||
][-1]
|
||||
|
||||
def patch_device(module):
|
||||
graphs = [module.graph] if hasattr(module, 'graph') else []
|
||||
if hasattr(module, 'forward1'):
|
||||
graphs.append(module.forward1.graph)
|
||||
|
||||
for graph in graphs:
|
||||
for node in graph.findAllNodes('prim::Constant'):
|
||||
if 'value' in node.attributeNames() and str(
|
||||
node['value']).startswith('cuda'):
|
||||
node.copyAttributes(device_node)
|
||||
|
||||
model.apply(patch_device)
|
||||
patch_device(model.encode_image)
|
||||
patch_device(model.encode_text)
|
||||
|
||||
# patch dtype to float32 on CPU
|
||||
if device == 'cpu':
|
||||
float_holder = torch.jit.trace(
|
||||
lambda: torch.ones([]).float(), example_inputs=[])
|
||||
float_input = list(float_holder.graph.findNode('aten::to').inputs())[1]
|
||||
float_node = float_input.node()
|
||||
|
||||
def patch_float(module):
|
||||
graphs = [module.graph] if hasattr(module, 'graph') else []
|
||||
if hasattr(module, 'forward1'):
|
||||
graphs.append(module.forward1.graph)
|
||||
|
||||
for graph in graphs:
|
||||
for node in graph.findAllNodes('aten::to'):
|
||||
inputs = list(node.inputs())
|
||||
for i in [1, 2]:
|
||||
# dtype can be the second or third argument to
|
||||
# aten::to()
|
||||
if inputs[i].node()['value'] == 5:
|
||||
inputs[i].node().copyAttributes(float_node)
|
||||
|
||||
model.apply(patch_float)
|
||||
patch_float(model.encode_image)
|
||||
patch_float(model.encode_text)
|
||||
|
||||
model.float()
|
||||
|
||||
return model, transform
|
||||
|
||||
|
||||
def load_custom(name: str,
|
||||
device: Union[str, torch.device] = 'cuda'
|
||||
if torch.cuda.is_available() else 'cpu',
|
||||
jit=True,
|
||||
n_px=224):
|
||||
"""Load a customized clip model."""
|
||||
if name not in _MODELS:
|
||||
raise RuntimeError(
|
||||
f'Model {name} not found; available models = {available_models()}')
|
||||
|
||||
model_path = _download(_MODELS[name])
|
||||
model = torch.jit.load(
|
||||
model_path, map_location=device if jit else 'cpu').eval()
|
||||
# n_px = model.input_resolution.item()
|
||||
|
||||
transform = Compose([
|
||||
Resize(n_px, interpolation=Image.BICUBIC),
|
||||
CenterCrop(n_px),
|
||||
lambda image: image.convert('RGB'),
|
||||
ToTensor(),
|
||||
Normalize((0.48145466, 0.4578275, 0.40821073),
|
||||
(0.26862954, 0.26130258, 0.27577711)),
|
||||
])
|
||||
|
||||
if not jit:
|
||||
model = build_model(model.state_dict()).to(device)
|
||||
return model, transform
|
||||
|
||||
# patch the device names
|
||||
device_holder = torch.jit.trace(
|
||||
lambda: torch.ones([]).to(torch.device(device)), example_inputs=[])
|
||||
device_node = [
|
||||
n for n in device_holder.graph.findAllNodes('prim::Constant')
|
||||
if 'Device' in repr(n)
|
||||
][-1]
|
||||
|
||||
def patch_device(module):
|
||||
graphs = [module.graph] if hasattr(module, 'graph') else []
|
||||
if hasattr(module, 'forward1'):
|
||||
graphs.append(module.forward1.graph)
|
||||
|
||||
for graph in graphs:
|
||||
for node in graph.findAllNodes('prim::Constant'):
|
||||
if 'value' in node.attributeNames() and str(
|
||||
node['value']).startswith('cuda'):
|
||||
node.copyAttributes(device_node)
|
||||
|
||||
model.apply(patch_device)
|
||||
patch_device(model.encode_image)
|
||||
patch_device(model.encode_text)
|
||||
|
||||
# patch dtype to float32 on CPU
|
||||
if device == 'cpu':
|
||||
float_holder = torch.jit.trace(
|
||||
lambda: torch.ones([]).float(), example_inputs=[])
|
||||
float_input = list(float_holder.graph.findNode('aten::to').inputs())[1]
|
||||
float_node = float_input.node()
|
||||
|
||||
def patch_float(module):
|
||||
graphs = [module.graph] if hasattr(module, 'graph') else []
|
||||
if hasattr(module, 'forward1'):
|
||||
graphs.append(module.forward1.graph)
|
||||
|
||||
for graph in graphs:
|
||||
for node in graph.findAllNodes('aten::to'):
|
||||
inputs = list(node.inputs())
|
||||
for i in [
|
||||
1, 2
|
||||
]: # dtype can be the second or third argument to
|
||||
# aten::to()
|
||||
if inputs[i].node()['value'] == 5:
|
||||
inputs[i].node().copyAttributes(float_node)
|
||||
|
||||
model.apply(patch_float)
|
||||
patch_float(model.encode_image)
|
||||
patch_float(model.encode_text)
|
||||
|
||||
model.float()
|
||||
|
||||
return model, transform
|
||||
|
||||
|
||||
def tokenize(texts: Union[str, List[str]], context_length: int = 77):
|
||||
"""Convert texts to tokens."""
|
||||
if isinstance(texts, str):
|
||||
texts = [texts]
|
||||
|
||||
sot_token = _tokenizer.encoder['<|startoftext|>']
|
||||
eot_token = _tokenizer.encoder['<|endoftext|>']
|
||||
# encode each template text phrase
|
||||
all_tokens = [[sot_token] + _tokenizer.encode(text) + [eot_token]
|
||||
for text in texts]
|
||||
result = torch.zeros(len(all_tokens), context_length, dtype=torch.long)
|
||||
|
||||
for i, tokens in enumerate(all_tokens):
|
||||
if len(tokens) > context_length:
|
||||
raise RuntimeError(
|
||||
f'Input {texts[i]} is too long for context length\
|
||||
{context_length}')
|
||||
result[i, :len(tokens)] = torch.tensor(tokens)
|
||||
|
||||
return result
|
||||
@@ -0,0 +1,79 @@
|
||||
# Copyright (c) OpenMMLab. All rights reserved.
|
||||
import torch
|
||||
from torch import nn as nn
|
||||
from torch.nn import functional as F
|
||||
|
||||
|
||||
class LinearAttention(nn.Module):
|
||||
"""Multi-Head linear attention proposed in "Transformers are RNNs".
|
||||
|
||||
Source: https://github.com/KU-CVLAB/CAT-Seg/blob/main/cat_seg/modeling/transformer/model.py#L247 # noqa
|
||||
"""
|
||||
|
||||
def __init__(self, eps=1e-6):
|
||||
super().__init__()
|
||||
self.eps = eps
|
||||
|
||||
def forward(self, queries, keys, values):
|
||||
"""
|
||||
Args:
|
||||
queries: [N, L, H, D]
|
||||
keys: [N, S, H, D]
|
||||
values: [N, S, H, D]
|
||||
q_mask: [N, L]
|
||||
kv_mask: [N, S]
|
||||
Returns:
|
||||
queried_values: (N, L, H, D)
|
||||
"""
|
||||
Q = F.elu(queries) + 1
|
||||
K = F.elu(keys) + 1
|
||||
|
||||
v_length = values.size(1)
|
||||
values = values / v_length # prevent fp16 overflow
|
||||
KV = torch.einsum('nshd,nshv->nhdv', K, values) # (S,D)' @ S,V
|
||||
Z = 1 / (torch.einsum('nlhd,nhd->nlh', Q, K.sum(dim=1)) + self.eps)
|
||||
queried_values = torch.einsum('nlhd,nhdv,nlh->nlhv', Q, KV,
|
||||
Z) * v_length
|
||||
|
||||
return queried_values.contiguous()
|
||||
|
||||
|
||||
class FullAttention(nn.Module):
|
||||
"""Multi-head scaled dot-product attention, a.k.a full attention.
|
||||
|
||||
Source: https://github.com/KU-CVLAB/CAT-Seg/blob/main/cat_seg/modeling/transformer/model.py#L276 # noqa
|
||||
"""
|
||||
|
||||
def __init__(self, use_dropout=False, attention_dropout=0.1):
|
||||
super().__init__()
|
||||
self.use_dropout = use_dropout
|
||||
self.dropout = nn.Dropout(attention_dropout)
|
||||
|
||||
def forward(self, queries, keys, values, q_mask=None, kv_mask=None):
|
||||
"""
|
||||
Args:
|
||||
queries: [N, L, H, D]
|
||||
keys: [N, S, H, D]
|
||||
values: [N, S, H, D]
|
||||
q_mask: [N, L]
|
||||
kv_mask: [N, S]
|
||||
Returns:
|
||||
queried_values: (N, L, H, D)
|
||||
"""
|
||||
|
||||
# Compute the unnormalized attention and apply the masks
|
||||
QK = torch.einsum('nlhd,nshd->nlsh', queries, keys)
|
||||
if kv_mask is not None:
|
||||
QK.masked_fill_(
|
||||
~(q_mask[:, :, None, None] * kv_mask[:, None, :, None]),
|
||||
float('-inf'))
|
||||
|
||||
# Compute the attention and the weighted average
|
||||
softmax_temp = 1. / queries.size(3)**.5 # sqrt(D)
|
||||
A = torch.softmax(softmax_temp * QK, dim=2)
|
||||
if self.use_dropout:
|
||||
A = self.dropout(A)
|
||||
|
||||
queried_values = torch.einsum('nlsh,nshd->nlhd', A, values)
|
||||
|
||||
return queried_values.contiguous()
|
||||
160
Seg_All_In_One_MMSeg/projects/CAT-Seg/cat_seg/utils/tokenizer.py
Normal file
160
Seg_All_In_One_MMSeg/projects/CAT-Seg/cat_seg/utils/tokenizer.py
Normal file
@@ -0,0 +1,160 @@
|
||||
# Copyright (c) OpenMMLab. All rights reserved.
|
||||
import gzip
|
||||
import html
|
||||
import os
|
||||
from functools import lru_cache
|
||||
|
||||
import ftfy
|
||||
import regex as re
|
||||
|
||||
|
||||
@lru_cache()
|
||||
def default_bpe():
|
||||
"""Return default BPE vocabulary path."""
|
||||
return os.path.join(
|
||||
os.path.dirname(os.path.abspath(__file__)),
|
||||
'bpe_vocab/bpe_simple_vocab_16e6.txt.gz')
|
||||
|
||||
|
||||
@lru_cache()
|
||||
def bytes_to_unicode():
|
||||
"""Returns list of utf-8 byte and a corresponding list of unicode strings.
|
||||
|
||||
The reversible bpe codes work on unicode strings. This means you need a
|
||||
large # of unicode characters in your vocab if you want to avoid UNKs. When
|
||||
you're at something like a 10B token dataset you end up needing around 5K
|
||||
for decent coverage. This is a significant percentage of your normal, say,
|
||||
32K bpe vocab. To avoid that, we want lookup tables between utf-8 bytes and
|
||||
unicode strings. And avoids mapping to whitespace/control characters the
|
||||
bpe code barfs on.
|
||||
"""
|
||||
bs = list(range(ord('!'),
|
||||
ord('~') + 1)) + list(range(
|
||||
ord('¡'),
|
||||
ord('¬') + 1)) + list(range(ord('®'),
|
||||
ord('ÿ') + 1))
|
||||
cs = bs[:]
|
||||
n = 0
|
||||
for b in range(2**8):
|
||||
if b not in bs:
|
||||
bs.append(b)
|
||||
cs.append(2**8 + n)
|
||||
n += 1
|
||||
cs = [chr(n) for n in cs]
|
||||
return dict(zip(bs, cs))
|
||||
|
||||
|
||||
def get_pairs(word):
|
||||
"""Return set of symbol pairs in a word.
|
||||
|
||||
Word is represented as tuple of symbols (symbols being variable-length
|
||||
strings).
|
||||
"""
|
||||
pairs = set()
|
||||
prev_char = word[0]
|
||||
for char in word[1:]:
|
||||
pairs.add((prev_char, char))
|
||||
prev_char = char
|
||||
return pairs
|
||||
|
||||
|
||||
def basic_clean(text):
|
||||
"""Clean string."""
|
||||
text = ftfy.fix_text(text)
|
||||
text = html.unescape(html.unescape(text))
|
||||
return text.strip()
|
||||
|
||||
|
||||
def whitespace_clean(text):
|
||||
"""Clean whitespace in string."""
|
||||
text = re.sub(r'\s+', ' ', text)
|
||||
text = text.strip()
|
||||
return text
|
||||
|
||||
|
||||
class SimpleTokenizer:
|
||||
"""Customized Tokenizer implementation."""
|
||||
|
||||
def __init__(self, bpe_path: str = default_bpe()):
|
||||
self.byte_encoder = bytes_to_unicode()
|
||||
self.byte_decoder = {v: k for k, v in self.byte_encoder.items()}
|
||||
merges = gzip.open(bpe_path).read().decode('utf-8').split('\n')
|
||||
merges = merges[1:49152 - 256 - 2 + 1]
|
||||
merges = [tuple(merge.split()) for merge in merges]
|
||||
vocab = list(bytes_to_unicode().values())
|
||||
vocab = vocab + [v + '</w>' for v in vocab]
|
||||
for merge in merges:
|
||||
vocab.append(''.join(merge))
|
||||
vocab.extend(['<|startoftext|>', '<|endoftext|>'])
|
||||
self.encoder = dict(zip(vocab, range(len(vocab))))
|
||||
self.decoder = {v: k for k, v in self.encoder.items()}
|
||||
self.bpe_ranks = dict(zip(merges, range(len(merges))))
|
||||
self.cache = {
|
||||
'<|startoftext|>': '<|startoftext|>',
|
||||
'<|endoftext|>': '<|endoftext|>'
|
||||
}
|
||||
self.pat = re.compile(
|
||||
r"""<\|startoftext\|>|<\|endoftext\|>|'s|'t|'re|'ve|'m|\
|
||||
'll|'d|[\p{L}]+|[\p{N}]|[^\s\p{L}\p{N}]+""", re.IGNORECASE)
|
||||
|
||||
def bpe(self, token):
|
||||
"""Refer to bpe vocabulary dictionary."""
|
||||
if token in self.cache:
|
||||
return self.cache[token]
|
||||
word = tuple(token[:-1]) + (token[-1] + '</w>', )
|
||||
pairs = get_pairs(word)
|
||||
|
||||
if not pairs:
|
||||
return token + '</w>'
|
||||
|
||||
while True:
|
||||
bigram = min(
|
||||
pairs, key=lambda pair: self.bpe_ranks.get(pair, float('inf')))
|
||||
if bigram not in self.bpe_ranks:
|
||||
break
|
||||
first, second = bigram
|
||||
new_word = []
|
||||
i = 0
|
||||
while i < len(word):
|
||||
try:
|
||||
j = word.index(first, i)
|
||||
new_word.extend(word[i:j])
|
||||
i = j
|
||||
except ValueError:
|
||||
new_word.extend(word[i:])
|
||||
break
|
||||
|
||||
if word[i] == first and i < len(word) - 1 and word[
|
||||
i + 1] == second:
|
||||
new_word.append(first + second)
|
||||
i += 2
|
||||
else:
|
||||
new_word.append(word[i])
|
||||
i += 1
|
||||
new_word = tuple(new_word)
|
||||
word = new_word
|
||||
if len(word) == 1:
|
||||
break
|
||||
else:
|
||||
pairs = get_pairs(word)
|
||||
word = ' '.join(word)
|
||||
self.cache[token] = word
|
||||
return word
|
||||
|
||||
def encode(self, text):
|
||||
"""Encode text strings."""
|
||||
bpe_tokens = []
|
||||
text = whitespace_clean(basic_clean(text)).lower()
|
||||
for token in re.findall(self.pat, text):
|
||||
token = ''.join(self.byte_encoder[b]
|
||||
for b in token.encode('utf-8'))
|
||||
bpe_tokens.extend(self.encoder[bpe_token]
|
||||
for bpe_token in self.bpe(token).split(' '))
|
||||
return bpe_tokens
|
||||
|
||||
def decode(self, tokens):
|
||||
"""Decoder tokens to strings."""
|
||||
text = ''.join([self.decoder[token] for token in tokens])
|
||||
text = bytearray([self.byte_decoder[c] for c in text]).decode(
|
||||
'utf-8', errors='replace').replace('</w>', ' ')
|
||||
return text
|
||||
@@ -0,0 +1,68 @@
|
||||
# dataset settings
|
||||
dataset_type = 'ADE20KDataset'
|
||||
data_root = 'data/ade/ADEChallengeData2016'
|
||||
crop_size = (384, 384)
|
||||
train_pipeline = [
|
||||
dict(type='LoadImageFromFile'),
|
||||
dict(type='LoadAnnotations', reduce_zero_label=True),
|
||||
dict(
|
||||
type='RandomResize',
|
||||
scale=(2048, 512),
|
||||
ratio_range=(0.5, 2.0),
|
||||
keep_ratio=True),
|
||||
dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
|
||||
dict(type='RandomFlip', prob=0.5),
|
||||
dict(type='PhotoMetricDistortion'),
|
||||
dict(type='PackSegInputs')
|
||||
]
|
||||
test_pipeline = [
|
||||
dict(type='LoadImageFromFile'),
|
||||
dict(type='Resize', scale=(2048, 512), keep_ratio=True),
|
||||
# add loading annotation after ``Resize`` because ground truth
|
||||
# does not need to do resize data transform
|
||||
dict(type='LoadAnnotations', reduce_zero_label=True),
|
||||
dict(type='PackSegInputs')
|
||||
]
|
||||
img_ratios = [0.5, 0.75, 1.0, 1.25, 1.5, 1.75]
|
||||
tta_pipeline = [
|
||||
dict(type='LoadImageFromFile', backend_args=None),
|
||||
dict(
|
||||
type='TestTimeAug',
|
||||
transforms=[
|
||||
[
|
||||
dict(type='Resize', scale_factor=r, keep_ratio=True)
|
||||
for r in img_ratios
|
||||
],
|
||||
[
|
||||
dict(type='RandomFlip', prob=0., direction='horizontal'),
|
||||
dict(type='RandomFlip', prob=1., direction='horizontal')
|
||||
], [dict(type='LoadAnnotations')], [dict(type='PackSegInputs')]
|
||||
])
|
||||
]
|
||||
train_dataloader = dict(
|
||||
batch_size=4,
|
||||
num_workers=4,
|
||||
persistent_workers=True,
|
||||
sampler=dict(type='InfiniteSampler', shuffle=True),
|
||||
dataset=dict(
|
||||
type=dataset_type,
|
||||
data_root=data_root,
|
||||
data_prefix=dict(
|
||||
img_path='images/training', seg_map_path='annotations/training'),
|
||||
pipeline=train_pipeline))
|
||||
val_dataloader = dict(
|
||||
batch_size=1,
|
||||
num_workers=4,
|
||||
persistent_workers=True,
|
||||
sampler=dict(type='DefaultSampler', shuffle=False),
|
||||
dataset=dict(
|
||||
type=dataset_type,
|
||||
data_root=data_root,
|
||||
data_prefix=dict(
|
||||
img_path='images/validation',
|
||||
seg_map_path='annotations/validation'),
|
||||
pipeline=test_pipeline))
|
||||
test_dataloader = val_dataloader
|
||||
|
||||
val_evaluator = dict(type='IoUMetric', iou_metrics=['mIoU'])
|
||||
test_evaluator = val_evaluator
|
||||
@@ -0,0 +1,62 @@
|
||||
# dataset settings
|
||||
dataset_type = 'COCOStuffDataset'
|
||||
data_root = 'data/coco_stuff164k'
|
||||
crop_size = (384, 384)
|
||||
train_pipeline = [
|
||||
dict(type='LoadImageFromFile'),
|
||||
dict(type='LoadAnnotations'),
|
||||
dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
|
||||
dict(type='RandomFlip', prob=0.5),
|
||||
dict(type='PhotoMetricDistortion'),
|
||||
dict(type='PackSegInputs')
|
||||
]
|
||||
test_pipeline = [
|
||||
dict(type='LoadImageFromFile'),
|
||||
dict(type='Resize', scale=(2048, 512), keep_ratio=True),
|
||||
# add loading annotation after ``Resize`` because ground truth
|
||||
# does not need to do resize data transform
|
||||
dict(type='LoadAnnotations'),
|
||||
dict(type='PackSegInputs')
|
||||
]
|
||||
img_ratios = [0.5, 0.75, 1.0, 1.25, 1.5, 1.75]
|
||||
tta_pipeline = [
|
||||
dict(type='LoadImageFromFile', backend_args=None),
|
||||
dict(
|
||||
type='TestTimeAug',
|
||||
transforms=[
|
||||
[
|
||||
dict(type='Resize', scale_factor=r, keep_ratio=True)
|
||||
for r in img_ratios
|
||||
],
|
||||
[
|
||||
dict(type='RandomFlip', prob=0., direction='horizontal'),
|
||||
dict(type='RandomFlip', prob=1., direction='horizontal')
|
||||
], [dict(type='LoadAnnotations')], [dict(type='PackSegInputs')]
|
||||
])
|
||||
]
|
||||
train_dataloader = dict(
|
||||
batch_size=2,
|
||||
num_workers=4,
|
||||
persistent_workers=True,
|
||||
sampler=dict(type='InfiniteSampler', shuffle=True),
|
||||
dataset=dict(
|
||||
type=dataset_type,
|
||||
data_root=data_root,
|
||||
data_prefix=dict(
|
||||
img_path='images/train2017', seg_map_path='annotations/train2017'),
|
||||
pipeline=train_pipeline))
|
||||
val_dataloader = dict(
|
||||
batch_size=1,
|
||||
num_workers=4,
|
||||
persistent_workers=True,
|
||||
sampler=dict(type='DefaultSampler', shuffle=False),
|
||||
dataset=dict(
|
||||
type=dataset_type,
|
||||
data_root=data_root,
|
||||
data_prefix=dict(
|
||||
img_path='images/val2017', seg_map_path='annotations/val2017'),
|
||||
pipeline=test_pipeline))
|
||||
test_dataloader = val_dataloader
|
||||
|
||||
val_evaluator = dict(type='IoUMetric', iou_metrics=['mIoU'])
|
||||
test_evaluator = val_evaluator
|
||||
@@ -0,0 +1,72 @@
|
||||
# dataset settings
|
||||
dataset_type = 'PascalContextDataset59'
|
||||
data_root = 'data/VOCdevkit/VOC2010/'
|
||||
|
||||
img_scale = (520, 520)
|
||||
crop_size = (384, 384)
|
||||
|
||||
train_pipeline = [
|
||||
dict(type='LoadImageFromFile'),
|
||||
dict(type='LoadAnnotations', reduce_zero_label=True),
|
||||
dict(
|
||||
type='RandomResize',
|
||||
scale=img_scale,
|
||||
ratio_range=(0.5, 2.0),
|
||||
keep_ratio=True),
|
||||
dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
|
||||
dict(type='RandomFlip', prob=0.5),
|
||||
dict(type='PhotoMetricDistortion'),
|
||||
dict(type='PackSegInputs')
|
||||
]
|
||||
test_pipeline = [
|
||||
dict(type='LoadImageFromFile'),
|
||||
dict(type='Resize', scale=img_scale, keep_ratio=True),
|
||||
# add loading annotation after ``Resize`` because ground truth
|
||||
# does not need to do resize data transform
|
||||
dict(type='LoadAnnotations', reduce_zero_label=True),
|
||||
dict(type='PackSegInputs')
|
||||
]
|
||||
img_ratios = [0.5, 0.75, 1.0, 1.25, 1.5, 1.75]
|
||||
tta_pipeline = [
|
||||
dict(type='LoadImageFromFile', backend_args=None),
|
||||
dict(
|
||||
type='TestTimeAug',
|
||||
transforms=[
|
||||
[
|
||||
dict(type='Resize', scale_factor=r, keep_ratio=True)
|
||||
for r in img_ratios
|
||||
],
|
||||
[
|
||||
dict(type='RandomFlip', prob=0., direction='horizontal'),
|
||||
dict(type='RandomFlip', prob=1., direction='horizontal')
|
||||
], [dict(type='LoadAnnotations')], [dict(type='PackSegInputs')]
|
||||
])
|
||||
]
|
||||
train_dataloader = dict(
|
||||
batch_size=4,
|
||||
num_workers=4,
|
||||
persistent_workers=True,
|
||||
sampler=dict(type='InfiniteSampler', shuffle=True),
|
||||
dataset=dict(
|
||||
type=dataset_type,
|
||||
data_root=data_root,
|
||||
data_prefix=dict(
|
||||
img_path='JPEGImages', seg_map_path='SegmentationClassContext'),
|
||||
ann_file='ImageSets/SegmentationContext/train.txt',
|
||||
pipeline=train_pipeline))
|
||||
val_dataloader = dict(
|
||||
batch_size=1,
|
||||
num_workers=4,
|
||||
persistent_workers=True,
|
||||
sampler=dict(type='DefaultSampler', shuffle=False),
|
||||
dataset=dict(
|
||||
type=dataset_type,
|
||||
data_root=data_root,
|
||||
data_prefix=dict(
|
||||
img_path='JPEGImages', seg_map_path='SegmentationClassContext'),
|
||||
ann_file='ImageSets/SegmentationContext/val.txt',
|
||||
pipeline=test_pipeline))
|
||||
test_dataloader = val_dataloader
|
||||
|
||||
val_evaluator = dict(type='IoUMetric', iou_metrics=['mIoU'])
|
||||
test_evaluator = val_evaluator
|
||||
@@ -0,0 +1,15 @@
|
||||
default_scope = 'mmseg'
|
||||
env_cfg = dict(
|
||||
cudnn_benchmark=True,
|
||||
mp_cfg=dict(mp_start_method='fork', opencv_num_threads=0),
|
||||
dist_cfg=dict(backend='nccl'),
|
||||
)
|
||||
vis_backends = [dict(type='LocalVisBackend')]
|
||||
visualizer = dict(
|
||||
type='SegLocalVisualizer', vis_backends=vis_backends, name='visualizer')
|
||||
log_processor = dict(by_epoch=False)
|
||||
log_level = 'INFO'
|
||||
load_from = None
|
||||
resume = False
|
||||
|
||||
tta_model = dict(type='SegTTAModel')
|
||||
@@ -0,0 +1,24 @@
|
||||
# optimizer
|
||||
optimizer = dict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0005)
|
||||
optim_wrapper = dict(type='OptimWrapper', optimizer=optimizer, clip_grad=None)
|
||||
# learning policy
|
||||
param_scheduler = [
|
||||
dict(
|
||||
type='PolyLR',
|
||||
eta_min=1e-4,
|
||||
power=0.9,
|
||||
begin=0,
|
||||
end=80000,
|
||||
by_epoch=False)
|
||||
]
|
||||
# training schedule for 80k
|
||||
train_cfg = dict(type='IterBasedTrainLoop', max_iters=80000, val_interval=8000)
|
||||
val_cfg = dict(type='ValLoop')
|
||||
test_cfg = dict(type='TestLoop')
|
||||
default_hooks = dict(
|
||||
timer=dict(type='IterTimerHook'),
|
||||
logger=dict(type='LoggerHook', interval=50, log_metric_by_epoch=False),
|
||||
param_scheduler=dict(type='ParamSchedulerHook'),
|
||||
checkpoint=dict(type='CheckpointHook', by_epoch=False, interval=8000),
|
||||
sampler_seed=dict(type='DistSamplerSeedHook'),
|
||||
visualization=dict(type='SegVisualizationHook'))
|
||||
@@ -0,0 +1,103 @@
|
||||
_base_ = [
|
||||
'../_base_/default_runtime.py', '../_base_/schedules/schedule_80k.py',
|
||||
'../_base_/datasets/ade20k_384x384.py'
|
||||
]
|
||||
|
||||
custom_imports = dict(imports=['cat_seg'])
|
||||
|
||||
norm_cfg = dict(type='SyncBN', requires_grad=True)
|
||||
crop_size = (384, 384)
|
||||
data_preprocessor = dict(
|
||||
type='SegDataPreProcessor',
|
||||
size=crop_size,
|
||||
# due to the clip model, we do normalization in backbone forward()
|
||||
bgr_to_rgb=True,
|
||||
pad_val=0,
|
||||
seg_pad_val=255)
|
||||
# model_cfg
|
||||
model = dict(
|
||||
type='EncoderDecoder',
|
||||
data_preprocessor=data_preprocessor,
|
||||
backbone=dict(
|
||||
type='CLIPOVCATSeg',
|
||||
feature_extractor=dict(
|
||||
type='ResNet',
|
||||
depth=101,
|
||||
# only use the first three layers
|
||||
num_stages=3,
|
||||
out_indices=(0, 1, 2),
|
||||
dilations=(1, 1, 1),
|
||||
strides=(1, 2, 2),
|
||||
norm_cfg=norm_cfg,
|
||||
norm_eval=False,
|
||||
style='pytorch',
|
||||
contract_dilation=True,
|
||||
init_cfg=dict(
|
||||
type='Pretrained', checkpoint='torchvision://resnet101'),
|
||||
),
|
||||
train_class_json='data/ade150.json',
|
||||
test_class_json='data/ade150.json',
|
||||
clip_pretrained='ViT-B/16',
|
||||
clip_finetune='attention',
|
||||
),
|
||||
neck=dict(
|
||||
type='CATSegAggregator',
|
||||
appearance_guidance_dim=1024,
|
||||
num_layers=2,
|
||||
pooling_size=(1, 1),
|
||||
),
|
||||
decode_head=dict(
|
||||
type='CATSegHead',
|
||||
in_channels=128,
|
||||
channels=128,
|
||||
num_classes=150,
|
||||
embed_dims=128,
|
||||
decoder_dims=(64, 32),
|
||||
decoder_guidance_dims=(512, 256),
|
||||
decoder_guidance_proj_dims=(32, 16),
|
||||
loss_decode=dict(
|
||||
type='CrossEntropyLoss',
|
||||
use_sigmoid=False,
|
||||
loss_weight=1.0,
|
||||
avg_non_ignore=True)),
|
||||
# model training and testing settings
|
||||
train_cfg=dict(),
|
||||
test_cfg=dict(mode='slide', stride=crop_size, crop_size=crop_size))
|
||||
|
||||
# dataset settings
|
||||
train_dataloader = dict(
|
||||
batch_size=2,
|
||||
num_workers=4,
|
||||
)
|
||||
|
||||
# training schedule for 80k
|
||||
train_cfg = dict(type='IterBasedTrainLoop', max_iters=80000, val_interval=4000)
|
||||
|
||||
default_hooks = dict(
|
||||
checkpoint=dict(type='CheckpointHook', by_epoch=False, interval=4000),
|
||||
visualization=dict(type='SegVisualizationHook', draw=True, interval=4000))
|
||||
|
||||
# optimizer
|
||||
optim_wrapper = dict(
|
||||
_delete_=True,
|
||||
type='OptimWrapper',
|
||||
optimizer=dict(
|
||||
type='AdamW', lr=0.0002, betas=(0.9, 0.999), weight_decay=0.0001),
|
||||
paramwise_cfg=dict(
|
||||
custom_keys={
|
||||
'backbone.feature_extractor': dict(lr_mult=0.01),
|
||||
'backbone.clip_model.visual': dict(lr_mult=0.01)
|
||||
}))
|
||||
|
||||
# learning policy
|
||||
param_scheduler = [
|
||||
# Use a linear warm-up at [0, 100) iterations
|
||||
dict(type='LinearLR', start_factor=0.01, by_epoch=False, begin=0, end=500),
|
||||
# Use a cosine learning rate at [100, 900) iterations
|
||||
dict(
|
||||
type='CosineAnnealingLR',
|
||||
T_max=79500,
|
||||
by_epoch=False,
|
||||
begin=500,
|
||||
end=80000),
|
||||
]
|
||||
@@ -0,0 +1,103 @@
|
||||
_base_ = [
|
||||
'../_base_/default_runtime.py', '../_base_/schedules/schedule_80k.py',
|
||||
'../_base_/datasets/pascal_context_59_384x384.py'
|
||||
]
|
||||
|
||||
custom_imports = dict(imports=['cat_seg'])
|
||||
|
||||
norm_cfg = dict(type='SyncBN', requires_grad=True)
|
||||
crop_size = (384, 384)
|
||||
data_preprocessor = dict(
|
||||
type='SegDataPreProcessor',
|
||||
size=crop_size,
|
||||
# due to the clip model, we do normalization in backbone forward()
|
||||
bgr_to_rgb=True,
|
||||
pad_val=0,
|
||||
seg_pad_val=255)
|
||||
# model_cfg
|
||||
model = dict(
|
||||
type='EncoderDecoder',
|
||||
data_preprocessor=data_preprocessor,
|
||||
backbone=dict(
|
||||
type='CLIPOVCATSeg',
|
||||
feature_extractor=dict(
|
||||
type='ResNet',
|
||||
depth=101,
|
||||
# only use the first three layers
|
||||
num_stages=3,
|
||||
out_indices=(0, 1, 2),
|
||||
dilations=(1, 1, 1),
|
||||
strides=(1, 2, 2),
|
||||
norm_cfg=norm_cfg,
|
||||
norm_eval=False,
|
||||
style='pytorch',
|
||||
contract_dilation=True,
|
||||
init_cfg=dict(
|
||||
type='Pretrained', checkpoint='torchvision://resnet101'),
|
||||
),
|
||||
train_class_json='data/pc59.json',
|
||||
test_class_json='data/pc59.json',
|
||||
clip_pretrained='ViT-B/16',
|
||||
clip_finetune='attention',
|
||||
),
|
||||
neck=dict(
|
||||
type='CATSegAggregator',
|
||||
appearance_guidance_dim=1024,
|
||||
num_layers=2,
|
||||
pooling_size=(1, 1),
|
||||
),
|
||||
decode_head=dict(
|
||||
type='CATSegHead',
|
||||
in_channels=128,
|
||||
channels=128,
|
||||
num_classes=59,
|
||||
embed_dims=128,
|
||||
decoder_dims=(64, 32),
|
||||
decoder_guidance_dims=(512, 256),
|
||||
decoder_guidance_proj_dims=(32, 16),
|
||||
loss_decode=dict(
|
||||
type='CrossEntropyLoss',
|
||||
use_sigmoid=False,
|
||||
loss_weight=1.0,
|
||||
avg_non_ignore=True)),
|
||||
# model training and testing settings
|
||||
train_cfg=dict(),
|
||||
test_cfg=dict(mode='slide', stride=crop_size, crop_size=crop_size))
|
||||
|
||||
# dataset settings
|
||||
train_dataloader = dict(
|
||||
batch_size=2,
|
||||
num_workers=4,
|
||||
)
|
||||
|
||||
# training schedule for 80k
|
||||
train_cfg = dict(type='IterBasedTrainLoop', max_iters=80000, val_interval=4000)
|
||||
|
||||
default_hooks = dict(
|
||||
checkpoint=dict(type='CheckpointHook', by_epoch=False, interval=4000),
|
||||
visualization=dict(type='SegVisualizationHook', draw=True, interval=4000))
|
||||
|
||||
# optimizer
|
||||
optim_wrapper = dict(
|
||||
_delete_=True,
|
||||
type='OptimWrapper',
|
||||
optimizer=dict(
|
||||
type='AdamW', lr=0.0002, betas=(0.9, 0.999), weight_decay=0.0001),
|
||||
paramwise_cfg=dict(
|
||||
custom_keys={
|
||||
'backbone.feature_extractor': dict(lr_mult=0.01),
|
||||
'backbone.clip_model.visual': dict(lr_mult=0.01)
|
||||
}))
|
||||
|
||||
# learning policy
|
||||
param_scheduler = [
|
||||
# Use a linear warm-up at [0, 100) iterations
|
||||
dict(type='LinearLR', start_factor=0.01, by_epoch=False, begin=0, end=500),
|
||||
# Use a cosine learning rate at [100, 900) iterations
|
||||
dict(
|
||||
type='CosineAnnealingLR',
|
||||
T_max=79500,
|
||||
by_epoch=False,
|
||||
begin=500,
|
||||
end=80000),
|
||||
]
|
||||
@@ -0,0 +1,102 @@
|
||||
_base_ = [
|
||||
'../_base_/default_runtime.py', '../_base_/schedules/schedule_80k.py',
|
||||
'../_base_/datasets/coco-stuff164k_384x384.py'
|
||||
]
|
||||
|
||||
custom_imports = dict(imports=['cat_seg'])
|
||||
|
||||
norm_cfg = dict(type='SyncBN', requires_grad=True)
|
||||
crop_size = (384, 384)
|
||||
data_preprocessor = dict(
|
||||
type='SegDataPreProcessor',
|
||||
size=crop_size,
|
||||
# due to the clip model, we do normalization in backbone forward()
|
||||
bgr_to_rgb=True,
|
||||
pad_val=0,
|
||||
seg_pad_val=255)
|
||||
# model_cfg
|
||||
model = dict(
|
||||
type='EncoderDecoder',
|
||||
data_preprocessor=data_preprocessor,
|
||||
backbone=dict(
|
||||
type='CLIPOVCATSeg',
|
||||
feature_extractor=dict(
|
||||
type='ResNet',
|
||||
depth=101,
|
||||
# only use the first three layers
|
||||
num_stages=3,
|
||||
out_indices=(0, 1, 2),
|
||||
dilations=(1, 1, 1),
|
||||
strides=(1, 2, 2),
|
||||
norm_cfg=norm_cfg,
|
||||
norm_eval=False,
|
||||
style='pytorch',
|
||||
contract_dilation=True,
|
||||
init_cfg=dict(
|
||||
type='Pretrained', checkpoint='torchvision://resnet101'),
|
||||
),
|
||||
train_class_json='data/coco.json',
|
||||
test_class_json='data/coco.json',
|
||||
clip_pretrained='ViT-B/16',
|
||||
clip_finetune='attention',
|
||||
),
|
||||
neck=dict(
|
||||
type='CATSegAggregator',
|
||||
appearance_guidance_dim=1024,
|
||||
num_layers=2,
|
||||
),
|
||||
decode_head=dict(
|
||||
type='CATSegHead',
|
||||
in_channels=128,
|
||||
channels=128,
|
||||
num_classes=171,
|
||||
embed_dims=128,
|
||||
decoder_dims=(64, 32),
|
||||
decoder_guidance_dims=(512, 256),
|
||||
decoder_guidance_proj_dims=(32, 16),
|
||||
loss_decode=dict(
|
||||
type='CrossEntropyLoss',
|
||||
use_sigmoid=False,
|
||||
loss_weight=1.0,
|
||||
avg_non_ignore=True)),
|
||||
# model training and testing settings
|
||||
train_cfg=dict(),
|
||||
test_cfg=dict(mode='slide', stride=crop_size, crop_size=crop_size))
|
||||
|
||||
# dataset settings
|
||||
train_dataloader = dict(
|
||||
batch_size=2,
|
||||
num_workers=4,
|
||||
)
|
||||
|
||||
# training schedule for 80k
|
||||
train_cfg = dict(type='IterBasedTrainLoop', max_iters=80000, val_interval=4000)
|
||||
|
||||
default_hooks = dict(
|
||||
checkpoint=dict(type='CheckpointHook', by_epoch=False, interval=4000),
|
||||
visualization=dict(type='SegVisualizationHook', draw=True, interval=4000))
|
||||
|
||||
# optimizer
|
||||
optim_wrapper = dict(
|
||||
_delete_=True,
|
||||
type='OptimWrapper',
|
||||
optimizer=dict(
|
||||
type='AdamW', lr=0.0002, betas=(0.9, 0.999), weight_decay=0.0001),
|
||||
paramwise_cfg=dict(
|
||||
custom_keys={
|
||||
'backbone.feature_extractor': dict(lr_mult=0.01),
|
||||
'backbone.clip_model.visual': dict(lr_mult=0.01)
|
||||
}))
|
||||
|
||||
# learning policy
|
||||
param_scheduler = [
|
||||
# Use a linear warm-up at [0, 100) iterations
|
||||
dict(type='LinearLR', start_factor=0.01, by_epoch=False, begin=0, end=500),
|
||||
# Use a cosine learning rate at [100, 900) iterations
|
||||
dict(
|
||||
type='CosineAnnealingLR',
|
||||
T_max=79500,
|
||||
by_epoch=False,
|
||||
begin=500,
|
||||
end=80000),
|
||||
]
|
||||
@@ -0,0 +1,11 @@
|
||||
_base_ = './catseg_vitl-swin-b_4xb1-warmcoslr2e-4_adamw-80k_coco-stuff164k_384x384.py' # noqa
|
||||
|
||||
model = dict(
|
||||
backbone=dict(
|
||||
type='CLIPOVCATSeg',
|
||||
clip_pretrained='ViT-G',
|
||||
custom_clip_weights='~/CLIP-ViT-bigG-14-laion2B-39B-b160k'),
|
||||
neck=dict(
|
||||
text_guidance_dim=1280,
|
||||
appearance_guidance_dim=512,
|
||||
))
|
||||
@@ -0,0 +1,11 @@
|
||||
_base_ = './catseg_vitl-swin-b_4xb1-warmcoslr2e-4_adamw-80k_coco-stuff164k_384x384.py' # noqa
|
||||
|
||||
model = dict(
|
||||
backbone=dict(
|
||||
type='CLIPOVCATSeg',
|
||||
clip_pretrained='ViT-H',
|
||||
custom_clip_weights='~/CLIP-ViT-H-14-laion2B-s32B-b79K'),
|
||||
neck=dict(
|
||||
text_guidance_dim=1024,
|
||||
appearance_guidance_dim=512,
|
||||
))
|
||||
@@ -0,0 +1,72 @@
|
||||
_base_ = './catseg_vitb-r101_4xb2-warmcoslr2e-4-adamw-80k_coco-stuff164k-384x384.py' # noqa
|
||||
|
||||
pretrained = 'https://download.openmmlab.com/mmsegmentation/v0.5/pretrain/swin/swin_base_patch4_window12_384_20220317-55b0104a.pth' # noqa
|
||||
crop_size = (384, 384)
|
||||
data_preprocessor = dict(size=crop_size)
|
||||
model = dict(
|
||||
backbone=dict(
|
||||
type='CLIPOVCATSeg',
|
||||
feature_extractor=dict(
|
||||
_delete_=True,
|
||||
type='SwinTransformer',
|
||||
pretrain_img_size=384,
|
||||
embed_dims=128,
|
||||
depths=[2, 2, 18],
|
||||
num_heads=[4, 8, 16],
|
||||
window_size=12,
|
||||
mlp_ratio=4,
|
||||
qkv_bias=True,
|
||||
qk_scale=None,
|
||||
drop_rate=0.,
|
||||
attn_drop_rate=0.,
|
||||
drop_path_rate=0.3,
|
||||
patch_norm=True,
|
||||
out_indices=(0, 1, 2),
|
||||
init_cfg=dict(type='Pretrained', checkpoint=pretrained)),
|
||||
clip_pretrained='ViT-L/14@336px',
|
||||
),
|
||||
neck=dict(
|
||||
text_guidance_dim=768,
|
||||
appearance_guidance_dim=512,
|
||||
),
|
||||
decode_head=dict(
|
||||
embed_dims=128,
|
||||
decoder_guidance_dims=(256, 128),
|
||||
))
|
||||
|
||||
# dataset settings
|
||||
train_dataloader = dict(
|
||||
batch_size=1,
|
||||
num_workers=2,
|
||||
)
|
||||
|
||||
# training schedule for 80k
|
||||
train_cfg = dict(type='IterBasedTrainLoop', max_iters=80000, val_interval=4000)
|
||||
|
||||
default_hooks = dict(
|
||||
visualization=dict(type='SegVisualizationHook', draw=True, interval=4000))
|
||||
|
||||
# optimizer
|
||||
optim_wrapper = dict(
|
||||
_delete_=True,
|
||||
type='OptimWrapper',
|
||||
optimizer=dict(
|
||||
type='AdamW', lr=0.0002, betas=(0.9, 0.999), weight_decay=0.0001),
|
||||
paramwise_cfg=dict(
|
||||
custom_keys={
|
||||
'backbone.feature_extractor': dict(lr_mult=0.01),
|
||||
'backbone.clip_model.visual': dict(lr_mult=0.01)
|
||||
}))
|
||||
|
||||
# learning policy
|
||||
param_scheduler = [
|
||||
# Use a linear warm-up at [0, 100) iterations
|
||||
dict(type='LinearLR', start_factor=0.01, by_epoch=False, begin=0, end=500),
|
||||
# Use a cosine learning rate at [100, 900) iterations
|
||||
dict(
|
||||
type='CosineAnnealingLR',
|
||||
T_max=79500,
|
||||
by_epoch=False,
|
||||
begin=500,
|
||||
end=80000),
|
||||
]
|
||||
7
Seg_All_In_One_MMSeg/projects/CAT-Seg/utils/__init__.py
Normal file
7
Seg_All_In_One_MMSeg/projects/CAT-Seg/utils/__init__.py
Normal file
@@ -0,0 +1,7 @@
|
||||
from .clip_templates import (IMAGENET_TEMPLATES, IMAGENET_TEMPLATES_SELECT,
|
||||
IMAGENET_TEMPLATES_SELECT_CLIP, ViLD_templates)
|
||||
|
||||
__all__ = [
|
||||
'IMAGENET_TEMPLATES', 'IMAGENET_TEMPLATES_SELECT',
|
||||
'IMAGENET_TEMPLATES_SELECT_CLIP', 'ViLD_templates'
|
||||
]
|
||||
19
Seg_All_In_One_MMSeg/projects/README.md
Normal file
19
Seg_All_In_One_MMSeg/projects/README.md
Normal file
@@ -0,0 +1,19 @@
|
||||
# Projects
|
||||
|
||||
The OpenMMLab ecosystem can only grow through the contributions of the community.
|
||||
Everyone is welcome to post their implementation of any great ideas in this folder! If you wish to start your own project, please go through the [example project](example_project/) for the best practice. For common questions about projects, please read our [faq](faq.md).
|
||||
|
||||
## External Projects
|
||||
|
||||
There are also selected external projects released in the community that use MMSegmentation:
|
||||
|
||||
- [SegNeXt: Rethinking Convolutional Attention Design for Semantic Segmentation](https://github.com/visual-attention-network/segnext)
|
||||
- [Vision Transformer Adapter for Dense Predictions](https://github.com/czczup/ViT-Adapter)
|
||||
- [UniFormer: Unifying Convolution and Self-attention for Visual Recognition](https://github.com/Sense-X/UniFormer)
|
||||
- [Multi-Scale High-Resolution Vision Transformer for Semantic Segmentation](https://github.com/facebookresearch/HRViT)
|
||||
- [ViTAE: Vision Transformer Advanced by Exploring Intrinsic Inductive Bias](https://github.com/ViTAE-Transformer/ViTAE-Transformer)
|
||||
- [DAFormer: Improving Network Architectures and Training Strategies for Domain-Adaptive Semantic Segmentation](https://github.com/lhoyer/DAFormer)
|
||||
- [MPViT : Multi-Path Vision Transformer for Dense Prediction](https://github.com/youngwanLEE/MPViT)
|
||||
- [TopFormer: Token Pyramid Transformer for Mobile Semantic Segmentation](https://github.com/hustvl/TopFormer)
|
||||
|
||||
Note: These projects are supported and maintained by their own contributors. The core maintainers of MMSegmentation only ensure the results are reproducible and the code quality meets its claim at the time each project was submitted, but they may not be responsible for future maintenance.
|
||||
17
Seg_All_In_One_MMSeg/projects/XDecoder/README.md
Normal file
17
Seg_All_In_One_MMSeg/projects/XDecoder/README.md
Normal file
@@ -0,0 +1,17 @@
|
||||
# X-Decoder
|
||||
|
||||
> [X-Decoder: Generalized Decoding for Pixel, Image, and Language](https://arxiv.org/pdf/2212.11270.pdf)
|
||||
|
||||
<!-- [ALGORITHM] -->
|
||||
|
||||
## Abstract
|
||||
|
||||
We present X-Decoder, a generalized decoding model that can predict pixel-level segmentation and language tokens seamlessly. X-Decodert takes as input two types of queries: (i) generic non-semantic queries and (ii) semantic queries induced from text inputs, to decode different pixel-level and token-level outputs in the same semantic space. With such a novel design, X-Decoder is the first work that provides a unified way to support all types of image segmentation and a variety of vision-language (VL) tasks. Further, our design enables seamless interactions across tasks at different granularities and brings mutual benefits by learning a common and rich pixel-level visual-semantic understanding space, without any pseudo-labeling. After pretraining on a mixed set of a limited amount of segmentation data and millions of image-text pairs, X-Decoder exhibits strong transferability to a wide range of downstream tasks in both zero-shot and finetuning settings. Notably, it achieves (1) state-of-the-art results on open-vocabulary segmentation and referring segmentation on eight datasets; (2) better or competitive finetuned performance to other generalist and specialist models on segmentation and VL tasks; and (3) flexibility for efficient finetuning and novel task composition (e.g., referring captioning and image editing).
|
||||
|
||||
<div align=center>
|
||||
<img src="https://github.com/open-mmlab/mmdetection/assets/17425982/cb126615-9402-4c19-8ea9-133722d7519c" width="70%"/>
|
||||
</div>
|
||||
|
||||
## Usage
|
||||
|
||||
We implement it based on [mmdetection](https://github.com/open-mmlab/mmdetection/), please refer to [mmdetection/projects/XDecoder](https://github.com/open-mmlab/mmdetection/tree/main/projects/XDecoder) for more details.
|
||||
50
Seg_All_In_One_MMSeg/projects/bdd100k_dataset/README.md
Normal file
50
Seg_All_In_One_MMSeg/projects/bdd100k_dataset/README.md
Normal file
@@ -0,0 +1,50 @@
|
||||
# BDD100K Dataset
|
||||
|
||||
Support **`BDD100K Dataset`**
|
||||
|
||||
## Description
|
||||
|
||||
Author: CastleDream
|
||||
|
||||
This project implements **`BDD100K Dataset`**
|
||||
|
||||
### Dataset preparing
|
||||
|
||||
Preparing `BDD100K Dataset` dataset following [BDD100K Dataset Preparing Guide](https://github.com/open-mmlab/mmsegmentation/tree/main/projects/mapillary_dataset/docs/en/user_guides/2_dataset_prepare.md#bdd100k)
|
||||
|
||||
```none
|
||||
mmsegmentation/data
|
||||
└── bdd100k
|
||||
├── images
|
||||
│ └── 10k
|
||||
│ ├── test [2000 entries exceeds filelimit, not opening dir]
|
||||
│ ├── train [7000 entries exceeds filelimit, not opening dir]
|
||||
│ └── val [1000 entries exceeds filelimit, not opening dir]
|
||||
└── labels
|
||||
└── sem_seg
|
||||
├── colormaps
|
||||
│ ├── train [7000 entries exceeds filelimit, not opening dir]
|
||||
│ └── val [1000 entries exceeds filelimit, not opening dir]
|
||||
├── masks
|
||||
│ ├── train [7000 entries exceeds filelimit, not opening dir]
|
||||
│ └── val [1000 entries exceeds filelimit, not opening dir]
|
||||
├── polygons
|
||||
│ ├── sem_seg_train.json
|
||||
│ └── sem_seg_val.json
|
||||
└── rles
|
||||
├── sem_seg_train.json
|
||||
└── sem_seg_val.json
|
||||
```
|
||||
|
||||
### Training commands
|
||||
|
||||
```bash
|
||||
%cd mmsegmentation
|
||||
!python tools/train.py projects/bdd100k_dataset/configs/pspnet_r50-d8_4xb2-80k_bdd100k-512x1024.py\
|
||||
--work-dir your_work_dir
|
||||
```
|
||||
|
||||
## Thanks
|
||||
|
||||
- [\[Datasets\] Add Mapillary Vistas Datasets to MMSeg Core Package. #2576](https://github.com/open-mmlab/mmsegmentation/pull/2576/files)
|
||||
- [\[Feature\] Support CIHP dataset #1493](https://github.com/open-mmlab/mmsegmentation/pull/1493/files)
|
||||
@@ -0,0 +1,70 @@
|
||||
# dataset settings
|
||||
dataset_type = 'BDD100KDataset'
|
||||
data_root = 'data/bdd100k/'
|
||||
|
||||
crop_size = (512, 1024)
|
||||
train_pipeline = [
|
||||
dict(type='LoadImageFromFile'),
|
||||
dict(type='LoadAnnotations'),
|
||||
dict(
|
||||
type='RandomResize',
|
||||
scale=(2048, 1024),
|
||||
ratio_range=(0.5, 2.0),
|
||||
keep_ratio=True),
|
||||
dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
|
||||
dict(type='RandomFlip', prob=0.5),
|
||||
dict(type='PhotoMetricDistortion'),
|
||||
dict(type='PackSegInputs')
|
||||
]
|
||||
test_pipeline = [
|
||||
dict(type='LoadImageFromFile'),
|
||||
dict(type='Resize', scale=(2048, 1024), keep_ratio=True),
|
||||
# add loading annotation after ``Resize`` because ground truth
|
||||
# does not need to do resize data transform
|
||||
dict(type='LoadAnnotations'),
|
||||
dict(type='PackSegInputs')
|
||||
]
|
||||
img_ratios = [0.5, 0.75, 1.0, 1.25, 1.5, 1.75]
|
||||
tta_pipeline = [
|
||||
dict(type='LoadImageFromFile', backend_args=None),
|
||||
dict(
|
||||
type='TestTimeAug',
|
||||
transforms=[
|
||||
[
|
||||
dict(type='Resize', scale_factor=r, keep_ratio=True)
|
||||
for r in img_ratios
|
||||
],
|
||||
[
|
||||
dict(type='RandomFlip', prob=0., direction='horizontal'),
|
||||
dict(type='RandomFlip', prob=1., direction='horizontal')
|
||||
], [dict(type='LoadAnnotations')], [dict(type='PackSegInputs')]
|
||||
])
|
||||
]
|
||||
train_dataloader = dict(
|
||||
batch_size=2,
|
||||
num_workers=2,
|
||||
persistent_workers=True,
|
||||
sampler=dict(type='InfiniteSampler', shuffle=True),
|
||||
dataset=dict(
|
||||
type=dataset_type,
|
||||
data_root=data_root,
|
||||
data_prefix=dict(
|
||||
img_path='images/10k/train',
|
||||
seg_map_path='labels/sem_seg/masks/train'),
|
||||
pipeline=train_pipeline))
|
||||
val_dataloader = dict(
|
||||
batch_size=1,
|
||||
num_workers=4,
|
||||
persistent_workers=True,
|
||||
sampler=dict(type='DefaultSampler', shuffle=False),
|
||||
dataset=dict(
|
||||
type=dataset_type,
|
||||
data_root=data_root,
|
||||
data_prefix=dict(
|
||||
img_path='images/10k/val',
|
||||
seg_map_path='labels/sem_seg/masks/val'),
|
||||
pipeline=test_pipeline))
|
||||
test_dataloader = val_dataloader
|
||||
|
||||
val_evaluator = dict(type='IoUMetric', iou_metrics=['mIoU'])
|
||||
test_evaluator = val_evaluator
|
||||
@@ -0,0 +1,11 @@
|
||||
_base_ = [
|
||||
'../../../configs/_base_/models/pspnet_r50-d8.py',
|
||||
'./_base_/datasets/bdd100k.py',
|
||||
'../../../configs/_base_/default_runtime.py',
|
||||
'../../../configs/_base_/schedules/schedule_80k.py'
|
||||
]
|
||||
custom_imports = dict(
|
||||
imports=['projects.bdd100k_dataset.mmseg.datasets.bdd100k'])
|
||||
crop_size = (512, 1024)
|
||||
data_preprocessor = dict(size=crop_size)
|
||||
model = dict(data_preprocessor=data_preprocessor)
|
||||
@@ -0,0 +1,40 @@
|
||||
## BDD100K
|
||||
|
||||
- You could download BDD100k datasets from [here](https://bdd-data.berkeley.edu/) after registration.
|
||||
|
||||
- You can download images and masks by clicking `10K Images` button and `Segmentation` button.
|
||||
|
||||
- After download, unzip by the following instructions:
|
||||
|
||||
```bash
|
||||
unzip ~/bdd100k_images_10k.zip -d ~/mmsegmentation/data/
|
||||
unzip ~/bdd100k_sem_seg_labels_trainval.zip -d ~/mmsegmentation/data/
|
||||
```
|
||||
|
||||
```none
|
||||
mmsegmentation
|
||||
├── mmseg
|
||||
├── tools
|
||||
├── configs
|
||||
├── data
|
||||
│ ├── bdd100k
|
||||
│ │ ├── images
|
||||
│ │ │ └── 10k
|
||||
| │ │ │ ├── test
|
||||
| │ │ │ ├── train
|
||||
| │ │ │ └── val
|
||||
│ │ └── labels
|
||||
│ │ │ └── sem_seg
|
||||
| │ │ │ ├── colormaps
|
||||
| │ │ │ │ ├──train
|
||||
| │ │ │ │ └──val
|
||||
| │ │ │ ├── masks
|
||||
| │ │ │ │ ├──train
|
||||
| │ │ │ │ └──val
|
||||
| │ │ │ ├── polygons
|
||||
| │ │ │ │ ├──sem_seg_train.json
|
||||
| │ │ │ │ └──sem_seg_val.json
|
||||
| │ │ │ └── rles
|
||||
| │ │ │ │ ├──sem_seg_train.json
|
||||
| │ │ │ │ └──sem_seg_val.json
|
||||
```
|
||||
@@ -0,0 +1,42 @@
|
||||
## BDD100K
|
||||
|
||||
- 可以从[官方网站](https://bdd-data.berkeley.edu/) 下载 BDD100K数据集(语义分割任务主要是10K数据集),按照官网要求注册并登陆后,数据可以在[这里](https://bdd-data.berkeley.edu/portal.html#download)找到。
|
||||
|
||||
- 图像数据对应的名称是是`10K Images`, 语义分割标注对应的名称是`Segmentation`
|
||||
|
||||
- 下载后,可以使用以下代码进行解压
|
||||
|
||||
```bash
|
||||
unzip ~/bdd100k_images_10k.zip -d ~/mmsegmentation/data/
|
||||
unzip ~/bdd100k_sem_seg_labels_trainval.zip -d ~/mmsegmentation/data/
|
||||
```
|
||||
|
||||
就可以得到以下文件结构了:
|
||||
|
||||
```none
|
||||
mmsegmentation
|
||||
├── mmseg
|
||||
├── tools
|
||||
├── configs
|
||||
├── data
|
||||
│ ├── bdd100k
|
||||
│ │ ├── images
|
||||
│ │ │ └── 10k
|
||||
| │ │ │ ├── test
|
||||
| │ │ │ ├── train
|
||||
| │ │ │ └── val
|
||||
│ │ └── labels
|
||||
│ │ │ └── sem_seg
|
||||
| │ │ │ ├── colormaps
|
||||
| │ │ │ │ ├──train
|
||||
| │ │ │ │ └──val
|
||||
| │ │ │ ├── masks
|
||||
| │ │ │ │ ├──train
|
||||
| │ │ │ │ └──val
|
||||
| │ │ │ ├── polygons
|
||||
| │ │ │ │ ├──sem_seg_train.json
|
||||
| │ │ │ │ └──sem_seg_val.json
|
||||
| │ │ │ └── rles
|
||||
| │ │ │ │ ├──sem_seg_train.json
|
||||
| │ │ │ │ └──sem_seg_val.json
|
||||
```
|
||||
@@ -0,0 +1,31 @@
|
||||
# Copyright (c) OpenMMLab. All rights reserved.
|
||||
|
||||
from mmseg.datasets.basesegdataset import BaseSegDataset
|
||||
|
||||
# from mmseg.registry import DATASETS
|
||||
# @DATASETS.register_module()
|
||||
|
||||
|
||||
class BDD100KDataset(BaseSegDataset):
|
||||
METAINFO = dict(
|
||||
classes=('road', 'sidewalk', 'building', 'wall', 'fence', 'pole',
|
||||
'traffic light', 'traffic sign', 'vegetation', 'terrain',
|
||||
'sky', 'person', 'rider', 'car', 'truck', 'bus', 'train',
|
||||
'motorcycle', 'bicycle'),
|
||||
palette=[[128, 64, 128], [244, 35, 232], [70, 70, 70], [102, 102, 156],
|
||||
[190, 153, 153], [153, 153, 153], [250, 170,
|
||||
30], [220, 220, 0],
|
||||
[107, 142, 35], [152, 251, 152], [70, 130, 180],
|
||||
[220, 20, 60], [255, 0, 0], [0, 0, 142], [0, 0, 70],
|
||||
[0, 60, 100], [0, 80, 100], [0, 0, 230], [119, 11, 32]])
|
||||
|
||||
def __init__(self,
|
||||
img_suffix='.jpg',
|
||||
seg_map_suffix='.png',
|
||||
reduce_zero_label=False,
|
||||
**kwargs) -> None:
|
||||
super().__init__(
|
||||
img_suffix=img_suffix,
|
||||
seg_map_suffix=seg_map_suffix,
|
||||
reduce_zero_label=reduce_zero_label,
|
||||
**kwargs)
|
||||
134
Seg_All_In_One_MMSeg/projects/example_project/README.md
Normal file
134
Seg_All_In_One_MMSeg/projects/example_project/README.md
Normal file
@@ -0,0 +1,134 @@
|
||||
# Dummy ResNet Wrapper
|
||||
|
||||
> A README.md template for releasing a project.
|
||||
>
|
||||
> All the fields in this README are **mandatory** for others to understand what you have achieved in this implementation.
|
||||
> Please read our [Projects FAQ](../faq.md) if you still feel unclear about the requirements, or raise an [issue](https://github.com/open-mmlab/mmsegmentation/issues) to us!
|
||||
|
||||
## Description
|
||||
|
||||
> Share any information you would like others to know. For example:
|
||||
>
|
||||
> Author: @xxx.
|
||||
>
|
||||
> This is an implementation of \[XXX\].
|
||||
|
||||
Author: @xxx.
|
||||
|
||||
This project implements a dummy ResNet wrapper, which literally does nothing new but prints "hello world" during initialization.
|
||||
|
||||
## Usage
|
||||
|
||||
> For a typical model, this section should contain the commands for training and testing.
|
||||
> You are also suggested to dump your environment specification to env.yml by `conda env export > env.yml`.
|
||||
|
||||
### Prerequisites
|
||||
|
||||
- Python 3.7
|
||||
- PyTorch 1.6 or higher
|
||||
- [MIM](https://github.com/open-mmlab/mim) v0.33 or higher
|
||||
- [MMSegmentation](https://github.com/open-mmlab/mmsegmentation) v1.0.0rc2 or higher
|
||||
|
||||
All the commands below rely on the correct configuration of `PYTHONPATH`, which should point to the project's directory so that Python can locate the module files. In `example_project/` root directory, run the following line to add the current directory to `PYTHONPATH`:
|
||||
|
||||
```shell
|
||||
export PYTHONPATH=`pwd`:$PYTHONPATH
|
||||
```
|
||||
|
||||
### Training commands
|
||||
|
||||
```shell
|
||||
mim train mmsegmentation configs/fcn_dummy-r50-d8_4xb2-40k_cityscapes-512x1024.py --work-dir work_dirs/dummy_resnet
|
||||
```
|
||||
|
||||
To train on multiple GPUs, e.g. 8 GPUs, run the following command:
|
||||
|
||||
```shell
|
||||
mim train mmsegmentation configs/fcn_dummy-r50-d8_4xb2-40k_cityscapes-512x1024.py --work-dir work_dirs/dummy_resnet --launcher pytorch --gpus 8
|
||||
```
|
||||
|
||||
### Testing commands
|
||||
|
||||
```shell
|
||||
mim test mmsegmentation configs/fcn_dummy-r50-d8_4xb2-40k_cityscapes-512x1024.py --work-dir work_dirs/dummy_resnet --checkpoint ${CHECKPOINT_PATH}
|
||||
```
|
||||
|
||||
> List the results as usually done in other model's README. \[Example\](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/fcn#results-and-models
|
||||
> You should claim whether this is based on the pre-trained weights, which are converted from the official release; or it's a reproduced result obtained from retraining the model in this project
|
||||
|
||||
| Method | Backbone | Crop Size | Lr schd | Mem (GB) | Inf time (fps) | mIoU | mIoU(ms+flip) | config | download |
|
||||
| ------ | -------- | --------- | ------: | -------- | -------------- | ----: | ------------: | ------------------------------------------------------------------ | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| FCN | R-50-D8 | 512x1024 | 40000 | 5.7 | 4.17 | 72.25 | 73.36 | [config](configs/fcn_dummy-r50-d8_4xb2-40k_cityscapes-512x1024.py) | [model](https://download.openmmlab.com/mmsegmentation/v0.5/fcn/fcn_r50-d8_512x1024_40k_cityscapes/fcn_r50-d8_512x1024_40k_cityscapes_20200604_192608-efe53f0d.pth) \| [log](https://download.openmmlab.com/mmsegmentation/v0.5/fcn/fcn_r50-d8_512x1024_40k_cityscapes/fcn_r50-d8_512x1024_40k_cityscapes_20200604_192608.log.json) |
|
||||
|
||||
## Citation
|
||||
|
||||
> You may remove this section if not applicable.
|
||||
|
||||
```bibtex
|
||||
@misc{mmseg2020,
|
||||
title={{MMSegmentation}: OpenMMLab Semantic Segmentation Toolbox and Benchmark},
|
||||
author={MMSegmentation Contributors},
|
||||
howpublished = {\url{https://github.com/open-mmlab/mmsegmentation}},
|
||||
year={2020}
|
||||
}
|
||||
```
|
||||
|
||||
## Checklist
|
||||
|
||||
Here is a checklist illustrating a usual development workflow of a successful project, and also serves as an overview of this project's progress.
|
||||
|
||||
> The PIC (person in charge) or contributors of this project should check all the items that they believe have been finished, which will further be verified by codebase maintainers via a PR.
|
||||
|
||||
> OpenMMLab's maintainer will review the code to ensure the project's quality. Reaching the first milestone means that this project suffices the minimum requirement of being merged into 'projects/'. But this project is only eligible to become a part of the core package upon attaining the last milestone.
|
||||
|
||||
> Note that keeping this section up-to-date is crucial not only for this project's developers but the entire community, since there might be some other contributors joining this project and deciding their starting point from this list. It also helps maintainers accurately estimate time and effort on further code polishing, if needed.
|
||||
|
||||
> A project does not necessarily have to be finished in a single PR, but it's essential for the project to at least reach the first milestone in its very first PR.
|
||||
|
||||
- [ ] Milestone 1: PR-ready, and acceptable to be one of the `projects/`.
|
||||
|
||||
- [ ] Finish the code
|
||||
|
||||
> The code's design shall follow existing interfaces and convention. For example, each model component should be registered into `mmseg.registry.MODELS` and configurable via a config file.
|
||||
|
||||
- [ ] Basic docstrings & proper citation
|
||||
|
||||
> Each major object should contain a docstring, describing its functionality and arguments. If you have adapted the code from other open-source projects, don't forget to cite the source project in docstring and make sure your behavior is not against its license. Typically, we do not accept any code snippet under GPL license. [A Short Guide to Open Source Licenses](https://medium.com/nationwide-technology/a-short-guide-to-open-source-licenses-cf5b1c329edd)
|
||||
|
||||
- [ ] Test-time correctness
|
||||
|
||||
> If you are reproducing the result from a paper, make sure your model's inference-time performance matches that in the original paper. The weights usually could be obtained by simply renaming the keys in the official pre-trained weights. This test could be skipped though, if you are able to prove the training-time correctness and check the second milestone.
|
||||
|
||||
- [ ] A full README
|
||||
|
||||
> As this template does.
|
||||
|
||||
- [ ] Milestone 2: Indicates a successful model implementation.
|
||||
|
||||
- [ ] Training-time correctness
|
||||
|
||||
> If you are reproducing the result from a paper, checking this item means that you should have trained your model from scratch based on the original paper's specification and verified that the final result matches the report within a minor error range.
|
||||
|
||||
- [ ] Milestone 3: Good to be a part of our core package!
|
||||
|
||||
- [ ] Type hints and docstrings
|
||||
|
||||
> Ideally *all* the methods should have [type hints](https://www.pythontutorial.net/python-basics/python-type-hints/) and [docstrings](https://google.github.io/styleguide/pyguide.html#381-docstrings). [Example](https://github.com/open-mmlab/mmsegmentation/blob/main/mmseg/utils/io.py#L9)
|
||||
|
||||
- [ ] Unit tests
|
||||
|
||||
> Unit tests for each module are required. [Example](https://github.com/open-mmlab/mmsegmentation/blob/main/tests/test_utils/test_io.py#L14)
|
||||
|
||||
- [ ] Code polishing
|
||||
|
||||
> Refactor your code according to reviewer's comment.
|
||||
|
||||
- [ ] Metafile.yml
|
||||
|
||||
> It will be parsed by MIM and Inferencer. [Example](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/fcn/fcn.yml)
|
||||
|
||||
- [ ] Move your modules into the core package following the codebase's file hierarchy structure.
|
||||
|
||||
> In particular, you may have to refactor this README into a standard one. [Example](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/fcn/README.md)
|
||||
|
||||
- [ ] Refactor your modules into the core package following the codebase's file hierarchy structure.
|
||||
@@ -0,0 +1,8 @@
|
||||
_base_ = ['mmseg::fcn/fcn_r50-d8_4xb2-40k_cityscapes-512x1024.py']
|
||||
|
||||
custom_imports = dict(imports=['dummy'])
|
||||
|
||||
crop_size = (512, 1024)
|
||||
data_preprocessor = dict(size=crop_size)
|
||||
model = dict(
|
||||
data_preprocessor=data_preprocessor, backbone=dict(type='DummyResNet'))
|
||||
@@ -0,0 +1,3 @@
|
||||
from .dummy_resnet import DummyResNet
|
||||
|
||||
__all__ = ['DummyResNet']
|
||||
@@ -0,0 +1,14 @@
|
||||
from mmseg.models.backbones import ResNetV1c
|
||||
from mmseg.registry import MODELS
|
||||
|
||||
|
||||
@MODELS.register_module()
|
||||
class DummyResNet(ResNetV1c):
|
||||
"""Implements a dummy ResNet wrapper for demonstration purpose.
|
||||
Args:
|
||||
**kwargs: All the arguments are passed to the parent class.
|
||||
"""
|
||||
|
||||
def __init__(self, **kwargs) -> None:
|
||||
print('Hello world!')
|
||||
super().__init__(**kwargs)
|
||||
19
Seg_All_In_One_MMSeg/projects/faq.md
Normal file
19
Seg_All_In_One_MMSeg/projects/faq.md
Normal file
@@ -0,0 +1,19 @@
|
||||
Q1: Why set up `projects/` folder?
|
||||
|
||||
Implementing new models and features into OpenMMLab's algorithm libraries could be troublesome due to the rigorous requirements on code quality, which could hinder the fast iteration of SOTA models and might discourage our members from sharing their latest outcomes here. And that's why we have this `projects/` folder now, where some experimental features, frameworks and models are placed, only needed to satisfy the minimum requirement on the code quality, and can be used as standalone libraries. Users are welcome to use them if they [use MMSegmentation from source](https://mmsegmentation.readthedocs.io/en/latest/get_started.html#best-practices).
|
||||
|
||||
Q2: Why should there be a checklist for a project?
|
||||
|
||||
This checkelist is crucial not only for this project's developers but the entire community, since there might be some other contributors joining this project and deciding their starting point from this list. It also helps maintainers accurately estimate time and effort on further code polishing, if needed.
|
||||
|
||||
Q3: What kind of PR will be merged?
|
||||
|
||||
Reaching the first milestone means that this project suffices the minimum requirement of being merged into 'projects/'. That is, the very first PR of a project must have all the terms in the first milestone checked. We do not have any extra requirements on the project's following PRs, so they can be a minor bug fix or update, and do not have to achieve one milestone at once. But keep in mind that this project is only eligible to become a part of the core package upon attaining the last milestone.
|
||||
|
||||
Q4: Compared to other models in the core packages, why do the model implementations in projects have different training/testing commands?
|
||||
|
||||
Projects are organized independently from the core package, and therefore their modules cannot be directly imported by train.py and test.py. Each model implementation in projects should either use `mim` for training/testing as suggested in the example project or provide a custom train.py/test.py.
|
||||
|
||||
Q5: How to debug a project with a debugger?
|
||||
|
||||
Debugger makes our lives easier, but using it becomes a bit tricky if we have to train/test a model via `mim`. The way to circumvent that is that we can take advantage of relative path to import these modules. Assuming that we are developing a project X and the core modules are placed under `projects/X/modules`, then simply adding `custom_imports = dict(imports='projects.X.modules')` to the config allows us to debug from usual entrypoints (e.g. `tools/train.py`) from the root directory of the algorithm library. Just don't forget to remove 'projects.X' before project publishment.
|
||||
@@ -0,0 +1,67 @@
|
||||
# dataset settings
|
||||
dataset_type = 'GID_Dataset' # 注册的类名
|
||||
data_root = 'data/gid/' # 数据集根目录
|
||||
crop_size = (256, 256) # 图像裁剪大小
|
||||
train_pipeline = [
|
||||
dict(type='LoadImageFromFile'), # 从文件中加载图像
|
||||
dict(type='LoadAnnotations'), # 从文件中加载标注
|
||||
dict(
|
||||
type='RandomResize', # 随机缩放
|
||||
scale=(512, 512), # 缩放尺寸
|
||||
ratio_range=(0.5, 2.0), # 缩放比例范围
|
||||
keep_ratio=True), # 是否保持长宽比
|
||||
dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75), # 随机裁剪
|
||||
dict(type='RandomFlip', prob=0.5), # 随机翻转
|
||||
dict(type='PhotoMetricDistortion'), # 图像增强
|
||||
dict(type='PackSegInputs') # 打包数据
|
||||
]
|
||||
test_pipeline = [
|
||||
dict(type='LoadImageFromFile'), # 从文件中加载图像
|
||||
dict(type='Resize', scale=(256, 256), keep_ratio=True), # 缩放
|
||||
# add loading annotation after ``Resize`` because ground truth
|
||||
# does not need to do resize data transform
|
||||
dict(type='LoadAnnotations'), # 从文件中加载标注
|
||||
dict(type='PackSegInputs') # 打包数据
|
||||
]
|
||||
img_ratios = [0.5, 0.75, 1.0, 1.25, 1.5, 1.75] # 多尺度预测缩放比例
|
||||
tta_pipeline = [ # 多尺度测试
|
||||
dict(type='LoadImageFromFile', file_client_args=dict(backend='disk')),
|
||||
dict(
|
||||
type='TestTimeAug',
|
||||
transforms=[
|
||||
[
|
||||
dict(type='Resize', scale_factor=r, keep_ratio=True)
|
||||
for r in img_ratios
|
||||
],
|
||||
[
|
||||
dict(type='RandomFlip', prob=0., direction='horizontal'),
|
||||
dict(type='RandomFlip', prob=1., direction='horizontal')
|
||||
], [dict(type='LoadAnnotations')], [dict(type='PackSegInputs')]
|
||||
])
|
||||
]
|
||||
train_dataloader = dict( # 训练数据加载器
|
||||
batch_size=2, # 训练时的数据批量大小
|
||||
num_workers=4, # 数据加载线程数
|
||||
persistent_workers=True, # 是否持久化线程
|
||||
sampler=dict(type='InfiniteSampler', shuffle=True), # 无限采样器
|
||||
dataset=dict(
|
||||
type=dataset_type, # 数据集类名
|
||||
data_root=data_root, # 数据集根目录
|
||||
data_prefix=dict(
|
||||
img_path='img_dir/train',
|
||||
seg_map_path='ann_dir/train'), # 训练集图像和标注路径
|
||||
pipeline=train_pipeline))
|
||||
val_dataloader = dict(
|
||||
batch_size=1, # 验证时的数据批量大小
|
||||
num_workers=4, # 数据加载线程数
|
||||
persistent_workers=True,
|
||||
sampler=dict(type='DefaultSampler', shuffle=False),
|
||||
dataset=dict(
|
||||
type=dataset_type,
|
||||
data_root=data_root,
|
||||
data_prefix=dict(img_path='img_dir/val', seg_map_path='ann_dir/val'),
|
||||
pipeline=test_pipeline))
|
||||
test_dataloader = val_dataloader
|
||||
|
||||
val_evaluator = dict(type='IoUMetric', iou_metrics=['mIoU'])
|
||||
test_evaluator = val_evaluator
|
||||
@@ -0,0 +1,15 @@
|
||||
_base_ = [
|
||||
'../../../configs/_base_/models/deeplabv3plus_r50-d8.py',
|
||||
'./_base_/datasets/gid.py', '../../../configs/_base_/default_runtime.py',
|
||||
'../../../configs/_base_/schedules/schedule_240k.py'
|
||||
]
|
||||
custom_imports = dict(imports=['projects.gid_dataset.mmseg.datasets.gid'])
|
||||
|
||||
crop_size = (256, 256)
|
||||
data_preprocessor = dict(size=crop_size)
|
||||
model = dict(
|
||||
data_preprocessor=data_preprocessor,
|
||||
pretrained='open-mmlab://resnet101_v1c',
|
||||
backbone=dict(depth=101),
|
||||
decode_head=dict(num_classes=6),
|
||||
auxiliary_head=dict(num_classes=6))
|
||||
@@ -0,0 +1,55 @@
|
||||
# Copyright (c) OpenMMLab. All rights reserved.
|
||||
from mmseg.datasets.basesegdataset import BaseSegDataset
|
||||
from mmseg.registry import DATASETS
|
||||
|
||||
|
||||
# 注册数据集类
|
||||
@DATASETS.register_module()
|
||||
class GID_Dataset(BaseSegDataset):
|
||||
"""Gaofen Image Dataset (GID)
|
||||
|
||||
Dataset paper link:
|
||||
https://www.sciencedirect.com/science/article/pii/S0034425719303414
|
||||
https://x-ytong.github.io/project/GID.html
|
||||
|
||||
GID 6 classes: others, built-up, farmland, forest, meadow, water
|
||||
|
||||
In this example, select 15 images from GID dataset as training set,
|
||||
and select 5 images as validation set.
|
||||
The selected images are listed as follows:
|
||||
|
||||
GF2_PMS1__L1A0000647767-MSS1
|
||||
GF2_PMS1__L1A0001064454-MSS1
|
||||
GF2_PMS1__L1A0001348919-MSS1
|
||||
GF2_PMS1__L1A0001680851-MSS1
|
||||
GF2_PMS1__L1A0001680853-MSS1
|
||||
GF2_PMS1__L1A0001680857-MSS1
|
||||
GF2_PMS1__L1A0001757429-MSS1
|
||||
GF2_PMS2__L1A0000607681-MSS2
|
||||
GF2_PMS2__L1A0000635115-MSS2
|
||||
GF2_PMS2__L1A0000658637-MSS2
|
||||
GF2_PMS2__L1A0001206072-MSS2
|
||||
GF2_PMS2__L1A0001471436-MSS2
|
||||
GF2_PMS2__L1A0001642620-MSS2
|
||||
GF2_PMS2__L1A0001787089-MSS2
|
||||
GF2_PMS2__L1A0001838560-MSS2
|
||||
|
||||
The ``img_suffix`` is fixed to '.tif' and ``seg_map_suffix`` is
|
||||
fixed to '.tif' for GID.
|
||||
"""
|
||||
METAINFO = dict(
|
||||
classes=('Others', 'Built-up', 'Farmland', 'Forest', 'Meadow',
|
||||
'Water'),
|
||||
palette=[[0, 0, 0], [255, 0, 0], [0, 255, 0], [0, 255, 255],
|
||||
[255, 255, 0], [0, 0, 255]])
|
||||
|
||||
def __init__(self,
|
||||
img_suffix='.png',
|
||||
seg_map_suffix='.png',
|
||||
reduce_zero_label=None,
|
||||
**kwargs) -> None:
|
||||
super().__init__(
|
||||
img_suffix=img_suffix,
|
||||
seg_map_suffix=seg_map_suffix,
|
||||
reduce_zero_label=reduce_zero_label,
|
||||
**kwargs)
|
||||
@@ -0,0 +1,181 @@
|
||||
import argparse
|
||||
import glob
|
||||
import math
|
||||
import os
|
||||
import os.path as osp
|
||||
|
||||
import mmcv
|
||||
import numpy as np
|
||||
from mmengine.utils import ProgressBar, mkdir_or_exist
|
||||
|
||||
|
||||
def parse_args():
|
||||
parser = argparse.ArgumentParser(
|
||||
description='Convert GID dataset to mmsegmentation format')
|
||||
parser.add_argument('dataset_img_path', help='GID images folder path')
|
||||
parser.add_argument('dataset_label_path', help='GID labels folder path')
|
||||
parser.add_argument('--tmp_dir', help='path of the temporary directory')
|
||||
parser.add_argument(
|
||||
'-o', '--out_dir', help='output path', default='data/gid')
|
||||
parser.add_argument(
|
||||
'--clip_size',
|
||||
type=int,
|
||||
help='clipped size of image after preparation',
|
||||
default=256)
|
||||
parser.add_argument(
|
||||
'--stride_size',
|
||||
type=int,
|
||||
help='stride of clipping original images',
|
||||
default=256)
|
||||
args = parser.parse_args()
|
||||
return args
|
||||
|
||||
|
||||
GID_COLORMAP = dict(
|
||||
Background=(0, 0, 0), # 0-背景-黑色
|
||||
Building=(255, 0, 0), # 1-建筑-红色
|
||||
Farmland=(0, 255, 0), # 2-农田-绿色
|
||||
Forest=(0, 0, 255), # 3-森林-蓝色
|
||||
Meadow=(255, 255, 0), # 4-草地-黄色
|
||||
Water=(0, 0, 255) # 5-水-蓝色
|
||||
)
|
||||
palette = list(GID_COLORMAP.values())
|
||||
classes = list(GID_COLORMAP.keys())
|
||||
|
||||
|
||||
# 用列表来存一个 RGB 和一个类别的对应
|
||||
def colormap2label(palette):
|
||||
colormap2label_list = np.zeros(256**3, dtype=np.longlong)
|
||||
for i, colormap in enumerate(palette):
|
||||
colormap2label_list[(colormap[0] * 256 + colormap[1]) * 256 +
|
||||
colormap[2]] = i
|
||||
return colormap2label_list
|
||||
|
||||
|
||||
# 给定那个列表,和vis_png然后生成masks_png
|
||||
def label_indices(RGB_label, colormap2label_list):
|
||||
RGB_label = RGB_label.astype('int32')
|
||||
idx = (RGB_label[:, :, 0] * 256 +
|
||||
RGB_label[:, :, 1]) * 256 + RGB_label[:, :, 2]
|
||||
return colormap2label_list[idx]
|
||||
|
||||
|
||||
def RGB2mask(RGB_label, colormap2label_list):
|
||||
mask_label = label_indices(RGB_label, colormap2label_list)
|
||||
return mask_label
|
||||
|
||||
|
||||
colormap2label_list = colormap2label(palette)
|
||||
|
||||
|
||||
def clip_big_image(image_path, clip_save_dir, args, to_label=False):
|
||||
"""Original image of GID dataset is very large, thus pre-processing of them
|
||||
is adopted.
|
||||
|
||||
Given fixed clip size and stride size to generate
|
||||
clipped image, the intersection of width and height is determined.
|
||||
For example, given one 6800 x 7200 original image, the clip size is
|
||||
256 and stride size is 256, thus it would generate 29 x 27 = 783 images
|
||||
whose size are all 256 x 256.
|
||||
"""
|
||||
|
||||
image = mmcv.imread(image_path, channel_order='rgb')
|
||||
# image = mmcv.bgr2gray(image)
|
||||
|
||||
h, w, c = image.shape
|
||||
clip_size = args.clip_size
|
||||
stride_size = args.stride_size
|
||||
|
||||
num_rows = math.ceil((h - clip_size) / stride_size) if math.ceil(
|
||||
(h - clip_size) /
|
||||
stride_size) * stride_size + clip_size >= h else math.ceil(
|
||||
(h - clip_size) / stride_size) + 1
|
||||
num_cols = math.ceil((w - clip_size) / stride_size) if math.ceil(
|
||||
(w - clip_size) /
|
||||
stride_size) * stride_size + clip_size >= w else math.ceil(
|
||||
(w - clip_size) / stride_size) + 1
|
||||
|
||||
x, y = np.meshgrid(np.arange(num_cols + 1), np.arange(num_rows + 1))
|
||||
xmin = x * clip_size
|
||||
ymin = y * clip_size
|
||||
|
||||
xmin = xmin.ravel()
|
||||
ymin = ymin.ravel()
|
||||
xmin_offset = np.where(xmin + clip_size > w, w - xmin - clip_size,
|
||||
np.zeros_like(xmin))
|
||||
ymin_offset = np.where(ymin + clip_size > h, h - ymin - clip_size,
|
||||
np.zeros_like(ymin))
|
||||
boxes = np.stack([
|
||||
xmin + xmin_offset, ymin + ymin_offset,
|
||||
np.minimum(xmin + clip_size, w),
|
||||
np.minimum(ymin + clip_size, h)
|
||||
],
|
||||
axis=1)
|
||||
|
||||
if to_label:
|
||||
image = RGB2mask(image, colormap2label_list)
|
||||
|
||||
for count, box in enumerate(boxes):
|
||||
start_x, start_y, end_x, end_y = box
|
||||
clipped_image = image[start_y:end_y,
|
||||
start_x:end_x] if to_label else image[
|
||||
start_y:end_y, start_x:end_x, :]
|
||||
img_name = osp.basename(image_path).replace('.tif', '')
|
||||
img_name = img_name.replace('_label', '')
|
||||
if count % 3 == 0:
|
||||
mmcv.imwrite(
|
||||
clipped_image.astype(np.uint8),
|
||||
osp.join(
|
||||
clip_save_dir.replace('train', 'val'),
|
||||
f'{img_name}_{start_x}_{start_y}_{end_x}_{end_y}.png'))
|
||||
else:
|
||||
mmcv.imwrite(
|
||||
clipped_image.astype(np.uint8),
|
||||
osp.join(
|
||||
clip_save_dir,
|
||||
f'{img_name}_{start_x}_{start_y}_{end_x}_{end_y}.png'))
|
||||
count += 1
|
||||
|
||||
|
||||
def main():
|
||||
args = parse_args()
|
||||
"""
|
||||
According to this paper: https://ieeexplore.ieee.org/document/9343296/
|
||||
select 15 images contained in GID, , which cover the whole six
|
||||
categories, to generate train set and validation set.
|
||||
|
||||
"""
|
||||
|
||||
if args.out_dir is None:
|
||||
out_dir = osp.join('data', 'gid')
|
||||
else:
|
||||
out_dir = args.out_dir
|
||||
|
||||
print('Making directories...')
|
||||
mkdir_or_exist(osp.join(out_dir, 'img_dir', 'train'))
|
||||
mkdir_or_exist(osp.join(out_dir, 'img_dir', 'val'))
|
||||
mkdir_or_exist(osp.join(out_dir, 'ann_dir', 'train'))
|
||||
mkdir_or_exist(osp.join(out_dir, 'ann_dir', 'val'))
|
||||
|
||||
src_path_list = glob.glob(os.path.join(args.dataset_img_path, '*.tif'))
|
||||
print(f'Find {len(src_path_list)} pictures')
|
||||
|
||||
prog_bar = ProgressBar(len(src_path_list))
|
||||
|
||||
dst_img_dir = osp.join(out_dir, 'img_dir', 'train')
|
||||
dst_label_dir = osp.join(out_dir, 'ann_dir', 'train')
|
||||
|
||||
for i, img_path in enumerate(src_path_list):
|
||||
label_path = osp.join(
|
||||
args.dataset_label_path,
|
||||
osp.basename(img_path.replace('.tif', '_label.tif')))
|
||||
|
||||
clip_big_image(img_path, dst_img_dir, args, to_label=False)
|
||||
clip_big_image(label_path, dst_label_dir, args, to_label=True)
|
||||
prog_bar.update()
|
||||
|
||||
print('Done!')
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
main()
|
||||
@@ -0,0 +1,75 @@
|
||||
import argparse
|
||||
import os
|
||||
import shutil
|
||||
|
||||
# select 15 images from GID dataset
|
||||
|
||||
img_list = [
|
||||
'GF2_PMS1__L1A0000647767-MSS1.tif', 'GF2_PMS1__L1A0001064454-MSS1.tif',
|
||||
'GF2_PMS1__L1A0001348919-MSS1.tif', 'GF2_PMS1__L1A0001680851-MSS1.tif',
|
||||
'GF2_PMS1__L1A0001680853-MSS1.tif', 'GF2_PMS1__L1A0001680857-MSS1.tif',
|
||||
'GF2_PMS1__L1A0001757429-MSS1.tif', 'GF2_PMS2__L1A0000607681-MSS2.tif',
|
||||
'GF2_PMS2__L1A0000635115-MSS2.tif', 'GF2_PMS2__L1A0000658637-MSS2.tif',
|
||||
'GF2_PMS2__L1A0001206072-MSS2.tif', 'GF2_PMS2__L1A0001471436-MSS2.tif',
|
||||
'GF2_PMS2__L1A0001642620-MSS2.tif', 'GF2_PMS2__L1A0001787089-MSS2.tif',
|
||||
'GF2_PMS2__L1A0001838560-MSS2.tif'
|
||||
]
|
||||
|
||||
labels_list = [
|
||||
'GF2_PMS1__L1A0000647767-MSS1_label.tif',
|
||||
'GF2_PMS1__L1A0001064454-MSS1_label.tif',
|
||||
'GF2_PMS1__L1A0001348919-MSS1_label.tif',
|
||||
'GF2_PMS1__L1A0001680851-MSS1_label.tif',
|
||||
'GF2_PMS1__L1A0001680853-MSS1_label.tif',
|
||||
'GF2_PMS1__L1A0001680857-MSS1_label.tif',
|
||||
'GF2_PMS1__L1A0001757429-MSS1_label.tif',
|
||||
'GF2_PMS2__L1A0000607681-MSS2_label.tif',
|
||||
'GF2_PMS2__L1A0000635115-MSS2_label.tif',
|
||||
'GF2_PMS2__L1A0000658637-MSS2_label.tif',
|
||||
'GF2_PMS2__L1A0001206072-MSS2_label.tif',
|
||||
'GF2_PMS2__L1A0001471436-MSS2_label.tif',
|
||||
'GF2_PMS2__L1A0001642620-MSS2_label.tif',
|
||||
'GF2_PMS2__L1A0001787089-MSS2_label.tif',
|
||||
'GF2_PMS2__L1A0001838560-MSS2_label.tif'
|
||||
]
|
||||
|
||||
|
||||
def parse_args():
|
||||
parser = argparse.ArgumentParser(
|
||||
description='From 150 images of GID dataset to select 15 images')
|
||||
parser.add_argument('dataset_img_dir', help='150 GID images folder path')
|
||||
parser.add_argument('dataset_label_dir', help='150 GID labels folder path')
|
||||
|
||||
parser.add_argument('dest_img_dir', help='15 GID images folder path')
|
||||
parser.add_argument('dest_label_dir', help='15 GID labels folder path')
|
||||
|
||||
args = parser.parse_args()
|
||||
|
||||
return args
|
||||
|
||||
|
||||
def main():
|
||||
"""This script is used to select 15 images from GID dataset, According to
|
||||
paper: https://ieeexplore.ieee.org/document/9343296/"""
|
||||
args = parse_args()
|
||||
|
||||
img_path = args.dataset_img_dir
|
||||
label_path = args.dataset_label_dir
|
||||
|
||||
dest_img_dir = args.dest_img_dir
|
||||
dest_label_dir = args.dest_label_dir
|
||||
|
||||
# copy images of 'img_list' to 'desr_dir'
|
||||
print('Copy images of img_list to desr_dir ing...')
|
||||
for img in img_list:
|
||||
shutil.copy(os.path.join(img_path, img), dest_img_dir)
|
||||
print('Done!')
|
||||
|
||||
print('copy labels of labels_list to desr_dir ing...')
|
||||
for label in labels_list:
|
||||
shutil.copy(os.path.join(label_path, label), dest_label_dir)
|
||||
print('Done!')
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
main()
|
||||
@@ -0,0 +1,53 @@
|
||||
## Gaofen Image Dataset (GID)
|
||||
|
||||
- GID 数据集可在[此处](https://x-ytong.github.io/project/GID.html)进行下载。
|
||||
- GID 数据集包含 150 张 6800x7200 的大尺寸图像,标签为 RGB 标签。
|
||||
- 根据[文献](https://ieeexplore.ieee.org/document/9343296/),此处选择 15 张图像生成训练集和验证集,该 15 张图像包含了所有六类信息。所选的图像名称如下:
|
||||
|
||||
```None
|
||||
GF2_PMS1__L1A0000647767-MSS1
|
||||
GF2_PMS1__L1A0001064454-MSS1
|
||||
GF2_PMS1__L1A0001348919-MSS1
|
||||
GF2_PMS1__L1A0001680851-MSS1
|
||||
GF2_PMS1__L1A0001680853-MSS1
|
||||
GF2_PMS1__L1A0001680857-MSS1
|
||||
GF2_PMS1__L1A0001757429-MSS1
|
||||
GF2_PMS2__L1A0000607681-MSS2
|
||||
GF2_PMS2__L1A0000635115-MSS2
|
||||
GF2_PMS2__L1A0000658637-MSS2
|
||||
GF2_PMS2__L1A0001206072-MSS2
|
||||
GF2_PMS2__L1A0001471436-MSS2
|
||||
GF2_PMS2__L1A0001642620-MSS2
|
||||
GF2_PMS2__L1A0001787089-MSS2
|
||||
GF2_PMS2__L1A0001838560-MSS2
|
||||
```
|
||||
|
||||
这里也提供了一个脚本来方便的筛选出15张图像,
|
||||
|
||||
```
|
||||
python projects/gid_dataset/tools/dataset_converters/gid_select15imgFromAll.py {150 张图像的路径} {150 张标签的路径} {15 张图像的路径} {15 张标签的路径}
|
||||
```
|
||||
|
||||
在选择出 15 张图像后,执行以下命令进行裁切及标签的转换,需要修改为您所存储 15 张图像及标签的路径。
|
||||
|
||||
```
|
||||
python projects/gid_dataset/tools/dataset_converters/gid.py {15 张图像的路径} {15 张标签的路径}
|
||||
```
|
||||
|
||||
完成裁切后的 GID 数据结构如下:
|
||||
|
||||
```none
|
||||
mmsegmentation
|
||||
├── mmseg
|
||||
├── tools
|
||||
├── configs
|
||||
├── data
|
||||
│ ├── gid
|
||||
│ │ ├── ann_dir
|
||||
| │ │ │ ├── train
|
||||
| │ │ │ ├── val
|
||||
│ │ ├── img_dir
|
||||
| │ │ │ ├── train
|
||||
| │ │ │ ├── val
|
||||
|
||||
```
|
||||
34
Seg_All_In_One_MMSeg/projects/hsidrive20_dataset/README.md
Normal file
34
Seg_All_In_One_MMSeg/projects/hsidrive20_dataset/README.md
Normal file
@@ -0,0 +1,34 @@
|
||||
# HSI Drive 2.0 Dataset
|
||||
|
||||
Support **`HSI Drive 2.0 Dataset`**
|
||||
|
||||
## Description
|
||||
|
||||
Author: Jon Gutierrez
|
||||
|
||||
This project implements **`HSI Drive 2.0 Dataset`**
|
||||
|
||||
### Dataset preparing
|
||||
|
||||
Preparing `HSI Drive 2.0 Dataset` dataset following [HSI Drive 2.0 Dataset Preparing Guide](https://github.com/open-mmlab/mmsegmentation/blob/main/docs/en/user_guides/2_dataset_prepare.md#hsi-drive-2.0)
|
||||
|
||||
```none
|
||||
mmsegmentation/data
|
||||
└── HSIDrive20
|
||||
├── images
|
||||
│ |── training []
|
||||
│ |── validation []
|
||||
│ |── test []
|
||||
└── labels
|
||||
│ |── training []
|
||||
│ |── validation []
|
||||
│ |── test []
|
||||
```
|
||||
|
||||
### Training commands
|
||||
|
||||
```bash
|
||||
%cd mmsegmentation
|
||||
!python tools/train.py projects/hsidrive20_dataset/configs/unet-s5-d16_fcn_4xb4-160k_hsidrive-208x400.py\
|
||||
--work-dir your_work_dir
|
||||
```
|
||||
@@ -0,0 +1,50 @@
|
||||
train_pipeline = [
|
||||
dict(type='LoadImageFromFile'),
|
||||
dict(type='LoadAnnotations'),
|
||||
dict(type='PackSegInputs')
|
||||
]
|
||||
test_pipeline = [
|
||||
dict(type='LoadImageFromFile'),
|
||||
dict(type='LoadAnnotations'),
|
||||
dict(type='PackSegInputs')
|
||||
]
|
||||
|
||||
train_dataloader = dict(
|
||||
batch_size=1,
|
||||
num_workers=1,
|
||||
persistent_workers=True,
|
||||
sampler=dict(type='InfiniteSampler', shuffle=True),
|
||||
dataset=dict(
|
||||
type='HSIDrive20',
|
||||
data_root='data/HSIDrive20',
|
||||
data_prefix=dict(
|
||||
img_path='images/training', seg_map_path='annotations/training'),
|
||||
pipeline=train_pipeline))
|
||||
|
||||
val_dataloader = dict(
|
||||
batch_size=1,
|
||||
num_workers=1,
|
||||
persistent_workers=True,
|
||||
sampler=dict(type='DefaultSampler', shuffle=False),
|
||||
dataset=dict(
|
||||
type='HSIDrive20',
|
||||
data_root='data/HSIDrive20',
|
||||
data_prefix=dict(
|
||||
img_path='images/validation',
|
||||
seg_map_path='annotations/validation'),
|
||||
pipeline=test_pipeline))
|
||||
|
||||
test_dataloader = dict(
|
||||
batch_size=1,
|
||||
num_workers=1,
|
||||
persistent_workers=True,
|
||||
sampler=dict(type='DefaultSampler', shuffle=False),
|
||||
dataset=dict(
|
||||
type='HSIDrive20',
|
||||
data_root='data/HSIDrive20',
|
||||
data_prefix=dict(
|
||||
img_path='images/test', seg_map_path='annotations/test'),
|
||||
pipeline=test_pipeline))
|
||||
|
||||
val_evaluator = dict(type='IoUMetric', iou_metrics=['mIoU'], ignore_index=0)
|
||||
test_evaluator = val_evaluator
|
||||
@@ -0,0 +1,58 @@
|
||||
_base_ = [
|
||||
'../../../configs/_base_/models/fcn_unet_s5-d16.py',
|
||||
'./_base_/datasets/hsi_drive.py',
|
||||
'../../../configs/_base_/default_runtime.py',
|
||||
'../../../configs/_base_/schedules/schedule_160k.py'
|
||||
]
|
||||
|
||||
custom_imports = dict(
|
||||
imports=['projects.hsidrive20_dataset.mmseg.datasets.hsi_drive'])
|
||||
|
||||
crop_size = (192, 384)
|
||||
data_preprocessor = dict(
|
||||
type='SegDataPreProcessor',
|
||||
size=crop_size,
|
||||
mean=None,
|
||||
std=None,
|
||||
bgr_to_rgb=None,
|
||||
pad_val=0,
|
||||
seg_pad_val=255)
|
||||
model = dict(
|
||||
data_preprocessor=data_preprocessor,
|
||||
backbone=dict(in_channels=25),
|
||||
decode_head=dict(
|
||||
ignore_index=0,
|
||||
num_classes=11,
|
||||
loss_decode=dict(
|
||||
type='CrossEntropyLoss',
|
||||
use_sigmoid=False,
|
||||
loss_weight=1.0,
|
||||
avg_non_ignore=True)),
|
||||
auxiliary_head=dict(
|
||||
ignore_index=0,
|
||||
num_classes=11,
|
||||
loss_decode=dict(
|
||||
type='CrossEntropyLoss',
|
||||
use_sigmoid=False,
|
||||
loss_weight=1.0,
|
||||
avg_non_ignore=True)),
|
||||
# model training and testing settings
|
||||
train_cfg=dict(),
|
||||
test_cfg=dict(mode='whole'))
|
||||
|
||||
train_pipeline = [
|
||||
dict(type='LoadImageFromFile'),
|
||||
dict(type='LoadAnnotations'),
|
||||
dict(type='RandomCrop', crop_size=crop_size),
|
||||
dict(type='PackSegInputs')
|
||||
]
|
||||
|
||||
test_pipeline = [
|
||||
dict(type='LoadImageFromFile'),
|
||||
dict(type='RandomCrop', crop_size=crop_size),
|
||||
dict(type='LoadAnnotations'),
|
||||
dict(type='PackSegInputs')
|
||||
]
|
||||
|
||||
train_dataloader = dict(dataset=dict(pipeline=train_pipeline))
|
||||
test_dataloader = dict(dataset=dict(pipeline=test_pipeline))
|
||||
@@ -0,0 +1,42 @@
|
||||
## HSI Drive 2.0
|
||||
|
||||
- You could download HSI Drive 2.0 dataset from [here](https://ipaccess.ehu.eus/HSI-Drive/#download) after just sending an email to gded@ehu.eus with the subject "download HSI-Drive". You will receive a password to uncompress the files.
|
||||
|
||||
- After download, unzip by the following instructions:
|
||||
|
||||
```bash
|
||||
7z x -p"password" ./HSI_Drive_v2_0_Phyton.zip
|
||||
|
||||
mv ./HSIDrive20 path_to_mmsegmentation/data
|
||||
mv ./HSI_Drive_v2_0_release_notes_Python_version.md path_to_mmsegmentation/data
|
||||
mv ./image_numbering.pdf path_to_mmsegmentation/data
|
||||
```
|
||||
|
||||
- After unzip, you get
|
||||
|
||||
```none
|
||||
mmsegmentation
|
||||
├── mmseg
|
||||
├── tools
|
||||
├── configs
|
||||
├── data
|
||||
│ ├── HSIDrive20
|
||||
│ │ ├── images
|
||||
│ │ │ ├── training
|
||||
│ │ │ ├── validation
|
||||
│ │ │ ├── test
|
||||
│ │ ├── annotations
|
||||
│ │ │ ├── training
|
||||
│ │ │ ├── validation
|
||||
│ │ │ ├── test
|
||||
│ │ ├── images_MF
|
||||
│ │ │ ├── training
|
||||
│ │ │ ├── validation
|
||||
│ │ │ ├── test
|
||||
│ │ ├── RGB
|
||||
│ │ ├── training_filenames.txt
|
||||
│ │ ├── validation_filenames.txt
|
||||
│ │ ├── test_filenames.txt
|
||||
│ ├── HSI_Drive_v2_0_release_notes_Python_version.md
|
||||
│ ├── image_numbering.pdf
|
||||
```
|
||||
@@ -0,0 +1,42 @@
|
||||
## HSI Drive 2.0
|
||||
|
||||
- 您可以从以下位置下载 HSI Drive 2.0 数据集 [here](https://ipaccess.ehu.eus/HSI-Drive/#download) 刚刚向 gded@ehu.eus 发送主题为“下载 HSI-Drive”的电子邮件后 您将收到解压缩文件的密码.
|
||||
|
||||
- 下载后,按照以下说明解压:
|
||||
|
||||
```bash
|
||||
7z x -p"password" ./HSI_Drive_v2_0_Phyton.zip
|
||||
|
||||
mv ./HSIDrive20 path_to_mmsegmentation/data
|
||||
mv ./HSI_Drive_v2_0_release_notes_Python_version.md path_to_mmsegmentation/data
|
||||
mv ./image_numbering.pdf path_to_mmsegmentation/data
|
||||
```
|
||||
|
||||
- 解压后得到:
|
||||
|
||||
```none
|
||||
mmsegmentation
|
||||
├── mmseg
|
||||
├── tools
|
||||
├── configs
|
||||
├── data
|
||||
│ ├── HSIDrive20
|
||||
│ │ ├── images
|
||||
│ │ │ ├── training
|
||||
│ │ │ ├── validation
|
||||
│ │ │ ├── test
|
||||
│ │ ├── annotations
|
||||
│ │ │ ├── training
|
||||
│ │ │ ├── validation
|
||||
│ │ │ ├── test
|
||||
│ │ ├── images_MF
|
||||
│ │ │ ├── training
|
||||
│ │ │ ├── validation
|
||||
│ │ │ ├── test
|
||||
│ │ ├── RGB
|
||||
│ │ ├── training_filenames.txt
|
||||
│ │ ├── validation_filenames.txt
|
||||
│ │ ├── test_filenames.txt
|
||||
│ ├── HSI_Drive_v2_0_release_notes_Python_version.md
|
||||
│ ├── image_numbering.pdf
|
||||
```
|
||||
@@ -0,0 +1,23 @@
|
||||
# Copyright (c) OpenMMLab. All rights reserved.
|
||||
from mmseg.datasets import BaseSegDataset
|
||||
|
||||
# from mmseg.registry import DATASETS
|
||||
|
||||
classes_exp = ('unlabelled', 'road', 'road marks', 'vegetation',
|
||||
'painted metal', 'sky', 'concrete', 'pedestrian', 'water',
|
||||
'unpainted metal', 'glass')
|
||||
palette_exp = [[0, 0, 0], [77, 77, 77], [255, 255, 255], [0, 255, 0],
|
||||
[255, 0, 0], [0, 0, 255], [102, 51, 0], [255, 255, 0],
|
||||
[0, 207, 250], [255, 166, 0], [0, 204, 204]]
|
||||
|
||||
|
||||
# @DATASETS.register_module()
|
||||
class HSIDrive20Dataset(BaseSegDataset):
|
||||
METAINFO = dict(classes=classes_exp, palette=palette_exp)
|
||||
|
||||
def __init__(self,
|
||||
img_suffix='.npy',
|
||||
seg_map_suffix='.png',
|
||||
**kwargs) -> None:
|
||||
super().__init__(
|
||||
img_suffix=img_suffix, seg_map_suffix=seg_map_suffix, **kwargs)
|
||||
91
Seg_All_In_One_MMSeg/projects/hssn/README.md
Normal file
91
Seg_All_In_One_MMSeg/projects/hssn/README.md
Normal file
@@ -0,0 +1,91 @@
|
||||
# HSSN
|
||||
|
||||
## Description
|
||||
|
||||
Author: AI-Tianlong
|
||||
|
||||
This project implements `Deep Hierarchical Semantic Segmentation` inference on `cityscapes` dataset
|
||||
|
||||
## Usage
|
||||
|
||||
### Prerequisites
|
||||
|
||||
- Python 3.8
|
||||
- PyTorch 1.6 or higher
|
||||
- [MMSegmentation](https://github.com/open-mmlab/mmsegmentation) v1.0.0rc5
|
||||
- mmcv v2.0.0rc4
|
||||
- mmengine >=0.4.0
|
||||
|
||||
### Dataset preparing
|
||||
|
||||
Preparing `cityscapes` dataset following this [Dataset Preparing Guide](https://github.com/open-mmlab/mmsegmentation/blob/master/docs/en/dataset_prepare.md#prepare-datasets)
|
||||
|
||||
### Testing commands
|
||||
|
||||
Please put [`hieraseg_deeplabv3plus_r101-d8_4xb2-80k_cityscapes-512x1024_20230112_125023-bc59a3d1.pth`](https://download.openmmlab.com/mmsegmentation/v0.5/hieraseg/hieraseg_deeplabv3plus_r101-d8_4xb2-80k_cityscapes-512x1024_20230112_125023-bc59a3d1.pth) to `mmsegmentation/checkpoints`
|
||||
|
||||
#### Multi-GPUs Test
|
||||
|
||||
```bash
|
||||
# --tta optional, multi-scale test, need mmengine >=0.4.0
|
||||
bash tools/dist_test.sh [configs] [model weights] [number of gpu] --tta
|
||||
```
|
||||
|
||||
#### Example
|
||||
|
||||
```shell
|
||||
bash tools/dist_test.sh projects/hssn/configs/hssn/hieraseg_deeplabv3plus_r101-d8_4xb2-80l_cityscapes-512x1024.py checkpoints/hieraseg_deeplabv3plus_r101-d8_4xb2-80k_cityscapes-512x1024_20230112_125023-bc59a3d1.pth 2 --tta
|
||||
```
|
||||
|
||||
## Results
|
||||
|
||||
### Cityscapes
|
||||
|
||||
| Method | Backbone | Crop Size | mIoU | mIoU (ms+flip) | config | model |
|
||||
| :--------: | :------: | :-------: | :---: | :------------: | :----------------------------------------------------------------------------------------------------------------------------------------------------------------: | :-----------------------------------------------------------------------------------------------------------------------------------------------------------: |
|
||||
| DeeplabV3+ | R-101-D8 | 512x1024 | 81.61 | 82.71 | [config](https://github.com/open-mmlab/mmsegmentation/tree/main/projects/HieraSeg/configs/hieraseg/hieraseg_deeplabv3plus_r101-d8_4xb2-80l_cityscapes-512x1024.py) | [model](https://download.openmmlab.com/mmsegmentation/v0.5/hieraseg/hieraseg_deeplabv3plus_r101-d8_4xb2-80k_cityscapes-512x1024_20230112_125023-bc59a3d1.pth) |
|
||||
|
||||
<img src="https://user-images.githubusercontent.com/50650583/210488953-e3e35ade-1132-47e1-9dfd-cf12b357ae80.png" width="50%"><img src="https://user-images.githubusercontent.com/50650583/210489746-e35ee229-3234-4292-a649-a8cd85f312ad.png" width="50%">
|
||||
|
||||
## Citation
|
||||
|
||||
This project is modified from [qhanghu/HSSN_pytorch](https://github.com/qhanghu/HSSN_pytorch)
|
||||
|
||||
```bibtex
|
||||
@article{li2022deep,
|
||||
title={Deep Hierarchical Semantic Segmentation},
|
||||
author={Li, Liulei and Zhou, Tianfei and Wang, Wenguan and Li, Jianwu and Yang, Yi},
|
||||
journal={CVPR},
|
||||
year={2022}
|
||||
}
|
||||
```
|
||||
|
||||
## Checklist
|
||||
|
||||
- [x] Milestone 1: PR-ready, and acceptable to be one of the `projects/`.
|
||||
|
||||
- [x] Finish the code
|
||||
|
||||
- [x] Basic docstrings & proper citation
|
||||
|
||||
- [x] Test-time correctness
|
||||
|
||||
- [x] A full README
|
||||
|
||||
- [ ] Milestone 2: Indicates a successful model implementation.
|
||||
|
||||
- [ ] Training-time correctness
|
||||
|
||||
- [ ] Milestone 3: Good to be a part of our core package!
|
||||
|
||||
- [ ] Type hints and docstrings
|
||||
|
||||
- [ ] Unit tests
|
||||
|
||||
- [ ] Code polishing
|
||||
|
||||
- [ ] Metafile.yml
|
||||
|
||||
- [ ] Move your modules into the core package following the codebase's file hierarchy structure.
|
||||
|
||||
- [ ] Refactor your modules into the core package following the codebase's file hierarchy structure.
|
||||
@@ -0,0 +1,67 @@
|
||||
# dataset settings
|
||||
dataset_type = 'CityscapesDataset'
|
||||
data_root = 'data/cityscapes/'
|
||||
crop_size = (512, 1024)
|
||||
train_pipeline = [
|
||||
dict(type='LoadImageFromFile'),
|
||||
dict(type='LoadAnnotations'),
|
||||
dict(
|
||||
type='RandomResize',
|
||||
scale=(2048, 1024),
|
||||
ratio_range=(0.5, 2.0),
|
||||
keep_ratio=True),
|
||||
dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
|
||||
dict(type='RandomFlip', prob=0.5),
|
||||
dict(type='PhotoMetricDistortion'),
|
||||
dict(type='PackSegInputs')
|
||||
]
|
||||
test_pipeline = [
|
||||
dict(type='LoadImageFromFile'),
|
||||
dict(type='Resize', scale=(2048, 1024), keep_ratio=True),
|
||||
# add loading annotation after ``Resize`` because ground truth
|
||||
# does not need to do resize data transform
|
||||
dict(type='LoadAnnotations'),
|
||||
dict(type='PackSegInputs')
|
||||
]
|
||||
img_ratios = [0.5, 0.75, 1.0, 1.25, 1.5, 1.75]
|
||||
tta_pipeline = [
|
||||
dict(type='LoadImageFromFile', file_client_args=dict(backend='disk')),
|
||||
dict(
|
||||
type='TestTimeAug',
|
||||
transforms=[
|
||||
[
|
||||
dict(type='Resize', scale_factor=r, keep_ratio=True)
|
||||
for r in img_ratios
|
||||
],
|
||||
[
|
||||
dict(type='RandomFlip', prob=0., direction='horizontal'),
|
||||
dict(type='RandomFlip', prob=1., direction='horizontal')
|
||||
], [dict(type='LoadAnnotations')], [dict(type='PackSegInputs')]
|
||||
])
|
||||
]
|
||||
train_dataloader = dict(
|
||||
batch_size=2,
|
||||
num_workers=2,
|
||||
persistent_workers=True,
|
||||
sampler=dict(type='InfiniteSampler', shuffle=True),
|
||||
dataset=dict(
|
||||
type=dataset_type,
|
||||
data_root=data_root,
|
||||
data_prefix=dict(
|
||||
img_path='leftImg8bit/train', seg_map_path='gtFine/train'),
|
||||
pipeline=train_pipeline))
|
||||
val_dataloader = dict(
|
||||
batch_size=1,
|
||||
num_workers=4,
|
||||
persistent_workers=True,
|
||||
sampler=dict(type='DefaultSampler', shuffle=False),
|
||||
dataset=dict(
|
||||
type=dataset_type,
|
||||
data_root=data_root,
|
||||
data_prefix=dict(
|
||||
img_path='leftImg8bit/val', seg_map_path='gtFine/val'),
|
||||
pipeline=test_pipeline))
|
||||
test_dataloader = val_dataloader
|
||||
|
||||
val_evaluator = dict(type='IoUMetric', iou_metrics=['mIoU'])
|
||||
test_evaluator = val_evaluator
|
||||
@@ -0,0 +1,15 @@
|
||||
default_scope = 'mmseg'
|
||||
env_cfg = dict(
|
||||
cudnn_benchmark=True,
|
||||
mp_cfg=dict(mp_start_method='fork', opencv_num_threads=0),
|
||||
dist_cfg=dict(backend='nccl'),
|
||||
)
|
||||
vis_backends = [dict(type='LocalVisBackend')]
|
||||
visualizer = dict(
|
||||
type='SegLocalVisualizer', vis_backends=vis_backends, name='visualizer')
|
||||
log_processor = dict(by_epoch=False)
|
||||
log_level = 'INFO'
|
||||
load_from = None
|
||||
resume = False
|
||||
|
||||
tta_model = dict(type='SegTTAModel')
|
||||
@@ -0,0 +1,55 @@
|
||||
# model settings
|
||||
norm_cfg = dict(type='SyncBN', requires_grad=True)
|
||||
data_preprocessor = dict(
|
||||
type='SegDataPreProcessor',
|
||||
mean=[123.675, 116.28, 103.53],
|
||||
std=[58.395, 57.12, 57.375],
|
||||
bgr_to_rgb=True,
|
||||
pad_val=0,
|
||||
seg_pad_val=255)
|
||||
model = dict(
|
||||
type='EncoderDecoder',
|
||||
data_preprocessor=data_preprocessor,
|
||||
pretrained=None,
|
||||
backbone=dict(
|
||||
type='ResNetV1d',
|
||||
depth=50,
|
||||
num_stages=4,
|
||||
out_indices=(0, 1, 2, 3),
|
||||
dilations=(1, 1, 2, 4),
|
||||
strides=(1, 2, 1, 1),
|
||||
norm_cfg=norm_cfg,
|
||||
norm_eval=False,
|
||||
style='pytorch',
|
||||
contract_dilation=True),
|
||||
decode_head=dict(
|
||||
type='DepthwiseSeparableASPPContrastHead',
|
||||
in_channels=2048,
|
||||
in_index=3,
|
||||
channels=512,
|
||||
dilations=(1, 12, 24, 36),
|
||||
c1_in_channels=256,
|
||||
c1_channels=48,
|
||||
dropout_ratio=0.1,
|
||||
num_classes=19,
|
||||
norm_cfg=norm_cfg,
|
||||
align_corners=False,
|
||||
proj='convmlp',
|
||||
loss_decode=dict(
|
||||
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
|
||||
auxiliary_head=dict(
|
||||
type='FCNHead',
|
||||
in_channels=1024,
|
||||
in_index=2,
|
||||
channels=256,
|
||||
num_convs=1,
|
||||
concat_input=False,
|
||||
dropout_ratio=0.1,
|
||||
num_classes=19,
|
||||
norm_cfg=norm_cfg,
|
||||
align_corners=False,
|
||||
loss_decode=dict(
|
||||
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)),
|
||||
# model training and testing settings
|
||||
train_cfg=dict(),
|
||||
test_cfg=dict(mode='whole'))
|
||||
@@ -0,0 +1,24 @@
|
||||
# optimizer
|
||||
optimizer = dict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0005)
|
||||
optim_wrapper = dict(type='OptimWrapper', optimizer=optimizer, clip_grad=None)
|
||||
# learning policy
|
||||
param_scheduler = [
|
||||
dict(
|
||||
type='PolyLR',
|
||||
eta_min=1e-4,
|
||||
power=0.9,
|
||||
begin=0,
|
||||
end=80000,
|
||||
by_epoch=False)
|
||||
]
|
||||
# training schedule for 80k
|
||||
train_cfg = dict(type='IterBasedTrainLoop', max_iters=80000, val_interval=8000)
|
||||
val_cfg = dict(type='ValLoop')
|
||||
test_cfg = dict(type='TestLoop')
|
||||
default_hooks = dict(
|
||||
timer=dict(type='IterTimerHook'),
|
||||
logger=dict(type='LoggerHook', interval=50, log_metric_by_epoch=False),
|
||||
param_scheduler=dict(type='ParamSchedulerHook'),
|
||||
checkpoint=dict(type='CheckpointHook', by_epoch=False, interval=8000),
|
||||
sampler_seed=dict(type='DistSamplerSeedHook'),
|
||||
visualization=dict(type='SegVisualizationHook'))
|
||||
@@ -0,0 +1,21 @@
|
||||
_base_ = [
|
||||
'../_base_/models/deeplabv3plus_r50-d8_vd_contrast.py',
|
||||
'../_base_/datasets/cityscapes.py', '../_base_/default_runtime.py',
|
||||
'../_base_/schedules/schedule_80k.py'
|
||||
]
|
||||
|
||||
custom_imports = dict(imports=[
|
||||
'projects.hssn.decode_head.sep_aspp_contrast_head',
|
||||
'projects.hssn.losses.hiera_triplet_loss_cityscape'
|
||||
])
|
||||
|
||||
model = dict(
|
||||
pretrained=None,
|
||||
backbone=dict(depth=101),
|
||||
decode_head=dict(
|
||||
num_classes=26,
|
||||
loss_decode=dict(
|
||||
type='HieraTripletLossCityscape', num_classes=19,
|
||||
loss_weight=1.0)),
|
||||
auxiliary_head=dict(num_classes=19),
|
||||
test_cfg=dict(mode='whole', is_hiera=True, hiera_num_classes=7))
|
||||
@@ -0,0 +1,4 @@
|
||||
# Copyright (c) OpenMMLab. All rights reserved.
|
||||
from .sep_aspp_contrast_head import DepthwiseSeparableASPPContrastHead
|
||||
|
||||
__all__ = ['DepthwiseSeparableASPPContrastHead']
|
||||
@@ -0,0 +1,193 @@
|
||||
# Copyright (c) OpenMMLab. All rights reserved.
|
||||
from typing import List, Tuple
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
from mmcv.cnn import build_norm_layer
|
||||
from torch import Tensor
|
||||
|
||||
from mmseg.models.decode_heads.sep_aspp_head import DepthwiseSeparableASPPHead
|
||||
from mmseg.models.losses import accuracy
|
||||
from mmseg.models.utils import resize
|
||||
from mmseg.registry import MODELS
|
||||
from mmseg.utils import SampleList
|
||||
|
||||
|
||||
class ProjectionHead(nn.Module):
|
||||
"""ProjectionHead, project feature map to specific channels.
|
||||
|
||||
Args:
|
||||
dim_in (int): Input channels.
|
||||
norm_cfg (dict): config of norm layer.
|
||||
proj_dim (int): Output channels. Default: 256.
|
||||
proj (str): Projection type, 'linear' or 'convmlp'. Default: 'convmlp'
|
||||
"""
|
||||
|
||||
def __init__(self,
|
||||
dim_in: int,
|
||||
norm_cfg: dict,
|
||||
proj_dim: int = 256,
|
||||
proj: str = 'convmlp'):
|
||||
super().__init__()
|
||||
assert proj in ['convmlp', 'linear']
|
||||
if proj == 'linear':
|
||||
self.proj = nn.Conv2d(dim_in, proj_dim, kernel_size=1)
|
||||
elif proj == 'convmlp':
|
||||
self.proj = nn.Sequential(
|
||||
nn.Conv2d(dim_in, dim_in, kernel_size=1),
|
||||
build_norm_layer(norm_cfg, dim_in)[1], nn.ReLU(inplace=True),
|
||||
nn.Conv2d(dim_in, proj_dim, kernel_size=1))
|
||||
|
||||
def forward(self, x):
|
||||
return torch.nn.functional.normalize(self.proj(x), p=2, dim=1)
|
||||
|
||||
|
||||
@MODELS.register_module()
|
||||
class DepthwiseSeparableASPPContrastHead(DepthwiseSeparableASPPHead):
|
||||
"""Deep Hierarchical Semantic Segmentation. This head is the implementation
|
||||
of `<https://arxiv.org/abs/2203.14335>`_.
|
||||
|
||||
Based on Encoder-Decoder with Atrous Separable Convolution for
|
||||
Semantic Image Segmentation.
|
||||
`DeepLabV3+ <https://arxiv.org/abs/1802.02611>`_.
|
||||
|
||||
Args:
|
||||
proj (str): The type of ProjectionHead, 'linear' or 'convmlp',
|
||||
default 'convmlp'
|
||||
"""
|
||||
|
||||
def __init__(self, proj: str = 'convmlp', **kwargs):
|
||||
super().__init__(**kwargs)
|
||||
self.proj_head = ProjectionHead(
|
||||
dim_in=2048, norm_cfg=self.norm_cfg, proj=proj)
|
||||
self.register_buffer('step', torch.zeros(1))
|
||||
|
||||
def forward(self, inputs) -> Tuple[Tensor]:
|
||||
"""Forward function."""
|
||||
output = super().forward(inputs)
|
||||
|
||||
self.step += 1
|
||||
embedding = self.proj_head(inputs[-1])
|
||||
|
||||
return output, embedding
|
||||
|
||||
def predict_by_feat(self, seg_logits: Tuple[Tensor],
|
||||
batch_img_metas: List[dict]) -> Tensor:
|
||||
"""Transform a batch of output seg_logits to the input shape.
|
||||
|
||||
Args:
|
||||
seg_logits (Tensor): The output from decode head forward function.
|
||||
batch_img_metas (list[dict]): Meta information of each image, e.g.,
|
||||
image size, scaling factor, etc.
|
||||
|
||||
Returns:
|
||||
Tensor: Outputs segmentation logits map.
|
||||
"""
|
||||
# HSSN decode_head output is: (out, embedding): tuple
|
||||
# only need 'out' here.
|
||||
if isinstance(seg_logits, tuple):
|
||||
seg_logit = seg_logits[0]
|
||||
|
||||
if seg_logit.size(1) == 26: # For cityscapes dataset,19 + 7
|
||||
hiera_num_classes = 7
|
||||
seg_logit[:, 0:2] += seg_logit[:, -7]
|
||||
seg_logit[:, 2:5] += seg_logit[:, -6]
|
||||
seg_logit[:, 5:8] += seg_logit[:, -5]
|
||||
seg_logit[:, 8:10] += seg_logit[:, -4]
|
||||
seg_logit[:, 10:11] += seg_logit[:, -3]
|
||||
seg_logit[:, 11:13] += seg_logit[:, -2]
|
||||
seg_logit[:, 13:19] += seg_logit[:, -1]
|
||||
|
||||
elif seg_logit.size(1) == 12: # For Pascal_person dataset, 7 + 5
|
||||
hiera_num_classes = 5
|
||||
seg_logit[:, 0:1] = seg_logit[:, 0:1] + \
|
||||
seg_logit[:, 7] + seg_logit[:, 10]
|
||||
seg_logit[:, 1:5] = seg_logit[:, 1:5] + \
|
||||
seg_logit[:, 8] + seg_logit[:, 11]
|
||||
seg_logit[:, 5:7] = seg_logit[:, 5:7] + \
|
||||
seg_logit[:, 9] + seg_logit[:, 11]
|
||||
|
||||
elif seg_logit.size(1) == 25: # For LIP dataset, 20 + 5
|
||||
hiera_num_classes = 5
|
||||
seg_logit[:, 0:1] = seg_logit[:, 0:1] + \
|
||||
seg_logit[:, 20] + seg_logit[:, 23]
|
||||
seg_logit[:, 1:8] = seg_logit[:, 1:8] + \
|
||||
seg_logit[:, 21] + seg_logit[:, 24]
|
||||
seg_logit[:, 10:12] = seg_logit[:, 10:12] + \
|
||||
seg_logit[:, 21] + seg_logit[:, 24]
|
||||
seg_logit[:, 13:16] = seg_logit[:, 13:16] + \
|
||||
seg_logit[:, 21] + seg_logit[:, 24]
|
||||
seg_logit[:, 8:10] = seg_logit[:, 8:10] + \
|
||||
seg_logit[:, 22] + seg_logit[:, 24]
|
||||
seg_logit[:, 12:13] = seg_logit[:, 12:13] + \
|
||||
seg_logit[:, 22] + seg_logit[:, 24]
|
||||
seg_logit[:, 16:20] = seg_logit[:, 16:20] + \
|
||||
seg_logit[:, 22] + seg_logit[:, 24]
|
||||
|
||||
# elif seg_logit.size(1) == 144 # For Mapillary dataset, 124+16+4
|
||||
# unofficial repository not release mapillary until 2023/2/6
|
||||
|
||||
if isinstance(batch_img_metas[0]['img_shape'], torch.Size):
|
||||
# slide inference
|
||||
size = batch_img_metas[0]['img_shape']
|
||||
elif 'pad_shape' in batch_img_metas[0]:
|
||||
size = batch_img_metas[0]['pad_shape'][:2]
|
||||
else:
|
||||
size = batch_img_metas[0]['img_shape']
|
||||
seg_logit = seg_logit[:, :-hiera_num_classes]
|
||||
seg_logit = resize(
|
||||
input=seg_logit,
|
||||
size=size,
|
||||
mode='bilinear',
|
||||
align_corners=self.align_corners)
|
||||
|
||||
return seg_logit
|
||||
|
||||
def loss_by_feat(
|
||||
self,
|
||||
seg_logits: Tuple[Tensor], # (out, embedding)
|
||||
batch_data_samples: SampleList) -> dict:
|
||||
"""Compute segmentation loss. Will fix in future.
|
||||
|
||||
Args:
|
||||
seg_logits (Tuple[Tensor]): The output from decode head
|
||||
forward function.
|
||||
For this decode_head output are (out, embedding): tuple
|
||||
batch_data_samples (List[:obj:`SegDataSample`]): The seg
|
||||
data samples. It usually includes information such
|
||||
as `metainfo` and `gt_sem_seg`.
|
||||
|
||||
Returns:
|
||||
dict[str, Tensor]: a dictionary of loss components
|
||||
"""
|
||||
seg_logit_before = seg_logits[0]
|
||||
embedding = seg_logits[1]
|
||||
seg_label = self._stack_batch_gt(batch_data_samples)
|
||||
|
||||
loss = dict()
|
||||
seg_logit = resize(
|
||||
input=seg_logit_before,
|
||||
size=seg_label.shape[2:],
|
||||
mode='bilinear',
|
||||
align_corners=self.align_corners)
|
||||
if self.sampler is not None:
|
||||
seg_weight = self.sampler.sample(seg_logit, seg_label)
|
||||
else:
|
||||
seg_weight = None
|
||||
seg_label = seg_label.squeeze(1)
|
||||
seg_logit_before = resize(
|
||||
input=seg_logit_before,
|
||||
scale_factor=0.5,
|
||||
mode='bilinear',
|
||||
align_corners=self.align_corners)
|
||||
|
||||
loss['loss_seg'] = self.loss_decode(
|
||||
self.step,
|
||||
embedding,
|
||||
seg_logit_before,
|
||||
seg_logit,
|
||||
seg_label,
|
||||
weight=seg_weight,
|
||||
ignore_index=self.ignore_index)
|
||||
loss['acc_seg'] = accuracy(seg_logit, seg_label)
|
||||
return loss
|
||||
4
Seg_All_In_One_MMSeg/projects/hssn/losses/__init__.py
Normal file
4
Seg_All_In_One_MMSeg/projects/hssn/losses/__init__.py
Normal file
@@ -0,0 +1,4 @@
|
||||
# Copyright (c) OpenMMLab. All rights reserved.
|
||||
from .hiera_triplet_loss_cityscape import HieraTripletLossCityscape
|
||||
|
||||
__all__ = ['HieraTripletLossCityscape']
|
||||
@@ -0,0 +1,218 @@
|
||||
# Copyright (c) OpenMMLab. All rights reserved.
|
||||
import math
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.nn.functional as F
|
||||
|
||||
from mmseg.models.builder import LOSSES
|
||||
from mmseg.models.losses.cross_entropy_loss import CrossEntropyLoss
|
||||
from .tree_triplet_loss import TreeTripletLoss
|
||||
|
||||
hiera_map = [0, 0, 1, 1, 1, 2, 2, 2, 3, 3, 4, 5, 5, 6, 6, 6, 6, 6, 6]
|
||||
hiera_index = [[0, 2], [2, 5], [5, 8], [8, 10], [10, 11], [11, 13], [13, 19]]
|
||||
|
||||
hiera = {
|
||||
'hiera_high': {
|
||||
'flat': [0, 2],
|
||||
'construction': [2, 5],
|
||||
'object': [5, 8],
|
||||
'nature': [8, 10],
|
||||
'sky': [10, 11],
|
||||
'human': [11, 13],
|
||||
'vehicle': [13, 19]
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
def prepare_targets(targets):
|
||||
b, h, w = targets.shape
|
||||
targets_high = torch.ones(
|
||||
(b, h, w), dtype=targets.dtype, device=targets.device) * 255
|
||||
indices_high = []
|
||||
for index, high in enumerate(hiera['hiera_high'].keys()):
|
||||
indices = hiera['hiera_high'][high]
|
||||
for ii in range(indices[0], indices[1]):
|
||||
targets_high[targets == ii] = index
|
||||
indices_high.append(indices)
|
||||
|
||||
return targets, targets_high, indices_high
|
||||
|
||||
|
||||
def losses_hiera(predictions,
|
||||
targets,
|
||||
targets_top,
|
||||
num_classes,
|
||||
indices_high,
|
||||
eps=1e-8):
|
||||
"""Implementation of hiera loss.
|
||||
|
||||
Args:
|
||||
predictions (torch.Tensor): seg logits produced by decode head.
|
||||
targets (torch.Tensor): The learning label of the prediction.
|
||||
targets_top (torch.Tensor): The hierarchy ground truth of the learning
|
||||
label.
|
||||
num_classes (int): Number of categories.
|
||||
indices_high (List[List[int]]): Hierarchy indices of each hierarchy.
|
||||
eps (float):Term added to the Logarithm to improve numerical stability.
|
||||
"""
|
||||
b, _, h, w = predictions.shape
|
||||
predictions = torch.sigmoid(predictions.float())
|
||||
void_indices = (targets == 255)
|
||||
targets[void_indices] = 0
|
||||
targets = F.one_hot(targets, num_classes=num_classes).permute(0, 3, 1, 2)
|
||||
void_indices2 = (targets_top == 255)
|
||||
targets_top[void_indices2] = 0
|
||||
targets_top = F.one_hot(targets_top, num_classes=7).permute(0, 3, 1, 2)
|
||||
|
||||
MCMA = predictions[:, :num_classes, :, :]
|
||||
MCMB = torch.zeros((b, 7, h, w)).to(predictions)
|
||||
for ii in range(7):
|
||||
MCMB[:, ii:ii + 1, :, :] = torch.max(
|
||||
torch.cat([
|
||||
predictions[:, indices_high[ii][0]:indices_high[ii][1], :, :],
|
||||
predictions[:, num_classes + ii:num_classes + ii + 1, :, :]
|
||||
],
|
||||
dim=1), 1, True)[0]
|
||||
|
||||
MCLB = predictions[:, num_classes:num_classes + 7, :, :]
|
||||
MCLA = predictions[:, :num_classes, :, :].clone()
|
||||
for ii in range(7):
|
||||
for jj in range(indices_high[ii][0], indices_high[ii][1]):
|
||||
MCLA[:, jj:jj + 1, :, :] = torch.min(
|
||||
torch.cat([
|
||||
predictions[:, jj:jj + 1, :, :], MCLB[:, ii:ii + 1, :, :]
|
||||
],
|
||||
dim=1), 1, True)[0]
|
||||
|
||||
valid_indices = (~void_indices).unsqueeze(1)
|
||||
num_valid = valid_indices.sum()
|
||||
valid_indices2 = (~void_indices2).unsqueeze(1)
|
||||
num_valid2 = valid_indices2.sum()
|
||||
# channel_num*sum()/one_channel_valid already has a weight
|
||||
loss = (
|
||||
(-targets[:, :num_classes, :, :] * torch.log(MCLA + eps) -
|
||||
(1.0 - targets[:, :num_classes, :, :]) * torch.log(1.0 - MCMA + eps))
|
||||
* valid_indices).sum() / num_valid / num_classes
|
||||
loss += ((-targets_top[:, :, :, :] * torch.log(MCLB + eps) -
|
||||
(1.0 - targets_top[:, :, :, :]) * torch.log(1.0 - MCMB + eps)) *
|
||||
valid_indices2).sum() / num_valid2 / 7
|
||||
|
||||
return 5 * loss
|
||||
|
||||
|
||||
def losses_hiera_focal(predictions,
|
||||
targets,
|
||||
targets_top,
|
||||
num_classes,
|
||||
indices_high,
|
||||
eps=1e-8,
|
||||
gamma=2):
|
||||
"""Implementation of hiera loss.
|
||||
|
||||
Args:
|
||||
predictions (torch.Tensor): seg logits produced by decode head.
|
||||
targets (torch.Tensor): The learning label of the prediction.
|
||||
targets_top (torch.Tensor): The hierarchy ground truth of the learning
|
||||
label.
|
||||
num_classes (int): Number of categories.
|
||||
indices_high (List[List[int]]): Hierarchy indices of each hierarchy.
|
||||
eps (float):Term added to the Logarithm to improve numerical stability.
|
||||
Defaults: 1e-8.
|
||||
gamma (int): The exponent value. Defaults: 2.
|
||||
"""
|
||||
b, _, h, w = predictions.shape
|
||||
predictions = torch.sigmoid(predictions.float())
|
||||
void_indices = (targets == 255)
|
||||
targets[void_indices] = 0
|
||||
targets = F.one_hot(targets, num_classes=num_classes).permute(0, 3, 1, 2)
|
||||
void_indices2 = (targets_top == 255)
|
||||
targets_top[void_indices2] = 0
|
||||
targets_top = F.one_hot(targets_top, num_classes=7).permute(0, 3, 1, 2)
|
||||
|
||||
MCMA = predictions[:, :num_classes, :, :]
|
||||
MCMB = torch.zeros((b, 7, h, w),
|
||||
dtype=predictions.dtype,
|
||||
device=predictions.device)
|
||||
for ii in range(7):
|
||||
MCMB[:, ii:ii + 1, :, :] = torch.max(
|
||||
torch.cat([
|
||||
predictions[:, indices_high[ii][0]:indices_high[ii][1], :, :],
|
||||
predictions[:, num_classes + ii:num_classes + ii + 1, :, :]
|
||||
],
|
||||
dim=1), 1, True)[0]
|
||||
|
||||
MCLB = predictions[:, num_classes:num_classes + 7, :, :]
|
||||
MCLA = predictions[:, :num_classes, :, :].clone()
|
||||
for ii in range(7):
|
||||
for jj in range(indices_high[ii][0], indices_high[ii][1]):
|
||||
MCLA[:, jj:jj + 1, :, :] = torch.min(
|
||||
torch.cat([
|
||||
predictions[:, jj:jj + 1, :, :], MCLB[:, ii:ii + 1, :, :]
|
||||
],
|
||||
dim=1), 1, True)[0]
|
||||
|
||||
valid_indices = (~void_indices).unsqueeze(1)
|
||||
num_valid = valid_indices.sum()
|
||||
valid_indices2 = (~void_indices2).unsqueeze(1)
|
||||
num_valid2 = valid_indices2.sum()
|
||||
# channel_num*sum()/one_channel_valid already has a weight
|
||||
loss = ((-targets[:, :num_classes, :, :] * torch.pow(
|
||||
(1.0 - MCLA), gamma) * torch.log(MCLA + eps) -
|
||||
(1.0 - targets[:, :num_classes, :, :]) * torch.pow(MCMA, gamma) *
|
||||
torch.log(1.0 - MCMA + eps)) *
|
||||
valid_indices).sum() / num_valid / num_classes
|
||||
loss += (
|
||||
(-targets_top[:, :, :, :] * torch.pow(
|
||||
(1.0 - MCLB), gamma) * torch.log(MCLB + eps) -
|
||||
(1.0 - targets_top[:, :, :, :]) * torch.pow(MCMB, gamma) *
|
||||
torch.log(1.0 - MCMB + eps)) * valid_indices2).sum() / num_valid2 / 7
|
||||
|
||||
return 5 * loss
|
||||
|
||||
|
||||
@LOSSES.register_module()
|
||||
class HieraTripletLossCityscape(nn.Module):
|
||||
"""Modified from https://github.com/qhanghu/HSSN_pytorch/blob/main/mmseg/mo
|
||||
dels/losses/hiera_triplet_loss_cityscape.py."""
|
||||
|
||||
def __init__(self, num_classes, use_sigmoid=False, loss_weight=1.0):
|
||||
super().__init__()
|
||||
self.num_classes = num_classes
|
||||
self.loss_weight = loss_weight
|
||||
self.treetripletloss = TreeTripletLoss(num_classes, hiera_map,
|
||||
hiera_index)
|
||||
self.ce = CrossEntropyLoss()
|
||||
|
||||
def forward(self,
|
||||
step,
|
||||
embedding,
|
||||
cls_score_before,
|
||||
cls_score,
|
||||
label,
|
||||
weight=None,
|
||||
**kwargs):
|
||||
targets, targets_top, indices_top = prepare_targets(label)
|
||||
|
||||
loss = losses_hiera(cls_score, targets, targets_top, self.num_classes,
|
||||
indices_top)
|
||||
ce_loss = self.ce(cls_score[:, :-7], label)
|
||||
ce_loss2 = self.ce(cls_score[:, -7:], targets_top)
|
||||
loss = loss + ce_loss + ce_loss2
|
||||
|
||||
loss_triplet, class_count = self.treetripletloss(embedding, label)
|
||||
class_counts = [
|
||||
torch.ones_like(class_count)
|
||||
for _ in range(torch.distributed.get_world_size())
|
||||
]
|
||||
torch.distributed.all_gather(class_counts, class_count, async_op=False)
|
||||
class_counts = torch.cat(class_counts, dim=0)
|
||||
|
||||
if torch.distributed.get_world_size() == torch.nonzero(
|
||||
class_counts, as_tuple=False).size(0):
|
||||
factor = 1 / 4 * (1 + torch.cos(
|
||||
torch.tensor((step.item() - 80000) / 80000 *
|
||||
math.pi))) if step.item() < 80000 else 0.5
|
||||
loss += factor * loss_triplet
|
||||
|
||||
return loss * self.loss_weight
|
||||
@@ -0,0 +1,86 @@
|
||||
# Copyright (c) OpenMMLab. All rights reserved.
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.nn.functional as F
|
||||
|
||||
from mmseg.models.builder import LOSSES
|
||||
|
||||
|
||||
@LOSSES.register_module()
|
||||
class TreeTripletLoss(nn.Module):
|
||||
"""TreeTripletLoss. Modified from https://github.com/qhanghu/HSSN_pytorch/b
|
||||
lob/main/mmseg/models/losses/tree_triplet_loss.py.
|
||||
|
||||
Args:
|
||||
num_classes (int): Number of categories.
|
||||
hiera_map (List[int]): Hierarchy map of each category.
|
||||
hiera_index (List[List[int]]): Hierarchy indices of each hierarchy.
|
||||
ignore_index (int): Specifies a target value that is ignored and
|
||||
does not contribute to the input gradients. Defaults: 255.
|
||||
|
||||
Examples:
|
||||
>>> num_classes = 19
|
||||
>>> hiera_map = [
|
||||
0, 0, 1, 1, 1, 2, 2, 2, 3, 3, 4, 5, 5, 6, 6, 6, 6, 6, 6]
|
||||
>>> hiera_index = [
|
||||
0, 2], [2, 5], [5, 8], [8, 10], [10, 11], [11, 13], [13, 19]]
|
||||
"""
|
||||
|
||||
def __init__(self, num_classes, hiera_map, hiera_index, ignore_index=255):
|
||||
super().__init__()
|
||||
|
||||
self.ignore_label = ignore_index
|
||||
self.num_classes = num_classes
|
||||
self.hiera_map = hiera_map
|
||||
self.hiera_index = hiera_index
|
||||
|
||||
def forward(self, feats: torch.Tensor, labels=None, max_triplet=200):
|
||||
labels = labels.unsqueeze(1).float().clone()
|
||||
labels = torch.nn.functional.interpolate(
|
||||
labels, (feats.shape[2], feats.shape[3]), mode='nearest')
|
||||
labels = labels.squeeze(1).long()
|
||||
assert labels.shape[-1] == feats.shape[-1], '{} {}'.format(
|
||||
labels.shape, feats.shape)
|
||||
|
||||
labels = labels.view(-1)
|
||||
feats = feats.permute(0, 2, 3, 1)
|
||||
feats = feats.contiguous().view(-1, feats.shape[-1])
|
||||
|
||||
triplet_loss = 0
|
||||
exist_classes = torch.unique(labels)
|
||||
exist_classes = [x for x in exist_classes if x != 255]
|
||||
class_count = 0
|
||||
|
||||
for ii in exist_classes:
|
||||
index_range = self.hiera_index[self.hiera_map[ii]]
|
||||
index_anchor = labels == ii
|
||||
index_pos = (labels >= index_range[0]) & (
|
||||
labels < index_range[-1]) & (~index_anchor)
|
||||
index_neg = (labels < index_range[0]) | (labels >= index_range[-1])
|
||||
|
||||
min_size = min(
|
||||
torch.sum(index_anchor), torch.sum(index_pos),
|
||||
torch.sum(index_neg), max_triplet)
|
||||
|
||||
feats_anchor = feats[index_anchor][:min_size]
|
||||
feats_pos = feats[index_pos][:min_size]
|
||||
feats_neg = feats[index_neg][:min_size]
|
||||
|
||||
distance = torch.zeros(min_size, 2).to(feats)
|
||||
distance[:, 0:1] = 1 - (feats_anchor * feats_pos).sum(1, True)
|
||||
distance[:, 1:2] = 1 - (feats_anchor * feats_neg).sum(1, True)
|
||||
|
||||
# margin always 0.1 + (4-2)/4 since the hierarchy is three level
|
||||
# TODO: should include label of pos is the same as anchor
|
||||
margin = 0.6 * torch.ones(min_size).to(feats)
|
||||
|
||||
tl = distance[:, 0] - distance[:, 1] + margin
|
||||
tl = F.relu(tl)
|
||||
|
||||
if tl.size(0) > 0:
|
||||
triplet_loss += tl.mean()
|
||||
class_count += 1
|
||||
if class_count == 0:
|
||||
return None, torch.tensor([0]).to(feats)
|
||||
triplet_loss /= class_count
|
||||
return triplet_loss, torch.tensor([class_count]).to(feats)
|
||||
117
Seg_All_In_One_MMSeg/projects/isnet/README.md
Normal file
117
Seg_All_In_One_MMSeg/projects/isnet/README.md
Normal file
@@ -0,0 +1,117 @@
|
||||
# ISNet
|
||||
|
||||
[ISNet: Integrate Image-Level and Semantic-Level Context for Semantic Segmentation](https://arxiv.org/pdf/2108.12382.pdf)
|
||||
|
||||
## Description
|
||||
|
||||
This is an implementation of [ISNet](https://arxiv.org/pdf/2108.12382.pdf).
|
||||
[Official Repo](https://github.com/SegmentationBLWX/sssegmentation)
|
||||
|
||||
## Usage
|
||||
|
||||
### Prerequisites
|
||||
|
||||
- Python 3.7
|
||||
- PyTorch 1.6 or higher
|
||||
- [MIM](https://github.com/open-mmlab/mim) v0.33 or higher
|
||||
- [MMSegmentation](https://github.com/open-mmlab/mmsegmentation) v1.0.0rc2 or higher
|
||||
|
||||
All the commands below rely on the correct configuration of `PYTHONPATH`, which should point to the project's directory so that Python can locate the module files. In `isnet/` root directory, run the following line to add the current directory to `PYTHONPATH`:
|
||||
|
||||
```shell
|
||||
export PYTHONPATH=`pwd`:$PYTHONPATH
|
||||
```
|
||||
|
||||
### Training commands
|
||||
|
||||
```shell
|
||||
mim train mmsegmentation configs/isnet_r50-d8_8xb2-160k_cityscapes-512x1024.py --work-dir work_dirs/isnet
|
||||
```
|
||||
|
||||
To train on multiple GPUs, e.g. 8 GPUs, run the following command:
|
||||
|
||||
```shell
|
||||
mim train mmsegmentation configs/isnet_r50-d8_8xb2-160k_cityscapes-512x1024.py --work-dir work_dirs/isnet --launcher pytorch --gpus 8
|
||||
```
|
||||
|
||||
### Testing commands
|
||||
|
||||
```shell
|
||||
mim test mmsegmentation configs/isnet_r50-d8_8xb2-160k_cityscapes-512x1024.py --work-dir work_dirs/isnet --checkpoint ${CHECKPOINT_PATH}
|
||||
```
|
||||
|
||||
| Method | Backbone | Crop Size | Lr schd | Mem (GB) | Inf time (fps) | mIoU | mIoU(ms+flip) | config | download |
|
||||
| ------ | -------- | --------- | ------: | -------- | -------------- | ----: | ------------: | --------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------------ |
|
||||
| ISNet | R-50-D8 | 512x1024 | - | - | - | 79.32 | 80.88 | [config](configs/isnet_r50-d8_8xb2-160k_cityscapes-512x1024.py) | [model](https://download.openmmlab.com/mmsegmentation/v0.5/isnet/isnet_r50-d8_cityscapes-512x1024_20230104-a7a8ccf2.pth) |
|
||||
|
||||
## Citation
|
||||
|
||||
```bibtex
|
||||
@article{Jin2021ISNetII,
|
||||
title={ISNet: Integrate Image-Level and Semantic-Level Context for Semantic Segmentation},
|
||||
author={Zhenchao Jin and B. Liu and Qi Chu and Nenghai Yu},
|
||||
journal={2021 IEEE/CVF International Conference on Computer Vision (ICCV)},
|
||||
year={2021},
|
||||
pages={7169-7178}
|
||||
}
|
||||
```
|
||||
|
||||
## Checklist
|
||||
|
||||
The progress of ISNet.
|
||||
|
||||
<!-- The PIC (person in charge) or contributors of this project should check all the items that they believe have been finished, which will further be verified by codebase maintainers via a PR.
|
||||
|
||||
OpenMMLab's maintainer will review the code to ensure the project's quality. Reaching the first milestone means that this project suffices the minimum requirement of being merged into 'projects/'. But this project is only eligible to become a part of the core package upon attaining the last milestone.
|
||||
|
||||
Note that keeping this section up-to-date is crucial not only for this project's developers but the entire community, since there might be some other contributors joining this project and deciding their starting point from this list. It also helps maintainers accurately estimate time and effort on further code polishing, if needed.
|
||||
|
||||
A project does not necessarily have to be finished in a single PR, but it's essential for the project to at least reach the first milestone in its very first PR. -->
|
||||
|
||||
- [x] Milestone 1: PR-ready, and acceptable to be one of the `projects/`.
|
||||
|
||||
- [x] Finish the code
|
||||
|
||||
<!-- The code's design shall follow existing interfaces and convention. For example, each model component should be registered into `mmseg.registry.MODELS` and configurable via a config file. -->
|
||||
|
||||
- [x] Basic docstrings & proper citation
|
||||
|
||||
<!-- Each major object should contain a docstring, describing its functionality and arguments. If you have adapted the code from other open-source projects, don't forget to cite the source project in docstring and make sure your behavior is not against its license. Typically, we do not accept any code snippet under GPL license. [A Short Guide to Open Source Licenses](https://medium.com/nationwide-technology/a-short-guide-to-open-source-licenses-cf5b1c329edd) -->
|
||||
|
||||
- [x] Test-time correctness
|
||||
|
||||
<!-- If you are reproducing the result from a paper, make sure your model's inference-time performance matches that in the original paper. The weights usually could be obtained by simply renaming the keys in the official pre-trained weights. This test could be skipped though, if you are able to prove the training-time correctness and check the second milestone. -->
|
||||
|
||||
- [x] A full README
|
||||
|
||||
<!-- As this template does. -->
|
||||
|
||||
- [ ] Milestone 2: Indicates a successful model implementation.
|
||||
|
||||
- [ ] Training-time correctness
|
||||
|
||||
<!-- If you are reproducing the result from a paper, checking this item means that you should have trained your model from scratch based on the original paper's specification and verified that the final result matches the report within a minor error range. -->
|
||||
|
||||
- [ ] Milestone 3: Good to be a part of our core package!
|
||||
|
||||
- [ ] Type hints and docstrings
|
||||
|
||||
<!-- Ideally *all* the methods should have [type hints](https://www.pythontutorial.net/python-basics/python-type-hints/) and [docstrings](https://google.github.io/styleguide/pyguide.html#381-docstrings). [Example](https://github.com/open-mmlab/mmsegmentation/blob/main/mmseg/utils/io.py#L9) -->
|
||||
|
||||
- [ ] Unit tests
|
||||
|
||||
<!-- Unit tests for each module are required. [Example](https://github.com/open-mmlab/mmsegmentation/blob/main/tests/test_utils/test_io.py#L14) -->
|
||||
|
||||
- [ ] Code polishing
|
||||
|
||||
<!-- Refactor your code according to reviewer's comment. -->
|
||||
|
||||
- [ ] Metafile.yml
|
||||
|
||||
<!-- It will be parsed by MIM and Inferencer. [Example](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/fcn/fcn.yml) -->
|
||||
|
||||
- [ ] Move your modules into the core package following the codebase's file hierarchy structure.
|
||||
|
||||
<!-- In particular, you may have to refactor this README into a standard one. [Example](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/fcn/README.md) -->
|
||||
|
||||
- [ ] Refactor your modules into the core package following the codebase's file hierarchy structure.
|
||||
@@ -0,0 +1,80 @@
|
||||
_base_ = [
|
||||
'../../../configs/_base_/datasets/cityscapes.py',
|
||||
'../../../configs/_base_/default_runtime.py',
|
||||
'../../../configs/_base_/schedules/schedule_80k.py'
|
||||
]
|
||||
|
||||
data_root = '../../data/cityscapes/'
|
||||
train_dataloader = dict(dataset=dict(data_root=data_root))
|
||||
val_dataloader = dict(dataset=dict(data_root=data_root))
|
||||
test_dataloader = dict(dataset=dict(data_root=data_root))
|
||||
|
||||
custom_imports = dict(imports=['projects.isnet.decode_heads'])
|
||||
|
||||
norm_cfg = dict(type='SyncBN', requires_grad=True)
|
||||
data_preprocessor = dict(
|
||||
type='SegDataPreProcessor',
|
||||
mean=[123.675, 116.28, 103.53],
|
||||
std=[58.395, 57.12, 57.375],
|
||||
bgr_to_rgb=True,
|
||||
pad_val=0,
|
||||
seg_pad_val=255)
|
||||
|
||||
model = dict(
|
||||
type='EncoderDecoder',
|
||||
data_preprocessor=data_preprocessor,
|
||||
pretrained='open-mmlab://resnet50_v1c',
|
||||
backbone=dict(
|
||||
type='ResNetV1c',
|
||||
depth=50,
|
||||
num_stages=4,
|
||||
out_indices=(0, 1, 2, 3),
|
||||
dilations=(1, 1, 2, 4),
|
||||
strides=(1, 2, 1, 1),
|
||||
norm_cfg=norm_cfg,
|
||||
norm_eval=False,
|
||||
style='pytorch',
|
||||
contract_dilation=True),
|
||||
decode_head=dict(
|
||||
type='ISNetHead',
|
||||
in_channels=(256, 512, 1024, 2048),
|
||||
input_transform='multiple_select',
|
||||
in_index=(0, 1, 2, 3),
|
||||
channels=512,
|
||||
dropout_ratio=0.1,
|
||||
transform_channels=256,
|
||||
concat_input=True,
|
||||
with_shortcut=False,
|
||||
shortcut_in_channels=256,
|
||||
shortcut_feat_channels=48,
|
||||
num_classes=19,
|
||||
norm_cfg=norm_cfg,
|
||||
align_corners=False,
|
||||
loss_decode=[
|
||||
dict(
|
||||
type='CrossEntropyLoss',
|
||||
use_sigmoid=False,
|
||||
loss_weight=1.0,
|
||||
loss_name='loss_o'),
|
||||
dict(
|
||||
type='CrossEntropyLoss',
|
||||
use_sigmoid=False,
|
||||
loss_weight=0.4,
|
||||
loss_name='loss_d'),
|
||||
]),
|
||||
auxiliary_head=dict(
|
||||
type='FCNHead',
|
||||
in_channels=1024,
|
||||
in_index=2,
|
||||
channels=512,
|
||||
num_convs=1,
|
||||
concat_input=False,
|
||||
dropout_ratio=0.1,
|
||||
num_classes=19,
|
||||
norm_cfg=norm_cfg,
|
||||
align_corners=False,
|
||||
loss_decode=dict(
|
||||
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)),
|
||||
train_cfg=dict(),
|
||||
# test_cfg=dict(mode='slide', crop_size=(769, 769), stride=(513, 513))
|
||||
test_cfg=dict(mode='whole'))
|
||||
@@ -0,0 +1,3 @@
|
||||
from .isnet_head import ISNetHead
|
||||
|
||||
__all__ = ['ISNetHead']
|
||||
337
Seg_All_In_One_MMSeg/projects/isnet/decode_heads/isnet_head.py
Normal file
337
Seg_All_In_One_MMSeg/projects/isnet/decode_heads/isnet_head.py
Normal file
@@ -0,0 +1,337 @@
|
||||
# Copyright (c) OpenMMLab. All rights reserved.
|
||||
from typing import List
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
from mmcv.cnn import ConvModule
|
||||
from torch import Tensor
|
||||
|
||||
from mmseg.models.decode_heads.decode_head import BaseDecodeHead
|
||||
from mmseg.models.losses import accuracy
|
||||
from mmseg.models.utils import SelfAttentionBlock, resize
|
||||
from mmseg.registry import MODELS
|
||||
from mmseg.utils import SampleList
|
||||
|
||||
|
||||
class ImageLevelContext(nn.Module):
|
||||
""" Image-Level Context Module
|
||||
Args:
|
||||
feats_channels (int): Input channels of query/key feature.
|
||||
transform_channels (int): Output channels of key/query transform.
|
||||
concat_input (bool): whether to concat input feature.
|
||||
align_corners (bool): align_corners argument of F.interpolate.
|
||||
conv_cfg (dict|None): Config of conv layers.
|
||||
norm_cfg (dict|None): Config of norm layers.
|
||||
act_cfg (dict): Config of activation layers.
|
||||
"""
|
||||
|
||||
def __init__(self,
|
||||
feats_channels,
|
||||
transform_channels,
|
||||
concat_input=False,
|
||||
align_corners=False,
|
||||
conv_cfg=None,
|
||||
norm_cfg=None,
|
||||
act_cfg=None):
|
||||
super().__init__()
|
||||
self.align_corners = align_corners
|
||||
self.global_avgpool = nn.AdaptiveAvgPool2d((1, 1))
|
||||
self.correlate_net = SelfAttentionBlock(
|
||||
key_in_channels=feats_channels * 2,
|
||||
query_in_channels=feats_channels,
|
||||
channels=transform_channels,
|
||||
out_channels=feats_channels,
|
||||
share_key_query=False,
|
||||
query_downsample=None,
|
||||
key_downsample=None,
|
||||
key_query_num_convs=2,
|
||||
value_out_num_convs=1,
|
||||
key_query_norm=True,
|
||||
value_out_norm=True,
|
||||
matmul_norm=True,
|
||||
with_out=True,
|
||||
conv_cfg=conv_cfg,
|
||||
norm_cfg=norm_cfg,
|
||||
act_cfg=act_cfg,
|
||||
)
|
||||
if concat_input:
|
||||
self.bottleneck = ConvModule(
|
||||
feats_channels * 2,
|
||||
feats_channels,
|
||||
kernel_size=3,
|
||||
stride=1,
|
||||
padding=1,
|
||||
conv_cfg=conv_cfg,
|
||||
norm_cfg=norm_cfg,
|
||||
act_cfg=act_cfg,
|
||||
)
|
||||
|
||||
'''forward'''
|
||||
|
||||
def forward(self, x):
|
||||
x_global = self.global_avgpool(x)
|
||||
x_global = resize(
|
||||
x_global,
|
||||
size=x.shape[2:],
|
||||
mode='bilinear',
|
||||
align_corners=self.align_corners)
|
||||
feats_il = self.correlate_net(x, torch.cat([x_global, x], dim=1))
|
||||
if hasattr(self, 'bottleneck'):
|
||||
feats_il = self.bottleneck(torch.cat([x, feats_il], dim=1))
|
||||
return feats_il
|
||||
|
||||
|
||||
class SemanticLevelContext(nn.Module):
|
||||
""" Semantic-Level Context Module
|
||||
Args:
|
||||
feats_channels (int): Input channels of query/key feature.
|
||||
transform_channels (int): Output channels of key/query transform.
|
||||
concat_input (bool): whether to concat input feature.
|
||||
conv_cfg (dict|None): Config of conv layers.
|
||||
norm_cfg (dict|None): Config of norm layers.
|
||||
act_cfg (dict): Config of activation layers.
|
||||
"""
|
||||
|
||||
def __init__(self,
|
||||
feats_channels,
|
||||
transform_channels,
|
||||
concat_input=False,
|
||||
conv_cfg=None,
|
||||
norm_cfg=None,
|
||||
act_cfg=None):
|
||||
super().__init__()
|
||||
self.correlate_net = SelfAttentionBlock(
|
||||
key_in_channels=feats_channels,
|
||||
query_in_channels=feats_channels,
|
||||
channels=transform_channels,
|
||||
out_channels=feats_channels,
|
||||
share_key_query=False,
|
||||
query_downsample=None,
|
||||
key_downsample=None,
|
||||
key_query_num_convs=2,
|
||||
value_out_num_convs=1,
|
||||
key_query_norm=True,
|
||||
value_out_norm=True,
|
||||
matmul_norm=True,
|
||||
with_out=True,
|
||||
conv_cfg=conv_cfg,
|
||||
norm_cfg=norm_cfg,
|
||||
act_cfg=act_cfg,
|
||||
)
|
||||
if concat_input:
|
||||
self.bottleneck = ConvModule(
|
||||
feats_channels * 2,
|
||||
feats_channels,
|
||||
kernel_size=3,
|
||||
stride=1,
|
||||
padding=1,
|
||||
conv_cfg=conv_cfg,
|
||||
norm_cfg=norm_cfg,
|
||||
act_cfg=act_cfg,
|
||||
)
|
||||
|
||||
'''forward'''
|
||||
|
||||
def forward(self, x, preds, feats_il):
|
||||
inputs = x
|
||||
batch_size, num_channels, h, w = x.size()
|
||||
num_classes = preds.size(1)
|
||||
feats_sl = torch.zeros(batch_size, h * w, num_channels).type_as(x)
|
||||
for batch_idx in range(batch_size):
|
||||
# (C, H, W), (num_classes, H, W) --> (H*W, C), (H*W, num_classes)
|
||||
feats_iter, preds_iter = x[batch_idx], preds[batch_idx]
|
||||
feats_iter, preds_iter = feats_iter.reshape(
|
||||
num_channels, -1), preds_iter.reshape(num_classes, -1)
|
||||
feats_iter, preds_iter = feats_iter.permute(1,
|
||||
0), preds_iter.permute(
|
||||
1, 0)
|
||||
# (H*W, )
|
||||
argmax = preds_iter.argmax(1)
|
||||
for clsid in range(num_classes):
|
||||
mask = (argmax == clsid)
|
||||
if mask.sum() == 0:
|
||||
continue
|
||||
feats_iter_cls = feats_iter[mask]
|
||||
preds_iter_cls = preds_iter[:, clsid][mask]
|
||||
weight = torch.softmax(preds_iter_cls, dim=0)
|
||||
feats_iter_cls = feats_iter_cls * weight.unsqueeze(-1)
|
||||
feats_iter_cls = feats_iter_cls.sum(0)
|
||||
feats_sl[batch_idx][mask] = feats_iter_cls
|
||||
feats_sl = feats_sl.reshape(batch_size, h, w, num_channels)
|
||||
feats_sl = feats_sl.permute(0, 3, 1, 2).contiguous()
|
||||
feats_sl = self.correlate_net(inputs, feats_sl)
|
||||
if hasattr(self, 'bottleneck'):
|
||||
feats_sl = self.bottleneck(torch.cat([feats_il, feats_sl], dim=1))
|
||||
return feats_sl
|
||||
|
||||
|
||||
@MODELS.register_module()
|
||||
class ISNetHead(BaseDecodeHead):
|
||||
"""ISNet: Integrate Image-Level and Semantic-Level
|
||||
Context for Semantic Segmentation
|
||||
|
||||
This head is the implementation of `ISNet`
|
||||
<https://arxiv.org/pdf/2108.12382.pdf>`_.
|
||||
|
||||
Args:
|
||||
transform_channels (int): Output channels of key/query transform.
|
||||
concat_input (bool): whether to concat input feature.
|
||||
with_shortcut (bool): whether to use shortcut connection.
|
||||
shortcut_in_channels (int): Input channels of shortcut.
|
||||
shortcut_feat_channels (int): Output channels of shortcut.
|
||||
dropout_ratio (float): Ratio of dropout.
|
||||
"""
|
||||
|
||||
def __init__(self, transform_channels, concat_input, with_shortcut,
|
||||
shortcut_in_channels, shortcut_feat_channels, dropout_ratio,
|
||||
**kwargs):
|
||||
super().__init__(**kwargs)
|
||||
|
||||
self.in_channels = self.in_channels[-1]
|
||||
|
||||
self.bottleneck = ConvModule(
|
||||
self.in_channels,
|
||||
self.channels,
|
||||
kernel_size=3,
|
||||
stride=1,
|
||||
padding=1,
|
||||
conv_cfg=self.conv_cfg,
|
||||
norm_cfg=self.norm_cfg,
|
||||
act_cfg=self.act_cfg)
|
||||
|
||||
self.ilc_net = ImageLevelContext(
|
||||
feats_channels=self.channels,
|
||||
transform_channels=transform_channels,
|
||||
concat_input=concat_input,
|
||||
norm_cfg=self.norm_cfg,
|
||||
act_cfg=self.act_cfg,
|
||||
align_corners=self.align_corners)
|
||||
self.slc_net = SemanticLevelContext(
|
||||
feats_channels=self.channels,
|
||||
transform_channels=transform_channels,
|
||||
concat_input=concat_input,
|
||||
norm_cfg=self.norm_cfg,
|
||||
act_cfg=self.act_cfg)
|
||||
|
||||
self.decoder_stage1 = nn.Sequential(
|
||||
ConvModule(
|
||||
self.channels,
|
||||
self.channels,
|
||||
kernel_size=1,
|
||||
stride=1,
|
||||
padding=0,
|
||||
conv_cfg=self.conv_cfg,
|
||||
norm_cfg=self.norm_cfg,
|
||||
act_cfg=self.act_cfg),
|
||||
nn.Dropout2d(dropout_ratio),
|
||||
nn.Conv2d(
|
||||
self.channels,
|
||||
self.num_classes,
|
||||
kernel_size=1,
|
||||
stride=1,
|
||||
padding=0,
|
||||
bias=True),
|
||||
)
|
||||
|
||||
if with_shortcut:
|
||||
self.shortcut = ConvModule(
|
||||
shortcut_in_channels,
|
||||
shortcut_feat_channels,
|
||||
kernel_size=1,
|
||||
stride=1,
|
||||
padding=0,
|
||||
conv_cfg=self.conv_cfg,
|
||||
norm_cfg=self.norm_cfg,
|
||||
act_cfg=self.act_cfg)
|
||||
self.decoder_stage2 = nn.Sequential(
|
||||
ConvModule(
|
||||
self.channels + shortcut_feat_channels,
|
||||
self.channels,
|
||||
kernel_size=3,
|
||||
stride=1,
|
||||
padding=1,
|
||||
conv_cfg=self.conv_cfg,
|
||||
norm_cfg=self.norm_cfg,
|
||||
act_cfg=self.act_cfg),
|
||||
nn.Dropout2d(dropout_ratio),
|
||||
nn.Conv2d(
|
||||
self.channels,
|
||||
self.num_classes,
|
||||
kernel_size=1,
|
||||
stride=1,
|
||||
padding=0,
|
||||
bias=True),
|
||||
)
|
||||
else:
|
||||
self.decoder_stage2 = nn.Sequential(
|
||||
nn.Dropout2d(dropout_ratio),
|
||||
nn.Conv2d(
|
||||
self.channels,
|
||||
self.num_classes,
|
||||
kernel_size=1,
|
||||
stride=1,
|
||||
padding=0,
|
||||
bias=True),
|
||||
)
|
||||
|
||||
self.conv_seg = None
|
||||
self.dropout = None
|
||||
|
||||
def forward(self, inputs):
|
||||
x = self._transform_inputs(inputs)
|
||||
feats = self.bottleneck(x[-1])
|
||||
|
||||
feats_il = self.ilc_net(feats)
|
||||
|
||||
preds_stage1 = self.decoder_stage1(feats)
|
||||
preds_stage1 = resize(
|
||||
preds_stage1,
|
||||
size=feats.size()[2:],
|
||||
mode='bilinear',
|
||||
align_corners=self.align_corners)
|
||||
|
||||
feats_sl = self.slc_net(feats, preds_stage1, feats_il)
|
||||
|
||||
if hasattr(self, 'shortcut'):
|
||||
shortcut_out = self.shortcut(x[0])
|
||||
feats_sl = resize(
|
||||
feats_sl,
|
||||
size=shortcut_out.shape[2:],
|
||||
mode='bilinear',
|
||||
align_corners=self.align_corners)
|
||||
feats_sl = torch.cat([feats_sl, shortcut_out], dim=1)
|
||||
preds_stage2 = self.decoder_stage2(feats_sl)
|
||||
|
||||
return preds_stage1, preds_stage2
|
||||
|
||||
def loss_by_feat(self, seg_logits: Tensor,
|
||||
batch_data_samples: SampleList) -> dict:
|
||||
seg_label = self._stack_batch_gt(batch_data_samples)
|
||||
loss = dict()
|
||||
|
||||
if self.sampler is not None:
|
||||
seg_weight = self.sampler.sample(seg_logits[-1], seg_label)
|
||||
else:
|
||||
seg_weight = None
|
||||
seg_label = seg_label.squeeze(1)
|
||||
|
||||
for seg_logit, loss_decode in zip(seg_logits, self.loss_decode):
|
||||
seg_logit = resize(
|
||||
input=seg_logit,
|
||||
size=seg_label.shape[2:],
|
||||
mode='bilinear',
|
||||
align_corners=self.align_corners)
|
||||
loss[loss_decode.name] = loss_decode(
|
||||
seg_logit,
|
||||
seg_label,
|
||||
seg_weight,
|
||||
ignore_index=self.ignore_index)
|
||||
|
||||
loss['acc_seg'] = accuracy(
|
||||
seg_logits[-1], seg_label, ignore_index=self.ignore_index)
|
||||
return loss
|
||||
|
||||
def predict_by_feat(self, seg_logits: Tensor,
|
||||
batch_img_metas: List[dict]) -> Tensor:
|
||||
_, seg_logits_stage2 = seg_logits
|
||||
return super().predict_by_feat(seg_logits_stage2, batch_img_metas)
|
||||
86
Seg_All_In_One_MMSeg/projects/mapillary_dataset/README.md
Normal file
86
Seg_All_In_One_MMSeg/projects/mapillary_dataset/README.md
Normal file
@@ -0,0 +1,86 @@
|
||||
# Mapillary Vistas Dataset
|
||||
|
||||
Support **`Mapillary Vistas Dataset`**
|
||||
|
||||
## Description
|
||||
|
||||
Author: AI-Tianlong
|
||||
|
||||
This project implements **`Mapillary Vistas Dataset`**
|
||||
|
||||
### Dataset preparing
|
||||
|
||||
Preparing `Mapillary Vistas Dataset` dataset following [Mapillary Vistas Dataset Preparing Guide](https://github.com/open-mmlab/mmsegmentation/tree/main/projects/mapillary_dataset/docs/en/user_guides/2_dataset_prepare.md)
|
||||
|
||||
```none
|
||||
mmsegmentation
|
||||
├── mmseg
|
||||
├── tools
|
||||
├── configs
|
||||
├── data
|
||||
│ ├── mapillary
|
||||
│ │ ├── training
|
||||
│ │ │ ├── images
|
||||
│ │ │ ├── v1.2
|
||||
| │ │ │ ├── instances
|
||||
| │ │ │ ├── labels
|
||||
| │ │ │ ├── labels_mask
|
||||
| │ │ │ └── panoptic
|
||||
│ │ │ ├── v2.0
|
||||
| │ │ │ ├── instances
|
||||
| │ │ │ ├── labels
|
||||
| │ │ │ ├── labels_mask
|
||||
| │ │ │ ├── panoptic
|
||||
| │ │ │ └── polygons
|
||||
│ │ ├── validation
|
||||
│ │ │ ├── images
|
||||
│ │ │ ├── v1.2
|
||||
| │ │ │ ├── instances
|
||||
| │ │ │ ├── labels
|
||||
| │ │ │ ├── labels_mask
|
||||
| │ │ │ └── panoptic
|
||||
│ │ │ ├── v2.0
|
||||
| │ │ │ ├── instances
|
||||
| │ │ │ ├── labels
|
||||
| │ │ │ ├── labels_mask
|
||||
| │ │ │ ├── panoptic
|
||||
| │ │ │ └── polygons
|
||||
```
|
||||
|
||||
### Training commands
|
||||
|
||||
```bash
|
||||
# Dataset train commands
|
||||
# at `mmsegmentation` folder
|
||||
bash tools/dist_train.sh projects/mapillary_dataset/configs/deeplabv3plus_r101-d8_4xb2-240k_mapillay_v1-512x1024.py 4
|
||||
```
|
||||
|
||||
## Checklist
|
||||
|
||||
- [x] Milestone 1: PR-ready, and acceptable to be one of the `projects/`.
|
||||
|
||||
- [x] Finish the code
|
||||
|
||||
- [x] Basic docstrings & proper citation
|
||||
|
||||
- [ ] Test-time correctness
|
||||
|
||||
- [x] A full README
|
||||
|
||||
- [x] Milestone 2: Indicates a successful model implementation.
|
||||
|
||||
- [x] Training-time correctness
|
||||
|
||||
- [x] Milestone 3: Good to be a part of our core package!
|
||||
|
||||
- [x] Type hints and docstrings
|
||||
|
||||
- [x] Unit tests
|
||||
|
||||
- [x] Code polishing
|
||||
|
||||
- [x] Metafile.yml
|
||||
|
||||
- [x] Move your modules into the core package following the codebase's file hierarchy structure.
|
||||
|
||||
- [x] Refactor your modules into the core package following the codebase's file hierarchy structure.
|
||||
@@ -0,0 +1,68 @@
|
||||
# dataset settings
|
||||
dataset_type = 'MapillaryDataset_v1'
|
||||
data_root = 'data/mapillary/'
|
||||
crop_size = (512, 1024)
|
||||
train_pipeline = [
|
||||
dict(type='LoadImageFromFile'),
|
||||
dict(type='LoadAnnotations'),
|
||||
dict(
|
||||
type='RandomResize',
|
||||
scale=(2048, 1024),
|
||||
ratio_range=(0.5, 2.0),
|
||||
keep_ratio=True),
|
||||
dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
|
||||
dict(type='RandomFlip', prob=0.5),
|
||||
dict(type='PhotoMetricDistortion'),
|
||||
dict(type='PackSegInputs')
|
||||
]
|
||||
test_pipeline = [
|
||||
dict(type='LoadImageFromFile'),
|
||||
dict(type='Resize', scale=(2048, 1024), keep_ratio=True),
|
||||
# add loading annotation after ``Resize`` because ground truth
|
||||
# does not need to do resize data transform
|
||||
dict(type='LoadAnnotations'),
|
||||
dict(type='PackSegInputs')
|
||||
]
|
||||
img_ratios = [0.5, 0.75, 1.0, 1.25, 1.5, 1.75]
|
||||
tta_pipeline = [
|
||||
dict(type='LoadImageFromFile', file_client_args=dict(backend='disk')),
|
||||
dict(
|
||||
type='TestTimeAug',
|
||||
transforms=[
|
||||
[
|
||||
dict(type='Resize', scale_factor=r, keep_ratio=True)
|
||||
for r in img_ratios
|
||||
],
|
||||
[
|
||||
dict(type='RandomFlip', prob=0., direction='horizontal'),
|
||||
dict(type='RandomFlip', prob=1., direction='horizontal')
|
||||
], [dict(type='LoadAnnotations')], [dict(type='PackSegInputs')]
|
||||
])
|
||||
]
|
||||
train_dataloader = dict(
|
||||
batch_size=2,
|
||||
num_workers=4,
|
||||
persistent_workers=True,
|
||||
sampler=dict(type='InfiniteSampler', shuffle=True),
|
||||
dataset=dict(
|
||||
type=dataset_type,
|
||||
data_root=data_root,
|
||||
data_prefix=dict(
|
||||
img_path='training/images', seg_map_path='training/v1.2/labels'),
|
||||
pipeline=train_pipeline))
|
||||
val_dataloader = dict(
|
||||
batch_size=1,
|
||||
num_workers=4,
|
||||
persistent_workers=True,
|
||||
sampler=dict(type='DefaultSampler', shuffle=False),
|
||||
dataset=dict(
|
||||
type=dataset_type,
|
||||
data_root=data_root,
|
||||
data_prefix=dict(
|
||||
img_path='validation/images',
|
||||
seg_map_path='validation/v1.2/labels'),
|
||||
pipeline=test_pipeline))
|
||||
test_dataloader = val_dataloader
|
||||
|
||||
val_evaluator = dict(type='IoUMetric', iou_metrics=['mIoU'])
|
||||
test_evaluator = val_evaluator
|
||||
@@ -0,0 +1,37 @@
|
||||
# dataset settings
|
||||
_base_ = './mapillary_v1.py'
|
||||
metainfo = dict(
|
||||
classes=('Bird', 'Ground Animal', 'Curb', 'Fence', 'Guard Rail', 'Barrier',
|
||||
'Wall', 'Bike Lane', 'Crosswalk - Plain', 'Curb Cut', 'Parking',
|
||||
'Pedestrian Area', 'Rail Track', 'Road', 'Service Lane',
|
||||
'Sidewalk', 'Bridge', 'Building', 'Tunnel', 'Person', 'Bicyclist',
|
||||
'Motorcyclist', 'Other Rider', 'Lane Marking - Crosswalk',
|
||||
'Lane Marking - General', 'Mountain', 'Sand', 'Sky', 'Snow',
|
||||
'Terrain', 'Vegetation', 'Water', 'Banner', 'Bench', 'Bike Rack',
|
||||
'Billboard', 'Catch Basin', 'CCTV Camera', 'Fire Hydrant',
|
||||
'Junction Box', 'Mailbox', 'Manhole', 'Phone Booth', 'Pothole',
|
||||
'Street Light', 'Pole', 'Traffic Sign Frame', 'Utility Pole',
|
||||
'Traffic Light', 'Traffic Sign (Back)', 'Traffic Sign (Front)',
|
||||
'Trash Can', 'Bicycle', 'Boat', 'Bus', 'Car', 'Caravan',
|
||||
'Motorcycle', 'On Rails', 'Other Vehicle', 'Trailer', 'Truck',
|
||||
'Wheeled Slow', 'Car Mount', 'Ego Vehicle'),
|
||||
palette=[[165, 42, 42], [0, 192, 0], [196, 196, 196], [190, 153, 153],
|
||||
[180, 165, 180], [90, 120, 150], [102, 102, 156], [128, 64, 255],
|
||||
[140, 140, 200], [170, 170, 170], [250, 170, 160], [96, 96, 96],
|
||||
[230, 150, 140], [128, 64, 128], [110, 110, 110], [244, 35, 232],
|
||||
[150, 100, 100], [70, 70, 70], [150, 120, 90], [220, 20, 60],
|
||||
[255, 0, 0], [255, 0, 100], [255, 0, 200], [200, 128, 128],
|
||||
[255, 255, 255], [64, 170, 64], [230, 160, 50], [70, 130, 180],
|
||||
[190, 255, 255], [152, 251, 152], [107, 142, 35], [0, 170, 30],
|
||||
[255, 255, 128], [250, 0, 30], [100, 140, 180], [220, 220, 220],
|
||||
[220, 128, 128], [222, 40, 40], [100, 170, 30], [40, 40, 40],
|
||||
[33, 33, 33], [100, 128, 160], [142, 0, 0], [70, 100, 150],
|
||||
[210, 170, 100], [153, 153, 153], [128, 128, 128], [0, 0, 80],
|
||||
[250, 170, 30], [192, 192, 192], [220, 220, 0], [140, 140, 20],
|
||||
[119, 11, 32], [150, 0, 255], [0, 60, 100], [0, 0, 142],
|
||||
[0, 0, 90], [0, 0, 230], [0, 80, 100], [128, 64, 64], [0, 0, 110],
|
||||
[0, 0, 70], [0, 0, 192], [32, 32, 32], [120, 10, 10]])
|
||||
|
||||
train_dataloader = dict(dataset=dict(metainfo=metainfo))
|
||||
val_dataloader = dict(dataset=dict(metainfo=metainfo))
|
||||
test_dataloader = val_dataloader
|
||||
@@ -0,0 +1,68 @@
|
||||
# dataset settings
|
||||
dataset_type = 'MapillaryDataset_v2'
|
||||
data_root = 'data/mapillary/'
|
||||
crop_size = (512, 1024)
|
||||
train_pipeline = [
|
||||
dict(type='LoadImageFromFile'),
|
||||
dict(type='LoadAnnotations'),
|
||||
dict(
|
||||
type='RandomResize',
|
||||
scale=(2048, 1024),
|
||||
ratio_range=(0.5, 2.0),
|
||||
keep_ratio=True),
|
||||
dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
|
||||
dict(type='RandomFlip', prob=0.5),
|
||||
dict(type='PhotoMetricDistortion'),
|
||||
dict(type='PackSegInputs')
|
||||
]
|
||||
test_pipeline = [
|
||||
dict(type='LoadImageFromFile'),
|
||||
dict(type='Resize', scale=(2048, 1024), keep_ratio=True),
|
||||
# add loading annotation after ``Resize`` because ground truth
|
||||
# does not need to do resize data transform
|
||||
dict(type='LoadAnnotations'),
|
||||
dict(type='PackSegInputs')
|
||||
]
|
||||
img_ratios = [0.5, 0.75, 1.0, 1.25, 1.5, 1.75]
|
||||
tta_pipeline = [
|
||||
dict(type='LoadImageFromFile', file_client_args=dict(backend='disk')),
|
||||
dict(
|
||||
type='TestTimeAug',
|
||||
transforms=[
|
||||
[
|
||||
dict(type='Resize', scale_factor=r, keep_ratio=True)
|
||||
for r in img_ratios
|
||||
],
|
||||
[
|
||||
dict(type='RandomFlip', prob=0., direction='horizontal'),
|
||||
dict(type='RandomFlip', prob=1., direction='horizontal')
|
||||
], [dict(type='LoadAnnotations')], [dict(type='PackSegInputs')]
|
||||
])
|
||||
]
|
||||
train_dataloader = dict(
|
||||
batch_size=2,
|
||||
num_workers=4,
|
||||
persistent_workers=True,
|
||||
sampler=dict(type='InfiniteSampler', shuffle=True),
|
||||
dataset=dict(
|
||||
type=dataset_type,
|
||||
data_root=data_root,
|
||||
data_prefix=dict(
|
||||
img_path='training/images', seg_map_path='training/v2.0/labels'),
|
||||
pipeline=train_pipeline))
|
||||
val_dataloader = dict(
|
||||
batch_size=1,
|
||||
num_workers=4,
|
||||
persistent_workers=True,
|
||||
sampler=dict(type='DefaultSampler', shuffle=False),
|
||||
dataset=dict(
|
||||
type=dataset_type,
|
||||
data_root=data_root,
|
||||
data_prefix=dict(
|
||||
img_path='validation/images',
|
||||
seg_map_path='validation/v2.0/labels'),
|
||||
pipeline=test_pipeline))
|
||||
test_dataloader = val_dataloader
|
||||
|
||||
val_evaluator = dict(type='IoUMetric', iou_metrics=['mIoU'])
|
||||
test_evaluator = val_evaluator
|
||||
@@ -0,0 +1,17 @@
|
||||
_base_ = [
|
||||
'../../../configs/_base_/models/deeplabv3plus_r50-d8.py',
|
||||
'./_base_/datasets/mapillary_v1.py',
|
||||
'../../../configs/_base_/default_runtime.py',
|
||||
'../../../configs/_base_/schedules/schedule_240k.py'
|
||||
]
|
||||
custom_imports = dict(
|
||||
imports=['projects.mapillary_dataset.mmseg.datasets.mapillary'])
|
||||
|
||||
crop_size = (512, 1024)
|
||||
data_preprocessor = dict(size=crop_size)
|
||||
model = dict(
|
||||
data_preprocessor=data_preprocessor,
|
||||
pretrained='open-mmlab://resnet101_v1c',
|
||||
backbone=dict(depth=101),
|
||||
decode_head=dict(num_classes=66),
|
||||
auxiliary_head=dict(num_classes=66))
|
||||
@@ -0,0 +1,16 @@
|
||||
_base_ = [
|
||||
'../../../configs/_base_/models/deeplabv3plus_r50-d8.py',
|
||||
'./_base_/datasets/mapillary_v2.py',
|
||||
'../../../configs/_base_/default_runtime.py',
|
||||
'../../../configs/_base_/schedules/schedule_240k.py'
|
||||
]
|
||||
custom_imports = dict(
|
||||
imports=['projects.mapillary_dataset.mmseg.datasets.mapillary'])
|
||||
crop_size = (512, 1024)
|
||||
data_preprocessor = dict(size=crop_size)
|
||||
model = dict(
|
||||
data_preprocessor=data_preprocessor,
|
||||
pretrained='open-mmlab://resnet101_v1c',
|
||||
backbone=dict(depth=101),
|
||||
decode_head=dict(num_classes=124),
|
||||
auxiliary_head=dict(num_classes=124))
|
||||
@@ -0,0 +1,16 @@
|
||||
_base_ = [
|
||||
'../../../configs/_base_/models/pspnet_r50-d8.py',
|
||||
'./_base_/datasets/mapillary_v1.py',
|
||||
'../../../configs/_base_/default_runtime.py',
|
||||
'../../../configs/_base_/schedules/schedule_240k.py'
|
||||
]
|
||||
custom_imports = dict(
|
||||
imports=['projects.mapillary_dataset.mmseg.datasets.mapillary'])
|
||||
crop_size = (512, 1024)
|
||||
data_preprocessor = dict(size=crop_size)
|
||||
model = dict(
|
||||
data_preprocessor=data_preprocessor,
|
||||
pretrained='open-mmlab://resnet101_v1c',
|
||||
backbone=dict(depth=101),
|
||||
decode_head=dict(num_classes=66),
|
||||
auxiliary_head=dict(num_classes=66))
|
||||
@@ -0,0 +1,16 @@
|
||||
_base_ = [
|
||||
'../../../configs/_base_/models/pspnet_r50-d8.py',
|
||||
'./_base_/datasets/mapillary_v2.py',
|
||||
'../../../configs/_base_/default_runtime.py',
|
||||
'../../../configs/_base_/schedules/schedule_240k.py'
|
||||
]
|
||||
custom_imports = dict(
|
||||
imports=['projects.mapillary_dataset.mmseg.datasets.mapillary'])
|
||||
crop_size = (512, 1024)
|
||||
data_preprocessor = dict(size=crop_size)
|
||||
model = dict(
|
||||
data_preprocessor=data_preprocessor,
|
||||
pretrained='open-mmlab://resnet101_v1c',
|
||||
backbone=dict(depth=101),
|
||||
decode_head=dict(num_classes=124),
|
||||
auxiliary_head=dict(num_classes=124))
|
||||
@@ -0,0 +1,255 @@
|
||||
## Mapillary Vistas Datasets
|
||||
|
||||
- The dataset could be download [here](https://www.mapillary.com/dataset/vistas) after registration.
|
||||
|
||||
- Mapillary Vistas Dataset use 8-bit with color-palette to store labels. No conversion operation is required.
|
||||
|
||||
- Assumption you have put the dataset zip file in `mmsegmentation/data/mapillary`
|
||||
|
||||
- Please run the following commands to unzip dataset.
|
||||
|
||||
```bash
|
||||
cd data/mapillary
|
||||
unzip An-ZjB1Zm61yAZG0ozTymz8I8NqI4x0MrYrh26dq7kPgfu8vf9ImrdaOAVOFYbJ2pNAgUnVGBmbue9lTgdBOb5BbKXIpFs0fpYWqACbrQDChAA2fdX0zS9PcHu7fY8c-FOvyBVxPNYNFQuM.zip
|
||||
```
|
||||
|
||||
- After unzip, you will get Mapillary Vistas Dataset like this structure. Semantic segmentation mask labels in `labels` folder.
|
||||
|
||||
```none
|
||||
mmsegmentation
|
||||
├── mmseg
|
||||
├── tools
|
||||
├── configs
|
||||
├── data
|
||||
│ ├── mapillary
|
||||
│ │ ├── training
|
||||
│ │ │ ├── images
|
||||
│ │ │ ├── v1.2
|
||||
| │ │ │ ├── instances
|
||||
| │ │ │ ├── labels
|
||||
| │ │ │ └── panoptic
|
||||
│ │ │ ├── v2.0
|
||||
| │ │ │ ├── instances
|
||||
| │ │ │ ├── labels
|
||||
| │ │ │ ├── panoptic
|
||||
| │ │ │ └── polygons
|
||||
│ │ ├── validation
|
||||
│ │ │ ├── images
|
||||
| │ │ ├── v1.2
|
||||
| │ │ │ ├── instances
|
||||
| │ │ │ ├── labels
|
||||
| │ │ │ └── panoptic
|
||||
│ │ │ ├── v2.0
|
||||
| │ │ │ ├── instances
|
||||
| │ │ │ ├── labels
|
||||
| │ │ │ ├── panoptic
|
||||
| │ │ │ └── polygons
|
||||
```
|
||||
|
||||
- You could set Datasets version with `MapillaryDataset_v1` and `MapillaryDataset_v2` in your configs.
|
||||
View the Mapillary Vistas Datasets config file here [V1.2](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/_base_/datasets/mapillary_v1.py) and [V2.0](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/_base_/datasets/mapillary_v2.py)
|
||||
|
||||
- **View datasets labels index and palette**
|
||||
|
||||
- **Mapillary Vistas Datasets labels information**
|
||||
**v1.2 information**
|
||||
|
||||
```none
|
||||
There are 66 labels classes in v1.2
|
||||
0--Bird--[165, 42, 42],
|
||||
1--Ground Animal--[0, 192, 0],
|
||||
2--Curb--[196, 196, 196],
|
||||
3--Fence--[190, 153, 153],
|
||||
4--Guard Rail--[180, 165, 180],
|
||||
5--Barrier--[90, 120, 150],
|
||||
6--Wall--[102, 102, 156],
|
||||
7--Bike Lane--[128, 64, 255],
|
||||
8--Crosswalk - Plain--[140, 140, 200],
|
||||
9--Curb Cut--[170, 170, 170],
|
||||
10--Parking--[250, 170, 160],
|
||||
11--Pedestrian Area--[96, 96, 96],
|
||||
12--Rail Track--[230, 150, 140],
|
||||
13--Road--[128, 64, 128],
|
||||
14--Service Lane--[110, 110, 110],
|
||||
15--Sidewalk--[244, 35, 232],
|
||||
16--Bridge--[150, 100, 100],
|
||||
17--Building--[70, 70, 70],
|
||||
18--Tunnel--[150, 120, 90],
|
||||
19--Person--[220, 20, 60],
|
||||
20--Bicyclist--[255, 0, 0],
|
||||
21--Motorcyclist--[255, 0, 100],
|
||||
22--Other Rider--[255, 0, 200],
|
||||
23--Lane Marking - Crosswalk--[200, 128, 128],
|
||||
24--Lane Marking - General--[255, 255, 255],
|
||||
25--Mountain--[64, 170, 64],
|
||||
26--Sand--[230, 160, 50],
|
||||
27--Sky--[70, 130, 180],
|
||||
28--Snow--[190, 255, 255],
|
||||
29--Terrain--[152, 251, 152],
|
||||
30--Vegetation--[107, 142, 35],
|
||||
31--Water--[0, 170, 30],
|
||||
32--Banner--[255, 255, 128],
|
||||
33--Bench--[250, 0, 30],
|
||||
34--Bike Rack--[100, 140, 180],
|
||||
35--Billboard--[220, 220, 220],
|
||||
36--Catch Basin--[220, 128, 128],
|
||||
37--CCTV Camera--[222, 40, 40],
|
||||
38--Fire Hydrant--[100, 170, 30],
|
||||
39--Junction Box--[40, 40, 40],
|
||||
40--Mailbox--[33, 33, 33],
|
||||
41--Manhole--[100, 128, 160],
|
||||
42--Phone Booth--[142, 0, 0],
|
||||
43--Pothole--[70, 100, 150],
|
||||
44--Street Light--[210, 170, 100],
|
||||
45--Pole--[153, 153, 153],
|
||||
46--Traffic Sign Frame--[128, 128, 128],
|
||||
47--Utility Pole--[0, 0, 80],
|
||||
48--Traffic Light--[250, 170, 30],
|
||||
49--Traffic Sign (Back)--[192, 192, 192],
|
||||
50--Traffic Sign (Front)--[220, 220, 0],
|
||||
51--Trash Can--[140, 140, 20],
|
||||
52--Bicycle--[119, 11, 32],
|
||||
53--Boat--[150, 0, 255],
|
||||
54--Bus--[0, 60, 100],
|
||||
55--Car--[0, 0, 142],
|
||||
56--Caravan--[0, 0, 90],
|
||||
57--Motorcycle--[0, 0, 230],
|
||||
58--On Rails--[0, 80, 100],
|
||||
59--Other Vehicle--[128, 64, 64],
|
||||
60--Trailer--[0, 0, 110],
|
||||
61--Truck--[0, 0, 70],
|
||||
62--Wheeled Slow--[0, 0, 192],
|
||||
63--Car Mount--[32, 32, 32],
|
||||
64--Ego Vehicle--[120, 10, 10],
|
||||
65--Unlabeled--[0, 0, 0]
|
||||
```
|
||||
|
||||
**v2.0 information**
|
||||
|
||||
```none
|
||||
There are 124 labels classes in v2.0
|
||||
0--Bird--[165, 42, 42],
|
||||
1--Ground Animal--[0, 192, 0],
|
||||
2--Ambiguous Barrier--[250, 170, 31],
|
||||
3--Concrete Block--[250, 170, 32],
|
||||
4--Curb--[196, 196, 196],
|
||||
5--Fence--[190, 153, 153],
|
||||
6--Guard Rail--[180, 165, 180],
|
||||
7--Barrier--[90, 120, 150],
|
||||
8--Road Median--[250, 170, 33],
|
||||
9--Road Side--[250, 170, 34],
|
||||
10--Lane Separator--[128, 128, 128],
|
||||
11--Temporary Barrier--[250, 170, 35],
|
||||
12--Wall--[102, 102, 156],
|
||||
13--Bike Lane--[128, 64, 255],
|
||||
14--Crosswalk - Plain--[140, 140, 200],
|
||||
15--Curb Cut--[170, 170, 170],
|
||||
16--Driveway--[250, 170, 36],
|
||||
17--Parking--[250, 170, 160],
|
||||
18--Parking Aisle--[250, 170, 37],
|
||||
19--Pedestrian Area--[96, 96, 96],
|
||||
20--Rail Track--[230, 150, 140],
|
||||
21--Road--[128, 64, 128],
|
||||
22--Road Shoulder--[110, 110, 110],
|
||||
23--Service Lane--[110, 110, 110],
|
||||
24--Sidewalk--[244, 35, 232],
|
||||
25--Traffic Island--[128, 196, 128],
|
||||
26--Bridge--[150, 100, 100],
|
||||
27--Building--[70, 70, 70],
|
||||
28--Garage--[150, 150, 150],
|
||||
29--Tunnel--[150, 120, 90],
|
||||
30--Person--[220, 20, 60],
|
||||
31--Person Group--[220, 20, 60],
|
||||
32--Bicyclist--[255, 0, 0],
|
||||
33--Motorcyclist--[255, 0, 100],
|
||||
34--Other Rider--[255, 0, 200],
|
||||
35--Lane Marking - Dashed Line--[255, 255, 255],
|
||||
36--Lane Marking - Straight Line--[255, 255, 255],
|
||||
37--Lane Marking - Zigzag Line--[250, 170, 29],
|
||||
38--Lane Marking - Ambiguous--[250, 170, 28],
|
||||
39--Lane Marking - Arrow (Left)--[250, 170, 26],
|
||||
40--Lane Marking - Arrow (Other)--[250, 170, 25],
|
||||
41--Lane Marking - Arrow (Right)--[250, 170, 24],
|
||||
42--Lane Marking - Arrow (Split Left or Straight)--[250, 170, 22],
|
||||
43--Lane Marking - Arrow (Split Right or Straight)--[250, 170, 21],
|
||||
44--Lane Marking - Arrow (Straight)--[250, 170, 20],
|
||||
45--Lane Marking - Crosswalk--[255, 255, 255],
|
||||
46--Lane Marking - Give Way (Row)--[250, 170, 19],
|
||||
47--Lane Marking - Give Way (Single)--[250, 170, 18],
|
||||
48--Lane Marking - Hatched (Chevron)--[250, 170, 12],
|
||||
49--Lane Marking - Hatched (Diagonal)--[250, 170, 11],
|
||||
50--Lane Marking - Other--[255, 255, 255],
|
||||
51--Lane Marking - Stop Line--[255, 255, 255],
|
||||
52--Lane Marking - Symbol (Bicycle)--[250, 170, 16],
|
||||
53--Lane Marking - Symbol (Other)--[250, 170, 15],
|
||||
54--Lane Marking - Text--[250, 170, 15],
|
||||
55--Lane Marking (only) - Dashed Line--[255, 255, 255],
|
||||
56--Lane Marking (only) - Crosswalk--[255, 255, 255],
|
||||
57--Lane Marking (only) - Other--[255, 255, 255],
|
||||
58--Lane Marking (only) - Test--[255, 255, 255],
|
||||
59--Mountain--[64, 170, 64],
|
||||
60--Sand--[230, 160, 50],
|
||||
61--Sky--[70, 130, 180],
|
||||
62--Snow--[190, 255, 255],
|
||||
63--Terrain--[152, 251, 152],
|
||||
64--Vegetation--[107, 142, 35],
|
||||
65--Water--[0, 170, 30],
|
||||
66--Banner--[255, 255, 128],
|
||||
67--Bench--[250, 0, 30],
|
||||
68--Bike Rack--[100, 140, 180],
|
||||
69--Catch Basin--[220, 128, 128],
|
||||
70--CCTV Camera--[222, 40, 40],
|
||||
71--Fire Hydrant--[100, 170, 30],
|
||||
72--Junction Box--[40, 40, 40],
|
||||
73--Mailbox--[33, 33, 33],
|
||||
74--Manhole--[100, 128, 160],
|
||||
75--Parking Meter--[20, 20, 255],
|
||||
76--Phone Booth--[142, 0, 0],
|
||||
77--Pothole--[70, 100, 150],
|
||||
78--Signage - Advertisement--[250, 171, 30],
|
||||
79--Signage - Ambiguous--[250, 172, 30],
|
||||
80--Signage - Back--[250, 173, 30],
|
||||
81--Signage - Information--[250, 174, 30],
|
||||
82--Signage - Other--[250, 175, 30],
|
||||
83--Signage - Store--[250, 176, 30],
|
||||
84--Street Light--[210, 170, 100],
|
||||
85--Pole--[153, 153, 153],
|
||||
86--Pole Group--[153, 153, 153],
|
||||
87--Traffic Sign Frame--[128, 128, 128],
|
||||
88--Utility Pole--[0, 0, 80],
|
||||
89--Traffic Cone--[210, 60, 60],
|
||||
90--Traffic Light - General (Single)--[250, 170, 30],
|
||||
91--Traffic Light - Pedestrians--[250, 170, 30],
|
||||
92--Traffic Light - General (Upright)--[250, 170, 30],
|
||||
93--Traffic Light - General (Horizontal)--[250, 170, 30],
|
||||
94--Traffic Light - Cyclists--[250, 170, 30],
|
||||
95--Traffic Light - Other--[250, 170, 30],
|
||||
96--Traffic Sign - Ambiguous--[192, 192, 192],
|
||||
97--Traffic Sign (Back)--[192, 192, 192],
|
||||
98--Traffic Sign - Direction (Back)--[192, 192, 192],
|
||||
99--Traffic Sign - Direction (Front)--[220, 220, 0],
|
||||
100--Traffic Sign (Front)--[220, 220, 0],
|
||||
101--Traffic Sign - Parking--[0, 0, 196],
|
||||
102--Traffic Sign - Temporary (Back)--[192, 192, 192],
|
||||
103--Traffic Sign - Temporary (Front)--[220, 220, 0],
|
||||
104--Trash Can--[140, 140, 20],
|
||||
105--Bicycle--[119, 11, 32],
|
||||
106--Boat--[150, 0, 255],
|
||||
107--Bus--[0, 60, 100],
|
||||
108--Car--[0, 0, 142],
|
||||
109--Caravan--[0, 0, 90],
|
||||
110--Motorcycle--[0, 0, 230],
|
||||
111--On Rails--[0, 80, 100],
|
||||
112--Other Vehicle--[128, 64, 64],
|
||||
113--Trailer--[0, 0, 110],
|
||||
114--Truck--[0, 0, 70],
|
||||
115--Vehicle Group--[0, 0, 142],
|
||||
116--Wheeled Slow--[0, 0, 192],
|
||||
117--Water Valve--[170, 170, 170],
|
||||
118--Car Mount--[32, 32, 32],
|
||||
119--Dynamic--[111, 74, 0],
|
||||
120--Ego Vehicle--[120, 10, 10],
|
||||
121--Ground--[81, 0, 81],
|
||||
122--Static--[111, 111, 0],
|
||||
123--Unlabeled--[0, 0, 0]
|
||||
```
|
||||
@@ -0,0 +1,177 @@
|
||||
# Copyright (c) OpenMMLab. All rights reserved.
|
||||
from mmseg.datasets.basesegdataset import BaseSegDataset
|
||||
|
||||
# from mmseg.registry import DATASETS
|
||||
|
||||
|
||||
# @DATASETS.register_module()
|
||||
class MapillaryDataset_v1(BaseSegDataset):
|
||||
"""Mapillary Vistas Dataset.
|
||||
|
||||
Dataset paper link:
|
||||
http://ieeexplore.ieee.org/document/8237796/
|
||||
|
||||
v1.2 contain 66 object classes.
|
||||
(37 instance-specific)
|
||||
|
||||
v2.0 contain 124 object classes.
|
||||
(70 instance-specific, 46 stuff, 8 void or crowd).
|
||||
|
||||
The ``img_suffix`` is fixed to '.jpg' and ``seg_map_suffix`` is
|
||||
fixed to '.png' for Mapillary Vistas Dataset.
|
||||
"""
|
||||
METAINFO = dict(
|
||||
classes=('Bird', 'Ground Animal', 'Curb', 'Fence', 'Guard Rail',
|
||||
'Barrier', 'Wall', 'Bike Lane', 'Crosswalk - Plain',
|
||||
'Curb Cut', 'Parking', 'Pedestrian Area', 'Rail Track',
|
||||
'Road', 'Service Lane', 'Sidewalk', 'Bridge', 'Building',
|
||||
'Tunnel', 'Person', 'Bicyclist', 'Motorcyclist',
|
||||
'Other Rider', 'Lane Marking - Crosswalk',
|
||||
'Lane Marking - General', 'Mountain', 'Sand', 'Sky', 'Snow',
|
||||
'Terrain', 'Vegetation', 'Water', 'Banner', 'Bench',
|
||||
'Bike Rack', 'Billboard', 'Catch Basin', 'CCTV Camera',
|
||||
'Fire Hydrant', 'Junction Box', 'Mailbox', 'Manhole',
|
||||
'Phone Booth', 'Pothole', 'Street Light', 'Pole',
|
||||
'Traffic Sign Frame', 'Utility Pole', 'Traffic Light',
|
||||
'Traffic Sign (Back)', 'Traffic Sign (Front)', 'Trash Can',
|
||||
'Bicycle', 'Boat', 'Bus', 'Car', 'Caravan', 'Motorcycle',
|
||||
'On Rails', 'Other Vehicle', 'Trailer', 'Truck',
|
||||
'Wheeled Slow', 'Car Mount', 'Ego Vehicle', 'Unlabeled'),
|
||||
palette=[[165, 42, 42], [0, 192, 0], [196, 196, 196], [190, 153, 153],
|
||||
[180, 165, 180], [90, 120, 150], [102, 102, 156],
|
||||
[128, 64, 255], [140, 140, 200], [170, 170, 170],
|
||||
[250, 170, 160], [96, 96, 96],
|
||||
[230, 150, 140], [128, 64, 128], [110, 110, 110],
|
||||
[244, 35, 232], [150, 100, 100], [70, 70, 70], [150, 120, 90],
|
||||
[220, 20, 60], [255, 0, 0], [255, 0, 100], [255, 0, 200],
|
||||
[200, 128, 128], [255, 255, 255], [64, 170,
|
||||
64], [230, 160, 50],
|
||||
[70, 130, 180], [190, 255, 255], [152, 251, 152],
|
||||
[107, 142, 35], [0, 170, 30], [255, 255, 128], [250, 0, 30],
|
||||
[100, 140, 180], [220, 220, 220], [220, 128, 128],
|
||||
[222, 40, 40], [100, 170, 30], [40, 40, 40], [33, 33, 33],
|
||||
[100, 128, 160], [142, 0, 0], [70, 100, 150], [210, 170, 100],
|
||||
[153, 153, 153], [128, 128, 128], [0, 0, 80], [250, 170, 30],
|
||||
[192, 192, 192], [220, 220, 0], [140, 140, 20], [119, 11, 32],
|
||||
[150, 0, 255], [0, 60, 100], [0, 0, 142], [0, 0, 90],
|
||||
[0, 0, 230], [0, 80, 100], [128, 64, 64], [0, 0, 110],
|
||||
[0, 0, 70], [0, 0, 192], [32, 32, 32], [120, 10,
|
||||
10], [0, 0, 0]])
|
||||
|
||||
def __init__(self,
|
||||
img_suffix='.jpg',
|
||||
seg_map_suffix='.png',
|
||||
**kwargs) -> None:
|
||||
super().__init__(
|
||||
img_suffix=img_suffix, seg_map_suffix=seg_map_suffix, **kwargs)
|
||||
|
||||
|
||||
# @DATASETS.register_module()
|
||||
class MapillaryDataset_v2(BaseSegDataset):
|
||||
"""Mapillary Vistas Dataset.
|
||||
|
||||
Dataset paper link:
|
||||
http://ieeexplore.ieee.org/document/8237796/
|
||||
|
||||
v1.2 contain 66 object classes.
|
||||
(37 instance-specific)
|
||||
|
||||
v2.0 contain 124 object classes.
|
||||
(70 instance-specific, 46 stuff, 8 void or crowd).
|
||||
|
||||
The ``img_suffix`` is fixed to '.jpg' and ``seg_map_suffix`` is
|
||||
fixed to '.png' for Mapillary Vistas Dataset.
|
||||
"""
|
||||
METAINFO = dict(
|
||||
classes=(
|
||||
'Bird', 'Ground Animal', 'Ambiguous Barrier', 'Concrete Block',
|
||||
'Curb', 'Fence', 'Guard Rail', 'Barrier', 'Road Median',
|
||||
'Road Side', 'Lane Separator', 'Temporary Barrier', 'Wall',
|
||||
'Bike Lane', 'Crosswalk - Plain', 'Curb Cut', 'Driveway',
|
||||
'Parking', 'Parking Aisle', 'Pedestrian Area', 'Rail Track',
|
||||
'Road', 'Road Shoulder', 'Service Lane', 'Sidewalk',
|
||||
'Traffic Island', 'Bridge', 'Building', 'Garage', 'Tunnel',
|
||||
'Person', 'Person Group', 'Bicyclist', 'Motorcyclist',
|
||||
'Other Rider', 'Lane Marking - Dashed Line',
|
||||
'Lane Marking - Straight Line', 'Lane Marking - Zigzag Line',
|
||||
'Lane Marking - Ambiguous', 'Lane Marking - Arrow (Left)',
|
||||
'Lane Marking - Arrow (Other)', 'Lane Marking - Arrow (Right)',
|
||||
'Lane Marking - Arrow (Split Left or Straight)',
|
||||
'Lane Marking - Arrow (Split Right or Straight)',
|
||||
'Lane Marking - Arrow (Straight)', 'Lane Marking - Crosswalk',
|
||||
'Lane Marking - Give Way (Row)',
|
||||
'Lane Marking - Give Way (Single)',
|
||||
'Lane Marking - Hatched (Chevron)',
|
||||
'Lane Marking - Hatched (Diagonal)', 'Lane Marking - Other',
|
||||
'Lane Marking - Stop Line', 'Lane Marking - Symbol (Bicycle)',
|
||||
'Lane Marking - Symbol (Other)', 'Lane Marking - Text',
|
||||
'Lane Marking (only) - Dashed Line',
|
||||
'Lane Marking (only) - Crosswalk', 'Lane Marking (only) - Other',
|
||||
'Lane Marking (only) - Test', 'Mountain', 'Sand', 'Sky', 'Snow',
|
||||
'Terrain', 'Vegetation', 'Water', 'Banner', 'Bench', 'Bike Rack',
|
||||
'Catch Basin', 'CCTV Camera', 'Fire Hydrant', 'Junction Box',
|
||||
'Mailbox', 'Manhole', 'Parking Meter', 'Phone Booth', 'Pothole',
|
||||
'Signage - Advertisement', 'Signage - Ambiguous', 'Signage - Back',
|
||||
'Signage - Information', 'Signage - Other', 'Signage - Store',
|
||||
'Street Light', 'Pole', 'Pole Group', 'Traffic Sign Frame',
|
||||
'Utility Pole', 'Traffic Cone', 'Traffic Light - General (Single)',
|
||||
'Traffic Light - Pedestrians', 'Traffic Light - General (Upright)',
|
||||
'Traffic Light - General (Horizontal)', 'Traffic Light - Cyclists',
|
||||
'Traffic Light - Other', 'Traffic Sign - Ambiguous',
|
||||
'Traffic Sign (Back)', 'Traffic Sign - Direction (Back)',
|
||||
'Traffic Sign - Direction (Front)', 'Traffic Sign (Front)',
|
||||
'Traffic Sign - Parking', 'Traffic Sign - Temporary (Back)',
|
||||
'Traffic Sign - Temporary (Front)', 'Trash Can', 'Bicycle', 'Boat',
|
||||
'Bus', 'Car', 'Caravan', 'Motorcycle', 'On Rails', 'Other Vehicle',
|
||||
'Trailer', 'Truck', 'Vehicle Group', 'Wheeled Slow', 'Water Valve',
|
||||
'Car Mount', 'Dynamic', 'Ego Vehicle', 'Ground', 'Static',
|
||||
'Unlabeled'),
|
||||
palette=[[165, 42, 42], [0, 192, 0], [250, 170, 31], [250, 170, 32],
|
||||
[196, 196, 196], [190, 153, 153], [180, 165, 180],
|
||||
[90, 120, 150], [250, 170, 33], [250, 170, 34],
|
||||
[128, 128, 128], [250, 170, 35], [102, 102, 156],
|
||||
[128, 64, 255], [140, 140, 200], [170, 170, 170],
|
||||
[250, 170, 36], [250, 170, 160], [250, 170, 37], [96, 96, 96],
|
||||
[230, 150, 140], [128, 64, 128], [110, 110, 110],
|
||||
[110, 110, 110], [244, 35, 232], [128, 196,
|
||||
128], [150, 100, 100],
|
||||
[70, 70, 70], [150, 150, 150], [150, 120, 90], [220, 20, 60],
|
||||
[220, 20, 60], [255, 0, 0], [255, 0, 100], [255, 0, 200],
|
||||
[255, 255, 255], [255, 255, 255], [250, 170, 29],
|
||||
[250, 170, 28], [250, 170, 26], [250, 170,
|
||||
25], [250, 170, 24],
|
||||
[250, 170, 22], [250, 170, 21], [250, 170,
|
||||
20], [255, 255, 255],
|
||||
[250, 170, 19], [250, 170, 18], [250, 170,
|
||||
12], [250, 170, 11],
|
||||
[255, 255, 255], [255, 255, 255], [250, 170, 16],
|
||||
[250, 170, 15], [250, 170, 15], [255, 255, 255],
|
||||
[255, 255, 255], [255, 255, 255], [255, 255, 255],
|
||||
[64, 170, 64], [230, 160, 50],
|
||||
[70, 130, 180], [190, 255, 255], [152, 251, 152],
|
||||
[107, 142, 35], [0, 170, 30], [255, 255, 128], [250, 0, 30],
|
||||
[100, 140, 180], [220, 128, 128], [222, 40,
|
||||
40], [100, 170, 30],
|
||||
[40, 40, 40], [33, 33, 33], [100, 128, 160], [20, 20, 255],
|
||||
[142, 0, 0], [70, 100, 150], [250, 171, 30], [250, 172, 30],
|
||||
[250, 173, 30], [250, 174, 30], [250, 175,
|
||||
30], [250, 176, 30],
|
||||
[210, 170, 100], [153, 153, 153], [153, 153, 153],
|
||||
[128, 128, 128], [0, 0, 80], [210, 60, 60], [250, 170, 30],
|
||||
[250, 170, 30], [250, 170, 30], [250, 170,
|
||||
30], [250, 170, 30],
|
||||
[250, 170, 30], [192, 192, 192], [192, 192, 192],
|
||||
[192, 192, 192], [220, 220, 0], [220, 220, 0], [0, 0, 196],
|
||||
[192, 192, 192], [220, 220, 0], [140, 140, 20], [119, 11, 32],
|
||||
[150, 0, 255], [0, 60, 100], [0, 0, 142], [0, 0, 90],
|
||||
[0, 0, 230], [0, 80, 100], [128, 64, 64], [0, 0, 110],
|
||||
[0, 0, 70], [0, 0, 142], [0, 0, 192], [170, 170, 170],
|
||||
[32, 32, 32], [111, 74, 0], [120, 10, 10], [81, 0, 81],
|
||||
[111, 111, 0], [0, 0, 0]])
|
||||
|
||||
def __init__(self,
|
||||
img_suffix='.jpg',
|
||||
seg_map_suffix='.png',
|
||||
**kwargs) -> None:
|
||||
super().__init__(
|
||||
img_suffix=img_suffix, seg_map_suffix=seg_map_suffix, **kwargs)
|
||||
@@ -0,0 +1,142 @@
|
||||
# Brain CT Images with Intracranial Hemorrhage Masks (Cranium)
|
||||
|
||||
## Description
|
||||
|
||||
This project supports **`Brain CT Images with Intracranial Hemorrhage Masks (Cranium)`**, which can be downloaded from [here](https://www.kaggle.com/datasets/vbookshelf/computed-tomography-ct-images).
|
||||
|
||||
### Dataset Overview
|
||||
|
||||
This dataset consists of head CT (Computed Thomography) images in jpg format. There are 2500 brain window images and 2500 bone window images, for 82 patients. There are approximately 30 image slices per patient. 318 images have associated intracranial image masks. Also included are csv files containing hemorrhage diagnosis data and patient data.
|
||||
This is version 1.0.0 of this dataset. A full description of this dataset as well as updated versions can be found here:
|
||||
https://physionet.org/content/ct-ich/1.0.0/
|
||||
|
||||
### Statistic Information
|
||||
|
||||
| Dataset Name | Anatomical Region | Task Type | Modality | Num. Classes | Train/Val/Test Images | Train/Val/Test Labeled | Release Date | License |
|
||||
| ----------------------------------------------------------------------------------- | ----------------- | ------------ | -------- | ------------ | --------------------- | ---------------------- | ------------ | --------------------------------------------------------- |
|
||||
| [Cranium](https://www.kaggle.com/datasets/vbookshelf/computed-tomography-ct-images) | head_and_neck | segmentation | ct | 2 | 2501/-/- | yes/-/- | 2020 | [CC-BY 4.0](https://creativecommons.org/licenses/by/4.0/) |
|
||||
|
||||
| Class Name | Num. Train | Pct. Train | Num. Val | Pct. Val | Num. Test | Pct. Test |
|
||||
| :--------: | :--------: | :--------: | :------: | :------: | :-------: | :-------: |
|
||||
| background | 2501 | 99.93 | - | - | - | - |
|
||||
| hemorrhage | 318 | 0.07 | - | - | - | - |
|
||||
|
||||
Note:
|
||||
|
||||
- `Pct` means percentage of pixels in this category in all pixels.
|
||||
|
||||
### Visualization
|
||||
|
||||
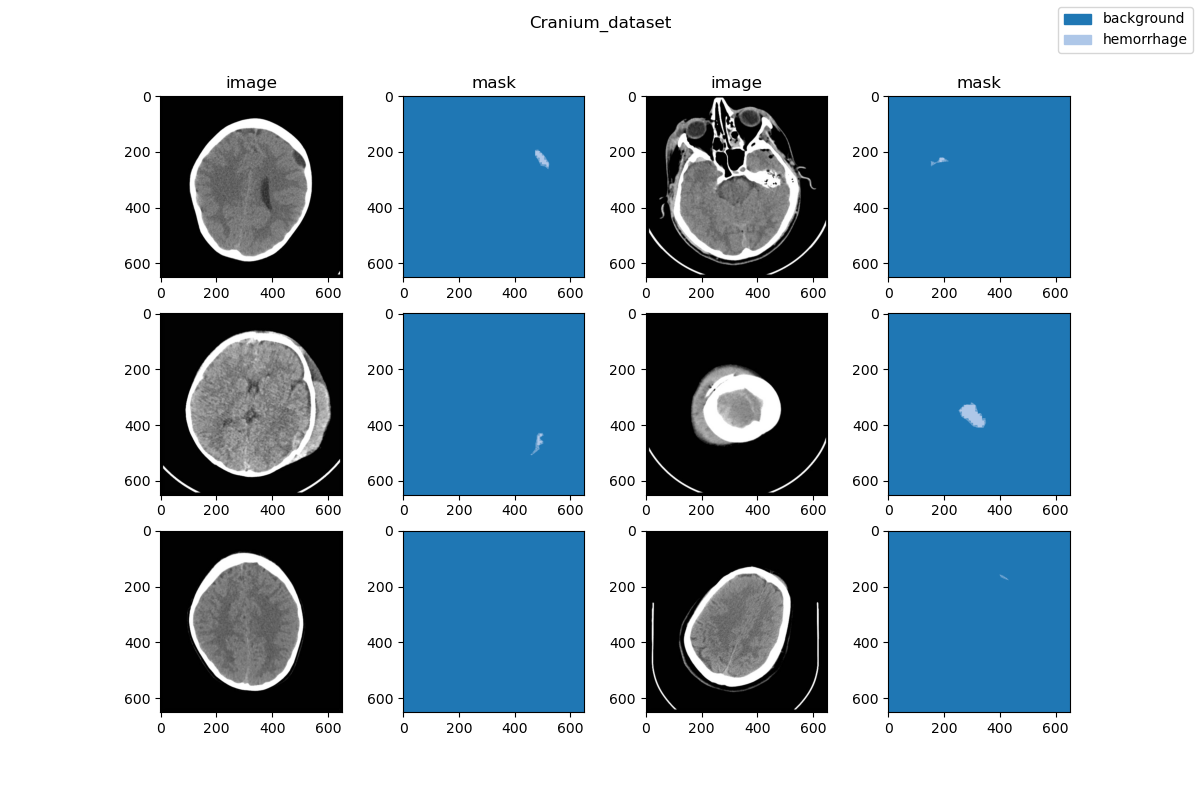
|
||||
|
||||
## Dataset Citation
|
||||
|
||||
```
|
||||
@article{hssayeni2020computed,
|
||||
title={Computed tomography images for intracranial hemorrhage detection and segmentation},
|
||||
author={Hssayeni, Murtadha and Croock, MS and Salman, AD and Al-khafaji, HF and Yahya, ZA and Ghoraani, B},
|
||||
journal={Intracranial Hemorrhage Segmentation Using A Deep Convolutional Model. Data},
|
||||
volume={5},
|
||||
number={1},
|
||||
pages={179},
|
||||
year={2020}
|
||||
}
|
||||
```
|
||||
|
||||
### Prerequisites
|
||||
|
||||
- Python v3.8
|
||||
- PyTorch v1.10.0
|
||||
- pillow(PIL) v9.3.0 9.3.0
|
||||
- scikit-learn(sklearn) v1.2.0 1.2.0
|
||||
- [MIM](https://github.com/open-mmlab/mim) v0.3.4
|
||||
- [MMCV](https://github.com/open-mmlab/mmcv) v2.0.0rc4
|
||||
- [MMEngine](https://github.com/open-mmlab/mmengine) v0.2.0 or higher
|
||||
- [MMSegmentation](https://github.com/open-mmlab/mmsegmentation) v1.0.0rc5
|
||||
|
||||
All the commands below rely on the correct configuration of `PYTHONPATH`, which should point to the project's directory so that Python can locate the module files. In `cranium/` root directory, run the following line to add the current directory to `PYTHONPATH`:
|
||||
|
||||
```shell
|
||||
export PYTHONPATH=`pwd`:$PYTHONPATH
|
||||
```
|
||||
|
||||
### Dataset Preparing
|
||||
|
||||
- download dataset from [here](https://www.kaggle.com/datasets/vbookshelf/computed-tomography-ct-images) and decompress data to path `'data/'`.
|
||||
- run script `"python tools/prepare_dataset.py"` to format data and change folder structure as below.
|
||||
- run script `"python ../../tools/split_seg_dataset.py"` to split dataset and generate `train.txt`, `val.txt` and `test.txt`. If the label of official validation set and test set cannot be obtained, we generate `train.txt` and `val.txt` from the training set randomly.
|
||||
|
||||
```none
|
||||
mmsegmentation
|
||||
├── mmseg
|
||||
├── projects
|
||||
│ ├── medical
|
||||
│ │ ├── 2d_image
|
||||
│ │ │ ├── ct
|
||||
│ │ │ │ ├── cranium
|
||||
│ │ │ │ │ ├── configs
|
||||
│ │ │ │ │ ├── datasets
|
||||
│ │ │ │ │ ├── tools
|
||||
│ │ │ │ │ ├── data
|
||||
│ │ │ │ │ │ ├── train.txt
|
||||
│ │ │ │ │ │ ├── val.txt
|
||||
│ │ │ │ │ │ ├── images
|
||||
│ │ │ │ │ │ │ ├── train
|
||||
│ │ │ │ | │ │ │ ├── xxx.png
|
||||
│ │ │ │ | │ │ │ ├── ...
|
||||
│ │ │ │ | │ │ │ └── xxx.png
|
||||
│ │ │ │ │ │ ├── masks
|
||||
│ │ │ │ │ │ │ ├── train
|
||||
│ │ │ │ | │ │ │ ├── xxx.png
|
||||
│ │ │ │ | │ │ │ ├── ...
|
||||
│ │ │ │ | │ │ │ └── xxx.png
|
||||
```
|
||||
|
||||
### Divided Dataset Information
|
||||
|
||||
***Note: The table information below is divided by ourselves.***
|
||||
|
||||
| Class Name | Num. Train | Pct. Train | Num. Val | Pct. Val | Num. Test | Pct. Test |
|
||||
| :--------: | :--------: | :--------: | :------: | :------: | :-------: | :-------: |
|
||||
| background | 2000 | 99.93 | 501 | 99.92 | - | - |
|
||||
| hemorrhage | 260 | 0.07 | 260 | 0.08 | - | - |
|
||||
|
||||
### Training commands
|
||||
|
||||
To train models on a single server with one GPU. (default)
|
||||
|
||||
```shell
|
||||
mim train mmseg ./configs/${CONFIG_FILE}
|
||||
```
|
||||
|
||||
### Testing commands
|
||||
|
||||
To test models on a single server with one GPU. (default)
|
||||
|
||||
```shell
|
||||
mim test mmseg ./configs/${CONFIG_FILE} --checkpoint ${CHECKPOINT_PATH}
|
||||
```
|
||||
|
||||
## Checklist
|
||||
|
||||
- [x] Milestone 1: PR-ready, and acceptable to be one of the `projects/`.
|
||||
|
||||
- [x] Finish the code
|
||||
- [x] Basic docstrings & proper citation
|
||||
- [ ] Test-time correctness
|
||||
- [x] A full README
|
||||
|
||||
- [ ] Milestone 2: Indicates a successful model implementation.
|
||||
|
||||
- [ ] Training-time correctness
|
||||
|
||||
- [ ] Milestone 3: Good to be a part of our core package!
|
||||
|
||||
- [ ] Type hints and docstrings
|
||||
- [ ] Unit tests
|
||||
- [ ] Code polishing
|
||||
- [ ] Metafile.yml
|
||||
|
||||
- [ ] Move your modules into the core package following the codebase's file hierarchy structure.
|
||||
|
||||
- [ ] Refactor your modules into the core package following the codebase's file hierarchy structure.
|
||||
@@ -0,0 +1,42 @@
|
||||
dataset_type = 'CraniumDataset'
|
||||
data_root = 'data/'
|
||||
img_scale = (512, 512)
|
||||
train_pipeline = [
|
||||
dict(type='LoadImageFromFile'),
|
||||
dict(type='LoadAnnotations'),
|
||||
dict(type='Resize', scale=img_scale, keep_ratio=False),
|
||||
dict(type='RandomFlip', prob=0.5),
|
||||
dict(type='PhotoMetricDistortion'),
|
||||
dict(type='PackSegInputs')
|
||||
]
|
||||
test_pipeline = [
|
||||
dict(type='LoadImageFromFile'),
|
||||
dict(type='Resize', scale=img_scale, keep_ratio=False),
|
||||
dict(type='LoadAnnotations'),
|
||||
dict(type='PackSegInputs')
|
||||
]
|
||||
train_dataloader = dict(
|
||||
batch_size=16,
|
||||
num_workers=4,
|
||||
persistent_workers=True,
|
||||
sampler=dict(type='InfiniteSampler', shuffle=True),
|
||||
dataset=dict(
|
||||
type=dataset_type,
|
||||
data_root=data_root,
|
||||
ann_file='train.txt',
|
||||
data_prefix=dict(img_path='images/', seg_map_path='masks/'),
|
||||
pipeline=train_pipeline))
|
||||
val_dataloader = dict(
|
||||
batch_size=1,
|
||||
num_workers=4,
|
||||
persistent_workers=True,
|
||||
sampler=dict(type='DefaultSampler', shuffle=False),
|
||||
dataset=dict(
|
||||
type=dataset_type,
|
||||
data_root=data_root,
|
||||
ann_file='val.txt',
|
||||
data_prefix=dict(img_path='images/', seg_map_path='masks/'),
|
||||
pipeline=test_pipeline))
|
||||
test_dataloader = val_dataloader
|
||||
val_evaluator = dict(type='IoUMetric', iou_metrics=['mIoU', 'mDice'])
|
||||
test_evaluator = dict(type='IoUMetric', iou_metrics=['mIoU', 'mDice'])
|
||||
@@ -0,0 +1,18 @@
|
||||
_base_ = [
|
||||
'mmseg::_base_/models/fcn_unet_s5-d16.py', './cranium_512x512.py',
|
||||
'mmseg::_base_/default_runtime.py',
|
||||
'mmseg::_base_/schedules/schedule_20k.py'
|
||||
]
|
||||
custom_imports = dict(imports='datasets.cranium_dataset')
|
||||
img_scale = (512, 512)
|
||||
data_preprocessor = dict(size=img_scale)
|
||||
optimizer = dict(lr=0.01)
|
||||
optim_wrapper = dict(optimizer=optimizer)
|
||||
model = dict(
|
||||
data_preprocessor=data_preprocessor,
|
||||
decode_head=dict(
|
||||
num_classes=2, loss_decode=dict(use_sigmoid=True), out_channels=1),
|
||||
auxiliary_head=None,
|
||||
test_cfg=dict(mode='whole', _delete_=True))
|
||||
vis_backends = None
|
||||
visualizer = dict(vis_backends=vis_backends)
|
||||
@@ -0,0 +1,17 @@
|
||||
_base_ = [
|
||||
'mmseg::_base_/models/fcn_unet_s5-d16.py', './cranium_512x512.py',
|
||||
'mmseg::_base_/default_runtime.py',
|
||||
'mmseg::_base_/schedules/schedule_20k.py'
|
||||
]
|
||||
custom_imports = dict(imports='datasets.cranium_dataset')
|
||||
img_scale = (512, 512)
|
||||
data_preprocessor = dict(size=img_scale)
|
||||
optimizer = dict(lr=0.0001)
|
||||
optim_wrapper = dict(optimizer=optimizer)
|
||||
model = dict(
|
||||
data_preprocessor=data_preprocessor,
|
||||
decode_head=dict(num_classes=2),
|
||||
auxiliary_head=None,
|
||||
test_cfg=dict(mode='whole', _delete_=True))
|
||||
vis_backends = None
|
||||
visualizer = dict(vis_backends=vis_backends)
|
||||
@@ -0,0 +1,17 @@
|
||||
_base_ = [
|
||||
'mmseg::_base_/models/fcn_unet_s5-d16.py', './cranium_512x512.py',
|
||||
'mmseg::_base_/default_runtime.py',
|
||||
'mmseg::_base_/schedules/schedule_20k.py'
|
||||
]
|
||||
custom_imports = dict(imports='datasets.cranium_dataset')
|
||||
img_scale = (512, 512)
|
||||
data_preprocessor = dict(size=img_scale)
|
||||
optimizer = dict(lr=0.001)
|
||||
optim_wrapper = dict(optimizer=optimizer)
|
||||
model = dict(
|
||||
data_preprocessor=data_preprocessor,
|
||||
decode_head=dict(num_classes=2),
|
||||
auxiliary_head=None,
|
||||
test_cfg=dict(mode='whole', _delete_=True))
|
||||
vis_backends = None
|
||||
visualizer = dict(vis_backends=vis_backends)
|
||||
@@ -0,0 +1,17 @@
|
||||
_base_ = [
|
||||
'mmseg::_base_/models/fcn_unet_s5-d16.py', './cranium_512x512.py',
|
||||
'mmseg::_base_/default_runtime.py',
|
||||
'mmseg::_base_/schedules/schedule_20k.py'
|
||||
]
|
||||
custom_imports = dict(imports='datasets.cranium_dataset')
|
||||
img_scale = (512, 512)
|
||||
data_preprocessor = dict(size=img_scale)
|
||||
optimizer = dict(lr=0.01)
|
||||
optim_wrapper = dict(optimizer=optimizer)
|
||||
model = dict(
|
||||
data_preprocessor=data_preprocessor,
|
||||
decode_head=dict(num_classes=2),
|
||||
auxiliary_head=None,
|
||||
test_cfg=dict(mode='whole', _delete_=True))
|
||||
vis_backends = None
|
||||
visualizer = dict(vis_backends=vis_backends)
|
||||
@@ -0,0 +1,31 @@
|
||||
from mmseg.datasets import BaseSegDataset
|
||||
from mmseg.registry import DATASETS
|
||||
|
||||
|
||||
@DATASETS.register_module()
|
||||
class CraniumDataset(BaseSegDataset):
|
||||
"""CraniumDataset dataset.
|
||||
|
||||
In segmentation map annotation for CraniumDataset,
|
||||
0 stands for background, which is included in 2 categories.
|
||||
``reduce_zero_label`` is fixed to False. The ``img_suffix``
|
||||
is fixed to '.png' and ``seg_map_suffix`` is fixed to '.png'.
|
||||
|
||||
Args:
|
||||
img_suffix (str): Suffix of images. Default: '.png'
|
||||
seg_map_suffix (str): Suffix of segmentation maps. Default: '.png'
|
||||
reduce_zero_label (bool): Whether to mark label zero as ignored.
|
||||
Default to False.
|
||||
"""
|
||||
METAINFO = dict(classes=('background', 'hemorrhage'))
|
||||
|
||||
def __init__(self,
|
||||
img_suffix='.png',
|
||||
seg_map_suffix='.png',
|
||||
reduce_zero_label=False,
|
||||
**kwargs) -> None:
|
||||
super().__init__(
|
||||
img_suffix=img_suffix,
|
||||
seg_map_suffix=seg_map_suffix,
|
||||
reduce_zero_label=reduce_zero_label,
|
||||
**kwargs)
|
||||
@@ -0,0 +1,66 @@
|
||||
import os
|
||||
|
||||
import numpy as np
|
||||
from PIL import Image
|
||||
|
||||
root_path = 'data/'
|
||||
img_suffix = '.png'
|
||||
seg_map_suffix = '.png'
|
||||
save_img_suffix = '.png'
|
||||
save_seg_map_suffix = '.png'
|
||||
tgt_img_dir = os.path.join(root_path, 'images/train/')
|
||||
tgt_mask_dir = os.path.join(root_path, 'masks/train/')
|
||||
os.system('mkdir -p ' + tgt_img_dir)
|
||||
os.system('mkdir -p ' + tgt_mask_dir)
|
||||
|
||||
|
||||
def read_single_array_from_pil(path):
|
||||
return np.asarray(Image.open(path))
|
||||
|
||||
|
||||
def save_png_from_array(arr, save_path, mode=None):
|
||||
Image.fromarray(arr, mode=mode).save(save_path)
|
||||
|
||||
|
||||
def convert_label(img, convert_dict):
|
||||
arr = np.zeros_like(img, dtype=np.uint8)
|
||||
for c, i in convert_dict.items():
|
||||
arr[img == c] = i
|
||||
return arr
|
||||
|
||||
|
||||
patients_dir = os.path.join(
|
||||
root_path, 'Cranium/computed-tomography-images-for-' +
|
||||
'intracranial-hemorrhage-detection-and-segmentation-1.0.0' +
|
||||
'/Patients_CT')
|
||||
|
||||
patients = sorted(os.listdir(patients_dir))
|
||||
for p in patients:
|
||||
data_dir = os.path.join(patients_dir, p, 'brain')
|
||||
file_names = os.listdir(data_dir)
|
||||
img_w_mask_names = [
|
||||
_.replace('_HGE_Seg', '') for _ in file_names if 'Seg' in _
|
||||
]
|
||||
img_wo_mask_names = [
|
||||
_ for _ in file_names if _ not in img_w_mask_names and 'Seg' not in _
|
||||
]
|
||||
|
||||
for file_name in file_names:
|
||||
path = os.path.join(data_dir, file_name)
|
||||
img = read_single_array_from_pil(path)
|
||||
tgt_name = file_name.replace('.jpg', img_suffix)
|
||||
tgt_name = p + '_' + tgt_name
|
||||
if 'Seg' in file_name: # is a mask
|
||||
tgt_name = tgt_name.replace('_HGE_Seg', '')
|
||||
mask_path = os.path.join(tgt_mask_dir, tgt_name)
|
||||
mask = convert_label(img, convert_dict={0: 0, 255: 1})
|
||||
save_png_from_array(mask, mask_path)
|
||||
else:
|
||||
img_path = os.path.join(tgt_img_dir, tgt_name)
|
||||
pil = Image.fromarray(img).convert('RGB')
|
||||
pil.save(img_path)
|
||||
|
||||
if file_name in img_wo_mask_names:
|
||||
mask = np.zeros_like(img, dtype=np.uint8)
|
||||
mask_path = os.path.join(tgt_mask_dir, tgt_name)
|
||||
save_png_from_array(mask, mask_path)
|
||||
@@ -0,0 +1,149 @@
|
||||
# ISIC-2016 Task1
|
||||
|
||||
## Description
|
||||
|
||||
This project support **`ISIC-2016 Task1 `**, and the dataset used in this project can be downloaded from [here](https://challenge.isic-archive.com/data/#2016).
|
||||
|
||||
### Dataset Overview
|
||||
|
||||
The overarching goal of the challenge is to develop image analysis tools to enable the automated diagnosis of melanoma from dermoscopic images.
|
||||
|
||||
This challenge provides training data (~900 images) for participants to engage in all 3 components of lesion image analysis. A separate test dataset (~350 images) will be provided for participants to generate and submit automated results.
|
||||
|
||||
### Original Statistic Information
|
||||
|
||||
| Dataset name | Anatomical region | Task type | Modality | Num. Classes | Train/Val/Test Images | Train/Val/Test Labeled | Release Date | License |
|
||||
| ---------------------------------------------------------------- | ----------------- | ------------ | ---------- | ------------ | --------------------- | ---------------------- | ------------ | ---------------------------------------------------------------------- |
|
||||
| [ISIC-2016 Task1](https://challenge.isic-archive.com/data/#2016) | full body | segmentation | dermoscopy | 2 | 900/-/379- | yes/-/yes | 2016 | [CC-0](https://creativecommons.org/share-your-work/public-domain/cc0/) |
|
||||
|
||||
| Class Name | Num. Train | Pct. Train | Num. Val | Pct. Val | Num. Test | Pct. Test |
|
||||
| :---------: | :--------: | :--------: | :------: | :------: | :-------: | :-------: |
|
||||
| background | 900 | 82.08 | - | - | 379 | 81.98 |
|
||||
| skin lesion | 900 | 17.92 | - | - | 379 | 18.02 |
|
||||
|
||||
Note:
|
||||
|
||||
- `Pct` means percentage of pixels in this category in all pixels.
|
||||
|
||||
### Visualization
|
||||
|
||||
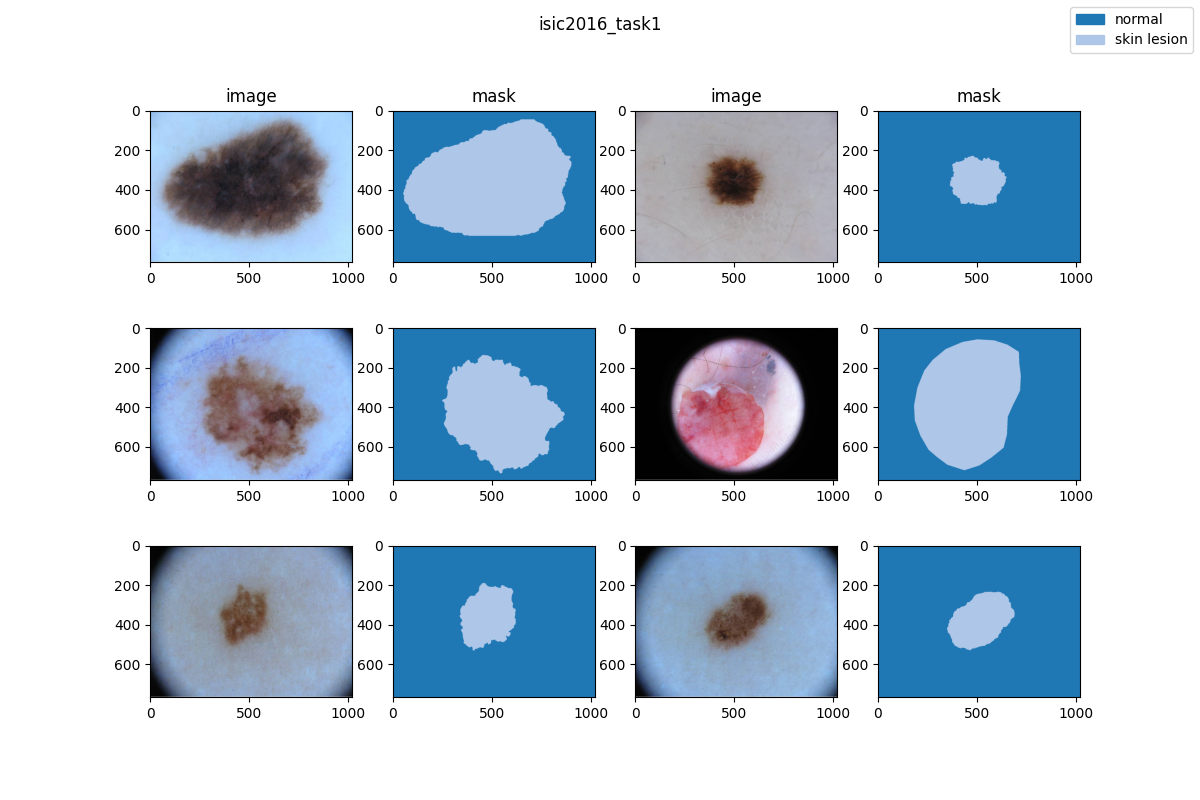
|
||||
|
||||
### Prerequisites
|
||||
|
||||
- Python 3.8
|
||||
- PyTorch 1.10.0
|
||||
- pillow(PIL) 9.3.0
|
||||
- scikit-learn(sklearn) 1.2.0
|
||||
- [MIM](https://github.com/open-mmlab/mim) v0.3.4
|
||||
- [MMCV](https://github.com/open-mmlab/mmcv) v2.0.0rc4
|
||||
- [MMEngine](https://github.com/open-mmlab/mmengine) v0.2.0 or higher
|
||||
- [MMSegmentation](https://github.com/open-mmlab/mmsegmentation) v1.0.0rc5
|
||||
|
||||
All the commands below rely on the correct configuration of PYTHONPATH, which should point to the project's directory so that Python can locate the module files. In isic2016_task1/ root directory, run the following line to add the current directory to PYTHONPATH:
|
||||
|
||||
```shell
|
||||
export PYTHONPATH=`pwd`:$PYTHONPATH
|
||||
```
|
||||
|
||||
### Dataset preparing
|
||||
|
||||
- download dataset from [here](https://challenge.isic-archive.com/data/#2016) and decompression data to path 'data/'.
|
||||
- run script `"python tools/prepare_dataset.py"` to split dataset and change folder structure as below.
|
||||
- run script `"python ../../tools/split_seg_dataset.py"` to split dataset and generate `train.txt` and `test.txt`. If the label of official validation set and test set can't be obtained, we generate `train.txt` and `val.txt` from the training set randomly.
|
||||
|
||||
```none
|
||||
mmsegmentation
|
||||
├── mmseg
|
||||
├── projects
|
||||
│ ├── medical
|
||||
│ │ ├── 2d_image
|
||||
│ │ │ ├── dermoscopy
|
||||
│ │ │ │ ├── isic2016_task1
|
||||
│ │ │ │ │ ├── configs
|
||||
│ │ │ │ │ ├── datasets
|
||||
│ │ │ │ │ ├── tools
|
||||
│ │ │ │ │ ├── data
|
||||
│ │ │ │ │ │ ├── train.txt
|
||||
│ │ │ │ │ │ ├── test.txt
|
||||
│ │ │ │ │ │ ├── images
|
||||
│ │ │ │ │ │ │ ├── train
|
||||
│ │ │ │ | │ │ │ ├── xxx.png
|
||||
│ │ │ │ | │ │ │ ├── ...
|
||||
│ │ │ │ | │ │ │ └── xxx.png
|
||||
│ │ │ │ │ │ │ ├── test
|
||||
│ │ │ │ | │ │ │ ├── yyy.png
|
||||
│ │ │ │ | │ │ │ ├── ...
|
||||
│ │ │ │ | │ │ │ └── yyy.png
|
||||
│ │ │ │ │ │ ├── masks
|
||||
│ │ │ │ │ │ │ ├── train
|
||||
│ │ │ │ | │ │ │ ├── xxx.png
|
||||
│ │ │ │ | │ │ │ ├── ...
|
||||
│ │ │ │ | │ │ │ └── xxx.png
|
||||
│ │ │ │ │ │ │ ├── test
|
||||
│ │ │ │ | │ │ │ ├── yyy.png
|
||||
│ │ │ │ | │ │ │ ├── ...
|
||||
│ │ │ │ | │ │ │ └── yyy.png
|
||||
```
|
||||
|
||||
### Training commands
|
||||
|
||||
```shell
|
||||
mim train mmseg ./configs/${CONFIG_PATH}
|
||||
```
|
||||
|
||||
To train on multiple GPUs, e.g. 8 GPUs, run the following command:
|
||||
|
||||
```shell
|
||||
mim train mmseg ./configs/${CONFIG_PATH} --launcher pytorch --gpus 8
|
||||
```
|
||||
|
||||
### Testing commands
|
||||
|
||||
```shell
|
||||
mim test mmseg ./configs/${CONFIG_PATH} --checkpoint ${CHECKPOINT_PATH}
|
||||
```
|
||||
|
||||
<!-- List the results as usually done in other model's README. [Example](https://github.com/open-mmlab/mmsegmentation/tree/dev-1.x/configs/fcn#results-and-models)
|
||||
|
||||
You should claim whether this is based on the pre-trained weights, which are converted from the official release; or it's a reproduced result obtained from retraining the model in this project. -->
|
||||
|
||||
## Results
|
||||
|
||||
### ISIC-2016 Task1
|
||||
|
||||
| Method | Backbone | Crop Size | lr | mIoU | mDice | config |
|
||||
| :-------------: | :------: | :-------: | :----: | :--: | :---: | :---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: |
|
||||
| fcn_unet_s5-d16 | unet | 512x512 | 0.01 | - | - | [config](https://github.com/open-mmlab/mmsegmentation/tree/dev-1.x/projects/medical/2d_image/dermoscopy/isic2016_task1/configs/fcn-unet-s5-d16_unet_1xb16-0.01-20k_isic2016-task1-512x512.py) |
|
||||
| fcn_unet_s5-d16 | unet | 512x512 | 0.001 | - | - | [config](https://github.com/open-mmlab/mmsegmentation/tree/dev-1.x/projects/medical/2d_image/dermoscopy/isic2016_task1/configs/fcn-unet-s5-d16_unet_1xb16-0.001-20k_isic2016-task1-512x512.py) |
|
||||
| fcn_unet_s5-d16 | unet | 512x512 | 0.0001 | - | - | [config](https://github.com/open-mmlab/mmsegmentation/tree/dev-1.x/projects/medical/2d_image/dermoscopy/isic2016_task1/configs/fcn-unet-s5-d16_unet_1xb16-0.0001-20k_isic2016-task1-512x512.py) |
|
||||
|
||||
## Checklist
|
||||
|
||||
- [x] Milestone 1: PR-ready, and acceptable to be one of the `projects/`.
|
||||
|
||||
- [x] Finish the code
|
||||
|
||||
- [x] Basic docstrings & proper citation
|
||||
|
||||
- [x] Test-time correctness
|
||||
|
||||
- [x] A full README
|
||||
|
||||
- [x] Milestone 2: Indicates a successful model implementation.
|
||||
|
||||
- [x] Training-time correctness
|
||||
|
||||
- [ ] Milestone 3: Good to be a part of our core package!
|
||||
|
||||
- [ ] Type hints and docstrings
|
||||
|
||||
- [ ] Unit tests
|
||||
|
||||
- [ ] Code polishing
|
||||
|
||||
- [ ] Metafile.yml
|
||||
|
||||
- [ ] Move your modules into the core package following the codebase's file hierarchy structure.
|
||||
|
||||
- [ ] Refactor your modules into the core package following the codebase's file hierarchy structure.
|
||||
@@ -0,0 +1,17 @@
|
||||
_base_ = [
|
||||
'mmseg::_base_/models/fcn_unet_s5-d16.py', './isic2016-task1_512x512.py',
|
||||
'mmseg::_base_/default_runtime.py',
|
||||
'mmseg::_base_/schedules/schedule_20k.py'
|
||||
]
|
||||
custom_imports = dict(imports='datasets.isic2016-task1_dataset')
|
||||
img_scale = (512, 512)
|
||||
data_preprocessor = dict(size=img_scale)
|
||||
optimizer = dict(lr=0.0001)
|
||||
optim_wrapper = dict(optimizer=optimizer)
|
||||
model = dict(
|
||||
data_preprocessor=data_preprocessor,
|
||||
decode_head=dict(num_classes=2),
|
||||
auxiliary_head=None,
|
||||
test_cfg=dict(mode='whole', _delete_=True))
|
||||
vis_backends = None
|
||||
visualizer = dict(vis_backends=vis_backends)
|
||||
@@ -0,0 +1,17 @@
|
||||
_base_ = [
|
||||
'mmseg::_base_/models/fcn_unet_s5-d16.py', './isic2016-task1_512x512.py',
|
||||
'mmseg::_base_/default_runtime.py',
|
||||
'mmseg::_base_/schedules/schedule_20k.py'
|
||||
]
|
||||
custom_imports = dict(imports='datasets.isic2016-task1_dataset')
|
||||
img_scale = (512, 512)
|
||||
data_preprocessor = dict(size=img_scale)
|
||||
optimizer = dict(lr=0.001)
|
||||
optim_wrapper = dict(optimizer=optimizer)
|
||||
model = dict(
|
||||
data_preprocessor=data_preprocessor,
|
||||
decode_head=dict(num_classes=2),
|
||||
auxiliary_head=None,
|
||||
test_cfg=dict(mode='whole', _delete_=True))
|
||||
vis_backends = None
|
||||
visualizer = dict(vis_backends=vis_backends)
|
||||
@@ -0,0 +1,17 @@
|
||||
_base_ = [
|
||||
'mmseg::_base_/models/fcn_unet_s5-d16.py', './isic2016-task1_512x512.py',
|
||||
'mmseg::_base_/default_runtime.py',
|
||||
'mmseg::_base_/schedules/schedule_20k.py'
|
||||
]
|
||||
custom_imports = dict(imports='datasets.isic2016-task1_dataset')
|
||||
img_scale = (512, 512)
|
||||
data_preprocessor = dict(size=img_scale)
|
||||
optimizer = dict(lr=0.01)
|
||||
optim_wrapper = dict(optimizer=optimizer)
|
||||
model = dict(
|
||||
data_preprocessor=data_preprocessor,
|
||||
decode_head=dict(num_classes=2),
|
||||
auxiliary_head=None,
|
||||
test_cfg=dict(mode='whole', _delete_=True))
|
||||
vis_backends = None
|
||||
visualizer = dict(vis_backends=vis_backends)
|
||||
@@ -0,0 +1,42 @@
|
||||
dataset_type = 'ISIC2017Task1'
|
||||
data_root = 'data/'
|
||||
img_scale = (512, 512)
|
||||
train_pipeline = [
|
||||
dict(type='LoadImageFromFile'),
|
||||
dict(type='LoadAnnotations'),
|
||||
dict(type='Resize', scale=img_scale, keep_ratio=False),
|
||||
dict(type='RandomFlip', prob=0.5),
|
||||
dict(type='PhotoMetricDistortion'),
|
||||
dict(type='PackSegInputs')
|
||||
]
|
||||
test_pipeline = [
|
||||
dict(type='LoadImageFromFile'),
|
||||
dict(type='Resize', scale=img_scale, keep_ratio=False),
|
||||
dict(type='LoadAnnotations'),
|
||||
dict(type='PackSegInputs')
|
||||
]
|
||||
train_dataloader = dict(
|
||||
batch_size=16,
|
||||
num_workers=4,
|
||||
persistent_workers=True,
|
||||
sampler=dict(type='InfiniteSampler', shuffle=True),
|
||||
dataset=dict(
|
||||
type=dataset_type,
|
||||
data_root=data_root,
|
||||
ann_file='train.txt',
|
||||
data_prefix=dict(img_path='images/', seg_map_path='masks/'),
|
||||
pipeline=train_pipeline))
|
||||
val_dataloader = dict(
|
||||
batch_size=1,
|
||||
num_workers=4,
|
||||
persistent_workers=True,
|
||||
sampler=dict(type='DefaultSampler', shuffle=False),
|
||||
dataset=dict(
|
||||
type=dataset_type,
|
||||
data_root=data_root,
|
||||
ann_file='test.txt',
|
||||
data_prefix=dict(img_path='images/', seg_map_path='masks/'),
|
||||
pipeline=test_pipeline))
|
||||
test_dataloader = val_dataloader
|
||||
val_evaluator = dict(type='IoUMetric', iou_metrics=['mIoU', 'mDice'])
|
||||
test_evaluator = dict(type='IoUMetric', iou_metrics=['mIoU', 'mDice'])
|
||||
@@ -0,0 +1,30 @@
|
||||
from mmseg.datasets import BaseSegDataset
|
||||
from mmseg.registry import DATASETS
|
||||
|
||||
|
||||
@DATASETS.register_module()
|
||||
class ISIC2017Task1(BaseSegDataset):
|
||||
"""ISIC2017Task1 dataset.
|
||||
|
||||
In segmentation map annotation for ISIC2017Task1,
|
||||
``reduce_zero_label`` is fixed to False. The ``img_suffix``
|
||||
is fixed to '.png' and ``seg_map_suffix`` is fixed to '.png'.
|
||||
|
||||
Args:
|
||||
img_suffix (str): Suffix of images. Default: '.png'
|
||||
seg_map_suffix (str): Suffix of segmentation maps. Default: '.png'
|
||||
reduce_zero_label (bool): Whether to mark label zero as ignored.
|
||||
Default to False.
|
||||
"""
|
||||
METAINFO = dict(classes=('normal', 'skin lesion'))
|
||||
|
||||
def __init__(self,
|
||||
img_suffix='.png',
|
||||
seg_map_suffix='.png',
|
||||
reduce_zero_label=False,
|
||||
**kwargs) -> None:
|
||||
super().__init__(
|
||||
img_suffix=img_suffix,
|
||||
seg_map_suffix=seg_map_suffix,
|
||||
reduce_zero_label=reduce_zero_label,
|
||||
**kwargs)
|
||||
@@ -0,0 +1,120 @@
|
||||
import glob
|
||||
import os
|
||||
import shutil
|
||||
|
||||
import numpy as np
|
||||
from PIL import Image
|
||||
|
||||
|
||||
def check_maskid(train_imgs):
|
||||
for i in train_masks:
|
||||
img = Image.open(i)
|
||||
print(np.unique(np.array(img)))
|
||||
|
||||
|
||||
def reformulate_file(image_list, mask_list):
|
||||
file_list = []
|
||||
for idx, (imgp,
|
||||
maskp) in enumerate(zip(sorted(image_list), sorted(mask_list))):
|
||||
item = {'image': imgp, 'label': maskp}
|
||||
file_list.append(item)
|
||||
return file_list
|
||||
|
||||
|
||||
def check_file_exist(pair_list):
|
||||
rel_path = os.getcwd()
|
||||
for idx, sample in enumerate(pair_list):
|
||||
image_path = sample['image']
|
||||
assert os.path.exists(os.path.join(rel_path, image_path))
|
||||
if 'label' in sample:
|
||||
mask_path = sample['label']
|
||||
assert os.path.exists(os.path.join(rel_path, mask_path))
|
||||
print('all file path ok!')
|
||||
|
||||
|
||||
def convert_maskid(mask):
|
||||
# add mask id conversion
|
||||
arr_mask = np.array(mask).astype(np.uint8)
|
||||
arr_mask[arr_mask == 255] = 1
|
||||
return Image.fromarray(arr_mask)
|
||||
|
||||
|
||||
def process_dataset(file_lists, part_dir_dict):
|
||||
for ith, part in enumerate(file_lists):
|
||||
part_dir = part_dir_dict[ith]
|
||||
for sample in part:
|
||||
# read image and mask
|
||||
image_path = sample['image']
|
||||
if 'label' in sample:
|
||||
mask_path = sample['label']
|
||||
|
||||
basename = os.path.basename(image_path)
|
||||
targetname = basename.split('.')[0] # from image name
|
||||
|
||||
# check image file
|
||||
img_save_path = os.path.join(root_path, 'images', part_dir,
|
||||
targetname + save_img_suffix)
|
||||
if not os.path.exists(img_save_path):
|
||||
if not image_path.endswith('.png'):
|
||||
src = Image.open(image_path)
|
||||
src.save(img_save_path)
|
||||
else:
|
||||
shutil.copy(image_path, img_save_path)
|
||||
|
||||
if mask_path is not None:
|
||||
mask_save_path = os.path.join(root_path, 'masks', part_dir,
|
||||
targetname + save_seg_map_suffix)
|
||||
if not os.path.exists(mask_save_path):
|
||||
# check mask file
|
||||
mask = Image.open(mask_path).convert('L')
|
||||
# convert mask id
|
||||
mask = convert_maskid(mask)
|
||||
if not mask_path.endswith('.png'):
|
||||
mask.save(mask_save_path)
|
||||
else:
|
||||
mask.save(mask_save_path)
|
||||
|
||||
# print image num
|
||||
part_dir_folder = os.path.join(root_path, 'images', part_dir)
|
||||
print(
|
||||
f'{part_dir} has {len(os.listdir(part_dir_folder))} images completed!' # noqa
|
||||
)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
|
||||
root_path = 'data/' # original file
|
||||
img_suffix = '.jpg'
|
||||
seg_map_suffix = '.png'
|
||||
save_img_suffix = '.png'
|
||||
save_seg_map_suffix = '.png'
|
||||
|
||||
train_imgs = glob.glob('data/ISBI2016_ISIC_Part1_Training_Data/*' # noqa
|
||||
+ img_suffix)
|
||||
train_masks = glob.glob(
|
||||
'data/ISBI2016_ISIC_Part1_Training_GroundTruth/*' # noqa
|
||||
+ seg_map_suffix)
|
||||
|
||||
test_imgs = glob.glob('data/ISBI2016_ISIC_Part1_Test_Data/*' + img_suffix)
|
||||
test_masks = glob.glob(
|
||||
'data/ISBI2016_ISIC_Part1_Test_GroundTruth/*' # noqa
|
||||
+ seg_map_suffix)
|
||||
|
||||
assert len(train_imgs) == len(train_masks)
|
||||
assert len(test_imgs) == len(test_masks)
|
||||
|
||||
print(f'training images: {len(train_imgs)}, test images: {len(test_imgs)}')
|
||||
|
||||
os.system('mkdir -p ' + root_path + 'images/train/')
|
||||
os.system('mkdir -p ' + root_path + 'images/test/')
|
||||
os.system('mkdir -p ' + root_path + 'masks/train/')
|
||||
os.system('mkdir -p ' + root_path + 'masks/test/')
|
||||
|
||||
train_pair_list = reformulate_file(train_imgs, train_masks)
|
||||
test_pair_list = reformulate_file(test_imgs, test_masks)
|
||||
|
||||
check_file_exist(train_pair_list)
|
||||
check_file_exist(test_pair_list)
|
||||
|
||||
part_dir_dict = {0: 'train/', 1: 'test/'}
|
||||
process_dataset([train_pair_list, test_pair_list], part_dir_dict)
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user