first commit
This commit is contained in:
17
Seg_All_In_One_MMSeg/docs/en/.readthedocs.yaml
Normal file
17
Seg_All_In_One_MMSeg/docs/en/.readthedocs.yaml
Normal file
@@ -0,0 +1,17 @@
|
||||
version: 2
|
||||
|
||||
build:
|
||||
os: ubuntu-22.04
|
||||
tools:
|
||||
python: "3.8"
|
||||
|
||||
formats:
|
||||
- epub
|
||||
|
||||
sphinx:
|
||||
configuration: docs/en/conf.py
|
||||
|
||||
python:
|
||||
install:
|
||||
- requirements: requirements/docs.txt
|
||||
- requirements: requirements/readthedocs.txt
|
||||
20
Seg_All_In_One_MMSeg/docs/en/Makefile
Normal file
20
Seg_All_In_One_MMSeg/docs/en/Makefile
Normal file
@@ -0,0 +1,20 @@
|
||||
# Minimal makefile for Sphinx documentation
|
||||
#
|
||||
|
||||
# You can set these variables from the command line, and also
|
||||
# from the environment for the first two.
|
||||
SPHINXOPTS ?=
|
||||
SPHINXBUILD ?= sphinx-build
|
||||
SOURCEDIR = .
|
||||
BUILDDIR = _build
|
||||
|
||||
# Put it first so that "make" without argument is like "make help".
|
||||
help:
|
||||
@$(SPHINXBUILD) -M help "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
|
||||
|
||||
.PHONY: help Makefile
|
||||
|
||||
# Catch-all target: route all unknown targets to Sphinx using the new
|
||||
# "make mode" option. $(O) is meant as a shortcut for $(SPHINXOPTS).
|
||||
%: Makefile
|
||||
@$(SPHINXBUILD) -M $@ "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
|
||||
6
Seg_All_In_One_MMSeg/docs/en/_static/css/readthedocs.css
Normal file
6
Seg_All_In_One_MMSeg/docs/en/_static/css/readthedocs.css
Normal file
@@ -0,0 +1,6 @@
|
||||
.header-logo {
|
||||
background-image: url("../images/mmsegmentation.png");
|
||||
background-size: 201px 40px;
|
||||
height: 40px;
|
||||
width: 201px;
|
||||
}
|
||||
BIN
Seg_All_In_One_MMSeg/docs/en/_static/images/mmsegmentation.png
Normal file
BIN
Seg_All_In_One_MMSeg/docs/en/_static/images/mmsegmentation.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 44 KiB |
199
Seg_All_In_One_MMSeg/docs/en/advanced_guides/add_datasets.md
Normal file
199
Seg_All_In_One_MMSeg/docs/en/advanced_guides/add_datasets.md
Normal file
@@ -0,0 +1,199 @@
|
||||
# Add New Datasets
|
||||
|
||||
## Add new custom dataset
|
||||
|
||||
Here we show how to develop a new custom dataset.
|
||||
|
||||
1. Create a new file `mmseg/datasets/example.py`
|
||||
|
||||
```python
|
||||
from mmseg.registry import DATASETS
|
||||
from .basesegdataset import BaseSegDataset
|
||||
|
||||
|
||||
@DATASETS.register_module()
|
||||
class ExampleDataset(BaseSegDataset):
|
||||
|
||||
METAINFO = dict(
|
||||
classes=('xxx', 'xxx', ...),
|
||||
palette=[[x, x, x], [x, x, x], ...])
|
||||
|
||||
def __init__(self, arg1, arg2):
|
||||
pass
|
||||
```
|
||||
|
||||
2. Import the module in `mmseg/datasets/__init__.py`
|
||||
|
||||
```python
|
||||
from .example import ExampleDataset
|
||||
```
|
||||
|
||||
3. Use it by creating a new new dataset config file `configs/_base_/datasets/example_dataset.py`
|
||||
|
||||
```python
|
||||
dataset_type = 'ExampleDataset'
|
||||
data_root = 'data/example/'
|
||||
...
|
||||
```
|
||||
|
||||
4. Add dataset meta information in `mmseg/utils/class_names.py`
|
||||
|
||||
```python
|
||||
def example_classes():
|
||||
return [
|
||||
'xxx', 'xxx',
|
||||
...
|
||||
]
|
||||
|
||||
def example_palette():
|
||||
return [
|
||||
[x, x, x], [x, x, x],
|
||||
...
|
||||
]
|
||||
dataset_aliases ={
|
||||
'example': ['example', ...],
|
||||
...
|
||||
}
|
||||
```
|
||||
|
||||
**Note:** If the new dataset does not satisfy the mmseg requirements, a data preprocessing script needs to be prepared in `tools/dataset_converters/`
|
||||
|
||||
## Customize datasets by reorganizing data
|
||||
|
||||
The simplest way is to convert your dataset to organize your data into folders.
|
||||
|
||||
An example of file structure is as followed.
|
||||
|
||||
```none
|
||||
├── data
|
||||
│ ├── my_dataset
|
||||
│ │ ├── img_dir
|
||||
│ │ │ ├── train
|
||||
│ │ │ │ ├── xxx{img_suffix}
|
||||
│ │ │ │ ├── yyy{img_suffix}
|
||||
│ │ │ │ ├── zzz{img_suffix}
|
||||
│ │ │ ├── val
|
||||
│ │ ├── ann_dir
|
||||
│ │ │ ├── train
|
||||
│ │ │ │ ├── xxx{seg_map_suffix}
|
||||
│ │ │ │ ├── yyy{seg_map_suffix}
|
||||
│ │ │ │ ├── zzz{seg_map_suffix}
|
||||
│ │ │ ├── val
|
||||
|
||||
```
|
||||
|
||||
A training pair will consist of the files with same suffix in img_dir/ann_dir.
|
||||
|
||||
Some datasets don't release the test set or don't release the ground truth of the test set, and we cannot evaluate models locally without the ground truth of the test set, so we set the validation set as the default test set in config files.
|
||||
|
||||
About how to build your own datasets or implement a new dataset class please refer to the [datasets guide](./datasets.md) for more detailed information.
|
||||
|
||||
**Note:** The annotations are images of shape (H, W), the value pixel should fall in range `[0, num_classes - 1]`.
|
||||
You may use `'P'` mode of [pillow](https://pillow.readthedocs.io/en/stable/handbook/concepts.html#palette) to create your annotation image with color.
|
||||
|
||||
## Customize datasets by mixing dataset
|
||||
|
||||
MMSegmentation also supports to mix dataset for training.
|
||||
Currently it supports to concat, repeat and multi-image mix datasets.
|
||||
|
||||
### Repeat dataset
|
||||
|
||||
We use `RepeatDataset` as wrapper to repeat the dataset.
|
||||
For example, suppose the original dataset is `Dataset_A`, to repeat it, the config looks like the following
|
||||
|
||||
```python
|
||||
dataset_A_train = dict(
|
||||
type='RepeatDataset',
|
||||
times=N,
|
||||
dataset=dict( # This is the original config of Dataset_A
|
||||
type='Dataset_A',
|
||||
...
|
||||
pipeline=train_pipeline
|
||||
)
|
||||
)
|
||||
```
|
||||
|
||||
### Concatenate dataset
|
||||
|
||||
In case the dataset you want to concatenate is different, you can concatenate the dataset configs like the following.
|
||||
|
||||
```python
|
||||
dataset_A_train = dict()
|
||||
dataset_B_train = dict()
|
||||
concatenate_dataset = dict(
|
||||
type='ConcatDataset',
|
||||
datasets=[dataset_A_train, dataset_B_train])
|
||||
```
|
||||
|
||||
A more complex example that repeats `Dataset_A` and `Dataset_B` by N and M times, respectively, and then concatenates the repeated datasets is as the following.
|
||||
|
||||
```python
|
||||
dataset_A_train = dict(
|
||||
type='RepeatDataset',
|
||||
times=N,
|
||||
dataset=dict(
|
||||
type='Dataset_A',
|
||||
...
|
||||
pipeline=train_pipeline
|
||||
)
|
||||
)
|
||||
dataset_A_val = dict(
|
||||
...
|
||||
pipeline=test_pipeline
|
||||
)
|
||||
dataset_A_test = dict(
|
||||
...
|
||||
pipeline=test_pipeline
|
||||
)
|
||||
dataset_B_train = dict(
|
||||
type='RepeatDataset',
|
||||
times=M,
|
||||
dataset=dict(
|
||||
type='Dataset_B',
|
||||
...
|
||||
pipeline=train_pipeline
|
||||
)
|
||||
)
|
||||
train_dataloader = dict(
|
||||
dataset=dict(
|
||||
type='ConcatDataset',
|
||||
datasets=[dataset_A_train, dataset_B_train]))
|
||||
|
||||
val_dataloader = dict(dataset=dataset_A_val)
|
||||
test_dataloader = dict(dataset=dataset_A_test)
|
||||
|
||||
```
|
||||
|
||||
You can refer base dataset [tutorial](https://mmengine.readthedocs.io/en/latest/advanced_tutorials/basedataset.html) from mmengine for more details
|
||||
|
||||
### Multi-image Mix Dataset
|
||||
|
||||
We use `MultiImageMixDataset` as a wrapper to mix images from multiple datasets.
|
||||
`MultiImageMixDataset` can be used by multiple images mixed data augmentation like mosaic and mixup.
|
||||
|
||||
An example of using `MultiImageMixDataset` with `Mosaic` data augmentation:
|
||||
|
||||
```python
|
||||
train_pipeline = [
|
||||
dict(type='RandomMosaic', prob=1),
|
||||
dict(type='Resize', img_scale=(1024, 512), keep_ratio=True),
|
||||
dict(type='RandomFlip', prob=0.5),
|
||||
dict(type='PackSegInputs')
|
||||
]
|
||||
|
||||
train_dataset = dict(
|
||||
type='MultiImageMixDataset',
|
||||
dataset=dict(
|
||||
type=dataset_type,
|
||||
reduce_zero_label=False,
|
||||
img_dir=data_root + "images/train",
|
||||
ann_dir=data_root + "annotations/train",
|
||||
pipeline=[
|
||||
dict(type='LoadImageFromFile'),
|
||||
dict(type='LoadAnnotations'),
|
||||
]
|
||||
),
|
||||
pipeline=train_pipeline
|
||||
)
|
||||
|
||||
```
|
||||
81
Seg_All_In_One_MMSeg/docs/en/advanced_guides/add_metrics.md
Normal file
81
Seg_All_In_One_MMSeg/docs/en/advanced_guides/add_metrics.md
Normal file
@@ -0,0 +1,81 @@
|
||||
# Add New Metrics
|
||||
|
||||
## Develop with the source code of MMSegmentation
|
||||
|
||||
Here we show how to develop a new metric with an example of `CustomMetric` as the following.
|
||||
|
||||
1. Create a new file `mmseg/evaluation/metrics/custom_metric.py`.
|
||||
|
||||
```python
|
||||
from typing import List, Sequence
|
||||
|
||||
from mmengine.evaluator import BaseMetric
|
||||
|
||||
from mmseg.registry import METRICS
|
||||
|
||||
|
||||
@METRICS.register_module()
|
||||
class CustomMetric(BaseMetric):
|
||||
|
||||
def __init__(self, arg1, arg2):
|
||||
"""
|
||||
The metric first processes each batch of data_samples and predictions,
|
||||
and appends the processed results to the results list. Then it
|
||||
collects all results together from all ranks if distributed training
|
||||
is used. Finally, it computes the metrics of the entire dataset.
|
||||
"""
|
||||
|
||||
def process(self, data_batch: dict, data_samples: Sequence[dict]) -> None:
|
||||
pass
|
||||
|
||||
def compute_metrics(self, results: list) -> dict:
|
||||
pass
|
||||
|
||||
def evaluate(self, size: int) -> dict:
|
||||
pass
|
||||
```
|
||||
|
||||
In the above example, `CustomMetric` is a subclass of `BaseMetric`. It has three methods: `process`, `compute_metrics` and `evaluate`.
|
||||
|
||||
- `process()` process one batch of data samples and predictions. The processed results are stored in `self.results` which will be used to compute the metrics after all the data samples are processed. Please refer to [MMEngine documentation](https://github.com/open-mmlab/mmengine/blob/main/docs/en/design/evaluation.md) for more details.
|
||||
|
||||
- `compute_metrics()` is used to compute the metrics from the processed results.
|
||||
|
||||
- `evaluate()` is an interface to compute the metrics and return the results. It will be called by `ValLoop` or `TestLoop` in the `Runner`. In most cases, you don't need to override this method, but you can override it if you want to do some extra work.
|
||||
|
||||
**Note:** You might find the details of calling `evaluate()` method in the `Runner` [here](https://github.com/open-mmlab/mmengine/blob/main/mmengine/runner/loops.py#L366). The `Runner` is the executor of the training and testing process, you can find more details about it at the [engine document](./engine.md).
|
||||
|
||||
2. Import the new metric in `mmseg/evaluation/metrics/__init__.py`.
|
||||
|
||||
```python
|
||||
from .custom_metric import CustomMetric
|
||||
__all__ = ['CustomMetric', ...]
|
||||
```
|
||||
|
||||
3. Add the new metric to the config file.
|
||||
|
||||
```python
|
||||
val_evaluator = dict(type='CustomMetric', arg1=xxx, arg2=xxx)
|
||||
test_evaluator = dict(type='CustomMetric', arg1=xxx, arg2=xxx)
|
||||
```
|
||||
|
||||
## Develop with the released version of MMSegmentation
|
||||
|
||||
The above example shows how to develop a new metric with the source code of MMSegmentation. If you want to develop a new metric with the released version of MMSegmentation, you can follow the following steps.
|
||||
|
||||
1. Create a new file `/Path/to/metrics/custom_metric.py`, implement the `process`, `compute_metrics` and `evaluate` methods, `evaluate` method is optional.
|
||||
|
||||
2. Import the new metric in your code or config file.
|
||||
|
||||
```python
|
||||
from path.to.metrics import CustomMetric
|
||||
```
|
||||
|
||||
or
|
||||
|
||||
```python
|
||||
custom_imports = dict(imports=['/Path/to/metrics'], allow_failed_imports=False)
|
||||
|
||||
val_evaluator = dict(type='CustomMetric', arg1=xxx, arg2=xxx)
|
||||
test_evaluator = dict(type='CustomMetric', arg1=xxx, arg2=xxx)
|
||||
```
|
||||
260
Seg_All_In_One_MMSeg/docs/en/advanced_guides/add_models.md
Normal file
260
Seg_All_In_One_MMSeg/docs/en/advanced_guides/add_models.md
Normal file
@@ -0,0 +1,260 @@
|
||||
# Add New Modules
|
||||
|
||||
## Develop new components
|
||||
|
||||
We can customize all the components introduced at [the model documentation](./models.md), such as **backbone**, **head**, **loss function** and **data preprocessor**.
|
||||
|
||||
### Add new backbones
|
||||
|
||||
Here we show how to develop a new backbone with an example of MobileNet.
|
||||
|
||||
1. Create a new file `mmseg/models/backbones/mobilenet.py`.
|
||||
|
||||
```python
|
||||
import torch.nn as nn
|
||||
|
||||
from mmseg.registry import MODELS
|
||||
|
||||
|
||||
@MODELS.register_module()
|
||||
class MobileNet(nn.Module):
|
||||
|
||||
def __init__(self, arg1, arg2):
|
||||
pass
|
||||
|
||||
def forward(self, x): # should return a tuple
|
||||
pass
|
||||
|
||||
def init_weights(self, pretrained=None):
|
||||
pass
|
||||
```
|
||||
|
||||
2. Import the module in `mmseg/models/backbones/__init__.py`.
|
||||
|
||||
```python
|
||||
from .mobilenet import MobileNet
|
||||
```
|
||||
|
||||
3. Use it in your config file.
|
||||
|
||||
```python
|
||||
model = dict(
|
||||
...
|
||||
backbone=dict(
|
||||
type='MobileNet',
|
||||
arg1=xxx,
|
||||
arg2=xxx),
|
||||
...
|
||||
```
|
||||
|
||||
### Add new heads
|
||||
|
||||
In MMSegmentation, we provide a [BaseDecodeHead](https://github.com/open-mmlab/mmsegmentation/blob/main/mmseg/models/decode_heads/decode_head.py#L17) for developing all segmentation heads.
|
||||
All newly implemented decode heads should be derived from it.
|
||||
Here we show how to develop a new head with the example of [PSPNet](https://arxiv.org/abs/1612.01105) as the following.
|
||||
|
||||
First, add a new decode head in `mmseg/models/decode_heads/psp_head.py`.
|
||||
PSPNet implements a decode head for segmentation decode.
|
||||
To implement a decode head, we need to implement three functions of the new module as the following.
|
||||
|
||||
```python
|
||||
from mmseg.registry import MODELS
|
||||
|
||||
@MODELS.register_module()
|
||||
class PSPHead(BaseDecodeHead):
|
||||
|
||||
def __init__(self, pool_scales=(1, 2, 3, 6), **kwargs):
|
||||
super(PSPHead, self).__init__(**kwargs)
|
||||
|
||||
def init_weights(self):
|
||||
pass
|
||||
|
||||
def forward(self, inputs):
|
||||
pass
|
||||
```
|
||||
|
||||
Next, the users need to add the module in the `mmseg/models/decode_heads/__init__.py`, thus the corresponding registry could find and load them.
|
||||
|
||||
To config file of PSPNet is as the following
|
||||
|
||||
```python
|
||||
norm_cfg = dict(type='SyncBN', requires_grad=True)
|
||||
model = dict(
|
||||
type='EncoderDecoder',
|
||||
pretrained='pretrain_model/resnet50_v1c_trick-2cccc1ad.pth',
|
||||
backbone=dict(
|
||||
type='ResNetV1c',
|
||||
depth=50,
|
||||
num_stages=4,
|
||||
out_indices=(0, 1, 2, 3),
|
||||
dilations=(1, 1, 2, 4),
|
||||
strides=(1, 2, 1, 1),
|
||||
norm_cfg=norm_cfg,
|
||||
norm_eval=False,
|
||||
style='pytorch',
|
||||
contract_dilation=True),
|
||||
decode_head=dict(
|
||||
type='PSPHead',
|
||||
in_channels=2048,
|
||||
in_index=3,
|
||||
channels=512,
|
||||
pool_scales=(1, 2, 3, 6),
|
||||
dropout_ratio=0.1,
|
||||
num_classes=19,
|
||||
norm_cfg=norm_cfg,
|
||||
align_corners=False,
|
||||
loss_decode=dict(
|
||||
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)))
|
||||
|
||||
```
|
||||
|
||||
### Add new loss
|
||||
|
||||
Assume you want to add a new loss as `MyLoss` for segmentation decode.
|
||||
To add a new loss function, the users need to implement it in `mmseg/models/losses/my_loss.py`.
|
||||
The decorator `weighted_loss` enables the loss to be weighted for each element.
|
||||
|
||||
```python
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
|
||||
from mmseg.registry import MODELS
|
||||
from .utils import weighted_loss
|
||||
|
||||
@weighted_loss
|
||||
def my_loss(pred, target):
|
||||
assert pred.size() == target.size() and target.numel() > 0
|
||||
loss = torch.abs(pred - target)
|
||||
return loss
|
||||
|
||||
@MODELS.register_module()
|
||||
class MyLoss(nn.Module):
|
||||
|
||||
def __init__(self, reduction='mean', loss_weight=1.0):
|
||||
super(MyLoss, self).__init__()
|
||||
self.reduction = reduction
|
||||
self.loss_weight = loss_weight
|
||||
|
||||
def forward(self,
|
||||
pred,
|
||||
target,
|
||||
weight=None,
|
||||
avg_factor=None,
|
||||
reduction_override=None):
|
||||
assert reduction_override in (None, 'none', 'mean', 'sum')
|
||||
reduction = (
|
||||
reduction_override if reduction_override else self.reduction)
|
||||
loss = self.loss_weight * my_loss(
|
||||
pred, target, weight, reduction=reduction, avg_factor=avg_factor)
|
||||
return loss
|
||||
```
|
||||
|
||||
Then the users need to add it in the `mmseg/models/losses/__init__.py`.
|
||||
|
||||
```python
|
||||
from .my_loss import MyLoss, my_loss
|
||||
|
||||
```
|
||||
|
||||
To use it, modify the `loss_xxx` field.
|
||||
Then you need to modify the `loss_decode` field in the head.
|
||||
`loss_weight` could be used to balance multiple losses.
|
||||
|
||||
```python
|
||||
loss_decode=dict(type='MyLoss', loss_weight=1.0))
|
||||
```
|
||||
|
||||
### Add new data preprocessor
|
||||
|
||||
In MMSegmentation 1.x versions, we use [SegDataPreProcessor](https://github.com/open-mmlab/mmsegmentation/blob/main/mmseg/models/data_preprocessor.py#L13) to copy data to the target device and preprocess the data into the model input format as default. Here we show how to develop a new data preprocessor.
|
||||
|
||||
1. Create a new file `mmseg/models/my_datapreprocessor.py`.
|
||||
|
||||
```python
|
||||
from mmengine.model import BaseDataPreprocessor
|
||||
|
||||
from mmseg.registry import MODELS
|
||||
|
||||
@MODELS.register_module()
|
||||
class MyDataPreProcessor(BaseDataPreprocessor):
|
||||
def __init__(self, **kwargs):
|
||||
super().__init__(**kwargs)
|
||||
|
||||
def forward(self, data: dict, training: bool=False) -> Dict[str, Any]:
|
||||
# TODO Define the logic for data pre-processing in the forward method
|
||||
pass
|
||||
```
|
||||
|
||||
2. Import your data preprocessor in `mmseg/models/__init__.py`
|
||||
|
||||
```python
|
||||
from .my_datapreprocessor import MyDataPreProcessor
|
||||
```
|
||||
|
||||
3. Use it in your config file.
|
||||
|
||||
```python
|
||||
model = dict(
|
||||
data_preprocessor=dict(type='MyDataPreProcessor)
|
||||
...
|
||||
)
|
||||
```
|
||||
|
||||
## Develop new segmentors
|
||||
|
||||
The segmentor is an algorithmic architecture in which users can customize their algorithms by adding customized components and defining the logic of algorithm execution. Please refer to [the model document](./models.md) for more details.
|
||||
|
||||
Since the [BaseSegmentor](https://github.com/open-mmlab/mmsegmentation/blob/main/mmseg/models/segmentors/base.py#L15) in MMSegmentation unifies three modes for a forward process, to develop a new segmentor, users need to overwrite `loss`, `predict` and `_forward` methods corresponding to the `loss`, `predict` and `tensor` modes.
|
||||
|
||||
Here we show how to develop a new segmentor.
|
||||
|
||||
1. Create a new file `mmseg/models/segmentors/my_segmentor.py`.
|
||||
|
||||
```python
|
||||
from typing import Dict, Optional, Union
|
||||
|
||||
import torch
|
||||
|
||||
from mmseg.registry import MODELS
|
||||
from mmseg.models import BaseSegmentor
|
||||
|
||||
@MODELS.register_module()
|
||||
class MySegmentor(BaseSegmentor):
|
||||
def __init__(self, **kwargs):
|
||||
super().__init__(**kwargs)
|
||||
# TODO users should build components of the network here
|
||||
|
||||
def loss(self, inputs: Tensor, data_samples: SampleList) -> dict:
|
||||
"""Calculate losses from a batch of inputs and data samples."""
|
||||
pass
|
||||
|
||||
def predict(self, inputs: Tensor, data_samples: OptSampleList=None) -> SampleList:
|
||||
"""Predict results from a batch of inputs and data samples with post-
|
||||
processing."""
|
||||
pass
|
||||
|
||||
def _forward(self,
|
||||
inputs: Tensor,
|
||||
data_samples: OptSampleList = None) -> Tuple[List[Tensor]]:
|
||||
"""Network forward process.
|
||||
|
||||
Usually includes backbone, neck and head forward without any post-
|
||||
processing.
|
||||
"""
|
||||
pass
|
||||
```
|
||||
|
||||
2. Import your segmentor in `mmseg/models/segmentors/__init__.py`.
|
||||
|
||||
```python
|
||||
from .my_segmentor import MySegmentor
|
||||
```
|
||||
|
||||
3. Use it in your config file.
|
||||
|
||||
```python
|
||||
model = dict(
|
||||
type='MySegmentor'
|
||||
...
|
||||
)
|
||||
```
|
||||
@@ -0,0 +1,52 @@
|
||||
# Adding New Data Transforms
|
||||
|
||||
## Customization data transformation
|
||||
|
||||
The customized data transformation must inherited from `BaseTransform` and implement `transform` function.
|
||||
Here we use a simple flipping transformation as example:
|
||||
|
||||
```python
|
||||
import random
|
||||
import mmcv
|
||||
from mmcv.transforms import BaseTransform, TRANSFORMS
|
||||
|
||||
@TRANSFORMS.register_module()
|
||||
class MyFlip(BaseTransform):
|
||||
def __init__(self, direction: str):
|
||||
super().__init__()
|
||||
self.direction = direction
|
||||
|
||||
def transform(self, results: dict) -> dict:
|
||||
img = results['img']
|
||||
results['img'] = mmcv.imflip(img, direction=self.direction)
|
||||
return results
|
||||
```
|
||||
|
||||
Moreover, import the new class.
|
||||
|
||||
```python
|
||||
from .my_pipeline import MyFlip
|
||||
```
|
||||
|
||||
Thus, we can instantiate a `MyFlip` object and use it to process the data dict.
|
||||
|
||||
```python
|
||||
import numpy as np
|
||||
|
||||
transform = MyFlip(direction='horizontal')
|
||||
data_dict = {'img': np.random.rand(224, 224, 3)}
|
||||
data_dict = transform(data_dict)
|
||||
processed_img = data_dict['img']
|
||||
```
|
||||
|
||||
Or, we can use `MyFlip` transformation in data pipeline in our config file.
|
||||
|
||||
```python
|
||||
pipeline = [
|
||||
...
|
||||
dict(type='MyFlip', direction='horizontal'),
|
||||
...
|
||||
]
|
||||
```
|
||||
|
||||
Note that if you want to use `MyFlip` in config, you must ensure the file containing `MyFlip` is imported during runtime.
|
||||
@@ -0,0 +1,168 @@
|
||||
# Customize Runtime Settings
|
||||
|
||||
## Customize hooks
|
||||
|
||||
### Step 1: Implement a new hook
|
||||
|
||||
MMEngine has implemented commonly used [hooks](https://github.com/open-mmlab/mmengine/blob/main/docs/en/tutorials/hook.md) for training and test,
|
||||
When users have requirements for customization, they can follow examples below.
|
||||
For example, if some hyper-parameter of the model needs to be changed when model training, we can implement a new hook for it:
|
||||
|
||||
```python
|
||||
# Copyright (c) OpenMMLab. All rights reserved.
|
||||
from typing import Optional, Sequence
|
||||
|
||||
from mmengine.hooks import Hook
|
||||
from mmengine.model import is_model_wrapper
|
||||
|
||||
from mmseg.registry import HOOKS
|
||||
|
||||
|
||||
@HOOKS.register_module()
|
||||
class NewHook(Hook):
|
||||
"""Docstring for NewHook.
|
||||
"""
|
||||
|
||||
def __init__(self, a: int, b: int) -> None:
|
||||
self.a = a
|
||||
self.b = b
|
||||
|
||||
def before_train_iter(self,
|
||||
runner,
|
||||
batch_idx: int,
|
||||
data_batch: Optional[Sequence[dict]] = None) -> None:
|
||||
cur_iter = runner.iter
|
||||
# acquire this model when it is in a wrapper
|
||||
if is_model_wrapper(runner.model):
|
||||
model = runner.model.module
|
||||
model.hyper_parameter = self.a * cur_iter + self.b
|
||||
```
|
||||
|
||||
### Step 2: Import a new hook
|
||||
|
||||
The module which is defined above needs to be imported into main namespace first to ensure being registered.
|
||||
We assume `NewHook` is implemented in `mmseg/engine/hooks/new_hook.py`, there are two ways to import it:
|
||||
|
||||
- Import it by modifying `mmseg/engine/hooks/__init__.py`.
|
||||
Modules should be imported in `mmseg/engine/hooks/__init__.py` thus these new modules can be found and added by registry.
|
||||
|
||||
```python
|
||||
from .new_hook import NewHook
|
||||
|
||||
__all__ = [..., NewHook]
|
||||
```
|
||||
|
||||
- Import it manually by `custom_imports` in config file.
|
||||
|
||||
```python
|
||||
custom_imports = dict(imports=['mmseg.engine.hooks.new_hook'], allow_failed_imports=False)
|
||||
```
|
||||
|
||||
### Step 3: Modify config file
|
||||
|
||||
Users can set and use customized hooks in training and test followed methods below.
|
||||
The execution priority of hooks at the same place of `Runner` can be referred [here](https://github.com/open-mmlab/mmengine/blob/main/docs/en/tutorials/hook.md#built-in-hooks),
|
||||
Default priority of customized hook is `NORMAL`.
|
||||
|
||||
```python
|
||||
custom_hooks = [
|
||||
dict(type='NewHook', a=a_value, b=b_value, priority='ABOVE_NORMAL')
|
||||
]
|
||||
```
|
||||
|
||||
## Customize optimizer
|
||||
|
||||
### Step 1: Implement a new optimizer
|
||||
|
||||
We recommend the customized optimizer implemented in `mmseg/engine/optimizers/my_optimizer.py`. Here is an example of a new optimizer `MyOptimizer` which has parameters `a`, `b` and `c`:
|
||||
|
||||
```python
|
||||
from mmseg.registry import OPTIMIZERS
|
||||
from torch.optim import Optimizer
|
||||
|
||||
|
||||
@OPTIMIZERS.register_module()
|
||||
class MyOptimizer(Optimizer):
|
||||
|
||||
def __init__(self, a, b, c)
|
||||
```
|
||||
|
||||
### Step 2: Import a new optimizer
|
||||
|
||||
The module which is defined above needs to be imported into main namespace first to ensure being registered.
|
||||
We assume `MyOptimizer` is implemented in `mmseg/engine/optimizers/my_optimizer.py`, there are two ways to import it:
|
||||
|
||||
- Import it by modifying `mmseg/engine/optimizers/__init__.py`.
|
||||
Modules should be imported in `mmseg/engine/optimizers/__init__.py` thus these new modules can be found and added by registry.
|
||||
|
||||
```python
|
||||
from .my_optimizer import MyOptimizer
|
||||
```
|
||||
|
||||
- Import it manually by `custom_imports` in config file.
|
||||
|
||||
```python
|
||||
custom_imports = dict(imports=['mmseg.engine.optimizers.my_optimizer'], allow_failed_imports=False)
|
||||
```
|
||||
|
||||
### Step 3: Modify config file
|
||||
|
||||
Then it needs to modify `optimizer` in `optim_wrapper` of config file, if users want to use customized `MyOptimizer`, it can be modified as:
|
||||
|
||||
```python
|
||||
optim_wrapper = dict(type='OptimWrapper',
|
||||
optimizer=dict(type='MyOptimizer',
|
||||
a=a_value, b=b_value, c=c_value),
|
||||
clip_grad=None)
|
||||
```
|
||||
|
||||
## Customize optimizer constructor
|
||||
|
||||
### Step 1: Implement a new optimizer constructor
|
||||
|
||||
Optimizer constructor is used to create optimizer and optimizer wrapper for model training, which has powerful functions like specifying learning rate and weight decay for different model layers.
|
||||
Here is an example for a customized optimizer constructor.
|
||||
|
||||
```python
|
||||
from mmengine.optim import DefaultOptimWrapperConstructor
|
||||
from mmseg.registry import OPTIM_WRAPPER_CONSTRUCTORS
|
||||
|
||||
@OPTIM_WRAPPER_CONSTRUCTORS.register_module()
|
||||
class LearningRateDecayOptimizerConstructor(DefaultOptimWrapperConstructor):
|
||||
def __init__(self, optim_wrapper_cfg, paramwise_cfg=None):
|
||||
|
||||
def __call__(self, model):
|
||||
|
||||
return my_optimizer
|
||||
```
|
||||
|
||||
Default optimizer constructor is implemented [here](https://github.com/open-mmlab/mmengine/blob/main/mmengine/optim/optimizer/default_constructor.py#L19).
|
||||
It can also be used as base class of new optimizer constructor.
|
||||
|
||||
### Step 2: Import a new optimizer constructor
|
||||
|
||||
The module which is defined above needs to be imported into main namespace first to ensure being registered.
|
||||
We assume `MyOptimizerConstructor` is implemented in `mmseg/engine/optimizers/my_optimizer_constructor.py`, there are two ways to import it:
|
||||
|
||||
- Import it by modifying `mmseg/engine/optimizers/__init__.py`.
|
||||
Modules should be imported in `mmseg/engine/optimizers/__init__.py` thus these new modules can be found and added by registry.
|
||||
|
||||
```python
|
||||
from .my_optimizer_constructor import MyOptimizerConstructor
|
||||
```
|
||||
|
||||
- Import it manually by `custom_imports` in config file.
|
||||
|
||||
```python
|
||||
custom_imports = dict(imports=['mmseg.engine.optimizers.my_optimizer_constructor'], allow_failed_imports=False)
|
||||
```
|
||||
|
||||
### Step 3: Modify config file
|
||||
|
||||
Then it needs to modify `constructor` in `optim_wrapper` of config file, if users want to use customized `MyOptimizerConstructor`, it can be modified as:
|
||||
|
||||
```python
|
||||
optim_wrapper = dict(type='OptimWrapper',
|
||||
constructor='MyOptimizerConstructor',
|
||||
clip_grad=None)
|
||||
```
|
||||
87
Seg_All_In_One_MMSeg/docs/en/advanced_guides/data_flow.md
Normal file
87
Seg_All_In_One_MMSeg/docs/en/advanced_guides/data_flow.md
Normal file
@@ -0,0 +1,87 @@
|
||||
# Dataflow
|
||||
|
||||
In this chapter, we will introduce the dataflow and data format convention between the internal modules managed by the [Runner](https://mmengine.readthedocs.io/en/latest/tutorials/runner.html).
|
||||
|
||||
## Overview of dataflow
|
||||
|
||||
The [Runner](https://github.com/open-mmlab/mmengine/blob/main/docs/en/design/runner.md) is an "integrator" in MMEngine. It covers all aspects of the framework and shoulders the responsibility of organizing and scheduling nearly all modules, that means the dataflow between all modules also controlled by the `Runner`. As illustrated in the [Runner document of MMEngine](https://mmengine.readthedocs.io/en/latest/tutorials/runner.html), the following diagram shows the basic dataflow.
|
||||
|
||||
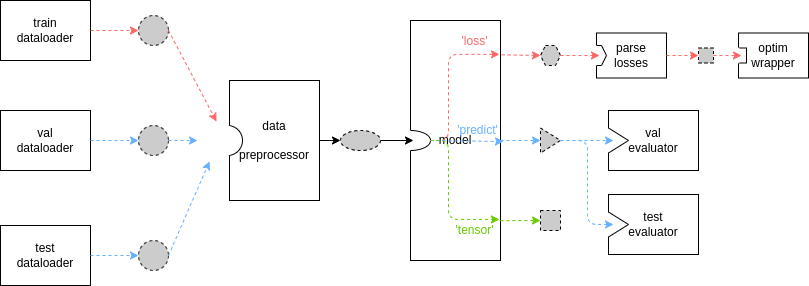
|
||||
|
||||
The dashed border, gray filled shapes represent different data formats, while solid boxes represent modules/methods. Due to the great flexibility and extensibility of MMEngine, some critical base classes can be inherited and their methods can be overridden. The diagram above only holds when users are not customizing `TrainLoop`, `ValLoop`, and `TestLoop` in `Runner`, and are not overriding `train_step`, `val_step` and `test_step` method in their custom model. The default setting of loops in MMSegmentation is as follows, it uses `IterBasedTrainLoop` to train models with 20000 iterations in total and do evaluation each 2000 iterations.
|
||||
|
||||
```python
|
||||
train_cfg = dict(type='IterBasedTrainLoop', max_iters=20000, val_interval=2000)
|
||||
val_cfg = dict(type='ValLoop')
|
||||
test_cfg = dict(type='TestLoop')
|
||||
```
|
||||
|
||||
In the above diagram, the red line indicates the [train_step](./models.md#train_step). At each training iteration, dataloader loads images from storage and transfer to data preprocessor, data preprocessor would put images to the specific device and stack data to batch, then model accepts the batch data as inputs, finally the outputs of the model would be sent to optimizer. The blue line indicates [val_step](./models.md#val_step) and [test_step](./models.md#test_step). The dataflow of these two process is similar to the `train_step` except the outputs of model, since model parameters are freezed when doing evaluation, the model output would be transferred to [Evaluator](./evaluation.md#ioumetric) to compute metrics.
|
||||
|
||||
## Dataflow convention in MMSegmentation
|
||||
|
||||
From the diagram above, we could see the basic dataflow. In this section, we would introduce format convention of data involved in this dataflow, respectively.
|
||||
|
||||
### DataLoader to Data Preprocessor
|
||||
|
||||
DataLoader is an essential component in training and testing pipelines of MMEngine. Conceptually, it is derived from and consistent with [PyTorch](https://pytorch.org/). DataLoader loads data from filesystem and the original data passes through data preparation pipeline, then it would be sent to Data Preprocessor.
|
||||
|
||||
MMSegmentation defines the default data format at [PackSegInputs](https://github.com/open-mmlab/mmsegmentation/blob/main/mmseg/datasets/transforms/formatting.py#L12), it's the last component of `train_pipeline` and `test_pipeline`. Please refer to [data transform documentation](./transforms.md) for more information about data transform `pipeline`.
|
||||
|
||||
Without any modifications, the return value of PackSegInputs is usually a `dict` and has only two keys, `inputs` and `data_samples`. The following pseudo-code shows the data types of the data loader output in mmseg, which is a batch of fetched data samples from the dataset, and data loader packs them into a dictionary of the list. `inputs` is the list of input tensors to the model and `data_samples` contains a list of input images' meta information and corresponding ground truth.
|
||||
|
||||
```python
|
||||
dict(
|
||||
inputs=List[torch.Tensor],
|
||||
data_samples=List[SegDataSample]
|
||||
)
|
||||
```
|
||||
|
||||
**Note:** [SegDataSample](https://github.com/open-mmlab/mmsegmentation/blob/1.x/mmseg/structures/seg_data_sample.py) is a data structure interface of MMSegmentation, it is used as an interface between different components. `SegDataSample` implements the abstract data element `mmengine.structures.BaseDataElement`, please refer to [the SegDataSample documentation](./structures.md) and [data element documentation](https://mmengine.readthedocs.io/en/latest/advanced_tutorials/data_element.html) in [MMEngine](https://github.com/open-mmlab/mmengine) for more information.
|
||||
|
||||
### Data Preprocessor to Model
|
||||
|
||||
Though drawn separately in the diagram [above](#overview-of-dataflow), data_preprocessor is a part of the model and thus can be found in [Model tutorial](./models.md) at data preprocessor chapter.
|
||||
|
||||
The return value of data preprocessor is a dictionary, containing `inputs` and `data_samples`, `inputs` is batched images, a 4D tensor, and some additional meta info used in data preprocesses would be added to the `data_samples`. When transferred to the network, the dictionary would be unpacked to two values. The following pseudo-codes show the return value of the data preprocessor and the input values of model.
|
||||
|
||||
```python
|
||||
dict(
|
||||
inputs=torch.Tensor,
|
||||
data_samples=List[SegDataSample]
|
||||
)
|
||||
```
|
||||
|
||||
```python
|
||||
class Network(BaseSegmentor):
|
||||
|
||||
def forward(self, inputs: torch.Tensor, data_samples: List[SegDataSample], mode: str):
|
||||
pass
|
||||
```
|
||||
|
||||
**Note:** Model forward has 3 kinds of mode, which is controlled by input argumentmode, please refer [model tutorial](./models.md) for more details.
|
||||
|
||||
### Model output
|
||||
|
||||
As [model tutorial](./models.md#forward) mentioned 3 kinds of mode forward with 3 kinds of output. `train_step`and `test_step`(or `val_step`) correspond to `'loss'` and `'predict'` respectively.
|
||||
|
||||
In `test_step` or `val_step`, the inference results would be transferred to `Evaluator`. You might read the [evaluation document](./evaluation.md) for more information about `Evaluator`.
|
||||
|
||||
After inference, the [BaseSegmentor](https://github.com/open-mmlab/mmsegmentation/blob/main/mmseg/models/segmentors/base.py#L15) in MMSegmentation would do a simple post process to pack inference results, the segmentation logits produced by the neural network, segmentation mask after the `argmax` operation and ground truth(if exists) would be packed into a similar `SegDataSample` instance. The return value of [postprocess_result](https://github.com/open-mmlab/mmsegmentation/blob/main/mmseg/models/segmentors/base.py#L132) is a **`List` of `SegDataSample`**. Following diagram shows the key properties of these `SegDataSample` instances.
|
||||
|
||||

|
||||
|
||||
The same as Data Preprocessor, loss function is also a part of the model, it's a property of [decode head](https://github.com/open-mmlab/mmsegmentation/blob/main/mmseg/models/decode_heads/decode_head.py#L142).
|
||||
|
||||
In MMSegmentation, the method [loss_by_feat](https://github.com/open-mmlab/mmsegmentation/blob/main/mmseg/models/decode_heads/decode_head.py#L291) of `decode_head` is an unified interface used to compute loss.
|
||||
|
||||
Parameters:
|
||||
|
||||
- seg_logits (Tensor): The output from decode head forward function.
|
||||
- batch_data_samples (List\[:obj:`SegDataSample`\]): The seg data samples. It usually includes information such as `metainfo` and `gt_sem_seg`.
|
||||
|
||||
Returns:
|
||||
|
||||
- dict\[str, Tensor\]: a dictionary of loss components
|
||||
|
||||
**Note:** The `train_step` transfers the loss into OptimWrapper to update the weights in model, please refer [train_step](./models.md#train_step) for more details.
|
||||
386
Seg_All_In_One_MMSeg/docs/en/advanced_guides/datasets.md
Normal file
386
Seg_All_In_One_MMSeg/docs/en/advanced_guides/datasets.md
Normal file
@@ -0,0 +1,386 @@
|
||||
# Dataset
|
||||
|
||||
Dataset classes in MMSegmentation have two functions: (1) load data information after [data preparation](../user_guides/2_dataset_prepare.md)
|
||||
and (2) send data into [dataset transform pipeline](https://github.com/open-mmlab/mmsegmentation/blob/main/mmseg/datasets/basesegdataset.py#L141) to do [data augmentation](./transforms.md).
|
||||
There are 2 kinds of loaded information: (1) meta information which is original dataset information such as categories (classes) of dataset and their corresponding palette information, (2) data information which includes
|
||||
the path of dataset images and labels.
|
||||
The tutorial includes some main interfaces in MMSegmentation 1.x dataset class: methods of loading data information and modifying dataset classes in base dataset class, and the relationship between dataset and the data transform pipeline.
|
||||
|
||||
## Main Interfaces
|
||||
|
||||
Take Cityscapes as an example, if you want to run the example, please download and [preprocess](../user_guides/2_dataset_prepare.md#cityscapes)
|
||||
Cityscapes dataset in `data` directory, before running the demo code:
|
||||
|
||||
Instantiate Cityscapes training dataset:
|
||||
|
||||
```python
|
||||
from mmseg.datasets import CityscapesDataset
|
||||
from mmengine.registry import init_default_scope
|
||||
init_default_scope('mmseg')
|
||||
|
||||
data_root = 'data/cityscapes/'
|
||||
data_prefix=dict(img_path='leftImg8bit/train', seg_map_path='gtFine/train')
|
||||
train_pipeline = [
|
||||
dict(type='LoadImageFromFile'),
|
||||
dict(type='LoadAnnotations'),
|
||||
dict(type='RandomCrop', crop_size=(512, 1024), cat_max_ratio=0.75),
|
||||
dict(type='RandomFlip', prob=0.5),
|
||||
dict(type='PackSegInputs')
|
||||
]
|
||||
|
||||
dataset = CityscapesDataset(data_root=data_root, data_prefix=data_prefix, test_mode=False, pipeline=train_pipeline)
|
||||
```
|
||||
|
||||
Get the length of training set:
|
||||
|
||||
```python
|
||||
print(len(dataset))
|
||||
|
||||
2975
|
||||
```
|
||||
|
||||
Get data information: The type of data information is `dict` which includes several keys:
|
||||
|
||||
- `'img_path'`: path of images
|
||||
- `'seg_map_path'`: path of segmentation labels
|
||||
- `'seg_fields'`: saving label fields
|
||||
- `'sample_idx'`: the index of the current sample
|
||||
|
||||
There are also `'label_map'` and `'reduce_zero_label'` whose functions would be introduced in the next section.
|
||||
|
||||
```python
|
||||
# Acquire data information of first sample in dataset
|
||||
print(dataset.get_data_info(0))
|
||||
|
||||
{'img_path': 'data/cityscapes/leftImg8bit/train/aachen/aachen_000000_000019_leftImg8bit.png',
|
||||
'seg_map_path': 'data/cityscapes/gtFine/train/aachen/aachen_000000_000019_gtFine_labelTrainIds.png',
|
||||
'label_map': None,
|
||||
'reduce_zero_label': False,
|
||||
'seg_fields': [],
|
||||
'sample_idx': 0}
|
||||
```
|
||||
|
||||
Get dataset meta information: the type of MMSegmentation meta information is also `dict`, which includes `'classes'` field for dataset classes and `'palette'` field for corresponding colors in visualization, and has `'label_map'` field and `'reduce_zero_label'` filed.
|
||||
|
||||
```python
|
||||
print(dataset.metainfo)
|
||||
|
||||
{'classes': ('road',
|
||||
'sidewalk',
|
||||
'building',
|
||||
'wall',
|
||||
'fence',
|
||||
'pole',
|
||||
'traffic light',
|
||||
'traffic sign',
|
||||
'vegetation',
|
||||
'terrain',
|
||||
'sky',
|
||||
'person',
|
||||
'rider',
|
||||
'car',
|
||||
'truck',
|
||||
'bus',
|
||||
'train',
|
||||
'motorcycle',
|
||||
'bicycle'),
|
||||
'palette': [[128, 64, 128],
|
||||
[244, 35, 232],
|
||||
[70, 70, 70],
|
||||
[102, 102, 156],
|
||||
[190, 153, 153],
|
||||
[153, 153, 153],
|
||||
[250, 170, 30],
|
||||
[220, 220, 0],
|
||||
[107, 142, 35],
|
||||
[152, 251, 152],
|
||||
[70, 130, 180],
|
||||
[220, 20, 60],
|
||||
[255, 0, 0],
|
||||
[0, 0, 142],
|
||||
[0, 0, 70],
|
||||
[0, 60, 100],
|
||||
[0, 80, 100],
|
||||
[0, 0, 230],
|
||||
[119, 11, 32]],
|
||||
'label_map': None,
|
||||
'reduce_zero_label': False}
|
||||
```
|
||||
|
||||
The return value of dataset `__getitem__` method is the output of data samples after data augmentation, whose type is also `dict`. It has two fields: `'inputs'` corresponding to images after data augmentation,
|
||||
and `'data_samples'` corresponding to [`SegDataSample`](./structures.md) which is new data structures in MMSegmentation 1.x,
|
||||
and `gt_sem_seg` of `SegDataSample` has labels after data augmentation operations.
|
||||
|
||||
```python
|
||||
print(dataset[0])
|
||||
|
||||
{'inputs': tensor([[[131, 130, 130, ..., 23, 23, 23],
|
||||
[132, 132, 132, ..., 23, 22, 23],
|
||||
[134, 133, 133, ..., 23, 23, 23],
|
||||
...,
|
||||
[ 66, 67, 67, ..., 71, 71, 71],
|
||||
[ 66, 67, 66, ..., 68, 68, 68],
|
||||
[ 67, 67, 66, ..., 70, 70, 70]],
|
||||
|
||||
[[143, 143, 142, ..., 28, 28, 29],
|
||||
[145, 145, 145, ..., 28, 28, 29],
|
||||
[145, 145, 145, ..., 27, 28, 29],
|
||||
...,
|
||||
[ 75, 75, 76, ..., 80, 81, 81],
|
||||
[ 75, 76, 75, ..., 80, 80, 80],
|
||||
[ 77, 76, 76, ..., 82, 82, 82]],
|
||||
|
||||
[[126, 125, 126, ..., 21, 21, 22],
|
||||
[127, 127, 128, ..., 21, 21, 22],
|
||||
[127, 127, 126, ..., 21, 21, 22],
|
||||
...,
|
||||
[ 63, 63, 64, ..., 69, 69, 70],
|
||||
[ 64, 65, 64, ..., 69, 69, 69],
|
||||
[ 65, 66, 66, ..., 72, 71, 71]]], dtype=torch.uint8),
|
||||
'data_samples': <SegDataSample(
|
||||
|
||||
META INFORMATION
|
||||
img_path: 'data/cityscapes/leftImg8bit/train/aachen/aachen_000000_000019_leftImg8bit.png'
|
||||
seg_map_path: 'data/cityscapes/gtFine/train/aachen/aachen_000000_000019_gtFine_labelTrainIds.png'
|
||||
img_shape: (512, 1024, 3)
|
||||
flip_direction: None
|
||||
ori_shape: (1024, 2048)
|
||||
flip: False
|
||||
|
||||
DATA FIELDS
|
||||
gt_sem_seg: <PixelData(
|
||||
|
||||
META INFORMATION
|
||||
|
||||
DATA FIELDS
|
||||
data: tensor([[[2, 2, 2, ..., 8, 8, 8],
|
||||
[2, 2, 2, ..., 8, 8, 8],
|
||||
[2, 2, 2, ..., 8, 8, 8],
|
||||
...,
|
||||
[0, 0, 0, ..., 0, 0, 0],
|
||||
[0, 0, 0, ..., 0, 0, 0],
|
||||
[0, 0, 0, ..., 0, 0, 0]]])
|
||||
)>
|
||||
_gt_sem_seg: <PixelData(
|
||||
|
||||
META INFORMATION
|
||||
|
||||
DATA FIELDS
|
||||
data: tensor([[[2, 2, 2, ..., 8, 8, 8],
|
||||
[2, 2, 2, ..., 8, 8, 8],
|
||||
[2, 2, 2, ..., 8, 8, 8],
|
||||
...,
|
||||
[0, 0, 0, ..., 0, 0, 0],
|
||||
[0, 0, 0, ..., 0, 0, 0],
|
||||
[0, 0, 0, ..., 0, 0, 0]]])
|
||||
)>
|
||||
)}
|
||||
```
|
||||
|
||||
## BaseSegDataset
|
||||
|
||||
As mentioned above, dataset classes have the same functions, we implemented [`BaseSegDataset`](https://mmsegmentation.readthedocs.io/en/latest/api.html?highlight=BaseSegDataset#mmseg.datasets.BaseSegDataset) to reues the common functions.
|
||||
It inherits [`BaseDataset` of MMEngine](https://github.com/open-mmlab/mmengine/blob/main/docs/en/advanced_tutorials/basedataset.md) and follows unified initialization process of OpenMMLab. It supports the highly effective interior storing format, some functions like
|
||||
dataset concatenation and repeatedly sampling. In MMSegmentation `BaseSegDataset`, the **method of loading data information** (`load_data_list`) is redefined and adds new `get_label_map` method to **modify dataset classes information**.
|
||||
|
||||
### Loading Dataset Information
|
||||
|
||||
The loaded data information includes the path of images samples and annotations samples, the detailed implementation could be found in
|
||||
[`load_data_list`](https://github.com/open-mmlab/mmsegmentation/blob/main/mmseg/datasets/basesegdataset.py#L231) of `BaseSegDataset` in MMSegmentation.
|
||||
There are two main methods to acquire the path of images and labels:
|
||||
|
||||
1. Load file paths according to the dirictory and suffix of input images and annotations
|
||||
|
||||
If the dataset directory structure is organized as below, the [`load_data_list`](https://github.com/open-mmlab/mmsegmentation/blob/main/mmseg/datasets/basesegdataset.py#L231) can parse dataset directory Structure:
|
||||
|
||||
```
|
||||
├── data
|
||||
│ ├── my_dataset
|
||||
│ │ ├── img_dir
|
||||
│ │ │ ├── train
|
||||
│ │ │ │ ├── xxx{img_suffix}
|
||||
│ │ │ │ ├── yyy{img_suffix}
|
||||
│ │ │ ├── val
|
||||
│ │ │ │ ├── zzz{img_suffix}
|
||||
│ │ ├── ann_dir
|
||||
│ │ │ ├── train
|
||||
│ │ │ │ ├── xxx{seg_map_suffix}
|
||||
│ │ │ │ ├── yyy{seg_map_suffix}
|
||||
│ │ │ ├── val
|
||||
│ │ │ │ ├── zzz{seg_map_suffix}
|
||||
```
|
||||
|
||||
Here is an example pf ADE20K, and below the directory structure of the dataset:
|
||||
|
||||
```
|
||||
├── ade
|
||||
│ ├── ADEChallengeData2016
|
||||
│ │ ├── annotations
|
||||
│ │ │ ├── training
|
||||
│ │ │ │ ├── ADE_train_00000001.png
|
||||
│ │ │ │ ├── ...
|
||||
│ │ │ │── validation
|
||||
│ │ │ │ ├── ADE_val_00000001.png
|
||||
│ │ │ │ ├── ...
|
||||
│ │ ├── images
|
||||
│ │ │ ├── training
|
||||
│ │ │ │ ├── ADE_train_00000001.jpg
|
||||
│ │ │ │ ├── ...
|
||||
│ │ │ ├── validation
|
||||
│ │ │ │ ├── ADE_val_00000001.jpg
|
||||
│ │ │ │ ├── ...
|
||||
```
|
||||
|
||||
```python
|
||||
from mmseg.datasets import ADE20KDataset
|
||||
|
||||
ADE20KDataset(data_root = 'data/ade/ADEChallengeData2016',
|
||||
data_prefix=dict(img_path='images/training', seg_map_path='annotations/training'),
|
||||
img_suffix='.jpg',
|
||||
seg_map_suffix='.png',
|
||||
reduce_zero_label=True)
|
||||
```
|
||||
|
||||
2. Load file paths from annotation file
|
||||
|
||||
Dataset also can load an annotation file which includes the data sample paths of dataset.
|
||||
Take PascalContext dataset instance as an example, its input annotation file is:
|
||||
|
||||
```python
|
||||
2008_000008
|
||||
...
|
||||
```
|
||||
|
||||
It needs to define `ann_file` when instantiation:
|
||||
|
||||
```python
|
||||
PascalContextDataset(data_root='data/VOCdevkit/VOC2010/',
|
||||
data_prefix=dict(img_path='JPEGImages', seg_map_path='SegmentationClassContext'),
|
||||
ann_file='ImageSets/SegmentationContext/train.txt')
|
||||
```
|
||||
|
||||
### Modification of Dataset Classes
|
||||
|
||||
- Use `metainfo` input argument
|
||||
|
||||
Meta information is defined as class variables, such as `METAINFO` variable of Cityscapes:
|
||||
|
||||
```python
|
||||
class CityscapesDataset(BaseSegDataset):
|
||||
"""Cityscapes dataset.
|
||||
|
||||
The ``img_suffix`` is fixed to '_leftImg8bit.png' and ``seg_map_suffix`` is
|
||||
fixed to '_gtFine_labelTrainIds.png' for Cityscapes dataset.
|
||||
"""
|
||||
METAINFO = dict(
|
||||
classes=('road', 'sidewalk', 'building', 'wall', 'fence', 'pole',
|
||||
'traffic light', 'traffic sign', 'vegetation', 'terrain',
|
||||
'sky', 'person', 'rider', 'car', 'truck', 'bus', 'train',
|
||||
'motorcycle', 'bicycle'),
|
||||
palette=[[128, 64, 128], [244, 35, 232], [70, 70, 70], [102, 102, 156],
|
||||
[190, 153, 153], [153, 153, 153], [250, 170,
|
||||
30], [220, 220, 0],
|
||||
[107, 142, 35], [152, 251, 152], [70, 130, 180],
|
||||
[220, 20, 60], [255, 0, 0], [0, 0, 142], [0, 0, 70],
|
||||
[0, 60, 100], [0, 80, 100], [0, 0, 230], [119, 11, 32]])
|
||||
|
||||
```
|
||||
|
||||
Here `'classes'` defines class names of Cityscapes dataset annotations, if users only concern some classes about vehicles and **ignore other classes**,
|
||||
the meta information of dataset could be modified by defined input argument `metainfo` when instantiating Cityscapes dataset:
|
||||
|
||||
```python
|
||||
from mmseg.datasets import CityscapesDataset
|
||||
|
||||
data_root = 'data/cityscapes/'
|
||||
data_prefix=dict(img_path='leftImg8bit/train', seg_map_path='gtFine/train')
|
||||
# metainfo only keep classes below:
|
||||
metainfo=dict(classes=( 'car', 'truck', 'bus', 'train', 'motorcycle', 'bicycle'))
|
||||
dataset = CityscapesDataset(data_root=data_root, data_prefix=data_prefix, metainfo=metainfo)
|
||||
|
||||
print(dataset.metainfo)
|
||||
|
||||
{'classes': ('car', 'truck', 'bus', 'train', 'motorcycle', 'bicycle'),
|
||||
'palette': [[0, 0, 142],
|
||||
[0, 0, 70],
|
||||
[0, 60, 100],
|
||||
[0, 80, 100],
|
||||
[0, 0, 230],
|
||||
[119, 11, 32],
|
||||
[128, 64, 128],
|
||||
[244, 35, 232],
|
||||
[70, 70, 70],
|
||||
[102, 102, 156],
|
||||
[190, 153, 153],
|
||||
[153, 153, 153],
|
||||
[250, 170, 30],
|
||||
[220, 220, 0],
|
||||
[107, 142, 35],
|
||||
[152, 251, 152],
|
||||
[70, 130, 180],
|
||||
[220, 20, 60],
|
||||
[255, 0, 0]],
|
||||
# pixels whose label index are 255 would be ignored when calculating loss
|
||||
'label_map': {0: 255,
|
||||
1: 255,
|
||||
2: 255,
|
||||
3: 255,
|
||||
4: 255,
|
||||
5: 255,
|
||||
6: 255,
|
||||
7: 255,
|
||||
8: 255,
|
||||
9: 255,
|
||||
10: 255,
|
||||
11: 255,
|
||||
12: 255,
|
||||
13: 0,
|
||||
14: 1,
|
||||
15: 2,
|
||||
16: 3,
|
||||
17: 4,
|
||||
18: 5},
|
||||
'reduce_zero_label': False}
|
||||
```
|
||||
|
||||
Meta information is different from default setting of Cityscapes dataset. Moreover, `label_map` field is also defined, which is used for modifying label index of each pixel on segmentation mask.
|
||||
The segmentation label would re-map class information by `label_map`, [here](https://github.com/open-mmlab/mmsegmentation/blob/main/mmseg/datasets/basesegdataset.py#L151) is detailed implementation:
|
||||
|
||||
```python
|
||||
gt_semantic_seg_copy = gt_semantic_seg.copy()
|
||||
for old_id, new_id in results['label_map'].items():
|
||||
gt_semantic_seg[gt_semantic_seg_copy == old_id] = new_id
|
||||
```
|
||||
|
||||
- Using `reduce_zero_label` input argument
|
||||
|
||||
To ignore label 0 (such as ADE20K dataset), we can use `reduce_zero_label` (default to `False`) argument of BaseSegDataset and its subclasses.
|
||||
When `reduce_zero_label` is `True`, label 0 in segmentation annotations would be set as 255 (models of MMSegmentation would ignore label 255 in calculating loss) and indices of other labels will minus 1:
|
||||
|
||||
```python
|
||||
gt_semantic_seg[gt_semantic_seg == 0] = 255
|
||||
gt_semantic_seg = gt_semantic_seg - 1
|
||||
gt_semantic_seg[gt_semantic_seg == 254] = 255
|
||||
```
|
||||
|
||||
## Dataset and Data Transform Pipeline
|
||||
|
||||
If the argument `pipeline` is defined, the return value of `__getitem__` method is after data argument.
|
||||
If dataset input argument does not define pipeline, it is the same as return value of `get_data_info` method.
|
||||
|
||||
```python
|
||||
from mmseg.datasets import CityscapesDataset
|
||||
|
||||
data_root = 'data/cityscapes/'
|
||||
data_prefix=dict(img_path='leftImg8bit/train', seg_map_path='gtFine/train')
|
||||
dataset = CityscapesDataset(data_root=data_root, data_prefix=data_prefix, test_mode=False)
|
||||
|
||||
print(dataset[0])
|
||||
|
||||
{'img_path': 'data/cityscapes/leftImg8bit/train/aachen/aachen_000000_000019_leftImg8bit.png',
|
||||
'seg_map_path': 'data/cityscapes/gtFine/train/aachen/aachen_000000_000019_gtFine_labelTrainIds.png',
|
||||
'label_map': None,
|
||||
'reduce_zero_label': False,
|
||||
'seg_fields': [],
|
||||
'sample_idx': 0}
|
||||
```
|
||||
279
Seg_All_In_One_MMSeg/docs/en/advanced_guides/engine.md
Normal file
279
Seg_All_In_One_MMSeg/docs/en/advanced_guides/engine.md
Normal file
@@ -0,0 +1,279 @@
|
||||
# Training Engine
|
||||
|
||||
MMEngine defined some [basic loop controllers](https://github.com/open-mmlab/mmengine/blob/main/mmengine/runner/loops.py) such as epoch-based training loop (`EpochBasedTrainLoop`), iteration-based training loop (`IterBasedTrainLoop`), standard validation loop (`ValLoop`), and standard testing loop (`TestLoop`).
|
||||
|
||||
OpenMMLab's algorithm libraries like MMSegmentation abstract model training, testing, and inference as `Runner` to handle. Users can use the default `Runner` in MMEngine directly or modify the `Runner` to meet customized needs. This document mainly introduces how users can configure existing running settings, hooks, and optimizers' basic concepts and usage methods.
|
||||
|
||||
## Configuring Runtime Settings
|
||||
|
||||
### Configuring Training Iterations
|
||||
|
||||
Loop controllers refer to the execution process during training, validation, and testing. `train_cfg`, `val_cfg`, and `test_cfg` are used to build these processes in the configuration file. MMSegmentation sets commonly used training iterations in `train_cfg` under the `configs/_base_/schedules` folder.
|
||||
For example, to train for 80,000 iterations using the iteration-based training loop (`IterBasedTrainLoop`) and perform validation every 8,000 iterations, you can set it as follows:
|
||||
|
||||
```python
|
||||
train_cfg = dict(type='IterBasedTrainLoop', max_iters=80000, val_interval=8000)
|
||||
```
|
||||
|
||||
### Configuring Training Optimizers
|
||||
|
||||
Here's an example of a SGD optimizer:
|
||||
|
||||
```python
|
||||
optim_wrapper = dict(
|
||||
type='OptimWrapper',
|
||||
optimizer=dict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0005),
|
||||
clip_grad=None)
|
||||
```
|
||||
|
||||
OpenMMLab supports all optimizers in PyTorch. For more details, please refer to the [MMEngine optimizer documentation](https://github.com/open-mmlab/mmengine/blob/main/docs/en/tutorials/optim_wrapper.md).
|
||||
|
||||
It is worth emphasizing that `optim_wrapper` is a variable of `runner`, so when configuring the optimizer, the field to configure is the `optim_wrapper` field. For more information on using optimizers, see the [Optimizer](#Optimizer) section below.
|
||||
|
||||
### Configuring Training Parameter Schedulers
|
||||
|
||||
Before configuring the training parameter scheduler, it is recommended to first understand the basic concepts of parameter schedulers in the [MMEngine documentation](https://github.com/open-mmlab/mmengine/blob/main/docs/en/tutorials/param_scheduler.md).
|
||||
|
||||
Here's an example of a parameter scheduler. During training, a linearly changing learning rate strategy is used for warm-up in the first 1,000 iterations. After the first 1,000 iterations until the 16,000 iterations in the end, the default polynomial learning rate decay is used:
|
||||
|
||||
```python
|
||||
param_scheduler = [
|
||||
dict(type='LinearLR', by_epoch=False, start_factor=0.1, begin=0, end=1000),
|
||||
dict(
|
||||
type='PolyLR',
|
||||
eta_min=1e-4,
|
||||
power=0.9,
|
||||
begin=1000,
|
||||
end=160000,
|
||||
by_epoch=False,
|
||||
)
|
||||
]
|
||||
```
|
||||
|
||||
Note: When modifying the `max_iters` in `train_cfg`, make sure the parameters in the parameter scheduler `param_scheduler` are also modified accordingly.
|
||||
|
||||
## Hook
|
||||
|
||||
### Introduction
|
||||
|
||||
OpenMMLab abstracts the model training and testing process as `Runner`. Inserting hooks can implement the corresponding functionality needed at different training and testing stages (such as "before and after each training iter", "before and after each validation iter", etc.) in `Runner`. For more introduction on hook mechanisms, please refer to [here](https://www.calltutors.com/blog/what-is-hook).
|
||||
|
||||
Hooks used in `Runner` are divided into two categories:
|
||||
|
||||
- Default hooks:
|
||||
|
||||
They implement essential functions during training and are defined in the configuration file by `default_hooks` and passed to `Runner`. `Runner` registers them through the [`register_default_hooks`](https://github.com/open-mmlab/mmengine/blob/main/mmengine/runner/runner.py#L1780) method.
|
||||
|
||||
Hooks have corresponding priorities; the higher the priority, the earlier the runner calls them. If the priorities are the same, the calling order is consistent with the hook registration order.
|
||||
|
||||
It is not recommended for users to modify the default hook priorities. Please refer to the [MMEngine hooks documentation](https://github.com/open-mmlab/mmengine/blob/main/docs/en/tutorials/hook.md) to understand the hook priority definitions.
|
||||
|
||||
The following are the default hooks used in MMSegmentation:
|
||||
|
||||
| Hook | Function | Priority |
|
||||
| :--------------------------------------------------------------------------------------------------------------------: | :------------------------------------------------------------------------------------------------------------------------: | :---------------: |
|
||||
| [IterTimerHook](https://github.com/open-mmlab/mmengine/blob/main/mmengine/hooks/iter_timer_hook.py) | Record the time spent on each iteration. | NORMAL (50) |
|
||||
| [LoggerHook](https://github.com/open-mmlab/mmengine/blob/main/mmengine/hooks/logger_hook.py) | Collect log records from different components in `Runner` and output them to terminal, JSON file, tensorboard, wandb, etc. | BELOW_NORMAL (60) |
|
||||
| [ParamSchedulerHook](https://github.com/open-mmlab/mmengine/blob/main/mmengine/hooks/param_scheduler_hook.py) | Update some hyperparameters in the optimizer, such as learning rate momentum. | LOW (70) |
|
||||
| [CheckpointHook](https://github.com/open-mmlab/mmengine/blob/main/mmengine/hooks/checkpoint_hook.py) | Regularly save checkpoint files. | VERY_LOW (90) |
|
||||
| [DistSamplerSeedHook](https://github.com/open-mmlab/mmengine/blob/main/mmengine/hooks/sampler_seed_hook.py) | Ensure the distributed sampler shuffle is enabled. | NORMAL (50) |
|
||||
| [SegVisualizationHook](https://github.com/open-mmlab/mmsegmentation/blob/main/mmseg/visualization/local_visualizer.py) | Visualize prediction results during validation and testing. | NORMAL (50) |
|
||||
|
||||
MMSegmentation registers some hooks with essential training functions in `default_hooks`:
|
||||
|
||||
```python
|
||||
default_hooks = dict(
|
||||
timer=dict(type='IterTimerHook'),
|
||||
logger=dict(type='LoggerHook', interval=50, log_metric_by_epoch=False),
|
||||
param_scheduler=dict(type='ParamSchedulerHook'),
|
||||
checkpoint=dict(type='CheckpointHook', by_epoch=False, interval=32000),
|
||||
sampler_seed=dict(type='DistSamplerSeedHook'),
|
||||
visualization=dict(type='SegVisualizationHook'))
|
||||
```
|
||||
|
||||
All the default hooks mentioned above, except for `SegVisualizationHook`, are implemented in MMEngine. The `SegVisualizationHook` is a hook implemented in MMSegmentation, which will be introduced later.
|
||||
|
||||
- Modifying default hooks
|
||||
|
||||
We will use the `logger` and `checkpoint` in `default_hooks` as examples to demonstrate how to modify the default hooks in `default_hooks`.
|
||||
|
||||
(1) Model saving configuration
|
||||
|
||||
`default_hooks` uses the `checkpoint` field to initialize the [model saving hook (CheckpointHook)](https://github.com/open-mmlab/mmengine/blob/main/mmengine/hooks/checkpoint_hook.py#L19).
|
||||
|
||||
```python
|
||||
checkpoint = dict(type='CheckpointHook', interval=1)
|
||||
```
|
||||
|
||||
Users can set `max_keep_ckpts` to save only a small number of checkpoints or use `save_optimizer` to determine whether to save optimizer information. More details on related parameters can be found [here](https://mmengine.readthedocs.io/en/latest/api/generated/mmengine.hooks.CheckpointHook.html#checkpointhook).
|
||||
|
||||
(2) Logging configuration
|
||||
|
||||
The `LoggerHook` is used to collect log information from different components in `Runner` and write it to terminal, JSON files, tensorboard, wandb, etc.
|
||||
|
||||
```python
|
||||
logger=dict(type='LoggerHook', interval=10)
|
||||
```
|
||||
|
||||
In the latest 1.x version of MMSegmentation, some logger hooks (LoggerHook) such as `TextLoggerHook`, `WandbLoggerHook`, and `TensorboardLoggerHook` will no longer be used. Instead, MMEngine uses `LogProcessor` to handle the information processed by the aforementioned hooks, which are now in [`MessageHub`](https://github.com/open-mmlab/mmengine/blob/main/mmengine/logging/message_hub.py#L17), [`WandbVisBackend`](https://github.com/open-mmlab/mmengine/blob/main/mmengine/visualization/vis_backend.py#L324), and [`TensorboardVisBackend`](https://github.com/open-mmlab/mmengine/blob/main/mmengine/visualization/vis_backend.py#L472).
|
||||
|
||||
Detailed usage is as follows, configuring the visualizer and specifying the visualization backend at the same time, here using Tensorboard as the visualizer's backend:
|
||||
|
||||
```python
|
||||
# TensorboardVisBackend
|
||||
visualizer = dict(
|
||||
type='SegLocalVisualizer', vis_backends=[dict(type='TensorboardVisBackend')], name='visualizer')
|
||||
```
|
||||
|
||||
For more related usage, please refer to [MMEngine Visualization Backend User Tutorial](https://github.com/open-mmlab/mmengine/blob/main/docs/en/advanced_tutorials/visualization.md).
|
||||
|
||||
- Custom hooks
|
||||
|
||||
Custom hooks are defined in the configuration through `custom_hooks`, and `Runner` registers them using the [`register_custom_hooks`](https://github.com/open-mmlab/mmengine/blob/main/mmengine/runner/runner.py#L1820) method.
|
||||
|
||||
The priority of custom hooks needs to be set in the configuration file; if not, it will be set to `NORMAL` by default. The following are some custom hooks implemented in MMEngine:
|
||||
|
||||
| Hook | Usage |
|
||||
| :----------------------------------------------------------------------------------------------------: | :--------------------------------------------------------------------------------------------------------------------------------: |
|
||||
| [EMAHook](https://github.com/open-mmlab/mmengine/blob/main/mmengine/hooks/ema_hook.py) | Use Exponential Moving Average (EMA) during model training. |
|
||||
| [EmptyCacheHook](https://github.com/open-mmlab/mmengine/blob/main/mmengine/hooks/empty_cache_hook.py) | Release all GPU memory not occupied by the cache during training |
|
||||
| [SyncBuffersHook](https://github.com/open-mmlab/mmengine/blob/main/mmengine/hooks/sync_buffer_hook.py) | Synchronize the parameters in the model buffer, such as `running_mean` and `running_var` in BN, at the end of each training epoch. |
|
||||
|
||||
The following is a use case for `EMAHook`, where the config file includes the configuration of the implemented custom hooks as members of the `custom_hooks` list.
|
||||
|
||||
```python
|
||||
custom_hooks = [
|
||||
dict(type='EMAHook', start_iters=500, priority='NORMAL')
|
||||
]
|
||||
```
|
||||
|
||||
### SegVisualizationHook
|
||||
|
||||
MMSegmentation implemented [`SegVisualizationHook`](https://github.com/open-mmlab/mmsegmentation/blob/main/mmseg/engine/hooks/visualization_hook.py#L17), which is used to visualize prediction results during validation and testing.
|
||||
`SegVisualizationHook` overrides the `_after_iter` method in the base class `Hook`. During validation or testing, it calls the `add_datasample` method of `visualizer` to draw semantic segmentation results according to the specified iteration interval. The specific implementation is as follows:
|
||||
|
||||
```python
|
||||
...
|
||||
@HOOKS.register_module()
|
||||
class SegVisualizationHook(Hook):
|
||||
...
|
||||
def _after_iter(self,
|
||||
runner: Runner,
|
||||
batch_idx: int,
|
||||
data_batch: dict,
|
||||
outputs: Sequence[SegDataSample],
|
||||
mode: str = 'val') -> None:
|
||||
...
|
||||
# If it's a training phase or self.draw is False, then skip it
|
||||
if self.draw is False or mode == 'train':
|
||||
return
|
||||
...
|
||||
if self.every_n_inner_iters(batch_idx, self.interval):
|
||||
for output in outputs:
|
||||
img_path = output.img_path
|
||||
img_bytes = self.file_client.get(img_path)
|
||||
img = mmcv.imfrombytes(img_bytes, channel_order='rgb')
|
||||
window_name = f'{mode}_{osp.basename(img_path)}'
|
||||
|
||||
self._visualizer.add_datasample(
|
||||
window_name,
|
||||
img,
|
||||
data_sample=output,
|
||||
show=self.show,
|
||||
wait_time=self.wait_time,
|
||||
step=runner.iter)
|
||||
|
||||
```
|
||||
|
||||
For more details about visualization, you can check [here](../user_guides/visualization.md).
|
||||
|
||||
## Optimizer
|
||||
|
||||
In the previous configuration and runtime settings, we provided a simple example of configuring the training optimizer. This section will further detailly introduce how to configure optimizers in MMSegmentation.
|
||||
|
||||
## Optimizer Wrapper
|
||||
|
||||
OpenMMLab 2.0 introduces an optimizer wrapper that supports different training strategies, including mixed-precision training, gradient accumulation, and gradient clipping. Users can choose the appropriate training strategy according to their needs. The optimizer wrapper also defines a standard parameter update process, allowing users to switch between different training strategies within the same code. For more information, please refer to the [MMEngine optimizer wrapper documentation](https://github.com/open-mmlab/mmengine/blob/main/docs/en/tutorials/optim_wrapper.md).
|
||||
|
||||
Here are some common usage methods in MMSegmentation:
|
||||
|
||||
#### Configuring PyTorch Supported Optimizers
|
||||
|
||||
OpenMMLab 2.0 supports all native PyTorch optimizers, as referenced [here](https://github.com/open-mmlab/mmengine/blob/main/docs/en/tutorials/optim_wrapper.md).
|
||||
|
||||
To set the optimizer used by the `Runner` during training in the configuration file, you need to define `optim_wrapper` instead of `optimizer`. Below is an example of configuring an optimizer during training:
|
||||
|
||||
```python
|
||||
optim_wrapper = dict(
|
||||
type='OptimWrapper',
|
||||
optimizer=dict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0005),
|
||||
clip_grad=None)
|
||||
```
|
||||
|
||||
#### Configuring Gradient Clipping
|
||||
|
||||
When the model training requires gradient clipping, you can configure it as shown in the following example:
|
||||
|
||||
```python
|
||||
optimizer = dict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0001)
|
||||
optim_wrapper = dict(type='OptimWrapper', optimizer=optimizer,
|
||||
clip_grad=dict(max_norm=0.01, norm_type=2))
|
||||
```
|
||||
|
||||
Here, `max_norm` refers to the maximum value of the gradient after clipping, and `norm_type` refers to the norm used when clipping the gradient. Related methods can be found in [torch.nn.utils.clip_grad_norm\_](https://pytorch.org/docs/stable/generated/torch.nn.utils.clip_grad_norm_.html).
|
||||
|
||||
#### Configuring Mixed Precision Training
|
||||
|
||||
When mixed precision training is needed to reduce memory usage, you can use `AmpOptimWrapper`. The specific configuration is as follows:
|
||||
|
||||
```python
|
||||
optimizer = dict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0001)
|
||||
optim_wrapper = dict(type='AmpOptimWrapper', optimizer=optimizer)
|
||||
```
|
||||
|
||||
The default setting for `loss_scale` in [`AmpOptimWrapper`](https://github.com/open-mmlab/mmengine/blob/main/mmengine/optim/optimizer/amp_optimizer_wrapper.py#L20) is `dynamic`.
|
||||
|
||||
#### Configuring Hyperparameters for Different Layers of the Model Network
|
||||
|
||||
In model training, if you want to set different optimization strategies for different parameters in the optimizer, such as setting different learning rates, weight decay, and other hyperparameters, you can achieve this by setting `paramwise_cfg` in the `optim_wrapper` of the configuration file.
|
||||
|
||||
The following config file uses the [ViT `optim_wrapper`](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/vit/vit_vit-b16-ln_mln_upernet_8xb2-160k_ade20k-512x512.py#L15-L27) as an example to introduce the use of `paramwise_cfg` parameters. During training, the weight decay parameter coefficients for the `pos_embed`, `mask_token`, and `norm` modules are set to 0. That is, during training, the weight decay for these modules will be changed to `weight_decay * decay_mult`=0.
|
||||
|
||||
```python
|
||||
optimizer = dict(
|
||||
type='AdamW', lr=0.00006, betas=(0.9, 0.999), weight_decay=0.01)
|
||||
optim_wrapper = dict(
|
||||
type='OptimWrapper',
|
||||
optimizer=optimizer,
|
||||
paramwise_cfg=dict(
|
||||
custom_keys={
|
||||
'pos_embed': dict(decay_mult=0.),
|
||||
'cls_token': dict(decay_mult=0.),
|
||||
'norm': dict(decay_mult=0.)
|
||||
}))
|
||||
```
|
||||
|
||||
Here, `decay_mult` refers to the weight decay coefficient for the corresponding parameters. For more information on the usage of `paramwise_cfg`, please refer to the [MMEngine optimizer wrapper documentation](https://github.com/open-mmlab/mmengine/blob/main/docs/en/tutorials/optim_wrapper.md).
|
||||
|
||||
### Optimizer Wrapper Constructor
|
||||
|
||||
The default optimizer wrapper constructor [`DefaultOptimWrapperConstructor`](https://github.com/open-mmlab/mmengine/blob/main/mmengine/optim/optimizer/default_constructor.py#L19) builds the optimizer used in training based on the input `optim_wrapper` and `paramwise_cfg` defined in the `optim_wrapper`. When the functionality of [`DefaultOptimWrapperConstructor`](https://github.com/open-mmlab/mmengine/blob/main/mmengine/optim/optimizer/default_constructor.py#L19) does not meet the requirements, you can customize the optimizer wrapper constructor to implement the configuration of hyperparameters.
|
||||
|
||||
MMSegmentation has implemented the [`LearningRateDecayOptimizerConstructor`](https://github.com/open-mmlab/mmsegmentation/blob/main/mmseg/engine/optimizers/layer_decay_optimizer_constructor.py#L104), which can decay the learning rate of model parameters in the backbone networks of ConvNeXt, BEiT, and MAE models during training according to the defined decay ratio (`decay_rate`). The configuration in the configuration file is as follows:
|
||||
|
||||
```python
|
||||
optim_wrapper = dict(
|
||||
_delete_=True,
|
||||
type='AmpOptimWrapper',
|
||||
optimizer=dict(
|
||||
type='AdamW', lr=0.0001, betas=(0.9, 0.999), weight_decay=0.05),
|
||||
paramwise_cfg={
|
||||
'decay_rate': 0.9,
|
||||
'decay_type': 'stage_wise',
|
||||
'num_layers': 12
|
||||
},
|
||||
constructor='LearningRateDecayOptimizerConstructor',
|
||||
loss_scale='dynamic')
|
||||
```
|
||||
|
||||
The purpose of `_delete_=True` is to ignore the inherited configuration in the OpenMMLab Config. In this code snippet, the inherited `optim_wrapper` configuration is ignored. For more information on `_delete_` fields, please refer to the [MMEngine documentation](https://github.com/open-mmlab/mmengine/blob/main/docs/en/advanced_tutorials/config.md#delete-key-in-dict).
|
||||
155
Seg_All_In_One_MMSeg/docs/en/advanced_guides/evaluation.md
Normal file
155
Seg_All_In_One_MMSeg/docs/en/advanced_guides/evaluation.md
Normal file
@@ -0,0 +1,155 @@
|
||||
# Evaluation
|
||||
|
||||
The evaluation procedure would be executed at [ValLoop](https://github.com/open-mmlab/mmengine/blob/main/mmengine/runner/loops.py#L300) and [TestLoop](https://github.com/open-mmlab/mmengine/blob/main/mmengine/runner/loops.py#L373), users can evaluate model performance during training or using the test script with simple settings in the configuration file. The `ValLoop` and `TestLoop` are properties of [Runner](https://github.com/open-mmlab/mmengine/blob/main/mmengine/runner/runner.py#L59), they will be built the first time they are called. To build the `ValLoop` successfully, the `val_dataloader` and `val_evaluator` must be set when building `Runner` since `dataloader` and `evaluator` are required parameters, and the same goes for `TestLoop`. For more information about the Runner's design, please refer to the [documentation](https://github.com/open-mmlab/mmengine/blob/main/docs/en/design/runner.md) of [MMEngine](https://github.com/open-mmlab/mmengine).
|
||||
|
||||

|
||||
|
||||
In MMSegmentation, we write the settings of dataloader and metrics in the config files of datasets and the configuration of the evaluation loop in the `schedule_x` config files by default.
|
||||
|
||||
For example, in the ADE20K config file `configs/_base_/dataset/ade20k.py`, on lines 37 to 48, we configured the `val_dataloader`, on line 51, we select `IoUMetric` as the evaluator and set `mIoU` as the metric:
|
||||
|
||||
```python
|
||||
val_dataloader = dict(
|
||||
batch_size=1,
|
||||
num_workers=4,
|
||||
persistent_workers=True,
|
||||
sampler=dict(type='DefaultSampler', shuffle=False),
|
||||
dataset=dict(
|
||||
type=dataset_type,
|
||||
data_root=data_root,
|
||||
data_prefix=dict(
|
||||
img_path='images/validation',
|
||||
seg_map_path='annotations/validation'),
|
||||
pipeline=test_pipeline))
|
||||
|
||||
val_evaluator = dict(type='IoUMetric', iou_metrics=['mIoU'])
|
||||
```
|
||||
|
||||
To be able to evaluate the model during training, for example, we add the evaluation configuration to the file `configs/schedules/schedule_40k.py` on lines 15 to 16:
|
||||
|
||||
```python
|
||||
train_cfg = dict(type='IterBasedTrainLoop', max_iters=40000, val_interval=4000)
|
||||
val_cfg = dict(type='ValLoop')
|
||||
```
|
||||
|
||||
With the above two settings, MMSegmentation evaluates the **mIoU** metric of the model once every 4000 iterations during the training of 40K iterations.
|
||||
|
||||
If we would like to test the model after training, we need to add the `test_dataloader`, `test_evaluator` and `test_cfg` configs to the config file.
|
||||
|
||||
```python
|
||||
test_dataloader = dict(
|
||||
batch_size=1,
|
||||
num_workers=4,
|
||||
persistent_workers=True,
|
||||
sampler=dict(type='DefaultSampler', shuffle=False),
|
||||
dataset=dict(
|
||||
type=dataset_type,
|
||||
data_root=data_root,
|
||||
data_prefix=dict(
|
||||
img_path='images/validation',
|
||||
seg_map_path='annotations/validation'),
|
||||
pipeline=test_pipeline))
|
||||
|
||||
test_evaluator = dict(type='IoUMetric', iou_metrics=['mIoU'])
|
||||
test_cfg = dict(type='TestLoop')
|
||||
```
|
||||
|
||||
In MMSegmentation, the settings of `test_dataloader` and `test_evaluator` are the same as the `ValLoop`'s dataloader and evaluator by default, we can modify these settings to meet our needs.
|
||||
|
||||
## IoUMetric
|
||||
|
||||
MMSegmentation implements [IoUMetric](https://github.com/open-mmlab/mmsegmentation/blob/1.x/mmseg/evaluation/metrics/iou_metric.py) and [CityscapesMetric](https://github.com/open-mmlab/mmsegmentation/blob/1.x/mmseg/evaluation/metrics/citys_metric.py) for evaluating the performance of models, based on the [BaseMetric](https://github.com/open-mmlab/mmengine/blob/main/mmengine/evaluator/metric.py) provided by [MMEngine](https://github.com/open-mmlab/mmengine). Please refer to [the documentation](https://mmengine.readthedocs.io/en/latest/tutorials/evaluation.html) for more details about the unified evaluation interface.
|
||||
|
||||
Here we briefly describe the arguments and the two main methods of `IoUMetric`.
|
||||
|
||||
The constructor of `IoUMetric` has some additional parameters besides the base `collect_device` and `prefix`.
|
||||
|
||||
The arguments of the constructor:
|
||||
|
||||
- ignore_index (int) - Index that will be ignored in evaluation. Default: 255.
|
||||
- iou_metrics (list\[str\] | str) - Metrics to be calculated, the options includes 'mIoU', 'mDice' and 'mFscore'.
|
||||
- nan_to_num (int, optional) - If specified, NaN values will be replaced by the numbers defined by the user. Default: None.
|
||||
- beta (int) - Determines the weight of recall in the combined score. Default: 1.
|
||||
- collect_device (str) - Device name used for collecting results from different ranks during distributed training. Must be 'cpu' or 'gpu'. Defaults to 'cpu'.
|
||||
- prefix (str, optional) - The prefix that will be added in the metric names to disambiguate homonymous metrics of different evaluators. If the prefix is not provided in the argument, self.default_prefix will be used instead. Defaults to None.
|
||||
|
||||
`IoUMetric` implements the IoU metric calculation, the core two methods of `IoUMetric` are `process` and `compute_metrics`.
|
||||
|
||||
- `process` method processes one batch of data and data_samples.
|
||||
- `compute_metrics` method computes the metrics from processed results.
|
||||
|
||||
### IoUMetric.process
|
||||
|
||||
Parameters:
|
||||
|
||||
- data_batch (Any) - A batch of data from the dataloader.
|
||||
- data_samples (Sequence\[dict\]) - A batch of outputs from the model.
|
||||
|
||||
Returns:
|
||||
|
||||
This method doesn't have returns since the processed results would be stored in `self.results`, which will be used to compute the metrics when all batches have been processed.
|
||||
|
||||
### IoUMetric.compute_metrics
|
||||
|
||||
Parameters:
|
||||
|
||||
- results (list) - The processed results of each batch.
|
||||
|
||||
Returns:
|
||||
|
||||
- Dict\[str, float\] - The computed metrics. The keys are the names of the metrics, and the values are corresponding results. The key mainly includes **aAcc**, **mIoU**, **mAcc**, **mDice**, **mFscore**, **mPrecision**, **mRecall**.
|
||||
|
||||
## CityscapesMetric
|
||||
|
||||
`CityscapesMetric` uses the official [CityscapesScripts](https://github.com/mcordts/cityscapesScripts) provided by Cityscapes to evaluate model performance.
|
||||
|
||||
### Usage
|
||||
|
||||
Before using it, please install the `cityscapesscripts` package first:
|
||||
|
||||
```shell
|
||||
pip install cityscapesscripts
|
||||
```
|
||||
|
||||
Since the `IoUMetric` is used as the default evaluator in MMSegmentation, if you would like to use `CityscapesMetric`, customizing the config file is required. In your customized config file, you should overwrite the default evaluator as follows.
|
||||
|
||||
```python
|
||||
val_evaluator = dict(type='CityscapesMetric', output_dir='tmp')
|
||||
test_evaluator = val_evaluator
|
||||
```
|
||||
|
||||
### Interface
|
||||
|
||||
The arguments of the constructor:
|
||||
|
||||
- output_dir (str) - The directory for output prediction
|
||||
- ignore_index (int) - Index that will be ignored in evaluation. Default: 255.
|
||||
- format_only (bool) - Only format result for results commit without perform evaluation. It is useful when you want to format the result to a specific format and submit it to the test server. Defaults to False.
|
||||
- keep_results (bool) - Whether to keep the results. When `format_only` is True, `keep_results` must be True. Defaults to False.
|
||||
- collect_device (str) - Device name used for collecting results from different ranks during distributed training. Must be 'cpu' or 'gpu'. Defaults to 'cpu'.
|
||||
- prefix (str, optional) - The prefix that will be added in the metric names to disambiguate homonymous metrics of different evaluators. If prefix is not provided in the argument, self.default_prefix will be used instead. Defaults to None.
|
||||
|
||||
#### CityscapesMetric.process
|
||||
|
||||
This method would draw the masks on images and save the painted images to `work_dir`.
|
||||
|
||||
Parameters:
|
||||
|
||||
- data_batch (dict) - A batch of data from the dataloader.
|
||||
- data_samples (Sequence\[dict\]) - A batch of outputs from the model.
|
||||
|
||||
Returns:
|
||||
|
||||
This method doesn't have returns, the annotations' path would be stored in `self.results`, which will be used to compute the metrics when all batches have been processed.
|
||||
|
||||
#### CityscapesMetric.compute_metrics
|
||||
|
||||
This method would call `cityscapesscripts.evaluation.evalPixelLevelSemanticLabeling` tool to calculate metrics.
|
||||
|
||||
Parameters:
|
||||
|
||||
- results (list) - Testing results of the dataset.
|
||||
|
||||
Returns:
|
||||
|
||||
- dict\[str: float\] - Cityscapes evaluation results.
|
||||
26
Seg_All_In_One_MMSeg/docs/en/advanced_guides/index.rst
Normal file
26
Seg_All_In_One_MMSeg/docs/en/advanced_guides/index.rst
Normal file
@@ -0,0 +1,26 @@
|
||||
Basic Concepts
|
||||
***************
|
||||
|
||||
.. toctree::
|
||||
:maxdepth: 1
|
||||
|
||||
data_flow.md
|
||||
structures.md
|
||||
models.md
|
||||
datasets.md
|
||||
transforms.md
|
||||
evaluation.md
|
||||
engine.md
|
||||
training_tricks.md
|
||||
|
||||
Component Customization
|
||||
************************
|
||||
|
||||
.. toctree::
|
||||
:maxdepth: 1
|
||||
|
||||
add_models.md
|
||||
add_datasets.md
|
||||
add_transforms.md
|
||||
add_metrics.md
|
||||
customize_runtime.md
|
||||
164
Seg_All_In_One_MMSeg/docs/en/advanced_guides/models.md
Normal file
164
Seg_All_In_One_MMSeg/docs/en/advanced_guides/models.md
Normal file
@@ -0,0 +1,164 @@
|
||||
# Models
|
||||
|
||||
We usually define a neural network in a deep learning task as a model, and this model is the core of an algorithm. [MMEngine](https://github.com/open-mmlab/mmengine) abstracts a unified model [BaseModel](https://github.com/open-mmlab/mmengine/blob/main/mmengine/model/base_model/base_model.py#L16) to standardize the interfaces for training, testing and other processes. All models implemented by MMSegmentation inherit from `BaseModel`, and in MMSegmentation we implemented forward and added some functions for the semantic segmentation algorithm.
|
||||
|
||||
## Common components
|
||||
|
||||
### Segmentor
|
||||
|
||||
In MMSegmentation, we abstract the network architecture as a **Segmentor**, it is a model that contains all components of a network. We have already implemented **EncoderDecoder** and **CascadeEncoderDecoder**, which typically consist of **Data preprocessor**, **Backbone**, **Decode head** and **Auxiliary head**.
|
||||
|
||||
### Data preprocessor
|
||||
|
||||
**Data preprocessor** is the part that copies data to the target device and preprocesses the data into the model input format.
|
||||
|
||||
### Backbone
|
||||
|
||||
**Backbone** is the part that transforms an image to feature maps, such as a **ResNet-50** without the last fully connected layer.
|
||||
|
||||
### Neck
|
||||
|
||||
**Neck** is the part that connects the backbone and heads. It performs some refinements or reconfigurations on the raw feature maps produced by the backbone. An example is **Feature Pyramid Network (FPN)**.
|
||||
|
||||
### Decode head
|
||||
|
||||
**Decode head** is the part that transforms the feature maps into a segmentation mask, such as **PSPNet**.
|
||||
|
||||
### Auxiliary head
|
||||
|
||||
**Auxiliary head** is an optional component that transforms the feature maps into segmentation masks which only used for computing auxiliary losses.
|
||||
|
||||
## Basic interfaces
|
||||
|
||||
MMSegmentation wraps `BaseModel` and implements the [BaseSegmentor](https://github.com/open-mmlab/mmsegmentation/blob/1.x/mmseg/models/segmentors/base.py#L15) class, which mainly provides the interfaces `forward`, `train_step`, `val_step` and `test_step`. The following will introduce these interfaces in detail.
|
||||
|
||||
### forward
|
||||
|
||||

|
||||

|
||||
|
||||
The `forward` method returns losses or predictions of training, validation, testing, and a simple inference process.
|
||||
|
||||
The method should accept three modes: "tensor", "predict" and "loss":
|
||||
|
||||
- "tensor": Forward the whole network and return the tensor or tuple of tensor without any post-processing, same as a common `nn.Module`.
|
||||
- "predict": Forward and return the predictions, which are fully processed to a list of `SegDataSample`.
|
||||
- "loss": Forward and return a `dict` of losses according to the given inputs and data samples.
|
||||
|
||||
**Note:** [SegDataSample](https://github.com/open-mmlab/mmsegmentation/blob/1.x/mmseg/structures/seg_data_sample.py) is a data structure interface of MMSegmentation, it is used as an interface between different components. `SegDataSample` implements the abstract data element `mmengine.structures.BaseDataElement`, please refer to [the SegDataSample documentation](https://mmsegmentation.readthedocs.io/en/1.x/advanced_guides/structures.html) and [data element documentation](https://mmengine.readthedocs.io/en/latest/advanced_tutorials/data_element.html) in [MMEngine](https://github.com/open-mmlab/mmengine) for more information.
|
||||
|
||||
Note that this method doesn't handle either backpropagation or optimizer updating, which are done in the method `train_step`.
|
||||
|
||||
Parameters:
|
||||
|
||||
- inputs (torch.Tensor) - The input tensor with shape (N, C, ...) in general.
|
||||
- data_sample (list\[[SegDataSample](https://github.com/open-mmlab/mmsegmentation/blob/1.x/mmseg/structures/seg_data_sample.py)\]) - The seg data samples. It usually includes information such as `metainfo` and `gt_sem_seg`. Default to None.
|
||||
- mode (str) - Return what kind of value. Defaults to 'tensor'.
|
||||
|
||||
Returns:
|
||||
|
||||
- `dict` or `list`:
|
||||
- If `mode == "loss"`, return a `dict` of loss tensor used for backward and logging.
|
||||
- If `mode == "predict"`, return a `list` of `SegDataSample`, the inference results will be incrementally added to the `data_sample` parameter passed to the forward method, each `SegDataSample` contains the following keys:
|
||||
- pred_sem_seg (`PixelData`): Prediction of semantic segmentation.
|
||||
- seg_logits (`PixelData`): Predicted logits of semantic segmentation before normalization.
|
||||
- If `mode == "tensor"`, return a `tensor` or `tuple of tensor` or `dict` of `tensor` for custom use.
|
||||
|
||||
### prediction modes
|
||||
|
||||
We briefly describe the fields of the model's configuration in [the config documentation](../user_guides/1_config.md), here we elaborate on the `model.test_cfg` field. `model.test_cfg` is used to control forward behavior, the `forward` method in `"predict"` mode can run in two modes:
|
||||
|
||||
- `whole_inference`: If `cfg.model.test_cfg.mode == 'whole'`, model will inference with full images.
|
||||
|
||||
An `whole_inference` mode example config:
|
||||
|
||||
```python
|
||||
model = dict(
|
||||
type='EncoderDecoder'
|
||||
...
|
||||
test_cfg=dict(mode='whole')
|
||||
)
|
||||
```
|
||||
|
||||
- `slide_inference`: If `cfg.model.test_cfg.mode == 'slide'`, model will inference by sliding-window. **Note:** if you select the `slide` mode, `cfg.model.test_cfg.stride` and `cfg.model.test_cfg.crop_size` should also be specified.
|
||||
|
||||
An `slide_inference` mode example config:
|
||||
|
||||
```python
|
||||
model = dict(
|
||||
type='EncoderDecoder'
|
||||
...
|
||||
test_cfg=dict(mode='slide', crop_size=256, stride=170)
|
||||
)
|
||||
```
|
||||
|
||||
### train_step
|
||||
|
||||
The `train_step` method calls the forward interface of the `loss` mode to get the loss `dict`. The `BaseModel` class implements the default model training process including preprocessing, model forward propagation, loss calculation, optimization, and back-propagation.
|
||||
|
||||
Parameters:
|
||||
|
||||
- data (dict or tuple or list) - Data sampled from the dataset. In MMSegmentation, the data dict contains `inputs` and `data_samples` two fields.
|
||||
- optim_wrapper (OptimWrapper) - OptimWrapper instance used to update model parameters.
|
||||
|
||||
**Note:** [OptimWrapper](https://github.com/open-mmlab/mmengine/blob/main/mmengine/optim/optimizer/optimizer_wrapper.py#L17) provides a common interface for updating parameters, please refer to optimizer wrapper [documentation](https://mmengine.readthedocs.io/en/latest/tutorials/optim_wrapper.html) in [MMEngine](https://github.com/open-mmlab/mmengine) for more information.
|
||||
|
||||
Returns:
|
||||
|
||||
- Dict\[str, `torch.Tensor`\]: A `dict` of tensor for logging.
|
||||
|
||||

|
||||
|
||||
### val_step
|
||||
|
||||
The `val_step` method calls the forward interface of the `predict` mode and returns the prediction result, which is further passed to the process interface of the evaluator and the `after_val_iter` interface of the Hook.
|
||||
|
||||
Parameters:
|
||||
|
||||
- data (`dict` or `tuple` or `list`) - Data sampled from the dataset. In MMSegmentation, the data dict contains `inputs` and `data_samples` two fields.
|
||||
|
||||
Returns:
|
||||
|
||||
- `list` - The predictions of given data.
|
||||
|
||||

|
||||
|
||||
### test_step
|
||||
|
||||
The `BaseModel` implements `test_step` the same as `val_step`.
|
||||
|
||||
## Data Preprocessor
|
||||
|
||||
The [SegDataPreProcessor](https://github.com/open-mmlab/mmsegmentation/blob/1.x/mmseg/models/data_preprocessor.py#L13) implemented by MMSegmentation inherits from the [BaseDataPreprocessor](https://github.com/open-mmlab/mmengine/blob/main/mmengine/model/base_model/data_preprocessor.py#L18) implemented by [MMEngine](https://github.com/open-mmlab/mmengine) and provides the functions of data preprocessing and copying data to the target device.
|
||||
|
||||
The runner carries the model to the specified device during the construction stage, while the data is carried to the specified device by the [SegDataPreProcessor](https://github.com/open-mmlab/mmsegmentation/blob/1.x/mmseg/models/data_preprocessor.py#L13) in `train_step`, `val_step`, and `test_step`, and the processed data is further passed to the model.
|
||||
|
||||
The parameters of the `SegDataPreProcessor` constructor:
|
||||
|
||||
- mean (Sequence\[Number\], optional) - The pixel mean of R, G, B channels. Defaults to None.
|
||||
- std (Sequence\[Number\], optional) - The pixel standard deviation of R, G, B channels. Defaults to None.
|
||||
- size (tuple, optional) - Fixed padding size.
|
||||
- size_divisor (int, optional) - The divisor of padded size.
|
||||
- pad_val (float, optional) - Padding value. Default: 0.
|
||||
- seg_pad_val (float, optional) - Padding value of segmentation map. Default: 255.
|
||||
- bgr_to_rgb (bool) - whether to convert image from BGR to RGB. Defaults to False.
|
||||
- rgb_to_bgr (bool) - whether to convert image from RGB to BGR. Defaults to False.
|
||||
- batch_augments (list\[dict\], optional) - Batch-level augmentations. Default to None.
|
||||
|
||||
The data will be processed as follows:
|
||||
|
||||
- Collate and move data to the target device.
|
||||
- Pad inputs to the input size with defined `pad_val`, and pad seg map with defined `seg_pad_val`.
|
||||
- Stack inputs to batch_inputs.
|
||||
- Convert inputs from bgr to rgb if the shape of input is (3, H, W).
|
||||
- Normalize image with defined std and mean.
|
||||
- Do batch augmentations like Mixup and Cutmix during training.
|
||||
|
||||
The parameters of the `forward` method:
|
||||
|
||||
- data (dict) - data sampled from dataloader.
|
||||
- training (bool) - Whether to enable training time augmentation.
|
||||
|
||||
The returns of the `forward` method:
|
||||
|
||||
- Dict: Data in the same format as the model input.
|
||||
104
Seg_All_In_One_MMSeg/docs/en/advanced_guides/structures.md
Normal file
104
Seg_All_In_One_MMSeg/docs/en/advanced_guides/structures.md
Normal file
@@ -0,0 +1,104 @@
|
||||
# Structures
|
||||
|
||||
To unify input and output interfaces between different models and modules, OpenMMLab 2.0 MMEngine defines an abstract data structure,
|
||||
it has implemented basic functions of `Create`, `Read`, `Update`, `Delete`, supported data transferring among different types of devices
|
||||
and tensor-like or dictionary-like operations such as `.cpu()`, `.cuda()`, `.get()` and `.detach()`.
|
||||
More details can be found [here](https://github.com/open-mmlab/mmengine/blob/main/docs/en/advanced_tutorials/data_element.md).
|
||||
|
||||
MMSegmentation also follows this interface protocol and defines `SegDataSample` which is used to encapsulate the data of semantic segmentation task.
|
||||
|
||||
## Semantic Segmentation Data SegDataSample
|
||||
|
||||
[SegDataSample](mmseg.structures.SegDataSample) includes three main fields `gt_sem_seg`, `pred_sem_seg` and `seg_logits`, which are used to store the annotation information and prediction results respectively.
|
||||
|
||||
| Field | Type | Description |
|
||||
| -------------- | ------------------------- | ------------------------------------------ |
|
||||
| gt_sem_seg | [`PixelData`](#pixeldata) | Annotation information. |
|
||||
| pred_instances | [`PixelData`](#pixeldata) | The predicted result. |
|
||||
| seg_logits | [`PixelData`](#pixeldata) | The raw (non-normalized) predicted result. |
|
||||
|
||||
The following sample code demonstrates the use of `SegDataSample`.
|
||||
|
||||
```python
|
||||
import torch
|
||||
from mmengine.structures import PixelData
|
||||
from mmseg.structures import SegDataSample
|
||||
|
||||
img_meta = dict(img_shape=(4, 4, 3),
|
||||
pad_shape=(4, 4, 3))
|
||||
data_sample = SegDataSample()
|
||||
# defining gt_segmentations for encapsulate the ground truth data
|
||||
gt_segmentations = PixelData(metainfo=img_meta)
|
||||
gt_segmentations.data = torch.randint(0, 2, (1, 4, 4))
|
||||
|
||||
# add and process property in SegDataSample
|
||||
data_sample.gt_sem_seg = gt_segmentations
|
||||
assert 'gt_sem_seg' in data_sample
|
||||
assert 'sem_seg' in data_sample.gt_sem_seg
|
||||
assert 'img_shape' in data_sample.gt_sem_seg.metainfo_keys()
|
||||
print(data_sample.gt_sem_seg.shape)
|
||||
'''
|
||||
(4, 4)
|
||||
'''
|
||||
print(data_sample)
|
||||
'''
|
||||
<SegDataSample(
|
||||
|
||||
META INFORMATION
|
||||
|
||||
DATA FIELDS
|
||||
gt_sem_seg: <PixelData(
|
||||
|
||||
META INFORMATION
|
||||
img_shape: (4, 4, 3)
|
||||
pad_shape: (4, 4, 3)
|
||||
|
||||
DATA FIELDS
|
||||
data: tensor([[[1, 1, 1, 0],
|
||||
[1, 0, 1, 1],
|
||||
[1, 1, 1, 1],
|
||||
[0, 1, 0, 1]]])
|
||||
) at 0x1c2b4156460>
|
||||
) at 0x1c2aae44d60>
|
||||
'''
|
||||
|
||||
# delete and change property in SegDataSample
|
||||
data_sample = SegDataSample()
|
||||
gt_segmentations = PixelData(metainfo=img_meta)
|
||||
gt_segmentations.data = torch.randint(0, 2, (1, 4, 4))
|
||||
data_sample.gt_sem_seg = gt_segmentations
|
||||
data_sample.gt_sem_seg.set_metainfo(dict(img_shape=(4,4,9), pad_shape=(4,4,9)))
|
||||
del data_sample.gt_sem_seg.img_shape
|
||||
|
||||
# Tensor-like operations
|
||||
data_sample = SegDataSample()
|
||||
gt_segmentations = PixelData(metainfo=img_meta)
|
||||
gt_segmentations.data = torch.randint(0, 2, (1, 4, 4))
|
||||
cuda_gt_segmentations = gt_segmentations.cuda()
|
||||
cuda_gt_segmentations = gt_segmentations.to('cuda:0')
|
||||
cpu_gt_segmentations = cuda_gt_segmentations.cpu()
|
||||
cpu_gt_segmentations = cuda_gt_segmentations.to('cpu')
|
||||
```
|
||||
|
||||
## Customize New Property in SegDataSample
|
||||
|
||||
If you want to customize new property in `SegDataSample`, you may follow [SegDataSample](https://github.com/open-mmlab/mmsegmentation/blob/1.x/mmseg/structures/seg_data_sample.py) below:
|
||||
|
||||
```python
|
||||
class SegDataSample(BaseDataElement):
|
||||
...
|
||||
|
||||
@property
|
||||
def xxx_property(self) -> xxxData:
|
||||
return self._xxx_property
|
||||
|
||||
@xxx_property.setter
|
||||
def xxx_property(self, value: xxxData) -> None:
|
||||
self.set_field(value, '_xxx_property', dtype=xxxData)
|
||||
|
||||
@xxx_property.deleter
|
||||
def xxx_property(self) -> None:
|
||||
del self._xxx_property
|
||||
```
|
||||
|
||||
Then a new property would be added to `SegDataSample`.
|
||||
@@ -0,0 +1,75 @@
|
||||
# Training Tricks
|
||||
|
||||
MMSegmentation support following training tricks out of box.
|
||||
|
||||
## Different Learning Rate(LR) for Backbone and Heads
|
||||
|
||||
In semantic segmentation, some methods make the LR of heads larger than backbone to achieve better performance or faster convergence.
|
||||
|
||||
In MMSegmentation, you may add following lines to config to make the LR of heads 10 times of backbone.
|
||||
|
||||
```python
|
||||
optim_wrapper=dict(
|
||||
paramwise_cfg = dict(
|
||||
custom_keys={
|
||||
'head': dict(lr_mult=10.)}))
|
||||
```
|
||||
|
||||
With this modification, the LR of any parameter group with `'head'` in name will be multiplied by 10.
|
||||
You may refer to [MMEngine documentation](https://mmengine.readthedocs.io/en/latest/tutorials/optim_wrapper.html#advanced-usages) for further details.
|
||||
|
||||
## Online Hard Example Mining (OHEM)
|
||||
|
||||
We implement pixel sampler for training sampling, like OHEM (Online Hard Example Mining),
|
||||
which is used for remove the "easy" examples for model training.
|
||||
Here is an example config of training PSPNet with OHEM enabled.
|
||||
|
||||
```python
|
||||
_base_ = './pspnet_r50-d8_4xb2-40k_cityscapes-512x1024.py'
|
||||
model=dict(
|
||||
decode_head=dict(
|
||||
sampler=dict(type='OHEMPixelSampler', thresh=0.7, min_kept=100000)) )
|
||||
```
|
||||
|
||||
In this way, only pixels with confidence score under 0.7 are used to train. And we keep at least 100000 pixels during training. If `thresh` is not specified, pixels of top `min_kept` loss will be selected.
|
||||
|
||||
## Class Balanced Loss
|
||||
|
||||
For dataset that is not balanced in classes distribution, you may change the loss weight of each class.
|
||||
Here is an example for cityscapes dataset.
|
||||
|
||||
```python
|
||||
_base_ = './pspnet_r50-d8_4xb2-40k_cityscapes-512x1024.py'
|
||||
model=dict(
|
||||
decode_head=dict(
|
||||
loss_decode=dict(
|
||||
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0,
|
||||
# DeepLab used this class weight for cityscapes
|
||||
class_weight=[0.8373, 0.9180, 0.8660, 1.0345, 1.0166, 0.9969, 0.9754,
|
||||
1.0489, 0.8786, 1.0023, 0.9539, 0.9843, 1.1116, 0.9037,
|
||||
1.0865, 1.0955, 1.0865, 1.1529, 1.0507])))
|
||||
```
|
||||
|
||||
`class_weight` will be passed into `CrossEntropyLoss` as `weight` argument. Please refer to [PyTorch Doc](https://pytorch.org/docs/stable/nn.html?highlight=crossentropy#torch.nn.CrossEntropyLoss) for details.
|
||||
|
||||
## Multiple Losses
|
||||
|
||||
For loss calculation, we support multiple losses training concurrently. Here is an example config of training `unet` on `DRIVE` dataset, whose loss function is `1:3` weighted sum of `CrossEntropyLoss` and `DiceLoss`:
|
||||
|
||||
```python
|
||||
_base_ = './fcn_unet_s5-d16_64x64_40k_drive.py'
|
||||
model = dict(
|
||||
decode_head=dict(loss_decode=[
|
||||
dict(type='CrossEntropyLoss', loss_name='loss_ce', loss_weight=1.0),
|
||||
dict(type='DiceLoss', loss_name='loss_dice', loss_weight=3.0)
|
||||
]),
|
||||
auxiliary_head=dict(loss_decode=[
|
||||
dict(type='CrossEntropyLoss', loss_name='loss_ce', loss_weight=1.0),
|
||||
dict(type='DiceLoss', loss_name='loss_dice', loss_weight=3.0)
|
||||
]),
|
||||
)
|
||||
```
|
||||
|
||||
In this way, `loss_weight` and `loss_name` will be weight and name in training log of corresponding loss, respectively.
|
||||
|
||||
Note: If you want this loss item to be included into the backward graph, `loss_` must be the prefix of the name.
|
||||
119
Seg_All_In_One_MMSeg/docs/en/advanced_guides/transforms.md
Normal file
119
Seg_All_In_One_MMSeg/docs/en/advanced_guides/transforms.md
Normal file
@@ -0,0 +1,119 @@
|
||||
# Data Transforms
|
||||
|
||||
In this tutorial, we introduce the design of transforms pipeline in MMSegmentation.
|
||||
|
||||
The structure of this guide is as follows:
|
||||
|
||||
- [Data Transforms](#data-transforms)
|
||||
- [Design of Data pipelines](#design-of-data-pipelines)
|
||||
- [Data loading](#data-loading)
|
||||
- [Pre-processing](#pre-processing)
|
||||
- [Formatting](#formatting)
|
||||
|
||||
## Design of Data pipelines
|
||||
|
||||
Following typical conventions, we use `Dataset` and `DataLoader` for data loading with multiple workers. `Dataset` returns a dict of data items corresponding the arguments of models' forward method. Since the data in semantic segmentation may not be the same size, we introduce a new `DataContainer` type in MMCV to help collect and distribute data of different size. See [here](https://github.com/open-mmlab/mmcv/blob/master/mmcv/parallel/data_container.py) for more details.
|
||||
|
||||
In 1.x version of MMSegmentation, all data transformations are inherited from [`BaseTransform`](https://github.com/open-mmlab/mmcv/blob/2.x/mmcv/transforms/base.py#L6).
|
||||
|
||||
The input and output types of transformations are both dict. A simple example is as follows:
|
||||
|
||||
```python
|
||||
>>> from mmseg.datasets.transforms import LoadAnnotations
|
||||
>>> transforms = LoadAnnotations()
|
||||
>>> img_path = './data/cityscapes/leftImg8bit/train/aachen/aachen_000000_000019_leftImg8bit.png.png'
|
||||
>>> gt_path = './data/cityscapes/gtFine/train/aachen/aachen_000015_000019_gtFine_instanceTrainIds.png'
|
||||
>>> results = dict(
|
||||
>>> img_path=img_path,
|
||||
>>> seg_map_path=gt_path,
|
||||
>>> reduce_zero_label=False,
|
||||
>>> seg_fields=[])
|
||||
>>> data_dict = transforms(results)
|
||||
>>> print(data_dict.keys())
|
||||
dict_keys(['img_path', 'seg_map_path', 'reduce_zero_label', 'seg_fields', 'gt_seg_map'])
|
||||
```
|
||||
|
||||
The data preparation pipeline and the dataset are decomposed. Usually a dataset defines how to process the annotations and a data pipeline defines all the steps to prepare a data dict. A pipeline consists of a sequence of operations. Each operation takes a dict as input and also outputs a dict for the next transform.
|
||||
|
||||
The operations are categorized into data loading, pre-processing, formatting and test-time augmentation.
|
||||
|
||||
Here is a pipeline example for PSPNet:
|
||||
|
||||
```python
|
||||
crop_size = (512, 1024)
|
||||
train_pipeline = [
|
||||
dict(type='LoadImageFromFile'),
|
||||
dict(type='LoadAnnotations'),
|
||||
dict(
|
||||
type='RandomResize',
|
||||
scale=(2048, 1024),
|
||||
ratio_range=(0.5, 2.0),
|
||||
keep_ratio=True),
|
||||
dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
|
||||
dict(type='RandomFlip', prob=0.5),
|
||||
dict(type='PhotoMetricDistortion'),
|
||||
dict(type='PackSegInputs')
|
||||
]
|
||||
test_pipeline = [
|
||||
dict(type='LoadImageFromFile'),
|
||||
dict(type='Resize', scale=(2048, 1024), keep_ratio=True),
|
||||
# add loading annotation after ``Resize`` because ground truth
|
||||
# does not need to resize data transform
|
||||
dict(type='LoadAnnotations'),
|
||||
dict(type='PackSegInputs')
|
||||
]
|
||||
```
|
||||
|
||||
For each operation, we list the related dict fields that are `added`/`updated`/`removed`. Before pipelines, the information we can directly obtain from the datasets are `img_path` and `seg_map_path`.
|
||||
|
||||
### Data loading
|
||||
|
||||
`LoadImageFromFile`: Load an image from file.
|
||||
|
||||
- add: `img`, `img_shape`, `ori_shape`
|
||||
|
||||
`LoadAnnotations`: Load semantic segmentation maps provided by dataset.
|
||||
|
||||
- add: `seg_fields`, `gt_seg_map`
|
||||
|
||||
### Pre-processing
|
||||
|
||||
`RandomResize`: Random resize image & segmentation map.
|
||||
|
||||
- add: `scale`, `scale_factor`, `keep_ratio`
|
||||
- update: `img`, `img_shape`, `gt_seg_map`
|
||||
|
||||
`Resize`: Resize image & segmentation map.
|
||||
|
||||
- add: `scale`, `scale_factor`, `keep_ratio`
|
||||
- update: `img`, `gt_seg_map`, `img_shape`
|
||||
|
||||
`RandomCrop`: Random crop image & segmentation map.
|
||||
|
||||
- update: `img`, `gt_seg_map`, `img_shape`
|
||||
|
||||
`RandomFlip`: Flip the image & segmentation map.
|
||||
|
||||
- add: `flip`, `flip_direction`
|
||||
- update: `img`, `gt_seg_map`
|
||||
|
||||
`PhotoMetricDistortion`: Apply photometric distortion to image sequentially, every transformation is applied with a probability of 0.5. The position of random contrast is in second or second to last(mode 0 or 1 below, respectively).
|
||||
|
||||
```
|
||||
1. random brightness
|
||||
2. random contrast (mode 0)
|
||||
3. convert color from BGR to HSV
|
||||
4. random saturation
|
||||
5. random hue
|
||||
6. convert color from HSV to BGR
|
||||
7. random contrast (mode 1)
|
||||
```
|
||||
|
||||
- update: `img`
|
||||
|
||||
### Formatting
|
||||
|
||||
`PackSegInputs`: Pack the inputs data for the semantic segmentation.
|
||||
|
||||
- add: `inputs`, `data_sample`
|
||||
- remove: keys specified by `meta_keys` (merged into the metainfo of data_sample), all other keys
|
||||
95
Seg_All_In_One_MMSeg/docs/en/api.rst
Normal file
95
Seg_All_In_One_MMSeg/docs/en/api.rst
Normal file
@@ -0,0 +1,95 @@
|
||||
mmseg.apis
|
||||
--------------
|
||||
.. automodule:: mmseg.apis
|
||||
:members:
|
||||
|
||||
mmseg.datasets
|
||||
--------------
|
||||
|
||||
datasets
|
||||
^^^^^^^^^^
|
||||
.. automodule:: mmseg.datasets
|
||||
:members:
|
||||
|
||||
transforms
|
||||
^^^^^^^^^^^^
|
||||
.. automodule:: mmseg.datasets.transforms
|
||||
:members:
|
||||
|
||||
mmseg.engine
|
||||
--------------
|
||||
|
||||
hooks
|
||||
^^^^^^^^^^
|
||||
.. automodule:: mmseg.engine.hooks
|
||||
:members:
|
||||
|
||||
optimizers
|
||||
^^^^^^^^^^^^^^^
|
||||
.. automodule:: mmseg.engine.optimizers
|
||||
:members:
|
||||
|
||||
mmseg.evaluation
|
||||
-----------------
|
||||
|
||||
metrics
|
||||
^^^^^^^^^^
|
||||
.. automodule:: mmseg.evaluation.metrics
|
||||
:members:
|
||||
|
||||
mmseg.models
|
||||
--------------
|
||||
|
||||
backbones
|
||||
^^^^^^^^^^^^^^^^^^
|
||||
.. automodule:: mmseg.models.backbones
|
||||
:members:
|
||||
|
||||
decode_heads
|
||||
^^^^^^^^^^^^^^^
|
||||
.. automodule:: mmseg.models.decode_heads
|
||||
:members:
|
||||
|
||||
segmentors
|
||||
^^^^^^^^^^
|
||||
.. automodule:: mmseg.models.segmentors
|
||||
:members:
|
||||
|
||||
losses
|
||||
^^^^^^^^^^
|
||||
.. automodule:: mmseg.models.losses
|
||||
:members:
|
||||
|
||||
necks
|
||||
^^^^^^^^^^^^
|
||||
.. automodule:: mmseg.models.necks
|
||||
:members:
|
||||
|
||||
utils
|
||||
^^^^^^^^^^
|
||||
.. automodule:: mmseg.models.utils
|
||||
:members:
|
||||
|
||||
|
||||
mmseg.structures
|
||||
--------------------
|
||||
|
||||
structures
|
||||
^^^^^^^^^^^^^^^^^
|
||||
.. automodule:: mmseg.structures
|
||||
:members:
|
||||
|
||||
sampler
|
||||
^^^^^^^^^^
|
||||
.. automodule:: mmseg.structures.sampler
|
||||
:members:
|
||||
|
||||
mmseg.visualization
|
||||
--------------------
|
||||
.. automodule:: mmseg.visualization
|
||||
:members:
|
||||
|
||||
mmseg.utils
|
||||
--------------
|
||||
.. automodule:: mmseg.utils
|
||||
:members:
|
||||
133
Seg_All_In_One_MMSeg/docs/en/conf.py
Normal file
133
Seg_All_In_One_MMSeg/docs/en/conf.py
Normal file
@@ -0,0 +1,133 @@
|
||||
# Copyright (c) OpenMMLab. All rights reserved.
|
||||
# Configuration file for the Sphinx documentation builder.
|
||||
#
|
||||
# This file only contains a selection of the most common options. For a full
|
||||
# list see the documentation:
|
||||
# https://www.sphinx-doc.org/en/master/usage/configuration.html
|
||||
|
||||
# -- Path setup --------------------------------------------------------------
|
||||
|
||||
# If extensions (or modules to document with autodoc) are in another directory,
|
||||
# add these directories to sys.path here. If the directory is relative to the
|
||||
# documentation root, use os.path.abspath to make it absolute, like shown here.
|
||||
#
|
||||
import os
|
||||
import subprocess
|
||||
import sys
|
||||
|
||||
import pytorch_sphinx_theme
|
||||
|
||||
sys.path.insert(0, os.path.abspath('../../'))
|
||||
|
||||
# -- Project information -----------------------------------------------------
|
||||
|
||||
project = 'MMSegmentation'
|
||||
copyright = '2020-2021, OpenMMLab'
|
||||
author = 'MMSegmentation Authors'
|
||||
version_file = '../../mmseg/version.py'
|
||||
|
||||
|
||||
def get_version():
|
||||
with open(version_file) as f:
|
||||
exec(compile(f.read(), version_file, 'exec'))
|
||||
return locals()['__version__']
|
||||
|
||||
|
||||
# The full version, including alpha/beta/rc tags
|
||||
release = get_version()
|
||||
|
||||
# -- General configuration ---------------------------------------------------
|
||||
|
||||
# Add any Sphinx extension module names here, as strings. They can be
|
||||
# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
|
||||
# ones.
|
||||
extensions = [
|
||||
'sphinx.ext.autodoc', 'sphinx.ext.napoleon', 'sphinx.ext.viewcode',
|
||||
'sphinx_markdown_tables', 'sphinx_copybutton', 'myst_parser'
|
||||
]
|
||||
|
||||
autodoc_mock_imports = [
|
||||
'matplotlib', 'pycocotools', 'mmseg.version', 'mmcv.ops'
|
||||
]
|
||||
|
||||
# Ignore >>> when copying code
|
||||
copybutton_prompt_text = r'>>> |\.\.\. '
|
||||
copybutton_prompt_is_regexp = True
|
||||
|
||||
# Add any paths that contain templates here, relative to this directory.
|
||||
templates_path = ['_templates']
|
||||
|
||||
# The suffix(es) of source filenames.
|
||||
# You can specify multiple suffix as a list of string:
|
||||
#
|
||||
source_suffix = {
|
||||
'.rst': 'restructuredtext',
|
||||
'.md': 'markdown',
|
||||
}
|
||||
|
||||
# The master toctree document.
|
||||
master_doc = 'index'
|
||||
|
||||
# List of patterns, relative to source directory, that match files and
|
||||
# directories to ignore when looking for source files.
|
||||
# This pattern also affects html_static_path and html_extra_path.
|
||||
exclude_patterns = ['_build', 'Thumbs.db', '.DS_Store']
|
||||
|
||||
# -- Options for HTML output -------------------------------------------------
|
||||
|
||||
# The theme to use for HTML and HTML Help pages. See the documentation for
|
||||
# a list of builtin themes.
|
||||
#
|
||||
# html_theme = 'sphinx_rtd_theme'
|
||||
html_theme = 'pytorch_sphinx_theme'
|
||||
html_theme_path = [pytorch_sphinx_theme.get_html_theme_path()]
|
||||
html_theme_options = {
|
||||
'logo_url':
|
||||
'https://mmsegmentation.readthedocs.io/en/latest/',
|
||||
'menu': [
|
||||
{
|
||||
'name':
|
||||
'Tutorial',
|
||||
'url':
|
||||
'https://github.com/open-mmlab/mmsegmentation/blob/master/'
|
||||
'demo/MMSegmentation_Tutorial.ipynb'
|
||||
},
|
||||
{
|
||||
'name': 'GitHub',
|
||||
'url': 'https://github.com/open-mmlab/mmsegmentation'
|
||||
},
|
||||
{
|
||||
'name':
|
||||
'Upstream',
|
||||
'children': [
|
||||
{
|
||||
'name': 'MMCV',
|
||||
'url': 'https://github.com/open-mmlab/mmcv',
|
||||
'description': 'Foundational library for computer vision'
|
||||
},
|
||||
]
|
||||
},
|
||||
],
|
||||
# Specify the language of shared menu
|
||||
'menu_lang':
|
||||
'en'
|
||||
}
|
||||
|
||||
# Add any paths that contain custom static files (such as style sheets) here,
|
||||
# relative to this directory. They are copied after the builtin static files,
|
||||
# so a file named "default.css" will overwrite the builtin "default.css".
|
||||
html_static_path = ['_static']
|
||||
html_css_files = ['css/readthedocs.css']
|
||||
|
||||
# Enable ::: for my_st
|
||||
myst_enable_extensions = ['colon_fence']
|
||||
|
||||
language = 'en'
|
||||
|
||||
|
||||
def builder_inited_handler(app):
|
||||
subprocess.run(['./stat.py'])
|
||||
|
||||
|
||||
def setup(app):
|
||||
app.connect('builder-inited', builder_inited_handler)
|
||||
39
Seg_All_In_One_MMSeg/docs/en/device/npu.md
Normal file
39
Seg_All_In_One_MMSeg/docs/en/device/npu.md
Normal file
@@ -0,0 +1,39 @@
|
||||
# NPU (HUAWEI Ascend)
|
||||
|
||||
## Usage
|
||||
|
||||
Please refer to the [building documentation of MMCV](https://mmcv.readthedocs.io/en/latest/get_started/build.html#build-mmcv-full-on-ascend-npu-machine) to install MMCV on NPU devices
|
||||
|
||||
Here we use 4 NPUs on your computer to train the model with the following command:
|
||||
|
||||
```shell
|
||||
bash tools/dist_train.sh configs/deeplabv3/deeplabv3_r50-d8_4xb2-40k_cityscapes-512x1024.py 4
|
||||
```
|
||||
|
||||
Also, you can use only one NPU to train the model with the following command:
|
||||
|
||||
```shell
|
||||
python tools/train.py configs/deeplabv3/deeplabv3_r50-d8_4xb2-40k_cityscapes-512x1024.py
|
||||
```
|
||||
|
||||
## Models Results
|
||||
|
||||
| Model | mIoU | Config | Download |
|
||||
| :-----------------: | :---: | :----------------------------------------------------------------------------------------------------------------------------------------- | :------------------------------------------------------------------------------------------------------------------------------------------ |
|
||||
| [deeplabv3](<>) | 78.85 | [config](https://github.com/open-mmlab/mmsegmentation/tree/1.x/configs/deeplabv3/deeplabv3_r50-d8_4xb2-40k_cityscapes-512x1024.py) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/device/npu/deeplabv3_r50-d8_4xb2-40k_cityscapes-512x1024_20230115_205626.json) |
|
||||
| [deeplabv3plus](<>) | 79.23 | [config](https://github.com/open-mmlab/mmsegmentation/tree/1.x/configs/deeplabv3plus/deeplabv3plus_r50-d8_4xb2-40k_cityscapes-512x1024.py) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/device/npu/deeplabv3plus_r50-d8_4xb2-40k_cityscapes-512x1024_20230116_043450.json) |
|
||||
| [hrnet](<>) | 78.1 | [config](https://github.com/open-mmlab/mmsegmentation/tree/1.x/configs/hrnet/fcn_hr18_4xb2-40k_cityscapes-512x1024.py) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/device/npu/fcn_hr18_4xb2-40k_cityscapes-512x1024_20230116_215821.json) |
|
||||
| [fcn](<>) | 74.15 | [config](https://github.com/open-mmlab/mmsegmentation/tree/1.x/configs/fcn/fcn_r50-d8_4xb2-40k_cityscapes-512x1024.py) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/device/npu/fcn_r50-d8_4xb2-40k_cityscapes-512x1024_20230111_083014.json) |
|
||||
| [icnet](<>) | 69.25 | [config](https://github.com/open-mmlab/mmsegmentation/tree/1.x/configs/icnet/icnet_r50-d8_4xb2-80k_cityscapes-832x832.py) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/device/npu/icnet_r50-d8_4xb2-80k_cityscapes-832x832_20230119_002929.json) |
|
||||
| [pspnet](<>) | 77.21 | [config](https://github.com/open-mmlab/mmsegmentation/tree/1.x/configs/pspnet/pspnet_r50b-d8_4xb2-80k_cityscapes-512x1024.py) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/device/npu/pspnet_r50b-d8_4xb2-80k_cityscapes-512x1024_20230114_042721.json) |
|
||||
| [unet](<>) | 68.86 | [config](https://github.com/open-mmlab/mmsegmentation/tree/1.x/configs/unet/unet-s5-d16_fcn_4xb4-160k_cityscapes-512x1024.py) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/device/npu/unet-s5-d16_fcn_4xb4-160k_cityscapes-512x1024_20230129_224750.json) |
|
||||
| [upernet](<>) | 77.81 | [config](https://github.com/open-mmlab/mmsegmentation/tree/1.x/configs/upernet/upernet_r50_4xb2-40k_cityscapes-512x1024.py) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/device/npu/upernet_r50_4xb2-40k_cityscapes-512x1024_20230129_014634.json) |
|
||||
| [apcnet](<>) | 78.02 | [config](https://github.com/open-mmlab/mmsegmentation/tree/1.x/configs/apcnet/apcnet_r50-d8_4xb2-40k_cityscapes-512x1024.py) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/device/npu/apcnet_r50-d8_4xb2-40k_cityscapes-512x1024_20230209_212545.json) |
|
||||
| [bisenetv1](<>) | 76.04 | [config](https://github.com/open-mmlab/mmsegmentation/tree/1.x/configs/bisenetv1/bisenetv1_r50-d32_4xb4-160k_cityscapes-1024x1024.py) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/device/npu/bisenetv1_r50-d32_4xb4-160k_cityscapes-1024x1024_20230201_023946.json) |
|
||||
| [bisenetv2](<>) | 72.44 | [config](https://github.com/open-mmlab/mmsegmentation/tree/1.x/configs/bisenetv2/bisenetv2_fcn_4xb4-amp-160k_cityscapes-1024x1024.py) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/device/npu/bisenetv2_fcn_4xb4-amp-160k_cityscapes-1024x1024_20230205_215606.json) |
|
||||
|
||||
**Notes:**
|
||||
|
||||
- If not specially marked, the results on NPU with amp are the basically same as those on the GPU with FP32.
|
||||
|
||||
**All above models are provided by Huawei Ascend group.**
|
||||
211
Seg_All_In_One_MMSeg/docs/en/get_started.md
Normal file
211
Seg_All_In_One_MMSeg/docs/en/get_started.md
Normal file
@@ -0,0 +1,211 @@
|
||||
# Get started: Install and Run MMSeg
|
||||
|
||||
## Prerequisites
|
||||
|
||||
In this section we demonstrate how to prepare an environment with PyTorch.
|
||||
|
||||
MMSegmentation works on Linux, Windows and macOS. It requires Python 3.7+, CUDA 10.2+ and PyTorch 1.8+.
|
||||
|
||||
**Note:**
|
||||
If you are experienced with PyTorch and have already installed it, just skip this part and jump to the [next section](##installation). Otherwise, you can follow these steps for the preparation.
|
||||
|
||||
**Step 0.** Download and install Miniconda from the [official website](https://docs.conda.io/en/latest/miniconda.html).
|
||||
|
||||
**Step 1.** Create a conda environment and activate it.
|
||||
|
||||
```shell
|
||||
conda create --name openmmlab python=3.8 -y
|
||||
conda activate openmmlab
|
||||
```
|
||||
|
||||
**Step 2.** Install PyTorch following [official instructions](https://pytorch.org/get-started/locally/), e.g.
|
||||
|
||||
On GPU platforms:
|
||||
|
||||
```shell
|
||||
conda install pytorch torchvision -c pytorch
|
||||
```
|
||||
|
||||
On CPU platforms:
|
||||
|
||||
```shell
|
||||
conda install pytorch torchvision cpuonly -c pytorch
|
||||
```
|
||||
|
||||
## Installation
|
||||
|
||||
We recommend that users follow our best practices to install MMSegmentation. However, the whole process is highly customizable. See [Customize Installation](#customize-installation) section for more information.
|
||||
|
||||
### Best Practices
|
||||
|
||||
**Step 0.** Install [MMCV](https://github.com/open-mmlab/mmcv) using [MIM](https://github.com/open-mmlab/mim).
|
||||
|
||||
```shell
|
||||
pip install -U openmim
|
||||
mim install mmengine
|
||||
mim install "mmcv>=2.0.0"
|
||||
```
|
||||
|
||||
**Step 1.** Install MMSegmentation.
|
||||
|
||||
Case a: If you develop and run mmseg directly, install it from source:
|
||||
|
||||
```shell
|
||||
git clone -b main https://github.com/open-mmlab/mmsegmentation.git
|
||||
cd mmsegmentation
|
||||
pip install -v -e .
|
||||
# '-v' means verbose, or more output
|
||||
# '-e' means installing a project in editable mode,
|
||||
# thus any local modifications made to the code will take effect without reinstallation.
|
||||
```
|
||||
|
||||
Case b: If you use mmsegmentation as a dependency or third-party package, install it with pip:
|
||||
|
||||
```shell
|
||||
pip install "mmsegmentation>=1.0.0"
|
||||
```
|
||||
|
||||
### Verify the installation
|
||||
|
||||
To verify whether MMSegmentation is installed correctly, we provide some sample codes to run an inference demo.
|
||||
|
||||
**Step 1.** We need to download config and checkpoint files.
|
||||
|
||||
```shell
|
||||
mim download mmsegmentation --config pspnet_r50-d8_4xb2-40k_cityscapes-512x1024 --dest .
|
||||
```
|
||||
|
||||
The downloading will take several seconds or more, depending on your network environment. When it is done, you will find two files `pspnet_r50-d8_4xb2-40k_cityscapes-512x1024.py` and `pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth` in your current folder.
|
||||
|
||||
**Step 2.** Verify the inference demo.
|
||||
|
||||
Option (a). If you install mmsegmentation from source, just run the following command.
|
||||
|
||||
```shell
|
||||
python demo/image_demo.py demo/demo.png configs/pspnet/pspnet_r50-d8_4xb2-40k_cityscapes-512x1024.py pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth --device cuda:0 --out-file result.jpg
|
||||
```
|
||||
|
||||
You will see a new image `result.jpg` on your current folder, where segmentation masks are covered on all objects.
|
||||
|
||||
Option (b). If you install mmsegmentation with pip, open you python interpreter and copy&paste the following codes.
|
||||
|
||||
```python
|
||||
from mmseg.apis import inference_model, init_model, show_result_pyplot
|
||||
import mmcv
|
||||
|
||||
config_file = 'pspnet_r50-d8_4xb2-40k_cityscapes-512x1024.py'
|
||||
checkpoint_file = 'pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth'
|
||||
|
||||
# build the model from a config file and a checkpoint file
|
||||
model = init_model(config_file, checkpoint_file, device='cuda:0')
|
||||
|
||||
# test a single image and show the results
|
||||
img = 'demo/demo.png' # or img = mmcv.imread(img), which will only load it once
|
||||
result = inference_model(model, img)
|
||||
# visualize the results in a new window
|
||||
show_result_pyplot(model, img, result, show=True)
|
||||
# or save the visualization results to image files
|
||||
# you can change the opacity of the painted segmentation map in (0, 1].
|
||||
show_result_pyplot(model, img, result, show=True, out_file='result.jpg', opacity=0.5)
|
||||
# test a video and show the results
|
||||
video = mmcv.VideoReader('video.mp4')
|
||||
for frame in video:
|
||||
result = inference_model(model, frame)
|
||||
show_result_pyplot(model, frame, result, wait_time=1)
|
||||
```
|
||||
|
||||
You can modify the code above to test a single image or a video, both of these options can verify that the installation was successful.
|
||||
|
||||
### Customize Installation
|
||||
|
||||
#### CUDA versions
|
||||
|
||||
When installing PyTorch, you need to specify the version of CUDA. If you are not clear on which to choose, follow our recommendations:
|
||||
|
||||
- For Ampere-based NVIDIA GPUs, such as GeForce 30 series and NVIDIA A100, CUDA 11 is a must.
|
||||
- For older NVIDIA GPUs, CUDA 11 is backward compatible, but CUDA 10.2 offers better compatibility and is more lightweight.
|
||||
|
||||
Please make sure the GPU driver satisfies the minimum version requirements. See [this table](https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html#cuda-major-component-versions__table-cuda-toolkit-driver-versions) for more information.
|
||||
|
||||
**Note:**
|
||||
Installing CUDA runtime libraries is enough if you follow our best practices, because no CUDA code will be compiled locally. However if you hope to compile MMCV from source or develop other CUDA operators, you need to install the complete CUDA toolkit from NVIDIA's [website](https://developer.nvidia.com/cuda-downloads), and its version should match the CUDA version of PyTorch. i.e., the specified version of cudatoolkit in `conda install` command.
|
||||
|
||||
#### Install MMCV without MIM
|
||||
|
||||
MMCV contains C++ and CUDA extensions, thus depending on PyTorch in a complex way. MIM solves such dependencies automatically and makes the installation easier. However, it is not a must.
|
||||
|
||||
To install MMCV with pip instead of MIM, please follow [MMCV installation guides](https://mmcv.readthedocs.io/en/latest/get_started/installation.html). This requires manually specifying a find-url based on PyTorch version and its CUDA version.
|
||||
|
||||
For example, the following command install mmcv==2.0.0 built for PyTorch 1.10.x and CUDA 11.3.
|
||||
|
||||
```shell
|
||||
pip install mmcv==2.0.0 -f https://download.openmmlab.com/mmcv/dist/cu113/torch1.10/index.html
|
||||
```
|
||||
|
||||
#### Install on CPU-only platforms
|
||||
|
||||
MMSegmentation can be built for CPU only environment. In CPU mode you can train (requires MMCV version >= 2.0.0), test or inference a model.
|
||||
|
||||
#### Install on Google Colab
|
||||
|
||||
[Google Colab](https://research.google.com/) usually has PyTorch installed,
|
||||
thus we only need to install MMCV and MMSegmentation with the following commands.
|
||||
|
||||
**Step 1.** Install [MMCV](https://github.com/open-mmlab/mmcv) using [MIM](https://github.com/open-mmlab/mim).
|
||||
|
||||
```shell
|
||||
!pip3 install openmim
|
||||
!mim install mmengine
|
||||
!mim install "mmcv>=2.0.0"
|
||||
```
|
||||
|
||||
**Step 2.** Install MMSegmentation from the source.
|
||||
|
||||
```shell
|
||||
!git clone https://github.com/open-mmlab/mmsegmentation.git
|
||||
%cd mmsegmentation
|
||||
!git checkout main
|
||||
!pip install -e .
|
||||
```
|
||||
|
||||
**Step 3.** Verification.
|
||||
|
||||
```python
|
||||
import mmseg
|
||||
print(mmseg.__version__)
|
||||
# Example output: 1.0.0
|
||||
```
|
||||
|
||||
**Note:**
|
||||
Within Jupyter, the exclamation mark `!` is used to call external executables and `%cd` is a [magic command](https://ipython.readthedocs.io/en/stable/interactive/magics.html#magic-cd) to change the current working directory of Python.
|
||||
|
||||
### Using MMSegmentation with Docker
|
||||
|
||||
We provide a [Dockerfile](https://github.com/open-mmlab/mmsegmentation/blob/main/docker/Dockerfile) to build an image. Ensure that your [docker version](https://docs.docker.com/engine/install/) >=19.03.
|
||||
|
||||
```shell
|
||||
# build an image with PyTorch 1.11, CUDA 11.3
|
||||
# If you prefer other versions, just modified the Dockerfile
|
||||
docker build -t mmsegmentation docker/
|
||||
```
|
||||
|
||||
Run it with
|
||||
|
||||
```shell
|
||||
docker run --gpus all --shm-size=8g -it -v {DATA_DIR}:/mmsegmentation/data mmsegmentation
|
||||
```
|
||||
|
||||
### Optional Dependencies
|
||||
|
||||
#### Install GDAL
|
||||
|
||||
[GDAL](https://gdal.org/) is a translator library for raster and vector geospatial data formats. Install GDAL to read complex formats and extremely large remote sensing images.
|
||||
|
||||
```shell
|
||||
conda install GDAL
|
||||
```
|
||||
|
||||
## Trouble shooting
|
||||
|
||||
If you have some issues during the installation, please first view the [FAQ](notes/faq.md) page.
|
||||
You may [open an issue](https://github.com/open-mmlab/mmsegmentation/issues/new/choose) on GitHub if no solution is found.
|
||||
63
Seg_All_In_One_MMSeg/docs/en/index.rst
Normal file
63
Seg_All_In_One_MMSeg/docs/en/index.rst
Normal file
@@ -0,0 +1,63 @@
|
||||
Welcome to MMSegmentation's documentation!
|
||||
===========================================
|
||||
|
||||
.. toctree::
|
||||
:maxdepth: 1
|
||||
:caption: Get Started
|
||||
|
||||
overview.md
|
||||
get_started.md
|
||||
|
||||
.. toctree::
|
||||
:maxdepth: 2
|
||||
:caption: User Guides
|
||||
|
||||
user_guides/index.rst
|
||||
|
||||
.. toctree::
|
||||
:maxdepth: 2
|
||||
:caption: Advanced Guides
|
||||
|
||||
advanced_guides/index.rst
|
||||
|
||||
.. toctree::
|
||||
:maxdepth: 1
|
||||
:caption: Migration
|
||||
|
||||
migration/index.rst
|
||||
|
||||
.. toctree::
|
||||
:caption: API Reference
|
||||
|
||||
api.rst
|
||||
|
||||
.. toctree::
|
||||
:maxdepth: 1
|
||||
:caption: Model Zoo
|
||||
|
||||
model_zoo.md
|
||||
modelzoo_statistics.md
|
||||
|
||||
.. toctree::
|
||||
:maxdepth: 1
|
||||
:caption: Notes
|
||||
|
||||
notes/changelog.md
|
||||
notes/faq.md
|
||||
|
||||
.. toctree::
|
||||
:caption: Device Support
|
||||
|
||||
device/npu.md
|
||||
|
||||
.. toctree::
|
||||
:caption: Switch Language
|
||||
|
||||
switch_language.md
|
||||
|
||||
|
||||
Indices and tables
|
||||
==================
|
||||
|
||||
* :ref:`genindex`
|
||||
* :ref:`search`
|
||||
35
Seg_All_In_One_MMSeg/docs/en/make.bat
Normal file
35
Seg_All_In_One_MMSeg/docs/en/make.bat
Normal file
@@ -0,0 +1,35 @@
|
||||
@ECHO OFF
|
||||
|
||||
pushd %~dp0
|
||||
|
||||
REM Command file for Sphinx documentation
|
||||
|
||||
if "%SPHINXBUILD%" == "" (
|
||||
set SPHINXBUILD=sphinx-build
|
||||
)
|
||||
set SOURCEDIR=.
|
||||
set BUILDDIR=_build
|
||||
|
||||
if "%1" == "" goto help
|
||||
|
||||
%SPHINXBUILD% >NUL 2>NUL
|
||||
if errorlevel 9009 (
|
||||
echo.
|
||||
echo.The 'sphinx-build' command was not found. Make sure you have Sphinx
|
||||
echo.installed, then set the SPHINXBUILD environment variable to point
|
||||
echo.to the full path of the 'sphinx-build' executable. Alternatively you
|
||||
echo.may add the Sphinx directory to PATH.
|
||||
echo.
|
||||
echo.If you don't have Sphinx installed, grab it from
|
||||
echo.http://sphinx-doc.org/
|
||||
exit /b 1
|
||||
)
|
||||
|
||||
%SPHINXBUILD% -M %1 %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O%
|
||||
goto end
|
||||
|
||||
:help
|
||||
%SPHINXBUILD% -M help %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O%
|
||||
|
||||
:end
|
||||
popd
|
||||
8
Seg_All_In_One_MMSeg/docs/en/migration/index.rst
Normal file
8
Seg_All_In_One_MMSeg/docs/en/migration/index.rst
Normal file
@@ -0,0 +1,8 @@
|
||||
Migration
|
||||
***************
|
||||
|
||||
.. toctree::
|
||||
:maxdepth: 1
|
||||
|
||||
interface.md
|
||||
package.md
|
||||
525
Seg_All_In_One_MMSeg/docs/en/migration/interface.md
Normal file
525
Seg_All_In_One_MMSeg/docs/en/migration/interface.md
Normal file
@@ -0,0 +1,525 @@
|
||||
# Migration from MMSegmentation 0.x
|
||||
|
||||
## Introduction
|
||||
|
||||
This guide describes the fundamental differences between MMSegmentation 0.x and MMSegmentation 1.x in terms of behaviors and the APIs, and how these all relate to your migration journey.
|
||||
|
||||
## New dependencies
|
||||
|
||||
MMSegmentation 1.x depends on some new packages, you can prepare a new clean environment and install again according to the [installation tutorial](../get_started.md).
|
||||
|
||||
Or install the below packages manually.
|
||||
|
||||
1. [MMEngine](https://github.com/open-mmlab/mmengine): MMEngine is the core the OpenMMLab 2.0 architecture, and we splited many compentents unrelated to computer vision from MMCV to MMEngine.
|
||||
|
||||
2. [MMCV](https://github.com/open-mmlab/mmcv): The computer vision package of OpenMMLab. This is not a new dependency, but you need to upgrade it to **2.0.0** version or above.
|
||||
|
||||
3. [MMClassification](https://github.com/open-mmlab/mmclassification)(Optional): The image classification toolbox and benchmark of OpenMMLab. This is not a new dependency, but you need to upgrade it to **1.0.0rc6** version.
|
||||
|
||||
4. [MMDetection](https://github.com/open-mmlab/mmdetection)(Optional): The object detection toolbox and benchmark of OpenMMLab. This is not a new dependency, but you need to upgrade it to **3.0.0** version or above.
|
||||
|
||||
## Train launch
|
||||
|
||||
The main improvement of OpenMMLab 2.0 is releasing MMEngine which provides universal and powerful runner for unified interfaces to launch training jobs.
|
||||
|
||||
Compared with MMSeg0.x, MMSeg1.x provides fewer command line arguments in `tools/train.py`
|
||||
|
||||
<table class="docutils">
|
||||
<tr>
|
||||
<td>Function</td>
|
||||
<td>Original</td>
|
||||
<td>New</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Loading pre-trained checkpoint</td>
|
||||
<td>--load_from=$CHECKPOINT</td>
|
||||
<td>--cfg-options load_from=$CHECKPOINT</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Resuming Train from specific checkpoint</td>
|
||||
<td>--resume-from=$CHECKPOINT</td>
|
||||
<td>--resume=$CHECKPOINT</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Resuming Train from the latest checkpoint</td>
|
||||
<td>--auto-resume</td>
|
||||
<td>--resume='auto'</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Whether not to evaluate the checkpoint during training</td>
|
||||
<td>--no-validate</td>
|
||||
<td>--cfg-options val_cfg=None val_dataloader=None val_evaluator=None</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Training device assignment</td>
|
||||
<td>--gpu-id=$DEVICE_ID</td>
|
||||
<td>-</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Whether or not set different seeds for different ranks</td>
|
||||
<td>--diff-seed</td>
|
||||
<td>--cfg-options randomness.diff_rank_seed=True</td>
|
||||
</tr>
|
||||
<td>Whether to set deterministic options for CUDNN backend</td>
|
||||
<td>--deterministic</td>
|
||||
<td>--cfg-options randomness.deterministic=True</td>
|
||||
</table>
|
||||
|
||||
## Test launch
|
||||
|
||||
Similar to training launch, there are only common arguments in tools/test.py of MMSegmentation 1.x.
|
||||
Below is the difference in test scripts,
|
||||
please refer to [this documentation](../user_guides/4_train_test.md) for more details about test launch.
|
||||
|
||||
<table class="docutils">
|
||||
<tr>
|
||||
<td>Function</td>
|
||||
<td>0.x</td>
|
||||
<td>1.x</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Evaluation metrics</td>
|
||||
<td>--eval mIoU</td>
|
||||
<td>--cfg-options test_evaluator.type=IoUMetric</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Whether to use test time augmentation</td>
|
||||
<td>--aug-test</td>
|
||||
<td>--tta</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Whether save the output results without perform evaluation</td>
|
||||
<td>--format-only</td>
|
||||
<td>--cfg-options test_evaluator.format_only=True</td>
|
||||
</tr>
|
||||
</table>
|
||||
|
||||
## Configuration file
|
||||
|
||||
### Model settings
|
||||
|
||||
No changes in `model.backbone`, `model.neck`, `model.decode_head` and `model.losses` fields.
|
||||
|
||||
Add `model.data_preprocessor` field to configure the `DataPreProcessor`, including:
|
||||
|
||||
- `mean` (Sequence, optional): The pixel mean of R, G, B channels. Defaults to None.
|
||||
|
||||
- `std` (Sequence, optional): The pixel standard deviation of R, G, B channels. Defaults to None.
|
||||
|
||||
- `size` (Sequence, optional): Fixed padding size.
|
||||
|
||||
- `size_divisor` (int, optional): The divisor of padded size.
|
||||
|
||||
- `seg_pad_val` (float, optional): Padding value of segmentation map. Default: 255.
|
||||
|
||||
- `padding_mode` (str): Type of padding. Default: 'constant'.
|
||||
|
||||
- constant: pads with a constant value, this value is specified with pad_val.
|
||||
|
||||
- `bgr_to_rgb` (bool): whether to convert image from BGR to RGB.Defaults to False.
|
||||
|
||||
- `rgb_to_bgr` (bool): whether to convert image from RGB to BGR. Defaults to False.
|
||||
|
||||
**Note:**
|
||||
Please refer [models documentation](../advanced_guides/models.md) for more details.
|
||||
|
||||
### Dataset settings
|
||||
|
||||
Changes in **data**:
|
||||
|
||||
The original `data` field is split to `train_dataloader`, `val_dataloader` and `test_dataloader`. This allows us to configure them in fine-grained. For example, you can specify different sampler and batch size during training and test.
|
||||
The `samples_per_gpu` is renamed to `batch_size`.
|
||||
The `workers_per_gpu` is renamed to `num_workers`.
|
||||
|
||||
<table class="docutils">
|
||||
<tr>
|
||||
<td>Original</td>
|
||||
<td>
|
||||
|
||||
```python
|
||||
data = dict(
|
||||
samples_per_gpu=4,
|
||||
workers_per_gpu=4,
|
||||
train=dict(...),
|
||||
val=dict(...),
|
||||
test=dict(...),
|
||||
)
|
||||
```
|
||||
|
||||
</td>
|
||||
<tr>
|
||||
<td>New</td>
|
||||
<td>
|
||||
|
||||
```python
|
||||
train_dataloader = dict(
|
||||
batch_size=4,
|
||||
num_workers=4,
|
||||
dataset=dict(...),
|
||||
sampler=dict(type='DefaultSampler', shuffle=True) # necessary
|
||||
)
|
||||
|
||||
val_dataloader = dict(
|
||||
batch_size=4,
|
||||
num_workers=4,
|
||||
dataset=dict(...),
|
||||
sampler=dict(type='DefaultSampler', shuffle=False) # necessary
|
||||
)
|
||||
|
||||
test_dataloader = val_dataloader
|
||||
```
|
||||
|
||||
</td>
|
||||
</tr>
|
||||
</table>
|
||||
|
||||
Changes in **pipeline**
|
||||
|
||||
- The original formatting transforms **`ToTensor`**、**`ImageToTensor`**、**`Collect`** are combined as [`PackSegInputs`](mmseg.datasets.transforms.PackSegInputs)
|
||||
- We don't recommend to do **`Normalize`** and **Pad** in the dataset pipeline. Please remove it from pipelines and set it in the `data_preprocessor` field.
|
||||
- The original **`Resize`** in MMSeg 1.x has been changed to **`RandomResize`** and the input arguments `img_scale` is renamed to `scale`, and the default value of `keep_ratio` is modified to False.
|
||||
- The original `test_pipeline` combines single-scale test and multi-scale test together, in MMSeg 1.x we separate it into `test_pipeline` and `tta_pipeline`.
|
||||
|
||||
**Note:**
|
||||
We move some work of data transforms to the data preprocessor, like normalization, see [the documentation](package.md) for more details.
|
||||
|
||||
train_pipeline
|
||||
|
||||
<table class="docutils">
|
||||
<tr>
|
||||
<td>Original</td>
|
||||
<td>
|
||||
|
||||
```python
|
||||
train_pipeline = [
|
||||
dict(type='LoadImageFromFile'),
|
||||
dict(type='LoadAnnotations', reduce_zero_label=True),
|
||||
dict(type='Resize', img_scale=(2560, 640), ratio_range=(0.5, 2.0)),
|
||||
dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
|
||||
dict(type='RandomFlip', prob=0.5),
|
||||
dict(type='PhotoMetricDistortion'),
|
||||
dict(type='Normalize', **img_norm_cfg),
|
||||
dict(type='Pad', size=crop_size, pad_val=0, seg_pad_val=255),
|
||||
dict(type='DefaultFormatBundle'),
|
||||
dict(type='Collect', keys=['img', 'gt_semantic_seg']),
|
||||
]
|
||||
```
|
||||
|
||||
</td>
|
||||
<tr>
|
||||
<td>New</td>
|
||||
<td>
|
||||
|
||||
```python
|
||||
train_pipeline = [
|
||||
dict(type='LoadImageFromFile'),
|
||||
dict(type='LoadAnnotations', reduce_zero_label=True),
|
||||
dict(
|
||||
type='RandomResize',
|
||||
scale=(2560, 640),
|
||||
ratio_range=(0.5, 2.0),
|
||||
keep_ratio=True),
|
||||
dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
|
||||
dict(type='RandomFlip', prob=0.5),
|
||||
dict(type='PhotoMetricDistortion'),
|
||||
dict(type='PackSegInputs')
|
||||
]
|
||||
```
|
||||
|
||||
</td>
|
||||
</tr>
|
||||
</table>
|
||||
|
||||
test_pipeline
|
||||
|
||||
<table class="docutils">
|
||||
<tr>
|
||||
<td>Original</td>
|
||||
<td>
|
||||
|
||||
```python
|
||||
test_pipeline = [
|
||||
dict(type='LoadImageFromFile'),
|
||||
dict(
|
||||
type='MultiScaleFlipAug',
|
||||
img_scale=(2560, 640),
|
||||
# img_ratios=[0.5, 0.75, 1.0, 1.25, 1.5, 1.75],
|
||||
flip=False,
|
||||
transforms=[
|
||||
dict(type='Resize', keep_ratio=True),
|
||||
dict(type='RandomFlip'),
|
||||
dict(type='Normalize', **img_norm_cfg),
|
||||
dict(type='ImageToTensor', keys=['img']),
|
||||
dict(type='Collect', keys=['img']),
|
||||
])
|
||||
]
|
||||
```
|
||||
|
||||
</td>
|
||||
<tr>
|
||||
<td>New</td>
|
||||
<td>
|
||||
|
||||
```python
|
||||
test_pipeline = [
|
||||
dict(type='LoadImageFromFile'),
|
||||
dict(type='Resize', scale=(2560, 640), keep_ratio=True),
|
||||
dict(type='LoadAnnotations', reduce_zero_label=True),
|
||||
dict(type='PackSegInputs')
|
||||
]
|
||||
img_ratios = [0.5, 0.75, 1.0, 1.25, 1.5, 1.75]
|
||||
tta_pipeline = [
|
||||
dict(type='LoadImageFromFile', backend_args=None),
|
||||
dict(
|
||||
type='TestTimeAug',
|
||||
transforms=[
|
||||
[
|
||||
dict(type='Resize', scale_factor=r, keep_ratio=True)
|
||||
for r in img_ratios
|
||||
],
|
||||
[
|
||||
dict(type='RandomFlip', prob=0., direction='horizontal'),
|
||||
dict(type='RandomFlip', prob=1., direction='horizontal')
|
||||
], [dict(type='LoadAnnotations')], [dict(type='PackSegInputs')]
|
||||
])
|
||||
]
|
||||
```
|
||||
|
||||
</td>
|
||||
</tr>
|
||||
</table>
|
||||
|
||||
Changes in **`evaluation`**:
|
||||
|
||||
- The **`evaluation`** field is split to `val_evaluator` and `test_evaluator`. And it won't support `interval` and `save_best` arguments.
|
||||
The `interval` is moved to `train_cfg.val_interval`, and the `save_best` is moved to `default_hooks.checkpoint.save_best`. `pre_eval` has been removed.
|
||||
- `'mIoU'` has been changed to `'IoUMetric'`.
|
||||
|
||||
<table class="docutils">
|
||||
<tr>
|
||||
<td>Original</td>
|
||||
<td>
|
||||
|
||||
```python
|
||||
evaluation = dict(interval=2000, metric='mIoU', pre_eval=True)
|
||||
```
|
||||
|
||||
</td>
|
||||
<tr>
|
||||
<td>New</td>
|
||||
<td>
|
||||
|
||||
```python
|
||||
val_evaluator = dict(type='IoUMetric', iou_metrics=['mIoU'])
|
||||
test_evaluator = val_evaluator
|
||||
```
|
||||
|
||||
</td>
|
||||
</tr>
|
||||
</table>
|
||||
|
||||
### Optimizer and Schedule settings
|
||||
|
||||
Changes in **`optimizer`** and **`optimizer_config`**:
|
||||
|
||||
- Now we use `optim_wrapper` field to specify all configuration about the optimization process. And the `optimizer` is a sub field of `optim_wrapper` now.
|
||||
- `paramwise_cfg` is also a sub field of `optim_wrapper`, instead of `optimizer`.
|
||||
- `optimizer_config` is removed now, and all configurations of it are moved to `optim_wrapper`.
|
||||
- `grad_clip` is renamed to `clip_grad`.
|
||||
|
||||
<table class="docutils">
|
||||
<tr>
|
||||
<td>Original</td>
|
||||
<td>
|
||||
|
||||
```python
|
||||
optimizer = dict(type='AdamW', lr=0.0001, weight_decay=0.0005)
|
||||
optimizer_config = dict(grad_clip=dict(max_norm=1, norm_type=2))
|
||||
```
|
||||
|
||||
</td>
|
||||
<tr>
|
||||
<td>New</td>
|
||||
<td>
|
||||
|
||||
```python
|
||||
optim_wrapper = dict(
|
||||
type='OptimWrapper',
|
||||
optimizer=dict(type='AdamW', lr=0.0001, weight_decay=0.0005),
|
||||
clip_grad=dict(max_norm=1, norm_type=2))
|
||||
```
|
||||
|
||||
</td>
|
||||
</tr>
|
||||
</table>
|
||||
|
||||
Changes in **`lr_config`**:
|
||||
|
||||
- The `lr_config` field is removed and we use new `param_scheduler` to replace it.
|
||||
- The `warmup` related arguments are removed, since we use schedulers combination to implement this functionality.
|
||||
|
||||
The new schedulers combination mechanism is very flexible, and you can use it to design many kinds of learning rate / momentum curves. See [the tutorial](TODO) for more details.
|
||||
|
||||
<table class="docutils">
|
||||
<tr>
|
||||
<td>Original</td>
|
||||
<td>
|
||||
|
||||
```python
|
||||
lr_config = dict(
|
||||
policy='poly',
|
||||
warmup='linear',
|
||||
warmup_iters=1500,
|
||||
warmup_ratio=1e-6,
|
||||
power=1.0,
|
||||
min_lr=0.0,
|
||||
by_epoch=False)
|
||||
```
|
||||
|
||||
</td>
|
||||
<tr>
|
||||
<td>New</td>
|
||||
<td>
|
||||
|
||||
```python
|
||||
param_scheduler = [
|
||||
dict(
|
||||
type='LinearLR', start_factor=1e-6, by_epoch=False, begin=0, end=1500),
|
||||
dict(
|
||||
type='PolyLR',
|
||||
power=1.0,
|
||||
begin=1500,
|
||||
end=160000,
|
||||
eta_min=0.0,
|
||||
by_epoch=False,
|
||||
)
|
||||
]
|
||||
```
|
||||
|
||||
</td>
|
||||
</tr>
|
||||
</table>
|
||||
|
||||
Changes in **`runner`**:
|
||||
|
||||
Most configuration in the original `runner` field is moved to `train_cfg`, `val_cfg` and `test_cfg`, which configure the loop in training, validation and test.
|
||||
|
||||
<table class="docutils">
|
||||
<tr>
|
||||
<td>Original</td>
|
||||
<td>
|
||||
|
||||
```python
|
||||
runner = dict(type='IterBasedRunner', max_iters=20000)
|
||||
```
|
||||
|
||||
</td>
|
||||
<tr>
|
||||
<td>New</td>
|
||||
<td>
|
||||
|
||||
```python
|
||||
# The `val_interval` is the original `evaluation.interval`.
|
||||
train_cfg = dict(type='IterBasedTrainLoop', max_iters=20000, val_interval=2000)
|
||||
val_cfg = dict(type='ValLoop') # Use the default validation loop.
|
||||
test_cfg = dict(type='TestLoop') # Use the default test loop.
|
||||
```
|
||||
|
||||
</td>
|
||||
</tr>
|
||||
</table>
|
||||
|
||||
In fact, in OpenMMLab 2.0, we introduced `Loop` to control the behaviors in training, validation and test. The functionalities of `Runner` are also changed. You can find more details of [runner tutorial](https://github.com/open-mmlab/mmengine/blob/main/docs/en/design/runner.md) in [MMEngine](https://github.com/open-mmlab/mmengine/).
|
||||
|
||||
### Runtime settings
|
||||
|
||||
Changes in **`checkpoint_config`** and **`log_config`**:
|
||||
|
||||
The `checkpoint_config` are moved to `default_hooks.checkpoint` and the `log_config` are moved to `default_hooks.logger`.
|
||||
And we move many hooks settings from the script code to the `default_hooks` field in the runtime configuration.
|
||||
|
||||
```python
|
||||
default_hooks = dict(
|
||||
# record the time of every iterations.
|
||||
timer=dict(type='IterTimerHook'),
|
||||
|
||||
# print log every 50 iterations.
|
||||
logger=dict(type='LoggerHook', interval=50, log_metric_by_epoch=False),
|
||||
|
||||
# enable the parameter scheduler.
|
||||
param_scheduler=dict(type='ParamSchedulerHook'),
|
||||
|
||||
# save checkpoint every 2000 iterations.
|
||||
checkpoint=dict(type='CheckpointHook', by_epoch=False, interval=2000),
|
||||
|
||||
# set sampler seed in distributed environment.
|
||||
sampler_seed=dict(type='DistSamplerSeedHook'),
|
||||
|
||||
# validation results visualization.
|
||||
visualization=dict(type='SegVisualizationHook'))
|
||||
```
|
||||
|
||||
In addition, we split the original logger to logger and visualizer. The logger is used to record information and the visualizer is used to show the logger in different backends, like terminal and TensorBoard.
|
||||
|
||||
<table class="docutils">
|
||||
<tr>
|
||||
<td>Original</td>
|
||||
<td>
|
||||
|
||||
```python
|
||||
log_config = dict(
|
||||
interval=100,
|
||||
hooks=[
|
||||
dict(type='TextLoggerHook'),
|
||||
dict(type='TensorboardLoggerHook'),
|
||||
])
|
||||
```
|
||||
|
||||
</td>
|
||||
<tr>
|
||||
<td>New</td>
|
||||
<td>
|
||||
|
||||
```python
|
||||
default_hooks = dict(
|
||||
...
|
||||
logger=dict(type='LoggerHook', interval=100),
|
||||
)
|
||||
vis_backends = [dict(type='LocalVisBackend'),
|
||||
dict(type='TensorboardVisBackend')]
|
||||
visualizer = dict(
|
||||
type='SegLocalVisualizer', vis_backends=vis_backends, name='visualizer')
|
||||
```
|
||||
|
||||
</td>
|
||||
</tr>
|
||||
</table>
|
||||
|
||||
Changes in **`load_from`** and **`resume_from`**:
|
||||
|
||||
- The `resume_from` is removed. And we use `resume` and `load_from` to replace it.
|
||||
- If `resume=True` and `load_from` is **not None**, resume training from the checkpoint in `load_from`.
|
||||
- If `resume=True` and `load_from` is **None**, try to resume from the latest checkpoint in the work directory.
|
||||
- If `resume=False` and `load_from` is **not None**, only load the checkpoint, not resume training.
|
||||
- If `resume=False` and `load_from` is **None**, do not load nor resume.
|
||||
|
||||
Changes in **`dist_params`**: The `dist_params` field is a sub field of `env_cfg` now. And there are some new configurations in the `env_cfg`.
|
||||
|
||||
```python
|
||||
env_cfg = dict(
|
||||
# whether to enable cudnn benchmark
|
||||
cudnn_benchmark=False,
|
||||
|
||||
# set multi process parameters
|
||||
mp_cfg=dict(mp_start_method='fork', opencv_num_threads=0),
|
||||
|
||||
# set distributed parameters
|
||||
dist_cfg=dict(backend='nccl'),
|
||||
)
|
||||
```
|
||||
|
||||
Changes in **`workflow`**: `workflow` related functionalities are removed.
|
||||
|
||||
New field **`visualizer`**: The visualizer is a new design in OpenMMLab 2.0 architecture. We use a visualizer instance in the runner to handle results & log visualization and save to different backends. See the [visualization tutorial](../user_guides/visualization.md) for more details.
|
||||
|
||||
New field **`default_scope`**: The start point to search module for all registries. The `default_scope` in MMSegmentation is `mmseg`. See [the registry tutorial](https://github.com/open-mmlab/mmengine/blob/main/docs/en/advanced_tutorials/registry.md) for more details.
|
||||
113
Seg_All_In_One_MMSeg/docs/en/migration/package.md
Normal file
113
Seg_All_In_One_MMSeg/docs/en/migration/package.md
Normal file
@@ -0,0 +1,113 @@
|
||||
# Package structures changes
|
||||
|
||||
This section is included if you are curious about what has changed between MMSeg 0.x and 1.x.
|
||||
|
||||
<table>
|
||||
<tr>
|
||||
<td>MMSegmentation 0.x</td>
|
||||
<td>MMSegmentation 1.x</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>mmseg.api</td>
|
||||
<td>mmseg.api</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td bgcolor=#fcf7f7>- mmseg.core</td>
|
||||
<td bgcolor=#ecf4eb>+ mmseg.engine</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>mmseg.datasets</td>
|
||||
<td>mmseg.datasets</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>mmseg.models</td>
|
||||
<td>mmseg.models</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td bgcolor=#fcf7f7>- mmseg.ops</td>
|
||||
<td bgcolor=#ecf4eb>+ mmseg.structure</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>mmseg.utils</td>
|
||||
<td>mmseg.utils</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td></td>
|
||||
<td bgcolor=#ecf4eb>+ mmseg.evaluation</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td></td>
|
||||
<td bgcolor=#ecf4eb>+ mmseg.registry</td>
|
||||
<tr>
|
||||
</table>
|
||||
|
||||
## Removed packages
|
||||
|
||||
### `mmseg.core`
|
||||
|
||||
In OpenMMLab 2.0, `core` package has been removed. `hooks` and `optimizers` of `core` are moved in `mmseg.engine`, and `evaluation` in `core` is mmseg.evaluation currently.
|
||||
|
||||
## `mmseg.ops`
|
||||
|
||||
`ops` package included `encoding` and `wrappers`, which are moved in `mmseg.models.utils`.
|
||||
|
||||
## Added packages
|
||||
|
||||
### `mmseg.engine`
|
||||
|
||||
OpenMMLab 2.0 adds a new foundational library for training deep learning, MMEngine. It servers as the training engine of all OpenMMLab codebases.
|
||||
`engine` package of mmseg is some customized modules for semantic segmentation task, like `SegVisualizationHook` which works for visualizing segmentation mask.
|
||||
|
||||
### `mmseg.structure`
|
||||
|
||||
In OpenMMLab 2.0, we designed data structure for computer vision task, and in mmseg, we implements `SegDataSample` in `structure` package.
|
||||
|
||||
### `mmseg.evaluation`
|
||||
|
||||
We move all evaluation metric in `mmseg.evaluation`.
|
||||
|
||||
### `mmseg.registry`
|
||||
|
||||
We moved registry implementations for all kinds of modules in MMSegmentation in `mmseg.registry`.
|
||||
|
||||
## Modified packages
|
||||
|
||||
### `mmseg.apis`
|
||||
|
||||
OpenMMLab 2.0 tries to support unified interface for multitasking of Computer Vision, and releases much stronger [`Runner`](https://github.com/open-mmlab/mmengine/blob/main/docs/en/design/runner.md), so MMSeg 1.x removed modules in `train.py` and `test.py` renamed `init_segmentor` to `init_model` and `inference_segmentor` to `inference_model`.
|
||||
|
||||
Here is the changes of `mmseg.apis`:
|
||||
|
||||
| Function | Changes |
|
||||
| :-------------------: | :---------------------------------------------- |
|
||||
| `init_segmentor` | Renamed to `init_model` |
|
||||
| `inference_segmentor` | Rename to `inference_model` |
|
||||
| `show_result_pyplot` | Implemented based on `SegLocalVisualizer` |
|
||||
| `train_model` | Removed, use `runner.train` to train. |
|
||||
| `multi_gpu_test` | Removed, use `runner.test` to test. |
|
||||
| `single_gpu_test` | Removed, use `runner.test` to test. |
|
||||
| `set_random_seed` | Removed, use `mmengine.runner.set_random_seed`. |
|
||||
| `init_random_seed` | Removed, use `mmengine.dist.sync_random_seed`. |
|
||||
|
||||
### `mmseg.datasets`
|
||||
|
||||
OpenMMLab 2.0 defines the `BaseDataset` to function and interface of dataset, and MMSegmentation 1.x also follow this protocol and defines the `BaseSegDataset` inherited from `BaseDataset`. MMCV 2.x collects general data transforms for multiple tasks e.g. classification, detection, segmentation, so MMSegmentation 1.x uses these data transforms and removes them from mmseg.datasets.
|
||||
|
||||
| Packages/Modules | Changes |
|
||||
| :-------------------: | :------------------------------------------------------------------------------------------ |
|
||||
| `mmseg.pipelines` | Moved in `mmcv.transforms` |
|
||||
| `mmseg.sampler` | Moved in `mmengine.dataset.sampler` |
|
||||
| `CustomDataset` | Renamed to `BaseSegDataset` and inherited from `BaseDataset` in MMEngine |
|
||||
| `DefaultFormatBundle` | Replaced with `PackSegInputs` |
|
||||
| `LoadImageFromFile` | Moved in `mmcv.transforms.LoadImageFromFile` |
|
||||
| `LoadAnnotations` | Moved in `mmcv.transforms.LoadAnnotations` |
|
||||
| `Resize` | Moved in `mmcv.transforms` and split into `Resize`, `RandomResize` and `RandomChoiceResize` |
|
||||
| `RandomFlip` | Moved in `mmcv.transforms.RandomFlip` |
|
||||
| `Pad` | Moved in `mmcv.transforms.Pad` |
|
||||
| `Normalize` | Moved in `mmcv.transforms.Normalize` |
|
||||
| `Compose` | Moved in `mmcv.transforms.Compose` |
|
||||
| `ImageToTensor` | Moved in `mmcv.transforms.ImageToTensor` |
|
||||
|
||||
### `mmseg.models`
|
||||
|
||||
`models` has not changed a lot, just added the `encoding` and `wrappers` from previous `mmseg.ops`
|
||||
186
Seg_All_In_One_MMSeg/docs/en/model_zoo.md
Normal file
186
Seg_All_In_One_MMSeg/docs/en/model_zoo.md
Normal file
@@ -0,0 +1,186 @@
|
||||
# Benchmark and Model Zoo
|
||||
|
||||
## Common settings
|
||||
|
||||
- We use distributed training with 4 GPUs by default.
|
||||
|
||||
- All pytorch-style pretrained backbones on ImageNet are train by ourselves, with the same procedure in the [paper](https://arxiv.org/pdf/1812.01187.pdf).
|
||||
Our ResNet style backbone are based on ResNetV1c variant, where the 7x7 conv in the input stem is replaced with three 3x3 convs.
|
||||
|
||||
- For the consistency across different hardwares, we report the GPU memory as the maximum value of `torch.cuda.max_memory_allocated()` for all 4 GPUs with `torch.backends.cudnn.benchmark=False`.
|
||||
Note that this value is usually less than what `nvidia-smi` shows.
|
||||
|
||||
- We report the inference time as the total time of network forwarding and post-processing, excluding the data loading time.
|
||||
Results are obtained with the script `tools/benchmark.py` which computes the average time on 200 images with `torch.backends.cudnn.benchmark=False`.
|
||||
|
||||
- There are two inference modes in this framework.
|
||||
|
||||
- `slide` mode: The `test_cfg` will be like `dict(mode='slide', crop_size=(769, 769), stride=(513, 513))`.
|
||||
|
||||
In this mode, multiple patches will be cropped from input image, passed into network individually.
|
||||
The crop size and stride between patches are specified by `crop_size` and `stride`.
|
||||
The overlapping area will be merged by average
|
||||
|
||||
- `whole` mode: The `test_cfg` will be like `dict(mode='whole')`.
|
||||
|
||||
In this mode, the whole imaged will be passed into network directly.
|
||||
|
||||
By default, we use `slide` inference for 769x769 trained model, `whole` inference for the rest.
|
||||
|
||||
- For input size of 8x+1 (e.g. 769), `align_corner=True` is adopted as a traditional practice.
|
||||
Otherwise, for input size of 8x (e.g. 512, 1024), `align_corner=False` is adopted.
|
||||
|
||||
## Baselines
|
||||
|
||||
### FCN
|
||||
|
||||
Please refer to [FCN](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/fcn) for details.
|
||||
|
||||
### PSPNet
|
||||
|
||||
Please refer to [PSPNet](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/pspnet) for details.
|
||||
|
||||
### DeepLabV3
|
||||
|
||||
Please refer to [DeepLabV3](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/deeplabv3) for details.
|
||||
|
||||
### PSANet
|
||||
|
||||
Please refer to [PSANet](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/psanet) for details.
|
||||
|
||||
### DeepLabV3+
|
||||
|
||||
Please refer to [DeepLabV3+](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/deeplabv3plus) for details.
|
||||
|
||||
### UPerNet
|
||||
|
||||
Please refer to [UPerNet](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/upernet) for details.
|
||||
|
||||
### NonLocal Net
|
||||
|
||||
Please refer to [NonLocal Net](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/nonlocal_net) for details.
|
||||
|
||||
### EncNet
|
||||
|
||||
Please refer to [EncNet](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/encnet) for details.
|
||||
|
||||
### CCNet
|
||||
|
||||
Please refer to [CCNet](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/ccnet) for details.
|
||||
|
||||
### DANet
|
||||
|
||||
Please refer to [DANet](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/danet) for details.
|
||||
|
||||
### APCNet
|
||||
|
||||
Please refer to [APCNet](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/apcnet) for details.
|
||||
|
||||
### HRNet
|
||||
|
||||
Please refer to [HRNet](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/hrnet) for details.
|
||||
|
||||
### GCNet
|
||||
|
||||
Please refer to [GCNet](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/gcnet) for details.
|
||||
|
||||
### DMNet
|
||||
|
||||
Please refer to [DMNet](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/dmnet) for details.
|
||||
|
||||
### ANN
|
||||
|
||||
Please refer to [ANN](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/ann) for details.
|
||||
|
||||
### OCRNet
|
||||
|
||||
Please refer to [OCRNet](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/ocrnet) for details.
|
||||
|
||||
### Fast-SCNN
|
||||
|
||||
Please refer to [Fast-SCNN](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/fastscnn) for details.
|
||||
|
||||
### ResNeSt
|
||||
|
||||
Please refer to [ResNeSt](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/resnest) for details.
|
||||
|
||||
### Semantic FPN
|
||||
|
||||
Please refer to [Semantic FPN](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/sem_fpn) for details.
|
||||
|
||||
### PointRend
|
||||
|
||||
Please refer to [PointRend](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/point_rend) for details.
|
||||
|
||||
### MobileNetV2
|
||||
|
||||
Please refer to [MobileNetV2](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/mobilenet_v2) for details.
|
||||
|
||||
### MobileNetV3
|
||||
|
||||
Please refer to [MobileNetV3](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/mobilenet_v3) for details.
|
||||
|
||||
### EMANet
|
||||
|
||||
Please refer to [EMANet](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/emanet) for details.
|
||||
|
||||
### DNLNet
|
||||
|
||||
Please refer to [DNLNet](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/dnlnet) for details.
|
||||
|
||||
### CGNet
|
||||
|
||||
Please refer to [CGNet](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/cgnet) for details.
|
||||
|
||||
### Mixed Precision (FP16) Training
|
||||
|
||||
Please refer [Mixed Precision (FP16) Training on BiSeNetV2](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/bisenetv2/bisenetv2_fcn_4xb4-160k_cityscapes-1024x1024.py) for details.
|
||||
|
||||
### U-Net
|
||||
|
||||
Please refer to [U-Net](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/unet/README.md) for details.
|
||||
|
||||
### ViT
|
||||
|
||||
Please refer to [ViT](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/vit/README.md) for details.
|
||||
|
||||
### Swin
|
||||
|
||||
Please refer to [Swin](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/swin/README.md) for details.
|
||||
|
||||
### SETR
|
||||
|
||||
Please refer to [SETR](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/setr/README.md) for details.
|
||||
|
||||
## Speed benchmark
|
||||
|
||||
### Hardware
|
||||
|
||||
- 8 NVIDIA Tesla V100 (32G) GPUs
|
||||
- Intel(R) Xeon(R) Gold 6148 CPU @ 2.40GHz
|
||||
|
||||
### Software environment
|
||||
|
||||
- Python 3.7
|
||||
- PyTorch 1.5
|
||||
- CUDA 10.1
|
||||
- CUDNN 7.6.03
|
||||
- NCCL 2.4.08
|
||||
|
||||
### Training speed
|
||||
|
||||
For fair comparison, we benchmark all implementations with ResNet-101V1c.
|
||||
The input size is fixed to 1024x512 with batch size 2.
|
||||
|
||||
The training speed is reported as followed, in terms of second per iter (s/iter). The lower, the better.
|
||||
|
||||
| Implementation | PSPNet (s/iter) | DeepLabV3+ (s/iter) |
|
||||
| --------------------------------------------------------------------------- | --------------- | ------------------- |
|
||||
| [MMSegmentation](https://github.com/open-mmlab/mmsegmentation) | **0.83** | **0.85** |
|
||||
| [SegmenTron](https://github.com/LikeLy-Journey/SegmenTron) | 0.84 | 0.85 |
|
||||
| [CASILVision](https://github.com/CSAILVision/semantic-segmentation-pytorch) | 1.15 | N/A |
|
||||
| [vedaseg](https://github.com/Media-Smart/vedaseg) | 0.95 | 1.25 |
|
||||
|
||||
:::{note}
|
||||
The output stride of DeepLabV3+ is 8.
|
||||
:::
|
||||
102
Seg_All_In_One_MMSeg/docs/en/modelzoo_statistics.md
Normal file
102
Seg_All_In_One_MMSeg/docs/en/modelzoo_statistics.md
Normal file
@@ -0,0 +1,102 @@
|
||||
# Model Zoo Statistics
|
||||
|
||||
- Number of papers: 47
|
||||
|
||||
- ALGORITHM: 36
|
||||
- BACKBONE: 11
|
||||
|
||||
- Number of checkpoints: 612
|
||||
|
||||
- \[ALGORITHM\] [ANN](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/ann) (16 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [APCNet](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/apcnet) (12 ckpts)
|
||||
|
||||
- \[BACKBONE\] [BEiT](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/beit) (2 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [BiSeNetV1](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/bisenetv1) (11 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [BiSeNetV2](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/bisenetv2) (4 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [CCNet](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/ccnet) (16 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [CGNet](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/cgnet) (2 ckpts)
|
||||
|
||||
- \[BACKBONE\] [ConvNeXt](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/convnext) (6 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [DANet](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/danet) (16 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [DeepLabV3](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/deeplabv3) (41 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [DeepLabV3+](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/deeplabv3plus) (42 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [DMNet](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/dmnet) (12 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [DNLNet](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/dnlnet) (12 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [DPT](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/dpt) (1 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [EMANet](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/emanet) (4 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [EncNet](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/encnet) (12 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [ERFNet](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/erfnet) (1 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [FastFCN](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/fastfcn) (12 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [Fast-SCNN](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/fastscnn) (1 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [FCN](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/fcn) (41 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [GCNet](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/gcnet) (16 ckpts)
|
||||
|
||||
- \[BACKBONE\] [HRNet](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/hrnet) (37 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [ICNet](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/icnet) (12 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [ISANet](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/isanet) (16 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [K-Net](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/knet) (7 ckpts)
|
||||
|
||||
- \[BACKBONE\] [MAE](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/mae) (1 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [Mask2Former](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/mask2former) (13 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [MaskFormer](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/maskformer) (4 ckpts)
|
||||
|
||||
- \[BACKBONE\] [MobileNetV2](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/mobilenet_v2) (8 ckpts)
|
||||
|
||||
- \[BACKBONE\] [MobileNetV3](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/mobilenet_v3) (4 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [NonLocal Net](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/nonlocal_net) (16 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [OCRNet](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/ocrnet) (24 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [PointRend](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/point_rend) (4 ckpts)
|
||||
|
||||
- \[BACKBONE\] [PoolFormer](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/poolformer) (5 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [PSANet](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/psanet) (16 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [PSPNet](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/pspnet) (54 ckpts)
|
||||
|
||||
- \[BACKBONE\] [ResNeSt](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/resnest) (8 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [SegFormer](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/segformer) (13 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [Segmenter](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/segmenter) (5 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [Semantic FPN](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/sem_fpn) (4 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [SETR](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/setr) (7 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [STDC](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/stdc) (4 ckpts)
|
||||
|
||||
- \[BACKBONE\] [Swin Transformer](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/swin) (6 ckpts)
|
||||
|
||||
- \[BACKBONE\] [Twins](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/twins) (12 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [UNet](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/unet) (25 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [UPerNet](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/upernet) (16 ckpts)
|
||||
|
||||
- \[BACKBONE\] [Vision Transformer](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/vit) (11 ckpts)
|
||||
506
Seg_All_In_One_MMSeg/docs/en/notes/changelog.md
Normal file
506
Seg_All_In_One_MMSeg/docs/en/notes/changelog.md
Normal file
@@ -0,0 +1,506 @@
|
||||
# Changelog of v1.x
|
||||
|
||||
## v1.2.2 (12/14/2023)
|
||||
|
||||
### Bug Fixes
|
||||
|
||||
- Fix bug in cross entropy loss ([#3457](https://github.com/open-mmlab/mmsegmentation/pull/3457))
|
||||
- Allow custom visualizer ([#3455](https://github.com/open-mmlab/mmsegmentation/pull/3455))
|
||||
- test resize with pad_shape ([#3421](https://github.com/open-mmlab/mmsegmentation/pull/3421))
|
||||
- add with-labels args to inferencer for visualization without labels ([#3466](https://github.com/open-mmlab/mmsegmentation/pull/3466))
|
||||
|
||||
### New Contributors
|
||||
|
||||
- @okotaku made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/3421
|
||||
|
||||
## v1.2.1 (10/17/2023)
|
||||
|
||||
### Bug Fixes
|
||||
|
||||
- Add bpe_simple_vocab_16e6.txt.gz to release ([#3386](https://github.com/open-mmlab/mmsegmentation/pull/3386))
|
||||
- Fix init api ([#3388](https://github.com/open-mmlab/mmsegmentation/pull/3388))
|
||||
|
||||
## v1.2.0 (10/12/2023)
|
||||
|
||||
### Features
|
||||
|
||||
- Support Side Adapter Network ([#3232](https://github.com/open-mmlab/mmsegmentation/pull/3232))
|
||||
|
||||
### Bug Fixes
|
||||
|
||||
- fix wrong variables passing for `set_dataset_meta` ([#3348](https://github.com/open-mmlab/mmsegmentation/pull/3348))
|
||||
|
||||
### Documentation
|
||||
|
||||
- add documentation of Finetune ONNX Models (MMSegemetation) Inference for NVIDIA Jetson ([#3372](https://github.com/open-mmlab/mmsegmentation/pull/3372))
|
||||
|
||||
## v1.1.2(09/20/2023)
|
||||
|
||||
### Features
|
||||
|
||||
- Add semantic label to the segmentation visualization results ([#3229](https://github.com/open-mmlab/mmsegmentation/pull/3229))
|
||||
- Support NYU depth estimation dataset ([#3269](https://github.com/open-mmlab/mmsegmentation/pull/3269))
|
||||
- Support Kullback-Leibler divergence Loss ([#3242](https://github.com/open-mmlab/mmsegmentation/pull/3242))
|
||||
- Support depth metrics ([#3297](https://github.com/open-mmlab/mmsegmentation/pull/3297))
|
||||
- Support Remote sensing inferencer ([#3131](https://github.com/open-mmlab/mmsegmentation/pull/3131))
|
||||
- Support VPD Depth Estimator ((#3321)(https://github.com/open-mmlab/mmsegmentation/pull/3321))
|
||||
- Support inference and visualization of VPD ([#3331](https://github.com/open-mmlab/mmsegmentation/pull/3331))
|
||||
- Support using the pytorch-grad-cam tool to visualize Class Activation Maps (CAM) ([#3324](https://github.com/open-mmlab/mmsegmentation/pull/3324))
|
||||
|
||||
### New projects
|
||||
|
||||
- Support PP-Mobileseg ([#3239](https://github.com/open-mmlab/mmsegmentation/pull/3239))
|
||||
- Support CAT-Seg (CVPR'2023) ([#3098](https://github.com/open-mmlab/mmsegmentation/pull/3098))
|
||||
- Support Adabins ([#3257](https://github.com/open-mmlab/mmsegmentation/pull/3257))
|
||||
- Add pp_mobileseg onnx inference script ([#3268](https://github.com/open-mmlab/mmsegmentation/pull/3268))
|
||||
|
||||
### Bug Fixes
|
||||
|
||||
- Fix module PascalContextDataset ([#3235](https://github.com/open-mmlab/mmsegmentation/pull/3235))
|
||||
- Fix one hot encoding for dice loss ([#3237](https://github.com/open-mmlab/mmsegmentation/pull/3237))
|
||||
- Fix confusion_matrix.py ([#3291](https://github.com/open-mmlab/mmsegmentation/pull/3291))
|
||||
- Fix inferencer visualization ([#3333](https://github.com/open-mmlab/mmsegmentation/pull/3333))
|
||||
|
||||
### Documentation
|
||||
|
||||
- Translate doc for docs/zh_cn/user_guides/5_deployment.md ([#3281](https://github.com/open-mmlab/mmsegmentation/pull/3281))
|
||||
|
||||
### New Contributors
|
||||
|
||||
- @angiecao made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/3235
|
||||
- @yeedrag made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/3237
|
||||
- @Yang-Changhui made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/3239
|
||||
- @ooooo-create made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/3261
|
||||
- @Ben-Louis made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/3269
|
||||
- @crazysteeaam made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/3284
|
||||
- @zen0no made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/3242
|
||||
- @XiandongWang made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/3291
|
||||
- @ZhaoQiiii made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/3332
|
||||
- @zhen6618 made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/3324
|
||||
|
||||
## v1.1.1(07/24/2023)
|
||||
|
||||
### Features
|
||||
|
||||
- Add bdd100K datasets ([#3158](https://github.com/open-mmlab/mmsegmentation/pull/3158))
|
||||
- Remove batch inference assertion ([#3210](https://github.com/open-mmlab/mmsegmentation/pull/3210))
|
||||
|
||||
### Bug Fixes
|
||||
|
||||
- Fix train map path for coco-stuff164k.py ([#3187](https://github.com/open-mmlab/mmsegmentation/pull/3187))
|
||||
- Fix mim search error ([#3194](https://github.com/open-mmlab/mmsegmentation/pull/3194))
|
||||
- Fix SegTTAModel with no attribute '\_gt_sem_seg' error ([#3152](https://github.com/open-mmlab/mmsegmentation/pull/3152))
|
||||
- Fix Albumentations default key mapping mismatch ([#3195](https://github.com/open-mmlab/mmsegmentation/pull/3195))
|
||||
|
||||
### New Contributors
|
||||
|
||||
- @OliverGrace made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/3187
|
||||
- @ZiAn-Su made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/3152
|
||||
- @CastleDream made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/3158
|
||||
- @coding-famer made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/3174
|
||||
- @Alias-z made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/3195
|
||||
|
||||
## v1.1.0(06/28/2023)
|
||||
|
||||
## What's Changed
|
||||
|
||||
### Features
|
||||
|
||||
- Support albu transform ([#2943](https://github.com/open-mmlab/mmsegmentation/pull/2943))
|
||||
- Support DDRNet ([#2855](https://github.com/open-mmlab/mmsegmentation/pull/2855))
|
||||
- Add GDAL backend and Support LEVIR-CD Dataset ([#2903](https://github.com/open-mmlab/mmsegmentation/pull/2903))
|
||||
- Support DSDL Dataset ([#2925](https://github.com/open-mmlab/mmsegmentation/pull/2925))
|
||||
- huasdorff distance loss ([#2820](https://github.com/open-mmlab/mmsegmentation/pull/2820))
|
||||
|
||||
### New Projects
|
||||
|
||||
- Support SAM inferencer ([#2897](https://github.com/open-mmlab/mmsegmentation/pull/2897))
|
||||
- Added a supported for Visual Attention Network (VAN) ([#2987](https://github.com/open-mmlab/mmsegmentation/pull/2987))
|
||||
- add GID dataset ([#3038](https://github.com/open-mmlab/mmsegmentation/pull/3038))
|
||||
- add Medical semantic seg dataset: Bactteria ([#2568](https://github.com/open-mmlab/mmsegmentation/pull/2568))
|
||||
- add Medical semantic seg dataset: Vampire ([#2633](https://github.com/open-mmlab/mmsegmentation/pull/2633))
|
||||
- add Medical semantic seg dataset: Ravir ([#2635](https://github.com/open-mmlab/mmsegmentation/pull/2635))
|
||||
- add Medical semantic seg dataset: Cranium ([#2675](https://github.com/open-mmlab/mmsegmentation/pull/2675))
|
||||
- add Medical semantic seg dataset: bccs ([#2861](https://github.com/open-mmlab/mmsegmentation/pull/2861))
|
||||
- add Medical semantic seg dataset: Gamma Task3 dataset ([#2695](https://github.com/open-mmlab/mmsegmentation/pull/2695))
|
||||
- add Medical semantic seg dataset: consep ([#2724](https://github.com/open-mmlab/mmsegmentation/pull/2724))
|
||||
- add Medical semantic seg dataset: breast_cancer_cell_seg dataset ([#2726](https://github.com/open-mmlab/mmsegmentation/pull/2726))
|
||||
- add Medical semantic seg dataset: chest_image_pneum dataset ([#2727](https://github.com/open-mmlab/mmsegmentation/pull/2727))
|
||||
- add Medical semantic seg dataset: conic2022 ([#2725](https://github.com/open-mmlab/mmsegmentation/pull/2725))
|
||||
- add Medical semantic seg dataset: dr_hagis ([#2729](https://github.com/open-mmlab/mmsegmentation/pull/2729))
|
||||
- add Medical semantic seg dataset: orvs ([#2728](https://github.com/open-mmlab/mmsegmentation/pull/2728))
|
||||
- add Medical semantic seg dataset: ISIC-2016 Task1 ([#2708](https://github.com/open-mmlab/mmsegmentation/pull/2708))
|
||||
- add Medical semantic seg dataset: ISIC-2017 Task1 ([#2709](https://github.com/open-mmlab/mmsegmentation/pull/2709))
|
||||
- add Medical semantic seg dataset: Kvasir seg ([#2677](https://github.com/open-mmlab/mmsegmentation/pull/2677))
|
||||
- add Medical semantic seg dataset: Kvasir seg aliyun ([#2678](https://github.com/open-mmlab/mmsegmentation/pull/2678))
|
||||
- add Medical semantic seg dataset: Rite ([#2680](https://github.com/open-mmlab/mmsegmentation/pull/2680))
|
||||
- add Medical semantic seg dataset: Fusc2021 ([#2682](https://github.com/open-mmlab/mmsegmentation/pull/2682))
|
||||
- add Medical semantic seg dataset: 2pm vessel ([#2685](https://github.com/open-mmlab/mmsegmentation/pull/2685))
|
||||
- add Medical semantic seg dataset: Pcam ([#2684](https://github.com/open-mmlab/mmsegmentation/pull/2684))
|
||||
- add Medical semantic seg dataset: Pannuke ([#2683](https://github.com/open-mmlab/mmsegmentation/pull/2683))
|
||||
- add Medical semantic seg dataset: Covid 19 ct cxr ([#2688](https://github.com/open-mmlab/mmsegmentation/pull/2688))
|
||||
- add Medical semantic seg dataset: Crass ([#2690](https://github.com/open-mmlab/mmsegmentation/pull/2690))
|
||||
- add Medical semantic seg dataset: Chest x ray images with pneumothorax masks ([#2687](https://github.com/open-mmlab/mmsegmentation/pull/2687))
|
||||
|
||||
### Enhancement
|
||||
|
||||
- Robust mapping from image path to seg map path ([#3091](https://github.com/open-mmlab/mmsegmentation/pull/3091))
|
||||
- Change assertion logic inference cfg.model.test_cfg ([#3012](https://github.com/open-mmlab/mmsegmentation/pull/3012))
|
||||
- Refactor dice loss ([#3002](https://github.com/open-mmlab/mmsegmentation/pull/3002))
|
||||
- Update Dockerfile libgl1-mesa-dev ([#3095](https://github.com/open-mmlab/mmsegmentation/pull/3095))
|
||||
- Prevent passed `ann_file` from silently failing to load ([#2966](https://github.com/open-mmlab/mmsegmentation/pull/2966))
|
||||
- Update the translation of models documentation ([#2833](https://github.com/open-mmlab/mmsegmentation/pull/2833))
|
||||
- Add docs contents at README.md ([#3083](https://github.com/open-mmlab/mmsegmentation/pull/3083))
|
||||
- Enhance swin pretrained model loading ([#3097](https://github.com/open-mmlab/mmsegmentation/pull/3097))
|
||||
|
||||
### Bug Fixes
|
||||
|
||||
- Handle case where device is neither CPU nor CUDA in HamHead ([#2868](https://github.com/open-mmlab/mmsegmentation/pull/2868))
|
||||
- Fix bugs when out_channels==1 ([#2911](https://github.com/open-mmlab/mmsegmentation/pull/2911))
|
||||
- Fix binary C=1 focal loss & dataset fileio ([#2935](https://github.com/open-mmlab/mmsegmentation/pull/2935))
|
||||
- Fix isaid dataset pre-processing tool ([#3010](https://github.com/open-mmlab/mmsegmentation/pull/3010))
|
||||
- Fix bug cannot use both '--tta' and '--out' while testing ([#3067](https://github.com/open-mmlab/mmsegmentation/pull/3067))
|
||||
- Fix inferencer ut ([#3117](https://github.com/open-mmlab/mmsegmentation/pull/3117))
|
||||
- Fix document ([#2863](https://github.com/open-mmlab/mmsegmentation/pull/2863), [#2896](https://github.com/open-mmlab/mmsegmentation/pull/2896), [#2919](https://github.com/open-mmlab/mmsegmentation/pull/2919), [#2951](https://github.com/open-mmlab/mmsegmentation/pull/2951), [#2970](https://github.com/open-mmlab/mmsegmentation/pull/2970), [#2961](https://github.com/open-mmlab/mmsegmentation/pull/2961), [#3042](https://github.com/open-mmlab/mmsegmentation/pull/3042), )
|
||||
- Fix squeeze error when N=1 and C=1 ([#2933](https://github.com/open-mmlab/mmsegmentation/pull/2933))
|
||||
|
||||
### New Contributors
|
||||
|
||||
- @liu-mengyang made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/2896
|
||||
- @likyoo made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/2911
|
||||
- @1qh made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/2902
|
||||
- @JoshuaChou2018 made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/2951
|
||||
- @jts250 made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/2833
|
||||
- @MGAMZ made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/2970
|
||||
- @tianbinli made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/2568
|
||||
- @Provable0816 made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/2633
|
||||
- @Zoulinx made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/2903
|
||||
- @wufan-tb made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/2925
|
||||
- @haruishi43 made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/2966
|
||||
- @Masaaki-75 made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/2675
|
||||
- @tang576225574 made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/2987
|
||||
- @Kedreamix made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/3010
|
||||
- @nightrain01 made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/3067
|
||||
- @shigengtian made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/3095
|
||||
- @SheffieldCao made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/3097
|
||||
- @wangruohui made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/3091
|
||||
- @LHamnett made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/3012
|
||||
|
||||
## v1.0.0(04/06/2023)
|
||||
|
||||
### Highlights
|
||||
|
||||
- Add Mapillary Vistas Datasets support to MMSegmentation Core Package ([#2576](https://github.com/open-mmlab/mmsegmentation/pull/2576))
|
||||
- Support PIDNet ([#2609](https://github.com/open-mmlab/mmsegmentation/pull/2609))
|
||||
- Support SegNeXt ([#2654](https://github.com/open-mmlab/mmsegmentation/pull/2654))
|
||||
|
||||
### Features
|
||||
|
||||
- Support calculating FLOPs of segmentors ([#2706](https://github.com/open-mmlab/mmsegmentation/pull/2706))
|
||||
- Support multi-band image for Mosaic ([#2748](https://github.com/open-mmlab/mmsegmentation/pull/2748))
|
||||
- Support dump segment prediction ([#2712](https://github.com/open-mmlab/mmsegmentation/pull/2712))
|
||||
|
||||
### Bug fix
|
||||
|
||||
- Fix format_result and fix prefix param in cityscape metric, and rename CitysMetric to CityscapesMetric ([#2660](https://github.com/open-mmlab/mmsegmentation/pull/2660))
|
||||
- Support input gt seg map is not 2D ([#2739](https://github.com/open-mmlab/mmsegmentation/pull/2739))
|
||||
- Fix accepting an unexpected argument `local-rank` in PyTorch 2.0 ([#2812](https://github.com/open-mmlab/mmsegmentation/pull/2812))
|
||||
|
||||
### Documentation
|
||||
|
||||
- Add Chinese version of various documentation ([#2673](https://github.com/open-mmlab/mmsegmentation/pull/2673), [#2702](https://github.com/open-mmlab/mmsegmentation/pull/2702), [#2703](https://github.com/open-mmlab/mmsegmentation/pull/2703), [#2701](https://github.com/open-mmlab/mmsegmentation/pull/2701), [#2722](https://github.com/open-mmlab/mmsegmentation/pull/2722), [#2733](https://github.com/open-mmlab/mmsegmentation/pull/2733), [#2769](https://github.com/open-mmlab/mmsegmentation/pull/2769), [#2790](https://github.com/open-mmlab/mmsegmentation/pull/2790), [#2798](https://github.com/open-mmlab/mmsegmentation/pull/2798))
|
||||
- Update and refine various English documentation ([#2715](https://github.com/open-mmlab/mmsegmentation/pull/2715), [#2755](https://github.com/open-mmlab/mmsegmentation/pull/2755), [#2745](https://github.com/open-mmlab/mmsegmentation/pull/2745), [#2797](https://github.com/open-mmlab/mmsegmentation/pull/2797), [#2799](https://github.com/open-mmlab/mmsegmentation/pull/2799), [#2821](https://github.com/open-mmlab/mmsegmentation/pull/2821), [#2827](https://github.com/open-mmlab/mmsegmentation/pull/2827), [#2831](https://github.com/open-mmlab/mmsegmentation/pull/2831))
|
||||
- Add deeplabv3 model structure documentation ([#2426](https://github.com/open-mmlab/mmsegmentation/pull/2426))
|
||||
- Add custom metrics documentation ([#2799](https://github.com/open-mmlab/mmsegmentation/pull/2799))
|
||||
- Add faq in dev-1.x branch ([#2765](https://github.com/open-mmlab/mmsegmentation/pull/2765))
|
||||
|
||||
### New Contributors
|
||||
|
||||
- @liuruiqiang made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/2554
|
||||
- @wangjiangben-hw made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/2569
|
||||
- @jinxianwei made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/2557
|
||||
- @KKIEEK made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/2747
|
||||
- @Renzhihan made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/2765
|
||||
|
||||
## v1.0.0rc6(03/03/2023)
|
||||
|
||||
### Highlights
|
||||
|
||||
- Support MMSegInferencer ([#2413](https://github.com/open-mmlab/mmsegmentation/pull/2413), [#2658](https://github.com/open-mmlab/mmsegmentation/pull/2658))
|
||||
- Support REFUGE dataset ([#2554](https://github.com/open-mmlab/mmsegmentation/pull/2554))
|
||||
|
||||
### Features
|
||||
|
||||
- Support auto import modules from registry ([#2481](https://github.com/open-mmlab/mmsegmentation/pull/2481))
|
||||
- Replace numpy ascontiguousarray with torch contiguous to speed-up ([#2604](https://github.com/open-mmlab/mmsegmentation/pull/2604))
|
||||
- Add browse_dataset.py tool ([#2649](https://github.com/open-mmlab/mmsegmentation/pull/2649))
|
||||
|
||||
### Bug fix
|
||||
|
||||
- Rename and Fix bug of projects HieraSeg ([#2565](https://github.com/open-mmlab/mmsegmentation/pull/2565))
|
||||
- Add out_channels in `CascadeEncoderDecoder` and update OCRNet and MobileNet v2 results ([#2656](https://github.com/open-mmlab/mmsegmentation/pull/2656))
|
||||
|
||||
### Documentation
|
||||
|
||||
- Add dataflow documentation of Chinese version ([#2652](https://github.com/open-mmlab/mmsegmentation/pull/2652))
|
||||
- Add custmized runtime documentation of English version ([#2533](https://github.com/open-mmlab/mmsegmentation/pull/2533))
|
||||
- Add documentation for visualizing feature map using wandb backend ([#2557](https://github.com/open-mmlab/mmsegmentation/pull/2557))
|
||||
- Add documentation for benchmark results on NPU (HUAWEI Ascend) ([#2569](https://github.com/open-mmlab/mmsegmentation/pull/2569), [#2596](https://github.com/open-mmlab/mmsegmentation/pull/2596), [#2610](https://github.com/open-mmlab/mmsegmentation/pull/2610))
|
||||
- Fix api name error in the migration doc ([#2601](https://github.com/open-mmlab/mmsegmentation/pull/2601))
|
||||
- Refine projects documentation ([#2586](https://github.com/open-mmlab/mmsegmentation/pull/2586))
|
||||
- Refine MMSegmentation documentation ([#2668](https://github.com/open-mmlab/mmsegmentation/pull/2668), [#2659](https://github.com/open-mmlab/mmsegmentation/pull/2659))
|
||||
|
||||
### New Contributors
|
||||
|
||||
- @zccjjj made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/2548
|
||||
- @liuruiqiang made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/2554
|
||||
- @wangjiangben-hw made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/2569
|
||||
- @jinxianwei made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/2557
|
||||
|
||||
## v1.0.0rc5(02/01/2023)
|
||||
|
||||
### Bug fix
|
||||
|
||||
- Fix MaskFormer and Mask2Former when install mmdet from source ([#2532](https://github.com/open-mmlab/mmsegmentation/pull/2532))
|
||||
- Support new fileio interface in `MMCV>=2.0.0rc4` ([#2543](https://github.com/open-mmlab/mmsegmentation/pull/2543))
|
||||
- Fix ERFNet URL in dev-1.x branch ([#2537](https://github.com/open-mmlab/mmsegmentation/pull/2537))
|
||||
- Fix misleading `List[Tensor]` types ([#2546](https://github.com/open-mmlab/mmsegmentation/pull/2546))
|
||||
- Rename typing.py to typing_utils.py ([#2548](https://github.com/open-mmlab/mmsegmentation/pull/2548))
|
||||
|
||||
## v1.0.0rc4(01/30/2023)
|
||||
|
||||
### Highlights
|
||||
|
||||
- Support ISNet (ICCV'2021) in projects ([#2400](https://github.com/open-mmlab/mmsegmentation/pull/2400))
|
||||
- Support HSSN (CVPR'2022) in projects ([#2444](https://github.com/open-mmlab/mmsegmentation/pull/2444))
|
||||
|
||||
### Features
|
||||
|
||||
- Add Gaussian Noise and Blur for biomedical data ([#2373](https://github.com/open-mmlab/mmsegmentation/pull/2373))
|
||||
- Add BioMedicalRandomGamma ([#2406](https://github.com/open-mmlab/mmsegmentation/pull/2406))
|
||||
- Add BioMedical3DPad ([#2383](https://github.com/open-mmlab/mmsegmentation/pull/2383))
|
||||
- Add BioMedical3DRandomFlip ([#2404](https://github.com/open-mmlab/mmsegmentation/pull/2404))
|
||||
- Add `gt_edge_map` field to SegDataSample ([#2466](https://github.com/open-mmlab/mmsegmentation/pull/2466))
|
||||
- Support synapse dataset ([#2432](https://github.com/open-mmlab/mmsegmentation/pull/2432), [#2465](https://github.com/open-mmlab/mmsegmentation/pull/2465))
|
||||
- Support Mapillary Vistas Dataset in projects ([#2484](https://github.com/open-mmlab/mmsegmentation/pull/2484))
|
||||
- Switch order of `reduce_zero_label` and applying `label_map` ([#2517](https://github.com/open-mmlab/mmsegmentation/pull/2517))
|
||||
|
||||
### Documentation
|
||||
|
||||
- Add ZN Customized_runtime Doc ([#2502](https://github.com/open-mmlab/mmsegmentation/pull/2502))
|
||||
- Add EN datasets.md ([#2464](https://github.com/open-mmlab/mmsegmentation/pull/2464))
|
||||
- Fix minor typo in migration `package.md` ([#2518](https://github.com/open-mmlab/mmsegmentation/pull/2518))
|
||||
|
||||
### Bug fix
|
||||
|
||||
- Fix incorrect `img_shape` value assignment in RandomCrop ([#2469](https://github.com/open-mmlab/mmsegmentation/pull/2469))
|
||||
- Fix inference api and support setting palette to SegLocalVisualizer ([#2475](https://github.com/open-mmlab/mmsegmentation/pull/2475))
|
||||
- Unfinished label conversion from `-1` to `255` ([#2516](https://github.com/open-mmlab/mmsegmentation/pull/2516))
|
||||
|
||||
### New Contributors
|
||||
|
||||
- @blueyo0 made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/2373
|
||||
- @Fivethousand5k made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/2406
|
||||
- @suyanzhou626 made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/2383
|
||||
- @unrealMJ made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/2400
|
||||
- @Dominic23331 made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/2432
|
||||
- @AI-Tianlong made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/2444
|
||||
- @morkovka1337 made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/2492
|
||||
- @Leeinsn made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/2404
|
||||
- @siddancha made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/2516
|
||||
|
||||
## v1.0.0rc3(31/12/2022)
|
||||
|
||||
### Highlights
|
||||
|
||||
- Support test time augmentation ([#2184](https://github.com/open-mmlab/mmsegmentation/pull/2184))
|
||||
- Add 'Projects/' folder and the first example project ([#2412](https://github.com/open-mmlab/mmsegmentation/pull/2412))
|
||||
|
||||
### Features
|
||||
|
||||
- Add Biomedical 3D array random crop transform ([#2378](https://github.com/open-mmlab/mmsegmentation/pull/2378))
|
||||
|
||||
### Documentation
|
||||
|
||||
- Add Chinese version of config tutorial ([#2371](https://github.com/open-mmlab/mmsegmentation/pull/2371))
|
||||
- Add Chinese version of train & test tutorial ([#2355](https://github.com/open-mmlab/mmsegmentation/pull/2355))
|
||||
- Add Chinese version of overview ([(#2397)](https://github.com/open-mmlab/mmsegmentation/pull/2397)))
|
||||
- Add Chinese version of get_started ([#2417](https://github.com/open-mmlab/mmsegmentation/pull/2417))
|
||||
- Add datasets in Chinese ([#2387](https://github.com/open-mmlab/mmsegmentation/pull/2387))
|
||||
- Add dataflow document ([#2403](https://github.com/open-mmlab/mmsegmentation/pull/2403))
|
||||
- Add pspnet model structure graph ([#2437](https://github.com/open-mmlab/mmsegmentation/pull/2437))
|
||||
- Update some content of engine Chinese documentation ([#2341](https://github.com/open-mmlab/mmsegmentation/pull/2341))
|
||||
- Update TTA to migration documentation ([#2335](https://github.com/open-mmlab/mmsegmentation/pull/2335))
|
||||
|
||||
### Bug fix
|
||||
|
||||
- Remove dependency mmdet when do not use MaskFormerHead and MMDET_Mask2FormerHead ([#2448](https://github.com/open-mmlab/mmsegmentation/pull/2448))
|
||||
|
||||
### Enhancement
|
||||
|
||||
- Add torch1.13 checking in CI ([#2402](https://github.com/open-mmlab/mmsegmentation/pull/2402))
|
||||
- Fix pytorch version for merge stage test ([#2449](https://github.com/open-mmlab/mmsegmentation/pull/2449))
|
||||
|
||||
## v1.0.0rc2(6/12/2022)
|
||||
|
||||
### Highlights
|
||||
|
||||
- Support MaskFormer ([#2215](https://github.com/open-mmlab/mmsegmentation/pull/2215))
|
||||
- Support Mask2Former ([#2255](https://github.com/open-mmlab/mmsegmentation/pull/2255))
|
||||
|
||||
### Features
|
||||
|
||||
- Add ResizeShortestEdge transform ([#2339](https://github.com/open-mmlab/mmsegmentation/pull/2339))
|
||||
- Support padding in data pre-processor for model testing([#2290](https://github.com/open-mmlab/mmsegmentation/pull/2290))
|
||||
- Fix the problem of post-processing not removing padding ([#2367](https://github.com/open-mmlab/mmsegmentation/pull/2367))
|
||||
|
||||
### Bug fix
|
||||
|
||||
- Fix links in README ([#2024](https://github.com/open-mmlab/mmsegmentation/pull/2024))
|
||||
- Fix swin load state_dict ([#2304](https://github.com/open-mmlab/mmsegmentation/pull/2304))
|
||||
- Fix typo of BaseSegDataset docstring ([#2322](https://github.com/open-mmlab/mmsegmentation/pull/2322))
|
||||
- Fix the bug in the visualization step ([#2326](https://github.com/open-mmlab/mmsegmentation/pull/2326))
|
||||
- Fix ignore class id from -1 to 255 in BaseSegDataset ([#2332](https://github.com/open-mmlab/mmsegmentation/pull/2332))
|
||||
- Fix KNet IterativeDecodeHead bug ([#2334](https://github.com/open-mmlab/mmsegmentation/pull/2334))
|
||||
- Add input argument for datasets ([#2379](https://github.com/open-mmlab/mmsegmentation/pull/2379))
|
||||
- Fix typo in warning on binary classification ([#2382](https://github.com/open-mmlab/mmsegmentation/pull/2382))
|
||||
|
||||
### Enhancement
|
||||
|
||||
- Fix ci for 1.x ([#2011](https://github.com/open-mmlab/mmsegmentation/pull/2011), [#2019](https://github.com/open-mmlab/mmsegmentation/pull/2019))
|
||||
- Fix lint and pre-commit hook ([#2308](https://github.com/open-mmlab/mmsegmentation/pull/2308))
|
||||
- Add `data` string in .gitignore file in dev-1.x branch ([#2336](https://github.com/open-mmlab/mmsegmentation/pull/2336))
|
||||
- Make scipy as a default dependency in runtime ([#2362](https://github.com/open-mmlab/mmsegmentation/pull/2362))
|
||||
- Delete mmcls in runtime.txt ([#2368](https://github.com/open-mmlab/mmsegmentation/pull/2368))
|
||||
|
||||
### Documentation
|
||||
|
||||
- Update configuration documentation ([#2048](https://github.com/open-mmlab/mmsegmentation/pull/2048))
|
||||
- Update inference documentation ([#2052](https://github.com/open-mmlab/mmsegmentation/pull/2052))
|
||||
- Update train test documentation ([#2061](https://github.com/open-mmlab/mmsegmentation/pull/2061))
|
||||
- Update get started documentatin ([#2148](https://github.com/open-mmlab/mmsegmentation/pull/2148))
|
||||
- Update transforms documentation ([#2088](https://github.com/open-mmlab/mmsegmentation/pull/2088))
|
||||
- Add MMEval projects like in README ([#2259](https://github.com/open-mmlab/mmsegmentation/pull/2259))
|
||||
- Translate the visualization.md ([#2298](https://github.com/open-mmlab/mmsegmentation/pull/2298))
|
||||
|
||||
## v1.0.0rc1 (2/11/2022)
|
||||
|
||||
### Highlights
|
||||
|
||||
- Support PoolFormer ([#2191](https://github.com/open-mmlab/mmsegmentation/pull/2191))
|
||||
- Add Decathlon dataset ([#2227](https://github.com/open-mmlab/mmsegmentation/pull/2227))
|
||||
|
||||
### Features
|
||||
|
||||
- Add BioMedical data loading ([#2176](https://github.com/open-mmlab/mmsegmentation/pull/2176))
|
||||
- Add LIP dataset ([#2251](https://github.com/open-mmlab/mmsegmentation/pull/2251))
|
||||
- Add `GenerateEdge` data transform ([#2210](https://github.com/open-mmlab/mmsegmentation/pull/2210))
|
||||
|
||||
### Bug fix
|
||||
|
||||
- Fix segmenter-vit-s_fcn config ([#2037](https://github.com/open-mmlab/mmsegmentation/pull/2037))
|
||||
- Fix binary segmentation ([#2101](https://github.com/open-mmlab/mmsegmentation/pull/2101))
|
||||
- Fix MMSegmentation colab demo ([#2089](https://github.com/open-mmlab/mmsegmentation/pull/2089))
|
||||
- Fix ResizeToMultiple transform ([#2185](https://github.com/open-mmlab/mmsegmentation/pull/2185))
|
||||
- Use SyncBN in mobilenet_v2 ([#2198](https://github.com/open-mmlab/mmsegmentation/pull/2198))
|
||||
- Fix typo in installation ([#2175](https://github.com/open-mmlab/mmsegmentation/pull/2175))
|
||||
- Fix typo in visualization.md ([#2116](https://github.com/open-mmlab/mmsegmentation/pull/2116))
|
||||
|
||||
### Enhancement
|
||||
|
||||
- Add mim extras_requires in setup.py ([#2012](https://github.com/open-mmlab/mmsegmentation/pull/2012))
|
||||
- Fix CI ([#2029](https://github.com/open-mmlab/mmsegmentation/pull/2029))
|
||||
- Remove ops module ([#2063](https://github.com/open-mmlab/mmsegmentation/pull/2063))
|
||||
- Add pyupgrade pre-commit hook ([#2078](https://github.com/open-mmlab/mmsegmentation/pull/2078))
|
||||
- Add `out_file` in `add_datasample` of `SegLocalVisualizer` to directly save image ([#2090](https://github.com/open-mmlab/mmsegmentation/pull/2090))
|
||||
- Upgrade pre commit hooks ([#2154](https://github.com/open-mmlab/mmsegmentation/pull/2154))
|
||||
- Ignore test timm in CI when torch\<1.7 ([#2158](https://github.com/open-mmlab/mmsegmentation/pull/2158))
|
||||
- Update requirements ([#2186](https://github.com/open-mmlab/mmsegmentation/pull/2186))
|
||||
- Fix Windows platform CI ([#2202](https://github.com/open-mmlab/mmsegmentation/pull/2202))
|
||||
|
||||
### Documentation
|
||||
|
||||
- Add `Overview` documentation ([#2042](https://github.com/open-mmlab/mmsegmentation/pull/2042))
|
||||
- Add `Evaluation` documentation ([#2077](https://github.com/open-mmlab/mmsegmentation/pull/2077))
|
||||
- Add `Migration` documentation ([#2066](https://github.com/open-mmlab/mmsegmentation/pull/2066))
|
||||
- Add `Structures` documentation ([#2070](https://github.com/open-mmlab/mmsegmentation/pull/2070))
|
||||
- Add `Structures` ZN documentation ([#2129](https://github.com/open-mmlab/mmsegmentation/pull/2129))
|
||||
- Add `Engine` ZN documentation ([#2157](https://github.com/open-mmlab/mmsegmentation/pull/2157))
|
||||
- Update `Prepare datasets` and `Visualization` doc ([#2054](https://github.com/open-mmlab/mmsegmentation/pull/2054))
|
||||
- Update `Models` documentation ([#2160](https://github.com/open-mmlab/mmsegmentation/pull/2160))
|
||||
- Update `Add New Modules` documentation ([#2067](https://github.com/open-mmlab/mmsegmentation/pull/2067))
|
||||
- Fix the installation commands in get_started.md ([#2174](https://github.com/open-mmlab/mmsegmentation/pull/2174))
|
||||
- Add MMYOLO to README.md ([#2220](https://github.com/open-mmlab/mmsegmentation/pull/2220))
|
||||
|
||||
## v1.0.0rc0 (31/8/2022)
|
||||
|
||||
We are excited to announce the release of MMSegmentation 1.0.0rc0.
|
||||
MMSeg 1.0.0rc0 is the first version of MMSegmentation 1.x, a part of the OpenMMLab 2.0 projects.
|
||||
Built upon the new [training engine](https://github.com/open-mmlab/mmengine),
|
||||
MMSeg 1.x unifies the interfaces of dataset, models, evaluation, and visualization with faster training and testing speed.
|
||||
|
||||
### Highlights
|
||||
|
||||
1. **New engines** MMSeg 1.x is based on [MMEngine](https://github.com/open-mmlab/mmengine), which provides a general and powerful runner that allows more flexible customizations and significantly simplifies the entrypoints of high-level interfaces.
|
||||
|
||||
2. **Unified interfaces** As a part of the OpenMMLab 2.0 projects, MMSeg 1.x unifies and refactors the interfaces and internal logics of train, testing, datasets, models, evaluation, and visualization. All the OpenMMLab 2.0 projects share the same design in those interfaces and logics to allow the emergence of multi-task/modality algorithms.
|
||||
|
||||
3. **Faster speed** We optimize the training and inference speed for common models.
|
||||
|
||||
4. **New features**:
|
||||
|
||||
- Support TverskyLoss function
|
||||
|
||||
5. **More documentation and tutorials**. We add a bunch of documentation and tutorials to help users get started more smoothly. Read it [here](https://mmsegmentation.readthedocs.io/en/1.x/).
|
||||
|
||||
### Breaking Changes
|
||||
|
||||
We briefly list the major breaking changes here.
|
||||
We will update the [migration guide](../migration.md) to provide complete details and migration instructions.
|
||||
|
||||
#### Training and testing
|
||||
|
||||
- MMSeg 1.x runs on PyTorch>=1.6. We have deprecated the support of PyTorch 1.5 to embrace the mixed precision training and other new features since PyTorch 1.6. Some models can still run on PyTorch 1.5, but the full functionality of MMSeg 1.x is not guaranteed.
|
||||
|
||||
- MMSeg 1.x uses Runner in [MMEngine](https://github.com/open-mmlab/mmengine) rather than that in MMCV. The new Runner implements and unifies the building logic of dataset, model, evaluation, and visualizer. Therefore, MMSeg 1.x no longer maintains the building logics of those modules in `mmseg.train.apis` and `tools/train.py`. Those code have been migrated into [MMEngine](https://github.com/open-mmlab/mmengine/blob/main/mmengine/runner/runner.py). Please refer to the [migration guide of Runner in MMEngine](https://mmengine.readthedocs.io/en/latest/migration/runner.html) for more details.
|
||||
|
||||
- The Runner in MMEngine also supports testing and validation. The testing scripts are also simplified, which has similar logic as that in training scripts to build the runner.
|
||||
|
||||
- The execution points of hooks in the new Runner have been enriched to allow more flexible customization. Please refer to the [migration guide of Hook in MMEngine](https://mmengine.readthedocs.io/en/latest/migration/hook.html) for more details.
|
||||
|
||||
- Learning rate and momentum scheduling has been migrated from `Hook` to `Parameter Scheduler` in MMEngine. Please refer to the [migration guide of Parameter Scheduler in MMEngine](https://mmengine.readthedocs.io/en/latest/migration/param_scheduler.html) for more details.
|
||||
|
||||
#### Configs
|
||||
|
||||
- The [Runner in MMEngine](https://github.com/open-mmlab/mmengine/blob/main/mmengine/runner/runner.py) uses a different config structures to ease the understanding of the components in runner. Users can read the [config example of mmseg](../user_guides/config.md) or refer to the [migration guide in MMEngine](https://mmengine.readthedocs.io/en/latest/migration/runner.html) for migration details.
|
||||
- The file names of configs and models are also refactored to follow the new rules unified across OpenMMLab 2.0 projects. Please refer to the [user guides of config](../user_guides/1_config.md) for more details.
|
||||
|
||||
#### Components
|
||||
|
||||
- Dataset
|
||||
- Data Transforms
|
||||
- Model
|
||||
- Evaluation
|
||||
- Visualization
|
||||
|
||||
### Improvements
|
||||
|
||||
- Support mixed precision training of all the models. However, some models may got Nan results due to some numerical issues. We will update the documentation and list their results (accuracy of failure) of mixed precision training.
|
||||
|
||||
### Bug Fixes
|
||||
|
||||
- Fix several config file errors [#1994](https://github.com/open-mmlab/mmsegmentation/pull/1994)
|
||||
|
||||
### New Features
|
||||
|
||||
1. Support data structures and encapsulating `seg_logits` in data samples, which can be return from models to support more common evaluation metrics.
|
||||
|
||||
### Ongoing changes
|
||||
|
||||
1. Test-time augmentation: which is supported in MMSeg 0.x is not implemented in this version due to limited time slot. We will support it in the following releases with a new and simplified design.
|
||||
|
||||
2. Inference interfaces: a unified inference interfaces will be supported in the future to ease the use of released models.
|
||||
|
||||
3. Interfaces of useful tools that can be used in notebook: more useful tools that implemented in the `tools` directory will have their python interfaces so that they can be used through notebook and in downstream libraries.
|
||||
|
||||
4. Documentation: we will add more design docs, tutorials, and migration guidance so that the community can deep dive into our new design, participate the future development, and smoothly migrate downstream libraries to MMSeg 1.x.
|
||||
720
Seg_All_In_One_MMSeg/docs/en/notes/changelog_v0.x.md
Normal file
720
Seg_All_In_One_MMSeg/docs/en/notes/changelog_v0.x.md
Normal file
@@ -0,0 +1,720 @@
|
||||
## Changelog
|
||||
|
||||
### V0.24.1 (5/1/2022)
|
||||
|
||||
**Bug Fixes**
|
||||
|
||||
- Fix `LayerDecayOptimizerConstructor` for MAE training ([#1539](https://github.com/open-mmlab/mmsegmentation/pull/1539), [#1540](https://github.com/open-mmlab/mmsegmentation/pull/1540))
|
||||
|
||||
### V0.24.0 (4/29/2022)
|
||||
|
||||
**Highlights**
|
||||
|
||||
- Support MAE: Masked Autoencoders Are Scalable Vision Learners
|
||||
- Support Resnet strikes back
|
||||
|
||||
**New Features**
|
||||
|
||||
- Support MAE: Masked Autoencoders Are Scalable Vision Learners ([#1307](https://github.com/open-mmlab/mmsegmentation/pull/1307), [#1523](https://github.com/open-mmlab/mmsegmentation/pull/1523))
|
||||
- Support Resnet strikes back ([#1390](https://github.com/open-mmlab/mmsegmentation/pull/1390))
|
||||
- Support extra dataloader settings in configs ([#1435](https://github.com/open-mmlab/mmsegmentation/pull/1435))
|
||||
|
||||
**Bug Fixes**
|
||||
|
||||
- Fix input previous results for the last cascade_decode_head ([#1450](https://github.com/open-mmlab/mmsegmentation/pull/1450))
|
||||
- Fix validation loss logging ([#1494](https://github.com/open-mmlab/mmsegmentation/pull/1494))
|
||||
- Fix the bug in binary_cross_entropy ([1527](https://github.com/open-mmlab/mmsegmentation/pull/1527))
|
||||
- Support single channel prediction for Binary Cross Entropy Loss ([#1454](https://github.com/open-mmlab/mmsegmentation/pull/1454))
|
||||
- Fix potential bugs in accuracy.py ([1496](https://github.com/open-mmlab/mmsegmentation/pull/1496))
|
||||
- Avoid converting label ids twice by label map during evaluation ([1417](https://github.com/open-mmlab/mmsegmentation/pull/1417))
|
||||
- Fix bug about label_map ([1445](https://github.com/open-mmlab/mmsegmentation/pull/1445))
|
||||
- Fix image save path bug in Windows ([1423](https://github.com/open-mmlab/mmsegmentation/pull/1423))
|
||||
- Fix MMSegmentation Colab demo ([1501](https://github.com/open-mmlab/mmsegmentation/pull/1501), [1452](https://github.com/open-mmlab/mmsegmentation/pull/1452))
|
||||
- Migrate azure blob for beit checkpoints ([1503](https://github.com/open-mmlab/mmsegmentation/pull/1503))
|
||||
- Fix bug in `tools/analyse_logs.py` caused by wrong plot_iter in some cases ([1428](https://github.com/open-mmlab/mmsegmentation/pull/1428))
|
||||
|
||||
**Improvements**
|
||||
|
||||
- Merge BEiT and ConvNext's LR decay optimizer constructors ([#1438](https://github.com/open-mmlab/mmsegmentation/pull/1438))
|
||||
- Register optimizer constructor with mmseg ([#1456](https://github.com/open-mmlab/mmsegmentation/pull/1456))
|
||||
- Refactor transformer encode layer in ViT and BEiT backbone ([#1481](https://github.com/open-mmlab/mmsegmentation/pull/1481))
|
||||
- Add `build_pos_embed` and `build_layers` for BEiT ([1517](https://github.com/open-mmlab/mmsegmentation/pull/1517))
|
||||
- Add `with_cp` to mit and vit ([1431](https://github.com/open-mmlab/mmsegmentation/pull/1431))
|
||||
- Fix inconsistent dtype of `seg_label` in stdc decode ([1463](https://github.com/open-mmlab/mmsegmentation/pull/1463))
|
||||
- Delete random seed for training in `dist_train.sh` ([1519](https://github.com/open-mmlab/mmsegmentation/pull/1519))
|
||||
- Revise high `workers_per_gpus` in config file ([#1506](https://github.com/open-mmlab/mmsegmentation/pull/1506))
|
||||
- Add GPG keys and del mmcv version in Dockerfile ([1534](https://github.com/open-mmlab/mmsegmentation/pull/1534))
|
||||
- Update checkpoint for model in deeplabv3plus ([#1487](https://github.com/open-mmlab/mmsegmentation/pull/1487))
|
||||
- Add `DistSamplerSeedHook` to set epoch number to dataloader when runner is `EpochBasedRunner` ([1449](https://github.com/open-mmlab/mmsegmentation/pull/1449))
|
||||
- Provide URLs of Swin Transformer pretrained models ([1389](https://github.com/open-mmlab/mmsegmentation/pull/1389))
|
||||
- Updating Dockerfiles From Docker Directory and `get_started.md` to reach latest stable version of Python, PyTorch and MMCV ([1446](https://github.com/open-mmlab/mmsegmentation/pull/1446))
|
||||
|
||||
**Documentation**
|
||||
|
||||
- Add more clearly statement of CPU training/inference ([1518](https://github.com/open-mmlab/mmsegmentation/pull/1518))
|
||||
|
||||
**Contributors**
|
||||
|
||||
- @jiangyitong made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/1431
|
||||
- @kahkeng made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/1447
|
||||
- @Nourollah made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/1446
|
||||
- @androbaza made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/1452
|
||||
- @Yzichen made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/1445
|
||||
- @whu-pzhang made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/1423
|
||||
- @panfeng-hover made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/1417
|
||||
- @Johnson-Wang made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/1496
|
||||
- @jere357 made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/1460
|
||||
- @mfernezir made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/1494
|
||||
- @donglixp made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/1503
|
||||
- @YuanLiuuuuuu made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/1307
|
||||
- @Dawn-bin made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/1527
|
||||
|
||||
### V0.23.0 (4/1/2022)
|
||||
|
||||
**Highlights**
|
||||
|
||||
- Support BEiT: BERT Pre-Training of Image Transformers
|
||||
- Support K-Net: Towards Unified Image Segmentation
|
||||
- Add `avg_non_ignore` of CELoss to support average loss over non-ignored elements
|
||||
- Support dataset initialization with file client
|
||||
|
||||
**New Features**
|
||||
|
||||
- Support BEiT: BERT Pre-Training of Image Transformers ([#1404](https://github.com/open-mmlab/mmsegmentation/pull/1404))
|
||||
- Support K-Net: Towards Unified Image Segmentation ([#1289](https://github.com/open-mmlab/mmsegmentation/pull/1289))
|
||||
- Support dataset initialization with file client ([#1402](https://github.com/open-mmlab/mmsegmentation/pull/1402))
|
||||
- Add class name function for STARE datasets ([#1376](https://github.com/open-mmlab/mmsegmentation/pull/1376))
|
||||
- Support different seeds on different ranks when distributed training ([#1362](https://github.com/open-mmlab/mmsegmentation/pull/1362))
|
||||
- Add `nlc2nchw2nlc` and `nchw2nlc2nchw` to simplify tensor with different dimension operation ([#1249](https://github.com/open-mmlab/mmsegmentation/pull/1249))
|
||||
|
||||
**Improvements**
|
||||
|
||||
- Synchronize random seed for distributed sampler ([#1411](https://github.com/open-mmlab/mmsegmentation/pull/1411))
|
||||
- Add script and documentation for multi-machine distributed training ([#1383](https://github.com/open-mmlab/mmsegmentation/pull/1383))
|
||||
|
||||
**Bug Fixes**
|
||||
|
||||
- Add `avg_non_ignore` of CELoss to support average loss over non-ignored elements ([#1409](https://github.com/open-mmlab/mmsegmentation/pull/1409))
|
||||
- Fix some wrong URLs of models or logs in `./configs` ([#1336](https://github.com/open-mmlab/mmsegmentation/pull/1433))
|
||||
- Add title and color theme arguments to plot function in `tools/confusion_matrix.py` ([#1401](https://github.com/open-mmlab/mmsegmentation/pull/1401))
|
||||
- Fix outdated link in Colab demo ([#1392](https://github.com/open-mmlab/mmsegmentation/pull/1392))
|
||||
- Fix typos ([#1424](https://github.com/open-mmlab/mmsegmentation/pull/1424), [#1405](https://github.com/open-mmlab/mmsegmentation/pull/1405), [#1371](https://github.com/open-mmlab/mmsegmentation/pull/1371), [#1366](https://github.com/open-mmlab/mmsegmentation/pull/1366), [#1363](https://github.com/open-mmlab/mmsegmentation/pull/1363))
|
||||
|
||||
**Documentation**
|
||||
|
||||
- Add FAQ document ([#1420](https://github.com/open-mmlab/mmsegmentation/pull/1420))
|
||||
- Fix the config name style description in official docs([#1414](https://github.com/open-mmlab/mmsegmentation/pull/1414))
|
||||
|
||||
**Contributors**
|
||||
|
||||
- @kinglintianxia made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/1371
|
||||
- @CCODING04 made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/1376
|
||||
- @mob5566 made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/1401
|
||||
- @xiongnemo made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/1392
|
||||
- @Xiangxu-0103 made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/1405
|
||||
|
||||
### V0.22.1 (3/9/2022)
|
||||
|
||||
**Bug Fixes**
|
||||
|
||||
- Fix the ZeroDivisionError that all pixels in one image is ignored. ([#1336](https://github.com/open-mmlab/mmsegmentation/pull/1336))
|
||||
|
||||
**Improvements**
|
||||
|
||||
- Provide URLs of STDC, Segmenter and Twins pretrained models ([#1272](https://github.com/open-mmlab/mmsegmentation/pull/1357))
|
||||
|
||||
### V0.22 (3/04/2022)
|
||||
|
||||
**Highlights**
|
||||
|
||||
- Support ConvNeXt: A ConvNet for the 2020s. Please use the latest MMClassification (0.21.0) to try it out.
|
||||
- Support iSAID aerial Dataset.
|
||||
- Officially Support inference on Windows OS.
|
||||
|
||||
**New Features**
|
||||
|
||||
- Support ConvNeXt: A ConvNet for the 2020s. ([#1216](https://github.com/open-mmlab/mmsegmentation/pull/1216))
|
||||
- Support iSAID aerial Dataset. ([#1115](https://github.com/open-mmlab/mmsegmentation/pull/1115)
|
||||
- Generating and plotting confusion matrix. ([#1301](https://github.com/open-mmlab/mmsegmentation/pull/1301))
|
||||
|
||||
**Improvements**
|
||||
|
||||
- Refactor 4 decoder heads (ASPP, FCN, PSP, UPer): Split forward function into `_forward_feature` and `cls_seg`. ([#1299](https://github.com/open-mmlab/mmsegmentation/pull/1299))
|
||||
- Add `min_size` arg in `Resize` to keep the shape after resize bigger than slide window. ([#1318](https://github.com/open-mmlab/mmsegmentation/pull/1318))
|
||||
- Revise pre-commit-hooks. ([#1315](https://github.com/open-mmlab/mmsegmentation/pull/1315))
|
||||
- Add win-ci. ([#1296](https://github.com/open-mmlab/mmsegmentation/pull/1296))
|
||||
|
||||
**Bug Fixes**
|
||||
|
||||
- Fix `mlp_ratio` type in Swin Transformer. ([#1274](https://github.com/open-mmlab/mmsegmentation/pull/1274))
|
||||
- Fix path errors in `./demo` . ([#1269](https://github.com/open-mmlab/mmsegmentation/pull/1269))
|
||||
- Fix bug in conversion of potsdam. ([#1279](https://github.com/open-mmlab/mmsegmentation/pull/1279))
|
||||
- Make accuracy take into account `ignore_index`. ([#1259](https://github.com/open-mmlab/mmsegmentation/pull/1259))
|
||||
- Add Pytorch HardSwish assertion in unit test. ([#1294](https://github.com/open-mmlab/mmsegmentation/pull/1294))
|
||||
- Fix wrong palette value in vaihingen. ([#1292](https://github.com/open-mmlab/mmsegmentation/pull/1292))
|
||||
- Fix the bug that SETR cannot load pretrain. ([#1293](https://github.com/open-mmlab/mmsegmentation/pull/1293))
|
||||
- Update correct `In Collection` in metafile of each configs. ([#1239](https://github.com/open-mmlab/mmsegmentation/pull/1239))
|
||||
- Upload completed STDC models. ([#1332](https://github.com/open-mmlab/mmsegmentation/pull/1332))
|
||||
- Fix `DNLHead` exports onnx inference difference type Cast error. ([#1161](https://github.com/open-mmlab/mmsegmentation/pull/1332))
|
||||
|
||||
**Contributors**
|
||||
|
||||
- @JiaYanhao made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/1269
|
||||
- @andife made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/1281
|
||||
- @SBCV made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/1279
|
||||
- @HJoonKwon made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/1259
|
||||
- @Tsingularity made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/1290
|
||||
- @Waterman0524 made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/1115
|
||||
- @MeowZheng made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/1315
|
||||
- @linfangjian01 made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/1318
|
||||
|
||||
### V0.21.1 (2/9/2022)
|
||||
|
||||
**Bug Fixes**
|
||||
|
||||
- Fix typos in docs. ([#1263](https://github.com/open-mmlab/mmsegmentation/pull/1263))
|
||||
- Fix repeating log by `setup_multi_processes`. ([#1267](https://github.com/open-mmlab/mmsegmentation/pull/1267))
|
||||
- Upgrade isort in pre-commit hook. ([#1270](https://github.com/open-mmlab/mmsegmentation/pull/1270))
|
||||
|
||||
**Improvements**
|
||||
|
||||
- Use MMCV load_state_dict func in ViT/Swin. ([#1272](https://github.com/open-mmlab/mmsegmentation/pull/1272))
|
||||
- Add exception for PointRend for support CPU-only. ([#1271](https://github.com/open-mmlab/mmsegmentation/pull/1270))
|
||||
|
||||
### V0.21 (1/29/2022)
|
||||
|
||||
**Highlights**
|
||||
|
||||
- Officially Support CPUs training and inference, please use the latest MMCV (1.4.4) to try it out.
|
||||
- Support Segmenter: Transformer for Semantic Segmentation (ICCV'2021).
|
||||
- Support ISPRS Potsdam and Vaihingen Dataset.
|
||||
- Add Mosaic transform and `MultiImageMixDataset` class in `dataset_wrappers`.
|
||||
|
||||
**New Features**
|
||||
|
||||
- Support Segmenter: Transformer for Semantic Segmentation (ICCV'2021) ([#955](https://github.com/open-mmlab/mmsegmentation/pull/955))
|
||||
- Support ISPRS Potsdam and Vaihingen Dataset ([#1097](https://github.com/open-mmlab/mmsegmentation/pull/1097), [#1171](https://github.com/open-mmlab/mmsegmentation/pull/1171))
|
||||
- Add segformer‘s benchmark on cityscapes ([#1155](https://github.com/open-mmlab/mmsegmentation/pull/1155))
|
||||
- Add auto resume ([#1172](https://github.com/open-mmlab/mmsegmentation/pull/1172))
|
||||
- Add Mosaic transform and `MultiImageMixDataset` class in `dataset_wrappers` ([#1093](https://github.com/open-mmlab/mmsegmentation/pull/1093), [#1105](https://github.com/open-mmlab/mmsegmentation/pull/1105))
|
||||
- Add log collector ([#1175](https://github.com/open-mmlab/mmsegmentation/pull/1175))
|
||||
|
||||
**Improvements**
|
||||
|
||||
- New-style CPU training and inference ([#1251](https://github.com/open-mmlab/mmsegmentation/pull/1251))
|
||||
- Add UNet benchmark with multiple losses supervision ([#1143](https://github.com/open-mmlab/mmsegmentation/pull/1143))
|
||||
|
||||
**Bug Fixes**
|
||||
|
||||
- Fix the model statistics in doc for readthedoc ([#1153](https://github.com/open-mmlab/mmsegmentation/pull/1153))
|
||||
- Set random seed for `palette` if not given ([#1152](https://github.com/open-mmlab/mmsegmentation/pull/1152))
|
||||
- Add `COCOStuffDataset` in `class_names.py` ([#1222](https://github.com/open-mmlab/mmsegmentation/pull/1222))
|
||||
- Fix bug in non-distributed multi-gpu training/testing ([#1247](https://github.com/open-mmlab/mmsegmentation/pull/1247))
|
||||
- Delete unnecessary lines of STDCHead ([#1231](https://github.com/open-mmlab/mmsegmentation/pull/1231))
|
||||
|
||||
**Contributors**
|
||||
|
||||
- @jbwang1997 made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/1152
|
||||
- @BeaverCC made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/1206
|
||||
- @Echo-minn made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/1214
|
||||
- @rstrudel made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/955
|
||||
|
||||
### V0.20.2 (12/15/2021)
|
||||
|
||||
**Bug Fixes**
|
||||
|
||||
- Revise --option to --options to avoid BC-breaking. ([#1140](https://github.com/open-mmlab/mmsegmentation/pull/1140))
|
||||
|
||||
### V0.20.1 (12/14/2021)
|
||||
|
||||
**Improvements**
|
||||
|
||||
- Change options to cfg-options ([#1129](https://github.com/open-mmlab/mmsegmentation/pull/1129))
|
||||
|
||||
**Bug Fixes**
|
||||
|
||||
- Fix `<!-- [ABSTRACT] -->` in metafile. ([#1127](https://github.com/open-mmlab/mmsegmentation/pull/1127))
|
||||
- Fix correct `num_classes` of HRNet in `LoveDA` dataset ([#1136](https://github.com/open-mmlab/mmsegmentation/pull/1136))
|
||||
|
||||
### V0.20 (12/10/2021)
|
||||
|
||||
**Highlights**
|
||||
|
||||
- Support Twins ([#989](https://github.com/open-mmlab/mmsegmentation/pull/989))
|
||||
- Support a real-time segmentation model STDC ([#995](https://github.com/open-mmlab/mmsegmentation/pull/995))
|
||||
- Support a widely-used segmentation model in lane detection ERFNet ([#960](https://github.com/open-mmlab/mmsegmentation/pull/960))
|
||||
- Support A Remote Sensing Land-Cover Dataset LoveDA ([#1028](https://github.com/open-mmlab/mmsegmentation/pull/1028))
|
||||
- Support focal loss ([#1024](https://github.com/open-mmlab/mmsegmentation/pull/1024))
|
||||
|
||||
**New Features**
|
||||
|
||||
- Support Twins ([#989](https://github.com/open-mmlab/mmsegmentation/pull/989))
|
||||
- Support a real-time segmentation model STDC ([#995](https://github.com/open-mmlab/mmsegmentation/pull/995))
|
||||
- Support a widely-used segmentation model in lane detection ERFNet ([#960](https://github.com/open-mmlab/mmsegmentation/pull/960))
|
||||
- Add SETR cityscapes benchmark ([#1087](https://github.com/open-mmlab/mmsegmentation/pull/1087))
|
||||
- Add BiSeNetV1 COCO-Stuff 164k benchmark ([#1019](https://github.com/open-mmlab/mmsegmentation/pull/1019))
|
||||
- Support focal loss ([#1024](https://github.com/open-mmlab/mmsegmentation/pull/1024))
|
||||
- Add Cutout transform ([#1022](https://github.com/open-mmlab/mmsegmentation/pull/1022))
|
||||
|
||||
**Improvements**
|
||||
|
||||
- Set a random seed when the user does not set a seed ([#1039](https://github.com/open-mmlab/mmsegmentation/pull/1039))
|
||||
- Add CircleCI setup ([#1086](https://github.com/open-mmlab/mmsegmentation/pull/1086))
|
||||
- Skip CI on ignoring given paths ([#1078](https://github.com/open-mmlab/mmsegmentation/pull/1078))
|
||||
- Add abstract and image for every paper ([#1060](https://github.com/open-mmlab/mmsegmentation/pull/1060))
|
||||
- Create a symbolic link on windows ([#1090](https://github.com/open-mmlab/mmsegmentation/pull/1090))
|
||||
- Support video demo using trained model ([#1014](https://github.com/open-mmlab/mmsegmentation/pull/1014))
|
||||
|
||||
**Bug Fixes**
|
||||
|
||||
- Fix incorrectly loading init_cfg or pretrained models of several transformer models ([#999](https://github.com/open-mmlab/mmsegmentation/pull/999), [#1069](https://github.com/open-mmlab/mmsegmentation/pull/1069), [#1102](https://github.com/open-mmlab/mmsegmentation/pull/1102))
|
||||
- Fix EfficientMultiheadAttention in SegFormer ([#1037](https://github.com/open-mmlab/mmsegmentation/pull/1037))
|
||||
- Remove `fp16` folder in `configs` ([#1031](https://github.com/open-mmlab/mmsegmentation/pull/1031))
|
||||
- Fix several typos in .yml file (Dice Metric [#1041](https://github.com/open-mmlab/mmsegmentation/pull/1041), ADE20K dataset [#1120](https://github.com/open-mmlab/mmsegmentation/pull/1120), Training Memory (GB) [#1083](https://github.com/open-mmlab/mmsegmentation/pull/1083))
|
||||
- Fix test error when using `--show-dir` ([#1091](https://github.com/open-mmlab/mmsegmentation/pull/1091))
|
||||
- Fix dist training infinite waiting issue ([#1035](https://github.com/open-mmlab/mmsegmentation/pull/1035))
|
||||
- Change the upper version of mmcv to 1.5.0 ([#1096](https://github.com/open-mmlab/mmsegmentation/pull/1096))
|
||||
- Fix symlink failure on Windows ([#1038](https://github.com/open-mmlab/mmsegmentation/pull/1038))
|
||||
- Cancel previous runs that are not completed ([#1118](https://github.com/open-mmlab/mmsegmentation/pull/1118))
|
||||
- Unified links of readthedocs in docs ([#1119](https://github.com/open-mmlab/mmsegmentation/pull/1119))
|
||||
|
||||
**Contributors**
|
||||
|
||||
- @Junjue-Wang made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/1028
|
||||
- @ddebby made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/1066
|
||||
- @del-zhenwu made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/1078
|
||||
- @KangBK0120 made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/1106
|
||||
- @zergzzlun made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/1091
|
||||
- @fingertap made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/1035
|
||||
- @irvingzhang0512 made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/1014
|
||||
- @littleSunlxy made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/989
|
||||
- @lkm2835
|
||||
- @RockeyCoss
|
||||
- @MengzhangLI
|
||||
- @Junjun2016
|
||||
- @xiexinch
|
||||
- @xvjiarui
|
||||
|
||||
### V0.19 (11/02/2021)
|
||||
|
||||
**Highlights**
|
||||
|
||||
- Support TIMMBackbone wrapper ([#998](https://github.com/open-mmlab/mmsegmentation/pull/998))
|
||||
- Support custom hook ([#428](https://github.com/open-mmlab/mmsegmentation/pull/428))
|
||||
- Add codespell pre-commit hook ([#920](https://github.com/open-mmlab/mmsegmentation/pull/920))
|
||||
- Add FastFCN benchmark on ADE20K ([#972](https://github.com/open-mmlab/mmsegmentation/pull/972))
|
||||
|
||||
**New Features**
|
||||
|
||||
- Support TIMMBackbone wrapper ([#998](https://github.com/open-mmlab/mmsegmentation/pull/998))
|
||||
- Support custom hook ([#428](https://github.com/open-mmlab/mmsegmentation/pull/428))
|
||||
- Add FastFCN benchmark on ADE20K ([#972](https://github.com/open-mmlab/mmsegmentation/pull/972))
|
||||
- Add codespell pre-commit hook and fix typos ([#920](https://github.com/open-mmlab/mmsegmentation/pull/920))
|
||||
|
||||
**Improvements**
|
||||
|
||||
- Make inputs & channels smaller in unittests ([#1004](https://github.com/open-mmlab/mmsegmentation/pull/1004))
|
||||
- Change `self.loss_decode` back to `dict` in Single Loss situation ([#1002](https://github.com/open-mmlab/mmsegmentation/pull/1002))
|
||||
|
||||
**Bug Fixes**
|
||||
|
||||
- Fix typo in usage example ([#1003](https://github.com/open-mmlab/mmsegmentation/pull/1003))
|
||||
- Add contiguous after permutation in ViT ([#992](https://github.com/open-mmlab/mmsegmentation/pull/992))
|
||||
- Fix the invalid link ([#985](https://github.com/open-mmlab/mmsegmentation/pull/985))
|
||||
- Fix bug in CI with python 3.9 ([#994](https://github.com/open-mmlab/mmsegmentation/pull/994))
|
||||
- Fix bug when loading class name form file in custom dataset ([#923](https://github.com/open-mmlab/mmsegmentation/pull/923))
|
||||
|
||||
**Contributors**
|
||||
|
||||
- @ShoupingShan made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/923
|
||||
- @RockeyCoss made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/954
|
||||
- @HarborYuan made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/992
|
||||
- @lkm2835 made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/1003
|
||||
- @gszh made their first contribution in https://github.com/open-mmlab/mmsegmentation/pull/428
|
||||
- @VVsssssk
|
||||
- @MengzhangLI
|
||||
- @Junjun2016
|
||||
|
||||
### V0.18 (10/07/2021)
|
||||
|
||||
**Highlights**
|
||||
|
||||
- Support three real-time segmentation models (ICNet [#884](https://github.com/open-mmlab/mmsegmentation/pull/884), BiSeNetV1 [#851](https://github.com/open-mmlab/mmsegmentation/pull/851), and BiSeNetV2 [#804](https://github.com/open-mmlab/mmsegmentation/pull/804))
|
||||
- Support one efficient segmentation model (FastFCN [#885](https://github.com/open-mmlab/mmsegmentation/pull/885))
|
||||
- Support one efficient non-local/self-attention based segmentation model (ISANet [#70](https://github.com/open-mmlab/mmsegmentation/pull/70))
|
||||
- Support COCO-Stuff 10k and 164k datasets ([#625](https://github.com/open-mmlab/mmsegmentation/pull/625))
|
||||
- Support evaluate concated dataset separately ([#833](https://github.com/open-mmlab/mmsegmentation/pull/833))
|
||||
- Support loading GT for evaluation from multi-file backend ([#867](https://github.com/open-mmlab/mmsegmentation/pull/867))
|
||||
|
||||
**New Features**
|
||||
|
||||
- Support three real-time segmentation models (ICNet [#884](https://github.com/open-mmlab/mmsegmentation/pull/884), BiSeNetV1 [#851](https://github.com/open-mmlab/mmsegmentation/pull/851), and BiSeNetV2 [#804](https://github.com/open-mmlab/mmsegmentation/pull/804))
|
||||
- Support one efficient segmentation model (FastFCN [#885](https://github.com/open-mmlab/mmsegmentation/pull/885))
|
||||
- Support one efficient non-local/self-attention based segmentation model (ISANet [#70](https://github.com/open-mmlab/mmsegmentation/pull/70))
|
||||
- Support COCO-Stuff 10k and 164k datasets ([#625](https://github.com/open-mmlab/mmsegmentation/pull/625))
|
||||
- Support evaluate concated dataset separately ([#833](https://github.com/open-mmlab/mmsegmentation/pull/833))
|
||||
|
||||
**Improvements**
|
||||
|
||||
- Support loading GT for evaluation from multi-file backend ([#867](https://github.com/open-mmlab/mmsegmentation/pull/867))
|
||||
- Auto-convert SyncBN to BN when training on DP automatly([#772](https://github.com/open-mmlab/mmsegmentation/pull/772))
|
||||
- Refactor Swin-Transformer ([#800](https://github.com/open-mmlab/mmsegmentation/pull/800))
|
||||
|
||||
**Bug Fixes**
|
||||
|
||||
- Update mmcv installation in dockerfile ([#860](https://github.com/open-mmlab/mmsegmentation/pull/860))
|
||||
- Fix number of iteration bug when resuming checkpoint in distributed train ([#866](https://github.com/open-mmlab/mmsegmentation/pull/866))
|
||||
- Fix parsing parse in val_step ([#906](https://github.com/open-mmlab/mmsegmentation/pull/906))
|
||||
|
||||
### V0.17 (09/01/2021)
|
||||
|
||||
**Highlights**
|
||||
|
||||
- Support SegFormer
|
||||
- Support DPT
|
||||
- Support Dark Zurich and Nighttime Driving datasets
|
||||
- Support progressive evaluation
|
||||
|
||||
**New Features**
|
||||
|
||||
- Support SegFormer ([#599](https://github.com/open-mmlab/mmsegmentation/pull/599))
|
||||
- Support DPT ([#605](https://github.com/open-mmlab/mmsegmentation/pull/605))
|
||||
- Support Dark Zurich and Nighttime Driving datasets ([#815](https://github.com/open-mmlab/mmsegmentation/pull/815))
|
||||
- Support progressive evaluation ([#709](https://github.com/open-mmlab/mmsegmentation/pull/709))
|
||||
|
||||
**Improvements**
|
||||
|
||||
- Add multiscale_output interface and unittests for HRNet ([#830](https://github.com/open-mmlab/mmsegmentation/pull/830))
|
||||
- Support inherit cityscapes dataset ([#750](https://github.com/open-mmlab/mmsegmentation/pull/750))
|
||||
- Fix some typos in README.md ([#824](https://github.com/open-mmlab/mmsegmentation/pull/824))
|
||||
- Delete convert function and add instruction to ViT/Swin README.md ([#791](https://github.com/open-mmlab/mmsegmentation/pull/791))
|
||||
- Add vit/swin/mit convert weight scripts ([#783](https://github.com/open-mmlab/mmsegmentation/pull/783))
|
||||
- Add copyright files ([#796](https://github.com/open-mmlab/mmsegmentation/pull/796))
|
||||
|
||||
**Bug Fixes**
|
||||
|
||||
- Fix invalid checkpoint link in inference_demo.ipynb ([#814](https://github.com/open-mmlab/mmsegmentation/pull/814))
|
||||
- Ensure that items in dataset have the same order across multi machine ([#780](https://github.com/open-mmlab/mmsegmentation/pull/780))
|
||||
- Fix the log error ([#766](https://github.com/open-mmlab/mmsegmentation/pull/766))
|
||||
|
||||
### V0.16 (08/04/2021)
|
||||
|
||||
**Highlights**
|
||||
|
||||
- Support PyTorch 1.9
|
||||
- Support SegFormer backbone MiT
|
||||
- Support md2yml pre-commit hook
|
||||
- Support frozen stage for HRNet
|
||||
|
||||
**New Features**
|
||||
|
||||
- Support SegFormer backbone MiT ([#594](https://github.com/open-mmlab/mmsegmentation/pull/594))
|
||||
- Support md2yml pre-commit hook ([#732](https://github.com/open-mmlab/mmsegmentation/pull/732))
|
||||
- Support mim ([#717](https://github.com/open-mmlab/mmsegmentation/pull/717))
|
||||
- Add mmseg2torchserve tool ([#552](https://github.com/open-mmlab/mmsegmentation/pull/552))
|
||||
|
||||
**Improvements**
|
||||
|
||||
- Support hrnet frozen stage ([#743](https://github.com/open-mmlab/mmsegmentation/pull/743))
|
||||
- Add template of reimplementation questions ([#741](https://github.com/open-mmlab/mmsegmentation/pull/741))
|
||||
- Output pdf and epub formats for readthedocs ([#742](https://github.com/open-mmlab/mmsegmentation/pull/742))
|
||||
- Refine the docstring of ResNet ([#723](https://github.com/open-mmlab/mmsegmentation/pull/723))
|
||||
- Replace interpolate with resize ([#731](https://github.com/open-mmlab/mmsegmentation/pull/731))
|
||||
- Update resource limit ([#700](https://github.com/open-mmlab/mmsegmentation/pull/700))
|
||||
- Update config.md ([#678](https://github.com/open-mmlab/mmsegmentation/pull/678))
|
||||
|
||||
**Bug Fixes**
|
||||
|
||||
- Fix ATTENTION registry ([#729](https://github.com/open-mmlab/mmsegmentation/pull/729))
|
||||
- Fix analyze log script ([#716](https://github.com/open-mmlab/mmsegmentation/pull/716))
|
||||
- Fix doc api display ([#725](https://github.com/open-mmlab/mmsegmentation/pull/725))
|
||||
- Fix patch_embed and pos_embed mismatch error ([#685](https://github.com/open-mmlab/mmsegmentation/pull/685))
|
||||
- Fix efficient test for multi-node ([#707](https://github.com/open-mmlab/mmsegmentation/pull/707))
|
||||
- Fix init_cfg in resnet backbone ([#697](https://github.com/open-mmlab/mmsegmentation/pull/697))
|
||||
- Fix efficient test bug ([#702](https://github.com/open-mmlab/mmsegmentation/pull/702))
|
||||
- Fix url error in config docs ([#680](https://github.com/open-mmlab/mmsegmentation/pull/680))
|
||||
- Fix mmcv installation ([#676](https://github.com/open-mmlab/mmsegmentation/pull/676))
|
||||
- Fix torch version ([#670](https://github.com/open-mmlab/mmsegmentation/pull/670))
|
||||
|
||||
**Contributors**
|
||||
|
||||
@sshuair @xiexinch @Junjun2016 @mmeendez8 @xvjiarui @sennnnn @puhsu @BIGWangYuDong @keke1u @daavoo
|
||||
|
||||
### V0.15 (07/04/2021)
|
||||
|
||||
**Highlights**
|
||||
|
||||
- Support ViT, SETR, and Swin-Transformer
|
||||
- Add Chinese documentation
|
||||
- Unified parameter initialization
|
||||
|
||||
**Bug Fixes**
|
||||
|
||||
- Fix typo and links ([#608](https://github.com/open-mmlab/mmsegmentation/pull/608))
|
||||
- Fix Dockerfile ([#607](https://github.com/open-mmlab/mmsegmentation/pull/607))
|
||||
- Fix ViT init ([#609](https://github.com/open-mmlab/mmsegmentation/pull/609))
|
||||
- Fix mmcv version compatible table ([#658](https://github.com/open-mmlab/mmsegmentation/pull/658))
|
||||
- Fix model links of DMNEt ([#660](https://github.com/open-mmlab/mmsegmentation/pull/660))
|
||||
|
||||
**New Features**
|
||||
|
||||
- Support loading DeiT weights ([#538](https://github.com/open-mmlab/mmsegmentation/pull/538))
|
||||
- Support SETR ([#531](https://github.com/open-mmlab/mmsegmentation/pull/531), [#635](https://github.com/open-mmlab/mmsegmentation/pull/635))
|
||||
- Add config and models for ViT backbone with UperHead ([#520](https://github.com/open-mmlab/mmsegmentation/pull/531), [#635](https://github.com/open-mmlab/mmsegmentation/pull/520))
|
||||
- Support Swin-Transformer ([#511](https://github.com/open-mmlab/mmsegmentation/pull/511))
|
||||
- Add higher accuracy FastSCNN ([#606](https://github.com/open-mmlab/mmsegmentation/pull/606))
|
||||
- Add Chinese documentation ([#666](https://github.com/open-mmlab/mmsegmentation/pull/666))
|
||||
|
||||
**Improvements**
|
||||
|
||||
- Unified parameter initialization ([#567](https://github.com/open-mmlab/mmsegmentation/pull/567))
|
||||
- Separate CUDA and CPU in github action CI ([#602](https://github.com/open-mmlab/mmsegmentation/pull/602))
|
||||
- Support persistent dataloader worker ([#646](https://github.com/open-mmlab/mmsegmentation/pull/646))
|
||||
- Update meta file fields ([#661](https://github.com/open-mmlab/mmsegmentation/pull/661), [#664](https://github.com/open-mmlab/mmsegmentation/pull/664))
|
||||
|
||||
### V0.14 (06/02/2021)
|
||||
|
||||
**Highlights**
|
||||
|
||||
- Support ONNX to TensorRT
|
||||
- Support MIM
|
||||
|
||||
**Bug Fixes**
|
||||
|
||||
- Fix ONNX to TensorRT verify ([#547](https://github.com/open-mmlab/mmsegmentation/pull/547))
|
||||
- Fix save best for EvalHook ([#575](https://github.com/open-mmlab/mmsegmentation/pull/575))
|
||||
|
||||
**New Features**
|
||||
|
||||
- Support loading DeiT weights ([#538](https://github.com/open-mmlab/mmsegmentation/pull/538))
|
||||
- Support ONNX to TensorRT ([#542](https://github.com/open-mmlab/mmsegmentation/pull/542))
|
||||
- Support output results for ADE20k ([#544](https://github.com/open-mmlab/mmsegmentation/pull/544))
|
||||
- Support MIM ([#549](https://github.com/open-mmlab/mmsegmentation/pull/549))
|
||||
|
||||
**Improvements**
|
||||
|
||||
- Add option for ViT output shape ([#530](https://github.com/open-mmlab/mmsegmentation/pull/530))
|
||||
- Infer batch size using len(result) ([#532](https://github.com/open-mmlab/mmsegmentation/pull/532))
|
||||
- Add compatible table between MMSeg and MMCV ([#558](https://github.com/open-mmlab/mmsegmentation/pull/558))
|
||||
|
||||
### V0.13 (05/05/2021)
|
||||
|
||||
**Highlights**
|
||||
|
||||
- Support Pascal Context Class-59 dataset.
|
||||
- Support Visual Transformer Backbone.
|
||||
- Support mFscore metric.
|
||||
|
||||
**Bug Fixes**
|
||||
|
||||
- Fixed Colaboratory tutorial ([#451](https://github.com/open-mmlab/mmsegmentation/pull/451))
|
||||
- Fixed mIoU calculation range ([#471](https://github.com/open-mmlab/mmsegmentation/pull/471))
|
||||
- Fixed sem_fpn, unet README.md ([#492](https://github.com/open-mmlab/mmsegmentation/pull/492))
|
||||
- Fixed `num_classes` in FCN for Pascal Context 60-class dataset ([#488](https://github.com/open-mmlab/mmsegmentation/pull/488))
|
||||
- Fixed FP16 inference ([#497](https://github.com/open-mmlab/mmsegmentation/pull/497))
|
||||
|
||||
**New Features**
|
||||
|
||||
- Support dynamic export and visualize to pytorch2onnx ([#463](https://github.com/open-mmlab/mmsegmentation/pull/463))
|
||||
- Support export to torchscript ([#469](https://github.com/open-mmlab/mmsegmentation/pull/469), [#499](https://github.com/open-mmlab/mmsegmentation/pull/499))
|
||||
- Support Pascal Context Class-59 dataset ([#459](https://github.com/open-mmlab/mmsegmentation/pull/459))
|
||||
- Support Visual Transformer backbone ([#465](https://github.com/open-mmlab/mmsegmentation/pull/465))
|
||||
- Support UpSample Neck ([#512](https://github.com/open-mmlab/mmsegmentation/pull/512))
|
||||
- Support mFscore metric ([#509](https://github.com/open-mmlab/mmsegmentation/pull/509))
|
||||
|
||||
**Improvements**
|
||||
|
||||
- Add more CI for PyTorch ([#460](https://github.com/open-mmlab/mmsegmentation/pull/460))
|
||||
- Add print model graph args for tools/print_config.py ([#451](https://github.com/open-mmlab/mmsegmentation/pull/451))
|
||||
- Add cfg links in modelzoo README.md ([#468](https://github.com/open-mmlab/mmsegmentation/pull/469))
|
||||
- Add BaseSegmentor import to segmentors/__init__.py ([#495](https://github.com/open-mmlab/mmsegmentation/pull/495))
|
||||
- Add MMOCR, MMGeneration links ([#501](https://github.com/open-mmlab/mmsegmentation/pull/501), [#506](https://github.com/open-mmlab/mmsegmentation/pull/506))
|
||||
- Add Chinese QR code ([#506](https://github.com/open-mmlab/mmsegmentation/pull/506))
|
||||
- Use MMCV MODEL_REGISTRY ([#515](https://github.com/open-mmlab/mmsegmentation/pull/515))
|
||||
- Add ONNX testing tools ([#498](https://github.com/open-mmlab/mmsegmentation/pull/498))
|
||||
- Replace data_dict calling 'img' key to support MMDet3D ([#514](https://github.com/open-mmlab/mmsegmentation/pull/514))
|
||||
- Support reading class_weight from file in loss function ([#513](https://github.com/open-mmlab/mmsegmentation/pull/513))
|
||||
- Make tags as comment ([#505](https://github.com/open-mmlab/mmsegmentation/pull/505))
|
||||
- Use MMCV EvalHook ([#438](https://github.com/open-mmlab/mmsegmentation/pull/438))
|
||||
|
||||
### V0.12 (04/03/2021)
|
||||
|
||||
**Highlights**
|
||||
|
||||
- Support FCN-Dilate 6 model.
|
||||
- Support Dice Loss.
|
||||
|
||||
**Bug Fixes**
|
||||
|
||||
- Fixed PhotoMetricDistortion Doc ([#388](https://github.com/open-mmlab/mmsegmentation/pull/388))
|
||||
- Fixed install scripts ([#399](https://github.com/open-mmlab/mmsegmentation/pull/399))
|
||||
- Fixed Dice Loss multi-class ([#417](https://github.com/open-mmlab/mmsegmentation/pull/417))
|
||||
|
||||
**New Features**
|
||||
|
||||
- Support Dice Loss ([#396](https://github.com/open-mmlab/mmsegmentation/pull/396))
|
||||
- Add plot logs tool ([#426](https://github.com/open-mmlab/mmsegmentation/pull/426))
|
||||
- Add opacity option to show_result ([#425](https://github.com/open-mmlab/mmsegmentation/pull/425))
|
||||
- Speed up mIoU metric ([#430](https://github.com/open-mmlab/mmsegmentation/pull/430))
|
||||
|
||||
**Improvements**
|
||||
|
||||
- Refactor unittest file structure ([#440](https://github.com/open-mmlab/mmsegmentation/pull/440))
|
||||
- Fix typos in the repo ([#449](https://github.com/open-mmlab/mmsegmentation/pull/449))
|
||||
- Include class-level metrics in the log ([#445](https://github.com/open-mmlab/mmsegmentation/pull/445))
|
||||
|
||||
### V0.11 (02/02/2021)
|
||||
|
||||
**Highlights**
|
||||
|
||||
- Support memory efficient test, add more UNet models.
|
||||
|
||||
**Bug Fixes**
|
||||
|
||||
- Fixed TTA resize scale ([#334](https://github.com/open-mmlab/mmsegmentation/pull/334))
|
||||
- Fixed CI for pip 20.3 ([#307](https://github.com/open-mmlab/mmsegmentation/pull/307))
|
||||
- Fixed ADE20k test ([#359](https://github.com/open-mmlab/mmsegmentation/pull/359))
|
||||
|
||||
**New Features**
|
||||
|
||||
- Support memory efficient test ([#330](https://github.com/open-mmlab/mmsegmentation/pull/330))
|
||||
- Add more UNet benchmarks ([#324](https://github.com/open-mmlab/mmsegmentation/pull/324))
|
||||
- Support Lovasz Loss ([#351](https://github.com/open-mmlab/mmsegmentation/pull/351))
|
||||
|
||||
**Improvements**
|
||||
|
||||
- Move train_cfg/test_cfg inside model ([#341](https://github.com/open-mmlab/mmsegmentation/pull/341))
|
||||
|
||||
### V0.10 (01/01/2021)
|
||||
|
||||
**Highlights**
|
||||
|
||||
- Support MobileNetV3, DMNet, APCNet. Add models of ResNet18V1b, ResNet18V1c, ResNet50V1b.
|
||||
|
||||
**Bug Fixes**
|
||||
|
||||
- Fixed CPU TTA ([#276](https://github.com/open-mmlab/mmsegmentation/pull/276))
|
||||
- Fixed CI for pip 20.3 ([#307](https://github.com/open-mmlab/mmsegmentation/pull/307))
|
||||
|
||||
**New Features**
|
||||
|
||||
- Add ResNet18V1b, ResNet18V1c, ResNet50V1b, ResNet101V1b models ([#316](https://github.com/open-mmlab/mmsegmentation/pull/316))
|
||||
- Support MobileNetV3 ([#268](https://github.com/open-mmlab/mmsegmentation/pull/268))
|
||||
- Add 4 retinal vessel segmentation benchmark ([#315](https://github.com/open-mmlab/mmsegmentation/pull/315))
|
||||
- Support DMNet ([#313](https://github.com/open-mmlab/mmsegmentation/pull/313))
|
||||
- Support APCNet ([#299](https://github.com/open-mmlab/mmsegmentation/pull/299))
|
||||
|
||||
**Improvements**
|
||||
|
||||
- Refactor Documentation page ([#311](https://github.com/open-mmlab/mmsegmentation/pull/311))
|
||||
- Support resize data augmentation according to original image size ([#291](https://github.com/open-mmlab/mmsegmentation/pull/291))
|
||||
|
||||
### V0.9 (30/11/2020)
|
||||
|
||||
**Highlights**
|
||||
|
||||
- Support 4 medical dataset, UNet and CGNet.
|
||||
|
||||
**New Features**
|
||||
|
||||
- Support RandomRotate transform ([#215](https://github.com/open-mmlab/mmsegmentation/pull/215), [#260](https://github.com/open-mmlab/mmsegmentation/pull/260))
|
||||
- Support RGB2Gray transform ([#227](https://github.com/open-mmlab/mmsegmentation/pull/227))
|
||||
- Support Rerange transform ([#228](https://github.com/open-mmlab/mmsegmentation/pull/228))
|
||||
- Support ignore_index for BCE loss ([#210](https://github.com/open-mmlab/mmsegmentation/pull/210))
|
||||
- Add modelzoo statistics ([#263](https://github.com/open-mmlab/mmsegmentation/pull/263))
|
||||
- Support Dice evaluation metric ([#225](https://github.com/open-mmlab/mmsegmentation/pull/225))
|
||||
- Support Adjust Gamma transform ([#232](https://github.com/open-mmlab/mmsegmentation/pull/232))
|
||||
- Support CLAHE transform ([#229](https://github.com/open-mmlab/mmsegmentation/pull/229))
|
||||
|
||||
**Bug Fixes**
|
||||
|
||||
- Fixed detail API link ([#267](https://github.com/open-mmlab/mmsegmentation/pull/267))
|
||||
|
||||
### V0.8 (03/11/2020)
|
||||
|
||||
**Highlights**
|
||||
|
||||
- Support 4 medical dataset, UNet and CGNet.
|
||||
|
||||
**New Features**
|
||||
|
||||
- Support customize runner ([#118](https://github.com/open-mmlab/mmsegmentation/pull/118))
|
||||
- Support UNet ([#161](https://github.com/open-mmlab/mmsegmentation/pull/162))
|
||||
- Support CHASE_DB1, DRIVE, STARE, HRD ([#203](https://github.com/open-mmlab/mmsegmentation/pull/203))
|
||||
- Support CGNet ([#223](https://github.com/open-mmlab/mmsegmentation/pull/223))
|
||||
|
||||
### V0.7 (07/10/2020)
|
||||
|
||||
**Highlights**
|
||||
|
||||
- Support Pascal Context dataset and customizing class dataset.
|
||||
|
||||
**Bug Fixes**
|
||||
|
||||
- Fixed CPU inference ([#153](https://github.com/open-mmlab/mmsegmentation/pull/153))
|
||||
|
||||
**New Features**
|
||||
|
||||
- Add DeepLab OS16 models ([#154](https://github.com/open-mmlab/mmsegmentation/pull/154))
|
||||
- Support Pascal Context dataset ([#133](https://github.com/open-mmlab/mmsegmentation/pull/133))
|
||||
- Support customizing dataset classes ([#71](https://github.com/open-mmlab/mmsegmentation/pull/71))
|
||||
- Support customizing dataset palette ([#157](https://github.com/open-mmlab/mmsegmentation/pull/157))
|
||||
|
||||
**Improvements**
|
||||
|
||||
- Support 4D tensor output in ONNX ([#150](https://github.com/open-mmlab/mmsegmentation/pull/150))
|
||||
- Remove redundancies in ONNX export ([#160](https://github.com/open-mmlab/mmsegmentation/pull/160))
|
||||
- Migrate to MMCV DepthwiseSeparableConv ([#158](https://github.com/open-mmlab/mmsegmentation/pull/158))
|
||||
- Migrate to MMCV collect_env ([#137](https://github.com/open-mmlab/mmsegmentation/pull/137))
|
||||
- Use img_prefix and seg_prefix for loading ([#153](https://github.com/open-mmlab/mmsegmentation/pull/153))
|
||||
|
||||
### V0.6 (10/09/2020)
|
||||
|
||||
**Highlights**
|
||||
|
||||
- Support new methods i.e. MobileNetV2, EMANet, DNL, PointRend, Semantic FPN, Fast-SCNN, ResNeSt.
|
||||
|
||||
**Bug Fixes**
|
||||
|
||||
- Fixed sliding inference ONNX export ([#90](https://github.com/open-mmlab/mmsegmentation/pull/90))
|
||||
|
||||
**New Features**
|
||||
|
||||
- Support MobileNet v2 ([#86](https://github.com/open-mmlab/mmsegmentation/pull/86))
|
||||
- Support EMANet ([#34](https://github.com/open-mmlab/mmsegmentation/pull/34))
|
||||
- Support DNL ([#37](https://github.com/open-mmlab/mmsegmentation/pull/37))
|
||||
- Support PointRend ([#109](https://github.com/open-mmlab/mmsegmentation/pull/109))
|
||||
- Support Semantic FPN ([#94](https://github.com/open-mmlab/mmsegmentation/pull/94))
|
||||
- Support Fast-SCNN ([#58](https://github.com/open-mmlab/mmsegmentation/pull/58))
|
||||
- Support ResNeSt backbone ([#47](https://github.com/open-mmlab/mmsegmentation/pull/47))
|
||||
- Support ONNX export (experimental) ([#12](https://github.com/open-mmlab/mmsegmentation/pull/12))
|
||||
|
||||
**Improvements**
|
||||
|
||||
- Support Upsample in ONNX ([#100](https://github.com/open-mmlab/mmsegmentation/pull/100))
|
||||
- Support Windows install (experimental) ([#75](https://github.com/open-mmlab/mmsegmentation/pull/75))
|
||||
- Add more OCRNet results ([#20](https://github.com/open-mmlab/mmsegmentation/pull/20))
|
||||
- Add PyTorch 1.6 CI ([#64](https://github.com/open-mmlab/mmsegmentation/pull/64))
|
||||
- Get version and githash automatically ([#55](https://github.com/open-mmlab/mmsegmentation/pull/55))
|
||||
|
||||
### v0.5.1 (11/08/2020)
|
||||
|
||||
**Highlights**
|
||||
|
||||
- Support FP16 and more generalized OHEM
|
||||
|
||||
**Bug Fixes**
|
||||
|
||||
- Fixed Pascal VOC conversion script (#19)
|
||||
- Fixed OHEM weight assign bug (#54)
|
||||
- Fixed palette type when palette is not given (#27)
|
||||
|
||||
**New Features**
|
||||
|
||||
- Support FP16 (#21)
|
||||
- Generalized OHEM (#54)
|
||||
|
||||
**Improvements**
|
||||
|
||||
- Add load-from flag (#33)
|
||||
- Fixed training tricks doc about different learning rates of model (#26)
|
||||
132
Seg_All_In_One_MMSeg/docs/en/notes/faq.md
Normal file
132
Seg_All_In_One_MMSeg/docs/en/notes/faq.md
Normal file
@@ -0,0 +1,132 @@
|
||||
# Frequently Asked Questions (FAQ)
|
||||
|
||||
We list some common troubles faced by many users and their corresponding solutions here. Feel free to enrich the list if you find any frequent issues and have ways to help others to solve them. If the contents here do not cover your issue, please create an issue using the [provided templates](https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/.github/ISSUE_TEMPLATE/error-report.md/) and make sure you fill in all required information in the template.
|
||||
|
||||
## Installation
|
||||
|
||||
The compatible MMSegmentation, MMCV and MMEngine versions are as below. Please install the correct versions of them to avoid installation issues.
|
||||
|
||||
| MMSegmentation version | MMCV version | MMEngine version | MMClassification (optional) version | MMDetection (optional) version |
|
||||
| :--------------------: | :----------------------------: | :---------------: | :---------------------------------: | :----------------------------: |
|
||||
| dev-1.x branch | mmcv >= 2.0.0 | MMEngine >= 0.7.4 | mmpretrain>=1.0.0rc7 | mmdet >= 3.0.0 |
|
||||
| main branch | mmcv >= 2.0.0 | MMEngine >= 0.7.4 | mmpretrain>=1.0.0rc7 | mmdet >= 3.0.0 |
|
||||
| 1.2.2 | mmcv >= 2.0.0 | MMEngine >= 0.7.4 | mmpretrain>=1.0.0rc7 | mmdet >= 3.0.0 |
|
||||
| 1.2.1 | mmcv >= 2.0.0 | MMEngine >= 0.7.4 | mmpretrain>=1.0.0rc7 | mmdet >= 3.0.0 |
|
||||
| 1.2.0 | mmcv >= 2.0.0 | MMEngine >= 0.7.4 | mmpretrain>=1.0.0rc7 | mmdet >= 3.0.0 |
|
||||
| 1.1.2 | mmcv >= 2.0.0 | MMEngine >= 0.7.4 | mmpretrain>=1.0.0rc7 | mmdet >= 3.0.0 |
|
||||
| 1.1.1 | mmcv >= 2.0.0 | MMEngine >= 0.7.4 | mmpretrain>=1.0.0rc7 | mmdet >= 3.0.0 |
|
||||
| 1.1.0 | mmcv >= 2.0.0 | MMEngine >= 0.7.4 | mmpretrain>=1.0.0rc7 | mmdet >= 3.0.0 |
|
||||
| 1.0.0 | mmcv >= 2.0.0rc4 | MMEngine >= 0.7.1 | mmcls==1.0.0rc6 | mmdet >= 3.0.0 |
|
||||
| 1.0.0rc6 | mmcv >= 2.0.0rc4 | MMEngine >= 0.5.0 | mmcls>=1.0.0rc0 | mmdet >= 3.0.0rc6 |
|
||||
| 1.0.0rc5 | mmcv >= 2.0.0rc4 | MMEngine >= 0.2.0 | mmcls>=1.0.0rc0 | mmdet>=3.0.0rc6 |
|
||||
| 1.0.0rc4 | mmcv == 2.0.0rc3 | MMEngine >= 0.1.0 | mmcls>=1.0.0rc0 | mmdet>=3.0.0rc4, \<=3.0.0rc5 |
|
||||
| 1.0.0rc3 | mmcv == 2.0.0rc3 | MMEngine >= 0.1.0 | mmcls>=1.0.0rc0 | mmdet>=3.0.0rc4, \<=3.0.0rc5 |
|
||||
| 1.0.0rc2 | mmcv == 2.0.0rc3 | MMEngine >= 0.1.0 | mmcls>=1.0.0rc0 | mmdet>=3.0.0rc4, \<=3.0.0rc5 |
|
||||
| 1.0.0rc1 | mmcv >= 2.0.0rc1, \<=2.0.0rc3> | MMEngine >= 0.1.0 | mmcls>=1.0.0rc0 | Not required |
|
||||
| 1.0.0rc0 | mmcv >= 2.0.0rc1, \<=2.0.0rc3> | MMEngine >= 0.1.0 | mmcls>=1.0.0rc0 | Not required |
|
||||
|
||||
Notes:
|
||||
|
||||
- MMClassification and MMDetatction are optional for MMSegmentation. If you didn't install them, `ConvNeXt` (required MMClassification) and MaskFormer, Mask2Former (required MMDetection) cannot be used. We recommend to install them with source code. Please refer to [MMClasssication](https://github.com/open-mmlab/mmclassification) and [MMDetection](https://github.com/open-mmlab/mmdetection) for more details about their installation.
|
||||
|
||||
- To install MMSegmentation 0.x and master branch, please refer to [the faq 0.x document](https://mmsegmentation.readthedocs.io/en/latest/faq.html#installation) to check compatible versions of MMCV.
|
||||
|
||||
- If you have installed an incompatible version of mmcv, please run `pip uninstall mmcv` to uninstall the installed mmcv first. If you have previously installed mmcv-full (which exists in OpenMMLab 1.x), please run `pip uninstall mmcv-full` to uninstall it.
|
||||
|
||||
- If "No module named 'mmcv'" appears, please follow the steps below;
|
||||
|
||||
1. Use `pip uninstall mmcv` to uninstall the existing mmcv in the environment.
|
||||
2. Install the corresponding mmcv according to the [installation instructions](https://mmsegmentation.readthedocs.io/en/dev-1.x/get_started.html#best-practices).
|
||||
|
||||
## How to know the number of GPUs needed to train the model
|
||||
|
||||
- Infer from the name of the config file of the model. You can refer to the `Config Name Style` part of [Learn about Configs](../user_guides/1_config.md). For example, for config file with name `segformer_mit-b0_8xb1-160k_cityscapes-1024x1024.py`, `8xb1` means training the model corresponding to it needs 8 GPUs, and the batch size of each GPU is 1.
|
||||
- Infer from the log file. Open the log file of the model and search `nGPU` in the file. The number of figures following `nGPU` is the number of GPUs needed to train the model. For instance, searching for `nGPU` in the log file yields the record `nGPU 0,1,2,3,4,5,6,7`, which indicates that eight GPUs are needed to train the model.
|
||||
|
||||
## What does the auxiliary head mean
|
||||
|
||||
Briefly, it is a deep supervision trick to improve the accuracy. In the training phase, `decode_head` is for decoding semantic segmentation output, `auxiliary_head` is just adding an auxiliary loss, the segmentation result produced by it has no impact to your model's result, it just works in training. You may read this [paper](https://arxiv.org/pdf/1612.01105.pdf) for more information.
|
||||
|
||||
## How to output the segmentation mask image when running the test script
|
||||
|
||||
In the test script, we provide `--out` argument to control whether output the painted images. Users might run the following command:
|
||||
|
||||
```shell
|
||||
python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} --out ${OUTPUT_DIR}
|
||||
```
|
||||
|
||||
## How to handle binary segmentation task
|
||||
|
||||
MMSegmentation uses `num_classes` and `out_channels` to control output of last layer `self.conv_seg`. More details could be found [here](https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/mmseg/models/decode_heads/decode_head.py).
|
||||
|
||||
`num_classes` should be the same as number of types of labels, in binary segmentation task, dataset only has two types of labels: foreground and background, so `num_classes=2`. `out_channels` controls the output channel of last layer of model, it usually equals to `num_classes`.
|
||||
But in binary segmentation task, there are two solutions:
|
||||
|
||||
- Set `out_channels=2`, using Cross Entropy Loss in training, using `F.softmax()` and `argmax()` to get prediction of each pixel in inference.
|
||||
|
||||
- Set `out_channels=1`, using Binary Cross Entropy Loss in training, using `F.sigmoid()` and `threshold` to get prediction of each pixel in inference. `threshold` is set 0.3 as default.
|
||||
|
||||
In summary, to implement binary segmentation methods users should modify below parameters in the `decode_head` and `auxiliary_head` configs. Here is a modification example of [pspnet_unet_s5-d16.py](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/_base_/models/pspnet_unet_s5-d16.py):
|
||||
|
||||
- (1) `num_classes=2`, `out_channels=2` and `use_sigmoid=False` in `CrossEntropyLoss`.
|
||||
|
||||
```python
|
||||
decode_head=dict(
|
||||
type='PSPHead',
|
||||
in_channels=64,
|
||||
in_index=4,
|
||||
num_classes=2,
|
||||
out_channels=2,
|
||||
loss_decode=dict(
|
||||
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
|
||||
auxiliary_head=dict(
|
||||
type='FCNHead',
|
||||
in_channels=128,
|
||||
in_index=3,
|
||||
num_classes=2,
|
||||
out_channels=2,
|
||||
loss_decode=dict(
|
||||
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)),
|
||||
```
|
||||
|
||||
- (2) `num_classes=2`, `out_channels=1` and `use_sigmoid=True` in `CrossEntropyLoss`.
|
||||
|
||||
```python
|
||||
decode_head=dict(
|
||||
type='PSPHead',
|
||||
in_channels=64,
|
||||
in_index=4,
|
||||
num_classes=2,
|
||||
out_channels=1,
|
||||
loss_decode=dict(
|
||||
type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0)),
|
||||
auxiliary_head=dict(
|
||||
type='FCNHead',
|
||||
in_channels=128,
|
||||
in_index=3,
|
||||
num_classes=2,
|
||||
out_channels=1,
|
||||
loss_decode=dict(
|
||||
type='CrossEntropyLoss', use_sigmoid=True, loss_weight=0.4)),
|
||||
```
|
||||
|
||||
## Functionality of `reduce_zero_label`
|
||||
|
||||
The parameter type of `reduce_zero_label` in dataset is Boolean, which is default to False. It is used to ignore the dataset label 0. The specific method is to change label 0 to 255, and subtract 1 from the corresponding number of all the remaining labels. At the same time, set 255 as ignore index in the decode head, which means that it will not participate in the loss calculation.
|
||||
|
||||
Following is the specific implementation logic of `reduce_zero_label`:
|
||||
|
||||
```python
|
||||
if self.reduce_zero_label:
|
||||
# avoid using underflow conversion
|
||||
gt_semantic_seg[gt_semantic_seg == 0] = 255
|
||||
gt_semantic_seg = gt_semantic_seg - 1
|
||||
gt_semantic_seg[gt_semantic_seg == 254] = 255
|
||||
```
|
||||
|
||||
Whether your dataset needs to use `reduce_zero_label`, there are two types of situations:
|
||||
|
||||
- On [Potsdam](https://github.com/open-mmlab/mmsegmentation/blob/1.x/docs/en/user_guides/2_dataset_prepare.md#isprs-potsdam) dataset, there are six classes: 0-Impervious surfaces, 1-Building, 2-Low vegetation, 3-Tree, 4-Car, 5-Clutter/background. However, this dataset provides two types of RGB labels, one with black pixels at the edges of the images, and the other without. For labels with black edges, in [dataset_converters.py](https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/tools/dataset_converters/potsdam.py), it converts the black edges to label 0, and the other labels are 1-Impervious surfaces, 2-Building, 3-Low vegetation, 4-Tree, 5-Car, 6-Clutter/background. Therefore, in the dataset config [potsdam.py](https://github.com/open-mmlab/mmsegmentation/blob/ff95416c3b5ce8d62b9289f743531398efce534f/mmseg/datasets/potsdam.py#L23) `reduce_zero_label=True`。 If you are using labels without black edges, then there are only class 0-5 in the mask label. At this point, you should use `reduce_zero_label=False`. `reduce_zero_label` usage needs to be considered with your actual situation.
|
||||
- On a dataset with class 0 as the background class, if you need to separate the background from the rest of your classes ultimately then you do not need to use `reduce_zero_label`, which in the dataset config settings should be `reduce_zero_label=False`
|
||||
|
||||
**Note:** Please confirm the number of original classes in the dataset. If there are only two classes, you should not use `reduce_zero_label` which is `reduce_zero_label=False`.
|
||||
85
Seg_All_In_One_MMSeg/docs/en/overview.md
Normal file
85
Seg_All_In_One_MMSeg/docs/en/overview.md
Normal file
@@ -0,0 +1,85 @@
|
||||
# Overview
|
||||
|
||||
This chapter introduces you to the framework of MMSegmentation, and the basic conception of semantic segmentation. It also provides links to detailed tutorials about MMSegmentation.
|
||||
|
||||
## What is semantic segmentation?
|
||||
|
||||
Semantic segmentation is the task of clustering parts of an image together that belong to the same object class.
|
||||
It is a form of pixel-level prediction because each pixel in an image is classified according to a category.
|
||||
Some example benchmarks for this task are [Cityscapes](https://www.cityscapes-dataset.com/benchmarks/), [PASCAL VOC](http://host.robots.ox.ac.uk/pascal/VOC/voc2012/) and [ADE20K](https://groups.csail.mit.edu/vision/datasets/ADE20K/).
|
||||
Models are usually evaluated with the Mean Intersection-Over-Union (Mean IoU) and Pixel Accuracy metrics.
|
||||
|
||||
## What is MMSegmentation?
|
||||
|
||||
MMSegmentation is a toolbox that provides a framework for unified implementation and evaluation of semant
|
||||
ic segmentation methods,
|
||||
and contains high-quality implementations of popular semantic segmentation methods and datasets.
|
||||
|
||||
MMSeg consists of 7 main parts including apis, structures, datasets, models, engine, evaluation and visualization.
|
||||
|
||||
- **apis** provides high-level APIs for model inference.
|
||||
|
||||
- **structures** provides segmentation data structure `SegDataSample`.
|
||||
|
||||
- **datasets** supports various datasets for semantic segmentation.
|
||||
|
||||
- **transforms** contains a lot of useful data augmentation transforms.
|
||||
|
||||
- **models** is the most vital part for segmentors and contains different components of a segmentor.
|
||||
|
||||
- **segmentors** defines all of the segmentation model classes.
|
||||
- **data_preprocessors** works for preprocessing the input data of the model.
|
||||
- **backbones** contains various backbone networks that transform an image to feature maps.
|
||||
- **necks** contains various neck components that connect the backbone and heads.
|
||||
- **decode_heads** contains various head components that take feature map as input and predict segmentation results.
|
||||
- **losses** contains various loss functions.
|
||||
|
||||
- **engine** is a part for runtime components that extends function of [MMEngine](https://github.com/open-mmlab/mmengine).
|
||||
|
||||
- **optimizers** provides optimizers and optimizer wrappers.
|
||||
- **hooks** provides various hooks of the runner.
|
||||
|
||||
- **evaluation** provides different metrics for evaluating model performance.
|
||||
|
||||
- **visualization** is for visualizing segmentation results.
|
||||
|
||||
## How to use this documentation
|
||||
|
||||
Here is a detailed step-by-step guide to learn more about MMSegmentation:
|
||||
|
||||
1. For installation instructions, please see [get_started](getting_started.md).
|
||||
|
||||
2. For beginners, MMSegmentation is the best place to start the journey of semantic segmentation
|
||||
as there are many SOTA and classic segmentation [models](model_zoo.md),
|
||||
and it is easier to carry out a segmentation task by plugging together building blocks and convenient high-level apis.
|
||||
Refer to the tutorials below for the basic usage of MMSegmentation:
|
||||
|
||||
- [Config](user_guides/1_config.md)
|
||||
- [Dataset Preparation](user_guides/2_dataset_prepare.md)
|
||||
- [Inference](user_guides/3_inference.md)
|
||||
- [Train and Test](user_guides/4_train_test.md)
|
||||
|
||||
3. If you would like to learn about the fundamental classes and features that make MMSegmentation work,
|
||||
please refer to the tutorials below to dive deeper:
|
||||
|
||||
- [Data flow](advanced_guides/data_flow.md)
|
||||
- [Structures](advanced_guides/structures.md)
|
||||
- [Models](advanced_guides/models.md)
|
||||
- [Datasets](advanced_guides/datasets.md)
|
||||
- [Evaluation](advanced_guides/evaluation.md)
|
||||
|
||||
4. MMSegmentation also provide tutorials for customization and advanced research,
|
||||
please refer to the below guides to build your own segmentation project:
|
||||
|
||||
- [Add new models](advanced_guides/add_models.md)
|
||||
- [Add new datasets](advanced_guides/add_datasets.md)
|
||||
- [Add new transforms](advanced_guides/add_transforms.md)
|
||||
- [Customize runtime](advanced_guides/customize_runtime.md)
|
||||
|
||||
5. If you are more familiar with MMSegmentation v0.x, there is documentation about migration from MMSegmentation v0.x to v1.x
|
||||
|
||||
- [migration](migration/index.rst)
|
||||
|
||||
## References
|
||||
|
||||
- [Paper with code](https://paperswithcode.com/task/semantic-segmentation/codeless#task-home)
|
||||
67
Seg_All_In_One_MMSeg/docs/en/stat.py
Normal file
67
Seg_All_In_One_MMSeg/docs/en/stat.py
Normal file
@@ -0,0 +1,67 @@
|
||||
#!/usr/bin/env python
|
||||
# Copyright (c) OpenMMLab. All rights reserved.
|
||||
import functools as func
|
||||
import glob
|
||||
import os.path as osp
|
||||
import re
|
||||
|
||||
import numpy as np
|
||||
|
||||
url_prefix = 'https://github.com/open-mmlab/mmsegmentation/blob/master/'
|
||||
|
||||
files = sorted(glob.glob('../../configs/*/README.md'))
|
||||
|
||||
stats = []
|
||||
titles = []
|
||||
num_ckpts = 0
|
||||
|
||||
for f in files:
|
||||
url = osp.dirname(f.replace('../../', url_prefix))
|
||||
|
||||
with open(f) as content_file:
|
||||
content = content_file.read()
|
||||
|
||||
title = content.split('\n')[0].replace('#', '').strip()
|
||||
ckpts = {
|
||||
x.lower().strip()
|
||||
for x in re.findall(r'https?://download.*\.pth', content)
|
||||
if 'mmsegmentation' in x
|
||||
}
|
||||
if len(ckpts) == 0:
|
||||
continue
|
||||
|
||||
_papertype = [
|
||||
x for x in re.findall(r'<!--\s*\[([A-Z]*?)\]\s*-->', content)
|
||||
]
|
||||
assert len(_papertype) > 0
|
||||
papertype = _papertype[0]
|
||||
|
||||
paper = {(papertype, title)}
|
||||
|
||||
titles.append(title)
|
||||
num_ckpts += len(ckpts)
|
||||
statsmsg = f"""
|
||||
\t* [{papertype}] [{title}]({url}) ({len(ckpts)} ckpts)
|
||||
"""
|
||||
stats.append((paper, ckpts, statsmsg))
|
||||
|
||||
allpapers = func.reduce(lambda a, b: a.union(b), [p for p, _, _ in stats])
|
||||
msglist = '\n'.join(x for _, _, x in stats)
|
||||
|
||||
papertypes, papercounts = np.unique([t for t, _ in allpapers],
|
||||
return_counts=True)
|
||||
countstr = '\n'.join(
|
||||
[f' - {t}: {c}' for t, c in zip(papertypes, papercounts)])
|
||||
|
||||
modelzoo = f"""
|
||||
# Model Zoo Statistics
|
||||
|
||||
* Number of papers: {len(set(titles))}
|
||||
{countstr}
|
||||
|
||||
* Number of checkpoints: {num_ckpts}
|
||||
{msglist}
|
||||
"""
|
||||
|
||||
with open('modelzoo_statistics.md', 'w') as f:
|
||||
f.write(modelzoo)
|
||||
3
Seg_All_In_One_MMSeg/docs/en/switch_language.md
Normal file
3
Seg_All_In_One_MMSeg/docs/en/switch_language.md
Normal file
@@ -0,0 +1,3 @@
|
||||
## <a href='https://mmsegmentation.readthedocs.io/en/latest/'>English</a>
|
||||
|
||||
## <a href='https://mmsegmentation.readthedocs.io/zh_CN/latest/'>简体中文</a>
|
||||
588
Seg_All_In_One_MMSeg/docs/en/user_guides/1_config.md
Normal file
588
Seg_All_In_One_MMSeg/docs/en/user_guides/1_config.md
Normal file
@@ -0,0 +1,588 @@
|
||||
# Tutorial 1: Learn about Configs
|
||||
|
||||
We incorporate modular and inheritance design into our config system, which is convenient to conduct various experiments.
|
||||
If you wish to inspect the config file, you may run `python tools/misc/print_config.py /PATH/TO/CONFIG` to see the complete config.
|
||||
You may also pass `--cfg-options xxx.yyy=zzz` to see updated config.
|
||||
|
||||
## Config File Structure
|
||||
|
||||
There are 4 basic component types under `config/_base_`, datasets, models, schedules, default_runtime.
|
||||
Many methods could be easily constructed with one of each like DeepLabV3, PSPNet.
|
||||
The configs that are composed by components from `_base_` are called _primitive_.
|
||||
|
||||
For all configs under the same folder, it is recommended to have only **one** _primitive_ config. All other configs should inherit from the _primitive_ config. In this way, the maximum of inheritance level is 3.
|
||||
|
||||
For easy understanding, we recommend contributors to inherit from existing methods.
|
||||
For example, if some modification is made base on DeepLabV3, user may first inherit the basic DeepLabV3 structure by specifying `_base_ = ../deeplabv3/deeplabv3_r50-d8_4xb2-40k_cityscapes-512x1024.py`, then modify the necessary fields in the config files.
|
||||
|
||||
If you are building an entirely new method that does not share the structure with any of the existing methods, you may create a folder `xxxnet` under `configs`,
|
||||
|
||||
Please refer to [mmengine](https://mmengine.readthedocs.io/en/latest/tutorials/config.html) for detailed documentation.
|
||||
|
||||
## Config Name Style
|
||||
|
||||
We follow the below style to name config files. Contributors are advised to follow the same style.
|
||||
|
||||
```text
|
||||
{algorithm name}_{model component names [component1]_[component2]_[...]}_{training settings}_{training dataset information}_{testing dataset information}
|
||||
```
|
||||
|
||||
The file name is divided to five parts. All parts and components are connected with `_` and words of each part or component should be connected with `-`.
|
||||
|
||||
- `{algorithm name}`: The name of the algorithm, such as `deeplabv3`, `pspnet`, etc.
|
||||
- `{model component names}`: Names of the components used in the algorithm such as backbone, head, etc. For example, `r50-d8` means using ResNet50 backbone and use output of backbone is 8 times downsampling as input.
|
||||
- `{training settings}`: Information of training settings such as batch size, augmentations, loss, learning rate scheduler, and epochs/iterations. For example: `4xb4-ce-linearlr-40K` means using 4-gpus x 4-images-per-gpu, CrossEntropy loss, Linear learning rate scheduler, and train 40K iterations.
|
||||
Some abbreviations:
|
||||
- `{gpu x batch_per_gpu}`: GPUs and samples per GPU. `bN` indicates N batch size per GPU. E.g. `8xb2` is the short term of 8-gpus x 2-images-per-gpu. And `4xb4` is used by default if not mentioned.
|
||||
- `{schedule}`: training schedule, options are `20k`, `40k`, etc. `20k` and `40k` means 20000 iterations and 40000 iterations respectively.
|
||||
- `{training dataset information}`: Training dataset names like `cityscapes`, `ade20k`, etc, and input resolutions. For example: `cityscapes-768x768` means training on `cityscapes` dataset and the input shape is `768x768`.
|
||||
- `{testing dataset information}` (optional): Testing dataset name for models trained on one dataset but tested on another. If not mentioned, it means the model was trained and tested on the same dataset type.
|
||||
|
||||
## An Example of PSPNet
|
||||
|
||||
To help the users have a basic idea of a complete config and the modules in a modern semantic segmentation system,
|
||||
we make brief comments on the config of PSPNet using ResNet50V1c as the following.
|
||||
For more detailed usage and the corresponding alternative for each module, please refer to the API documentation.
|
||||
|
||||
```python
|
||||
_base_ = [
|
||||
'../_base_/models/pspnet_r50-d8.py', '../_base_/datasets/cityscapes.py',
|
||||
'../_base_/default_runtime.py', '../_base_/schedules/schedule_40k.py'
|
||||
] # base config file which we build new config file on.
|
||||
crop_size = (512, 1024)
|
||||
data_preprocessor = dict(size=crop_size)
|
||||
model = dict(data_preprocessor=data_preprocessor)
|
||||
```
|
||||
|
||||
`_base_/models/pspnet_r50-d8.py` is a basic model cfg file for PSPNet using ResNet50V1c
|
||||
|
||||
```python
|
||||
# model settings
|
||||
norm_cfg = dict(type='SyncBN', requires_grad=True) # Segmentation usually uses SyncBN
|
||||
data_preprocessor = dict( # The config of data preprocessor, usually includes image normalization and augmentation.
|
||||
type='SegDataPreProcessor', # The type of data preprocessor.
|
||||
mean=[123.675, 116.28, 103.53], # Mean values used for normalizing the input images.
|
||||
std=[58.395, 57.12, 57.375], # Standard variance used for normalizing the input images.
|
||||
bgr_to_rgb=True, # Whether to convert image from BGR to RGB.
|
||||
pad_val=0, # Padding value of image.
|
||||
seg_pad_val=255) # Padding value of segmentation map.
|
||||
model = dict(
|
||||
type='EncoderDecoder', # Name of segmentor
|
||||
data_preprocessor=data_preprocessor,
|
||||
pretrained='open-mmlab://resnet50_v1c', # The ImageNet pretrained backbone to be loaded
|
||||
backbone=dict(
|
||||
type='ResNetV1c', # The type of backbone. Please refer to mmseg/models/backbones/resnet.py for details.
|
||||
depth=50, # Depth of backbone. Normally 50, 101 are used.
|
||||
num_stages=4, # Number of stages of backbone.
|
||||
out_indices=(0, 1, 2, 3), # The index of output feature maps produced in each stages.
|
||||
dilations=(1, 1, 2, 4), # The dilation rate of each layer.
|
||||
strides=(1, 2, 1, 1), # The stride of each layer.
|
||||
norm_cfg=norm_cfg, # The configuration of norm layer.
|
||||
norm_eval=False, # Whether to freeze the statistics in BN
|
||||
style='pytorch', # The style of backbone, 'pytorch' means that stride 2 layers are in 3x3 conv, 'caffe' means stride 2 layers are in 1x1 convs.
|
||||
contract_dilation=True), # When dilation > 1, whether contract first layer of dilation.
|
||||
decode_head=dict(
|
||||
type='PSPHead', # Type of decode head. Please refer to mmseg/models/decode_heads for available options.
|
||||
in_channels=2048, # Input channel of decode head.
|
||||
in_index=3, # The index of feature map to select.
|
||||
channels=512, # The intermediate channels of decode head.
|
||||
pool_scales=(1, 2, 3, 6), # The avg pooling scales of PSPHead. Please refer to paper for details.
|
||||
dropout_ratio=0.1, # The dropout ratio before final classification layer.
|
||||
num_classes=19, # Number of segmentation class. Usually 19 for cityscapes, 21 for VOC, 150 for ADE20k.
|
||||
norm_cfg=norm_cfg, # The configuration of norm layer.
|
||||
align_corners=False, # The align_corners argument for resize in decoding.
|
||||
loss_decode=dict( # Config of loss function for the decode_head.
|
||||
type='CrossEntropyLoss', # Type of loss used for segmentation.
|
||||
use_sigmoid=False, # Whether use sigmoid activation for segmentation.
|
||||
loss_weight=1.0)), # Loss weight of decode_head.
|
||||
auxiliary_head=dict(
|
||||
type='FCNHead', # Type of auxiliary head. Please refer to mmseg/models/decode_heads for available options.
|
||||
in_channels=1024, # Input channel of auxiliary head.
|
||||
in_index=2, # The index of feature map to select.
|
||||
channels=256, # The intermediate channels of decode head.
|
||||
num_convs=1, # Number of convs in FCNHead. It is usually 1 in auxiliary head.
|
||||
concat_input=False, # Whether concat output of convs with input before classification layer.
|
||||
dropout_ratio=0.1, # The dropout ratio before final classification layer.
|
||||
num_classes=19, # Number of segmentation class. Usually 19 for cityscapes, 21 for VOC, 150 for ADE20k.
|
||||
norm_cfg=norm_cfg, # The configuration of norm layer.
|
||||
align_corners=False, # The align_corners argument for resize in decoding.
|
||||
loss_decode=dict( # Config of loss function for the auxiliary_head.
|
||||
type='CrossEntropyLoss', # Type of loss used for segmentation.
|
||||
use_sigmoid=False, # Whether use sigmoid activation for segmentation.
|
||||
loss_weight=0.4)), # Loss weight of auxiliary_head.
|
||||
# model training and testing settings
|
||||
train_cfg=dict(), # train_cfg is just a place holder for now.
|
||||
test_cfg=dict(mode='whole')) # The test mode, options are 'whole' and 'slide'. 'whole': whole image fully-convolutional test. 'slide': sliding crop window on the image.
|
||||
```
|
||||
|
||||
`_base_/datasets/cityscapes.py` is the configuration file of the dataset
|
||||
|
||||
```python
|
||||
# dataset settings
|
||||
dataset_type = 'CityscapesDataset' # Dataset type, this will be used to define the dataset.
|
||||
data_root = 'data/cityscapes/' # Root path of data.
|
||||
crop_size = (512, 1024) # The crop size during training.
|
||||
train_pipeline = [ # Training pipeline.
|
||||
dict(type='LoadImageFromFile'), # First pipeline to load images from file path.
|
||||
dict(type='LoadAnnotations'), # Second pipeline to load annotations for current image.
|
||||
dict(type='RandomResize', # Augmentation pipeline that resize the images and their annotations.
|
||||
scale=(2048, 1024), # The scale of image.
|
||||
ratio_range=(0.5, 2.0), # The augmented scale range as ratio.
|
||||
keep_ratio=True), # Whether to keep the aspect ratio when resizing the image.
|
||||
dict(type='RandomCrop', # Augmentation pipeline that randomly crop a patch from current image.
|
||||
crop_size=crop_size, # The crop size of patch.
|
||||
cat_max_ratio=0.75), # The max area ratio that could be occupied by single category.
|
||||
dict(type='RandomFlip', # Augmentation pipeline that flip the images and their annotations
|
||||
prob=0.5), # The ratio or probability to flip
|
||||
dict(type='PhotoMetricDistortion'), # Augmentation pipeline that distort current image with several photo metric methods.
|
||||
dict(type='PackSegInputs') # Pack the inputs data for the semantic segmentation.
|
||||
]
|
||||
test_pipeline = [
|
||||
dict(type='LoadImageFromFile'), # First pipeline to load images from file path
|
||||
dict(type='Resize', # Use resize augmentation
|
||||
scale=(2048, 1024), # Images scales for resizing.
|
||||
keep_ratio=True), # Whether to keep the aspect ratio when resizing the image.
|
||||
# add loading annotation after ``Resize`` because ground truth
|
||||
# does not need to do resize data transform
|
||||
dict(type='LoadAnnotations'), # Load annotations for semantic segmentation provided by dataset.
|
||||
dict(type='PackSegInputs') # Pack the inputs data for the semantic segmentation.
|
||||
]
|
||||
train_dataloader = dict( # Train dataloader config
|
||||
batch_size=2, # Batch size of a single GPU
|
||||
num_workers=2, # Worker to pre-fetch data for each single GPU
|
||||
persistent_workers=True, # Shut down the worker processes after an epoch end, which can accelerate training speed.
|
||||
sampler=dict(type='InfiniteSampler', shuffle=True), # Randomly shuffle during training.
|
||||
dataset=dict( # Train dataset config
|
||||
type=dataset_type, # Type of dataset, refer to mmseg/datasets/ for details.
|
||||
data_root=data_root, # The root of dataset.
|
||||
data_prefix=dict(
|
||||
img_path='leftImg8bit/train', seg_map_path='gtFine/train'), # Prefix for training data.
|
||||
pipeline=train_pipeline)) # Processing pipeline. This is passed by the train_pipeline created before.
|
||||
val_dataloader = dict(
|
||||
batch_size=1, # Batch size of a single GPU
|
||||
num_workers=4, # Worker to pre-fetch data for each single GPU
|
||||
persistent_workers=True, # Shut down the worker processes after an epoch end, which can accelerate testing speed.
|
||||
sampler=dict(type='DefaultSampler', shuffle=False), # Not shuffle during validation and testing.
|
||||
dataset=dict( # Test dataset config
|
||||
type=dataset_type, # Type of dataset, refer to mmseg/datasets/ for details.
|
||||
data_root=data_root, # The root of dataset.
|
||||
data_prefix=dict(
|
||||
img_path='leftImg8bit/val', seg_map_path='gtFine/val'), # Prefix for testing data.
|
||||
pipeline=test_pipeline)) # Processing pipeline. This is passed by the test_pipeline created before.
|
||||
test_dataloader = val_dataloader
|
||||
# The metric to measure the accuracy. Here, we use IoUMetric.
|
||||
val_evaluator = dict(type='IoUMetric', iou_metrics=['mIoU'])
|
||||
test_evaluator = val_evaluator
|
||||
```
|
||||
|
||||
`_base_/schedules/schedule_40k.py`
|
||||
|
||||
```python
|
||||
# optimizer
|
||||
optimizer = dict(type='SGD', # Type of optimizers, refer to https://github.com/open-mmlab/mmengine/blob/main/mmengine/optim/optimizer/default_constructor.py for more details
|
||||
lr=0.01, # Learning rate of optimizers, see detail usages of the parameters in the documentation of PyTorch
|
||||
momentum=0.9, # Momentum
|
||||
weight_decay=0.0005) # Weight decay of SGD
|
||||
optim_wrapper = dict(type='OptimWrapper', # Optimizer wrapper provides a common interface for updating parameters.
|
||||
optimizer=optimizer, # Optimizer used to update model parameters.
|
||||
clip_grad=None) # If ``clip_grad`` is not None, it will be the arguments of ``torch.nn.utils.clip_grad``.
|
||||
# learning policy
|
||||
param_scheduler = [
|
||||
dict(
|
||||
type='PolyLR', # The policy of scheduler, also support Step, CosineAnnealing, Cyclic, etc. Refer to details of supported LrUpdater from https://github.com/open-mmlab/mmengine/blob/main/mmengine/optim/scheduler/lr_scheduler.py
|
||||
eta_min=1e-4, # Minimum learning rate at the end of scheduling.
|
||||
power=0.9, # The power of polynomial decay.
|
||||
begin=0, # Step at which to start updating the parameters.
|
||||
end=40000, # Step at which to stop updating the parameters.
|
||||
by_epoch=False) # Whether count by epoch or not.
|
||||
]
|
||||
# training schedule for 40k iteration
|
||||
train_cfg = dict(type='IterBasedTrainLoop', max_iters=40000, val_interval=4000)
|
||||
val_cfg = dict(type='ValLoop')
|
||||
test_cfg = dict(type='TestLoop')
|
||||
# default hooks
|
||||
default_hooks = dict(
|
||||
timer=dict(type='IterTimerHook'), # Log the time spent during iteration.
|
||||
logger=dict(type='LoggerHook', interval=50, log_metric_by_epoch=False), # Collect and write logs from different components of ``Runner``.
|
||||
param_scheduler=dict(type='ParamSchedulerHook'), # update some hyper-parameters in optimizer, e.g., learning rate.
|
||||
checkpoint=dict(type='CheckpointHook', by_epoch=False, interval=4000), # Save checkpoints periodically.
|
||||
sampler_seed=dict(type='DistSamplerSeedHook')) # Data-loading sampler for distributed training.
|
||||
```
|
||||
|
||||
in `_base_/default_runtime.py`
|
||||
|
||||
```python
|
||||
# Set the default scope of the registry to mmseg.
|
||||
default_scope = 'mmseg'
|
||||
# environment
|
||||
env_cfg = dict(
|
||||
cudnn_benchmark=True,
|
||||
mp_cfg=dict(mp_start_method='fork', opencv_num_threads=0),
|
||||
dist_cfg=dict(backend='nccl'),
|
||||
)
|
||||
log_level = 'INFO'
|
||||
log_processor = dict(by_epoch=False)
|
||||
load_from = None # Load checkpoint from file.
|
||||
resume = False # Whether to resume from existed model.
|
||||
```
|
||||
|
||||
These are all the configs for training and testing PSPNet, to load and parse them, we can use [Config](https://mmengine.readthedocs.io/en/latest/tutorials/config.html) implemented in [MMEngine](https://github.com/open-mmlab/mmengine)
|
||||
|
||||
```python
|
||||
from mmengine.config import Config
|
||||
|
||||
cfg = Config.fromfile('configs/pspnet/pspnet_r50-d8_4xb2-40k_cityscapes-512x1024.py')
|
||||
print(cfg.train_dataloader)
|
||||
```
|
||||
|
||||
```shell
|
||||
{'batch_size': 2,
|
||||
'num_workers': 2,
|
||||
'persistent_workers': True,
|
||||
'sampler': {'type': 'InfiniteSampler', 'shuffle': True},
|
||||
'dataset': {'type': 'CityscapesDataset',
|
||||
'data_root': 'data/cityscapes/',
|
||||
'data_prefix': {'img_path': 'leftImg8bit/train',
|
||||
'seg_map_path': 'gtFine/train'},
|
||||
'pipeline': [{'type': 'LoadImageFromFile'},
|
||||
{'type': 'LoadAnnotations'},
|
||||
{'type': 'RandomResize',
|
||||
'scale': (2048, 1024),
|
||||
'ratio_range': (0.5, 2.0),
|
||||
'keep_ratio': True},
|
||||
{'type': 'RandomCrop', 'crop_size': (512, 1024), 'cat_max_ratio': 0.75},
|
||||
{'type': 'RandomFlip', 'prob': 0.5},
|
||||
{'type': 'PhotoMetricDistortion'},
|
||||
{'type': 'PackSegInputs'}]}}
|
||||
```
|
||||
|
||||
`cfg` is an instance of `mmengine.config.Config`, its interface is the same as a dict object and also allows access config values as attributes. See [config tutorial](https://mmengine.readthedocs.io/en/latest/tutorials/config.html) in [MMEngine](https://github.com/open-mmlab/mmengine) for more information.
|
||||
|
||||
## FAQ
|
||||
|
||||
### Ignore some fields in the base configs
|
||||
|
||||
Sometimes, you may set `_delete_=True` to ignore some of the fields in base configs.
|
||||
See [config tutorial](https://mmengine.readthedocs.io/en/latest/tutorials/config.html) in [MMEngine](https://github.com/open-mmlab/mmengine) for simple illustration.
|
||||
|
||||
In MMSegmentation, for example, if you would like to modify the backbone of PSPNet with the following config file `pspnet.py`:
|
||||
|
||||
```python
|
||||
norm_cfg = dict(type='SyncBN', requires_grad=True)
|
||||
model = dict(
|
||||
type='EncoderDecoder',
|
||||
pretrained='torchvision://resnet50',
|
||||
backbone=dict(
|
||||
type='ResNetV1c',
|
||||
depth=50,
|
||||
num_stages=4,
|
||||
out_indices=(0, 1, 2, 3),
|
||||
dilations=(1, 1, 2, 4),
|
||||
strides=(1, 2, 1, 1),
|
||||
norm_cfg=norm_cfg,
|
||||
norm_eval=False,
|
||||
style='pytorch',
|
||||
contract_dilation=True),
|
||||
decode_head=dict(
|
||||
type='PSPHead',
|
||||
in_channels=2048,
|
||||
in_index=3,
|
||||
channels=512,
|
||||
pool_scales=(1, 2, 3, 6),
|
||||
dropout_ratio=0.1,
|
||||
num_classes=19,
|
||||
norm_cfg=norm_cfg,
|
||||
align_corners=False,
|
||||
loss_decode=dict(
|
||||
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)))
|
||||
```
|
||||
|
||||
Load and parse the config file `pspnet.py` in the code as follows:
|
||||
|
||||
```python
|
||||
from mmengine.config import Config
|
||||
|
||||
cfg = Config.fromfile('pspnet.py')
|
||||
print(cfg.model)
|
||||
```
|
||||
|
||||
```shell
|
||||
{'type': 'EncoderDecoder',
|
||||
'pretrained': 'torchvision://resnet50',
|
||||
'backbone': {'type': 'ResNetV1c',
|
||||
'depth': 50,
|
||||
'num_stages': 4,
|
||||
'out_indices': (0, 1, 2, 3),
|
||||
'dilations': (1, 1, 2, 4),
|
||||
'strides': (1, 2, 1, 1),
|
||||
'norm_cfg': {'type': 'SyncBN', 'requires_grad': True},
|
||||
'norm_eval': False,
|
||||
'style': 'pytorch',
|
||||
'contract_dilation': True},
|
||||
'decode_head': {'type': 'PSPHead',
|
||||
'in_channels': 2048,
|
||||
'in_index': 3,
|
||||
'channels': 512,
|
||||
'pool_scales': (1, 2, 3, 6),
|
||||
'dropout_ratio': 0.1,
|
||||
'num_classes': 19,
|
||||
'norm_cfg': {'type': 'SyncBN', 'requires_grad': True},
|
||||
'align_corners': False,
|
||||
'loss_decode': {'type': 'CrossEntropyLoss',
|
||||
'use_sigmoid': False,
|
||||
'loss_weight': 1.0}}}
|
||||
```
|
||||
|
||||
`ResNet` and `HRNet` use different keywords to construct, write a new config file `hrnet.py` as follows:
|
||||
|
||||
```python
|
||||
_base_ = 'pspnet.py'
|
||||
norm_cfg = dict(type='SyncBN', requires_grad=True)
|
||||
model = dict(
|
||||
pretrained='open-mmlab://msra/hrnetv2_w32',
|
||||
backbone=dict(
|
||||
_delete_=True,
|
||||
type='HRNet',
|
||||
norm_cfg=norm_cfg,
|
||||
extra=dict(
|
||||
stage1=dict(
|
||||
num_modules=1,
|
||||
num_branches=1,
|
||||
block='BOTTLENECK',
|
||||
num_blocks=(4, ),
|
||||
num_channels=(64, )),
|
||||
stage2=dict(
|
||||
num_modules=1,
|
||||
num_branches=2,
|
||||
block='BASIC',
|
||||
num_blocks=(4, 4),
|
||||
num_channels=(32, 64)),
|
||||
stage3=dict(
|
||||
num_modules=4,
|
||||
num_branches=3,
|
||||
block='BASIC',
|
||||
num_blocks=(4, 4, 4),
|
||||
num_channels=(32, 64, 128)),
|
||||
stage4=dict(
|
||||
num_modules=3,
|
||||
num_branches=4,
|
||||
block='BASIC',
|
||||
num_blocks=(4, 4, 4, 4),
|
||||
num_channels=(32, 64, 128, 256)))))
|
||||
```
|
||||
|
||||
Load and parse the config file `hrnet.py` in the code as follows:
|
||||
|
||||
```python
|
||||
from mmengine.config import Config
|
||||
cfg = Config.fromfile('hrnet.py')
|
||||
print(cfg.model)
|
||||
```
|
||||
|
||||
```shell
|
||||
{'type': 'EncoderDecoder',
|
||||
'pretrained': 'open-mmlab://msra/hrnetv2_w32',
|
||||
'backbone': {'type': 'HRNet',
|
||||
'norm_cfg': {'type': 'SyncBN', 'requires_grad': True},
|
||||
'extra': {'stage1': {'num_modules': 1,
|
||||
'num_branches': 1,
|
||||
'block': 'BOTTLENECK',
|
||||
'num_blocks': (4,),
|
||||
'num_channels': (64,)},
|
||||
'stage2': {'num_modules': 1,
|
||||
'num_branches': 2,
|
||||
'block': 'BASIC',
|
||||
'num_blocks': (4, 4),
|
||||
'num_channels': (32, 64)},
|
||||
'stage3': {'num_modules': 4,
|
||||
'num_branches': 3,
|
||||
'block': 'BASIC',
|
||||
'num_blocks': (4, 4, 4),
|
||||
'num_channels': (32, 64, 128)},
|
||||
'stage4': {'num_modules': 3,
|
||||
'num_branches': 4,
|
||||
'block': 'BASIC',
|
||||
'num_blocks': (4, 4, 4, 4),
|
||||
'num_channels': (32, 64, 128, 256)}}},
|
||||
'decode_head': {'type': 'PSPHead',
|
||||
'in_channels': 2048,
|
||||
'in_index': 3,
|
||||
'channels': 512,
|
||||
'pool_scales': (1, 2, 3, 6),
|
||||
'dropout_ratio': 0.1,
|
||||
'num_classes': 19,
|
||||
'norm_cfg': {'type': 'SyncBN', 'requires_grad': True},
|
||||
'align_corners': False,
|
||||
'loss_decode': {'type': 'CrossEntropyLoss',
|
||||
'use_sigmoid': False,
|
||||
'loss_weight': 1.0}}}
|
||||
```
|
||||
|
||||
The `_delete_=True` would replace all old keys in `backbone` field with new keys.
|
||||
|
||||
### Use intermediate variables in configs
|
||||
|
||||
Some intermediate variables are used in the configs files, like `train_pipeline`/`test_pipeline` in datasets.
|
||||
It's worth noting that when modifying intermediate variables in the children configs, user need to pass the intermediate variables into corresponding fields again.
|
||||
For example, we would like to change multi scale strategy to train/test a PSPNet. `train_pipeline`/`test_pipeline` are intermediate variable we would like to modify.
|
||||
|
||||
```python
|
||||
_base_ = '../pspnet/pspnet_r50-d8_4xb4-40k_cityscpaes-512x1024.py'
|
||||
crop_size = (512, 1024)
|
||||
img_norm_cfg = dict(
|
||||
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
|
||||
train_pipeline = [
|
||||
dict(type='LoadImageFromFile'),
|
||||
dict(type='LoadAnnotations'),
|
||||
dict(type='RandomResize',
|
||||
img_scale=(2048, 1024),
|
||||
ratio_range=(1., 2.),
|
||||
keep_ration=True),
|
||||
dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
|
||||
dict(type='RandomFlip', flip_ratio=0.5),
|
||||
dict(type='PhotoMetricDistortion'),
|
||||
dict(type='PackSegInputs'),
|
||||
]
|
||||
test_pipeline = [
|
||||
dict(type='LoadImageFromFile'),
|
||||
dict(type='Resize',
|
||||
scale=(2048, 1024),
|
||||
keep_ratio=True),
|
||||
dict(type='LoadAnnotations'),
|
||||
dict(type='PackSegInputs')
|
||||
]
|
||||
train_dataset=dict(
|
||||
type=dataset_type,
|
||||
data_root=data_root,
|
||||
data_prefix=dict(
|
||||
img_path='leftImg8bit/train', seg_map_path='gtFine/train'),
|
||||
pipeline=train_pipeline)
|
||||
test_dataset=dict(
|
||||
type=dataset_type,
|
||||
data_root=data_root,
|
||||
data_prefix=dict(
|
||||
img_path='leftImg8bit/val', seg_map_path='gtFine/val'),
|
||||
pipeline=test_pipeline)
|
||||
train_dataloader = dict(dataset=train_dataset)
|
||||
val_dataloader = dict(dataset=test_dataset)
|
||||
test_dataloader = val_dataloader
|
||||
```
|
||||
|
||||
We first define the new `train_pipeline`/`test_pipeline` and pass them into `dataset`.
|
||||
|
||||
Similarly, if we would like to switch from `SyncBN` to `BN` or `MMSyncBN`, we need to substitute every `norm_cfg` in the config.
|
||||
|
||||
```python
|
||||
_base_ = '../pspnet/pspnet_r50-d8_4xb4-40k_cityscpaes-512x1024.py'
|
||||
norm_cfg = dict(type='BN', requires_grad=True)
|
||||
model = dict(
|
||||
backbone=dict(norm_cfg=norm_cfg),
|
||||
decode_head=dict(norm_cfg=norm_cfg),
|
||||
auxiliary_head=dict(norm_cfg=norm_cfg))
|
||||
```
|
||||
|
||||
## Modify config through script arguments
|
||||
|
||||
In the [training script](https://github.com/open-mmlab/mmsegmentation/blob/1.x/tools/train.py) and the [testing script](https://github.com/open-mmlab/mmsegmentation/blob/1.x/tools/test.py), we support the script argument `--cfg-options`, it may help users override some settings in the used config, the key-value pair in `xxx=yyy` format will be merged into config file.
|
||||
|
||||
For example, this is a simplified script `demo_script.py`:
|
||||
|
||||
```python
|
||||
import argparse
|
||||
|
||||
from mmengine.config import Config, DictAction
|
||||
|
||||
def parse_args():
|
||||
parser = argparse.ArgumentParser(description='Script Example')
|
||||
parser.add_argument('config', help='train config file path')
|
||||
parser.add_argument(
|
||||
'--cfg-options',
|
||||
nargs='+',
|
||||
action=DictAction,
|
||||
help='override some settings in the used config, the key-value pair '
|
||||
'in xxx=yyy format will be merged into config file. If the value to '
|
||||
'be overwritten is a list, it should be like key="[a,b]" or key=a,b '
|
||||
'It also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]" '
|
||||
'Note that the quotation marks are necessary and that no white space '
|
||||
'is allowed.')
|
||||
args = parser.parse_args()
|
||||
return args
|
||||
|
||||
def main():
|
||||
args = parse_args()
|
||||
|
||||
cfg = Config.fromfile(args.config)
|
||||
if args.cfg_options is not None:
|
||||
cfg.merge_from_dict(args.cfg_options)
|
||||
|
||||
print(cfg)
|
||||
|
||||
if __name__ == '__main__':
|
||||
main()
|
||||
```
|
||||
|
||||
An example config file `demo_config.py` as follows:
|
||||
|
||||
```python
|
||||
backbone = dict(
|
||||
type='ResNetV1c',
|
||||
depth=50,
|
||||
num_stages=4,
|
||||
out_indices=(0, 1, 2, 3),
|
||||
dilations=(1, 1, 2, 4),
|
||||
strides=(1, 2, 1, 1),
|
||||
norm_eval=False,
|
||||
style='pytorch',
|
||||
contract_dilation=True)
|
||||
```
|
||||
|
||||
Run `demo_script.py`:
|
||||
|
||||
```shell
|
||||
python demo_script.py demo_config.py
|
||||
```
|
||||
|
||||
```shell
|
||||
Config (path: demo_config.py): {'backbone': {'type': 'ResNetV1c', 'depth': 50, 'num_stages': 4, 'out_indices': (0, 1, 2, 3), 'dilations': (1, 1, 2, 4), 'strides': (1, 2, 1, 1), 'norm_eval': False, 'style': 'pytorch', 'contract_dilation': True}}
|
||||
```
|
||||
|
||||
Modify config through script arguments:
|
||||
|
||||
```shell
|
||||
python demo_script.py demo_config.py --cfg-options backbone.depth=101
|
||||
```
|
||||
|
||||
```shell
|
||||
Config (path: demo_config.py): {'backbone': {'type': 'ResNetV1c', 'depth': 101, 'num_stages': 4, 'out_indices': (0, 1, 2, 3), 'dilations': (1, 1, 2, 4), 'strides': (1, 2, 1, 1), 'norm_eval': False, 'style': 'pytorch', 'contract_dilation': True}}
|
||||
```
|
||||
|
||||
- Update values of list/tuples.
|
||||
|
||||
If the value to be updated is a list or a tuple. For example, the config file `demo_config.py` sets `strides=(1, 2, 1, 1)` in `backbone`.
|
||||
If you want to change this key, you may specify in two ways:
|
||||
|
||||
1. `--cfg-options backbone.strides="(1, 1, 1, 1)"`. Note that the quotation mark " is necessary to support list/tuple data types.
|
||||
|
||||
```shell
|
||||
python demo_script.py demo_config.py --cfg-options backbone.strides="(1, 1, 1, 1)"
|
||||
```
|
||||
|
||||
```shell
|
||||
Config (path: demo_config.py): {'backbone': {'type': 'ResNetV1c', 'depth': 50, 'num_stages': 4, 'out_indices': (0, 1, 2, 3), 'dilations': (1, 1, 2, 4), 'strides': (1, 1, 1, 1), 'norm_eval': False, 'style': 'pytorch', 'contract_dilation': True}}
|
||||
```
|
||||
|
||||
2. `--cfg-options backbone.strides=1,1,1,1`. Note that **NO** white space is allowed in the specified value.
|
||||
In addition, if the original type is tuple, it will be automatically converted to list after this way.
|
||||
|
||||
```shell
|
||||
python demo_script.py demo_config.py --cfg-options backbone.strides=1,1,1,1
|
||||
```
|
||||
|
||||
```shell
|
||||
Config (path: demo_config.py): {'backbone': {'type': 'ResNetV1c', 'depth': 50, 'num_stages': 4, 'out_indices': (0, 1, 2, 3), 'dilations': (1, 1, 2, 4), 'strides': [1, 1, 1, 1], 'norm_eval': False, 'style': 'pytorch', 'contract_dilation': True}}
|
||||
```
|
||||
|
||||
```{note}
|
||||
This modification method only supports modifying configuration items of string, int, float, boolean, None, list and tuple types.
|
||||
More specifically, for list and tuple types, the elements inside them must also be one of the above seven types.
|
||||
```
|
||||
806
Seg_All_In_One_MMSeg/docs/en/user_guides/2_dataset_prepare.md
Normal file
806
Seg_All_In_One_MMSeg/docs/en/user_guides/2_dataset_prepare.md
Normal file
@@ -0,0 +1,806 @@
|
||||
# Tutorial 2: Prepare datasets
|
||||
|
||||
It is recommended to symlink the dataset root to `$MMSEGMENTATION/data`.
|
||||
If your folder structure is different, you may need to change the corresponding paths in config files.
|
||||
For users in China, we also recommend you get the dsdl dataset from our opensource platform [OpenDataLab](https://opendatalab.com/), for better download and use experience,here is an example: [DSDLReadme](../../../configs/dsdl/README.md), welcome to try.
|
||||
|
||||
```none
|
||||
mmsegmentation
|
||||
├── mmseg
|
||||
├── tools
|
||||
├── configs
|
||||
├── data
|
||||
│ ├── cityscapes
|
||||
│ │ ├── leftImg8bit
|
||||
│ │ │ ├── train
|
||||
│ │ │ ├── val
|
||||
│ │ ├── gtFine
|
||||
│ │ │ ├── train
|
||||
│ │ │ ├── val
|
||||
│ ├── VOCdevkit
|
||||
│ │ ├── VOC2012
|
||||
│ │ │ ├── JPEGImages
|
||||
│ │ │ ├── SegmentationClass
|
||||
│ │ │ ├── ImageSets
|
||||
│ │ │ │ ├── Segmentation
|
||||
│ │ ├── VOC2010
|
||||
│ │ │ ├── JPEGImages
|
||||
│ │ │ ├── SegmentationClassContext
|
||||
│ │ │ ├── ImageSets
|
||||
│ │ │ │ ├── SegmentationContext
|
||||
│ │ │ │ │ ├── train.txt
|
||||
│ │ │ │ │ ├── val.txt
|
||||
│ │ │ ├── trainval_merged.json
|
||||
│ │ ├── VOCaug
|
||||
│ │ │ ├── dataset
|
||||
│ │ │ │ ├── cls
|
||||
│ ├── ade
|
||||
│ │ ├── ADEChallengeData2016
|
||||
│ │ │ ├── annotations
|
||||
│ │ │ │ ├── training
|
||||
│ │ │ │ ├── validation
|
||||
│ │ │ ├── images
|
||||
│ │ │ │ ├── training
|
||||
│ │ │ │ ├── validation
|
||||
│ ├── coco_stuff10k
|
||||
│ │ ├── images
|
||||
│ │ │ ├── train2014
|
||||
│ │ │ ├── test2014
|
||||
│ │ ├── annotations
|
||||
│ │ │ ├── train2014
|
||||
│ │ │ ├── test2014
|
||||
│ │ ├── imagesLists
|
||||
│ │ │ ├── train.txt
|
||||
│ │ │ ├── test.txt
|
||||
│ │ │ ├── all.txt
|
||||
│ ├── coco_stuff164k
|
||||
│ │ ├── images
|
||||
│ │ │ ├── train2017
|
||||
│ │ │ ├── val2017
|
||||
│ │ ├── annotations
|
||||
│ │ │ ├── train2017
|
||||
│ │ │ ├── val2017
|
||||
│ ├── CHASE_DB1
|
||||
│ │ ├── images
|
||||
│ │ │ ├── training
|
||||
│ │ │ ├── validation
|
||||
│ │ ├── annotations
|
||||
│ │ │ ├── training
|
||||
│ │ │ ├── validation
|
||||
│ ├── DRIVE
|
||||
│ │ ├── images
|
||||
│ │ │ ├── training
|
||||
│ │ │ ├── validation
|
||||
│ │ ├── annotations
|
||||
│ │ │ ├── training
|
||||
│ │ │ ├── validation
|
||||
│ ├── HRF
|
||||
│ │ ├── images
|
||||
│ │ │ ├── training
|
||||
│ │ │ ├── validation
|
||||
│ │ ├── annotations
|
||||
│ │ │ ├── training
|
||||
│ │ │ ├── validation
|
||||
│ ├── STARE
|
||||
│ │ ├── images
|
||||
│ │ │ ├── training
|
||||
│ │ │ ├── validation
|
||||
│ │ ├── annotations
|
||||
│ │ │ ├── training
|
||||
│ │ │ ├── validation
|
||||
| ├── dark_zurich
|
||||
| │ ├── gps
|
||||
| │ │ ├── val
|
||||
| │ │ └── val_ref
|
||||
| │ ├── gt
|
||||
| │ │ └── val
|
||||
| │ ├── LICENSE.txt
|
||||
| │ ├── lists_file_names
|
||||
| │ │ ├── val_filenames.txt
|
||||
| │ │ └── val_ref_filenames.txt
|
||||
| │ ├── README.md
|
||||
| │ └── rgb_anon
|
||||
| │ | ├── val
|
||||
| │ | └── val_ref
|
||||
| ├── NighttimeDrivingTest
|
||||
| | ├── gtCoarse_daytime_trainvaltest
|
||||
| | │ └── test
|
||||
| | │ └── night
|
||||
| | └── leftImg8bit
|
||||
| | | └── test
|
||||
| | | └── night
|
||||
│ ├── loveDA
|
||||
│ │ ├── img_dir
|
||||
│ │ │ ├── train
|
||||
│ │ │ ├── val
|
||||
│ │ │ ├── test
|
||||
│ │ ├── ann_dir
|
||||
│ │ │ ├── train
|
||||
│ │ │ ├── val
|
||||
│ ├── potsdam
|
||||
│ │ ├── img_dir
|
||||
│ │ │ ├── train
|
||||
│ │ │ ├── val
|
||||
│ │ ├── ann_dir
|
||||
│ │ │ ├── train
|
||||
│ │ │ ├── val
|
||||
│ ├── vaihingen
|
||||
│ │ ├── img_dir
|
||||
│ │ │ ├── train
|
||||
│ │ │ ├── val
|
||||
│ │ ├── ann_dir
|
||||
│ │ │ ├── train
|
||||
│ │ │ ├── val
|
||||
│ ├── iSAID
|
||||
│ │ ├── img_dir
|
||||
│ │ │ ├── train
|
||||
│ │ │ ├── val
|
||||
│ │ │ ├── test
|
||||
│ │ ├── ann_dir
|
||||
│ │ │ ├── train
|
||||
│ │ │ ├── val
|
||||
│ ├── synapse
|
||||
│ │ ├── img_dir
|
||||
│ │ │ ├── train
|
||||
│ │ │ ├── val
|
||||
│ │ ├── ann_dir
|
||||
│ │ │ ├── train
|
||||
│ │ │ ├── val
|
||||
│ ├── REFUGE
|
||||
│ │ ├── images
|
||||
│ │ │ ├── training
|
||||
│ │ │ ├── validation
|
||||
│ │ │ ├── test
|
||||
│ │ ├── annotations
|
||||
│ │ │ ├── training
|
||||
│ │ │ ├── validation
|
||||
│ │ │ ├── test
|
||||
│ ├── mapillary
|
||||
│ │ ├── training
|
||||
│ │ │ ├── images
|
||||
│ │ │ ├── v1.2
|
||||
| │ │ │ ├── instances
|
||||
| │ │ │ ├── labels
|
||||
| │ │ │ └── panoptic
|
||||
│ │ │ ├── v2.0
|
||||
| │ │ │ ├── instances
|
||||
| │ │ │ ├── labels
|
||||
| │ │ │ ├── panoptic
|
||||
| │ │ │ └── polygons
|
||||
│ │ ├── validation
|
||||
│ │ │ ├── images
|
||||
| │ │ ├── v1.2
|
||||
| │ │ │ ├── instances
|
||||
| │ │ │ ├── labels
|
||||
| │ │ │ └── panoptic
|
||||
│ │ │ ├── v2.0
|
||||
| │ │ │ ├── instances
|
||||
| │ │ │ ├── labels
|
||||
| │ │ │ ├── panoptic
|
||||
| │ │ │ └── polygons
|
||||
│ ├── bdd100k
|
||||
│ │ ├── images
|
||||
│ │ │ └── 10k
|
||||
| │ │ │ ├── test
|
||||
| │ │ │ ├── train
|
||||
| │ │ │ └── val
|
||||
│ │ └── labels
|
||||
│ │ │ └── sem_seg
|
||||
| │ │ │ ├── colormaps
|
||||
| │ │ │ │ ├──train
|
||||
| │ │ │ │ └──val
|
||||
| │ │ │ ├── masks
|
||||
| │ │ │ │ ├──train
|
||||
| │ │ │ │ └──val
|
||||
| │ │ │ ├── polygons
|
||||
| │ │ │ │ ├──sem_seg_train.json
|
||||
| │ │ │ │ └──sem_seg_val.json
|
||||
| │ │ │ └── rles
|
||||
| │ │ │ │ ├──sem_seg_train.json
|
||||
| │ │ │ │ └──sem_seg_val.json
|
||||
│ ├── nyu
|
||||
│ │ ├── images
|
||||
│ │ │ ├── train
|
||||
│ │ │ ├── test
|
||||
│ │ ├── annotations
|
||||
│ │ │ ├── train
|
||||
│ │ │ ├── test
|
||||
│ ├── HSIDrive20
|
||||
│ │ ├── images
|
||||
│ │ │ ├── train
|
||||
│ │ │ ├── validation
|
||||
│ │ │ ├── test
|
||||
│ │ ├── annotations
|
||||
│ │ │ ├── train
|
||||
│ │ │ ├── validation
|
||||
│ │ │ ├── test
|
||||
```
|
||||
|
||||
## Download dataset via MIM
|
||||
|
||||
By using [OpenXLab](https://openxlab.org.cn/datasets), you can obtain free formatted datasets in various fields. Through the search function of the platform, you may address the dataset they look for quickly and easily. Using the formatted datasets from the platform, you can efficiently conduct tasks across datasets.
|
||||
|
||||
If you use MIM to download, make sure that the version is greater than v0.3.8. You can use the following command to update, install, login and download the dataset:
|
||||
|
||||
```shell
|
||||
# upgrade your MIM
|
||||
pip install -U openmim
|
||||
|
||||
# install OpenXLab CLI tools
|
||||
pip install -U openxlab
|
||||
# log in OpenXLab
|
||||
openxlab login
|
||||
|
||||
# download ADE20K by MIM
|
||||
mim download mmsegmentation --dataset ade20k
|
||||
```
|
||||
|
||||
## Cityscapes
|
||||
|
||||
The data could be found [here](https://www.cityscapes-dataset.com/downloads/) after registration.
|
||||
|
||||
By convention, `**labelTrainIds.png` are used for cityscapes training.
|
||||
We provided a [script](https://github.com/open-mmlab/mmsegmentation/blob/1.x/tools/dataset_converters/cityscapes.py) based on [cityscapesscripts](https://github.com/mcordts/cityscapesScripts)to generate `**labelTrainIds.png`.
|
||||
|
||||
```shell
|
||||
# --nproc means 8 process for conversion, which could be omitted as well.
|
||||
python tools/dataset_converters/cityscapes.py data/cityscapes --nproc 8
|
||||
```
|
||||
|
||||
## Pascal VOC
|
||||
|
||||
Pascal VOC 2012 could be downloaded from [here](http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar).
|
||||
Beside, most recent works on Pascal VOC dataset usually exploit extra augmentation data, which could be found [here](http://www.eecs.berkeley.edu/Research/Projects/CS/vision/grouping/semantic_contours/benchmark.tgz).
|
||||
|
||||
If you would like to use augmented VOC dataset, please run following command to convert augmentation annotations into proper format.
|
||||
|
||||
```shell
|
||||
# --nproc means 8 process for conversion, which could be omitted as well.
|
||||
python tools/dataset_converters/voc_aug.py data/VOCdevkit data/VOCdevkit/VOCaug --nproc 8
|
||||
```
|
||||
|
||||
Please refer to [concat dataset](../advanced_guides/add_datasets.md#concatenate-dataset) and [voc_aug config example](../../../configs/_base_/datasets/pascal_voc12_aug.py) for details about how to concatenate them and train them together.
|
||||
|
||||
## ADE20K
|
||||
|
||||
The training and validation set of ADE20K could be download from this [link](http://data.csail.mit.edu/places/ADEchallenge/ADEChallengeData2016.zip).
|
||||
We may also download test set from [here](http://data.csail.mit.edu/places/ADEchallenge/release_test.zip).
|
||||
|
||||
## Pascal Context
|
||||
|
||||
The training and validation set of Pascal Context could be download from [here](http://host.robots.ox.ac.uk/pascal/VOC/voc2010/VOCtrainval_03-May-2010.tar). You may also download test set from [here](http://host.robots.ox.ac.uk:8080/eval/downloads/VOC2010test.tar) after registration.
|
||||
|
||||
To split the training and validation set from original dataset, you may download trainval_merged.json from [here](https://codalabuser.blob.core.windows.net/public/trainval_merged.json).
|
||||
|
||||
If you would like to use Pascal Context dataset, please install [Detail](https://github.com/zhanghang1989/detail-api) and then run the following command to convert annotations into proper format.
|
||||
|
||||
```shell
|
||||
python tools/dataset_converters/pascal_context.py data/VOCdevkit data/VOCdevkit/VOC2010/trainval_merged.json
|
||||
```
|
||||
|
||||
## COCO Stuff 10k
|
||||
|
||||
The data could be downloaded [here](http://calvin.inf.ed.ac.uk/wp-content/uploads/data/cocostuffdataset/cocostuff-10k-v1.1.zip) by wget.
|
||||
|
||||
For COCO Stuff 10k dataset, please run the following commands to download and convert the dataset.
|
||||
|
||||
```shell
|
||||
# download
|
||||
mkdir coco_stuff10k && cd coco_stuff10k
|
||||
wget http://calvin.inf.ed.ac.uk/wp-content/uploads/data/cocostuffdataset/cocostuff-10k-v1.1.zip
|
||||
|
||||
# unzip
|
||||
unzip cocostuff-10k-v1.1.zip
|
||||
|
||||
# --nproc means 8 process for conversion, which could be omitted as well.
|
||||
python tools/dataset_converters/coco_stuff10k.py /path/to/coco_stuff10k --nproc 8
|
||||
```
|
||||
|
||||
By convention, mask labels in `/path/to/coco_stuff164k/annotations/*2014/*_labelTrainIds.png` are used for COCO Stuff 10k training and testing.
|
||||
|
||||
## COCO Stuff 164k
|
||||
|
||||
For COCO Stuff 164k dataset, please run the following commands to download and convert the augmented dataset.
|
||||
|
||||
```shell
|
||||
# download
|
||||
mkdir coco_stuff164k && cd coco_stuff164k
|
||||
wget http://images.cocodataset.org/zips/train2017.zip
|
||||
wget http://images.cocodataset.org/zips/val2017.zip
|
||||
wget http://calvin.inf.ed.ac.uk/wp-content/uploads/data/cocostuffdataset/stuffthingmaps_trainval2017.zip
|
||||
|
||||
# unzip
|
||||
unzip train2017.zip -d images/
|
||||
unzip val2017.zip -d images/
|
||||
unzip stuffthingmaps_trainval2017.zip -d annotations/
|
||||
|
||||
# --nproc means 8 process for conversion, which could be omitted as well.
|
||||
python tools/dataset_converters/coco_stuff164k.py /path/to/coco_stuff164k --nproc 8
|
||||
```
|
||||
|
||||
By convention, mask labels in `/path/to/coco_stuff164k/annotations/*2017/*_labelTrainIds.png` are used for COCO Stuff 164k training and testing.
|
||||
|
||||
The details of this dataset could be found at [here](https://github.com/nightrome/cocostuff#downloads).
|
||||
|
||||
## CHASE DB1
|
||||
|
||||
The training and validation set of CHASE DB1 could be download from [here](https://staffnet.kingston.ac.uk/~ku15565/CHASE_DB1/assets/CHASEDB1.zip).
|
||||
|
||||
To convert CHASE DB1 dataset to MMSegmentation format, you should run the following command:
|
||||
|
||||
```shell
|
||||
python tools/dataset_converters/chase_db1.py /path/to/CHASEDB1.zip
|
||||
```
|
||||
|
||||
The script will make directory structure automatically.
|
||||
|
||||
## DRIVE
|
||||
|
||||
The training and validation set of DRIVE could be download from [here](https://drive.grand-challenge.org/). Before that, you should register an account. Currently '1st_manual' is not provided officially.
|
||||
|
||||
To convert DRIVE dataset to MMSegmentation format, you should run the following command:
|
||||
|
||||
```shell
|
||||
python tools/dataset_converters/drive.py /path/to/training.zip /path/to/test.zip
|
||||
```
|
||||
|
||||
The script will make directory structure automatically.
|
||||
|
||||
## HRF
|
||||
|
||||
First, download [healthy.zip](https://www5.cs.fau.de/fileadmin/research/datasets/fundus-images/healthy.zip), [glaucoma.zip](https://www5.cs.fau.de/fileadmin/research/datasets/fundus-images/glaucoma.zip), [diabetic_retinopathy.zip](https://www5.cs.fau.de/fileadmin/research/datasets/fundus-images/diabetic_retinopathy.zip), [healthy_manualsegm.zip](https://www5.cs.fau.de/fileadmin/research/datasets/fundus-images/healthy_manualsegm.zip), [glaucoma_manualsegm.zip](https://www5.cs.fau.de/fileadmin/research/datasets/fundus-images/glaucoma_manualsegm.zip) and [diabetic_retinopathy_manualsegm.zip](https://www5.cs.fau.de/fileadmin/research/datasets/fundus-images/diabetic_retinopathy_manualsegm.zip).
|
||||
|
||||
To convert HRF dataset to MMSegmentation format, you should run the following command:
|
||||
|
||||
```shell
|
||||
python tools/dataset_converters/hrf.py /path/to/healthy.zip /path/to/healthy_manualsegm.zip /path/to/glaucoma.zip /path/to/glaucoma_manualsegm.zip /path/to/diabetic_retinopathy.zip /path/to/diabetic_retinopathy_manualsegm.zip
|
||||
```
|
||||
|
||||
The script will make directory structure automatically.
|
||||
|
||||
## STARE
|
||||
|
||||
First, download [stare-images.tar](http://cecas.clemson.edu/~ahoover/stare/probing/stare-images.tar), [labels-ah.tar](http://cecas.clemson.edu/~ahoover/stare/probing/labels-ah.tar) and [labels-vk.tar](http://cecas.clemson.edu/~ahoover/stare/probing/labels-vk.tar).
|
||||
|
||||
To convert STARE dataset to MMSegmentation format, you should run the following command:
|
||||
|
||||
```shell
|
||||
python tools/dataset_converters/stare.py /path/to/stare-images.tar /path/to/labels-ah.tar /path/to/labels-vk.tar
|
||||
```
|
||||
|
||||
The script will make directory structure automatically.
|
||||
|
||||
## Dark Zurich
|
||||
|
||||
Since we only support test models on this dataset, you may only download [the validation set](https://data.vision.ee.ethz.ch/csakarid/shared/GCMA_UIoU/Dark_Zurich_val_anon.zip).
|
||||
|
||||
## Nighttime Driving
|
||||
|
||||
Since we only support test models on this dataset, you may only download [the test set](http://data.vision.ee.ethz.ch/daid/NighttimeDriving/NighttimeDrivingTest.zip).
|
||||
|
||||
## LoveDA
|
||||
|
||||
The data could be downloaded from Google Drive [here](https://drive.google.com/drive/folders/1ibYV0qwn4yuuh068Rnc-w4tPi0U0c-ti?usp=sharing).
|
||||
|
||||
Or it can be downloaded from [zenodo](https://zenodo.org/record/5706578#.YZvN7SYRXdF), you should run the following command:
|
||||
|
||||
```shell
|
||||
# Download Train.zip
|
||||
wget https://zenodo.org/record/5706578/files/Train.zip
|
||||
# Download Val.zip
|
||||
wget https://zenodo.org/record/5706578/files/Val.zip
|
||||
# Download Test.zip
|
||||
wget https://zenodo.org/record/5706578/files/Test.zip
|
||||
```
|
||||
|
||||
For LoveDA dataset, please run the following command to re-organize the dataset.
|
||||
|
||||
```shell
|
||||
python tools/dataset_converters/loveda.py /path/to/loveDA
|
||||
```
|
||||
|
||||
Using trained model to predict test set of LoveDA and submit it to server can be found [here](https://codalab.lisn.upsaclay.fr/competitions/421).
|
||||
|
||||
More details about LoveDA can be found [here](https://github.com/Junjue-Wang/LoveDA).
|
||||
|
||||
## ISPRS Potsdam
|
||||
|
||||
The [Potsdam](https://www.isprs.org/education/benchmarks/UrbanSemLab/2d-sem-label-potsdam.aspx) dataset is for urban semantic segmentation used in the 2D Semantic Labeling Contest - Potsdam.
|
||||
|
||||
The dataset can be requested at the challenge [homepage](https://www.isprs.org/education/benchmarks/UrbanSemLab/default.aspx).
|
||||
Or download on [BaiduNetdisk](https://pan.baidu.com/s/1K-cLVZnd1X7d8c26FQ-nGg?pwd=mseg),password:mseg, [Google Drive](https://drive.google.com/drive/folders/1w3EJuyUGet6_qmLwGAWZ9vw5ogeG0zLz?usp=sharing) and [OpenDataLab](https://opendatalab.com/ISPRS_Potsdam/download).
|
||||
The '2_Ortho_RGB.zip' and '5_Labels_all_noBoundary.zip' are required.
|
||||
|
||||
For Potsdam dataset, please run the following command to re-organize the dataset.
|
||||
|
||||
```shell
|
||||
python tools/dataset_converters/potsdam.py /path/to/potsdam
|
||||
```
|
||||
|
||||
In our default setting, it will generate 3456 images for training and 2016 images for validation.
|
||||
|
||||
## ISPRS Vaihingen
|
||||
|
||||
The [Vaihingen](https://www2.isprs.org/commissions/comm2/wg4/benchmark/2d-sem-label-vaihingen/) dataset is for urban semantic segmentation used in the 2D Semantic Labeling Contest - Vaihingen.
|
||||
|
||||
The dataset can be requested at the challenge [homepage](https://www2.isprs.org/commissions/comm2/wg4/benchmark/data-request-form/).
|
||||
Or [BaiduNetdisk](https://pan.baidu.com/s/109D3WLrLafsuYtLeerLiiA?pwd=mseg),password:mseg, [Google Drive](https://drive.google.com/drive/folders/1w3NhvLVA2myVZqOn2pbiDXngNC7NTP_t?usp=sharing).
|
||||
The 'ISPRS_semantic_labeling_Vaihingen.zip' and 'ISPRS_semantic_labeling_Vaihingen_ground_truth_eroded_COMPLETE.zip' are required.
|
||||
|
||||
For Vaihingen dataset, please run the following command to re-organize the dataset.
|
||||
|
||||
```shell
|
||||
python tools/dataset_converters/vaihingen.py /path/to/vaihingen
|
||||
```
|
||||
|
||||
In our default setting (`clip_size`=512, `stride_size`=256), it will generate 344 images for training and 398 images for validation.
|
||||
|
||||
## iSAID
|
||||
|
||||
The data images could be download from [DOTA-v1.0](https://captain-whu.github.io/DOTA/dataset.html) (train/val/test)
|
||||
|
||||
The data annotations could be download from [iSAID](https://captain-whu.github.io/iSAID/dataset.html) (train/val)
|
||||
|
||||
The dataset is a Large-scale Dataset for Instance Segmentation (also have semantic segmentation) in Aerial Images.
|
||||
|
||||
You may need to follow the following structure for dataset preparation after downloading iSAID dataset.
|
||||
|
||||
```none
|
||||
├── data
|
||||
│ ├── iSAID
|
||||
│ │ ├── train
|
||||
│ │ │ ├── images
|
||||
│ │ │ │ ├── part1.zip
|
||||
│ │ │ │ ├── part2.zip
|
||||
│ │ │ │ ├── part3.zip
|
||||
│ │ │ ├── Semantic_masks
|
||||
│ │ │ │ ├── images.zip
|
||||
│ │ ├── val
|
||||
│ │ │ ├── images
|
||||
│ │ │ │ ├── part1.zip
|
||||
│ │ │ ├── Semantic_masks
|
||||
│ │ │ │ ├── images.zip
|
||||
│ │ ├── test
|
||||
│ │ │ ├── images
|
||||
│ │ │ │ ├── part1.zip
|
||||
│ │ │ │ ├── part2.zip
|
||||
```
|
||||
|
||||
```shell
|
||||
python tools/dataset_converters/isaid.py /path/to/iSAID
|
||||
```
|
||||
|
||||
In our default setting (`patch_width`=896, `patch_height`=896, `overlap_area`=384), it will generate 33978 images for training and 11644 images for validation.
|
||||
|
||||
## LIP(Look Into Person) dataset
|
||||
|
||||
This dataset could be download from [this page](https://lip.sysuhcp.com/overview.php).
|
||||
|
||||
Please run the following commands to unzip dataset.
|
||||
|
||||
```shell
|
||||
unzip LIP.zip
|
||||
cd LIP
|
||||
unzip TrainVal_images.zip
|
||||
unzip TrainVal_parsing_annotations.zip
|
||||
cd TrainVal_parsing_annotations
|
||||
unzip TrainVal_parsing_annotations.zip
|
||||
mv train_segmentations ../
|
||||
mv val_segmentations ../
|
||||
cd ..
|
||||
```
|
||||
|
||||
The contents of LIP datasets include:
|
||||
|
||||
```none
|
||||
├── data
|
||||
│ ├── LIP
|
||||
│ │ ├── train_images
|
||||
│ │ │ ├── 1000_1234574.jpg
|
||||
│ │ │ ├── ...
|
||||
│ │ ├── train_segmentations
|
||||
│ │ │ ├── 1000_1234574.png
|
||||
│ │ │ ├── ...
|
||||
│ │ ├── val_images
|
||||
│ │ │ ├── 100034_483681.jpg
|
||||
│ │ │ ├── ...
|
||||
│ │ ├── val_segmentations
|
||||
│ │ │ ├── 100034_483681.png
|
||||
│ │ │ ├── ...
|
||||
```
|
||||
|
||||
## Synapse dataset
|
||||
|
||||
This dataset could be download from [this page](https://www.synapse.org/#!Synapse:syn3193805/wiki/).
|
||||
|
||||
To follow the data preparation setting of [TransUNet](https://arxiv.org/abs/2102.04306), which splits original training set (30 scans) into new training (18 scans) and validation set (12 scans). Please run the following command to prepare the dataset.
|
||||
|
||||
```shell
|
||||
unzip RawData.zip
|
||||
cd ./RawData/Training
|
||||
```
|
||||
|
||||
Then create `train.txt` and `val.txt` to split dataset.
|
||||
|
||||
According to TransUnet, the following is the data set division.
|
||||
|
||||
train.txt
|
||||
|
||||
```none
|
||||
img0005.nii.gz
|
||||
img0006.nii.gz
|
||||
img0007.nii.gz
|
||||
img0009.nii.gz
|
||||
img0010.nii.gz
|
||||
img0021.nii.gz
|
||||
img0023.nii.gz
|
||||
img0024.nii.gz
|
||||
img0026.nii.gz
|
||||
img0027.nii.gz
|
||||
img0028.nii.gz
|
||||
img0030.nii.gz
|
||||
img0031.nii.gz
|
||||
img0033.nii.gz
|
||||
img0034.nii.gz
|
||||
img0037.nii.gz
|
||||
img0039.nii.gz
|
||||
img0040.nii.gz
|
||||
```
|
||||
|
||||
val.txt
|
||||
|
||||
```none
|
||||
img0008.nii.gz
|
||||
img0022.nii.gz
|
||||
img0038.nii.gz
|
||||
img0036.nii.gz
|
||||
img0032.nii.gz
|
||||
img0002.nii.gz
|
||||
img0029.nii.gz
|
||||
img0003.nii.gz
|
||||
img0001.nii.gz
|
||||
img0004.nii.gz
|
||||
img0025.nii.gz
|
||||
img0035.nii.gz
|
||||
```
|
||||
|
||||
The contents of synapse datasets include:
|
||||
|
||||
```none
|
||||
├── Training
|
||||
│ ├── img
|
||||
│ │ ├── img0001.nii.gz
|
||||
│ │ ├── img0002.nii.gz
|
||||
│ │ ├── ...
|
||||
│ ├── label
|
||||
│ │ ├── label0001.nii.gz
|
||||
│ │ ├── label0002.nii.gz
|
||||
│ │ ├── ...
|
||||
│ ├── train.txt
|
||||
│ ├── val.txt
|
||||
```
|
||||
|
||||
Then, use this command to convert synapse dataset.
|
||||
|
||||
```shell
|
||||
python tools/dataset_converters/synapse.py --dataset-path /path/to/synapse
|
||||
```
|
||||
|
||||
Noted that MMSegmentation default evaluation metric (such as mean dice value) is calculated on 2D slice image, which is not comparable to results of 3D scan in some paper such as [TransUNet](https://arxiv.org/abs/2102.04306).
|
||||
|
||||
## REFUGE
|
||||
|
||||
Register in [REFUGE Challenge](https://refuge.grand-challenge.org) and download [REFUGE dataset](https://refuge.grand-challenge.org/REFUGE2Download).
|
||||
|
||||
Then, unzip `REFUGE2.zip` and the contents of original datasets include:
|
||||
|
||||
```none
|
||||
├── REFUGE2
|
||||
│ ├── REFUGE2
|
||||
│ │ ├── Annotation-Training400.zip
|
||||
│ │ ├── REFUGE-Test400.zip
|
||||
│ │ ├── REFUGE-Test-GT.zip
|
||||
│ │ ├── REFUGE-Training400.zip
|
||||
│ │ ├── REFUGE-Validation400.zip
|
||||
│ │ ├── REFUGE-Validation400-GT.zip
|
||||
│ ├── __MACOSX
|
||||
```
|
||||
|
||||
Please run the following command to convert REFUGE dataset:
|
||||
|
||||
```shell
|
||||
python tools/convert_datasets/refuge.py --raw_data_root=/path/to/refuge/REFUGE2/REFUGE2
|
||||
```
|
||||
|
||||
The script will make directory structure below:
|
||||
|
||||
```none
|
||||
│ ├── REFUGE
|
||||
│ │ ├── images
|
||||
│ │ │ ├── training
|
||||
│ │ │ ├── validation
|
||||
│ │ │ ├── test
|
||||
│ │ ├── annotations
|
||||
│ │ │ ├── training
|
||||
│ │ │ ├── validation
|
||||
│ │ │ ├── test
|
||||
```
|
||||
|
||||
It includes 400 images for training, 400 images for validation and 400 images for testing which is the same as REFUGE 2018 dataset.
|
||||
|
||||
## Mapillary Vistas Datasets
|
||||
|
||||
- The dataset could be download [here](https://www.mapillary.com/dataset/vistas) after registration.
|
||||
|
||||
- Mapillary Vistas Dataset use 8-bit with color-palette to store labels. No conversion operation is required.
|
||||
|
||||
- Assumption you have put the dataset zip file in `mmsegmentation/data/mapillary`
|
||||
|
||||
- Please run the following commands to unzip dataset.
|
||||
|
||||
```bash
|
||||
cd data/mapillary
|
||||
unzip An-ZjB1Zm61yAZG0ozTymz8I8NqI4x0MrYrh26dq7kPgfu8vf9ImrdaOAVOFYbJ2pNAgUnVGBmbue9lTgdBOb5BbKXIpFs0fpYWqACbrQDChAA2fdX0zS9PcHu7fY8c-FOvyBVxPNYNFQuM.zip
|
||||
```
|
||||
|
||||
- After unzip, you will get Mapillary Vistas Dataset like this structure. Semantic segmentation mask labels in `labels` folder.
|
||||
|
||||
```none
|
||||
mmsegmentation
|
||||
├── mmseg
|
||||
├── tools
|
||||
├── configs
|
||||
├── data
|
||||
│ ├── mapillary
|
||||
│ │ ├── training
|
||||
│ │ │ ├── images
|
||||
│ │ │ ├── v1.2
|
||||
| │ │ │ ├── instances
|
||||
| │ │ │ ├── labels
|
||||
| │ │ │ └── panoptic
|
||||
│ │ │ ├── v2.0
|
||||
| │ │ │ ├── instances
|
||||
| │ │ │ ├── labels
|
||||
| │ │ │ ├── panoptic
|
||||
| │ │ │ └── polygons
|
||||
│ │ ├── validation
|
||||
│ │ │ ├── images
|
||||
| │ │ ├── v1.2
|
||||
| │ │ │ ├── instances
|
||||
| │ │ │ ├── labels
|
||||
| │ │ │ └── panoptic
|
||||
│ │ │ ├── v2.0
|
||||
| │ │ │ ├── instances
|
||||
| │ │ │ ├── labels
|
||||
| │ │ │ ├── panoptic
|
||||
| │ │ │ └── polygons
|
||||
```
|
||||
|
||||
- You could set Datasets version with `MapillaryDataset_v1` and `MapillaryDataset_v2` in your configs.
|
||||
View the Mapillary Vistas Datasets config file here [V1.2](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/_base_/datasets/mapillary_v1.py) and [V2.0](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/_base_/datasets/mapillary_v2.py)
|
||||
|
||||
## LEVIR-CD
|
||||
|
||||
[LEVIR-CD](https://justchenhao.github.io/LEVIR/) Large-scale Remote Sensing Change Detection Dataset for Building.
|
||||
|
||||
Download the dataset from [here](https://justchenhao.github.io/LEVIR/).
|
||||
|
||||
The supplement version of the dataset can be requested on the [homepage](https://github.com/S2Looking/Dataset)
|
||||
|
||||
Please download the supplement version of the dataset, then unzip `LEVIR-CD+.zip`, the contents of original datasets include:
|
||||
|
||||
```none
|
||||
│ ├── LEVIR-CD+
|
||||
│ │ ├── train
|
||||
│ │ │ ├── A
|
||||
│ │ │ ├── B
|
||||
│ │ │ ├── label
|
||||
│ │ ├── test
|
||||
│ │ │ ├── A
|
||||
│ │ │ ├── B
|
||||
│ │ │ ├── label
|
||||
```
|
||||
|
||||
For LEVIR-CD dataset, please run the following command to crop images without overlap:
|
||||
|
||||
```shell
|
||||
python tools/dataset_converters/levircd.py --dataset-path /path/to/LEVIR-CD+ --out_dir /path/to/LEVIR-CD
|
||||
```
|
||||
|
||||
The size of cropped image is 256x256, which is consistent with the original paper.
|
||||
|
||||
## BDD100K
|
||||
|
||||
- You could download BDD100k datasets from [here](https://bdd-data.berkeley.edu/) after registration.
|
||||
|
||||
- You can download images and masks by clicking `10K Images` button and `Segmentation` button.
|
||||
|
||||
- After download, unzip by the following instructions:
|
||||
|
||||
```bash
|
||||
unzip ~/bdd100k_images_10k.zip -d ~/mmsegmentation/data/
|
||||
unzip ~/bdd100k_sem_seg_labels_trainval.zip -d ~/mmsegmentation/data/
|
||||
```
|
||||
|
||||
- And get
|
||||
|
||||
```none
|
||||
mmsegmentation
|
||||
├── mmseg
|
||||
├── tools
|
||||
├── configs
|
||||
├── data
|
||||
│ ├── bdd100k
|
||||
│ │ ├── images
|
||||
│ │ │ └── 10k
|
||||
| │ │ │ ├── test
|
||||
| │ │ │ ├── train
|
||||
| │ │ │ └── val
|
||||
│ │ └── labels
|
||||
│ │ │ └── sem_seg
|
||||
| │ │ │ ├── colormaps
|
||||
| │ │ │ │ ├──train
|
||||
| │ │ │ │ └──val
|
||||
| │ │ │ ├── masks
|
||||
| │ │ │ │ ├──train
|
||||
| │ │ │ │ └──val
|
||||
| │ │ │ ├── polygons
|
||||
| │ │ │ │ ├──sem_seg_train.json
|
||||
| │ │ │ │ └──sem_seg_val.json
|
||||
| │ │ │ └── rles
|
||||
| │ │ │ │ ├──sem_seg_train.json
|
||||
| │ │ │ │ └──sem_seg_val.json
|
||||
```
|
||||
|
||||
## NYU
|
||||
|
||||
- To access the NYU dataset, you can download it from [this link](https://drive.google.com/file/d/1wC-io-14RCIL4XTUrQLk6lBqU2AexLVp/view?usp=share_link)
|
||||
|
||||
- Once the download is complete, you can utilize the [tools/dataset_converters/nyu.py](/tools/dataset_converters/nyu.py) script to extract and organize the data into the required format. Run the following command in your terminal:
|
||||
|
||||
```bash
|
||||
python tools/dataset_converters/nyu.py nyu.zip
|
||||
```
|
||||
|
||||
## HSI Drive 2.0
|
||||
|
||||
- You could download HSI Drive 2.0 dataset from [here](https://ipaccess.ehu.eus/HSI-Drive/#download) after just sending an email to gded@ehu.eus with the subject "download HSI-Drive". You will receive a password to uncompress the files.
|
||||
|
||||
- After download, unzip by the following instructions:
|
||||
|
||||
```bash
|
||||
7z x -p"password" ./HSI_Drive_v2_0_Phyton.zip
|
||||
|
||||
mv ./HSIDrive20 path_to_mmsegmentation/data
|
||||
mv ./HSI_Drive_v2_0_release_notes_Python_version.md path_to_mmsegmentation/data
|
||||
mv ./image_numbering.pdf path_to_mmsegmentation/data
|
||||
```
|
||||
|
||||
- After unzip, you get
|
||||
|
||||
```none
|
||||
mmsegmentation
|
||||
├── mmseg
|
||||
├── tools
|
||||
├── configs
|
||||
├── data
|
||||
│ ├── HSIDrive20
|
||||
│ │ ├── images
|
||||
│ │ │ ├── training
|
||||
│ │ │ ├── validation
|
||||
│ │ │ ├── test
|
||||
│ │ ├── annotations
|
||||
│ │ │ ├── training
|
||||
│ │ │ ├── validation
|
||||
│ │ │ ├── test
|
||||
│ │ ├── images_MF
|
||||
│ │ │ ├── training
|
||||
│ │ │ ├── validation
|
||||
│ │ │ ├── test
|
||||
│ │ ├── RGB
|
||||
│ │ ├── training_filenames.txt
|
||||
│ │ ├── validation_filenames.txt
|
||||
│ │ ├── test_filenames.txt
|
||||
│ ├── HSI_Drive_v2_0_release_notes_Python_version.md
|
||||
│ ├── image_numbering.pdf
|
||||
```
|
||||
244
Seg_All_In_One_MMSeg/docs/en/user_guides/3_inference.md
Normal file
244
Seg_All_In_One_MMSeg/docs/en/user_guides/3_inference.md
Normal file
@@ -0,0 +1,244 @@
|
||||
# Tutorial 3: Inference with existing models
|
||||
|
||||
MMSegmentation provides pre-trained models for semantic segmentation in [Model Zoo](../model_zoo.md), and supports multiple standard datasets, including Cityscapes, ADE20K, etc.
|
||||
This note will show how to use existing models to inference on given images.
|
||||
As for how to test existing models on standard datasets, please see this [guide](./4_train_test.md)
|
||||
|
||||
MMSegmentation provides several interfaces for users to easily use pre-trained models for inference.
|
||||
|
||||
- [Tutorial 3: Inference with existing models](#tutorial-3-inference-with-existing-models)
|
||||
- [Inferencer](#inferencer)
|
||||
- [Basic Usage](#basic-usage)
|
||||
- [Initialization](#initialization)
|
||||
- [Visualize prediction](#visualize-prediction)
|
||||
- [List model](#list-model)
|
||||
- [Inference API](#inference-api)
|
||||
- [mmseg.apis.init_model](#mmsegapisinit_model)
|
||||
- [mmseg.apis.inference_model](#mmsegapisinference_model)
|
||||
- [mmseg.apis.show_result_pyplot](#mmsegapisshow_result_pyplot)
|
||||
|
||||
## Inferencer
|
||||
|
||||
We provide the most **convenient** way to use the model in MMSegmentation `MMSegInferencer`. You can get segmentation mask for an image with only 3 lines of code.
|
||||
|
||||
### Basic Usage
|
||||
|
||||
The following example shows how to use `MMSegInferencer` to perform inference on a single image.
|
||||
|
||||
```
|
||||
>>> from mmseg.apis import MMSegInferencer
|
||||
>>> # Load models into memory
|
||||
>>> inferencer = MMSegInferencer(model='deeplabv3plus_r18-d8_4xb2-80k_cityscapes-512x1024')
|
||||
>>> # Inference
|
||||
>>> inferencer('demo/demo.png', show=True)
|
||||
```
|
||||
|
||||
The visualization result should look like:
|
||||
|
||||
<div align="center">
|
||||
<img src='https://user-images.githubusercontent.com/76149310/221507927-ae01e3a7-016f-4425-b966-7b19cbbe494e.png' />
|
||||
</div>
|
||||
|
||||
Moreover, you can use `MMSegInferencer` to process a list of images:
|
||||
|
||||
```
|
||||
# Input a list of images
|
||||
>>> images = [image1, image2, ...] # image1 can be a file path or a np.ndarray
|
||||
>>> inferencer(images, show=True, wait_time=0.5) # wait_time is delay time, and 0 means forever
|
||||
|
||||
# Or input image directory
|
||||
>>> images = $IMAGESDIR
|
||||
>>> inferencer(images, show=True, wait_time=0.5)
|
||||
|
||||
# Save visualized rendering color maps and predicted results
|
||||
# out_dir is the directory to save the output results, img_out_dir and pred_out_dir are subdirectories of out_dir
|
||||
# to save visualized rendering color maps and predicted results
|
||||
>>> inferencer(images, out_dir='outputs', img_out_dir='vis', pred_out_dir='pred')
|
||||
```
|
||||
|
||||
There is a optional parameter of inferencer, `return_datasamples`, whose default value is False, and return value of inferencer is a `dict` type by default, including 2 keys 'visualization' and 'predictions'.
|
||||
If `return_datasamples=True` inferencer will return [`SegDataSample`](../advanced_guides/structures.md), or list of it.
|
||||
|
||||
```
|
||||
result = inferencer('demo/demo.png')
|
||||
# result is a `dict` including 2 keys 'visualization' and 'predictions'
|
||||
# 'visualization' includes color segmentation map
|
||||
print(result['visualization'].shape)
|
||||
# (512, 683, 3)
|
||||
|
||||
# 'predictions' includes segmentation mask with label indice
|
||||
print(result['predictions'].shape)
|
||||
# (512, 683)
|
||||
|
||||
result = inferencer('demo/demo.png', return_datasamples=True)
|
||||
print(type(result))
|
||||
# <class 'mmseg.structures.seg_data_sample.SegDataSample'>
|
||||
|
||||
# Input a list of images
|
||||
results = inferencer(images)
|
||||
# The output is list
|
||||
print(type(results['visualization']), results['visualization'][0].shape)
|
||||
# <class 'list'> (512, 683, 3)
|
||||
print(type(results['predictions']), results['predictions'][0].shape)
|
||||
# <class 'list'> (512, 683)
|
||||
|
||||
results = inferencer(images, return_datasamples=True)
|
||||
# <class 'list'>
|
||||
print(type(results[0]))
|
||||
# <class 'mmseg.structures.seg_data_sample.SegDataSample'>
|
||||
```
|
||||
|
||||
### Initialization
|
||||
|
||||
`MMSegInferencer` must be initialized from a `model`, which can be a model name or a `Config` even a path of config file.
|
||||
The model names can be found in models' metafile (configs/xxx/metafile.yaml), like one model name of maskformer is `maskformer_r50-d32_8xb2-160k_ade20k-512x512`, and if input model name and the weights of the model will be download automatically. Below are other input parameters:
|
||||
|
||||
- weights (str, optional) - Path to the checkpoint. If it is not specified and model is a model name of metafile, the weights will be loaded from metafile. Defaults to None.
|
||||
- classes (list, optional) - Input classes for result rendering, as the prediction of segmentation model is a segment map with label indices, `classes` is a list which includes items responding to the label indices. If classes is not defined, visualizer will take `cityscapes` classes by default. Defaults to None.
|
||||
- palette (list, optional) - Input palette for result rendering, which is a list of colors responding to the classes. If the palette is not defined, the visualizer will take the palette of `cityscapes` by default. Defaults to None.
|
||||
- dataset_name (str, optional) - [Dataset name or alias](https://github.com/open-mmlab/mmsegmentation/blob/main/mmseg/utils/class_names.py#L302-L317), visualizer will use the meta information of the dataset i.e. classes and palette, but the `classes` and `palette` have higher priority. Defaults to None.
|
||||
- device (str, optional) - Device to run inference. If None, the available device will be automatically used. Defaults to None.
|
||||
- scope (str, optional) - The scope of the model. Defaults to 'mmseg'.
|
||||
|
||||
### Visualize prediction
|
||||
|
||||
`MMSegInferencer` supports 4 parameters for visualize prediction, you can use them when call initialized inferencer:
|
||||
|
||||
- show (bool) - Whether to display the image in a popup window. Defaults to False.
|
||||
- wait_time (float) - The interval of show (s). Defaults to 0.
|
||||
- img_out_dir (str) - Subdirectory of `out_dir`, used to save rendering color segmentation mask, so `out_dir` must be defined if you would like to save predicted mask. Defaults to 'vis'.
|
||||
- opacity (int, float) - The transparency of segmentation mask. Defaults to 0.8.
|
||||
|
||||
The examples of these parameters is in [Basic Usage](#basic-usage)
|
||||
|
||||
### List model
|
||||
|
||||
There is a very easy to list all model names in MMSegmentation
|
||||
|
||||
```
|
||||
>>> from mmseg.apis import MMSegInferencer
|
||||
# models is a list of model names, and them will print automatically
|
||||
>>> models = MMSegInferencer.list_models('mmseg')
|
||||
```
|
||||
|
||||
## Inference API
|
||||
|
||||
### mmseg.apis.init_model
|
||||
|
||||
Initialize a segmentor from config file.
|
||||
|
||||
Parameters:
|
||||
|
||||
- config (str, `Path`, or `mmengine.Config`) - Config file path or the config object.
|
||||
- checkpoint (str, optional) - Checkpoint path. If left as None, the model will not load any weights.
|
||||
- device (str, optional) - CPU/CUDA device option. Default 'cuda:0'.
|
||||
- cfg_options (dict, optional) - Options to override some settings in the used config.
|
||||
|
||||
Returns:
|
||||
|
||||
- nn.Module: The constructed segmentor.
|
||||
|
||||
Example:
|
||||
|
||||
```python
|
||||
from mmseg.apis import init_model
|
||||
|
||||
config_path = 'configs/pspnet/pspnet_r50-d8_4xb2-40k_cityscapes-512x1024.py'
|
||||
checkpoint_path = 'checkpoints/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth'
|
||||
|
||||
# initialize model without checkpoint
|
||||
model = init_model(config_path)
|
||||
|
||||
# init model and load checkpoint
|
||||
model = init_model(config_path, checkpoint_path)
|
||||
|
||||
# init model and load checkpoint on CPU
|
||||
model = init_model(config_path, checkpoint_path, 'cpu')
|
||||
```
|
||||
|
||||
### mmseg.apis.inference_model
|
||||
|
||||
Inference image(s) with the segmentor.
|
||||
|
||||
Parameters:
|
||||
|
||||
- model (nn.Module) - The loaded segmentor
|
||||
- imgs (str, np.ndarray, or list\[str/np.ndarray\]) - Either image files or loaded images
|
||||
|
||||
Returns:
|
||||
|
||||
- `SegDataSample` or list\[`SegDataSample`\]: If imgs is a list or tuple, the same length list type results will be returned, otherwise return the segmentation results directly.
|
||||
|
||||
**Note:** [SegDataSample](https://github.com/open-mmlab/mmsegmentation/blob/1.x/mmseg/structures/seg_data_sample.py) is a data structure interface of MMSegmentation, it is used as interfaces between different components. `SegDataSample` implement the abstract data element `mmengine.structures.BaseDataElement`, please refer to data element [documentation](https://mmengine.readthedocs.io/en/latest/advanced_tutorials/data_element.html) in [MMEngine](https://github.com/open-mmlab/mmengine) for more information.
|
||||
|
||||
The attributes in `SegDataSample` are divided into several parts:
|
||||
|
||||
- `gt_sem_seg` (`PixelData`) - Ground truth of semantic segmentation.
|
||||
- `pred_sem_seg` (`PixelData`) - Prediction of semantic segmentation.
|
||||
- `seg_logits` (`PixelData`) - Predicted logits of semantic segmentation.
|
||||
|
||||
**Note** [PixelData](https://github.com/open-mmlab/mmengine/blob/main/mmengine/structures/pixel_data.py) is the data structure for pixel-level annotations or predictions, please refer to PixelData [documentation](https://mmengine.readthedocs.io/en/latest/advanced_tutorials/data_element.html) in [MMEngine](https://github.com/open-mmlab/mmengine) for more information.
|
||||
|
||||
Example:
|
||||
|
||||
```python
|
||||
from mmseg.apis import init_model, inference_model
|
||||
|
||||
config_path = 'configs/pspnet/pspnet_r50-d8_4xb2-40k_cityscapes-512x1024.py'
|
||||
checkpoint_path = 'checkpoints/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth'
|
||||
img_path = 'demo/demo.png'
|
||||
|
||||
|
||||
model = init_model(config_path, checkpoint_path)
|
||||
result = inference_model(model, img_path)
|
||||
```
|
||||
|
||||
### mmseg.apis.show_result_pyplot
|
||||
|
||||
Visualize the segmentation results on the image.
|
||||
|
||||
Parameters:
|
||||
|
||||
- model (nn.Module) - The loaded segmentor.
|
||||
- img (str or np.ndarray) - Image filename or loaded image.
|
||||
- result (`SegDataSample`) - The prediction SegDataSample result.
|
||||
- opacity (float) - Opacity of painted segmentation map. Default `0.5`, must be in `(0, 1]` range.
|
||||
- title (str) - The title of pyplot figure. Default is ''.
|
||||
- draw_gt (bool) - Whether to draw GT SegDataSample. Default to `True`.
|
||||
- draw_pred (draws_pred) - Whether to draw Prediction SegDataSample. Default to `True`.
|
||||
- wait_time (float) - The interval of show (s), 0 is the special value that means "forever". Default to `0`.
|
||||
- show (bool) - Whether to display the drawn image. Default to `True`.
|
||||
- save_dir (str, optional) - Save file dir for all storage backends. If it is `None`, the backend storage will not save any data.
|
||||
- out_file (str, optional) - Path to output file. Default to `None`.
|
||||
|
||||
Returns:
|
||||
|
||||
- np.ndarray: the drawn image which channel is RGB.
|
||||
|
||||
Example:
|
||||
|
||||
```python
|
||||
from mmseg.apis import init_model, inference_model, show_result_pyplot
|
||||
|
||||
config_path = 'configs/pspnet/pspnet_r50-d8_4xb2-40k_cityscapes-512x1024.py'
|
||||
checkpoint_path = 'checkpoints/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth'
|
||||
img_path = 'demo/demo.png'
|
||||
|
||||
|
||||
# build the model from a config file and a checkpoint file
|
||||
model = init_model(config_path, checkpoint_path, device='cuda:0')
|
||||
|
||||
# inference on given image
|
||||
result = inference_model(model, img_path)
|
||||
|
||||
# display the segmentation result
|
||||
vis_image = show_result_pyplot(model, img_path, result)
|
||||
|
||||
# save the visualization result, the output image would be found at the path `work_dirs/result.png`
|
||||
vis_iamge = show_result_pyplot(model, img_path, result, out_file='work_dirs/result.png')
|
||||
|
||||
# Modify the time of displaying images, note that 0 is the special value that means "forever"
|
||||
vis_image = show_result_pyplot(model, img_path, result, wait_time=5)
|
||||
```
|
||||
|
||||
**Note:** If your current device doesn't have graphical user interface, it is recommended that setting `show` to `False` and specify the `out_file` or `save_dir` to save the results. If you would like to display the result on a window, no special settings are required.
|
||||
315
Seg_All_In_One_MMSeg/docs/en/user_guides/4_train_test.md
Normal file
315
Seg_All_In_One_MMSeg/docs/en/user_guides/4_train_test.md
Normal file
@@ -0,0 +1,315 @@
|
||||
# Tutorial 4: Train and test with existing models
|
||||
|
||||
MMSegmentation supports training and testing models on a variety of devices, which are described below for single-GPU, distributed, and cluster training and testing, respectively. Through this tutorial, you will learn how to train and test using the scripts provided by MMSegmentation.
|
||||
|
||||
## Training and testing on a single GPU
|
||||
|
||||
### Training on a single GPU
|
||||
|
||||
We provide `tools/train.py` to launch training jobs on a single GPU.
|
||||
The basic usage is as follows.
|
||||
|
||||
```shell
|
||||
python tools/train.py ${CONFIG_FILE} [optional arguments]
|
||||
```
|
||||
|
||||
This tool accepts several optional arguments, including:
|
||||
|
||||
- `--work-dir ${WORK_DIR}`: Override the working directory.
|
||||
- `--amp`: Use auto mixed precision training.
|
||||
- `--resume`: Resume from the latest checkpoint in the work_dir automatically.
|
||||
- `--cfg-options ${OVERRIDE_CONFIGS}`: Override some settings in the used config, and the key-value pair in xxx=yyy format will be merged into the config file.
|
||||
For example, '--cfg-option model.encoder.in_channels=6'. Please see this [guide](./1_config.md#Modify-config-through-script-arguments) for more details.
|
||||
|
||||
Below are the optional arguments for the multi-gpu test:
|
||||
|
||||
- `--launcher`: Items for distributed job initialization launcher. Allowed choices are `none`, `pytorch`, `slurm`, `mpi`. Especially, if set to none, it will test in a non-distributed mode.
|
||||
- `--local_rank`: ID for local rank. If not specified, it will be set to 0.
|
||||
|
||||
**Note:** Difference between the argument `--resume` and the field `load_from` in the config file:
|
||||
|
||||
`--resume` only determines whether to resume from the latest checkpoint in the work_dir. It is usually used for resuming the training process that is interrupted accidentally.
|
||||
|
||||
`load_from` will specify the checkpoint to be loaded and the training iteration starts from 0. It is usually used for fine-tuning.
|
||||
|
||||
If you would like to resume training from a specific checkpoint, you can use:
|
||||
|
||||
```python
|
||||
python tools/train.py ${CONFIG_FILE} --resume --cfg-options load_from=${CHECKPOINT}
|
||||
```
|
||||
|
||||
**Training on CPU**: The process of training on the CPU is consistent with single GPU training if a machine does not have GPU. If it has GPUs but not wanting to use them, we just need to disable GPUs before the training process.
|
||||
|
||||
```shell
|
||||
export CUDA_VISIBLE_DEVICES=-1
|
||||
```
|
||||
|
||||
And then run the script [above](#training-on-a-single-gpu).
|
||||
|
||||
### Testing on a single GPU
|
||||
|
||||
We provide `tools/test.py` to launch training jobs on a single GPU.
|
||||
The basic usage is as follows.
|
||||
|
||||
```shell
|
||||
python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [optional arguments]
|
||||
```
|
||||
|
||||
This tool accepts several optional arguments, including:
|
||||
|
||||
- `--work-dir`: If specified, results will be saved in this directory. If not specified, the results will be automatically saved to `work_dirs/{CONFIG_NAME}`.
|
||||
- `--show`: Show prediction results at runtime, available when `--show-dir` is not specified.
|
||||
- `--show-dir`: Directory where painted images will be saved. If specified, the visualized segmentation mask will be saved to the `work_dir/timestamp/show_dir`.
|
||||
- `--wait-time`: The interval of show (s), which takes effect when `--show` is activated. Default to 2.
|
||||
- `--cfg-options`: If specified, the key-value pair in xxx=yyy format will be merged into the config file.
|
||||
- `--tta`: Test time augmentation option.
|
||||
|
||||
**Testing on CPU**: The process of testing on the CPU is consistent with single GPU testing if a machine does not have GPU. If it has GPUs but not wanting to use them, we just need to disable GPUs before the training process.
|
||||
|
||||
```shell
|
||||
export CUDA_VISIBLE_DEVICES=-1
|
||||
```
|
||||
|
||||
then run the script [above](#testing-on-a-single-gpu).
|
||||
|
||||
## Training and testing on multiple GPUs and multiple machines
|
||||
|
||||
### Training on multiple GPUs
|
||||
|
||||
OpenMMLab2.0 implements **distributed** training with `MMDistributedDataParallel`.
|
||||
We provide `tools/dist_train.sh` to launch training on multiple GPUs.
|
||||
|
||||
The basic usage is as follows:
|
||||
|
||||
```shell
|
||||
sh tools/dist_train.sh ${CONFIG_FILE} ${GPU_NUM} [optional arguments]
|
||||
```
|
||||
|
||||
Optional arguments remain the same as stated [above](#training-on-a-single-gpu) and have additional arguments to specify the number of GPUs.
|
||||
|
||||
An example:
|
||||
|
||||
```shell
|
||||
# checkpoints and logs saved in WORK_DIR=work_dirs/pspnet_r50-d8_4xb4-80k_ade20k-512x512/
|
||||
# If work_dir is not set, it will be generated automatically.
|
||||
sh tools/dist_train.sh configs/pspnet/pspnet_r50-d8_4xb4-80k_ade20k-512x512.py 8 --work-dir work_dirs/pspnet_r50-d8_4xb4-80k_ade20k-512x512
|
||||
```
|
||||
|
||||
**Note**: During training, checkpoints and logs are saved in the same folder structure as the config file under `work_dirs/`. A custom work directory is not recommended since evaluation scripts infer work directories from the config file name. If you want to save your weights somewhere else, please use a symlink, for example:
|
||||
|
||||
```shell
|
||||
ln -s ${YOUR_WORK_DIRS} ${MMSEG}/work_dirs
|
||||
```
|
||||
|
||||
### Testing on multiple GPUs
|
||||
|
||||
We provide `tools/dist_test.sh` to launch testing on multiple GPUs.
|
||||
The basic usage is as follows.
|
||||
|
||||
```shell
|
||||
sh tools/dist_test.sh ${CONFIG_FILE} ${CHECKPOINT_FILE} ${GPU_NUM} [optional arguments]
|
||||
```
|
||||
|
||||
Optional arguments remain the same as stated [above](#testing-on-a-single-gpu) and have additional arguments to specify the number of GPUs.
|
||||
|
||||
An example:
|
||||
|
||||
```shell
|
||||
./tools/dist_test.sh configs/pspnet/pspnet_r50-d8_4xb2-40k_cityscapes-512x1024.py \
|
||||
checkpoints/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth 4
|
||||
```
|
||||
|
||||
### Launch multiple jobs on a single machine
|
||||
|
||||
If you launch multiple jobs on a single machine, e.g., 2 jobs of 4-GPU training on a machine with 8 GPUs, you need to specify different ports (29500 by default) for each job to avoid communication conflict. Otherwise, there will be an error message saying `RuntimeError: Address already in use`.
|
||||
If you use `dist_train.sh` to launch training jobs, you can set the port in commands with the environment variable `PORT`.
|
||||
|
||||
```shell
|
||||
CUDA_VISIBLE_DEVICES=0,1,2,3 PORT=29500 sh tools/dist_train.sh ${CONFIG_FILE} 4
|
||||
CUDA_VISIBLE_DEVICES=4,5,6,7 PORT=29501 sh tools/dist_train.sh ${CONFIG_FILE} 4
|
||||
```
|
||||
|
||||
### Training with multiple machines
|
||||
|
||||
MMSegmentation relies on `torch.distributed` package for distributed training.
|
||||
Thus, as a basic usage, one can launch distributed training via PyTorch's [launch utility](https://pytorch.org/docs/stable/distributed.html#launch-utility).
|
||||
|
||||
If you launch with multiple machines simply connected with ethernet, you can simply run the following commands:
|
||||
On the first machine:
|
||||
|
||||
```shell
|
||||
NNODES=2 NODE_RANK=0 PORT=${MASTER_PORT} MASTER_ADDR=${MASTER_ADDR} sh tools/dist_train.sh ${CONFIG_FILE} ${GPUS}
|
||||
```
|
||||
|
||||
On the second machine:
|
||||
|
||||
```shell
|
||||
NNODES=2 NODE_RANK=1 PORT=${MASTER_PORT} MASTER_ADDR=${MASTER_ADDR} sh tools/dist_train.sh ${CONFIG_FILE} ${GPUS}
|
||||
```
|
||||
|
||||
Usually, it is slow if you do not have high-speed networking like InfiniBand.
|
||||
|
||||
## Manage jobs with Slurm
|
||||
|
||||
[Slurm](https://slurm.schedmd.com/) is a good job scheduling system for computing clusters.
|
||||
|
||||
### Training on a cluster with Slurm
|
||||
|
||||
On a cluster managed by Slurm, you can use `slurm_train.sh` to spawn training jobs. It supports both single-node and multi-node training.
|
||||
|
||||
The basic usage is as follows:
|
||||
|
||||
```shell
|
||||
[GPUS=${GPUS}] sh tools/slurm_train.sh ${PARTITION} ${JOB_NAME} ${CONFIG_FILE} [optional arguments]
|
||||
```
|
||||
|
||||
Below is an example of using 4 GPUs to train PSPNet on a Slurm partition named _dev_, and set the work-dir to some shared file systems.
|
||||
|
||||
```shell
|
||||
GPUS=4 sh tools/slurm_train.sh dev pspnet configs/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes.py --work-dir work_dir/pspnet
|
||||
```
|
||||
|
||||
You can check [the source code](../../../tools/slurm_train.sh) to review full arguments and environment variables.
|
||||
|
||||
### Testing on a cluster with Slurm
|
||||
|
||||
Similar to the training task, MMSegmentation provides `slurm_test.sh` to launch testing jobs.
|
||||
|
||||
The basic usage is as follows:
|
||||
|
||||
```shell
|
||||
[GPUS=${GPUS}] sh tools/slurm_test.sh ${PARTITION} ${JOB_NAME} ${CONFIG_FILE} ${CHECKPOINT_FILE} [optional arguments]
|
||||
```
|
||||
|
||||
You can check [the source code](../../../tools/slurm_test.sh) to review full arguments and environment variables.
|
||||
|
||||
**Note:** When using Slurm, the port option needs to be set in one of the following ways:
|
||||
|
||||
1. Set the port through `--cfg-options`. This is more recommended since it does not change the original configs.
|
||||
|
||||
```shell
|
||||
GPUS=4 GPUS_PER_NODE=4 sh tools/slurm_train.sh ${PARTITION} ${JOB_NAME} config1.py ${WORK_DIR} --cfg-options env_cfg.dist_cfg.port=29500
|
||||
GPUS=4 GPUS_PER_NODE=4 sh tools/slurm_train.sh ${PARTITION} ${JOB_NAME} config2.py ${WORK_DIR} --cfg-options env_cfg.dist_cfg.port=29501
|
||||
```
|
||||
|
||||
2. Modify the config files to set different communication ports.
|
||||
In `config1.py`:
|
||||
|
||||
```python
|
||||
enf_cfg = dict(dist_cfg=dict(backend='nccl', port=29500))
|
||||
```
|
||||
|
||||
In `config2.py`:
|
||||
|
||||
```python
|
||||
enf_cfg = dict(dist_cfg=dict(backend='nccl', port=29501))
|
||||
```
|
||||
|
||||
Then you can launch two jobs with config1.py and config2.py.
|
||||
|
||||
```shell
|
||||
CUDA_VISIBLE_DEVICES=0,1,2,3 GPUS=4 sh tools/slurm_train.sh ${PARTITION} ${JOB_NAME} config1.py ${WORK_DIR}
|
||||
CUDA_VISIBLE_DEVICES=4,5,6,7 GPUS=4 sh tools/slurm_train.sh ${PARTITION} ${JOB_NAME} config2.py ${WORK_DIR}
|
||||
```
|
||||
|
||||
3. Set the port in the command using the environment variable 'MASTER_PORT':
|
||||
|
||||
```shell
|
||||
CUDA_VISIBLE_DEVICES=0,1,2,3 GPUS=4 MASTER_PORT=29500 sh tools/slurm_train.sh ${PARTITION} ${JOB_NAME} config1.py ${WORK_DIR}
|
||||
CUDA_VISIBLE_DEVICES=4,5,6,7 GPUS=4 MASTER_PORT=29501 sh tools/slurm_train.sh ${PARTITION} ${JOB_NAME} config2.py ${WORK_DIR}
|
||||
```
|
||||
|
||||
## Testing and saving segment files
|
||||
|
||||
### Basic Usage
|
||||
|
||||
When you want to save the results, you can use `--out` to specify the output directory.
|
||||
|
||||
```shell
|
||||
python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} --out ${OUTPUT_DIR}
|
||||
```
|
||||
|
||||
Here is an example to save the predicted results from model `fcn_r50-d8_4xb4-80k_ade20k-512x512` on ADE20k validatation dataset.
|
||||
|
||||
```shell
|
||||
python tools/test.py configs/fcn/fcn_r50-d8_4xb4-80k_ade20k-512x512.py ckpt/fcn_r50-d8_512x512_80k_ade20k_20200614_144016-f8ac5082.pth --out work_dirs/format_results
|
||||
```
|
||||
|
||||
You also can modify the config file to define `output_dir`. We also take
|
||||
`fcn_r50-d8_4xb4-80k_ade20k-512x512` as example just add
|
||||
`test_evaluator` in `configs/fcn/fcn_r50-d8_4xb4-80k_ade20k-512x512.py`
|
||||
|
||||
```python
|
||||
test_evaluator = dict(type='IoUMetric', iou_metrics=['mIoU'], output_dir='work_dirs/format_results')
|
||||
```
|
||||
|
||||
then run command without `--out`:
|
||||
|
||||
```shell
|
||||
python tools/test.py configs/fcn/fcn_r50-d8_4xb4-80k_ade20k-512x512.py ckpt/fcn_r50-d8_512x512_80k_ade20k_20200614_144016-f8ac5082.pth
|
||||
```
|
||||
|
||||
If you would like to only save the predicted results without evaluation as annotation is not released by the official dataset, you can set `format_only=True` and modify `test_dataloader`.
|
||||
As there is no annotation in dataset, we remove `dict(type='LoadAnnotations')` from `test_dataloader` Here is the example configuration:
|
||||
|
||||
```python
|
||||
test_evaluator = dict(
|
||||
type='IoUMetric',
|
||||
iou_metrics=['mIoU'],
|
||||
format_only=True,
|
||||
output_dir='work_dirs/format_results')
|
||||
test_dataloader = dict(
|
||||
batch_size=1,
|
||||
num_workers=4,
|
||||
persistent_workers=True,
|
||||
sampler=dict(type='DefaultSampler', shuffle=False),
|
||||
dataset=dict(
|
||||
type = 'ADE20KDataset'
|
||||
data_root='data/ade/release_test',
|
||||
data_prefix=dict(img_path='testing'),
|
||||
# we don't load annotation in test transform pipeline.
|
||||
pipeline=[
|
||||
dict(type='LoadImageFromFile'),
|
||||
dict(type='Resize', scale=(2048, 512), keep_ratio=True),
|
||||
dict(type='PackSegInputs')
|
||||
]))
|
||||
```
|
||||
|
||||
then run test command:
|
||||
|
||||
```shell
|
||||
python tools/test.py configs/fcn/fcn_r50-d8_4xb4-80k_ade20k-512x512.py ckpt/fcn_r50-d8_512x512_80k_ade20k_20200614_144016-f8ac5082.pth
|
||||
```
|
||||
|
||||
### Testing Cityscape dataset and save predicted segment files
|
||||
|
||||
We recommend `CityscapesMetric` which is the wrapper of Cityscapes'sdk, when you want to
|
||||
save the predicted results of Cityscape test dataset to submit them in [Cityscape test server](https://www.cityscapes-dataset.com/submit/). Here is the example configuration:
|
||||
|
||||
```python
|
||||
test_evaluator = dict(
|
||||
type='CityscapesMetric',
|
||||
format_only=True,
|
||||
keep_results=True,
|
||||
output_dir='work_dirs/format_results')
|
||||
test_dataloader = dict(
|
||||
batch_size=1,
|
||||
num_workers=4,
|
||||
persistent_workers=True,
|
||||
sampler=dict(type='DefaultSampler', shuffle=False),
|
||||
dataset=dict(
|
||||
type='CityscapesDataset',
|
||||
data_root='data/cityscapes/',
|
||||
data_prefix=dict(img_path='leftImg8bit/test'),
|
||||
pipeline=[
|
||||
dict(type='LoadImageFromFile'),
|
||||
dict(type='Resize', scale=(2048, 1024), keep_ratio=True),
|
||||
dict(type='PackSegInputs')
|
||||
]))
|
||||
```
|
||||
|
||||
then run test command, for example:
|
||||
|
||||
```shell
|
||||
python tools/test.py configs/fcn/fcn_r18-d8_4xb2-80k_cityscapes-512x1024.py ckpt/fcn_r18-d8_512x1024_80k_cityscapes_20201225_021327-6c50f8b4.pth
|
||||
```
|
||||
255
Seg_All_In_One_MMSeg/docs/en/user_guides/5_deployment.md
Normal file
255
Seg_All_In_One_MMSeg/docs/en/user_guides/5_deployment.md
Normal file
@@ -0,0 +1,255 @@
|
||||
# Tutorial 5: Model Deployment
|
||||
|
||||
# MMSegmentation Model Deployment
|
||||
|
||||
- [Tutorial 5: Model Deployment](#tutorial-5-model-deployment)
|
||||
- [MMSegmentation Model Deployment](#mmsegmentation-model-deployment)
|
||||
- [Installation](#installation)
|
||||
- [Install mmseg](#install-mmseg)
|
||||
- [Install mmdeploy](#install-mmdeploy)
|
||||
- [Convert model](#convert-model)
|
||||
- [Model specification](#model-specification)
|
||||
- [Model inference](#model-inference)
|
||||
- [Backend model inference](#backend-model-inference)
|
||||
- [SDK model inference](#sdk-model-inference)
|
||||
- [Supported models](#supported-models)
|
||||
- [Note](#note)
|
||||
|
||||
______________________________________________________________________
|
||||
|
||||
[MMSegmentation](https://github.com/open-mmlab/mmsegmentation/tree/main), also known as `mmseg`, is an open source semantic segmentation toolbox based on Pytorch. It's a part of the [OpenMMLab](<(https://openmmlab.com/)>) object.
|
||||
|
||||
## Installation
|
||||
|
||||
### Install mmseg
|
||||
|
||||
Please follow the [Installation Guide](https://mmsegmentation.readthedocs.io/en/latest/get_started.html).
|
||||
|
||||
### Install mmdeploy
|
||||
|
||||
`mmdeploy` can be installed as follows:
|
||||
|
||||
**Option 1:** Install precompiled package
|
||||
|
||||
Please follow the [Installation overview](https://mmdeploy.readthedocs.io/zh_CN/latest/get_started.html#mmdeploy)
|
||||
|
||||
**Option 2:** Automatic Installation script
|
||||
|
||||
If the deployment platform is **Ubuntu 18.04 +**, please follow the [scription installation](../01-how-to-build/build_from_script.md) to install.
|
||||
For example, the following commands describe how to install mmdeploy and inference engine-`ONNX Runtime`.
|
||||
|
||||
```shell
|
||||
git clone --recursive -b main https://github.com/open-mmlab/mmdeploy.git
|
||||
cd mmdeploy
|
||||
python3 tools/scripts/build_ubuntu_x64_ort.py $(nproc)
|
||||
export PYTHONPATH=$(pwd)/build/lib:$PYTHONPATH
|
||||
export LD_LIBRARY_PATH=$(pwd)/../mmdeploy-dep/onnxruntime-linux-x64-1.8.1/lib/:$LD_LIBRARY_PATH
|
||||
```
|
||||
|
||||
**NOTE**:
|
||||
|
||||
- Add `$(pwd)/build/lib` to `PYTHONPATH`, can loading mmdeploy SDK python package `mmdeploy_runtime`. See [SDK model inference](#SDK-model-inference) for more information.
|
||||
- With [ONNX Runtime model inference](#Backend-model-inference), need to load custom operator library and add ONNX Runtime Library's PATH to `LD_LIBRARY_PATH`.
|
||||
|
||||
**Option 3:** Install with mim
|
||||
|
||||
1. Use mim to install mmcv
|
||||
|
||||
```shell
|
||||
pip install -U openmim
|
||||
mim install "mmcv>=2.0.0rc2"
|
||||
```
|
||||
|
||||
2. Install mmdeploy
|
||||
|
||||
```shell
|
||||
git clone https://github.com/open-mmlab/mmdeploy.git
|
||||
cd mmdeploy
|
||||
mim install -e .
|
||||
```
|
||||
|
||||
**Option 4:** Build MMDeploy from source
|
||||
|
||||
If the first three methods aren't suitable, please [Build MMDeploy from source](<(../01-how-to-build/build_from_source.md)>)
|
||||
|
||||
## Convert model
|
||||
|
||||
[tools/deploy.py](https://github.com/open-mmlab/mmdeploy/tree/main/tools/deploy.py) can convert mmseg Model to backend model conveniently. See [this](https://github.com/open-mmlab/mmdeploy/tree/main/docs/en/02-how-to-run/convert_model.md#usage) for detailed information.
|
||||
|
||||
Then convert `unet` to onnx model as follows:
|
||||
|
||||
```shell
|
||||
cd mmdeploy
|
||||
|
||||
# download unet model from mmseg model zoo
|
||||
mim download mmsegmentation --config unet-s5-d16_fcn_4xb4-160k_cityscapes-512x1024 --dest .
|
||||
|
||||
# convert mmseg model to onnxruntime model with dynamic shape
|
||||
python tools/deploy.py \
|
||||
configs/mmseg/segmentation_onnxruntime_dynamic.py \
|
||||
unet-s5-d16_fcn_4xb4-160k_cityscapes-512x1024.py \
|
||||
fcn_unet_s5-d16_4x4_512x1024_160k_cityscapes_20211210_145204-6860854e.pth \
|
||||
demo/resources/cityscapes.png \
|
||||
--work-dir mmdeploy_models/mmseg/ort \
|
||||
--device cpu \
|
||||
--show \
|
||||
--dump-info
|
||||
```
|
||||
|
||||
It is crucial to specify the correct deployment config during model conversion. MMDeploy has already provided builtin deployment config [files](https://github.com/open-mmlab/mmdeploy/tree/main/configs/mmseg) of all supported backends for mmsegmentation, under which the config file path follows the pattern:
|
||||
|
||||
```
|
||||
segmentation_{backend}-{precision}_{static | dynamic}_{shape}.py
|
||||
```
|
||||
|
||||
- **{backend}:** inference backend, such as onnxruntime, tensorrt, pplnn, ncnn, openvino, coreml etc.
|
||||
- **{precision}:** fp16, int8. When it's empty, it means fp32
|
||||
- **{static | dynamic}:** static shape or dynamic shape
|
||||
- **{shape}:** input shape or shape range of a model
|
||||
|
||||
Therefore, in the above example, you can also convert `unet` to tensorrt-fp16 model by `segmentation_tensorrt-fp16_dynamic-512x1024-2048x2048.py`.
|
||||
|
||||
```{tip}
|
||||
When converting mmsegmentation models to tensorrt models, --device should be set to "cuda"
|
||||
```
|
||||
|
||||
## Model specification
|
||||
|
||||
Before moving on to model inference chapter, let's know more about the converted model structure which is very important for model inference.
|
||||
|
||||
The converted model locates in the working directory like `mmdeploy_models/mmseg/ort` in the previous example. It includes:
|
||||
|
||||
```
|
||||
mmdeploy_models/mmseg/ort
|
||||
├── deploy.json
|
||||
├── detail.json
|
||||
├── end2end.onnx
|
||||
└── pipeline.json
|
||||
```
|
||||
|
||||
in which,
|
||||
|
||||
- **end2end.onnx**: backend model which can be inferred by ONNX Runtime
|
||||
- ***xxx*.json**: the necessary information for mmdeploy SDK
|
||||
|
||||
The whole package **mmdeploy_models/mmseg/ort** is defined as **mmdeploy SDK model**, i.e., **mmdeploy SDK model** includes both backend model and inference meta information.
|
||||
|
||||
## Model inference
|
||||
|
||||
### Backend model inference
|
||||
|
||||
Take the previous converted `end2end.onnx` model as an example, you can use the following code to inference the model and visualize the results:
|
||||
|
||||
```python
|
||||
from mmdeploy.apis.utils import build_task_processor
|
||||
from mmdeploy.utils import get_input_shape, load_config
|
||||
import torch
|
||||
|
||||
deploy_cfg = 'configs/mmseg/segmentation_onnxruntime_dynamic.py'
|
||||
model_cfg = './unet-s5-d16_fcn_4xb4-160k_cityscapes-512x1024.py'
|
||||
device = 'cpu'
|
||||
backend_model = ['./mmdeploy_models/mmseg/ort/end2end.onnx']
|
||||
image = './demo/resources/cityscapes.png'
|
||||
|
||||
# read deploy_cfg and model_cfg
|
||||
deploy_cfg, model_cfg = load_config(deploy_cfg, model_cfg)
|
||||
|
||||
# build task and backend model
|
||||
task_processor = build_task_processor(model_cfg, deploy_cfg, device)
|
||||
model = task_processor.build_backend_model(backend_model)
|
||||
|
||||
# process input image
|
||||
input_shape = get_input_shape(deploy_cfg)
|
||||
model_inputs, _ = task_processor.create_input(image, input_shape)
|
||||
|
||||
# do model inference
|
||||
with torch.no_grad():
|
||||
result = model.test_step(model_inputs)
|
||||
|
||||
# visualize results
|
||||
task_processor.visualize(
|
||||
image=image,
|
||||
model=model,
|
||||
result=result[0],
|
||||
window_name='visualize',
|
||||
output_file='./output_segmentation.png')
|
||||
```
|
||||
|
||||
### SDK model inference
|
||||
|
||||
You can also perform SDK model inference like following:
|
||||
|
||||
```python
|
||||
from mmdeploy_runtime import Segmentor
|
||||
import cv2
|
||||
import numpy as np
|
||||
|
||||
img = cv2.imread('./demo/resources/cityscapes.png')
|
||||
|
||||
# create a classifier
|
||||
segmentor = Segmentor(model_path='./mmdeploy_models/mmseg/ort', device_name='cpu', device_id=0)
|
||||
# perform inference
|
||||
seg = segmentor(img)
|
||||
|
||||
# visualize inference result
|
||||
## random a palette with size 256x3
|
||||
palette = np.random.randint(0, 256, size=(256, 3))
|
||||
color_seg = np.zeros((seg.shape[0], seg.shape[1], 3), dtype=np.uint8)
|
||||
for label, color in enumerate(palette):
|
||||
color_seg[seg == label, :] = color
|
||||
# convert to BGR
|
||||
color_seg = color_seg[..., ::-1]
|
||||
img = img * 0.5 + color_seg * 0.5
|
||||
img = img.astype(np.uint8)
|
||||
cv2.imwrite('output_segmentation.png', img)
|
||||
```
|
||||
|
||||
Besides python API, mmdeploy SDK also provides other FFI (Foreign Function Interface), such as C, C++, C#, Java and so on. You can learn their usage from [demo](https://github.com/open-mmlab/mmdeploy/tree/main/demo)
|
||||
|
||||
## Supported models
|
||||
|
||||
| Model | TorchScript | OnnxRuntime | TensorRT | ncnn | PPLNN | OpenVino |
|
||||
| :-------------------------------------------------------------------------------------------------------- | :---------: | :---------: | :------: | :--: | :---: | :------: |
|
||||
| [FCN](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/fcn) | Y | Y | Y | Y | Y | Y |
|
||||
| [PSPNet](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/pspnet)[\*](#static_shape) | Y | Y | Y | Y | Y | Y |
|
||||
| [DeepLabV3](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/deeplabv3) | Y | Y | Y | Y | Y | Y |
|
||||
| [DeepLabV3+](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/deeplabv3plus) | Y | Y | Y | Y | Y | Y |
|
||||
| [Fast-SCNN](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/fastscnn)[\*](#static_shape) | Y | Y | Y | N | Y | Y |
|
||||
| [UNet](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/unet) | Y | Y | Y | Y | Y | Y |
|
||||
| [ANN](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/ann)[\*](#static_shape) | Y | Y | Y | N | N | N |
|
||||
| [APCNet](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/apcnet) | Y | Y | Y | Y | N | N |
|
||||
| [BiSeNetV1](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/bisenetv1) | Y | Y | Y | Y | N | Y |
|
||||
| [BiSeNetV2](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/bisenetv2) | Y | Y | Y | Y | N | Y |
|
||||
| [CGNet](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/cgnet) | Y | Y | Y | Y | N | Y |
|
||||
| [DMNet](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/dmnet) | ? | Y | N | N | N | N |
|
||||
| [DNLNet](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/dnlnet) | ? | Y | Y | Y | N | Y |
|
||||
| [EMANet](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/emanet) | Y | Y | Y | N | N | Y |
|
||||
| [EncNet](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/encnet) | Y | Y | Y | N | N | Y |
|
||||
| [ERFNet](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/erfnet) | Y | Y | Y | Y | N | Y |
|
||||
| [FastFCN](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/fastfcn) | Y | Y | Y | Y | N | Y |
|
||||
| [GCNet](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/gcnet) | Y | Y | Y | N | N | N |
|
||||
| [ICNet](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/icnet)[\*](#static_shape) | Y | Y | Y | N | N | Y |
|
||||
| [ISANet](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/isanet)[\*](#static_shape) | N | Y | Y | N | N | Y |
|
||||
| [NonLocal Net](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/nonlocal_net) | ? | Y | Y | Y | N | Y |
|
||||
| [OCRNet](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/ocrnet) | Y | Y | Y | Y | N | Y |
|
||||
| [PointRend](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/point_rend)[\*](#static_shape) | Y | Y | Y | N | N | N |
|
||||
| [Semantic FPN](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/sem_fpn) | Y | Y | Y | Y | N | Y |
|
||||
| [STDC](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/stdc) | Y | Y | Y | Y | N | Y |
|
||||
| [UPerNet](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/upernet)[\*](#static_shape) | N | Y | Y | N | N | N |
|
||||
| [DANet](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/danet) | ? | Y | Y | N | N | Y |
|
||||
| [Segmenter](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/segmenter)[\*](#static_shape) | N | Y | Y | Y | N | Y |
|
||||
| [SegFormer](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/segformer)[\*](#static_shape) | ? | Y | Y | N | N | Y |
|
||||
| [SETR](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/setr) | ? | Y | N | N | N | Y |
|
||||
| [CCNet](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/ccnet) | ? | N | N | N | N | N |
|
||||
| [PSANet](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/psanet) | ? | N | N | N | N | N |
|
||||
| [DPT](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/dpt) | ? | N | N | N | N | N |
|
||||
|
||||
## Note
|
||||
|
||||
- All mmseg models only support the 'whole' inference mode.
|
||||
|
||||
- <i id=“static_shape”>PSPNet,Fast-SCNN</i> only supports static input, because most inference framework's [nn.AdaptiveAvgPool2d](https://github.com/open-mmlab/mmsegmentation/blob/0c87f7a0c9099844eff8e90fa3db5b0d0ca02fee/mmseg/models/decode_heads/psp_head.py#L38) don't support dynamic input。
|
||||
|
||||
- For models that only support static shapes, should use the static shape deployment config file, such as `configs/mmseg/segmentation_tensorrt_static-1024x2048.py`
|
||||
|
||||
- To deploy models to generate probabilistic feature maps, please add `codebase_config = dict(with_argmax=False)` to deployment config file.
|
||||
21
Seg_All_In_One_MMSeg/docs/en/user_guides/index.rst
Normal file
21
Seg_All_In_One_MMSeg/docs/en/user_guides/index.rst
Normal file
@@ -0,0 +1,21 @@
|
||||
Train & Test
|
||||
**************
|
||||
|
||||
.. toctree::
|
||||
:maxdepth: 1
|
||||
|
||||
1_config.md
|
||||
2_dataset_prepare.md
|
||||
3_inference.md
|
||||
4_train_test.md
|
||||
|
||||
Useful Tools
|
||||
*************
|
||||
|
||||
.. toctree::
|
||||
:maxdepth: 2
|
||||
|
||||
visualization.md
|
||||
useful_tools.md
|
||||
deployment.md
|
||||
visualization_feature_map.md
|
||||
245
Seg_All_In_One_MMSeg/docs/en/user_guides/useful_tools.md
Normal file
245
Seg_All_In_One_MMSeg/docs/en/user_guides/useful_tools.md
Normal file
@@ -0,0 +1,245 @@
|
||||
# \[WIP\] Useful Tools
|
||||
|
||||
Apart from training/testing scripts, We provide lots of useful tools under the
|
||||
`tools/` directory.
|
||||
|
||||
## Analysis Tools
|
||||
|
||||
### Plot training logs
|
||||
|
||||
`tools/analyze_logs.py` plots loss/mIoU curves given a training log file. `pip install seaborn` first to install the dependency.
|
||||
|
||||
```shell
|
||||
python tools/analysis_tools/analyze_logs.py xxx.json [--keys ${KEYS}] [--legend ${LEGEND}] [--backend ${BACKEND}] [--style ${STYLE}] [--out ${OUT_FILE}]
|
||||
```
|
||||
|
||||
Examples:
|
||||
|
||||
- Plot the mIoU, mAcc, aAcc metrics.
|
||||
|
||||
```shell
|
||||
python tools/analysis_tools/analyze_logs.py log.json --keys mIoU mAcc aAcc --legend mIoU mAcc aAcc
|
||||
```
|
||||
|
||||
- Plot loss metric.
|
||||
|
||||
```shell
|
||||
python tools/analysis_tools/analyze_logs.py log.json --keys loss --legend loss
|
||||
```
|
||||
|
||||
### Confusion Matrix (experimental)
|
||||
|
||||
In order to generate and plot a `nxn` confusion matrix where `n` is the number of classes, you can follow the steps:
|
||||
|
||||
#### 1.Generate a prediction result in pkl format using `test.py`
|
||||
|
||||
```shell
|
||||
python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [--out ${PATH_TO_RESULT_FILE}]
|
||||
```
|
||||
|
||||
Example:
|
||||
|
||||
```shell
|
||||
python tools/test.py \
|
||||
configs/fcn/fcn_r50-d8_4xb2-40k_cityscapes-512x1024.py \
|
||||
checkpoint/fcn_r50-d8_512x1024_40k_cityscapes_20200604_192608-efe53f0d.pth \
|
||||
--out result/pred_result.pkl
|
||||
```
|
||||
|
||||
#### 2. Use `confusion_matrix.py` to generate and plot a confusion matrix
|
||||
|
||||
```shell
|
||||
python tools/confusion_matrix.py ${CONFIG_FILE} ${PATH_TO_RESULT_FILE} ${SAVE_DIR} --show
|
||||
```
|
||||
|
||||
Description of arguments:
|
||||
|
||||
- `config`: Path to the test config file.
|
||||
- `prediction_path`: Path to the prediction .pkl result.
|
||||
- `save_dir`: Directory where confusion matrix will be saved.
|
||||
- `--show`: Enable result visualize.
|
||||
- `--color-theme`: Theme of the matrix color map.
|
||||
- `--cfg_options`: Custom options to replace the config file.
|
||||
|
||||
Example:
|
||||
|
||||
```shell
|
||||
python tools/confusion_matrix.py \
|
||||
configs/fcn/fcn_r50-d8_512x1024_40k_cityscapes.py \
|
||||
result/pred_result.pkl \
|
||||
result/confusion_matrix \
|
||||
--show
|
||||
```
|
||||
|
||||
### Get the FLOPs and params (experimental)
|
||||
|
||||
We provide a script adapted from [flops-counter.pytorch](https://github.com/sovrasov/flops-counter.pytorch) to compute the FLOPs and params of a given model.
|
||||
|
||||
```shell
|
||||
python tools/analysis_tools/get_flops.py ${CONFIG_FILE} [--shape ${INPUT_SHAPE}]
|
||||
```
|
||||
|
||||
You will get the result like this.
|
||||
|
||||
```none
|
||||
==============================
|
||||
Input shape: (3, 2048, 1024)
|
||||
Flops: 1429.68 GMac
|
||||
Params: 48.98 M
|
||||
==============================
|
||||
```
|
||||
|
||||
:::{note}
|
||||
This tool is still experimental and we do not guarantee that the number is correct. You may well use the result for simple comparisons, but double check it before you adopt it in technical reports or papers.
|
||||
:::
|
||||
|
||||
(1) FLOPs are related to the input shape while parameters are not. The default input shape is (1, 3, 1280, 800).
|
||||
(2) Some operators are not counted into FLOPs like GN and custom operators.
|
||||
|
||||
## Miscellaneous
|
||||
|
||||
### Publish a model
|
||||
|
||||
Before you upload a model to AWS, you may want to
|
||||
(1) convert model weights to CPU tensors, (2) delete the optimizer states and
|
||||
(3) compute the hash of the checkpoint file and append the hash id to the filename.
|
||||
|
||||
```shell
|
||||
python tools/misc/publish_model.py ${INPUT_FILENAME} ${OUTPUT_FILENAME}
|
||||
```
|
||||
|
||||
E.g.,
|
||||
|
||||
```shell
|
||||
python tools/publish_model.py work_dirs/pspnet/latest.pth psp_r50_512x1024_40k_cityscapes.pth
|
||||
```
|
||||
|
||||
The final output filename will be `psp_r50_512x1024_40k_cityscapes-{hash id}.pth`.
|
||||
|
||||
### Print the entire config
|
||||
|
||||
`tools/misc/print_config.py` prints the whole config verbatim, expanding all its
|
||||
imports.
|
||||
|
||||
```shell
|
||||
python tools/misc/print_config.py \
|
||||
${CONFIG} \
|
||||
--graph \
|
||||
--cfg-options ${OPTIONS [OPTIONS...]} \
|
||||
```
|
||||
|
||||
Description of arguments:
|
||||
|
||||
- `config` : The path of a pytorch model config file.
|
||||
- `--graph` : Determines whether to print the models graph.
|
||||
- `--cfg-options`: Custom options to replace the config file.
|
||||
|
||||
## Model conversion
|
||||
|
||||
`tools/model_converters/` provide several scripts to convert pretrain models released by other repos to MMSegmentation style.
|
||||
|
||||
### ViT Swin MiT Transformer Models
|
||||
|
||||
- ViT
|
||||
|
||||
`tools/model_converters/vit2mmseg.py` convert keys in timm pretrained vit models to MMSegmentation style.
|
||||
|
||||
```shell
|
||||
python tools/model_converters/vit2mmseg.py ${SRC} ${DST}
|
||||
```
|
||||
|
||||
- Swin
|
||||
|
||||
`tools/model_converters/swin2mmseg.py` convert keys in official pretrained swin models to MMSegmentation style.
|
||||
|
||||
```shell
|
||||
python tools/model_converters/swin2mmseg.py ${SRC} ${DST}
|
||||
```
|
||||
|
||||
- SegFormer
|
||||
|
||||
`tools/model_converters/mit2mmseg.py` convert keys in official pretrained mit models to MMSegmentation style.
|
||||
|
||||
```shell
|
||||
python tools/model_converters/mit2mmseg.py ${SRC} ${DST}
|
||||
```
|
||||
|
||||
## Model Serving
|
||||
|
||||
In order to serve an `MMSegmentation` model with [`TorchServe`](https://pytorch.org/serve/), you can follow the steps:
|
||||
|
||||
### 1. Convert model from MMSegmentation to TorchServe
|
||||
|
||||
```shell
|
||||
python tools/torchserve/mmseg2torchserve.py ${CONFIG_FILE} ${CHECKPOINT_FILE} \
|
||||
--output-folder ${MODEL_STORE} \
|
||||
--model-name ${MODEL_NAME}
|
||||
```
|
||||
|
||||
:::{note}
|
||||
${MODEL_STORE} needs to be an absolute path to a folder.
|
||||
:::
|
||||
|
||||
### 2. Build `mmseg-serve` docker image
|
||||
|
||||
```shell
|
||||
docker build -t mmseg-serve:latest docker/serve/
|
||||
```
|
||||
|
||||
### 3. Run `mmseg-serve`
|
||||
|
||||
Check the official docs for [running TorchServe with docker](https://github.com/pytorch/serve/blob/master/docker/README.md#running-torchserve-in-a-production-docker-environment).
|
||||
|
||||
In order to run in GPU, you need to install [nvidia-docker](https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/install-guide.html). You can omit the `--gpus` argument in order to run in CPU.
|
||||
|
||||
Example:
|
||||
|
||||
```shell
|
||||
docker run --rm \
|
||||
--cpus 8 \
|
||||
--gpus device=0 \
|
||||
-p8080:8080 -p8081:8081 -p8082:8082 \
|
||||
--mount type=bind,source=$MODEL_STORE,target=/home/model-server/model-store \
|
||||
mmseg-serve:latest
|
||||
```
|
||||
|
||||
[Read the docs](https://github.com/pytorch/serve/blob/072f5d088cce9bb64b2a18af065886c9b01b317b/docs/rest_api.md) about the Inference (8080), Management (8081) and Metrics (8082) APIs
|
||||
|
||||
### 4. Test deployment
|
||||
|
||||
```shell
|
||||
curl -O https://raw.githubusercontent.com/open-mmlab/mmsegmentation/master/resources/3dogs.jpg
|
||||
curl http://127.0.0.1:8080/predictions/${MODEL_NAME} -T 3dogs.jpg -o 3dogs_mask.png
|
||||
```
|
||||
|
||||
The response will be a ".png" mask.
|
||||
|
||||
You can visualize the output as follows:
|
||||
|
||||
```python
|
||||
import matplotlib.pyplot as plt
|
||||
import mmcv
|
||||
plt.imshow(mmcv.imread("3dogs_mask.png", "grayscale"))
|
||||
plt.show()
|
||||
```
|
||||
|
||||
You should see something similar to:
|
||||
|
||||

|
||||
|
||||
And you can use `test_torchserve.py` to compare result of torchserve and pytorch, and visualize them.
|
||||
|
||||
```shell
|
||||
python tools/torchserve/test_torchserve.py ${IMAGE_FILE} ${CONFIG_FILE} ${CHECKPOINT_FILE} ${MODEL_NAME}
|
||||
[--inference-addr ${INFERENCE_ADDR}] [--result-image ${RESULT_IMAGE}] [--device ${DEVICE}]
|
||||
```
|
||||
|
||||
Example:
|
||||
|
||||
```shell
|
||||
python tools/torchserve/test_torchserve.py \
|
||||
demo/demo.png \
|
||||
configs/fcn/fcn_r50-d8_512x1024_40k_cityscapes.py \
|
||||
checkpoint/fcn_r50-d8_512x1024_40k_cityscapes_20200604_192608-efe53f0d.pth \
|
||||
fcn
|
||||
```
|
||||
174
Seg_All_In_One_MMSeg/docs/en/user_guides/visualization.md
Normal file
174
Seg_All_In_One_MMSeg/docs/en/user_guides/visualization.md
Normal file
@@ -0,0 +1,174 @@
|
||||
# Visualization
|
||||
|
||||
MMSegmentation 1.x provides convenient ways for monitoring training status or visualizing data and model predictions.
|
||||
|
||||
## Training status Monitor
|
||||
|
||||
MMSegmentation 1.x uses TensorBoard to monitor training status.
|
||||
|
||||
### TensorBoard Configuration
|
||||
|
||||
Install TensorBoard following [official instructions](https://www.tensorflow.org/install) e.g.
|
||||
|
||||
```shell
|
||||
pip install tensorboardX
|
||||
pip install future tensorboard
|
||||
```
|
||||
|
||||
Add `TensorboardVisBackend` in `vis_backend` of `visualizer` in `default_runtime.py` config file:
|
||||
|
||||
```python
|
||||
vis_backends = [dict(type='LocalVisBackend'),
|
||||
dict(type='TensorboardVisBackend')]
|
||||
visualizer = dict(
|
||||
type='SegLocalVisualizer', vis_backends=vis_backends, name='visualizer')
|
||||
```
|
||||
|
||||
### Examining scalars in TensorBoard
|
||||
|
||||
Launch training experiment e.g.
|
||||
|
||||
```shell
|
||||
python tools/train.py configs/pspnet/pspnet_r50-d8_4xb4-80k_ade20k-512x512.py --work-dir work_dir/test_visual
|
||||
```
|
||||
|
||||
Find the `vis_data` path of `work_dir` after starting training, for example, the vis_data path of this particular test is as follows:
|
||||
|
||||
```shell
|
||||
work_dirs/test_visual/20220810_115248/vis_data
|
||||
```
|
||||
|
||||
The scalar file in vis_data path includes learning rate, losses and data_time etc, also record metrics results and you can refer [logging tutorial](https://mmengine.readthedocs.io/en/latest/advanced_tutorials/logging.html) in MMEngine to log custom data. The tensorboard visualization results are executed with the following command:
|
||||
|
||||
```shell
|
||||
tensorboard --logdir work_dirs/test_visual/20220810_115248/vis_data
|
||||
```
|
||||
|
||||
## Data and Results visualization
|
||||
|
||||
### Visualizer Data Samples during Model Testing or Validation
|
||||
|
||||
MMSegmentation provides `SegVisualizationHook` which is a [hook](https://github.com/open-mmlab/mmengine/blob/main/docs/en/tutorials/hook.md) working to visualize ground truth and prediction of segmentation during model testing and evaluation. Its configuration is in `default_hooks`, please see [Runner tutorial](https://github.com/open-mmlab/mmengine/blob/main/docs/en/tutorials/runner.md) for more details.
|
||||
|
||||
For example, In `_base_/schedules/schedule_20k.py`, modify the `SegVisualizationHook` configuration, set `draw` to `True` to enable the storage of network inference results, `interval` indicates the sampling interval of the prediction results, and when set to 1, each inference result of the network will be saved. `interval` is set to 50 by default:
|
||||
|
||||
```python
|
||||
default_hooks = dict(
|
||||
timer=dict(type='IterTimerHook'),
|
||||
logger=dict(type='LoggerHook', interval=50, log_metric_by_epoch=False),
|
||||
param_scheduler=dict(type='ParamSchedulerHook'),
|
||||
checkpoint=dict(type='CheckpointHook', by_epoch=False, interval=2000),
|
||||
sampler_seed=dict(type='DistSamplerSeedHook'),
|
||||
visualization=dict(type='SegVisualizationHook', draw=True, interval=1))
|
||||
|
||||
```
|
||||
|
||||
After launch training experiment, visualization results will be stored in the local folder in validation loop,
|
||||
or when launch evaluation a model on one dataset, the prediction results will be store in the local.
|
||||
The stored results of the local visualization are kept in `vis_image` under `$WORK_DIRS/vis_data`, e.g.:
|
||||
|
||||
```shell
|
||||
work_dirs/test_visual/20220810_115248/vis_data/vis_image
|
||||
```
|
||||
|
||||
In addition, if `TensorboardVisBackend` is add in `vis_backends`, like [above](#tensorboard-configuration),
|
||||
we can also run the following command to view them in TensorBoard:
|
||||
|
||||
```shell
|
||||
tensorboard --logdir work_dirs/test_visual/20220810_115248/vis_data
|
||||
```
|
||||
|
||||
### Visualize a Single Data Sample
|
||||
|
||||
If you want to visualize a single data sample, we suggest to use `SegLocalVisualizer`.
|
||||
|
||||
`SegLocalVisualizer` is child class inherits from `Visualizer` in MMEngine and works for MMSegmentation visualization, for more details about `Visualizer` please refer to [visualization tutorial](https://github.com/open-mmlab/mmengine/blob/main/docs/en/advanced_tutorials/visualization.md) in MMEngine.
|
||||
|
||||
Here is an example about `SegLocalVisualizer`, first you may download example data below by following commands:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://user-images.githubusercontent.com/24582831/189833109-eddad58f-f777-4fc0-b98a-6bd429143b06.png" width="70%"/>
|
||||
</div>
|
||||
|
||||
```shell
|
||||
wget https://user-images.githubusercontent.com/24582831/189833109-eddad58f-f777-4fc0-b98a-6bd429143b06.png --output-document aachen_000000_000019_leftImg8bit.png
|
||||
wget https://user-images.githubusercontent.com/24582831/189833143-15f60f8a-4d1e-4cbb-a6e7-5e2233869fac.png --output-document aachen_000000_000019_gtFine_labelTrainIds.png
|
||||
```
|
||||
|
||||
Then you can find their local path and use the scripts below to visualize:
|
||||
|
||||
```python
|
||||
import mmcv
|
||||
import os.path as osp
|
||||
import torch
|
||||
# `PixelData` is data structure for pixel-level annotations or predictions defined in MMEngine.
|
||||
# Please refer to below tutorial file of data structures in MMEngine:
|
||||
# https://github.com/open-mmlab/mmengine/tree/main/docs/en/advanced_tutorials/data_element.md
|
||||
|
||||
from mmengine.structures import PixelData
|
||||
|
||||
# `SegDataSample` is data structure interface between different components
|
||||
# defined in MMSegmentation, it includes ground truth, prediction and
|
||||
# predicted logits of semantic segmentation.
|
||||
# Please refer to below tutorial file of `SegDataSample` for more details:
|
||||
# https://github.com/open-mmlab/mmsegmentation/blob/1.x/docs/en/advanced_guides/structures.md
|
||||
|
||||
from mmseg.structures import SegDataSample
|
||||
from mmseg.visualization import SegLocalVisualizer
|
||||
|
||||
out_file = 'out_file_cityscapes'
|
||||
save_dir = './work_dirs'
|
||||
|
||||
image = mmcv.imread(
|
||||
osp.join(
|
||||
osp.dirname(__file__),
|
||||
'./aachen_000000_000019_leftImg8bit.png'
|
||||
),
|
||||
'color')
|
||||
sem_seg = mmcv.imread(
|
||||
osp.join(
|
||||
osp.dirname(__file__),
|
||||
'./aachen_000000_000019_gtFine_labelTrainIds.png' # noqa
|
||||
),
|
||||
'unchanged')
|
||||
sem_seg = torch.from_numpy(sem_seg)
|
||||
gt_sem_seg_data = dict(data=sem_seg)
|
||||
gt_sem_seg = PixelData(**gt_sem_seg_data)
|
||||
data_sample = SegDataSample()
|
||||
data_sample.gt_sem_seg = gt_sem_seg
|
||||
|
||||
seg_local_visualizer = SegLocalVisualizer(
|
||||
vis_backends=[dict(type='LocalVisBackend')],
|
||||
save_dir=save_dir)
|
||||
|
||||
# The meta information of dataset usually includes `classes` for class names and
|
||||
# `palette` for visualization color of each foreground.
|
||||
# All class names and palettes are defined in the file:
|
||||
# https://github.com/open-mmlab/mmsegmentation/blob/1.x/mmseg/utils/class_names.py
|
||||
|
||||
seg_local_visualizer.dataset_meta = dict(
|
||||
classes=('road', 'sidewalk', 'building', 'wall', 'fence',
|
||||
'pole', 'traffic light', 'traffic sign',
|
||||
'vegetation', 'terrain', 'sky', 'person', 'rider',
|
||||
'car', 'truck', 'bus', 'train', 'motorcycle',
|
||||
'bicycle'),
|
||||
palette=[[128, 64, 128], [244, 35, 232], [70, 70, 70],
|
||||
[102, 102, 156], [190, 153, 153], [153, 153, 153],
|
||||
[250, 170, 30], [220, 220, 0], [107, 142, 35],
|
||||
[152, 251, 152], [70, 130, 180], [220, 20, 60],
|
||||
[255, 0, 0], [0, 0, 142], [0, 0, 70],
|
||||
[0, 60, 100], [0, 80, 100], [0, 0, 230],
|
||||
[119, 11, 32]])
|
||||
# When `show=True`, the results would be shown directly,
|
||||
# else if `show=False`, the results would be saved in local directory folder.
|
||||
seg_local_visualizer.add_datasample(out_file, image,
|
||||
data_sample, show=False)
|
||||
```
|
||||
|
||||
Then the visualization result of image with its corresponding ground truth could be found in `./work_dirs/vis_data/vis_image/` whose name is `out_file_cityscapes_0.png`:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://user-images.githubusercontent.com/24582831/189835713-c0534054-4bfa-4b75-9254-0afbeb5ff02e.png" width="70%"/>
|
||||
</div>
|
||||
|
||||
If you would like to know more visualization usage, you can refer to [visualization tutorial](https://mmengine.readthedocs.io/en/latest/advanced_tutorials/visualization.html) in MMEngine.
|
||||
@@ -0,0 +1,201 @@
|
||||
# Wandb Feature Map Visualization
|
||||
|
||||
MMSegmentation 1.x provides backend support for Weights & Biases to facilitate visualization and management of project code results.
|
||||
|
||||
## Wandb Configuration
|
||||
|
||||
Install Weights & Biases following [official instructions](https://docs.wandb.ai/quickstart) e.g.
|
||||
|
||||
```shell
|
||||
pip install wandb
|
||||
wandb login
|
||||
```
|
||||
|
||||
Add `WandbVisBackend` in `vis_backend` of `visualizer` in `default_runtime.py` config file:
|
||||
|
||||
```python
|
||||
vis_backends=[dict(type='LocalVisBackend'),
|
||||
dict(type='TensorboardVisBackend'),
|
||||
dict(type='WandbVisBackend')]
|
||||
```
|
||||
|
||||
## Examining feature map visualization in Wandb
|
||||
|
||||
`SegLocalVisualizer` is child class inherits from `Visualizer` in MMEngine and works for MMSegmentation visualization, for more details about `Visualizer` please refer to [visualization tutorial](https://github.com/open-mmlab/mmengine/blob/main/docs/en/advanced_tutorials/visualization.md) in MMEngine.
|
||||
|
||||
Here is an example about `SegLocalVisualizer`, first you may download example data below by following commands:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://user-images.githubusercontent.com/24582831/189833109-eddad58f-f777-4fc0-b98a-6bd429143b06.png" width="70%"/>
|
||||
</div>
|
||||
|
||||
```shell
|
||||
wget https://user-images.githubusercontent.com/24582831/189833109-eddad58f-f777-4fc0-b98a-6bd429143b06.png --output-document aachen_000000_000019_leftImg8bit.png
|
||||
wget https://user-images.githubusercontent.com/24582831/189833143-15f60f8a-4d1e-4cbb-a6e7-5e2233869fac.png --output-document aachen_000000_000019_gtFine_labelTrainIds.png
|
||||
|
||||
wget https://download.openmmlab.com/mmsegmentation/v0.5/ann/ann_r50-d8_512x1024_40k_cityscapes/ann_r50-d8_512x1024_40k_cityscapes_20200605_095211-049fc292.pth
|
||||
|
||||
```
|
||||
|
||||
```python
|
||||
# Copyright (c) OpenMMLab. All rights reserved.
|
||||
from argparse import ArgumentParser
|
||||
from typing import Type
|
||||
|
||||
import mmcv
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
|
||||
from mmengine.model import revert_sync_batchnorm
|
||||
from mmengine.structures import PixelData
|
||||
from mmseg.apis import inference_model, init_model
|
||||
from mmseg.structures import SegDataSample
|
||||
from mmseg.utils import register_all_modules
|
||||
from mmseg.visualization import SegLocalVisualizer
|
||||
|
||||
|
||||
class Recorder:
|
||||
"""record the forward output feature map and save to data_buffer."""
|
||||
|
||||
def __init__(self) -> None:
|
||||
self.data_buffer = list()
|
||||
|
||||
def __enter__(self, ):
|
||||
self._data_buffer = list()
|
||||
|
||||
def record_data_hook(self, model: nn.Module, input: Type, output: Type):
|
||||
self.data_buffer.append(output)
|
||||
|
||||
def __exit__(self, *args, **kwargs):
|
||||
pass
|
||||
|
||||
|
||||
def visualize(args, model, recorder, result):
|
||||
seg_visualizer = SegLocalVisualizer(
|
||||
vis_backends=[dict(type='WandbVisBackend')],
|
||||
save_dir='temp_dir',
|
||||
alpha=0.5)
|
||||
seg_visualizer.dataset_meta = dict(
|
||||
classes=model.dataset_meta['classes'],
|
||||
palette=model.dataset_meta['palette'])
|
||||
|
||||
image = mmcv.imread(args.img, 'color')
|
||||
|
||||
seg_visualizer.add_datasample(
|
||||
name='predict',
|
||||
image=image,
|
||||
data_sample=result,
|
||||
draw_gt=False,
|
||||
draw_pred=True,
|
||||
wait_time=0,
|
||||
out_file=None,
|
||||
show=False)
|
||||
|
||||
# add feature map to wandb visualizer
|
||||
for i in range(len(recorder.data_buffer)):
|
||||
feature = recorder.data_buffer[i][0] # remove the batch
|
||||
drawn_img = seg_visualizer.draw_featmap(
|
||||
feature, image, channel_reduction='select_max')
|
||||
seg_visualizer.add_image(f'feature_map{i}', drawn_img)
|
||||
|
||||
if args.gt_mask:
|
||||
sem_seg = mmcv.imread(args.gt_mask, 'unchanged')
|
||||
sem_seg = torch.from_numpy(sem_seg)
|
||||
gt_mask = dict(data=sem_seg)
|
||||
gt_mask = PixelData(**gt_mask)
|
||||
data_sample = SegDataSample()
|
||||
data_sample.gt_sem_seg = gt_mask
|
||||
|
||||
seg_visualizer.add_datasample(
|
||||
name='gt_mask',
|
||||
image=image,
|
||||
data_sample=data_sample,
|
||||
draw_gt=True,
|
||||
draw_pred=False,
|
||||
wait_time=0,
|
||||
out_file=None,
|
||||
show=False)
|
||||
|
||||
seg_visualizer.add_image('image', image)
|
||||
|
||||
|
||||
def main():
|
||||
parser = ArgumentParser(
|
||||
description='Draw the Feature Map During Inference')
|
||||
parser.add_argument('img', help='Image file')
|
||||
parser.add_argument('config', help='Config file')
|
||||
parser.add_argument('checkpoint', help='Checkpoint file')
|
||||
parser.add_argument('--gt_mask', default=None, help='Path of gt mask file')
|
||||
parser.add_argument('--out-file', default=None, help='Path to output file')
|
||||
parser.add_argument(
|
||||
'--device', default='cuda:0', help='Device used for inference')
|
||||
parser.add_argument(
|
||||
'--opacity',
|
||||
type=float,
|
||||
default=0.5,
|
||||
help='Opacity of painted segmentation map. In (0, 1] range.')
|
||||
parser.add_argument(
|
||||
'--title', default='result', help='The image identifier.')
|
||||
args = parser.parse_args()
|
||||
|
||||
register_all_modules()
|
||||
|
||||
# build the model from a config file and a checkpoint file
|
||||
model = init_model(args.config, args.checkpoint, device=args.device)
|
||||
if args.device == 'cpu':
|
||||
model = revert_sync_batchnorm(model)
|
||||
|
||||
# show all named module in the model and use it in source list below
|
||||
for name, module in model.named_modules():
|
||||
print(name)
|
||||
|
||||
source = [
|
||||
'decode_head.fusion.stages.0.query_project.activate',
|
||||
'decode_head.context.stages.0.key_project.activate',
|
||||
'decode_head.context.bottleneck.activate'
|
||||
]
|
||||
source = dict.fromkeys(source)
|
||||
|
||||
count = 0
|
||||
recorder = Recorder()
|
||||
# registry the forward hook
|
||||
for name, module in model.named_modules():
|
||||
if name in source:
|
||||
count += 1
|
||||
module.register_forward_hook(recorder.record_data_hook)
|
||||
if count == len(source):
|
||||
break
|
||||
|
||||
with recorder:
|
||||
# test a single image, and record feature map to data_buffer
|
||||
result = inference_model(model, args.img)
|
||||
|
||||
visualize(args, model, recorder, result)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
main()
|
||||
|
||||
```
|
||||
|
||||
Save the above code as feature_map_visual.py and execute the following code in terminal
|
||||
|
||||
```shell
|
||||
python feature_map_visual.py ${image} ${config} ${checkpoint} [optional args]
|
||||
```
|
||||
|
||||
e.g
|
||||
|
||||
```shell
|
||||
python feature_map_visual.py \
|
||||
aachen_000000_000019_leftImg8bit.png \
|
||||
configs/ann/ann_r50-d8_4xb2-40k_cityscapes-512x1024.py \
|
||||
ann_r50-d8_512x1024_40k_cityscapes_20200605_095211-049fc292.pth \
|
||||
--gt_mask aachen_000000_000019_gtFine_labelTrainIds.png
|
||||
```
|
||||
|
||||
The visualized image result and its corresponding feature map will appear in the wandb account.
|
||||
|
||||
<div align=center>
|
||||
<img src="https://user-images.githubusercontent.com/76149310/217520321-647f5bf9-eef2-446d-a9e8-5ca7b621d500.png">
|
||||
</div>
|
||||
17
Seg_All_In_One_MMSeg/docs/zh_cn/.readthedocs.yaml
Normal file
17
Seg_All_In_One_MMSeg/docs/zh_cn/.readthedocs.yaml
Normal file
@@ -0,0 +1,17 @@
|
||||
version: 2
|
||||
|
||||
build:
|
||||
os: ubuntu-22.04
|
||||
tools:
|
||||
python: "3.8"
|
||||
|
||||
formats:
|
||||
- epub
|
||||
|
||||
sphinx:
|
||||
configuration: docs/zh_cn/conf.py
|
||||
|
||||
python:
|
||||
install:
|
||||
- requirements: requirements/docs.txt
|
||||
- requirements: requirements/readthedocs.txt
|
||||
20
Seg_All_In_One_MMSeg/docs/zh_cn/Makefile
Normal file
20
Seg_All_In_One_MMSeg/docs/zh_cn/Makefile
Normal file
@@ -0,0 +1,20 @@
|
||||
# Minimal makefile for Sphinx documentation
|
||||
#
|
||||
|
||||
# You can set these variables from the command line, and also
|
||||
# from the environment for the first two.
|
||||
SPHINXOPTS ?=
|
||||
SPHINXBUILD ?= sphinx-build
|
||||
SOURCEDIR = .
|
||||
BUILDDIR = _build
|
||||
|
||||
# Put it first so that "make" without argument is like "make help".
|
||||
help:
|
||||
@$(SPHINXBUILD) -M help "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
|
||||
|
||||
.PHONY: help Makefile
|
||||
|
||||
# Catch-all target: route all unknown targets to Sphinx using the new
|
||||
# "make mode" option. $(O) is meant as a shortcut for $(SPHINXOPTS).
|
||||
%: Makefile
|
||||
@$(SPHINXBUILD) -M $@ "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
|
||||
@@ -0,0 +1,6 @@
|
||||
.header-logo {
|
||||
background-image: url("../images/mmsegmentation.png");
|
||||
background-size: 201px 40px;
|
||||
height: 40px;
|
||||
width: 201px;
|
||||
}
|
||||
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 44 KiB |
199
Seg_All_In_One_MMSeg/docs/zh_cn/advanced_guides/add_datasets.md
Normal file
199
Seg_All_In_One_MMSeg/docs/zh_cn/advanced_guides/add_datasets.md
Normal file
@@ -0,0 +1,199 @@
|
||||
# 新增自定义数据集
|
||||
|
||||
## 新增自定义数据集
|
||||
|
||||
在这里,我们展示如何构建一个新的数据集。
|
||||
|
||||
1. 创建一个新文件 `mmseg/datasets/example.py`
|
||||
|
||||
```python
|
||||
from mmseg.registry import DATASETS
|
||||
from .basesegdataset import BaseSegDataset
|
||||
|
||||
|
||||
@DATASETS.register_module()
|
||||
class ExampleDataset(BaseSegDataset):
|
||||
|
||||
METAINFO = dict(
|
||||
classes=('xxx', 'xxx', ...),
|
||||
palette=[[x, x, x], [x, x, x], ...])
|
||||
|
||||
def __init__(self, arg1, arg2):
|
||||
pass
|
||||
```
|
||||
|
||||
2. 在 `mmseg/datasets/__init__.py` 中导入模块
|
||||
|
||||
```python
|
||||
from .example import ExampleDataset
|
||||
```
|
||||
|
||||
3. 通过创建一个新的数据集配置文件 `configs/_base_/datasets/example_dataset.py` 来使用它
|
||||
|
||||
```python
|
||||
dataset_type = 'ExampleDataset'
|
||||
data_root = 'data/example/'
|
||||
...
|
||||
```
|
||||
|
||||
4. 在 `mmseg/utils/class_names.py` 中补充数据集元信息
|
||||
|
||||
```python
|
||||
def example_classes():
|
||||
return [
|
||||
'xxx', 'xxx',
|
||||
...
|
||||
]
|
||||
|
||||
def example_palette():
|
||||
return [
|
||||
[x, x, x], [x, x, x],
|
||||
...
|
||||
]
|
||||
dataset_aliases ={
|
||||
'example': ['example', ...],
|
||||
...
|
||||
}
|
||||
```
|
||||
|
||||
**注意:** 如果新数据集不满足 mmseg 的要求,则需要在 `tools/dataset_converters/` 中准备一个数据集预处理脚本
|
||||
|
||||
## 通过重新组织数据来定制数据集
|
||||
|
||||
最简单的方法是将您的数据集进行转化,并组织成文件夹的形式。
|
||||
|
||||
如下的文件结构就是一个例子。
|
||||
|
||||
```none
|
||||
├── data
|
||||
│ ├── my_dataset
|
||||
│ │ ├── img_dir
|
||||
│ │ │ ├── train
|
||||
│ │ │ │ ├── xxx{img_suffix}
|
||||
│ │ │ │ ├── yyy{img_suffix}
|
||||
│ │ │ │ ├── zzz{img_suffix}
|
||||
│ │ │ ├── val
|
||||
│ │ ├── ann_dir
|
||||
│ │ │ ├── train
|
||||
│ │ │ │ ├── xxx{seg_map_suffix}
|
||||
│ │ │ │ ├── yyy{seg_map_suffix}
|
||||
│ │ │ │ ├── zzz{seg_map_suffix}
|
||||
│ │ │ ├── val
|
||||
|
||||
```
|
||||
|
||||
一个训练对将由 img_dir/ann_dir 里同样首缀的文件组成。
|
||||
|
||||
有些数据集不会发布测试集或测试集的标注,如果没有测试集的标注,我们就无法在本地进行评估模型,因此我们在配置文件中将验证集设置为默认测试集。
|
||||
|
||||
关于如何构建自己的数据集或实现新的数据集类,请参阅[数据集指南](./datasets.md)以获取更多详细信息。
|
||||
|
||||
**注意:** 标注是跟图像同样的形状 (H, W),其中的像素值的范围是 `[0, num_classes - 1]`。
|
||||
您也可以使用 [pillow](https://pillow.readthedocs.io/en/stable/handbook/concepts.html#palette) 的 `'P'` 模式去创建包含颜色的标注。
|
||||
|
||||
## 通过混合数据去定制数据集
|
||||
|
||||
MMSegmentation 同样支持混合数据集去训练。
|
||||
当前它支持拼接 (concat), 重复 (repeat) 和多图混合 (multi-image mix) 数据集。
|
||||
|
||||
### 重复数据集
|
||||
|
||||
我们使用 `RepeatDataset` 作为包装 (wrapper) 去重复数据集。
|
||||
例如,假设原始数据集是 `Dataset_A`,为了重复它,配置文件如下:
|
||||
|
||||
```python
|
||||
dataset_A_train = dict(
|
||||
type='RepeatDataset',
|
||||
times=N,
|
||||
dataset=dict( # 这是 Dataset_A 数据集的原始配置
|
||||
type='Dataset_A',
|
||||
...
|
||||
pipeline=train_pipeline
|
||||
)
|
||||
)
|
||||
```
|
||||
|
||||
### 拼接数据集
|
||||
|
||||
如果要拼接不同的数据集,可以按如下方式连接数据集配置。
|
||||
|
||||
```python
|
||||
dataset_A_train = dict()
|
||||
dataset_B_train = dict()
|
||||
concatenate_dataset = dict(
|
||||
type='ConcatDataset',
|
||||
datasets=[dataset_A_train, dataset_B_train])
|
||||
```
|
||||
|
||||
下面是一个更复杂的示例,它分别重复 `Dataset_A` 和 `Dataset_B` N 次和 M 次,然后连接重复的数据集。
|
||||
|
||||
```python
|
||||
dataset_A_train = dict(
|
||||
type='RepeatDataset',
|
||||
times=N,
|
||||
dataset=dict(
|
||||
type='Dataset_A',
|
||||
...
|
||||
pipeline=train_pipeline
|
||||
)
|
||||
)
|
||||
dataset_A_val = dict(
|
||||
...
|
||||
pipeline=test_pipeline
|
||||
)
|
||||
dataset_A_test = dict(
|
||||
...
|
||||
pipeline=test_pipeline
|
||||
)
|
||||
dataset_B_train = dict(
|
||||
type='RepeatDataset',
|
||||
times=M,
|
||||
dataset=dict(
|
||||
type='Dataset_B',
|
||||
...
|
||||
pipeline=train_pipeline
|
||||
)
|
||||
)
|
||||
train_dataloader = dict(
|
||||
dataset=dict(
|
||||
type='ConcatDataset',
|
||||
datasets=[dataset_A_train, dataset_B_train]))
|
||||
|
||||
val_dataloader = dict(dataset=dataset_A_val)
|
||||
test_dataloader = dict(dataset=dataset_A_test)
|
||||
|
||||
```
|
||||
|
||||
您可以参考 mmengine 的基础数据集[教程](https://mmengine.readthedocs.io/zh_CN/latest/advanced_tutorials/basedataset.html)以了解更多详细信息
|
||||
|
||||
### 多图混合集
|
||||
|
||||
我们使用 `MultiImageMixDataset` 作为包装(wrapper)去混合多个数据集的图片。
|
||||
`MultiImageMixDataset`可以被类似 mosaic 和 mixup 的多图混合数据増广使用。
|
||||
|
||||
`MultiImageMixDataset` 与 `Mosaic` 数据増广一起使用的例子:
|
||||
|
||||
```python
|
||||
train_pipeline = [
|
||||
dict(type='RandomMosaic', prob=1),
|
||||
dict(type='Resize', img_scale=(1024, 512), keep_ratio=True),
|
||||
dict(type='RandomFlip', prob=0.5),
|
||||
dict(type='PackSegInputs')
|
||||
]
|
||||
|
||||
train_dataset = dict(
|
||||
type='MultiImageMixDataset',
|
||||
dataset=dict(
|
||||
type=dataset_type,
|
||||
reduce_zero_label=False,
|
||||
img_dir=data_root + "images/train",
|
||||
ann_dir=data_root + "annotations/train",
|
||||
pipeline=[
|
||||
dict(type='LoadImageFromFile'),
|
||||
dict(type='LoadAnnotations'),
|
||||
]
|
||||
),
|
||||
pipeline=train_pipeline
|
||||
)
|
||||
|
||||
```
|
||||
@@ -0,0 +1,81 @@
|
||||
# 新增评测指标
|
||||
|
||||
## 使用 MMSegmentation 的源代码进行开发
|
||||
|
||||
在这里,我们用 `CustomMetric` 作为例子来展示如何开发一个新的评测指标。
|
||||
|
||||
1. 创建一个新文件 `mmseg/evaluation/metrics/custom_metric.py`。
|
||||
|
||||
```python
|
||||
from typing import List, Sequence
|
||||
|
||||
from mmengine.evaluator import BaseMetric
|
||||
|
||||
from mmseg.registry import METRICS
|
||||
|
||||
|
||||
@METRICS.register_module()
|
||||
class CustomMetric(BaseMetric):
|
||||
|
||||
def __init__(self, arg1, arg2):
|
||||
"""
|
||||
The metric first processes each batch of data_samples and predictions,
|
||||
and appends the processed results to the results list. Then it
|
||||
collects all results together from all ranks if distributed training
|
||||
is used. Finally, it computes the metrics of the entire dataset.
|
||||
"""
|
||||
|
||||
def process(self, data_batch: dict, data_samples: Sequence[dict]) -> None:
|
||||
pass
|
||||
|
||||
def compute_metrics(self, results: list) -> dict:
|
||||
pass
|
||||
|
||||
def evaluate(self, size: int) -> dict:
|
||||
pass
|
||||
```
|
||||
|
||||
在上面的示例中,`CustomMetric` 是 `BaseMetric` 的子类。它有三个方法:`process`,`compute_metrics` 和 `evaluate`。
|
||||
|
||||
- `process()` 处理一批数据样本和预测。处理后的结果需要显示地传给 `self.results` ,将在处理所有数据样本后用于计算指标。更多细节请参考 [MMEngine 文档](https://github.com/open-mmlab/mmengine/blob/main/docs/zh_cn/design/evaluation.md)
|
||||
|
||||
- `compute_metrics()` 用于从处理后的结果中计算指标。
|
||||
|
||||
- `evaluate()` 是一个接口,用于计算指标并返回结果。它将由 `ValLoop` 或 `TestLoop` 在 `Runner` 中调用。在大多数情况下,您不需要重写此方法,但如果您想做一些额外的工作,可以重写它。
|
||||
|
||||
**注意:** 您可以在[这里](https://github.com/open-mmlab/mmengine/blob/main/mmengine/runner/loops.py#L366) 找到 `Runner` 调用 `evaluate()` 方法的过程。`Runner` 是训练和测试过程的执行器,您可以在[训练引擎文档](./engine.md)中找到有关它的详细信息。
|
||||
|
||||
2. 在 `mmseg/evaluation/metrics/__init__.py` 中导入新的指标。
|
||||
|
||||
```python
|
||||
from .custom_metric import CustomMetric
|
||||
__all__ = ['CustomMetric', ...]
|
||||
```
|
||||
|
||||
3. 在配置文件中设置新的评测指标
|
||||
|
||||
```python
|
||||
val_evaluator = dict(type='CustomMetric', arg1=xxx, arg2=xxx)
|
||||
test_evaluator = dict(type='CustomMetric', arg1=xxx, arg2=xxx)
|
||||
```
|
||||
|
||||
## 使用发布版本的 MMSegmentation 进行开发
|
||||
|
||||
上面的示例展示了如何使用 MMSegmentation 的源代码开发新指标。如果您想使用 MMSegmentation 的发布版本开发新指标,可以按照以下步骤操作。
|
||||
|
||||
1. 创建一个新文件 `/Path/to/metrics/custom_metric.py`,实现 `process`,`compute_metrics` 和 `evaluate` 方法,`evaluate` 方法是可选的。
|
||||
|
||||
2. 在代码或配置文件中导入新的指标。
|
||||
|
||||
```python
|
||||
from path.to.metrics import CustomMetric
|
||||
```
|
||||
|
||||
或者
|
||||
|
||||
```python
|
||||
custom_imports = dict(imports=['/Path/to/metrics'], allow_failed_imports=False)
|
||||
|
||||
val_evaluator = dict(type='CustomMetric', arg1=xxx, arg2=xxx)
|
||||
test_evaluator = dict(type='CustomMetric', arg1=xxx, arg2=xxx)
|
||||
```
|
||||
260
Seg_All_In_One_MMSeg/docs/zh_cn/advanced_guides/add_models.md
Normal file
260
Seg_All_In_One_MMSeg/docs/zh_cn/advanced_guides/add_models.md
Normal file
@@ -0,0 +1,260 @@
|
||||
# 新增模块
|
||||
|
||||
## 开发新组件
|
||||
|
||||
我们可以自定义 [模型文档](./models.md) 中介绍的所有组件,例如**主干网络(backbone)**、**头(head)**、**损失函数(loss function)**和**数据预处理器(data preprocessor)**。
|
||||
|
||||
### 添加新的主干网络(backbone)
|
||||
|
||||
在这里,我们以 MobileNet 为例展示如何开发新的主干网络。
|
||||
|
||||
1. 创建一个新文件 `mmseg/models/backbones/mobilenet.py`。
|
||||
|
||||
```python
|
||||
import torch.nn as nn
|
||||
|
||||
from mmseg.registry import MODELS
|
||||
|
||||
|
||||
@MODELS.register_module()
|
||||
class MobileNet(nn.Module):
|
||||
|
||||
def __init__(self, arg1, arg2):
|
||||
pass
|
||||
|
||||
def forward(self, x): # should return a tuple
|
||||
pass
|
||||
|
||||
def init_weights(self, pretrained=None):
|
||||
pass
|
||||
```
|
||||
|
||||
2. 在 `mmseg/models/backbones/__init__.py` 中引入模块。
|
||||
|
||||
```python
|
||||
from .mobilenet import MobileNet
|
||||
```
|
||||
|
||||
3. 在配置文件中使用它。
|
||||
|
||||
```python
|
||||
model = dict(
|
||||
...
|
||||
backbone=dict(
|
||||
type='MobileNet',
|
||||
arg1=xxx,
|
||||
arg2=xxx),
|
||||
...
|
||||
```
|
||||
|
||||
### 添加新的头(head)
|
||||
|
||||
在 MMSegmentation 中,我们提供 [BaseDecodeHead](https://github.com/open-mmlab/mmsegmentation/blob/1.x/mmseg/models/decode_heads/decode_head.py#L17) 用于开发所有分割头。
|
||||
所有新实现的解码头都应该从中派生出来。
|
||||
接下来我们以 [PSPNet](https://arxiv.org/abs/1612.01105) 为例说明如何开发新的头。
|
||||
|
||||
首先,在 `mmseg/models/decode_heads/psp_head.py` 中添加一个新的解码头。
|
||||
PSPNet 实现了用于分割解码的解码头。
|
||||
为了实现解码头,在新模块中我们需要执行以下三个函数。
|
||||
|
||||
```python
|
||||
from mmseg.registry import MODELS
|
||||
|
||||
@MODELS.register_module()
|
||||
class PSPHead(BaseDecodeHead):
|
||||
|
||||
def __init__(self, pool_scales=(1, 2, 3, 6), **kwargs):
|
||||
super(PSPHead, self).__init__(**kwargs)
|
||||
|
||||
def init_weights(self):
|
||||
pass
|
||||
|
||||
def forward(self, inputs):
|
||||
pass
|
||||
```
|
||||
|
||||
接下来,用户需要在 `mmseg/models/decode_heads/__init__.py` 中添加模块,这样相应的注册器就可以找到并加载它们。
|
||||
|
||||
PSPNet 的配置文件如下
|
||||
|
||||
```python
|
||||
norm_cfg = dict(type='SyncBN', requires_grad=True)
|
||||
model = dict(
|
||||
type='EncoderDecoder',
|
||||
pretrained='pretrain_model/resnet50_v1c_trick-2cccc1ad.pth',
|
||||
backbone=dict(
|
||||
type='ResNetV1c',
|
||||
depth=50,
|
||||
num_stages=4,
|
||||
out_indices=(0, 1, 2, 3),
|
||||
dilations=(1, 1, 2, 4),
|
||||
strides=(1, 2, 1, 1),
|
||||
norm_cfg=norm_cfg,
|
||||
norm_eval=False,
|
||||
style='pytorch',
|
||||
contract_dilation=True),
|
||||
decode_head=dict(
|
||||
type='PSPHead',
|
||||
in_channels=2048,
|
||||
in_index=3,
|
||||
channels=512,
|
||||
pool_scales=(1, 2, 3, 6),
|
||||
dropout_ratio=0.1,
|
||||
num_classes=19,
|
||||
norm_cfg=norm_cfg,
|
||||
align_corners=False,
|
||||
loss_decode=dict(
|
||||
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)))
|
||||
|
||||
```
|
||||
|
||||
### 添加新的损失函数(loss)
|
||||
|
||||
假设您想为分割解码添加一个叫做 `MyLoss` 的新的损失函数。
|
||||
要添加新的损失函数,用户需要在 `mmseg/models/loss/my_loss.py` 中实现它。
|
||||
修饰器 `weighted_loss` 可以对损失的每个元素进行加权。
|
||||
|
||||
```python
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
|
||||
from mmseg.registry import MODELS
|
||||
from .utils import weighted_loss
|
||||
|
||||
@weighted_loss
|
||||
def my_loss(pred, target):
|
||||
assert pred.size() == target.size() and target.numel() > 0
|
||||
loss = torch.abs(pred - target)
|
||||
return loss
|
||||
|
||||
@MODELS.register_module()
|
||||
class MyLoss(nn.Module):
|
||||
|
||||
def __init__(self, reduction='mean', loss_weight=1.0):
|
||||
super(MyLoss, self).__init__()
|
||||
self.reduction = reduction
|
||||
self.loss_weight = loss_weight
|
||||
|
||||
def forward(self,
|
||||
pred,
|
||||
target,
|
||||
weight=None,
|
||||
avg_factor=None,
|
||||
reduction_override=None):
|
||||
assert reduction_override in (None, 'none', 'mean', 'sum')
|
||||
reduction = (
|
||||
reduction_override if reduction_override else self.reduction)
|
||||
loss = self.loss_weight * my_loss(
|
||||
pred, target, weight, reduction=reduction, avg_factor=avg_factor)
|
||||
return loss
|
||||
```
|
||||
|
||||
然后,用户需要将其添加到 `mmseg/models/loss/__init__.py` 中。
|
||||
|
||||
```python
|
||||
from .my_loss import MyLoss, my_loss
|
||||
|
||||
```
|
||||
|
||||
要使用它,请修改 `loss_xx` 字段。
|
||||
然后需要修改头中的 `loss_decode` 字段。
|
||||
`loss_weight` 可用于平衡多重损失。
|
||||
|
||||
```python
|
||||
loss_decode=dict(type='MyLoss', loss_weight=1.0))
|
||||
```
|
||||
|
||||
### 添加新的数据预处理器(data preprocessor)
|
||||
|
||||
在 MMSegmentation 1.x 版本中,我们使用 [SegDataPreProcessor](https://github.com/open-mmlab/mmsegmentation/blob/main/mmseg/models/data_preprocessor.py#L13) 将数据复制到目标设备,并将数据预处理为默认的模型输入格式。这里我们将展示如何开发一个新的数据预处理器。
|
||||
|
||||
1. 创建一个新文件 `mmseg/models/my_datapreprocessor.py`。
|
||||
|
||||
```python
|
||||
from mmengine.model import BaseDataPreprocessor
|
||||
|
||||
from mmseg.registry import MODELS
|
||||
|
||||
@MODELS.register_module()
|
||||
class MyDataPreProcessor(BaseDataPreprocessor):
|
||||
def __init__(self, **kwargs):
|
||||
super().__init__(**kwargs)
|
||||
|
||||
def forward(self, data: dict, training: bool=False) -> Dict[str, Any]:
|
||||
# TODO Define the logic for data pre-processing in the forward method
|
||||
pass
|
||||
```
|
||||
|
||||
2. 在 `mmseg/models/__init__.py` 中导入数据预处理器
|
||||
|
||||
```python
|
||||
from .my_datapreprocessor import MyDataPreProcessor
|
||||
```
|
||||
|
||||
3. 在配置文件中使用它。
|
||||
|
||||
```python
|
||||
model = dict(
|
||||
data_preprocessor=dict(type='MyDataPreProcessor)
|
||||
...
|
||||
)
|
||||
```
|
||||
|
||||
## 开发新的分割器(segmentor)
|
||||
|
||||
分割器是一种户可以通过添加自定义组件和定义算法执行逻辑来自定义其算法的算法架构。请参考[模型文档](./models.md)了解更多详情。
|
||||
|
||||
由于 MMSegmentation 中的 [BaseSegmenter](https://github.com/open-mmlab/mmsegmentation/blob/1.x/mmseg/models/segmentors/base.py#L15) 统一了前向过程的三种模式,为了开发新的分割器,用户需要重写与 `loss`、`predict` 和 `tensor` 相对应的 `loss`、`predict` 和 `_forward` 方法。
|
||||
|
||||
这里我们将展示如何开发一个新的分割器。
|
||||
|
||||
1. 创建一个新文件 `mmseg/models/segmentors/my_segmentor.py`。
|
||||
|
||||
```python
|
||||
from typing import Dict, Optional, Union
|
||||
|
||||
import torch
|
||||
|
||||
from mmseg.registry import MODELS
|
||||
from mmseg.models import BaseSegmentor
|
||||
|
||||
@MODELS.register_module()
|
||||
class MySegmentor(BaseSegmentor):
|
||||
def __init__(self, **kwargs):
|
||||
super().__init__(**kwargs)
|
||||
# TODO users should build components of the network here
|
||||
|
||||
def loss(self, inputs: Tensor, data_samples: SampleList) -> dict:
|
||||
"""Calculate losses from a batch of inputs and data samples."""
|
||||
pass
|
||||
|
||||
def predict(self, inputs: Tensor, data_samples: OptSampleList=None) -> SampleList:
|
||||
"""Predict results from a batch of inputs and data samples with post-
|
||||
processing."""
|
||||
pass
|
||||
|
||||
def _forward(self,
|
||||
inputs: Tensor,
|
||||
data_samples: OptSampleList = None) -> Tuple[List[Tensor]]:
|
||||
"""Network forward process.
|
||||
|
||||
Usually includes backbone, neck and head forward without any post-
|
||||
processing.
|
||||
"""
|
||||
pass
|
||||
```
|
||||
|
||||
2. 在 `mmseg/models/segmentors/__init__.py` 中导入分割器。
|
||||
|
||||
```python
|
||||
from .my_segmentor import MySegmentor
|
||||
```
|
||||
|
||||
3. 在配置文件中使用它。
|
||||
|
||||
```python
|
||||
model = dict(
|
||||
type='MySegmentor'
|
||||
...
|
||||
)
|
||||
```
|
||||
@@ -0,0 +1,51 @@
|
||||
# 新增数据增强
|
||||
|
||||
## 自定义数据增强
|
||||
|
||||
自定义数据增强必须继承 `BaseTransform` 并实现 `transform` 函数。这里我们使用一个简单的翻转变换作为示例:
|
||||
|
||||
```python
|
||||
import random
|
||||
import mmcv
|
||||
from mmcv.transforms import BaseTransform, TRANSFORMS
|
||||
|
||||
@TRANSFORMS.register_module()
|
||||
class MyFlip(BaseTransform):
|
||||
def __init__(self, direction: str):
|
||||
super().__init__()
|
||||
self.direction = direction
|
||||
|
||||
def transform(self, results: dict) -> dict:
|
||||
img = results['img']
|
||||
results['img'] = mmcv.imflip(img, direction=self.direction)
|
||||
return results
|
||||
```
|
||||
|
||||
此外,新的类需要被导入。
|
||||
|
||||
```python
|
||||
from .my_pipeline import MyFlip
|
||||
```
|
||||
|
||||
这样,我们就可以实例化一个 `MyFlip` 对象并使用它来处理数据字典。
|
||||
|
||||
```python
|
||||
import numpy as np
|
||||
|
||||
transform = MyFlip(direction='horizontal')
|
||||
data_dict = {'img': np.random.rand(224, 224, 3)}
|
||||
data_dict = transform(data_dict)
|
||||
processed_img = data_dict['img']
|
||||
```
|
||||
|
||||
或者,我们可以在配置文件中的数据流程中使用 `MyFlip` 变换。
|
||||
|
||||
```python
|
||||
pipeline = [
|
||||
...
|
||||
dict(type='MyFlip', direction='horizontal'),
|
||||
...
|
||||
]
|
||||
```
|
||||
|
||||
需要注意,如果要在配置文件中使用 `MyFlip`,必须确保在运行时导入了包含 `MyFlip` 的文件。
|
||||
@@ -0,0 +1,461 @@
|
||||
# 在 mmsegmentation projects 中贡献一个标准格式的数据集
|
||||
|
||||
- 在开始您的贡献流程前,请先阅读[《OpenMMLab 贡献代码指南》](https://mmcv.readthedocs.io/zh_CN/latest/community/contributing.html),以详细的了解 OpenMMLab 代码库的代码贡献流程。
|
||||
- 该教程以 [Gaofen Image Dataset (GID)](https://www.sciencedirect.com/science/article/pii/S0034425719303414) 高分 2 号卫星所拍摄的遥感图像语义分割数据集作为样例,来演示在 mmsegmentation 中的数据集贡献流程。
|
||||
|
||||
## 步骤 1: 配置 mmsegmentation 开发所需必要环境
|
||||
|
||||
- 开发所必需的环境安装请参考[中文快速入门指南](https://github.com/open-mmlab/mmsegmentation/blob/main/docs/zh_cn/get_started.md)或[英文 get_started](https://github.com/open-mmlab/mmsegmentation/blob/main/docs/en/get_started.md)。
|
||||
|
||||
- 如果您已安装了最新版的 pytorch、mmcv、mmengine,那么您可以跳过步骤 1 至[步骤 2](<#[步骤-2](#%E6%AD%A5%E9%AA%A4-2%E4%BB%A3%E7%A0%81%E8%B4%A1%E7%8C%AE%E5%89%8D%E7%9A%84%E5%87%86%E5%A4%87%E5%B7%A5%E4%BD%9C)>)。
|
||||
|
||||
- **注:** 在此处无需安装 mmsegmentation,只需安装开发 mmsegmentation 所必需的 pytorch、mmcv、mmengine 等即可。
|
||||
|
||||
**新建虚拟环境(如已有合适的开发环境,可跳过)**
|
||||
|
||||
- 从[官方网站](https://docs.conda.io/en/latest/miniconda.html)下载并安装 Miniconda
|
||||
- 创建一个 conda 环境,并激活
|
||||
|
||||
```shell
|
||||
conda create --name openmmlab python=3.8 -y
|
||||
conda activate openmmlab
|
||||
```
|
||||
|
||||
**安装 pytorch (如环境下已安装 pytorch,可跳过)**
|
||||
|
||||
- 参考 [official instructions](https://pytorch.org/get-started/locally/) 安装 **PyTorch**
|
||||
|
||||
**使用 mim 安装 mmcv、mmengine**
|
||||
|
||||
- 使用 [MIM](https://github.com/open-mmlab/mim) 安装 [MMCV](https://github.com/open-mmlab/mmcv)
|
||||
|
||||
```shell
|
||||
pip install -U openmim
|
||||
mim install mmengine
|
||||
mim install "mmcv>=2.0.0"
|
||||
```
|
||||
|
||||
## 步骤 2:代码贡献前的准备工作
|
||||
|
||||
### 2.1 Fork mmsegmentation 仓库
|
||||
|
||||
- 通过浏览器打开[mmsegmentation 官方仓库](https://github.com/open-mmlab/mmsegmentation/tree/main)。
|
||||
- 登录您的 GitHub 账户,以下步骤均需在 GitHub 登录的情况下进行。
|
||||
- Fork mmsegmentation 仓库
|
||||

|
||||
- Fork 之后,mmsegmentation 仓库将会出现在您的个人仓库中。
|
||||
|
||||
### 2.2 在您的代码编写软件中 git clone mmsegmentation
|
||||
|
||||
这里以 VSCODE 为例
|
||||
|
||||
- 打开 VSCODE,新建终端窗口并激活您在[步骤 1 ](#%E6%AD%A5%E9%AA%A4-1-%E9%85%8D%E7%BD%AE-mmsegmentation-%E5%BC%80%E5%8F%91%E6%89%80%E9%9C%80%E5%BF%85%E8%A6%81%E7%8E%AF%E5%A2%83)中所安装的虚拟环境。
|
||||
- 在您 GitHub 的个人仓库中找到您 Fork 的 mmsegmentation 仓库,复制其链接。
|
||||

|
||||
- 在终端中执行命令
|
||||
```bash
|
||||
git clone {您所复制的个人仓库的链接}
|
||||
```
|
||||

|
||||
**注:** 如提示以下信息,请在 GitHub 中添加 [SSH 秘钥](https://docs.github.com/en/authentication/connecting-to-github-with-ssh/generating-a-new-ssh-key-and-adding-it-to-the-ssh-agent)
|
||||

|
||||
- 进入 mmsegmentation 目录(之后的操作均在 mmsegmentation 目录下)。
|
||||
```bash
|
||||
cd mmsegmentation
|
||||
```
|
||||
- 在终端中执行以下命令,添加官方仓库为上游仓库。
|
||||
```bash
|
||||
git remote add upstream git@github.com:open-mmlab/mmsegmentation.git
|
||||
```
|
||||
- 使用以下命令检查 remote 是否添加成功。
|
||||
```bash
|
||||
git remote -v
|
||||
```
|
||||

|
||||
|
||||
### 2.3 切换目录至 mmsegmentation 并从源码安装mmsegmentation
|
||||
|
||||
在`mmsegmentation`目录下执行`pip install -v -e .`,通过源码构建方式安装 mmsegmentaion 库。
|
||||
安装完成后,您将能看到如下图所示的文件树。
|
||||
<img src="https://user-images.githubusercontent.com/50650583/233826064-4b111358-8f97-44dd-955c-df3204410b8b.png" alt="image" style="zoom:67%;" />
|
||||
|
||||
### 2.4 切换分支为 dev-1.x
|
||||
|
||||
正如您在[ mmsegmentation 官网](https://github.com/open-mmlab/mmsegmentation/tree/main)所见,该仓库有许多分支,默认分支`main`为稳定的发行版本,以及用于贡献者进行开发的`dev-1.x`分支。`dev-1.x`分支是贡献者们用来提交创意和 PR 的分支,`dev-1.x`分支的内容会被周期性的合入到`main`分支。
|
||||

|
||||
|
||||
回到 VSCODE 中,在终端执行命令
|
||||
|
||||
```bash
|
||||
git checkout dev-1.x
|
||||
```
|
||||
|
||||
### 2.5 创新属于自己的新分支
|
||||
|
||||
在基于`dev-1.x`分支下,使用如下命令,创建属于您自己的分支。
|
||||
|
||||
```bash
|
||||
# git checkout -b 您的GitHubID/您的分支想要实现的功能的名字
|
||||
# git checkout -b AI-Tianlong/support_GID_dataset
|
||||
git checkout -b {您的GitHubID/您的分支想要实现的功能的名字}
|
||||
```
|
||||
|
||||
### 2.6 配置 pre-commit
|
||||
|
||||
OpenMMLab 仓库对代码质量有着较高的要求,所有提交的 PR 必须要通过代码格式检查。pre-commit 详细配置参阅[配置 pre-commit](https://mmcv.readthedocs.io/zh_CN/latest/community/contributing.html#pre-commit)。
|
||||
|
||||
## 步骤 3:在`mmsegmentation/projects`下贡献您的代码
|
||||
|
||||
**先对 GID 数据集进行分析**
|
||||
|
||||
这里以贡献高分 2 号遥感图像语义分割数据集 GID 为例,GID 数据集是由我国自主研发的高分 2 号卫星所拍摄的光学遥感图像所创建,经图像预处理后共提供了 150 张 6800x7200 像素的 RGB 三通道遥感图像。并提供了两种不同类别数的数据标注,一种是包含 5 类有效物体的 RGB 标签,另一种是包含 15 类有效物体的 RGB 标签。本教程将针对 5 类标签进行数据集贡献流程讲解。
|
||||
|
||||
GID 的 5 类有效标签分别为:0-背景-\[0,0,0\](mask 标签值-标签名称-RGB 标签值)、1-建筑-\[255,0,0\]、2-农田-\[0,255,0\]、3-森林-\[0,0,255\]、4-草地-\[255,255,0\]、5-水-\[0,0,255\]。在语义分割任务中,标签是与原图尺寸一致的单通道图像,标签图像中的像素值为真实样本图像中对应像素所包含的物体的类别。GID 数据集提供的是具有 RGB 三通道的彩色标签,为了模型的训练需要将 RGB 标签转换为 mask 标签。并且由于图像尺寸为 6800x7200 像素,对于神经网络的训练来有些过大,所以将每张图像裁切成了没有重叠的 512x512 的图像以便进行训练。
|
||||
<img align='center' src="https://user-images.githubusercontent.com/50650583/234192183-83ee4209-e181-4a18-90ca-4d71757cd2c7.png" alt="image" style="zoom:67%;" />
|
||||
|
||||
### 3.1 在`mmsegmentation/projects`下创建新的项目文件夹
|
||||
|
||||
在`mmsegmentation/projects`下创建文件夹`gid_dataset`
|
||||

|
||||
|
||||
### 3.2 贡献您的数据集代码
|
||||
|
||||
为了最终能将您在 projects 中贡献的代码更加顺畅的移入核心库中(对代码要求质量更高),非常建议按照核心库的目录来编辑您的数据集文件。
|
||||
关于数据集有 4 个必要的文件:
|
||||
|
||||
- **1** `mmseg/datasets/gid.py` 定义了数据集的尾缀、CLASSES、PALETTE、reduce_zero_label等
|
||||
- **2** `configs/_base_/gid.py` GID 数据集的配置文件,定义了数据集的`dataset_type`(数据集类型,`mmseg/datasets/gid.py`中注册的数据集的类名)、`data_root`(数据集所在的根目录,建议将数据集通过软连接的方式将数据集放至`mmsegmentation/data`)、`train_pipline`(训练的数据流)、`test_pipline`(测试和验证时的数据流)、`img_rations`(多尺度预测时的多尺度配置)、`tta_pipeline`(多尺度预测)、`train_dataloader`(训练集的数据加载器)、`val_dataloader`(验证集的数据加载器)、`test_dataloader`(测试集的数据加载器)、`val_evaluator`(验证集的评估器)、`test_evaluator`(测试集的评估器)。
|
||||
- **3** 使用了 GID 数据集的模型训练配置文件
|
||||
这个是可选的,但是强烈建议您添加。在核心库中,所贡献的数据集需要和参考文献中所提出的结果精度对齐,为了后期将您贡献的代码合并入核心库。如您的算力充足,最好能提供对应的模型配置文件在您贡献的数据集上所验证的结果以及相应的权重文件,并撰写较为详细的README.md文档。[示例参考结果](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/deeplabv3plus#mapillary-vistas-v12)
|
||||

|
||||
- **4** 使用如下命令格式: 撰写`docs/zh_cn/user_guides/2_dataset_prepare.md`来添加您的数据集介绍,包括但不限于数据集的下载方式,数据集目录结构、数据集生成等一些必要性的文字性描述和运行命令。以更好地帮助用户能更快的实现数据集的准备工作。
|
||||
|
||||
### 3.3 贡献`tools/dataset_converters/gid.py`
|
||||
|
||||
由于 GID 数据集是由未经过切分的 6800x7200 图像所构成的数据集,并且没有划分训练集、验证集与测试集。以及其标签为 RGB 彩色标签,需要将标签转换为单通道的 mask label。为了方便训练,首先将 GID 数据集进行裁切和标签转换,并进行数据集划分,构建为 mmsegmentation 所支持的格式。
|
||||
|
||||
```python
|
||||
# tools/dataset_converters/gid.py
|
||||
import argparse
|
||||
import glob
|
||||
import math
|
||||
import os
|
||||
import os.path as osp
|
||||
from PIL import Image
|
||||
|
||||
import mmcv
|
||||
import numpy as np
|
||||
from mmengine.utils import ProgressBar, mkdir_or_exist
|
||||
|
||||
def parse_args():
|
||||
parser = argparse.ArgumentParser(
|
||||
description='Convert GID dataset to mmsegmentation format')
|
||||
parser.add_argument('dataset_img_path', help='GID images folder path')
|
||||
parser.add_argument('dataset_label_path', help='GID labels folder path')
|
||||
parser.add_argument('--tmp_dir', help='path of the temporary directory')
|
||||
parser.add_argument('-o', '--out_dir', help='output path', default='data/gid')
|
||||
parser.add_argument(
|
||||
'--clip_size',
|
||||
type=int,
|
||||
help='clipped size of image after preparation',
|
||||
default=256)
|
||||
parser.add_argument(
|
||||
'--stride_size',
|
||||
type=int,
|
||||
help='stride of clipping original images',
|
||||
default=256)
|
||||
args = parser.parse_args()
|
||||
return args
|
||||
|
||||
GID_COLORMAP = dict(
|
||||
Background=(0, 0, 0), #0-背景-黑色
|
||||
Building=(255, 0, 0), #1-建筑-红色
|
||||
Farmland=(0, 255, 0), #2-农田-绿色
|
||||
Forest=(0, 0, 255), #3-森林-蓝色
|
||||
Meadow=(255, 255, 0),#4-草地-黄色
|
||||
Water=(0, 0, 255)#5-水-蓝色
|
||||
)
|
||||
palette = list(GID_COLORMAP.values())
|
||||
classes = list(GID_COLORMAP.keys())
|
||||
|
||||
#############用列表来存一个 RGB 和一个类别的对应################
|
||||
def colormap2label(palette):
|
||||
colormap2label_list = np.zeros(256**3, dtype = np.longlong)
|
||||
for i, colormap in enumerate(palette):
|
||||
colormap2label_list[(colormap[0] * 256 + colormap[1])*256+colormap[2]] = i
|
||||
return colormap2label_list
|
||||
|
||||
#############给定那个列表,和vis_png然后生成masks_png################
|
||||
def label_indices(RGB_label, colormap2label_list):
|
||||
RGB_label = RGB_label.astype('int32')
|
||||
idx = (RGB_label[:, :, 0] * 256 + RGB_label[:, :, 1]) * 256 + RGB_label[:, :, 2]
|
||||
# print(idx.shape)
|
||||
return colormap2label_list[idx]
|
||||
|
||||
def RGB2mask(RGB_label, colormap2label_list):
|
||||
# RGB_label = np.array(Image.open(RGB_label).convert('RGB')) #打开RGB_png
|
||||
mask_label = label_indices(RGB_label, colormap2label_list) # .numpy()
|
||||
return mask_label
|
||||
|
||||
colormap2label_list = colormap2label(palette)
|
||||
|
||||
def clip_big_image(image_path, clip_save_dir, args, to_label=False):
|
||||
"""
|
||||
Original image of GID dataset is very large, thus pre-processing
|
||||
of them is adopted. Given fixed clip size and stride size to generate
|
||||
clipped image, the intersection of width and height is determined.
|
||||
For example, given one 6800 x 7200 original image, the clip size is
|
||||
256 and stride size is 256, thus it would generate 29 x 27 = 783 images
|
||||
whose size are all 256 x 256.
|
||||
|
||||
"""
|
||||
|
||||
image = mmcv.imread(image_path, channel_order='rgb')
|
||||
# image = mmcv.bgr2gray(image)
|
||||
|
||||
h, w, c = image.shape
|
||||
clip_size = args.clip_size
|
||||
stride_size = args.stride_size
|
||||
|
||||
num_rows = math.ceil((h - clip_size) / stride_size) if math.ceil(
|
||||
(h - clip_size) /
|
||||
stride_size) * stride_size + clip_size >= h else math.ceil(
|
||||
(h - clip_size) / stride_size) + 1
|
||||
num_cols = math.ceil((w - clip_size) / stride_size) if math.ceil(
|
||||
(w - clip_size) /
|
||||
stride_size) * stride_size + clip_size >= w else math.ceil(
|
||||
(w - clip_size) / stride_size) + 1
|
||||
|
||||
x, y = np.meshgrid(np.arange(num_cols + 1), np.arange(num_rows + 1))
|
||||
xmin = x * clip_size
|
||||
ymin = y * clip_size
|
||||
|
||||
xmin = xmin.ravel()
|
||||
ymin = ymin.ravel()
|
||||
xmin_offset = np.where(xmin + clip_size > w, w - xmin - clip_size,
|
||||
np.zeros_like(xmin))
|
||||
ymin_offset = np.where(ymin + clip_size > h, h - ymin - clip_size,
|
||||
np.zeros_like(ymin))
|
||||
boxes = np.stack([
|
||||
xmin + xmin_offset, ymin + ymin_offset,
|
||||
np.minimum(xmin + clip_size, w),
|
||||
np.minimum(ymin + clip_size, h)
|
||||
], axis=1)
|
||||
|
||||
if to_label:
|
||||
image = RGB2mask(image, colormap2label_list) #这里得改一下
|
||||
|
||||
for count, box in enumerate(boxes):
|
||||
start_x, start_y, end_x, end_y = box
|
||||
clipped_image = image[start_y:end_y,
|
||||
start_x:end_x] if to_label else image[
|
||||
start_y:end_y, start_x:end_x, :]
|
||||
img_name = osp.basename(image_path).replace('.tif', '')
|
||||
img_name = img_name.replace('_label', '')
|
||||
if count % 3 == 0:
|
||||
mmcv.imwrite(
|
||||
clipped_image.astype(np.uint8),
|
||||
osp.join(
|
||||
clip_save_dir.replace('train', 'val'),
|
||||
f'{img_name}_{start_x}_{start_y}_{end_x}_{end_y}.png'))
|
||||
else:
|
||||
mmcv.imwrite(
|
||||
clipped_image.astype(np.uint8),
|
||||
osp.join(
|
||||
clip_save_dir,
|
||||
f'{img_name}_{start_x}_{start_y}_{end_x}_{end_y}.png'))
|
||||
count += 1
|
||||
|
||||
def main():
|
||||
args = parse_args()
|
||||
|
||||
"""
|
||||
According to this paper: https://ieeexplore.ieee.org/document/9343296/
|
||||
select 15 images contained in GID, , which cover the whole six
|
||||
categories, to generate train set and validation set.
|
||||
|
||||
According to Paper: https://ieeexplore.ieee.org/document/9343296/
|
||||
|
||||
"""
|
||||
|
||||
if args.out_dir is None:
|
||||
out_dir = osp.join('data', 'gid')
|
||||
else:
|
||||
out_dir = args.out_dir
|
||||
|
||||
print('Making directories...')
|
||||
mkdir_or_exist(osp.join(out_dir, 'img_dir', 'train'))
|
||||
mkdir_or_exist(osp.join(out_dir, 'img_dir', 'val'))
|
||||
mkdir_or_exist(osp.join(out_dir, 'ann_dir', 'train'))
|
||||
mkdir_or_exist(osp.join(out_dir, 'ann_dir', 'val'))
|
||||
|
||||
src_path_list = glob.glob(os.path.join(args.dataset_img_path, '*.tif'))
|
||||
print(f'Find {len(src_path_list)} pictures')
|
||||
|
||||
prog_bar = ProgressBar(len(src_path_list))
|
||||
|
||||
dst_img_dir = osp.join(out_dir, 'img_dir', 'train')
|
||||
dst_label_dir = osp.join(out_dir, 'ann_dir', 'train')
|
||||
|
||||
for i, img_path in enumerate(src_path_list):
|
||||
label_path = osp.join(args.dataset_label_path, osp.basename(img_path.replace('.tif', '_label.tif')))
|
||||
|
||||
clip_big_image(img_path, dst_img_dir, args, to_label=False)
|
||||
clip_big_image(label_path, dst_label_dir, args, to_label=True)
|
||||
prog_bar.update()
|
||||
|
||||
print('Done!')
|
||||
|
||||
if __name__ == '__main__':
|
||||
main()
|
||||
```
|
||||
|
||||
### 3.4 贡献`mmseg/datasets/gid.py`
|
||||
|
||||
可参考[`projects/mapillary_dataset/mmseg/datasets/mapillary.py`](https://github.com/open-mmlab/mmsegmentation/blob/main/projects/mapillary_dataset/mmseg/datasets/mapillary.py)并在此基础上修改相应变量以适配您的数据集。
|
||||
|
||||
```python
|
||||
# mmseg/datasets/gid.py
|
||||
# Copyright (c) OpenMMLab. All rights reserved.
|
||||
from mmseg.datasets.basesegdataset import BaseSegDataset
|
||||
from mmseg.registry import DATASETS
|
||||
|
||||
# 注册数据集类
|
||||
@DATASETS.register_module()
|
||||
class GID_Dataset(BaseSegDataset):
|
||||
"""Gaofen Image Dataset (GID)
|
||||
|
||||
Dataset paper link:
|
||||
https://www.sciencedirect.com/science/article/pii/S0034425719303414
|
||||
https://x-ytong.github.io/project/GID.html
|
||||
|
||||
GID 6 classes: background(others), built-up, farmland, forest, meadow, water
|
||||
|
||||
In This example, select 10 images from GID dataset as training set,
|
||||
and select 5 images as validation set.
|
||||
The selected images are listed as follows:
|
||||
|
||||
GF2_PMS1__L1A0000647767-MSS1
|
||||
GF2_PMS1__L1A0001064454-MSS1
|
||||
GF2_PMS1__L1A0001348919-MSS1
|
||||
GF2_PMS1__L1A0001680851-MSS1
|
||||
GF2_PMS1__L1A0001680853-MSS1
|
||||
GF2_PMS1__L1A0001680857-MSS1
|
||||
GF2_PMS1__L1A0001757429-MSS1
|
||||
GF2_PMS2__L1A0000607681-MSS2
|
||||
GF2_PMS2__L1A0000635115-MSS2
|
||||
GF2_PMS2__L1A0000658637-MSS2
|
||||
GF2_PMS2__L1A0001206072-MSS2
|
||||
GF2_PMS2__L1A0001471436-MSS2
|
||||
GF2_PMS2__L1A0001642620-MSS2
|
||||
GF2_PMS2__L1A0001787089-MSS2
|
||||
GF2_PMS2__L1A0001838560-MSS2
|
||||
|
||||
The ``img_suffix`` is fixed to '.tif' and ``seg_map_suffix`` is
|
||||
fixed to '.tif' for GID.
|
||||
"""
|
||||
METAINFO = dict(
|
||||
classes=('Others', 'Built-up', 'Farmland', 'Forest',
|
||||
'Meadow', 'Water'),
|
||||
|
||||
palette=[[0, 0, 0], [255, 0, 0], [0, 255, 0], [0, 255, 255],
|
||||
[255, 255, 0], [0, 0, 255]])
|
||||
|
||||
def __init__(self,
|
||||
img_suffix='.png',
|
||||
seg_map_suffix='.png',
|
||||
reduce_zero_label=None,
|
||||
**kwargs) -> None:
|
||||
super().__init__(
|
||||
img_suffix=img_suffix,
|
||||
seg_map_suffix=seg_map_suffix,
|
||||
reduce_zero_label=reduce_zero_label,
|
||||
**kwargs)
|
||||
```
|
||||
|
||||
### 3.5 贡献使用 GID 的训练 config file
|
||||
|
||||
```python
|
||||
_base_ = [
|
||||
'../../../configs/_base_/models/deeplabv3plus_r50-d8.py',
|
||||
'./_base_/datasets/gid.py',
|
||||
'../../../configs/_base_/default_runtime.py',
|
||||
'../../../configs/_base_/schedules/schedule_240k.py'
|
||||
]
|
||||
custom_imports = dict(
|
||||
imports=['projects.gid_dataset.mmseg.datasets.gid'])
|
||||
|
||||
crop_size = (256, 256)
|
||||
data_preprocessor = dict(size=crop_size)
|
||||
model = dict(
|
||||
data_preprocessor=data_preprocessor,
|
||||
pretrained='open-mmlab://resnet101_v1c',
|
||||
backbone=dict(depth=101),
|
||||
decode_head=dict(num_classes=6),
|
||||
auxiliary_head=dict(num_classes=6))
|
||||
|
||||
```
|
||||
|
||||
### 3.6 撰写`docs/zh_cn/user_guides/2_dataset_prepare.md`
|
||||
|
||||
**Gaofen Image Dataset (GID)**
|
||||
|
||||
- GID 数据集可在[此处](https://x-ytong.github.io/project/Five-Billion-Pixels.html)进行下载。
|
||||
- GID 数据集包含 150 张 6800x7200 的大尺寸图像,标签为 RGB 标签。
|
||||
- 此处选择 15 张图像生成训练集和验证集,该 15 张图像包含了所有六类信息。所选的图像名称如下:
|
||||
|
||||
```None
|
||||
GF2_PMS1__L1A0000647767-MSS1
|
||||
GF2_PMS1__L1A0001064454-MSS1
|
||||
GF2_PMS1__L1A0001348919-MSS1
|
||||
GF2_PMS1__L1A0001680851-MSS1
|
||||
GF2_PMS1__L1A0001680853-MSS1
|
||||
GF2_PMS1__L1A0001680857-MSS1
|
||||
GF2_PMS1__L1A0001757429-MSS1
|
||||
GF2_PMS2__L1A0000607681-MSS2
|
||||
GF2_PMS2__L1A0000635115-MSS2
|
||||
GF2_PMS2__L1A0000658637-MSS2
|
||||
GF2_PMS2__L1A0001206072-MSS2
|
||||
GF2_PMS2__L1A0001471436-MSS2
|
||||
GF2_PMS2__L1A0001642620-MSS2
|
||||
GF2_PMS2__L1A0001787089-MSS2
|
||||
GF2_PMS2__L1A0001838560-MSS2
|
||||
```
|
||||
|
||||
执行以下命令进行裁切及标签的转换,需要修改为您所存储 15 张图像及标签的路径。
|
||||
|
||||
```
|
||||
python projects/gid_dataset/tools/dataset_converters/gid.py [15 张图像的路径] [15 张标签的路径]
|
||||
```
|
||||
|
||||
完成裁切后的 GID 数据结构如下:
|
||||
|
||||
```none
|
||||
mmsegmentation
|
||||
├── mmseg
|
||||
├── tools
|
||||
├── configs
|
||||
├── data
|
||||
│ ├── gid
|
||||
│ │ ├── ann_dir
|
||||
| │ │ │ ├── train
|
||||
| │ │ │ ├── val
|
||||
│ │ ├── img_dir
|
||||
| │ │ │ ├── train
|
||||
| │ │ │ ├── val
|
||||
|
||||
```
|
||||
|
||||
### 3.7 贡献的代码及文档通过`pre-commit`检查
|
||||
|
||||
使用命令
|
||||
|
||||
```bash
|
||||
git add .
|
||||
git commit -m "添加描述"
|
||||
git push
|
||||
```
|
||||
|
||||
### 3.8 在 GitHub 中向 mmsegmentation 提交 PR
|
||||
|
||||
具体步骤可见[《OpenMMLab 贡献代码指南》](https://mmcv.readthedocs.io/zh_CN/latest/community/contributing.html)
|
||||
@@ -0,0 +1,162 @@
|
||||
# 自定义运行设定
|
||||
|
||||
## 实现自定义钩子
|
||||
|
||||
### Step 1: 创建一个新的钩子
|
||||
|
||||
MMEngine 已实现了训练和测试常用的[钩子](https://github.com/open-mmlab/mmengine/blob/main/docs/zh_cn/tutorials/hook.md),
|
||||
当有定制化需求时, 可以按照如下示例实现适用于自身训练需求的钩子, 例如想修改一个超参数 `model.hyper_paramete` 的值, 让它随着训练迭代次数而变化:
|
||||
|
||||
```python
|
||||
# Copyright (c) OpenMMLab. All rights reserved.
|
||||
from typing import Optional, Sequence
|
||||
|
||||
from mmengine.hooks import Hook
|
||||
from mmengine.model import is_model_wrapper
|
||||
|
||||
from mmseg.registry import HOOKS
|
||||
|
||||
|
||||
@HOOKS.register_module()
|
||||
class NewHook(Hook):
|
||||
"""Docstring for NewHook.
|
||||
"""
|
||||
|
||||
def __init__(self, a: int, b: int) -> None:
|
||||
self.a = a
|
||||
self.b = b
|
||||
|
||||
def before_train_iter(self,
|
||||
runner,
|
||||
batch_idx: int,
|
||||
data_batch: Optional[Sequence[dict]] = None) -> None:
|
||||
cur_iter = runner.iter
|
||||
# 当模型被包在 wrapper 里时获取这个模型
|
||||
if is_model_wrapper(runner.model):
|
||||
model = runner.model.module
|
||||
model.hyper_parameter = self.a * cur_iter + self.b
|
||||
```
|
||||
|
||||
### Step 2: 导入一个新的钩子
|
||||
|
||||
为了让上面定义的模块可以被执行的程序发现, 这个模块需要先被导入主命名空间 (main namespace) 里面,
|
||||
假设 NewHook 在 `mmseg/engine/hooks/new_hook.py` 里面, 有两种方式去实现它:
|
||||
|
||||
- 修改 `mmseg/engine/hooks/__init__.py` 来导入它.
|
||||
新定义的模块应该在 `mmseg/engine/hooks/__init__.py` 里面导入, 这样注册器可以发现并添加这个新的模块:
|
||||
|
||||
```python
|
||||
from .new_hook import NewHook
|
||||
|
||||
__all__ = [..., NewHook]
|
||||
```
|
||||
|
||||
- 在配置文件里使用 custom_imports 来手动导入它.
|
||||
|
||||
```python
|
||||
custom_imports = dict(imports=['mmseg.engine.hooks.new_hook'], allow_failed_imports=False)
|
||||
```
|
||||
|
||||
### Step 3: 修改配置文件
|
||||
|
||||
可以按照如下方式, 在训练或测试中配置并使用自定义的钩子. 不同钩子在同一位点的优先级可以参考[这里](https://github.com/open-mmlab/mmengine/blob/main/docs/zh_cn/tutorials/hook.md#%E5%86%85%E7%BD%AE%E9%92%A9%E5%AD%90), 自定义钩子如果没有指定优先, 默认是 `NORMAL`.
|
||||
|
||||
```python
|
||||
custom_hooks = [
|
||||
dict(type='NewHook', a=a_value, b=b_value, priority='ABOVE_NORMAL')
|
||||
]
|
||||
```
|
||||
|
||||
## 实现自定义优化器
|
||||
|
||||
### Step 1: 创建一个新的优化器
|
||||
|
||||
如果增加一个叫作 `MyOptimizer` 的优化器, 它有参数 `a`, `b` 和 `c`. 推荐在 `mmseg/engine/optimizers/my_optimizer.py` 文件中实现
|
||||
|
||||
```python
|
||||
from mmseg.registry import OPTIMIZERS
|
||||
from torch.optim import Optimizer
|
||||
|
||||
|
||||
@OPTIMIZERS.register_module()
|
||||
class MyOptimizer(Optimizer):
|
||||
|
||||
def __init__(self, a, b, c)
|
||||
```
|
||||
|
||||
### Step 2: 导入一个新的优化器
|
||||
|
||||
为了让上面定义的模块可以被执行的程序发现, 这个模块需要先被导入主命名空间 (main namespace) 里面,
|
||||
假设 `MyOptimizer` 在 `mmseg/engine/optimizers/my_optimizer.py` 里面, 有两种方式去实现它:
|
||||
|
||||
- 修改 `mmseg/engine/optimizers/__init__.py` 来导入它.
|
||||
新定义的模块应该在 `mmseg/engine/optimizers/__init__.py` 里面导入, 这样注册器可以发现并添加这个新的模块:
|
||||
|
||||
```python
|
||||
from .my_optimizer import MyOptimizer
|
||||
```
|
||||
|
||||
- 在配置文件里使用 `custom_imports` 来手动导入它.
|
||||
|
||||
```python
|
||||
custom_imports = dict(imports=['mmseg.engine.optimizers.my_optimizer'], allow_failed_imports=False)
|
||||
```
|
||||
|
||||
### Step 3: 修改配置文件
|
||||
|
||||
随后需要修改配置文件 `optim_wrapper` 里的 `optimizer` 参数, 如果要使用你自己的优化器 `MyOptimizer`, 字段可以被修改成:
|
||||
|
||||
```python
|
||||
optim_wrapper = dict(type='OptimWrapper',
|
||||
optimizer=dict(type='MyOptimizer',
|
||||
a=a_value, b=b_value, c=c_value),
|
||||
clip_grad=None)
|
||||
```
|
||||
|
||||
## 实现自定义优化器封装构造器
|
||||
|
||||
### Step 1: 创建一个新的优化器封装构造器
|
||||
|
||||
构造器可以用来创建优化器, 优化器包, 以及自定义模型网络不同层的超参数. 一些模型的优化器可能会根据特定的参数而调整, 例如 BatchNorm 层的 weight decay. 使用者可以通过自定义优化器构造器来精细化设定不同参数的优化策略.
|
||||
|
||||
```python
|
||||
from mmengine.optim import DefaultOptimWrapperConstructor
|
||||
from mmseg.registry import OPTIM_WRAPPER_CONSTRUCTORS
|
||||
|
||||
@OPTIM_WRAPPER_CONSTRUCTORS.register_module()
|
||||
class LearningRateDecayOptimizerConstructor(DefaultOptimWrapperConstructor):
|
||||
def __init__(self, optim_wrapper_cfg, paramwise_cfg=None):
|
||||
|
||||
def __call__(self, model):
|
||||
|
||||
return my_optimizer
|
||||
```
|
||||
|
||||
默认的优化器构造器在[这里](https://github.com/open-mmlab/mmengine/blob/main/mmengine/optim/optimizer/default_constructor.py#L19) 被实现, 它也可以用来作为新的优化器构造器的模板.
|
||||
|
||||
### Step 2: 导入一个新的优化器封装构造器
|
||||
|
||||
为了让上面定义的模块可以被执行的程序发现, 这个模块需要先被导入主命名空间 (main namespace) 里面, 假设 `MyOptimizerConstructor` 在 `mmseg/engine/optimizers/my_optimizer_constructor.py` 里面, 有两种方式去实现它:
|
||||
|
||||
- 修改 `mmseg/engine/optimizers/__init__.py` 来导入它.
|
||||
新定义的模块应该在 `mmseg/engine/optimizers/__init__.py` 里面导入, 这样注册器可以发现并添加这个新的模块:
|
||||
|
||||
```python
|
||||
from .my_optimizer_constructor import MyOptimizerConstructor
|
||||
```
|
||||
|
||||
- 在配置文件里使用 `custom_imports` 来手动导入它.
|
||||
|
||||
```python
|
||||
custom_imports = dict(imports=['mmseg.engine.optimizers.my_optimizer_constructor'], allow_failed_imports=False)
|
||||
```
|
||||
|
||||
### Step 3: 修改配置文件
|
||||
|
||||
随后需要修改配置文件 `optim_wrapper` 里的 `constructor` 参数, 如果要使用你自己的优化器封装构造器 `MyOptimizerConstructor`, 字段可以被修改成:
|
||||
|
||||
```python
|
||||
optim_wrapper = dict(type='OptimWrapper',
|
||||
constructor='MyOptimizerConstructor',
|
||||
clip_grad=None)
|
||||
```
|
||||
90
Seg_All_In_One_MMSeg/docs/zh_cn/advanced_guides/data_flow.md
Normal file
90
Seg_All_In_One_MMSeg/docs/zh_cn/advanced_guides/data_flow.md
Normal file
@@ -0,0 +1,90 @@
|
||||
# 数据流
|
||||
|
||||
在本章节中,我们将介绍 [Runner](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/runner.html) 管理的内部模块之间的数据流和数据格式约定。
|
||||
|
||||
## 数据流概述
|
||||
|
||||
[Runner](https://github.com/open-mmlab/mmengine/blob/main/docs/zh_cn/design/runner.md) 相当于 MMEngine 中的“集成器”。它覆盖了框架的所有方面,并肩负着组织和调度几乎所有模块的责任,这意味着各模块之间的数据流也由 `Runner` 控制。 如 [MMEngine 中的 Runner 文档](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/runner.html)所示,下图展示了基本的数据流。
|
||||
|
||||

|
||||
|
||||
虚线边框、灰色填充形状代表不同的数据格式,而实心框表示模块/方法。由于 MMEngine 极大的灵活性和可扩展性,一些重要的基类可以被继承,并且它们的方法可以被覆写。 上图所示数据流仅适用于当用户没有自定义 `Runner` 中的 `TrainLoop`、`ValLoop` 和 `TestLoop`,并且没有在其自定义模型中覆写 `train_step`、`val_step` 和 `test_step` 方法时。MMSegmentation 中 loop 的默认设置如下:使用`IterBasedTrainLoop` 训练模型,共计 20000 次迭代,并且在每 2000 次迭代后进行一次验证。
|
||||
|
||||
```python
|
||||
train_cfg = dict(type='IterBasedTrainLoop', max_iters=20000, val_interval=2000)
|
||||
val_cfg = dict(type='ValLoop')
|
||||
test_cfg = dict(type='TestLoop')
|
||||
```
|
||||
|
||||
在上图中,红色线表示 [train_step](./models.md#train_step),在每次训练迭代中,数据加载器(dataloader)从存储中加载图像并传输到数据预处理器(data preprocessor),数据预处理器会将图像放到特定的设备上,并将数据堆叠到批处理中,之后模型接受批处理数据作为输入,最后将模型的输出发送给优化器(optimizer)。蓝色线表示 [val_step](./models.md#val_step) 和 [test_step](./models.md#test_step)。这两个过程的数据流除了模型输出与 `train_step` 不同外,其余均和 `train_step` 类似。由于在评估时模型参数会被冻结,因此模型的输出将被传递给 [Evaluator](./evaluation.md#ioumetric)。
|
||||
来计算指标。
|
||||
|
||||
## MMSegmentation 中的数据流约定
|
||||
|
||||
在上面的图中,我们可以看到基本的数据流。在本节中,我们将分别介绍数据流中涉及的数据的格式约定。
|
||||
|
||||
### 数据加载器到数据预处理器
|
||||
|
||||
数据加载器(DataLoader)是 MMEngine 的训练和测试流程中的一个重要组件。
|
||||
从概念上讲,它源于 [PyTorch](https://pytorch.org/) 并保持一致。DataLoader 从文件系统加载数据,原始数据通过数据准备流程后被发送给数据预处理器。
|
||||
|
||||
MMSegmentation 在 [PackSegInputs](https://github.com/open-mmlab/mmsegmentation/blob/main/mmseg/datasets/transforms/formatting.py#L12) 中定义了默认数据格式, 它是 `train_pipeline` 和 `test_pipeline` 的最后一个组件。有关数据转换 `pipeline` 的更多信息,请参阅[数据转换文档](./transforms.md)。
|
||||
|
||||
在没有任何修改的情况下,PackSegInputs 的返回值通常是一个包含 `inputs` 和 `data_samples` 的 `dict`。以下伪代码展示了 mmseg 中数据加载器输出的数据类型,它是从数据集中获取的一批数据样本,数据加载器将它们打包成一个字典列表。`inputs` 是输入进模型的张量列表,`data_samples` 包含了输入图像的 meta information 和相应的 ground truth。
|
||||
|
||||
```python
|
||||
dict(
|
||||
inputs=List[torch.Tensor],
|
||||
data_samples=List[SegDataSample]
|
||||
)
|
||||
```
|
||||
|
||||
**注意:** [SegDataSample](https://github.com/open-mmlab/mmsegmentation/blob/1.x/mmseg/structures/seg_data_sample.py) 是 MMSegmentation 的数据结构接口,用于连接不同组件。`SegDataSample` 实现了抽象数据元素 `mmengine.structures.BaseDataElement`,更多信息请在 [MMEngine](https://github.com/open-mmlab/mmengine) 中参阅 [SegDataSample 文档](./structures.md)和[数据元素文档](https://mmengine.readthedocs.io/zh_CN/latest/advanced_tutorials/data_element.html)。
|
||||
|
||||
### 数据预处理器到模型
|
||||
|
||||
虽然在[上面的图](##数据流概述)中分开绘制了数据预处理器和模型,但数据预处理器是模型的一部分,因此可以在[模型教程](./models.md)中找到数据预处理器章节。
|
||||
|
||||
数据预处理器的返回值是一个包含 `inputs` 和 `data_samples` 的字典,其中 `inputs` 是批处理图像的 4D 张量,`data_samples` 中添加了一些用于数据预处理的额外元信息。当传递给网络时,字典将被解包为两个值。 以下伪代码展示了数据预处理器的返回值和模型的输入值。
|
||||
|
||||
```python
|
||||
dict(
|
||||
inputs=torch.Tensor,
|
||||
data_samples=List[SegDataSample]
|
||||
)
|
||||
```
|
||||
|
||||
```python
|
||||
class Network(BaseSegmentor):
|
||||
|
||||
def forward(self, inputs: torch.Tensor, data_samples: List[SegDataSample], mode: str):
|
||||
pass
|
||||
```
|
||||
|
||||
**注意:** 模型的前向传播有 3 种模式,由输入参数 mode 控制,更多信息请参阅[模型教程](./models.md)。
|
||||
|
||||
### 模型输出
|
||||
|
||||
如[模型教程](./models.md#forward) ***([中文链接待更新](./models.md#forward))*** 所提到的 3 种前向传播具有 3 种输出。
|
||||
`train_step` 和 `test_step`(或 `val_step`)分别对应于 `'loss'` 和 `'predict'`。
|
||||
|
||||
在 `test_step` 或 `val_step` 中,推理结果会被传递给 `Evaluator` 。您可以参阅[评估文档](./evaluation.md)来获取更多关于 `Evaluator` 的信息。
|
||||
|
||||
在推理后,MMSegmentation 中的 [BaseSegmentor](https://github.com/open-mmlab/mmsegmentation/blob/main/mmseg/models/segmentors/base.py#L15) 会对推理结果进行简单的后处理以打包推理结果。神经网络生成的分割 logits,经过 `argmax` 操作后的分割 mask 和 ground truth(如果存在)将被打包到类似 `SegDataSample` 的实例。 [postprocess_result](https://github.com/open-mmlab/mmsegmentation/blob/main/mmseg/models/segmentors/base.py#L132) 的返回值是一个 **`SegDataSample`的`List`**。下图显示了这些 `SegDataSample` 实例的关键属性。
|
||||
|
||||

|
||||
|
||||
与数据预处理器一致,损失函数也是模型的一部分,它是[解码头](https://github.com/open-mmlab/mmsegmentation/blob/main/mmseg/models/decode_heads/decode_head.py#L142)的属性之一。
|
||||
|
||||
在 MMSegmentation 中,`decode_head` 的 [loss_by_feat](https://github.com/open-mmlab/mmsegmentation/blob/main/mmseg/models/decode_heads/decode_head.py#L291) 方法是用于计算损失的统一接口。
|
||||
|
||||
参数:
|
||||
|
||||
- seg_logits (Tensor):解码头前向函数的输出
|
||||
- batch_data_samples (List\[SegDataSample\]):分割数据样本,通常包括如 `metainfo` 和 `gt_sem_seg` 等信息
|
||||
|
||||
返回值:
|
||||
|
||||
- dict\[str, Tensor\]:一个损失组件的字典
|
||||
|
||||
**注意:** `train_step` 将损失传递进 OptimWrapper 以更新模型中的权重,更多信息请参阅 [train_step](./models.md#train_step)。
|
||||
363
Seg_All_In_One_MMSeg/docs/zh_cn/advanced_guides/datasets.md
Normal file
363
Seg_All_In_One_MMSeg/docs/zh_cn/advanced_guides/datasets.md
Normal file
@@ -0,0 +1,363 @@
|
||||
# 数据集
|
||||
|
||||
在 MMSegmentation 算法库中, 所有 Dataset 类的功能有两个: 加载[预处理](../user_guides/2_dataset_prepare.md) 之后的数据集的信息, 和将数据送入[数据集变换流水线](https://github.com/open-mmlab/mmsegmentation/blob/main/mmseg/datasets/basesegdataset.py#L141) 中, 进行[数据变换操作](./transforms.md). 加载的数据集信息包括两类: 元信息 (meta information), 数据集本身的信息, 例如数据集总共的类别, 和它们对应调色盘信息: 数据信息 (data information) 是指每组数据中图片和对应标签的路径. 下文中介绍了 MMSegmentation 1.x 中数据集的常用接口, 和 mmseg 数据集基类中数据信息加载与修改数据集类别的逻辑, 以及数据集与数据变换流水线 (pipeline) 的关系.
|
||||
|
||||
## 常用接口
|
||||
|
||||
以 Cityscapes 为例, 介绍数据集常用接口. 如需运行以下示例, 请在当前工作目录下的 `data` 目录下载并[预处理](../user_guides/2_dataset_prepare.md#cityscapes) Cityscapes 数据集.
|
||||
|
||||
实例化 Cityscapes 训练数据集:
|
||||
|
||||
```python
|
||||
from mmengine.registry import init_default_scope
|
||||
from mmseg.datasets import CityscapesDataset
|
||||
|
||||
init_default_scope('mmseg')
|
||||
|
||||
data_root = 'data/cityscapes/'
|
||||
data_prefix=dict(img_path='leftImg8bit/train', seg_map_path='gtFine/train')
|
||||
train_pipeline = [
|
||||
dict(type='LoadImageFromFile'),
|
||||
dict(type='LoadAnnotations'),
|
||||
dict(type='RandomCrop', crop_size=(512, 1024), cat_max_ratio=0.75),
|
||||
dict(type='RandomFlip', prob=0.5),
|
||||
dict(type='PackSegInputs')
|
||||
]
|
||||
|
||||
dataset = CityscapesDataset(data_root=data_root, data_prefix=data_prefix, test_mode=False, pipeline=train_pipeline)
|
||||
```
|
||||
|
||||
查看训练数据集长度:
|
||||
|
||||
```python
|
||||
print(len(dataset))
|
||||
|
||||
2975
|
||||
```
|
||||
|
||||
获取数据信息, 数据信息的类型是一个字典, 包括 `'img_path'` 字段的存放图片的路径和 `'seg_map_path'` 字段存放分割标注的路径, 以及标签重映射的字段 `'label_map'` 和 `'reduce_zero_label'`(主要功能在下文中介绍), 还有存放已加载标签字段 `'seg_fields'`, 和当前样本的索引字段 `'sample_idx'`.
|
||||
|
||||
```python
|
||||
# 获取数据集中第一组样本的数据信息
|
||||
print(dataset.get_data_info(0))
|
||||
|
||||
{'img_path': 'data/cityscapes/leftImg8bit/train/aachen/aachen_000000_000019_leftImg8bit.png',
|
||||
'seg_map_path': 'data/cityscapes/gtFine/train/aachen/aachen_000000_000019_gtFine_labelTrainIds.png',
|
||||
'label_map': None,
|
||||
'reduce_zero_label': False,
|
||||
'seg_fields': [],
|
||||
'sample_idx': 0}
|
||||
```
|
||||
|
||||
获取数据集元信息, MMSegmentation 的数据集元信息的类型同样是一个字典, 包括 `'classes'` 字段存放数据集类别, `'palette'` 存放数据集类别对应的可视化时调色盘的颜色, 以及标签重映射的字段 `'label_map'` 和 `'reduce_zero_label'`.
|
||||
|
||||
```python
|
||||
print(dataset.metainfo)
|
||||
|
||||
{'classes': ('road',
|
||||
'sidewalk',
|
||||
'building',
|
||||
'wall',
|
||||
'fence',
|
||||
'pole',
|
||||
'traffic light',
|
||||
'traffic sign',
|
||||
'vegetation',
|
||||
'terrain',
|
||||
'sky',
|
||||
'person',
|
||||
'rider',
|
||||
'car',
|
||||
'truck',
|
||||
'bus',
|
||||
'train',
|
||||
'motorcycle',
|
||||
'bicycle'),
|
||||
'palette': [[128, 64, 128],
|
||||
[244, 35, 232],
|
||||
[70, 70, 70],
|
||||
[102, 102, 156],
|
||||
[190, 153, 153],
|
||||
[153, 153, 153],
|
||||
[250, 170, 30],
|
||||
[220, 220, 0],
|
||||
[107, 142, 35],
|
||||
[152, 251, 152],
|
||||
[70, 130, 180],
|
||||
[220, 20, 60],
|
||||
[255, 0, 0],
|
||||
[0, 0, 142],
|
||||
[0, 0, 70],
|
||||
[0, 60, 100],
|
||||
[0, 80, 100],
|
||||
[0, 0, 230],
|
||||
[119, 11, 32]],
|
||||
'label_map': None,
|
||||
'reduce_zero_label': False}
|
||||
```
|
||||
|
||||
数据集 `__getitem__` 方法的返回值, 是经过数据增强的样本数据的输出, 同样也是一个字典, 包括两个字段, `'inputs'` 字段是当前样本经过数据增强操作的图像, 类型为 torch.Tensor, `'data_samples'` 字段存放的数据类型是 MMSegmentation 1.x 新添加的数据结构 [`Segdatasample`](./structures.md), 其中`gt_sem_seg` 字段是经过数据增强的标签数据.
|
||||
|
||||
```python
|
||||
print(dataset[0])
|
||||
|
||||
{'inputs': tensor([[[131, 130, 130, ..., 23, 23, 23],
|
||||
[132, 132, 132, ..., 23, 22, 23],
|
||||
[134, 133, 133, ..., 23, 23, 23],
|
||||
...,
|
||||
[ 66, 67, 67, ..., 71, 71, 71],
|
||||
[ 66, 67, 66, ..., 68, 68, 68],
|
||||
[ 67, 67, 66, ..., 70, 70, 70]],
|
||||
|
||||
[[143, 143, 142, ..., 28, 28, 29],
|
||||
[145, 145, 145, ..., 28, 28, 29],
|
||||
[145, 145, 145, ..., 27, 28, 29],
|
||||
...,
|
||||
[ 75, 75, 76, ..., 80, 81, 81],
|
||||
[ 75, 76, 75, ..., 80, 80, 80],
|
||||
[ 77, 76, 76, ..., 82, 82, 82]],
|
||||
|
||||
[[126, 125, 126, ..., 21, 21, 22],
|
||||
[127, 127, 128, ..., 21, 21, 22],
|
||||
[127, 127, 126, ..., 21, 21, 22],
|
||||
...,
|
||||
[ 63, 63, 64, ..., 69, 69, 70],
|
||||
[ 64, 65, 64, ..., 69, 69, 69],
|
||||
[ 65, 66, 66, ..., 72, 71, 71]]], dtype=torch.uint8),
|
||||
'data_samples': <SegDataSample(
|
||||
|
||||
META INFORMATION
|
||||
img_path: 'data/cityscapes/leftImg8bit/train/aachen/aachen_000000_000019_leftImg8bit.png'
|
||||
seg_map_path: 'data/cityscapes/gtFine/train/aachen/aachen_000000_000019_gtFine_labelTrainIds.png'
|
||||
img_shape: (512, 1024, 3)
|
||||
flip_direction: None
|
||||
ori_shape: (1024, 2048)
|
||||
flip: False
|
||||
|
||||
DATA FIELDS
|
||||
gt_sem_seg: <PixelData(
|
||||
|
||||
META INFORMATION
|
||||
|
||||
DATA FIELDS
|
||||
data: tensor([[[2, 2, 2, ..., 8, 8, 8],
|
||||
[2, 2, 2, ..., 8, 8, 8],
|
||||
[2, 2, 2, ..., 8, 8, 8],
|
||||
...,
|
||||
[0, 0, 0, ..., 0, 0, 0],
|
||||
[0, 0, 0, ..., 0, 0, 0],
|
||||
[0, 0, 0, ..., 0, 0, 0]]])
|
||||
)>
|
||||
_gt_sem_seg: <PixelData(
|
||||
|
||||
META INFORMATION
|
||||
|
||||
DATA FIELDS
|
||||
data: tensor([[[2, 2, 2, ..., 8, 8, 8],
|
||||
[2, 2, 2, ..., 8, 8, 8],
|
||||
[2, 2, 2, ..., 8, 8, 8],
|
||||
...,
|
||||
[0, 0, 0, ..., 0, 0, 0],
|
||||
[0, 0, 0, ..., 0, 0, 0],
|
||||
[0, 0, 0, ..., 0, 0, 0]]])
|
||||
)>
|
||||
)}
|
||||
```
|
||||
|
||||
## BaseSegDataset
|
||||
|
||||
由于 MMSegmentation 中的所有数据集的基本功能均包括(1) 加载[数据集预处理](../user_guides/2_dataset_prepare.md) 之后的数据信息和 (2) 将数据送入数据变换流水线中进行数据变换, 因此在 MMSegmentation 中将其中的共同接口抽象成 [`BaseSegDataset`](https://mmsegmentation.readthedocs.io/zh_CN/latest/api.html?highlight=BaseSegDataset#mmseg.datasets.BaseSegDataset),它继承自 [MMEngine 的 `BaseDataset`](https://github.com/open-mmlab/mmengine/blob/main/docs/en/advanced_tutorials/basedataset.md), 遵循 OpenMMLab 数据集初始化统一流程, 支持高效的内部数据存储格式, 支持数据集拼接、数据集重复采样等功能.
|
||||
在 MMSegmentation BaseSegDataset 中重新定义了**数据信息加载方法**(`load_data_list`)和并新增了 `get_label_map` 方法用来**修改数据集的类别信息**.
|
||||
|
||||
### 数据信息加载
|
||||
|
||||
数据信息加载的内容是样本数据的图片路径和标签路径, 具体实现在 MMSegmentation 的 BaseSegDataset 的 [`load_data_list`](https://github.com/open-mmlab/mmsegmentation/blob/main/mmseg/datasets/basesegdataset.py#L231) 中.
|
||||
主要有两种获取图片和标签的路径方法, 如果当数据集目录按以下目录结构组织, [`load_data_list`](https://github.com/open-mmlab/mmsegmentation/blob/main/mmseg/datasets/basesegdataset.py#L231)) 会根据数据路径和后缀来解析.
|
||||
|
||||
```
|
||||
├── data
|
||||
│ ├── my_dataset
|
||||
│ │ ├── img_dir
|
||||
│ │ │ ├── train
|
||||
│ │ │ │ ├── xxx{img_suffix}
|
||||
│ │ │ │ ├── yyy{img_suffix}
|
||||
│ │ │ ├── val
|
||||
│ │ │ │ ├── zzz{img_suffix}
|
||||
│ │ ├── ann_dir
|
||||
│ │ │ ├── train
|
||||
│ │ │ │ ├── xxx{seg_map_suffix}
|
||||
│ │ │ │ ├── yyy{seg_map_suffix}
|
||||
│ │ │ ├── val
|
||||
│ │ │ │ ├── zzz{seg_map_suffix}
|
||||
```
|
||||
|
||||
例如 ADE20k 数据集结构如下所示:
|
||||
|
||||
```
|
||||
├── ade
|
||||
│ ├── ADEChallengeData2016
|
||||
│ │ ├── annotations
|
||||
│ │ │ ├── training
|
||||
│ │ │ │ ├── ADE_train_00000001.png
|
||||
│ │ │ │ ├── ...
|
||||
│ │ │ │── validation
|
||||
│ │ │ │ ├── ADE_val_00000001.png
|
||||
│ │ │ │ ├── ...
|
||||
│ │ ├── images
|
||||
│ │ │ ├── training
|
||||
│ │ │ │ ├── ADE_train_00000001.jpg
|
||||
│ │ │ │ ├── ...
|
||||
│ │ │ ├── validation
|
||||
│ │ │ │ ├── ADE_val_00000001.jpg
|
||||
│ │ │ │ ├── ...
|
||||
```
|
||||
|
||||
实例化 ADE20k 数据集时,输入图片和标签的路径和后缀:
|
||||
|
||||
```python
|
||||
from mmseg.datasets import ADE20KDataset
|
||||
|
||||
ADE20KDataset(data_root = 'data/ade/ADEChallengeData2016',
|
||||
data_prefix=dict(img_path='images/training', seg_map_path='annotations/training'),
|
||||
img_suffix='.jpg',
|
||||
seg_map_suffix='.png',
|
||||
reduce_zero_label=True)
|
||||
```
|
||||
|
||||
如果数据集有标注文件, 实例化数据集时会根据输入的数据集标注文件加载数据信息. 例如, PascalContext 数据集实例, 输入标注文件的内容为:
|
||||
|
||||
```python
|
||||
2008_000008
|
||||
...
|
||||
```
|
||||
|
||||
实例化时需要定义 `ann_file`
|
||||
|
||||
```python
|
||||
PascalContextDataset(data_root='data/VOCdevkit/VOC2010/',
|
||||
data_prefix=dict(img_path='JPEGImages', seg_map_path='SegmentationClassContext'),
|
||||
ann_file='ImageSets/SegmentationContext/train.txt')
|
||||
```
|
||||
|
||||
### 数据集类别修改
|
||||
|
||||
- 通过输入 metainfo 修改
|
||||
`BaseSegDataset` 的子类元信息在数据集实现时定义为类变量,例如 Cityscapes 的 `METAINFO` 变量:
|
||||
|
||||
```python
|
||||
class CityscapesDataset(BaseSegDataset):
|
||||
"""Cityscapes dataset.
|
||||
|
||||
The ``img_suffix`` is fixed to '_leftImg8bit.png' and ``seg_map_suffix`` is
|
||||
fixed to '_gtFine_labelTrainIds.png' for Cityscapes dataset.
|
||||
"""
|
||||
METAINFO = dict(
|
||||
classes=('road', 'sidewalk', 'building', 'wall', 'fence', 'pole',
|
||||
'traffic light', 'traffic sign', 'vegetation', 'terrain',
|
||||
'sky', 'person', 'rider', 'car', 'truck', 'bus', 'train',
|
||||
'motorcycle', 'bicycle'),
|
||||
palette=[[128, 64, 128], [244, 35, 232], [70, 70, 70], [102, 102, 156],
|
||||
[190, 153, 153], [153, 153, 153], [250, 170,
|
||||
30], [220, 220, 0],
|
||||
[107, 142, 35], [152, 251, 152], [70, 130, 180],
|
||||
[220, 20, 60], [255, 0, 0], [0, 0, 142], [0, 0, 70],
|
||||
[0, 60, 100], [0, 80, 100], [0, 0, 230], [119, 11, 32]])
|
||||
|
||||
```
|
||||
|
||||
这里的 `'classes'` 中定义了 Cityscapes 数据集标签中的类别名, 如果训练时只关注几个交通工具类别, **忽略其他类别**,
|
||||
在实例化 Cityscapes 数据集时通过定义 `metainfo` 输入参数的 classes 的字段来修改数据集的元信息:
|
||||
|
||||
```python
|
||||
from mmseg.datasets import CityscapesDataset
|
||||
|
||||
data_root = 'data/cityscapes/'
|
||||
data_prefix=dict(img_path='leftImg8bit/train', seg_map_path='gtFine/train')
|
||||
# metainfo 中只保留以下 classes
|
||||
metainfo=dict(classes=( 'car', 'truck', 'bus', 'train', 'motorcycle', 'bicycle'))
|
||||
dataset = CityscapesDataset(data_root=data_root, data_prefix=data_prefix, metainfo=metainfo)
|
||||
|
||||
print(dataset.metainfo)
|
||||
|
||||
{'classes': ('car', 'truck', 'bus', 'train', 'motorcycle', 'bicycle'),
|
||||
'palette': [[0, 0, 142],
|
||||
[0, 0, 70],
|
||||
[0, 60, 100],
|
||||
[0, 80, 100],
|
||||
[0, 0, 230],
|
||||
[119, 11, 32],
|
||||
[128, 64, 128],
|
||||
[244, 35, 232],
|
||||
[70, 70, 70],
|
||||
[102, 102, 156],
|
||||
[190, 153, 153],
|
||||
[153, 153, 153],
|
||||
[250, 170, 30],
|
||||
[220, 220, 0],
|
||||
[107, 142, 35],
|
||||
[152, 251, 152],
|
||||
[70, 130, 180],
|
||||
[220, 20, 60],
|
||||
[255, 0, 0]],
|
||||
# 类别索引为 255 的像素,在计算损失时会被忽略
|
||||
'label_map': {0: 255,
|
||||
1: 255,
|
||||
2: 255,
|
||||
3: 255,
|
||||
4: 255,
|
||||
5: 255,
|
||||
6: 255,
|
||||
7: 255,
|
||||
8: 255,
|
||||
9: 255,
|
||||
10: 255,
|
||||
11: 255,
|
||||
12: 255,
|
||||
13: 0,
|
||||
14: 1,
|
||||
15: 2,
|
||||
16: 3,
|
||||
17: 4,
|
||||
18: 5},
|
||||
'reduce_zero_label': False}
|
||||
```
|
||||
|
||||
可以看到, 数据集元信息的类别和默认 Cityscapes 不同. 并且, 定义了标签重映射的字段 `label_map` 用来修改每个分割掩膜上的像素的类别索引, 分割标签类别会根据 `label_map`, 将类别重映射, [具体实现](https://github.com/open-mmlab/mmsegmentation/blob/main/mmseg/datasets/basesegdataset.py#L151):
|
||||
|
||||
```python
|
||||
gt_semantic_seg_copy = gt_semantic_seg.copy()
|
||||
for old_id, new_id in results['label_map'].items():
|
||||
gt_semantic_seg[gt_semantic_seg_copy == old_id] = new_id
|
||||
```
|
||||
|
||||
- 通过 `reduce_zero_label` 修改
|
||||
对于常见的忽略 0 号标签的场景, `BaseSegDataset` 的子类中可以用 `reduce_zero_label` 输入参数来控制。`reduce_zero_label` (默认为 `False`)
|
||||
用来控制是否将标签 0 忽略, 当该参数为 `True` 时(最常见的应用是 ADE20k 数据集), 对分割标签中第 0 个类别对应的类别索引改为 255 (MMSegmentation 模型中计算损失时, 默认忽略 255), 其他类别对应的类别索引减一:
|
||||
|
||||
```python
|
||||
gt_semantic_seg[gt_semantic_seg == 0] = 255
|
||||
gt_semantic_seg = gt_semantic_seg - 1
|
||||
gt_semantic_seg[gt_semantic_seg == 254] = 255
|
||||
```
|
||||
|
||||
## 数据集与数据变换流水线
|
||||
|
||||
在常用接口的例子中可以看到, 输入的参数中定义了数据变换流水线参数 `pipeline`, 数据集 `__getitem__` 方法返回经过数据变换的值.
|
||||
当数据集输入参数没有定义 pipeline, 返回值和 `get_data_info` 方法返回值相同, 例如:
|
||||
|
||||
```python
|
||||
from mmseg.datasets import CityscapesDataset
|
||||
|
||||
data_root = 'data/cityscapes/'
|
||||
data_prefix=dict(img_path='leftImg8bit/train', seg_map_path='gtFine/train')
|
||||
dataset = CityscapesDataset(data_root=data_root, data_prefix=data_prefix, test_mode=False)
|
||||
|
||||
print(dataset[0])
|
||||
|
||||
{'img_path': 'data/cityscapes/leftImg8bit/train/aachen/aachen_000000_000019_leftImg8bit.png',
|
||||
'seg_map_path': 'data/cityscapes/gtFine/train/aachen/aachen_000000_000019_gtFine_labelTrainIds.png',
|
||||
'label_map': None,
|
||||
'reduce_zero_label': False,
|
||||
'seg_fields': [],
|
||||
'sample_idx': 0}
|
||||
```
|
||||
281
Seg_All_In_One_MMSeg/docs/zh_cn/advanced_guides/engine.md
Normal file
281
Seg_All_In_One_MMSeg/docs/zh_cn/advanced_guides/engine.md
Normal file
@@ -0,0 +1,281 @@
|
||||
# 训练引擎
|
||||
|
||||
MMEngine 定义了一些[基础循环控制器](https://github.com/open-mmlab/mmengine/blob/main/mmengine/runner/loops.py) 例如基于轮次的训练循环 (`EpochBasedTrainLoop`), 基于迭代次数的训练循环 (`IterBasedTrainLoop`), 标准的验证循环 (`ValLoop`) 和标准的测试循环 (`TestLoop`).
|
||||
OpenMMLab 的算法库如 MMSegmentation 将模型训练, 测试和推理抽象为执行器(`Runner`) 来处理. 用户可以直接使用 MMEngine 中的默认执行器, 也可以对执行器进行修改以满足定制化需求. 这个文档主要介绍用户如何配置已有的运行设定, 钩子和优化器的基本概念与使用方法.
|
||||
|
||||
## 配置运行设定
|
||||
|
||||
### 配置训练长度
|
||||
|
||||
循环控制器指的是训练, 验证和测试时的执行流程, 在配置文件里面使用 `train_cfg`, `val_cfg` 和 `test_cfg` 来构建这些流程. MMSegmentation 在 `configs/_base_/schedules` 文件夹里面的 `train_cfg` 设置常用的训练长度.
|
||||
例如, 使用基于迭代次数的训练循环 (`IterBasedTrainLoop`) 去训练 80,000 个迭代次数, 并且每 8,000 iteration 做一次验证, 可以如下设置:
|
||||
|
||||
```python
|
||||
train_cfg = dict(type='IterBasedTrainLoop', max_iters=80000, val_interval=8000)
|
||||
```
|
||||
|
||||
### 配置训练优化器
|
||||
|
||||
这里是一个 SGD 优化器的例子:
|
||||
|
||||
```python
|
||||
optim_wrapper = dict(
|
||||
type='OptimWrapper',
|
||||
optimizer=dict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0005),
|
||||
clip_grad=None)
|
||||
```
|
||||
|
||||
OpenMMLab 支持 PyTorch 里面所有的优化器, 更多细节可以参考 MMEngine [优化器文档](https://github.com/open-mmlab/mmengine/blob/main/docs/zh_cn/tutorials/optim_wrapper.md).
|
||||
|
||||
需要强调的是, `optim_wrapper` 是 `runner` 的变量, 所以需要配置优化器时配置的字段是 `optim_wrapper` 字段. 更多关于优化器的使用方法, 可以看下面优化器的章节.
|
||||
|
||||
### 配置训练参数调度器
|
||||
|
||||
在配置训练参数调度器前, 推荐先了解 [MMEngine 文档](https://github.com/open-mmlab/mmengine/blob/main/docs/en/tutorials/param_scheduler.md) 里面关于参数调度器的基本概念.
|
||||
|
||||
以下是一个参数调度器的例子, 训练时前 1,000 个 iteration 时采用线性变化的学习率策略作为训练预热, 从 1,000 iteration 之后直到最后 16,000 个 iteration 时则采用默认的多项式学习率衰减:
|
||||
|
||||
```python
|
||||
param_scheduler = [
|
||||
dict(type='LinearLR', by_epoch=False, start_factor=0.1, begin=0, end=1000),
|
||||
dict(
|
||||
type='PolyLR',
|
||||
eta_min=1e-4,
|
||||
power=0.9,
|
||||
begin=1000,
|
||||
end=160000,
|
||||
by_epoch=False,
|
||||
)
|
||||
]
|
||||
```
|
||||
|
||||
注意: 当修改 `train_cfg` 里面 `max_iters` 的时候, 请确保参数调度器 `param_scheduler` 里面的参数也被同时修改.
|
||||
|
||||
## 钩子 (Hook)
|
||||
|
||||
### 介绍
|
||||
|
||||
OpenMMLab 将模型训练和测试过程抽象为 `Runner`, 插入钩子可以实现在 `Runner` 中不同的训练和测试节点 (例如 "每个训练 iter 前后", "每个验证 iter 前后" 等不同阶段) 所需要的相应功能. 更多钩子机制的介绍可以参考[这里](https://www.calltutors.com/blog/what-is-hook).
|
||||
|
||||
`Runner` 中所使用的钩子分为两类:
|
||||
|
||||
- 默认钩子 (default hooks)
|
||||
|
||||
它们实现了训练时所必需的功能, 在配置文件中用 `default_hooks` 定义传给 `Runner`, `Runner` 通过 [`register_default_hooks`](https://github.com/open-mmlab/mmengine/blob/main/mmengine/runner/runner.py#L1780) 方法注册.
|
||||
钩子有对应的优先级, 优先级越高, 越早被执行器调用. 如果优先级一样, 被调用的顺序和钩子注册的顺序一致.
|
||||
不建议用户修改默认钩子的优先级, 可以参考 [mmengine hooks 文档](https://github.com/open-mmlab/mmengine/blob/main/docs/zh_cn/tutorials/hook.md) 了解钩子优先级的定义.
|
||||
下面是 MMSegmentation 中所用到的默认钩子:
|
||||
|
||||
| 钩子 | 功能 | 优先级 |
|
||||
| :--------------------------------------------------------------------------------------------------------------------: | :---------------------------------------------------------------------------------------------: | :---------------: |
|
||||
| [IterTimerHook](https://github.com/open-mmlab/mmengine/blob/main/mmengine/hooks/iter_timer_hook.py) | 记录 iteration 花费的时间. | NORMAL (50) |
|
||||
| [LoggerHook](https://github.com/open-mmlab/mmengine/blob/main/mmengine/hooks/logger_hook.py) | 从 `Runner` 里不同的组件中收集日志记录, 并将其输出到终端, JSON 文件, tensorboard, wandb 等下游. | BELOW_NORMAL (60) |
|
||||
| [ParamSchedulerHook](https://github.com/open-mmlab/mmengine/blob/main/mmengine/hooks/param_scheduler_hook.py) | 更新优化器里面的一些超参数, 例如学习率的动量. | LOW (70) |
|
||||
| [CheckpointHook](https://github.com/open-mmlab/mmengine/blob/main/mmengine/hooks/checkpoint_hook.py) | 规律性地保存 checkpoint 文件. | VERY_LOW (90) |
|
||||
| [DistSamplerSeedHook](https://github.com/open-mmlab/mmengine/blob/main/mmengine/hooks/sampler_seed_hook.py) | 确保分布式采样器 shuffle 是打开的. | NORMAL (50) |
|
||||
| [SegVisualizationHook](https://github.com/open-mmlab/mmsegmentation/blob/main/mmseg/visualization/local_visualizer.py) | 可视化验证和测试过程里的预测结果. | NORMAL (50) |
|
||||
|
||||
MMSegmentation 会在 [`defualt_hooks`](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/_base_/schedules/schedule_160k.py#L19-L25) 里面注册一些训练所必需功能的钩子::
|
||||
|
||||
```python
|
||||
default_hooks = dict(
|
||||
timer=dict(type='IterTimerHook'),
|
||||
logger=dict(type='LoggerHook', interval=50, log_metric_by_epoch=False),
|
||||
param_scheduler=dict(type='ParamSchedulerHook'),
|
||||
checkpoint=dict(type='CheckpointHook', by_epoch=False, interval=32000),
|
||||
sampler_seed=dict(type='DistSamplerSeedHook'),
|
||||
visualization=dict(type='SegVisualizationHook'))
|
||||
```
|
||||
|
||||
以上默认钩子除 `SegVisualizationHook` 外都是在 MMEngine 中所实现, `SegVisualizationHook` 是在 MMSegmentation 里被实现的钩子, 之后会专门介绍.
|
||||
|
||||
- 修改默认的钩子
|
||||
|
||||
以 `default_hooks` 里面的 `logger` 和 `checkpoint` 为例, 我们来介绍如何修改 `default_hooks` 中默认的钩子.
|
||||
|
||||
(1) 模型保存配置
|
||||
|
||||
`default_hooks` 使用 `checkpoint` 字段来初始化[模型保存钩子 (CheckpointHook)](https://github.com/open-mmlab/mmengine/blob/main/mmengine/hooks/checkpoint_hook.py#L19).
|
||||
|
||||
```python
|
||||
checkpoint = dict(type='CheckpointHook', interval=1)
|
||||
```
|
||||
|
||||
用户可以设置 `max_keep_ckpts` 来只保存少量的检查点或者用 `save_optimizer` 来决定是否保存 optimizer 的信息.
|
||||
更多相关参数的细节可以参考[这里](https://mmengine.readthedocs.io/zh_CN/latest/api/generated/mmengine.hooks.CheckpointHook.html#checkpointhook).
|
||||
|
||||
(2) 日志配置
|
||||
|
||||
`日志钩子 (LoggerHook)` 被用来收集 `执行器 (Runner)` 里面不同组件的日志信息然后写入终端, JSON 文件, tensorboard 和 wandb 等地方.
|
||||
|
||||
```python
|
||||
logger=dict(type='LoggerHook', interval=10)
|
||||
```
|
||||
|
||||
在最新的 1.x 版本的 MMSegmentation 里面, 一些日志钩子 (LoggerHook) 例如 `TextLoggerHook`, `WandbLoggerHook` 和 `TensorboardLoggerHook` 将不再被使用.
|
||||
作为替代, MMEngine 使用 `LogProcessor` 来处理上述钩子处理的信息, 它们现在在 [`MessageHub`](https://github.com/open-mmlab/mmengine/blob/main/mmengine/logging/message_hub.py#L17),
|
||||
[`WandbVisBackend`](https://github.com/open-mmlab/mmengine/blob/main/mmengine/visualization/vis_backend.py#L324) 和 [`TensorboardVisBackend`](https://github.com/open-mmlab/mmengine/blob/main/mmengine/visualization/vis_backend.py#L472) 里面.
|
||||
|
||||
具体使用方法如下, 配置可视化器和同时指定可视化后端, 这里使用 Tensorboard 作为可视化器的后端:
|
||||
|
||||
```python
|
||||
# TensorboardVisBackend
|
||||
visualizer = dict(
|
||||
type='SegLocalVisualizer', vis_backends=[dict(type='TensorboardVisBackend')], name='visualizer')
|
||||
```
|
||||
|
||||
关于更多相关用法, 可以参考 [MMEngine 可视化后端用户教程](https://github.com/open-mmlab/mmengine/blob/main/docs/zh_cn/advanced_tutorials/visualization.md).
|
||||
|
||||
- 自定义钩子 (custom hooks)
|
||||
|
||||
自定义钩子在配置通过 `custom_hooks` 定义, `Runner` 通过 [`register_custom_hooks`](https://github.com/open-mmlab/mmengine/blob/main/mmengine/runner/runner.py#L1820) 方法注册.
|
||||
自定义钩子优先级需要在配置文件里设置, 如果没有设置, 则会被默认设置为 `NORMAL`. 下面是部分 MMEngine 中实现的自定义钩子:
|
||||
|
||||
| 钩子 | 用法 |
|
||||
| :----------------------------------------------------------------------------------------------------: | :------------------------------------------------------------------------------------------: |
|
||||
| [EMAHook](https://github.com/open-mmlab/mmengine/blob/main/mmengine/hooks/ema_hook.py) | 在模型训练时使用指数滑动平均 (Exponential Moving Average, EMA). |
|
||||
| [EmptyCacheHook](https://github.com/open-mmlab/mmengine/blob/main/mmengine/hooks/empty_cache_hook.py) | 在训练时释放所有没有被缓存占用的 GPU 显存. |
|
||||
| [SyncBuffersHook](https://github.com/open-mmlab/mmengine/blob/main/mmengine/hooks/sync_buffer_hook.py) | 在每个训练 Epoch 结束时同步模型 buffer 里的参数例如 BN 里的 `running_mean` 和 `running_var`. |
|
||||
|
||||
以下是 `EMAHook` 的用例, 配置文件中, 将已经实现的自定义钩子的配置作为 `custom_hooks` 列表中的成员.
|
||||
|
||||
```python
|
||||
custom_hooks = [
|
||||
dict(type='EMAHook', start_iters=500, priority='NORMAL')
|
||||
]
|
||||
```
|
||||
|
||||
### SegVisualizationHook
|
||||
|
||||
MMSegmentation 实现了 [`SegVisualizationHook`](https://github.com/open-mmlab/mmsegmentation/blob/main/mmseg/engine/hooks/visualization_hook.py#L17), 用来在验证和测试时可视化预测结果.
|
||||
`SegVisualizationHook` 重写了基类 `Hook` 中的 `_after_iter` 方法, 在验证或测试时, 根据指定的迭代次数间隔调用 `visualizer` 的 `add_datasample` 方法绘制语义分割结果, 具体实现如下:
|
||||
|
||||
```python
|
||||
...
|
||||
@HOOKS.register_module()
|
||||
class SegVisualizationHook(Hook):
|
||||
...
|
||||
def _after_iter(self,
|
||||
runner: Runner,
|
||||
batch_idx: int,
|
||||
data_batch: dict,
|
||||
outputs: Sequence[SegDataSample],
|
||||
mode: str = 'val') -> None:
|
||||
...
|
||||
# 如果是训练阶段或者 self.draw 为 False 则直接跳出
|
||||
if self.draw is False or mode == 'train':
|
||||
return
|
||||
...
|
||||
if self.every_n_inner_iters(batch_idx, self.interval):
|
||||
for output in outputs:
|
||||
img_path = output.img_path
|
||||
img_bytes = self.file_client.get(img_path)
|
||||
img = mmcv.imfrombytes(img_bytes, channel_order='rgb')
|
||||
window_name = f'{mode}_{osp.basename(img_path)}'
|
||||
|
||||
self._visualizer.add_datasample(
|
||||
window_name,
|
||||
img,
|
||||
data_sample=output,
|
||||
show=self.show,
|
||||
wait_time=self.wait_time,
|
||||
step=runner.iter)
|
||||
|
||||
```
|
||||
|
||||
关于可视化更多的细节可以查看[这里](../user_guides/visualization.md).
|
||||
|
||||
## 优化器
|
||||
|
||||
在上面配置运行设定里, 我们给出了配置训练优化器的简单示例. 本章节将进一步详细介绍在 MMSegmentation 里如何配置优化器.
|
||||
|
||||
### 优化器封装
|
||||
|
||||
OpenMMLab 2.0 设计了优化器封装, 它支持不同的训练策略, 包括混合精度训练、梯度累加和梯度截断等, 用户可以根据需求选择合适的训练策略.
|
||||
优化器封装还定义了一套标准的参数更新流程, 用户可以基于这一套流程, 在同一套代码里, 实现不同训练策略的切换. 如果想了解更多, 可以参考 [MMEngine 优化器封装文档](https://github.com/open-mmlab/mmengine/blob/main/docs/zh_cn/tutorials/optim_wrapper.md).
|
||||
|
||||
以下是 MMSegmentation 中常用的使用方法:
|
||||
|
||||
#### 配置 PyTorch 支持的优化器
|
||||
|
||||
OpenMMLab 2.0 支持 PyTorch 原生所有优化器, 参考[这里](https://github.com/open-mmlab/mmengine/blob/main/docs/zh_cn/tutorials/optim_wrapper.md#%E7%AE%80%E5%8D%95%E9%85%8D%E7%BD%AE).
|
||||
|
||||
在配置文件中设置训练时 `Runner` 所使用的优化器, 需要定义 `optim_wrapper`, 而不是 `optimizer`, 下面是一个配置训练中优化器的例子:
|
||||
|
||||
```python
|
||||
optim_wrapper = dict(
|
||||
type='OptimWrapper',
|
||||
optimizer=dict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0005),
|
||||
clip_grad=None)
|
||||
```
|
||||
|
||||
#### 配置梯度裁剪
|
||||
|
||||
当模型训练需要使用梯度裁剪的训练技巧式, 可以按照如下示例进行配置:
|
||||
|
||||
```python
|
||||
optimizer = dict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0001)
|
||||
optim_wrapper = dict(type='OptimWrapper', optimizer=optimizer,
|
||||
clip_grad=dict(max_norm=0.01, norm_type=2))
|
||||
```
|
||||
|
||||
这里 `max_norm` 指的是裁剪后梯度的最大值, `norm_type` 指的是裁剪梯度时使用的范数. 相关方法可参考 [torch.nn.utils.clip_grad_norm\_](https://pytorch.org/docs/stable/generated/torch.nn.utils.clip_grad_norm_.html).
|
||||
|
||||
#### 配置混合精度训练
|
||||
|
||||
当需要使用混合精度训练降低内存时, 可以使用 `AmpOptimWrapper`, 具体配置如下:
|
||||
|
||||
```python
|
||||
optimizer = dict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0001)
|
||||
optim_wrapper = dict(type='AmpOptimWrapper', optimizer=optimizer)
|
||||
```
|
||||
|
||||
[`AmpOptimWrapper`](https://github.com/open-mmlab/mmengine/blob/main/mmengine/optim/optimizer/amp_optimizer_wrapper.py#L20) 中 `loss_scale` 的默认设置是 `dynamic`.
|
||||
|
||||
#### 配置模型网络不同层的超参数
|
||||
|
||||
在模型训练中, 如果想在优化器里为不同参数分别设置优化策略, 例如设置不同的学习率、权重衰减等超参数, 可以通过设置配置文件里 `optim_wrapper` 中的 `paramwise_cfg` 来实现.
|
||||
|
||||
下面的配置文件以 [ViT `optim_wrapper`](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/vit/vit_vit-b16-ln_mln_upernet_8xb2-160k_ade20k-512x512.py#L15-L27) 为例介绍 `paramwise_cfg` 参数使用.
|
||||
训练时将 `pos_embed`, `mask_token`, `norm` 模块的 weight decay 参数的系数设置成 0.
|
||||
即: 在训练时, 这些模块的 weight decay 将被变为 `weight_decay * decay_mult`=0.
|
||||
|
||||
```python
|
||||
optimizer = dict(
|
||||
type='AdamW', lr=0.00006, betas=(0.9, 0.999), weight_decay=0.01)
|
||||
optim_wrapper = dict(
|
||||
type='OptimWrapper',
|
||||
optimizer=optimizer,
|
||||
paramwise_cfg=dict(
|
||||
custom_keys={
|
||||
'pos_embed': dict(decay_mult=0.),
|
||||
'cls_token': dict(decay_mult=0.),
|
||||
'norm': dict(decay_mult=0.)
|
||||
}))
|
||||
```
|
||||
|
||||
其中 `decay_mult` 指的是对应参数的权重衰减的系数.
|
||||
关于更多 `paramwise_cfg` 的使用可以在 [MMEngine 优化器封装文档](https://github.com/open-mmlab/mmengine/blob/main/docs/zh_cn/tutorials/optim_wrapper.md) 里面查到.
|
||||
|
||||
### 优化器封装构造器
|
||||
|
||||
默认的优化器封装构造器 [`DefaultOptimWrapperConstructor`](https://github.com/open-mmlab/mmengine/blob/main/mmengine/optim/optimizer/default_constructor.py#L19) 根据输入的 `optim_wrapper` 和 `optim_wrapper` 中定义的 `paramwise_cfg` 来构建训练中使用的优化器. 当 [`DefaultOptimWrapperConstructor`](https://github.com/open-mmlab/mmengine/blob/main/mmengine/optim/optimizer/default_constructor.py#L19) 功能不能满足需求时, 可以自定义优化器封装构造器来实现超参数的配置.
|
||||
|
||||
MMSegmentation 中的实现了 [`LearningRateDecayOptimizerConstructor`](https://github.com/open-mmlab/mmsegmentation/blob/main/mmseg/engine/optimizers/layer_decay_optimizer_constructor.py#L104), 可以对以 ConvNeXt, BEiT 和 MAE 为骨干网络的模型训练时, 骨干网络的模型参数的学习率按照定义的衰减比例(`decay_rate`)逐层递减, 在配置文件中的配置如下:
|
||||
|
||||
```python
|
||||
optim_wrapper = dict(
|
||||
_delete_=True,
|
||||
type='AmpOptimWrapper',
|
||||
optimizer=dict(
|
||||
type='AdamW', lr=0.0001, betas=(0.9, 0.999), weight_decay=0.05),
|
||||
paramwise_cfg={
|
||||
'decay_rate': 0.9,
|
||||
'decay_type': 'stage_wise',
|
||||
'num_layers': 12
|
||||
},
|
||||
constructor='LearningRateDecayOptimizerConstructor',
|
||||
loss_scale='dynamic')
|
||||
```
|
||||
|
||||
`_delete_=True` 的作用是 OpenMMLab Config 中的忽略继承的配置, 在该代码片段中忽略继承的 `optim_wrapper` 配置, 更多 `_delete_` 字段的内容可以参考 [MMEngine 文档](https://github.com/open-mmlab/mmengine/blob/main/docs/zh_cn/advanced_tutorials/config.md#%E5%88%A0%E9%99%A4%E5%AD%97%E5%85%B8%E4%B8%AD%E7%9A%84-key).
|
||||
158
Seg_All_In_One_MMSeg/docs/zh_cn/advanced_guides/evaluation.md
Normal file
158
Seg_All_In_One_MMSeg/docs/zh_cn/advanced_guides/evaluation.md
Normal file
@@ -0,0 +1,158 @@
|
||||
# 模型评测
|
||||
|
||||
模型评测过程会分别在 [ValLoop](https://github.com/open-mmlab/mmengine/blob/main/mmengine/runner/loops.py#L300) 和 [TestLoop](https://github.com/open-mmlab/mmengine/blob/main/mmengine/runner/loops.py#L373) 中被执行,用户可以在训练期间或使用配置文件中简单设置的测试脚本进行模型性能评估。`ValLoop` 和 `TestLoop` 属于 [Runner](https://github.com/open-mmlab/mmengine/blob/main/mmengine/runner/runner.py#L59),它们会在第一次被调用时构建。由于 `dataloader` 与 `evaluator` 是必需的参数,所以要成功构建 `ValLoop`,在构建 `Runner` 时必须设置 `val_dataloader` 和 `val_evaluator`,`TestLoop` 亦然。有关 Runner 设计的更多信息,请参阅 [MMEngine](https://github.com/open-mmlab/mmengine) 的[文档](https://github.com/open-mmlab/mmengine/blob/main/docs/zh_cn/design/runner.md)。
|
||||
|
||||
<center>
|
||||
<img src='../../../resources/test_step.png' />
|
||||
<center>测试/验证 数据流</center>
|
||||
</center>
|
||||
|
||||
在 MMSegmentation 中,默认情况下,我们将 dataloader 和 metrics 的设置写在数据集配置文件中,并将 evaluation loop 的配置写在 `schedule_x` 配置文件中。
|
||||
|
||||
例如,在 ADE20K 配置文件 `configs/_base_/dataset/ADE20K.py` 中,在第37到48行,我们配置了 `val_dataloader`,在第51行,我们选择 `IoUMetric` 作为 evaluator,并设置 `mIoU` 作为指标:
|
||||
|
||||
```python
|
||||
val_dataloader = dict(
|
||||
batch_size=1,
|
||||
num_workers=4,
|
||||
persistent_workers=True,
|
||||
sampler=dict(type='DefaultSampler', shuffle=False),
|
||||
dataset=dict(
|
||||
type=dataset_type,
|
||||
data_root=data_root,
|
||||
data_prefix=dict(
|
||||
img_path='images/validation',
|
||||
seg_map_path='annotations/validation'),
|
||||
pipeline=test_pipeline))
|
||||
|
||||
val_evaluator = dict(type='IoUMetric', iou_metrics=['mIoU'])
|
||||
```
|
||||
|
||||
为了能够在训练期间进行评估模型,我们将评估配置添加到了 `configs/schedules/schedule_40k.py` 文件的第15至16行:
|
||||
|
||||
```python
|
||||
train_cfg = dict(type='IterBasedTrainLoop', max_iters=40000, val_interval=4000)
|
||||
val_cfg = dict(type='ValLoop')
|
||||
```
|
||||
|
||||
使用以上两种设置,MMSegmentation 在 40K 迭代训练期间,每 4000 次迭代进行一次模型 **mIoU** 指标的评估。
|
||||
|
||||
如果我们希望在训练后测试模型,则需要将 `test_dataloader`、`test_evaluator` 和 `test_cfg` 配置添加到配置文件中。
|
||||
|
||||
```python
|
||||
test_dataloader = dict(
|
||||
batch_size=1,
|
||||
num_workers=4,
|
||||
persistent_workers=True,
|
||||
sampler=dict(type='DefaultSampler', shuffle=False),
|
||||
dataset=dict(
|
||||
type=dataset_type,
|
||||
data_root=data_root,
|
||||
data_prefix=dict(
|
||||
img_path='images/validation',
|
||||
seg_map_path='annotations/validation'),
|
||||
pipeline=test_pipeline))
|
||||
|
||||
test_evaluator = dict(type='IoUMetric', iou_metrics=['mIoU'])
|
||||
test_cfg = dict(type='TestLoop')
|
||||
```
|
||||
|
||||
在 MMSegmentation 中,默认情况下,`test_dataloader` 和 `test_evaluator` 的设置与 `ValLoop` 的 dataloader 和 evaluator 相同,我们可以修改这些设置以满足我们的需要。
|
||||
|
||||
## IoUMetric
|
||||
|
||||
MMSegmentation 基于 [MMEngine](https://github.com/open-mmlab/mmengine) 提供的 [BaseMetric](https://github.com/open-mmlab/mmengine/blob/main/mmengine/evaluator/metric.py) 实现 [IoUMetric](https://github.com/open-mmlab/mmsegmentation/blob/1.x/mmseg/evaluation/metrics/iou_metric.py) 和 [CityscapesMetric](https://github.com/open-mmlab/mmsegmentation/blob/1.x/mmseg/evaluation/metrics/citys_metric.py),以评估模型的性能。有关统一评估接口的更多详细信息,请参阅[文档](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/evaluation.html)。
|
||||
|
||||
这里我们简要介绍 `IoUMetric` 的参数和两种主要方法。
|
||||
|
||||
除了 `collect_device` 和 `prefix` 之外,`IoUMetric` 的构建还包含一些其他参数。
|
||||
|
||||
构造函数的参数:
|
||||
|
||||
- ignore_index(int)- 将在评估中忽略的类别索引。默认值:255。
|
||||
- iou_metrics(list\[str\] | str)- 需要计算的指标,可选项包括 'mIoU'、'mDice' 和 'mFscore'。
|
||||
- nan_to_num(int,可选)- 如果指定,NaN 值将被用户定义的数字替换。默认值:None。
|
||||
- beta(int)- 决定综合评分中 recall 的权重。默认值:1。
|
||||
- collect_device(str)- 用于在分布式训练期间从不同进程收集结果的设备名称。必须是 'cpu' 或 'gpu'。默认为 'cpu'。
|
||||
- prefix(str,可选)- 将添加到指标名称中的前缀,以消除不同 evaluator 的同名指标的歧义。如果参数中未提供前缀,则将使用 self.default_prefix 进行替代。默认为 None。
|
||||
|
||||
`IoUMetric` 实现 IoU 指标的计算,`IoUMetric` 的两个核心方法是 `process` 和 `compute_metrics`。
|
||||
|
||||
- `process` 方法处理一批 data 和 data_samples。
|
||||
- `compute_metrics` 方法根据处理的结果计算指标。
|
||||
|
||||
### IoUMetric.process
|
||||
|
||||
参数:
|
||||
|
||||
- data_batch(Any)- 来自 dataloader 的一批数据。
|
||||
- data_samples(Sequence\[dict\])- 模型的一批输出。
|
||||
|
||||
返回值:
|
||||
|
||||
此方法没有返回值,因为处理的结果将存储在 `self.results` 中,以在处理完所有批次后进行指标的计算。
|
||||
|
||||
### IoUMetric.compute_metrics
|
||||
|
||||
参数:
|
||||
|
||||
- results(list)- 每个批次的处理结果。
|
||||
|
||||
返回值:
|
||||
|
||||
- Dict\[str,float\] - 计算的指标。指标的名称为 key,值是相应的结果。key 主要包括 **aAcc**、**mIoU**、**mAcc**、**mDice**、**mFscore**、**mPrecision**、**mPrecall**。
|
||||
|
||||
## CityscapesMetric
|
||||
|
||||
`CityscapesMetric` 使用由 Cityscapes 官方提供的 [CityscapesScripts](https://github.com/mcordts/cityscapesScripts) 进行模型性能的评估。
|
||||
|
||||
### 使用方法
|
||||
|
||||
在使用之前,请先安装 `cityscapesscripts` 包:
|
||||
|
||||
```shell
|
||||
pip install cityscapesscripts
|
||||
```
|
||||
|
||||
由于 `IoUMetric` 在 MMSegmentation 中作为默认的 evaluator 使用,如果您想使用 `CityscapesMetric`,则需要自定义配置文件。在自定义配置文件中,应按如下方式替换默认 evaluator。
|
||||
|
||||
```python
|
||||
val_evaluator = dict(type='CityscapesMetric', output_dir='tmp')
|
||||
test_evaluator = val_evaluator
|
||||
```
|
||||
|
||||
### 接口
|
||||
|
||||
构造函数的参数:
|
||||
|
||||
- output_dir (str) - 预测结果输出的路径
|
||||
- ignore_index (int) - 将在评估中忽略的类别索引。默认值:255。
|
||||
- format_only (bool) - 只为提交进行结果格式化而不进行评估。当您希望将结果格式化为特定格式并将其提交给测试服务器时有用。默认为 False。
|
||||
- keep_results (bool) - 是否保留结果。当 `format_only` 为 True 时,`keep_results` 必须为 True。默认为 False。
|
||||
- collect_device (str) - 用于在分布式训练期间从不同进程收集结果的设备名称。必须是 'cpu' 或 'gpu'。默认为 'cpu'。
|
||||
- prefix (str,可选) - 将添加到指标名称中的前缀,以消除不同 evaluator 的同名指标的歧义。如果参数中未提供前缀,则将使用 self.default_prefix 进行替代。默认为 None。
|
||||
|
||||
#### CityscapesMetric.process
|
||||
|
||||
该方法将在图像上绘制 mask,并将绘制的图像保存到 `work_dir` 中。
|
||||
|
||||
参数:
|
||||
|
||||
- data_batch(dict)- 来自 dataloader 的一批数据。
|
||||
- data_samples(Sequence\[dict\])- 模型的一批输出。
|
||||
|
||||
返回值:
|
||||
|
||||
此方法没有返回值,因为处理的结果将存储在 `self.results` 中,以在处理完所有批次后进行指标的计算。
|
||||
|
||||
#### CityscapesMetric.compute_metrics
|
||||
|
||||
此方法将调用 `cityscapessscripts.evaluation.evalPixelLevelSemanticLabeling` 工具来计算指标。
|
||||
|
||||
参数:
|
||||
|
||||
- results(list)- 数据集的测试结果。
|
||||
|
||||
返回值:
|
||||
|
||||
- dict\[str:float\] - Cityscapes 评测结果。
|
||||
26
Seg_All_In_One_MMSeg/docs/zh_cn/advanced_guides/index.rst
Normal file
26
Seg_All_In_One_MMSeg/docs/zh_cn/advanced_guides/index.rst
Normal file
@@ -0,0 +1,26 @@
|
||||
基本概念
|
||||
***************
|
||||
|
||||
.. toctree::
|
||||
:maxdepth: 1
|
||||
|
||||
data_flow.md
|
||||
structures.md
|
||||
models.md
|
||||
datasets.md
|
||||
transforms.md
|
||||
evaluation.md
|
||||
engine.md
|
||||
training_tricks.md
|
||||
|
||||
自定义组件
|
||||
************************
|
||||
|
||||
.. toctree::
|
||||
:maxdepth: 1
|
||||
|
||||
add_models.md
|
||||
add_datasets.md
|
||||
add_transforms.md
|
||||
add_metrics.md
|
||||
customize_runtime.md
|
||||
177
Seg_All_In_One_MMSeg/docs/zh_cn/advanced_guides/models.md
Normal file
177
Seg_All_In_One_MMSeg/docs/zh_cn/advanced_guides/models.md
Normal file
@@ -0,0 +1,177 @@
|
||||
# 模型
|
||||
|
||||
我们通常将深度学习任务中的神经网络定义为模型,这个模型即是算法的核心。[MMEngine](https://github.com/open-mmlab/mmengine) 抽象出了一个统一模型 [BaseModel](https://github.com/open-mmlab/mmengine/blob/main/mmengine/model/base_model/base_model.py#L16) 以标准化训练、测试和其他过程。MMSegmentation 实现的所有模型都继承自 `BaseModel`,并且在 MMSegmention 中,我们实现了前向传播并为语义分割算法添加了一些功能。
|
||||
|
||||
## 常用组件
|
||||
|
||||
### 分割器(Segmentor)
|
||||
|
||||
在 MMSegmentation 中,我们将网络架构抽象为**分割器**,它是一个包含网络所有组件的模型。我们已经实现了**编码器解码器(EncoderDecoder)**和**级联编码器解码器(CascadeEncoderDecoder)**,它们通常由**数据预处理器**、**骨干网络**、**解码头**和**辅助头**组成。
|
||||
|
||||
### 数据预处理器(Data preprocessor)
|
||||
|
||||
**数据预处理器**是将数据复制到目标设备并将数据预处理为模型输入格式的部分。
|
||||
|
||||
### 主干网络(Backbone)
|
||||
|
||||
**主干网络**是将图像转换为特征图的部分,例如没有最后全连接层的 **ResNet-50**。
|
||||
|
||||
### 颈部(Neck)
|
||||
|
||||
**颈部**是连接主干网络和头的部分。它对主干网络生成的原始特征图进行一些改进或重新配置。例如 **Feature Pyramid Network(FPN)**。
|
||||
|
||||
### 解码头(Decode head)
|
||||
|
||||
**解码头**是将特征图转换为分割掩膜的部分,例如 **PSPNet**。
|
||||
|
||||
### 辅助头(Auxiliary head)
|
||||
|
||||
**辅助头**是一个可选组件,它将特征图转换为仅用于计算辅助损失的分割掩膜。
|
||||
|
||||
## 基本接口
|
||||
|
||||
MMSegmentation 封装 `BaseModel` 并实现了 [BaseSegmentor](https://github.com/open-mmlab/mmsegmentation/blob/1.x/mmseg/models/segmentors/base.py#L15) 类,主要提供 `forward`、`train_step`、`val_step` 和 `test_step` 接口。接下来将详细介绍这些接口。
|
||||
|
||||
### forward
|
||||
|
||||
<center>
|
||||
<img src='https://user-images.githubusercontent.com/15952744/228827860-c0e34875-d370-4736-84f0-9560c26c9576.png' />
|
||||
<center>编码器解码器数据流</center>
|
||||
</center>
|
||||
|
||||
<center>
|
||||
<center><img src='https://user-images.githubusercontent.com/15952744/228827987-aa214507-0c6d-4a08-8ce4-679b2b200b79.png' /></center>
|
||||
<center>级联编码器解码器数据流</center>
|
||||
</center>
|
||||
|
||||
`forward` 方法返回训练、验证、测试和简单推理过程的损失或预测。
|
||||
|
||||
该方法应接受三种模式:“tensor”、“predict” 和 “loss”:
|
||||
|
||||
- “tensor”:前向推理整个网络并返回张量或张量数组,无需任何后处理,与常见的 `nn.Module` 相同。
|
||||
- “predict”:前向推理并返回预测值,这些预测值将被完全处理到 `SegDataSample` 列表中。
|
||||
- “loss”:前向推理并根据给定的输入和数据样本返回损失的`字典`。
|
||||
|
||||
**注:**[SegDataSample](https://github.com/open-mmlab/mmsegmentation/blob/1.x/mmseg/structures/seg_data_sample.py) 是 MMSegmentation 的数据结构接口,用作不同组件之间的接口。`SegDataSample` 实现了抽象数据元素 `mmengine.structures.BaseDataElement`,请参阅 [MMMEngine](https://github.com/open-mmlab/mmengine) 中的 [SegDataSample 文档](https://mmsegmentation.readthedocs.io/zh_CN/1.x/advanced_guides/structures.html)和[数据元素文档](https://mmengine.readthedocs.io/zh_CN/latest/advanced_tutorials/data_element.html)了解更多信息。
|
||||
|
||||
注意,此方法不处理在 `train_step` 方法中完成的反向传播或优化器更新。
|
||||
|
||||
参数:
|
||||
|
||||
- inputs(torch.Tensor)- 通常为形状是(N, C, ...) 的输入张量。
|
||||
- data_sample(list\[[SegDataSample](https://github.com/open-mmlab/mmsegmentation/blob/1.x/mmseg/structures/seg_data_sample.py)\]) - 分割数据样本。它通常包括 `metainfo` 和 `gt_sem_seg` 等信息。默认值为 None。
|
||||
- mode (str) - 返回什么类型的值。默认为 'tensor'。
|
||||
|
||||
返回值:
|
||||
|
||||
- `dict` 或 `list`:
|
||||
- 如果 `mode == "loss"`,则返回用于反向过程和日志记录的损失张量`字典`。
|
||||
- 如果 `mode == "predict"`,则返回 `SegDataSample` 的`列表`,推理结果将被递增地添加到传递给 forward 方法的 `data_sample` 参数中,每个 `SegDataSeample` 包含以下关键词:
|
||||
- pred_sm_seg (`PixelData`):语义分割的预测。
|
||||
- seg_logits (`PixelData`):标准化前语义分割的预测指标。
|
||||
- 如果 `mode == "tensor"`,则返回`张量`或`张量数组`的`字典`以供自定义使用。
|
||||
|
||||
### 预测模式
|
||||
|
||||
我们在[配置文档](../user_guides/1_config.md)中简要描述了模型配置的字段,这里我们详细介绍 `model.test_cfg` 字段。`model.test_cfg` 用于控制前向行为,`"predict"` 模式下的 `forward` 方法可以在两种模式下运行:
|
||||
|
||||
- `whole_inference`:如果 `cfg.model.test_cfg.mode == 'whole'`,则模型将使用完整图像进行推理。
|
||||
|
||||
`whole_inference` 模式的一个示例配置:
|
||||
|
||||
```python
|
||||
model = dict(
|
||||
type='EncoderDecoder'
|
||||
...
|
||||
test_cfg=dict(mode='whole')
|
||||
)
|
||||
```
|
||||
|
||||
- `slide_inference`:如果 `cfg.model.test_cfg.mode == ‘slide’`,则模型将通过滑动窗口进行推理。**注意:** 如果选择 `slide` 模式,还应指定 `cfg.model.test_cfg.stride` 和 `cfg.model.test_cfg.crop_size`。
|
||||
|
||||
`slide_inference` 模式的一个示例配置:
|
||||
|
||||
```python
|
||||
model = dict(
|
||||
type='EncoderDecoder'
|
||||
...
|
||||
test_cfg=dict(mode='slide', crop_size=256, stride=170)
|
||||
)
|
||||
```
|
||||
|
||||
### train_step
|
||||
|
||||
`train_step` 方法调用 `loss` 模式的前向接口以获得损失`字典`。`BaseModel` 类实现默认的模型训练过程,包括预处理、模型前向传播、损失计算、优化和反向传播。
|
||||
|
||||
参数:
|
||||
|
||||
- data (dict or tuple or list) - 从数据集采样的数据。在 MMSegmentation 中,数据字典包含 `inputs` 和 `data_samples` 两个字段。
|
||||
- optim_wrapper (OptimWrapper) - 用于更新模型参数的 OptimWrapper 实例。
|
||||
|
||||
**注:**[OptimWrapper](https://github.com/open-mmlab/mmengine/blob/main/mmengine/optim/optimizer/optimizer_wrapper.py#L17) 提供了一个用于更新参数的通用接口,请参阅 [MMMEngine](https://github.com/open-mmlab/mmengine) 中的优化器封装[文档](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/optim_wrapper.html)了解更多信息。
|
||||
|
||||
返回值:
|
||||
|
||||
-Dict\[str, `torch.Tensor`\]:用于记录日志的张量的`字典`。
|
||||
|
||||
<center>
|
||||
<img src='https://user-images.githubusercontent.com/15952744/228828089-a9ae1225-958d-4cf7-99af-9af8576f7ef7.png' />
|
||||
<center>train_step 数据流</center>
|
||||
</center>
|
||||
|
||||
### val_step
|
||||
|
||||
`val_step` 方法调用 `predict` 模式的前向接口并返回预测结果,预测结果将进一步被传递给评测器的进程接口和钩子的 `after_val_inter` 接口。
|
||||
|
||||
参数:
|
||||
|
||||
- data (`dict` or `tuple` or `list`) - 从数据集中采样的数据。在 MMSegmentation 中,数据字典包含 `inputs` 和 `data_samples` 两个字段。
|
||||
|
||||
返回值:
|
||||
|
||||
- `list` - 给定数据的预测结果。
|
||||
|
||||
<center>
|
||||
<img src='https://user-images.githubusercontent.com/15952744/228828179-3269baa3-bebd-4c9a-9787-59e7d785fbcf.png' />
|
||||
<center>test_step/val_step 数据流</center>
|
||||
</center>
|
||||
|
||||
### test_step
|
||||
|
||||
`BaseModel` 中 `test_step` 与 `val_step` 的实现相同。
|
||||
|
||||
## 数据预处理器(Data Preprocessor)
|
||||
|
||||
MMSegmentation 实现的 [SegDataPreProcessor](https://github.com/open-mmlab/mmsegmentation/blob/1.x/mmseg/models/data_preprocessor.py#L13) 继承自由 [MMEngine](https://github.com/open-mmlab/mmengine) 实现的 [BaseDataPreprocessor](https://github.com/open-mmlab/mmengine/blob/main/mmengine/model/base_model/data_preprocessor.py#L18),提供数据预处理和将数据复制到目标设备的功能。
|
||||
|
||||
Runner 在构建阶段将模型传送到指定的设备,而 [SegDataPreProcessor](https://github.com/open-mmlab/mmsegmentation/blob/1.x/mmseg/models/data_preprocessor.py#L13) 在 `train_step`、`val_step` 和 `test_step` 中将数据传送到指定设备,之后处理后的数据将被进一步传递给模型。
|
||||
|
||||
`SegDataPreProcessor` 构造函数的参数:
|
||||
|
||||
- mean (Sequence\[Number\], 可选) - R、G、B 通道的像素平均值。默认为 None。
|
||||
- std (Sequence\[Number\], 可选) - R、G、B 通道的像素标准差。默认为 None。
|
||||
- size (tuple, 可选) - 固定的填充大小。
|
||||
- size_divisor (int, 可选) - 填充大小的除法因子。
|
||||
- pad_val (float, 可选) - 填充值。默认值:0。
|
||||
- seg_pad_val (float, 可选) - 分割图的填充值。默认值:255。
|
||||
- bgr_to_rgb (bool) - 是否将图像从 BGR 转换为 RGB。默认为 False。
|
||||
- rgb_to_bgr (bool) - 是否将图像从 RGB 转换为 BGR。默认为 False。
|
||||
- batch_augments (list\[dict\], 可选) - 批量化的数据增强。默认值为 None。
|
||||
|
||||
数据将按如下方式处理:
|
||||
|
||||
- 收集数据并将其移动到目标设备。
|
||||
- 用定义的 `pad_val` 将输入填充到输入大小,并用定义的 `seg_Pad_val` 填充分割图。
|
||||
- 将输入堆栈到 batch_input。
|
||||
- 如果输入的形状为 (3, H, W),则将输入从 BGR 转换为 RGB。
|
||||
- 使用定义的标准差和平均值标准化图像。
|
||||
- 在训练期间进行如 Mixup 和 Cutmix 的批量化数据增强。
|
||||
|
||||
`forward` 方法的参数:
|
||||
|
||||
- data (dict) - 从数据加载器采样的数据。
|
||||
- training (bool) - 是否启用训练时数据增强。
|
||||
|
||||
`forward` 方法的返回值:
|
||||
|
||||
- Dict:与模型输入格式相同的数据。
|
||||
102
Seg_All_In_One_MMSeg/docs/zh_cn/advanced_guides/structures.md
Normal file
102
Seg_All_In_One_MMSeg/docs/zh_cn/advanced_guides/structures.md
Normal file
@@ -0,0 +1,102 @@
|
||||
# 数据结构
|
||||
|
||||
为了统一模型和各功能模块之间的输入和输出的接口, 在 OpenMMLab 2.0 MMEngine 中定义了一套抽象数据结构, 实现了基础的增/删/查/改功能, 支持不同设备间的数据迁移, 也支持了如
|
||||
`.cpu()`, `.cuda()`, `.get()` 和 `.detach()` 的类字典和张量的操作。具体可以参考 [MMEngine 文档](https://github.com/open-mmlab/mmengine/blob/main/docs/en/advanced_tutorials/data_element.md)。
|
||||
|
||||
同样的, MMSegmentation 亦遵循了 OpenMMLab 2.0 各模块间的接口协议, 定义了 `SegDataSample` 用来封装语义分割任务所需要的数据。
|
||||
|
||||
## 语义分割数据 SegDataSample
|
||||
|
||||
[SegDataSample](mmseg.structures.SegDataSample) 包括了三个主要数据字段 `gt_sem_seg`, `pred_sem_seg` 和 `seg_logits`, 分别用来存放标注信息, 预测结果和预测的未归一化前的 logits 值。
|
||||
|
||||
| 字段 | 类型 | 描述 |
|
||||
| -------------- | ------------------------- | ------------------------------- |
|
||||
| gt_sem_seg | [`PixelData`](#pixeldata) | 图像标注信息. |
|
||||
| pred_instances | [`PixelData`](#pixeldata) | 图像预测结果. |
|
||||
| seg_logits | [`PixelData`](#pixeldata) | 模型预测未归一化前的 logits 值. |
|
||||
|
||||
以下示例代码展示了 `SegDataSample` 的使用方法:
|
||||
|
||||
```python
|
||||
import torch
|
||||
from mmengine.structures import PixelData
|
||||
from mmseg.structures import SegDataSample
|
||||
|
||||
img_meta = dict(img_shape=(4, 4, 3),
|
||||
pad_shape=(4, 4, 3))
|
||||
data_sample = SegDataSample()
|
||||
# 定义 gt_segmentations 用于封装模型的输出信息
|
||||
gt_segmentations = PixelData(metainfo=img_meta)
|
||||
gt_segmentations.data = torch.randint(0, 2, (1, 4, 4))
|
||||
|
||||
# 增加和处理 SegDataSample 中的属性
|
||||
data_sample.gt_sem_seg = gt_segmentations
|
||||
assert 'gt_sem_seg' in data_sample
|
||||
assert 'data' in data_sample.gt_sem_seg
|
||||
assert 'img_shape' in data_sample.gt_sem_seg.metainfo_keys()
|
||||
print(data_sample.gt_sem_seg.shape)
|
||||
'''
|
||||
(4, 4)
|
||||
'''
|
||||
print(data_sample)
|
||||
'''
|
||||
<SegDataSample(
|
||||
|
||||
META INFORMATION
|
||||
|
||||
DATA FIELDS
|
||||
gt_sem_seg: <PixelData(
|
||||
|
||||
META INFORMATION
|
||||
img_shape: (4, 4, 3)
|
||||
pad_shape: (4, 4, 3)
|
||||
|
||||
DATA FIELDS
|
||||
data: tensor([[[1, 1, 1, 0],
|
||||
[1, 0, 1, 1],
|
||||
[1, 1, 1, 1],
|
||||
[0, 1, 0, 1]]])
|
||||
) at 0x1c2b4156460>
|
||||
) at 0x1c2aae44d60>
|
||||
'''
|
||||
|
||||
# 删除和修改 SegDataSample 中的属性
|
||||
data_sample = SegDataSample()
|
||||
gt_segmentations = PixelData(metainfo=img_meta)
|
||||
gt_segmentations.data = torch.randint(0, 2, (1, 4, 4))
|
||||
data_sample.gt_sem_seg = gt_segmentations
|
||||
data_sample.gt_sem_seg.set_metainfo(dict(img_shape=(4,4,9), pad_shape=(4,4,9)))
|
||||
del data_sample.gt_sem_seg.img_shape
|
||||
|
||||
# 类张量的操作
|
||||
data_sample = SegDataSample()
|
||||
gt_segmentations = PixelData(metainfo=img_meta)
|
||||
gt_segmentations.data = torch.randint(0, 2, (1, 4, 4))
|
||||
cuda_gt_segmentations = gt_segmentations.cuda()
|
||||
cuda_gt_segmentations = gt_segmentations.to('cuda:0')
|
||||
cpu_gt_segmentations = cuda_gt_segmentations.cpu()
|
||||
cpu_gt_segmentations = cuda_gt_segmentations.to('cpu')
|
||||
```
|
||||
|
||||
## 在 SegDataSample 中自定义新的属性
|
||||
|
||||
如果你想在 `SegDataSample` 中自定义新的属性,你可以参考下面的 [SegDataSample](https://github.com/open-mmlab/mmsegmentation/blob/1.x/mmseg/structures/seg_data_sample.py) 示例:
|
||||
|
||||
```python
|
||||
class SegDataSample(BaseDataElement):
|
||||
...
|
||||
|
||||
@property
|
||||
def xxx_property(self) -> xxxData:
|
||||
return self._xxx_property
|
||||
|
||||
@xxx_property.setter
|
||||
def xxx_property(self, value: xxxData) -> None:
|
||||
self.set_field(value, '_xxx_property', dtype=xxxData)
|
||||
|
||||
@xxx_property.deleter
|
||||
def xxx_property(self) -> None:
|
||||
del self._xxx_property
|
||||
```
|
||||
|
||||
这样一个新的属性 `xxx_property` 就将被增加到 `SegDataSample` 里面了。
|
||||
@@ -0,0 +1,74 @@
|
||||
# 训练技巧
|
||||
|
||||
MMSegmentation 支持如下训练技巧:
|
||||
|
||||
## 主干网络和解码头组件使用不同的学习率 (Learning Rate, LR)
|
||||
|
||||
在语义分割里,一些方法会让解码头组件的学习率大于主干网络的学习率,这样可以获得更好的表现或更快的收敛。
|
||||
|
||||
在 MMSegmentation 里面,您也可以在配置文件里添加如下行来让解码头组件的学习率是主干组件的10倍。
|
||||
|
||||
```python
|
||||
optim_wrapper=dict(
|
||||
paramwise_cfg = dict(
|
||||
custom_keys={
|
||||
'head': dict(lr_mult=10.)}))
|
||||
```
|
||||
|
||||
通过这种修改,任何被分组到 `'head'` 的参数的学习率都将乘以10。您也可以参照 [MMEngine 文档](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/optim_wrapper.html#id6) 获取更详细的信息。
|
||||
|
||||
## 在线难样本挖掘 (Online Hard Example Mining, OHEM)
|
||||
|
||||
MMSegmentation 中实现了像素采样器,训练时可以对特定像素进行采样,例如 OHEM(Online Hard Example Mining),可以解决样本不平衡问题,
|
||||
如下例子是使用 PSPNet 训练并采用 OHEM 策略的配置:
|
||||
|
||||
```python
|
||||
_base_ = './pspnet_r50-d8_512x1024_40k_cityscapes.py'
|
||||
model=dict(
|
||||
decode_head=dict(
|
||||
sampler=dict(type='OHEMPixelSampler', thresh=0.7, min_kept=100000)) )
|
||||
```
|
||||
|
||||
通过这种方式,只有置信分数在0.7以下的像素值点会被拿来训练。在训练时我们至少要保留100000个像素值点。如果 `thresh` 并未被指定,前 `min_kept`
|
||||
个损失的像素值点才会被选择。
|
||||
|
||||
## 类别平衡损失 (Class Balanced Loss)
|
||||
|
||||
对于不平衡类别分布的数据集,您也许可以改变每个类别的损失权重。这里以 cityscapes 数据集为例:
|
||||
|
||||
```python
|
||||
_base_ = './pspnet_r50-d8_512x1024_40k_cityscapes.py'
|
||||
model=dict(
|
||||
decode_head=dict(
|
||||
loss_decode=dict(
|
||||
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0,
|
||||
# DeepLab 对 cityscapes 使用这种权重
|
||||
class_weight=[0.8373, 0.9180, 0.8660, 1.0345, 1.0166, 0.9969, 0.9754,
|
||||
1.0489, 0.8786, 1.0023, 0.9539, 0.9843, 1.1116, 0.9037,
|
||||
1.0865, 1.0955, 1.0865, 1.1529, 1.0507])))
|
||||
```
|
||||
|
||||
`class_weight` 将被作为 `weight` 参数,传递给 `CrossEntropyLoss`。详细信息请参照 [PyTorch 文档](https://pytorch.org/docs/stable/nn.html?highlight=crossentropy#torch.nn.CrossEntropyLoss) 。
|
||||
|
||||
## 同时使用多种损失函数 (Multiple Losses)
|
||||
|
||||
对于训练时损失函数的计算,我们目前支持多个损失函数同时使用。 以 `unet` 使用 `DRIVE` 数据集训练为例,
|
||||
使用 `CrossEntropyLoss` 和 `DiceLoss` 的 `1:3` 的加权和作为损失函数。配置文件写为:
|
||||
|
||||
```python
|
||||
_base_ = './fcn_unet_s5-d16_64x64_40k_drive.py'
|
||||
model = dict(
|
||||
decode_head=dict(loss_decode=[
|
||||
dict(type='CrossEntropyLoss', loss_name='loss_ce', loss_weight=1.0),
|
||||
dict(type='DiceLoss', loss_name='loss_dice', loss_weight=3.0)
|
||||
]),
|
||||
auxiliary_head=dict(loss_decode=[
|
||||
dict(type='CrossEntropyLoss', loss_name='loss_ce', loss_weight=1.0),
|
||||
dict(type='DiceLoss', loss_name='loss_dice', loss_weight=3.0)
|
||||
]),
|
||||
)
|
||||
```
|
||||
|
||||
通过这种方式,确定训练过程中损失函数的权重 `loss_weight` 和在训练日志里的名字 `loss_name`。
|
||||
|
||||
注意: `loss_name` 的名字必须带有 `loss_` 前缀,这样它才能被包括在计算图里。
|
||||
119
Seg_All_In_One_MMSeg/docs/zh_cn/advanced_guides/transforms.md
Normal file
119
Seg_All_In_One_MMSeg/docs/zh_cn/advanced_guides/transforms.md
Normal file
@@ -0,0 +1,119 @@
|
||||
# 数据增强变化
|
||||
|
||||
在本教程中,我们将介绍 MMSegmentation 中数据增强变化流程的设计。
|
||||
|
||||
本指南的结构如下:
|
||||
|
||||
- [数据增强变化](#数据增强变化)
|
||||
- [数据增强变化流程设计](#数据增强变化流程设计)
|
||||
- [数据加载](#数据加载)
|
||||
- [预处理](#预处理)
|
||||
- [格式修改](#格式修改)
|
||||
|
||||
## 数据增强变化流程设计
|
||||
|
||||
按照惯例,我们使用 `Dataset` 和 `DataLoader` 多进程地加载数据。`Dataset` 返回与模型 forward 方法的参数相对应的数据项的字典。由于语义分割中的数据可能大小不同,我们在 MMCV 中引入了一种新的 `DataContainer` 类型,以帮助收集和分发不同大小的数据。参见[此处](https://github.com/open-mmlab/mmcv/blob/master/mmcv/parallel/data_container.py)了解更多详情。
|
||||
|
||||
在 MMSegmentation 的 1.x 版本中,所有数据转换都继承自 [`BaseTransform`](https://github.com/open-mmlab/mmcv/blob/2.x/mmcv/transforms/base.py#L6).
|
||||
|
||||
转换的输入和输出类型都是字典。一个简单的示例如下:
|
||||
|
||||
```python
|
||||
>>> from mmseg.datasets.transforms import LoadAnnotations
|
||||
>>> transforms = LoadAnnotations()
|
||||
>>> img_path = './data/cityscapes/leftImg8bit/train/aachen/aachen_000000_000019_leftImg8bit.png.png'
|
||||
>>> gt_path = './data/cityscapes/gtFine/train/aachen/aachen_000015_000019_gtFine_instanceTrainIds.png'
|
||||
>>> results = dict(
|
||||
>>> img_path=img_path,
|
||||
>>> seg_map_path=gt_path,
|
||||
>>> reduce_zero_label=False,
|
||||
>>> seg_fields=[])
|
||||
>>> data_dict = transforms(results)
|
||||
>>> print(data_dict.keys())
|
||||
dict_keys(['img_path', 'seg_map_path', 'reduce_zero_label', 'seg_fields', 'gt_seg_map'])
|
||||
```
|
||||
|
||||
数据准备流程和数据集是解耦的。通常,数据集定义如何处理标注,数据流程定义准备数据字典的所有步骤。流程由一系列操作组成。每个操作都将字典作为输入,并为接下来的转换输出字典。
|
||||
|
||||
操作分为数据加载、预处理、格式修改和测试数据增强。
|
||||
|
||||
这里是 PSPNet 的流程示例:
|
||||
|
||||
```python
|
||||
crop_size = (512, 1024)
|
||||
train_pipeline = [
|
||||
dict(type='LoadImageFromFile'),
|
||||
dict(type='LoadAnnotations'),
|
||||
dict(
|
||||
type='RandomResize',
|
||||
scale=(2048, 1024),
|
||||
ratio_range=(0.5, 2.0),
|
||||
keep_ratio=True),
|
||||
dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
|
||||
dict(type='RandomFlip', prob=0.5),
|
||||
dict(type='PhotoMetricDistortion'),
|
||||
dict(type='PackSegInputs')
|
||||
]
|
||||
test_pipeline = [
|
||||
dict(type='LoadImageFromFile'),
|
||||
dict(type='Resize', scale=(2048, 1024), keep_ratio=True),
|
||||
# add loading annotation after ``Resize`` because ground truth
|
||||
# does not need to resize data transform
|
||||
dict(type='LoadAnnotations'),
|
||||
dict(type='PackSegInputs')
|
||||
]
|
||||
```
|
||||
|
||||
对于每个操作,我们列出了 `添加`/`更新`/`删除` 相关的字典字段。在流程前,我们可以从数据集直接获得的信息是 `img_path` 和 `seg_map_path`。
|
||||
|
||||
### 数据加载
|
||||
|
||||
`LoadImageFromFile`:从文件加载图像。
|
||||
|
||||
- 添加:`img`,`img_shape`,`ori_shape`
|
||||
|
||||
`LoadAnnotations`:加载数据集提供的语义分割图。
|
||||
|
||||
- 添加:`seg_fields`,`gt_seg_map`
|
||||
|
||||
### 预处理
|
||||
|
||||
`RandomResize`:随机调整图像和分割图大小。
|
||||
|
||||
-添加:`scale`,`scale_factor`,`keep_ratio`
|
||||
-更新:`img`,`img_shape`,`gt_seg_map`
|
||||
|
||||
`Resize`:调整图像和分割图的大小。
|
||||
|
||||
-添加:`scale`,`scale_factor`,`keep_ratio`
|
||||
-更新:`img`,`gt_seg_map`,`img_shape`
|
||||
|
||||
`RandomCrop`:随机裁剪图像和分割图。
|
||||
|
||||
-更新:`img`,`gt_seg_map`,`img_shape`
|
||||
|
||||
`RandomFlip`:翻转图像和分割图。
|
||||
|
||||
-添加:`flip`,`flip_direction`
|
||||
-更新:`img`,`gt_seg_map`
|
||||
|
||||
`PhotoMetricDistortion`:按顺序对图像应用光度失真,每个变换的应用概率为 0.5。随机对比度的位置是第二或倒数第二(分别为下面的模式 0 或 1)。
|
||||
|
||||
```
|
||||
1.随机亮度
|
||||
2.随机对比度(模式 0)
|
||||
3.将颜色从 BGR 转换为 HSV
|
||||
4.随机饱和度
|
||||
5.随机色调
|
||||
6.将颜色从 HSV 转换为 BGR
|
||||
7.随机对比度(模式 1)
|
||||
```
|
||||
|
||||
- 更新:`img`
|
||||
|
||||
### 格式修改
|
||||
|
||||
`PackSegInputs`:为语义分段打包输入数据。
|
||||
|
||||
- 添加:`inputs`,`data_sample`
|
||||
- 删除:由 `meta_keys` 指定的 keys(合并到 data_sample 的 metainfo 中),所有其他 keys
|
||||
95
Seg_All_In_One_MMSeg/docs/zh_cn/api.rst
Normal file
95
Seg_All_In_One_MMSeg/docs/zh_cn/api.rst
Normal file
@@ -0,0 +1,95 @@
|
||||
mmseg.apis
|
||||
--------------
|
||||
.. automodule:: mmseg.apis
|
||||
:members:
|
||||
|
||||
mmseg.datasets
|
||||
--------------
|
||||
|
||||
datasets
|
||||
^^^^^^^^^^
|
||||
.. automodule:: mmseg.datasets
|
||||
:members:
|
||||
|
||||
transforms
|
||||
^^^^^^^^^^^^
|
||||
.. automodule:: mmseg.datasets.transforms
|
||||
:members:
|
||||
|
||||
mmseg.engine
|
||||
--------------
|
||||
|
||||
hooks
|
||||
^^^^^^^^^^
|
||||
.. automodule:: mmseg.engine.hooks
|
||||
:members:
|
||||
|
||||
optimizers
|
||||
^^^^^^^^^^^^^^^
|
||||
.. automodule:: mmseg.engine.optimizers
|
||||
:members:
|
||||
|
||||
mmseg.evaluation
|
||||
--------------
|
||||
|
||||
metrics
|
||||
^^^^^^^^^^
|
||||
.. automodule:: mmseg.evaluation.metrics
|
||||
:members:
|
||||
|
||||
mmseg.models
|
||||
--------------
|
||||
|
||||
backbones
|
||||
^^^^^^^^^^^^^^^^^^
|
||||
.. automodule:: mmseg.models.backbones
|
||||
:members:
|
||||
|
||||
decode_heads
|
||||
^^^^^^^^^^^^^^^
|
||||
.. automodule:: mmseg.models.decode_heads
|
||||
:members:
|
||||
|
||||
segmentors
|
||||
^^^^^^^^^^
|
||||
.. automodule:: mmseg.models.segmentors
|
||||
:members:
|
||||
|
||||
losses
|
||||
^^^^^^^^^^
|
||||
.. automodule:: mmseg.models.losses
|
||||
:members:
|
||||
|
||||
necks
|
||||
^^^^^^^^^^^^
|
||||
.. automodule:: mmseg.models.necks
|
||||
:members:
|
||||
|
||||
utils
|
||||
^^^^^^^^^^
|
||||
.. automodule:: mmseg.models.utils
|
||||
:members:
|
||||
|
||||
|
||||
mmseg.structures
|
||||
--------------------
|
||||
|
||||
structures
|
||||
^^^^^^^^^^^^^^^^^
|
||||
.. automodule:: mmseg.structures
|
||||
:members:
|
||||
|
||||
sampler
|
||||
^^^^^^^^^^
|
||||
.. automodule:: mmseg.structures.sampler
|
||||
:members:
|
||||
|
||||
mmseg.visualization
|
||||
--------------------
|
||||
.. automodule:: mmseg.visualization
|
||||
:members:
|
||||
|
||||
mmseg.utils
|
||||
--------------
|
||||
.. automodule:: mmseg.utils
|
||||
:members:
|
||||
133
Seg_All_In_One_MMSeg/docs/zh_cn/conf.py
Normal file
133
Seg_All_In_One_MMSeg/docs/zh_cn/conf.py
Normal file
@@ -0,0 +1,133 @@
|
||||
# Copyright (c) OpenMMLab. All rights reserved.
|
||||
# Configuration file for the Sphinx documentation builder.
|
||||
#
|
||||
# This file only contains a selection of the most common options. For a full
|
||||
# list see the documentation:
|
||||
# https://www.sphinx-doc.org/en/master/usage/configuration.html
|
||||
|
||||
# -- Path setup --------------------------------------------------------------
|
||||
|
||||
# If extensions (or modules to document with autodoc) are in another directory,
|
||||
# add these directories to sys.path here. If the directory is relative to the
|
||||
# documentation root, use os.path.abspath to make it absolute, like shown here.
|
||||
#
|
||||
import os
|
||||
import subprocess
|
||||
import sys
|
||||
|
||||
import pytorch_sphinx_theme
|
||||
|
||||
sys.path.insert(0, os.path.abspath('../../'))
|
||||
|
||||
# -- Project information -----------------------------------------------------
|
||||
|
||||
project = 'MMSegmentation'
|
||||
copyright = '2020-2021, OpenMMLab'
|
||||
author = 'MMSegmentation Authors'
|
||||
version_file = '../../mmseg/version.py'
|
||||
|
||||
|
||||
def get_version():
|
||||
with open(version_file) as f:
|
||||
exec(compile(f.read(), version_file, 'exec'))
|
||||
return locals()['__version__']
|
||||
|
||||
|
||||
# The full version, including alpha/beta/rc tags
|
||||
release = get_version()
|
||||
|
||||
# -- General configuration ---------------------------------------------------
|
||||
|
||||
# Add any Sphinx extension module names here, as strings. They can be
|
||||
# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
|
||||
# ones.
|
||||
extensions = [
|
||||
'sphinx.ext.autodoc', 'sphinx.ext.napoleon', 'sphinx.ext.viewcode',
|
||||
'sphinx_markdown_tables', 'sphinx_copybutton', 'myst_parser'
|
||||
]
|
||||
|
||||
autodoc_mock_imports = [
|
||||
'matplotlib', 'pycocotools', 'mmseg.version', 'mmcv.ops'
|
||||
]
|
||||
|
||||
# Ignore >>> when copying code
|
||||
copybutton_prompt_text = r'>>> |\.\.\. '
|
||||
copybutton_prompt_is_regexp = True
|
||||
|
||||
# Add any paths that contain templates here, relative to this directory.
|
||||
templates_path = ['_templates']
|
||||
|
||||
# The suffix(es) of source filenames.
|
||||
# You can specify multiple suffix as a list of string:
|
||||
#
|
||||
source_suffix = {
|
||||
'.rst': 'restructuredtext',
|
||||
'.md': 'markdown',
|
||||
}
|
||||
|
||||
# The master toctree document.
|
||||
master_doc = 'index'
|
||||
|
||||
# List of patterns, relative to source directory, that match files and
|
||||
# directories to ignore when looking for source files.
|
||||
# This pattern also affects html_static_path and html_extra_path.
|
||||
exclude_patterns = ['_build', 'Thumbs.db', '.DS_Store']
|
||||
|
||||
# -- Options for HTML output -------------------------------------------------
|
||||
|
||||
# The theme to use for HTML and HTML Help pages. See the documentation for
|
||||
# a list of builtin themes.
|
||||
#
|
||||
# html_theme = 'sphinx_rtd_theme'
|
||||
html_theme = 'pytorch_sphinx_theme'
|
||||
html_theme_path = [pytorch_sphinx_theme.get_html_theme_path()]
|
||||
html_theme_options = {
|
||||
'logo_url':
|
||||
'https://mmsegmentation.readthedocs.io/zh-CN/latest/',
|
||||
'menu': [
|
||||
{
|
||||
'name':
|
||||
'教程',
|
||||
'url':
|
||||
'https://github.com/open-mmlab/mmsegmentation/blob/master/'
|
||||
'demo/MMSegmentation_Tutorial.ipynb'
|
||||
},
|
||||
{
|
||||
'name': 'GitHub',
|
||||
'url': 'https://github.com/open-mmlab/mmsegmentation'
|
||||
},
|
||||
{
|
||||
'name':
|
||||
'上游库',
|
||||
'children': [
|
||||
{
|
||||
'name': 'MMCV',
|
||||
'url': 'https://github.com/open-mmlab/mmcv',
|
||||
'description': '基础视觉库'
|
||||
},
|
||||
]
|
||||
},
|
||||
],
|
||||
# Specify the language of shared menu
|
||||
'menu_lang':
|
||||
'cn',
|
||||
}
|
||||
|
||||
# Add any paths that contain custom static files (such as style sheets) here,
|
||||
# relative to this directory. They are copied after the builtin static files,
|
||||
# so a file named "default.css" will overwrite the builtin "default.css".
|
||||
html_static_path = ['_static']
|
||||
html_css_files = ['css/readthedocs.css']
|
||||
|
||||
# Enable ::: for my_st
|
||||
myst_enable_extensions = ['colon_fence']
|
||||
|
||||
language = 'zh-CN'
|
||||
|
||||
|
||||
def builder_inited_handler(app):
|
||||
subprocess.run(['./stat.py'])
|
||||
|
||||
|
||||
def setup(app):
|
||||
app.connect('builder-inited', builder_inited_handler)
|
||||
39
Seg_All_In_One_MMSeg/docs/zh_cn/device/npu.md
Normal file
39
Seg_All_In_One_MMSeg/docs/zh_cn/device/npu.md
Normal file
@@ -0,0 +1,39 @@
|
||||
# NPU (华为 昇腾)
|
||||
|
||||
## 使用方法
|
||||
|
||||
请参考 [MMCV 的安装文档](https://mmcv.readthedocs.io/en/latest/get_started/build.html#build-mmcv-full-on-ascend-npu-machine) 来安装 NPU 版本的 MMCV。
|
||||
|
||||
以下展示单机四卡场景的运行指令:
|
||||
|
||||
```shell
|
||||
bash tools/dist_train.sh configs/deeplabv3/deeplabv3_r50-d8_4xb2-40k_cityscapes-512x1024.py 4
|
||||
```
|
||||
|
||||
以下展示单机单卡下的运行指令:
|
||||
|
||||
```shell
|
||||
python tools/train.py configs/deeplabv3/deeplabv3_r50-d8_4xb2-40k_cityscapes-512x1024.py
|
||||
```
|
||||
|
||||
## 模型验证结果
|
||||
|
||||
| Model | mIoU | Config | Download |
|
||||
| :-----------------: | :---: | :----------------------------------------------------------------------------------------------------------------------------------------- | :------------------------------------------------------------------------------------------------------------------------------------------ |
|
||||
| [deeplabv3](<>) | 78.85 | [config](https://github.com/open-mmlab/mmsegmentation/tree/1.x/configs/deeplabv3/deeplabv3_r50-d8_4xb2-40k_cityscapes-512x1024.py) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/device/npu/deeplabv3_r50-d8_4xb2-40k_cityscapes-512x1024_20230115_205626.json) |
|
||||
| [deeplabv3plus](<>) | 79.23 | [config](https://github.com/open-mmlab/mmsegmentation/tree/1.x/configs/deeplabv3plus/deeplabv3plus_r50-d8_4xb2-40k_cityscapes-512x1024.py) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/device/npu/deeplabv3plus_r50-d8_4xb2-40k_cityscapes-512x1024_20230116_043450.json) |
|
||||
| [hrnet](<>) | 78.1 | [config](https://github.com/open-mmlab/mmsegmentation/tree/1.x/configs/hrnet/fcn_hr18_4xb2-40k_cityscapes-512x1024.py) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/device/npu/fcn_hr18_4xb2-40k_cityscapes-512x1024_20230116_215821.json) |
|
||||
| [fcn](<>) | 74.15 | [config](https://github.com/open-mmlab/mmsegmentation/tree/1.x/configs/fcn/fcn_r50-d8_4xb2-40k_cityscapes-512x1024.py) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/device/npu/fcn_r50-d8_4xb2-40k_cityscapes-512x1024_20230111_083014.json) |
|
||||
| [icnet](<>) | 69.25 | [config](https://github.com/open-mmlab/mmsegmentation/tree/1.x/configs/icnet/icnet_r50-d8_4xb2-80k_cityscapes-832x832.py) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/device/npu/icnet_r50-d8_4xb2-80k_cityscapes-832x832_20230119_002929.json) |
|
||||
| [pspnet](<>) | 77.21 | [config](https://github.com/open-mmlab/mmsegmentation/tree/1.x/configs/pspnet/pspnet_r50b-d8_4xb2-80k_cityscapes-512x1024.py) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/device/npu/pspnet_r50b-d8_4xb2-80k_cityscapes-512x1024_20230114_042721.json) |
|
||||
| [unet](<>) | 68.86 | [config](https://github.com/open-mmlab/mmsegmentation/tree/1.x/configs/unet/unet-s5-d16_fcn_4xb4-160k_cityscapes-512x1024.py) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/device/npu/unet-s5-d16_fcn_4xb4-160k_cityscapes-512x1024_20230129_224750.json) |
|
||||
| [upernet](<>) | 77.81 | [config](https://github.com/open-mmlab/mmsegmentation/tree/1.x/configs/upernet/upernet_r50_4xb2-40k_cityscapes-512x1024.py) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/device/npu/upernet_r50_4xb2-40k_cityscapes-512x1024_20230129_014634.json) |
|
||||
| [apcnet](<>) | 78.02 | [config](https://github.com/open-mmlab/mmsegmentation/tree/1.x/configs/apcnet/apcnet_r50-d8_4xb2-40k_cityscapes-512x1024.py) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/device/npu/apcnet_r50-d8_4xb2-40k_cityscapes-512x1024_20230209_212545.json) |
|
||||
| [bisenetv1](<>) | 76.04 | [config](https://github.com/open-mmlab/mmsegmentation/tree/1.x/configs/bisenetv1/bisenetv1_r50-d32_4xb4-160k_cityscapes-1024x1024.py) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/device/npu/bisenetv1_r50-d32_4xb4-160k_cityscapes-1024x1024_20230201_023946.json) |
|
||||
| [bisenetv2](<>) | 72.44 | [config](https://github.com/open-mmlab/mmsegmentation/tree/1.x/configs/bisenetv2/bisenetv2_fcn_4xb4-amp-160k_cityscapes-1024x1024.py) | [log](https://download.openmmlab.com/mmsegmentation/v0.5/device/npu/bisenetv2_fcn_4xb4-amp-160k_cityscapes-1024x1024_20230205_215606.json) |
|
||||
|
||||
**注意:**
|
||||
|
||||
- 如果没有特别标记,NPU 上的使用混合精度训练的结果与使用 FP32 的 GPU 上的结果相同。
|
||||
|
||||
**以上模型结果由华为昇腾团队提供**
|
||||
209
Seg_All_In_One_MMSeg/docs/zh_cn/get_started.md
Normal file
209
Seg_All_In_One_MMSeg/docs/zh_cn/get_started.md
Normal file
@@ -0,0 +1,209 @@
|
||||
# 开始:安装和运行 MMSeg
|
||||
|
||||
## 预备知识
|
||||
|
||||
本教程中,我们将会演示如何使用 PyTorch 准备环境。
|
||||
|
||||
MMSegmentation 可以在 Linux, Windows 和 macOS 系统上运行,并且需要安装 Python 3.7+, CUDA 10.2+ 和 PyTorch 1.8+
|
||||
|
||||
**注意:**
|
||||
如果您已经安装了 PyTorch, 可以跳过该部分,直接到[下一小节](##安装)。否则,您可以按照以下步骤操作。
|
||||
|
||||
**步骤 0.** 从[官方网站](https://docs.conda.io/en/latest/miniconda.html)下载并安装 Miniconda
|
||||
|
||||
**步骤 1.** 创建一个 conda 环境,并激活
|
||||
|
||||
```shell
|
||||
conda create --name openmmlab python=3.8 -y
|
||||
conda activate openmmlab
|
||||
```
|
||||
|
||||
**Step 2.** 参考 [official instructions](https://pytorch.org/get-started/locally/) 安装 PyTorch
|
||||
|
||||
在 GPU 平台上:
|
||||
|
||||
```shell
|
||||
conda install pytorch torchvision -c pytorch
|
||||
```
|
||||
|
||||
在 CPU 平台上
|
||||
|
||||
```shell
|
||||
conda install pytorch torchvision cpuonly -c pytorch
|
||||
```
|
||||
|
||||
## 安装
|
||||
|
||||
我们建议用户遵循我们的最佳实践来安装 MMSegmentation 。但是整个过程是高度自定义的。更多信息请参见[自定义安装](##自定义安装)部分。
|
||||
|
||||
### 最佳实践
|
||||
|
||||
**步骤 0.** 使用 [MIM](https://github.com/open-mmlab/mim) 安装 [MMCV](https://github.com/open-mmlab/mmcv)
|
||||
|
||||
```shell
|
||||
pip install -U openmim
|
||||
mim install mmengine
|
||||
mim install "mmcv>=2.0.0"
|
||||
```
|
||||
|
||||
**步骤 1.** 安装 MMSegmentation
|
||||
|
||||
情况 a: 如果您想立刻开发和运行 mmsegmentation,您可通过源码安装:
|
||||
|
||||
```shell
|
||||
git clone -b main https://github.com/open-mmlab/mmsegmentation.git
|
||||
cd mmsegmentation
|
||||
pip install -v -e .
|
||||
# '-v' 表示详细模式,更多的输出
|
||||
# '-e' 表示以可编辑模式安装工程,
|
||||
# 因此对代码所做的任何修改都生效,无需重新安装
|
||||
```
|
||||
|
||||
情况 b: 如果您把 mmsegmentation 作为依赖库或者第三方库,可以通过 pip 安装:
|
||||
|
||||
```shell
|
||||
pip install "mmsegmentation>=1.0.0"
|
||||
```
|
||||
|
||||
### 验证是否安装成功
|
||||
|
||||
为了验证 MMSegmentation 是否正确安装,我们提供了一些示例代码来运行一个推理 demo 。
|
||||
|
||||
**步骤 1.** 下载配置文件和模型文件
|
||||
|
||||
```shell
|
||||
mim download mmsegmentation --config pspnet_r50-d8_4xb2-40k_cityscapes-512x1024 --dest .
|
||||
```
|
||||
|
||||
该下载过程可能需要花费几分钟,这取决于您的网络环境。当下载结束,您将看到以下两个文件在您当前工作目录:`pspnet_r50-d8_4xb2-40k_cityscapes-512x1024.py` 和 `pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth`
|
||||
|
||||
**步骤 2.** 验证推理 demo
|
||||
|
||||
选项 (a). 如果您通过源码安装了 mmsegmentation,运行以下命令即可:
|
||||
|
||||
```shell
|
||||
python demo/image_demo.py demo/demo.png configs/pspnet/pspnet_r50-d8_4xb2-40k_cityscapes-512x1024.py pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth --device cuda:0 --out-file result.jpg
|
||||
```
|
||||
|
||||
您将在当前文件夹中看到一个新图像 `result.jpg`,其中所有目标都覆盖了分割 mask
|
||||
|
||||
选项 (b). 如果您通过 pip 安装 mmsegmentation, 打开您的 python 解释器,复制粘贴以下代码:
|
||||
|
||||
```python
|
||||
from mmseg.apis import inference_model, init_model, show_result_pyplot
|
||||
import mmcv
|
||||
|
||||
config_file = 'pspnet_r50-d8_4xb2-40k_cityscapes-512x1024.py'
|
||||
checkpoint_file = 'pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth'
|
||||
|
||||
# 根据配置文件和模型文件建立模型
|
||||
model = init_model(config_file, checkpoint_file, device='cuda:0')
|
||||
|
||||
# 在单张图像上测试并可视化
|
||||
img = 'demo/demo.png' # or img = mmcv.imread(img), 这样仅需下载一次
|
||||
result = inference_model(model, img)
|
||||
# 在新的窗口可视化结果
|
||||
show_result_pyplot(model, img, result, show=True)
|
||||
# 或者将可视化结果保存到图像文件夹中
|
||||
# 您可以修改分割 map 的透明度 (0, 1].
|
||||
show_result_pyplot(model, img, result, show=True, out_file='result.jpg', opacity=0.5)
|
||||
# 在一段视频上测试并可视化分割结果
|
||||
video = mmcv.VideoReader('video.mp4')
|
||||
for frame in video:
|
||||
result = inference_model(model, frame)
|
||||
show_result_pyplot(model, frame, result, wait_time=1)
|
||||
```
|
||||
|
||||
您可以修改上面的代码来测试单个图像或视频,这两个选项都可以验证安装是否成功。
|
||||
|
||||
### 自定义安装
|
||||
|
||||
#### CUDA 版本
|
||||
|
||||
当安装 PyTorch 的时候,您需要指定 CUDA 的版本, 如果您不确定选择哪个版本,请遵循我们的建议:
|
||||
|
||||
- 对于基于 Ampere 的 NVIDIA GPUs, 例如 GeForce 30 系列和 NVIDIA A100, 必须要求是 CUDA 11.
|
||||
- 对于更老的 NVIDIA GPUs, CUDA 11 is backward compatible, but CUDA 10.2 提供了更好的兼容性,以及更加的轻量化
|
||||
|
||||
请确保 GPU 驱动满足最小的版本需求。详情请参考这个[表格](https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html#cuda-major-component-versions__table-cuda-toolkit-driver-versions)
|
||||
|
||||
**注意:**
|
||||
如果您按照我们的最佳实践,安装 CUDA 运行库就足够了,因为不需要 CUDA 代码在本地编译。 但是如果您希望从源码编译 MMCV 或者需要开发其他的 CUDA 算子,您需要从 NVIDIA 的[官网](https://developer.nvidia.com/cuda-downloads)安装完整的 CUDA 工具,同时它的版本需要与 PyTorch 的 CUDA 版本匹配。即 `conda install` 命令中指定的 cudatoolkit 版本。
|
||||
|
||||
#### 不使用 MIM 安装 MMCV
|
||||
|
||||
MMCV 包含 C++ 和 CUDA 扩展,因此与 PyTorch 的依赖方式比较复杂。MIM 自动解决了这种依赖关系,使安装更容易。然而,MIM 也并不是必须的。
|
||||
|
||||
为了使用 pip 而不是 MIM 安装 MMCV, 请参考 [MMCV 安装指南](https://mmcv.readthedocs.io/en/latest/get_started/installation.html). 这需要手动指定一个基于 PyTorch 版本及其 CUDA 版本的 find-url.
|
||||
|
||||
例如,以下命令可为 PyTorch 1.10.x and CUDA 11.3 安装 mmcv==2.0.0
|
||||
|
||||
```shell
|
||||
pip install mmcv==2.0.0 -f https://download.openmmlab.com/mmcv/dist/cu113/torch1.10/index.html
|
||||
```
|
||||
|
||||
#### 在仅有 CPU 的平台安装
|
||||
|
||||
MMSegmentation 可以在仅有 CPU 的版本上运行。在 CPU 模式,您可以训练(需要 MMCV 版本 >= 2.0.0),测试和推理模型。
|
||||
|
||||
#### 在 Google Colab 上安装
|
||||
|
||||
[Google Colab](https://research.google.com/) 通常已经安装了 PyTorch,因此我们仅需要通过以下命令安装 MMCV 和 MMSegmentation。
|
||||
|
||||
**步骤 1.** 使用 [MIM](https://github.com/open-mmlab/mim) 安装 [MMCV](https://github.com/open-mmlab/mmcv)
|
||||
|
||||
```shell
|
||||
!pip3 install openmim
|
||||
!mim install mmengine
|
||||
!mim install "mmcv>=2.0.0"
|
||||
```
|
||||
|
||||
**Step 2.** 通过源码安装 MMSegmentation
|
||||
|
||||
```shell
|
||||
!git clone https://github.com/open-mmlab/mmsegmentation.git
|
||||
%cd mmsegmentation
|
||||
!git checkout main
|
||||
!pip install -e .
|
||||
```
|
||||
|
||||
**Step 3.** 验证
|
||||
|
||||
```python
|
||||
import mmseg
|
||||
print(mmseg.__version__)
|
||||
# 示例输出: 1.0.0
|
||||
```
|
||||
|
||||
**注意:**
|
||||
在 Jupyter 中, 感叹号 `!` 用于调用外部可执行命令,`%cd` 是一个 [magic command](https://ipython.readthedocs.io/en/stable/interactive/magics.html#magic-cd) 可以改变当前 python 的工作目录。
|
||||
|
||||
### 通过 Docker 使用 MMSegmentation
|
||||
|
||||
我们提供了一个 [Dockerfile](https://github.com/open-mmlab/mmsegmentation/blob/master/docker/Dockerfile) 来建立映像。确保您的 [docker 版本](https://docs.docker.com/engine/install/) >=19.03.
|
||||
|
||||
```shell
|
||||
# 通过 PyTorch 1.11, CUDA 11.3 建立映像
|
||||
# 如果您使用其他版本,修改 Dockerfile 即可
|
||||
docker build -t mmsegmentation docker/
|
||||
```
|
||||
|
||||
运行:
|
||||
|
||||
```shell
|
||||
docker run --gpus all --shm-size=8g -it -v {DATA_DIR}:/mmsegmentation/data mmsegmentation
|
||||
```
|
||||
|
||||
### 可选依赖
|
||||
|
||||
#### 安装 GDAL
|
||||
|
||||
[GDAL](https://gdal.org/) 是一个用于栅格和矢量地理空间数据格式的转换库。安装 GDAL 可以读取复杂格式和极大的遥感图像。
|
||||
|
||||
```shell
|
||||
conda install GDAL
|
||||
```
|
||||
|
||||
## 问题解答
|
||||
|
||||
如果您在安装过程中遇到了其他问题,请第一时间查阅 [FAQ](notes/faq.md) 文件。如果没有找到答案,您也可以在 GitHub 上提出 [issue](https://github.com/open-mmlab/mmsegmentation/issues/new/choose)
|
||||
BIN
Seg_All_In_One_MMSeg/docs/zh_cn/imgs/zhihu_qrcode.jpg
Normal file
BIN
Seg_All_In_One_MMSeg/docs/zh_cn/imgs/zhihu_qrcode.jpg
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 388 KiB |
57
Seg_All_In_One_MMSeg/docs/zh_cn/index.rst
Normal file
57
Seg_All_In_One_MMSeg/docs/zh_cn/index.rst
Normal file
@@ -0,0 +1,57 @@
|
||||
欢迎来到 MMSegmentation 的文档!
|
||||
=======================================
|
||||
|
||||
.. toctree::
|
||||
:maxdepth: 2
|
||||
:caption: 开始你的第一步
|
||||
|
||||
get_started.md
|
||||
|
||||
.. toctree::
|
||||
:maxdepth: 2
|
||||
:caption: 用户指南
|
||||
|
||||
user_guides/index.rst
|
||||
|
||||
.. toctree::
|
||||
:maxdepth: 2
|
||||
:caption: 进阶指南
|
||||
|
||||
advanced_guides/index.rst
|
||||
|
||||
.. toctree::
|
||||
:maxdepth: 1
|
||||
:caption: 迁移指引
|
||||
|
||||
migration/index.rst
|
||||
|
||||
.. toctree::
|
||||
:caption: 接口文档(英文)
|
||||
|
||||
api.rst
|
||||
|
||||
.. toctree::
|
||||
:maxdepth: 1
|
||||
:caption: 模型库
|
||||
|
||||
model_zoo.md
|
||||
modelzoo_statistics.md
|
||||
|
||||
.. toctree::
|
||||
:maxdepth: 2
|
||||
:caption: 说明
|
||||
|
||||
changelog.md
|
||||
faq.md
|
||||
|
||||
.. toctree::
|
||||
:caption: 语言切换
|
||||
|
||||
switch_language.md
|
||||
|
||||
|
||||
Indices and tables
|
||||
==================
|
||||
|
||||
* :ref:`genindex`
|
||||
* :ref:`search`
|
||||
35
Seg_All_In_One_MMSeg/docs/zh_cn/make.bat
Normal file
35
Seg_All_In_One_MMSeg/docs/zh_cn/make.bat
Normal file
@@ -0,0 +1,35 @@
|
||||
@ECHO OFF
|
||||
|
||||
pushd %~dp0
|
||||
|
||||
REM Command file for Sphinx documentation
|
||||
|
||||
if "%SPHINXBUILD%" == "" (
|
||||
set SPHINXBUILD=sphinx-build
|
||||
)
|
||||
set SOURCEDIR=.
|
||||
set BUILDDIR=_build
|
||||
|
||||
if "%1" == "" goto help
|
||||
|
||||
%SPHINXBUILD% >NUL 2>NUL
|
||||
if errorlevel 9009 (
|
||||
echo.
|
||||
echo.The 'sphinx-build' command was not found. Make sure you have Sphinx
|
||||
echo.installed, then set the SPHINXBUILD environment variable to point
|
||||
echo.to the full path of the 'sphinx-build' executable. Alternatively you
|
||||
echo.may add the Sphinx directory to PATH.
|
||||
echo.
|
||||
echo.If you don't have Sphinx installed, grab it from
|
||||
echo.http://sphinx-doc.org/
|
||||
exit /b 1
|
||||
)
|
||||
|
||||
%SPHINXBUILD% -M %1 %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O%
|
||||
goto end
|
||||
|
||||
:help
|
||||
%SPHINXBUILD% -M help %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O%
|
||||
|
||||
:end
|
||||
popd
|
||||
8
Seg_All_In_One_MMSeg/docs/zh_cn/migration/index.rst
Normal file
8
Seg_All_In_One_MMSeg/docs/zh_cn/migration/index.rst
Normal file
@@ -0,0 +1,8 @@
|
||||
迁移
|
||||
***************
|
||||
|
||||
.. toctree::
|
||||
:maxdepth: 1
|
||||
|
||||
interface.md
|
||||
package.md
|
||||
523
Seg_All_In_One_MMSeg/docs/zh_cn/migration/interface.md
Normal file
523
Seg_All_In_One_MMSeg/docs/zh_cn/migration/interface.md
Normal file
@@ -0,0 +1,523 @@
|
||||
# 从 MMSegmentation 0.x 迁移
|
||||
|
||||
## 引言
|
||||
|
||||
本指南介绍了 MMSegmentation 0.x 和 MMSegmentation1.x 在表现和 API 方面的基本区别,以及这些与迁移过程的关系。
|
||||
|
||||
## 新的依赖
|
||||
|
||||
MMSegmentation 1.x 依赖于一些新的软件包,您可以准备一个新的干净环境,然后根据[安装教程](../get_started.md)重新安装。
|
||||
|
||||
或手动安装以下软件包。
|
||||
|
||||
1. [MMEngine](https://github.com/open-mmlab/mmengine):MMEngine 是 OpenMMLab 2.0 架构的核心,我们将许多与计算机视觉无关的内容从 MMCV 拆分到 MMEngine 中。
|
||||
|
||||
2. [MMCV](https://github.com/open-mmlab/mmcv):OpenMMLab 的计算机视觉包。这不是一个新的依赖,但您需要将其升级到 **2.0.0** 或以上的版本。
|
||||
|
||||
3. [MMClassification](https://github.com/open-mmlab/mmclassification)(可选):OpenMMLab 的图像分类工具箱和基准。这不是一个新的依赖,但您需要将其升级到 **1.0.0rc6** 版本。
|
||||
|
||||
4. [MMDetection](https://github.com/open-mmlab/mmdetection)(可选): OpenMMLab 的目标检测工具箱和基准。这不是一个新的依赖,但您需要将其升级到 **3.0.0** 或以上的版本。
|
||||
|
||||
## 启动训练
|
||||
|
||||
OpenMMLab 2.0 的主要改进是发布了 MMEngine,它为启动训练任务的统一接口提供了通用且强大的执行器。
|
||||
|
||||
与 MMSeg 0.x 相比,MMSeg 1.x 在 `tools/train.py` 中提供的命令行参数更少
|
||||
|
||||
<table class="docutils">
|
||||
<tr>
|
||||
<td>功能</td>
|
||||
<td>原版</td>
|
||||
<td>新版</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>加载预训练模型</td>
|
||||
<td>--load_from=$CHECKPOINT</td>
|
||||
<td>--cfg-options load_from=$CHECKPOINT</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>从特定检查点恢复训练</td>
|
||||
<td>--resume-from=$CHECKPOINT</td>
|
||||
<td>--resume=$CHECKPOINT</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>从最新的检查点恢复训练</td>
|
||||
<td>--auto-resume</td>
|
||||
<td>--resume='auto'</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>训练期间是否不评估检查点</td>
|
||||
<td>--no-validate</td>
|
||||
<td>--cfg-options val_cfg=None val_dataloader=None val_evaluator=None</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>指定训练设备</td>
|
||||
<td>--gpu-id=$DEVICE_ID</td>
|
||||
<td>-</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>是否为不同进程设置不同的种子</td>
|
||||
<td>--diff-seed</td>
|
||||
<td>--cfg-options randomness.diff_rank_seed=True</td>
|
||||
</tr>
|
||||
<td>是否为 CUDNN 后端设置确定性选项</td>
|
||||
<td>--deterministic</td>
|
||||
<td>--cfg-options randomness.deterministic=True</td>
|
||||
</table>
|
||||
|
||||
## 测试启动
|
||||
|
||||
与训练启动类似,MMSegmentation 1.x 的测试启动脚本在 tools/test.py 中仅提供关键命令行参数,以下是测试启动脚本的区别,更多关于测试启动的细节请参考[这里](../user_guides/4_train_test.md)。
|
||||
|
||||
<table class="docutils">
|
||||
<tr>
|
||||
<td>功能</td>
|
||||
<td>0.x</td>
|
||||
<td>1.x</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>指定评测指标</td>
|
||||
<td>--eval mIoU</td>
|
||||
<td>--cfg-options test_evaluator.type=IoUMetric</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>测试时数据增强</td>
|
||||
<td>--aug-test</td>
|
||||
<td>--tta</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>测试时是否只保存预测结果不计算评测指标</td>
|
||||
<td>--format-only</td>
|
||||
<td>--cfg-options test_evaluator.format_only=True</td>
|
||||
</tr>
|
||||
</table>
|
||||
|
||||
## 配置文件
|
||||
|
||||
### 模型设置
|
||||
|
||||
`model.backend`、`model.neck`、`model.decode_head` 和 `model.loss` 字段没有更改。
|
||||
|
||||
添加 `model.data_preprocessor` 字段以配置 `DataPreProcessor`,包括:
|
||||
|
||||
- `mean`(Sequence,可选):R、G、B 通道的像素平均值。默认为 None。
|
||||
|
||||
- `std`(Sequence,可选):R、G、B 通道的像素标准差。默认为 None。
|
||||
|
||||
- `size`(Sequence,可选):固定的填充大小。
|
||||
|
||||
- `size_divisor`(int,可选):填充图像可以被当前值整除。
|
||||
|
||||
- `seg_pad_val`(float,可选):分割图的填充值。默认值:255。
|
||||
|
||||
- `padding_mode`(str):填充类型。默认值:'constant'。
|
||||
|
||||
- constant:常量值填充,值由 pad_val 指定。
|
||||
|
||||
- `bgr_to_rgb`(bool):是否将图像从 BGR 转换为 RGB。默认为 False。
|
||||
|
||||
- `rgb_to_bgr`(bool):是否将图像从 RGB 转换为 BGR。默认为 False。
|
||||
|
||||
**注:**
|
||||
有关详细信息,请参阅[模型文档](../advanced_guides/models.md)。
|
||||
|
||||
### 数据集设置
|
||||
|
||||
**data** 的更改:
|
||||
|
||||
原版 `data` 字段被拆分为 `train_dataloader`、`val_dataloader` 和 `test_dataloader`,允许我们以细粒度配置它们。例如,您可以在训练和测试期间指定不同的采样器和批次大小。
|
||||
`samples_per_gpu` 重命名为 `batch_size`。
|
||||
`workers_per_gpu` 重命名为 `num_workers`。
|
||||
|
||||
<table class="docutils">
|
||||
<tr>
|
||||
<td>原版</td>
|
||||
<td>
|
||||
|
||||
```python
|
||||
data = dict(
|
||||
samples_per_gpu=4,
|
||||
workers_per_gpu=4,
|
||||
train=dict(...),
|
||||
val=dict(...),
|
||||
test=dict(...),
|
||||
)
|
||||
```
|
||||
|
||||
</td>
|
||||
<tr>
|
||||
<td>新版</td>
|
||||
<td>
|
||||
|
||||
```python
|
||||
train_dataloader = dict(
|
||||
batch_size=4,
|
||||
num_workers=4,
|
||||
dataset=dict(...),
|
||||
sampler=dict(type='DefaultSampler', shuffle=True) # 必须
|
||||
)
|
||||
|
||||
val_dataloader = dict(
|
||||
batch_size=4,
|
||||
num_workers=4,
|
||||
dataset=dict(...),
|
||||
sampler=dict(type='DefaultSampler', shuffle=False) # 必须
|
||||
)
|
||||
|
||||
test_dataloader = val_dataloader
|
||||
```
|
||||
|
||||
</td>
|
||||
</tr>
|
||||
</table>
|
||||
|
||||
**数据增强变换流程**变更
|
||||
|
||||
- 原始格式转换 **`ToTensor`**、**`ImageToTensor`**、**`Collect`** 组合为 [`PackSegInputs`](mmseg.datasets.transforms.PackSegInputs)
|
||||
- 我们不建议在数据集流程中执行 **`Normalize`** 和 **Pad**。请将其从流程中删除,并将其设置在 `data_preprocessor` 字段中。
|
||||
- MMSeg 1.x 中原始的 **`Resize`** 已更改为 **`RandomResize `**,输入参数 `img_scale` 重命名为 `scale`,`keep_ratio` 的默认值修改为 False。
|
||||
- 原始的 `test_pipeline` 将单尺度和多尺度测试结合在一起,在 MMSeg 1.x 中,我们将其分为 `test_pipeline` 和 `tta_pipeline`。
|
||||
|
||||
**注:**
|
||||
我们将一些数据转换工作转移到数据预处理器中,如归一化,请参阅[文档](package.md)了解更多详细信息。
|
||||
|
||||
训练流程
|
||||
|
||||
<table class="docutils">
|
||||
<tr>
|
||||
<td>原版</td>
|
||||
<td>
|
||||
|
||||
```python
|
||||
train_pipeline = [
|
||||
dict(type='LoadImageFromFile'),
|
||||
dict(type='LoadAnnotations', reduce_zero_label=True),
|
||||
dict(type='Resize', img_scale=(2560, 640), ratio_range=(0.5, 2.0)),
|
||||
dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
|
||||
dict(type='RandomFlip', prob=0.5),
|
||||
dict(type='PhotoMetricDistortion'),
|
||||
dict(type='Normalize', **img_norm_cfg),
|
||||
dict(type='Pad', size=crop_size, pad_val=0, seg_pad_val=255),
|
||||
dict(type='DefaultFormatBundle'),
|
||||
dict(type='Collect', keys=['img', 'gt_semantic_seg']),
|
||||
]
|
||||
```
|
||||
|
||||
</td>
|
||||
<tr>
|
||||
<td>新版</td>
|
||||
<td>
|
||||
|
||||
```python
|
||||
train_pipeline = [
|
||||
dict(type='LoadImageFromFile'),
|
||||
dict(type='LoadAnnotations', reduce_zero_label=True),
|
||||
dict(
|
||||
type='RandomResize',
|
||||
scale=(2560, 640),
|
||||
ratio_range=(0.5, 2.0),
|
||||
keep_ratio=True),
|
||||
dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
|
||||
dict(type='RandomFlip', prob=0.5),
|
||||
dict(type='PhotoMetricDistortion'),
|
||||
dict(type='PackSegInputs')
|
||||
]
|
||||
```
|
||||
|
||||
</td>
|
||||
</tr>
|
||||
</table>
|
||||
|
||||
测试流程
|
||||
|
||||
<table class="docutils">
|
||||
<tr>
|
||||
<td>原版</td>
|
||||
<td>
|
||||
|
||||
```python
|
||||
test_pipeline = [
|
||||
dict(type='LoadImageFromFile'),
|
||||
dict(
|
||||
type='MultiScaleFlipAug',
|
||||
img_scale=(2560, 640),
|
||||
# img_ratios=[0.5, 0.75, 1.0, 1.25, 1.5, 1.75],
|
||||
flip=False,
|
||||
transforms=[
|
||||
dict(type='Resize', keep_ratio=True),
|
||||
dict(type='RandomFlip'),
|
||||
dict(type='Normalize', **img_norm_cfg),
|
||||
dict(type='ImageToTensor', keys=['img']),
|
||||
dict(type='Collect', keys=['img']),
|
||||
])
|
||||
]
|
||||
```
|
||||
|
||||
</td>
|
||||
<tr>
|
||||
<td>新版</td>
|
||||
<td>
|
||||
|
||||
```python
|
||||
test_pipeline = [
|
||||
dict(type='LoadImageFromFile'),
|
||||
dict(type='Resize', scale=(2560, 640), keep_ratio=True),
|
||||
dict(type='LoadAnnotations', reduce_zero_label=True),
|
||||
dict(type='PackSegInputs')
|
||||
]
|
||||
img_ratios = [0.5, 0.75, 1.0, 1.25, 1.5, 1.75]
|
||||
tta_pipeline = [
|
||||
dict(type='LoadImageFromFile', backend_args=None),
|
||||
dict(
|
||||
type='TestTimeAug',
|
||||
transforms=[
|
||||
[
|
||||
dict(type='Resize', scale_factor=r, keep_ratio=True)
|
||||
for r in img_ratios
|
||||
],
|
||||
[
|
||||
dict(type='RandomFlip', prob=0., direction='horizontal'),
|
||||
dict(type='RandomFlip', prob=1., direction='horizontal')
|
||||
], [dict(type='LoadAnnotations')], [dict(type='PackSegInputs')]
|
||||
])
|
||||
]
|
||||
```
|
||||
|
||||
</td>
|
||||
</tr>
|
||||
</table>
|
||||
|
||||
**`evaluation`** 中的更改:
|
||||
|
||||
- **`evaluation`** 字段被拆分为 `val_evaluator` 和 `test_evaluator `。而且不再支持 `interval` 和 `save_best` 参数。
|
||||
`interval` 已移动到 `train_cfg.val_interval`,`save_best` 已移动到 `default_hooks.checkpoint.save_best`。`pre_eval` 已删除。
|
||||
- `IoU` 已更改为 `IoUMetric`。
|
||||
|
||||
<table class="docutils">
|
||||
<tr>
|
||||
<td>原版</td>
|
||||
<td>
|
||||
|
||||
```python
|
||||
evaluation = dict(interval=2000, metric='mIoU', pre_eval=True)
|
||||
```
|
||||
|
||||
</td>
|
||||
<tr>
|
||||
<td>新版</td>
|
||||
<td>
|
||||
|
||||
```python
|
||||
val_evaluator = dict(type='IoUMetric', iou_metrics=['mIoU'])
|
||||
test_evaluator = val_evaluator
|
||||
```
|
||||
|
||||
</td>
|
||||
</tr>
|
||||
</table>
|
||||
|
||||
### Optimizer 和 Schedule 设置
|
||||
|
||||
**`optimizer`** 和 **`optimizer_config`** 中的更改:
|
||||
|
||||
- 现在我们使用 `optim_wrapper` 字段来指定优化过程的所有配置。以及 `optimizer` 是 `optim_wrapper` 的一个子字段。
|
||||
- `paramwise_cfg` 也是 `optim_wrapper` 的一个子字段,以替代 `optimizer`。
|
||||
- `optimizer_config` 现在被删除,它的所有配置都被移动到 `optim_wrapper` 中。
|
||||
- `grad_clip` 重命名为 `clip_grad`。
|
||||
|
||||
<table class="docutils">
|
||||
<tr>
|
||||
<td>原版</td>
|
||||
<td>
|
||||
|
||||
```python
|
||||
optimizer = dict(type='AdamW', lr=0.0001, weight_decay=0.0005)
|
||||
optimizer_config = dict(grad_clip=dict(max_norm=1, norm_type=2))
|
||||
```
|
||||
|
||||
</td>
|
||||
<tr>
|
||||
<td>新版</td>
|
||||
<td>
|
||||
|
||||
```python
|
||||
optim_wrapper = dict(
|
||||
type='OptimWrapper',
|
||||
optimizer=dict(type='AdamW', lr=0.0001, weight_decay=0.0005),
|
||||
clip_grad=dict(max_norm=1, norm_type=2))
|
||||
```
|
||||
|
||||
</td>
|
||||
</tr>
|
||||
</table>
|
||||
|
||||
**`lr_config`** 中的更改:
|
||||
|
||||
- 我们将 `lr_config` 字段删除,并使用新的 `param_scheduler` 替代。
|
||||
- 我们删除了与 `warmup` 相关的参数,因为我们使用 scheduler 组合来实现该功能。
|
||||
|
||||
新的 scheduler 组合机制非常灵活,您可以使用它来设计多种学习率/动量曲线。有关详细信息,请参见[教程](TODO)。
|
||||
|
||||
<table class="docutils">
|
||||
<tr>
|
||||
<td>原版</td>
|
||||
<td>
|
||||
|
||||
```python
|
||||
lr_config = dict(
|
||||
policy='poly',
|
||||
warmup='linear',
|
||||
warmup_iters=1500,
|
||||
warmup_ratio=1e-6,
|
||||
power=1.0,
|
||||
min_lr=0.0,
|
||||
by_epoch=False)
|
||||
```
|
||||
|
||||
</td>
|
||||
<tr>
|
||||
<td>新版</td>
|
||||
<td>
|
||||
|
||||
```python
|
||||
param_scheduler = [
|
||||
dict(
|
||||
type='LinearLR', start_factor=1e-6, by_epoch=False, begin=0, end=1500),
|
||||
dict(
|
||||
type='PolyLR',
|
||||
power=1.0,
|
||||
begin=1500,
|
||||
end=160000,
|
||||
eta_min=0.0,
|
||||
by_epoch=False,
|
||||
)
|
||||
]
|
||||
```
|
||||
|
||||
</td>
|
||||
</tr>
|
||||
</table>
|
||||
|
||||
**`runner`** 中的更改:
|
||||
|
||||
原版 `runner` 字段中的大多数配置被移动到 `train_cfg`、`val_cfg` 和 `test_cfg` 中,以在训练、验证和测试中配置 loop。
|
||||
|
||||
<table class="docutils">
|
||||
<tr>
|
||||
<td>原版</td>
|
||||
<td>
|
||||
|
||||
```python
|
||||
runner = dict(type='IterBasedRunner', max_iters=20000)
|
||||
```
|
||||
|
||||
</td>
|
||||
<tr>
|
||||
<td>新版</td>
|
||||
<td>
|
||||
|
||||
```python
|
||||
# `val_interval` 是旧版本的 `evaluation.interval`。
|
||||
train_cfg = dict(type='IterBasedTrainLoop', max_iters=20000, val_interval=2000)
|
||||
val_cfg = dict(type='ValLoop') # 使用默认的验证循环。
|
||||
test_cfg = dict(type='TestLoop') # 使用默认的测试循环。
|
||||
```
|
||||
|
||||
</td>
|
||||
</tr>
|
||||
</table>
|
||||
|
||||
事实上,在 OpenMMLab 2.0 中,我们引入了 `Loop` 来控制训练、验证和测试中的行为。`Runner` 的功能也发生了变化。您可以在 [MMMEngine](https://github.com/open-mmlab/mmengine/) 的[执行器教程](https://github.com/open-mmlab/mmengine/blob/main/docs/zh_cn/design/runner.md) 中找到更多的详细信息。
|
||||
|
||||
### 运行时设置
|
||||
|
||||
**`checkpoint_config`** 和 **`log_config`** 中的更改:
|
||||
|
||||
`checkpoint_config` 被移动到 `default_hooks.checkpoint` 中,`log_config` 被移动到 `default_hooks.logger` 中。
|
||||
并且我们将许多钩子设置从脚本代码移动到运行时配置的 `default_hooks` 字段中。
|
||||
|
||||
```python
|
||||
default_hooks = dict(
|
||||
# 记录每次迭代的时间。
|
||||
timer=dict(type='IterTimerHook'),
|
||||
|
||||
# 每50次迭代打印一次日志。
|
||||
logger=dict(type='LoggerHook', interval=50, log_metric_by_epoch=False),
|
||||
|
||||
# 启用参数调度程序。
|
||||
param_scheduler=dict(type='ParamSchedulerHook'),
|
||||
|
||||
# 每2000次迭代保存一次检查点。
|
||||
checkpoint=dict(type='CheckpointHook', by_epoch=False, interval=2000),
|
||||
|
||||
# 在分布式环境中设置采样器种子。
|
||||
sampler_seed=dict(type='DistSamplerSeedHook'),
|
||||
|
||||
# 验证结果可视化。
|
||||
visualization=dict(type='SegVisualizationHook'))
|
||||
```
|
||||
|
||||
此外,我们将原版 logger 拆分为 logger 和 visualizer。logger 用于记录信息,visualizer 用于在不同的后端显示 logger,如 terminal 和 TensorBoard。
|
||||
|
||||
<table class="docutils">
|
||||
<tr>
|
||||
<td>原版</td>
|
||||
<td>
|
||||
|
||||
```python
|
||||
log_config = dict(
|
||||
interval=100,
|
||||
hooks=[
|
||||
dict(type='TextLoggerHook'),
|
||||
dict(type='TensorboardLoggerHook'),
|
||||
])
|
||||
```
|
||||
|
||||
</td>
|
||||
<tr>
|
||||
<td>新版</td>
|
||||
<td>
|
||||
|
||||
```python
|
||||
default_hooks = dict(
|
||||
...
|
||||
logger=dict(type='LoggerHook', interval=100),
|
||||
)
|
||||
vis_backends = [dict(type='LocalVisBackend'),
|
||||
dict(type='TensorboardVisBackend')]
|
||||
visualizer = dict(
|
||||
type='SegLocalVisualizer', vis_backends=vis_backends, name='visualizer')
|
||||
```
|
||||
|
||||
</td>
|
||||
</tr>
|
||||
</table>
|
||||
|
||||
**`load_from`** 和 **`resume_from`** 中的更改:
|
||||
|
||||
- 删除 `resume_from`。我们使用 `resume` 和 `load_from` 来替换它。
|
||||
- 如果 `resume=True` 且 `load_from` 为 **not None**,则从 `load_from` 中的检查点恢复训练。
|
||||
- 如果 `resume=True` 且 `load_from` 为 **None**,则尝试从工作目录中的最新检查点恢复。
|
||||
- 如果 `resume=False` 且 `load_from` 为 **not None**,则只加载检查点,而不继续训练。
|
||||
- 如果 `resume=False` 且 `load_from` 为 **None**,则不加载或恢复。
|
||||
|
||||
**`dist_params`** 中的更改:`dist_params` 字段现在是 `env_cfg` 的子字段。并且 `env_cfg` 中还有一些新的配置。
|
||||
|
||||
```python
|
||||
env_cfg = dict(
|
||||
# 是否启用 cudnn_benchmark
|
||||
cudnn_benchmark=False,
|
||||
|
||||
# 设置多进程参数
|
||||
mp_cfg=dict(mp_start_method='fork', opencv_num_threads=0),
|
||||
|
||||
# 设置分布式参数
|
||||
dist_cfg=dict(backend='nccl'),
|
||||
)
|
||||
```
|
||||
|
||||
**`workflow`** 的改动:`workflow` 相关功能被删除。
|
||||
|
||||
新字段 **`visualizer`**:visualizer 是 OpenMMLab 2.0 体系结构中的新设计。我们在 runner 中使用 visualizer 实例来处理结果和日志可视化,并保存到不同的后端。更多详细信息,请参阅[可视化教程](../user_guides/visualization.md)。
|
||||
|
||||
新字段 **`default_scope`**:搜索所有注册模块的起点。MMSegmentation 中的 `default_scope` 为 `mmseg`。请参见[注册器教程](https://github.com/open-mmlab/mmengine/blob/main/docs/zh_cn/advanced_tutorials/registry.md)了解更多详情。
|
||||
113
Seg_All_In_One_MMSeg/docs/zh_cn/migration/package.md
Normal file
113
Seg_All_In_One_MMSeg/docs/zh_cn/migration/package.md
Normal file
@@ -0,0 +1,113 @@
|
||||
# 包结构更改
|
||||
|
||||
本节包含您对 MMSeg 0.x 和 1.x 之间的变化可能感到好奇的内容。
|
||||
|
||||
<table>
|
||||
<tr>
|
||||
<td>MMSegmentation 0.x</td>
|
||||
<td>MMSegmentation 1.x</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>mmseg.api</td>
|
||||
<td>mmseg.api</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td bgcolor=#fcf7f7>- mmseg.core</td>
|
||||
<td bgcolor=#ecf4eb>+ mmseg.engine</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>mmseg.datasets</td>
|
||||
<td>mmseg.datasets</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>mmseg.models</td>
|
||||
<td>mmseg.models</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td bgcolor=#fcf7f7>- mmseg.ops</td>
|
||||
<td bgcolor=#ecf4eb>+ mmseg.structure</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>mmseg.utils</td>
|
||||
<td>mmseg.utils</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td></td>
|
||||
<td bgcolor=#ecf4eb>+ mmseg.evaluation</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td></td>
|
||||
<td bgcolor=#ecf4eb>+ mmseg.registry</td>
|
||||
<tr>
|
||||
</table>
|
||||
|
||||
## 已删除的包
|
||||
|
||||
### `mmseg.core`
|
||||
|
||||
在 OpenMMLab 2.0 中,`core` 包已被删除。`core` 的 `hooks` 和 `optimizers` 被移动到了 `mmseg.engine` 中,而 `core` 中的 `evaluation` 目前是 mmseg.evaluation。
|
||||
|
||||
## `mmseg.ops`
|
||||
|
||||
`ops` 包含 `encoding` 和 `wrappers`,它们被移到了 `mmseg.models.utils` 中。
|
||||
|
||||
## 增加的包
|
||||
|
||||
### `mmseg.engine`
|
||||
|
||||
OpenMMLab 2.0 增加了一个新的深度学习训练基础库 MMEngine。它是所有 OpenMMLab 代码库的训练引擎。
|
||||
mmseg 的 `engine` 包是一些用于语义分割任务的定制模块,如 `SegVisualizationHook` 用于可视化分割掩膜。
|
||||
|
||||
### `mmseg.structure`
|
||||
|
||||
在 OpenMMLab 2.0 中,我们为计算机视觉任务设计了数据结构,在 mmseg 中,我们在 `structure` 包中实现了 `SegDataSample`。
|
||||
|
||||
### `mmseg.evaluation`
|
||||
|
||||
我们将所有评估指标都移动到了 `mmseg.evaluation` 中。
|
||||
|
||||
### `mmseg.registry`
|
||||
|
||||
我们将 MMSegmentation 中所有类型模块的注册实现移动到 `mmseg.registry` 中。
|
||||
|
||||
## 修改的包
|
||||
|
||||
### `mmseg.apis`
|
||||
|
||||
OpenMMLab 2.0 尝试支持计算机视觉的多任务统一接口,并发布了更强的 [`Runner`](https://github.com/open-mmlab/mmengine/blob/main/docs/zh_cn/design/runner.md),因此 MMSeg 1.x 删除了 `train.py` 和 `test.py` 中的模块,并将 `init_segmentor` 重命名为 `init_model`,将 `inference_segmentor` 重命名为 `inference_model`。
|
||||
|
||||
以下是 `mmseg.apis` 的更改:
|
||||
|
||||
| 函数 | 变化 |
|
||||
| :-------------------: | :--------------------------------------------- |
|
||||
| `init_segmentor` | 重命名为 `init_model` |
|
||||
| `inference_segmentor` | 重命名为 `inference_model` |
|
||||
| `show_result_pyplot` | 基于 `SegLocalVisualizer` 实现 |
|
||||
| `train_model` | 删除,使用 `runner.train` 训练。 |
|
||||
| `multi_gpu_test` | 删除,使用 `runner.test` 测试。 |
|
||||
| `single_gpu_test` | 删除,使用 `runner.test` 测试。 |
|
||||
| `set_random_seed` | 删除,使用 `mmengine.runner.set_random_seed`。 |
|
||||
| `init_random_seed` | 删除,使用 `mmengine.dist.sync_random_seed`。 |
|
||||
|
||||
### `mmseg.datasets`
|
||||
|
||||
OpenMMLab 2.0 将 `BaseDataset` 定义为数据集的函数和接口,MMSegmentation 1.x 也遵循此协议,并定义了从 `BaseDataset` 继承的 `BaseSegDataset`。MMCV 2.x 收集多种任务的通用数据转换,例如分类、检测、分割,因此 MMSegmentation 1.x 使用这些数据转换并将其从 mmseg.dataset 中删除。
|
||||
|
||||
| 包/模块 | 更改 |
|
||||
| :-------------------: | :----------------------------------------------------------------------------------- |
|
||||
| `mmseg.pipelines` | 移动到 `mmcv.transforms` 中 |
|
||||
| `mmseg.sampler` | 移动到 `mmengine.dataset.sampler` 中 |
|
||||
| `CustomDataset` | 重命名为 `BaseSegDataset` 并从 MMEngine 中的 `BaseDataset` 继承 |
|
||||
| `DefaultFormatBundle` | 替换为 `PackSegInputs` |
|
||||
| `LoadImageFromFile` | 移动到 `mmcv.transforms.LoadImageFromFile` 中 |
|
||||
| `LoadAnnotations` | 移动到 `mmcv.transforms.LoadAnnotations` 中 |
|
||||
| `Resize` | 移动到 `mmcv.transforms` 中并拆分为 `Resize`,`RandomResize` 和 `RandomChoiceResize` |
|
||||
| `RandomFlip` | 移动到 `mmcv.transforms.RandomFlip` 中 |
|
||||
| `Pad` | 移动到 `mmcv.transforms.Pad` 中 |
|
||||
| `Normalize` | 移动到 `mmcv.transforms.Normalize` 中 |
|
||||
| `Compose` | 移动到 `mmcv.transforms.Compose` 中 |
|
||||
| `ImageToTensor` | 移动到 `mmcv.transforms.ImageToTensor` 中 |
|
||||
|
||||
### `mmseg.models`
|
||||
|
||||
`models` 没有太大变化,只是从以前的 `mmseg.ops` 添加了 `encoding` 和 `wrappers`
|
||||
152
Seg_All_In_One_MMSeg/docs/zh_cn/model_zoo.md
Normal file
152
Seg_All_In_One_MMSeg/docs/zh_cn/model_zoo.md
Normal file
@@ -0,0 +1,152 @@
|
||||
# 标准与模型库
|
||||
|
||||
## 共同设定
|
||||
|
||||
- 我们默认使用 4 卡分布式训练
|
||||
- 所有 PyTorch 风格的 ImageNet 预训练网络由我们自己训练,和 [论文](https://arxiv.org/pdf/1812.01187.pdf) 保持一致。
|
||||
我们的 ResNet 网络是基于 ResNetV1c 的变种,在这里输入层的 7x7 卷积被 3个 3x3 取代
|
||||
- 为了在不同的硬件上保持一致,我们以 `torch.cuda.max_memory_allocated()` 的最大值作为 GPU 占用率,同时设置 `torch.backends.cudnn.benchmark=False`。
|
||||
注意,这通常比 `nvidia-smi` 显示的要少
|
||||
- 我们以网络 forward 和后处理的时间加和作为推理时间,除去数据加载时间。我们使用脚本 `tools/benchmark.py` 来获取推理时间,它在 `torch.backends.cudnn.benchmark=False` 的设定下,计算 200 张图片的平均推理时间
|
||||
- 在框架中,有两种推理模式
|
||||
- `slide` 模式(滑动模式):测试的配置文件字段 `test_cfg` 会是 `dict(mode='slide', crop_size=(769, 769), stride=(513, 513))`.
|
||||
在这个模式下,从原图中裁剪多个小图分别输入网络中进行推理。小图的大小和小图之间的距离由 `crop_size` 和 `stride` 决定,重合区域会进行平均
|
||||
- `whole` 模式 (全图模式):测试的配置文件字段 `test_cfg` 会是 `dict(mode='whole')`. 在这个模式下,全图会被直接输入到网络中进行推理。
|
||||
对于 769x769 下训练的模型,我们默认使用 `slide` 进行推理,其余模型用 `whole` 进行推理
|
||||
- 对于输入大小为 8x+1 (比如769),我们使用 `align_corners=True`。其余情况,对于输入大小为 8x (比如 512,1024),我们使用 `align_corners=False`
|
||||
|
||||
## 基线
|
||||
|
||||
### FCN
|
||||
|
||||
请参考 [FCN](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/fcn) 获得详细信息。
|
||||
|
||||
### PSPNet
|
||||
|
||||
请参考 [PSPNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/pspnet) 获得详细信息。
|
||||
|
||||
### DeepLabV3
|
||||
|
||||
请参考 [DeepLabV3](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/deeplabv3) 获得详细信息。
|
||||
|
||||
### PSANet
|
||||
|
||||
请参考 [PSANet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/psanet) 获得详细信息。
|
||||
|
||||
### DeepLabV3+
|
||||
|
||||
请参考 [DeepLabV3+](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/deeplabv3plus) 获得详细信息。
|
||||
|
||||
### UPerNet
|
||||
|
||||
请参考 [UPerNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/upernet) 获得详细信息。
|
||||
|
||||
### NonLocal Net
|
||||
|
||||
请参考 [NonLocal Net](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/nlnet) 获得详细信息。
|
||||
|
||||
### EncNet
|
||||
|
||||
请参考 [EncNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/encnet) 获得详细信息。
|
||||
|
||||
### CCNet
|
||||
|
||||
请参考 [CCNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/ccnet) 获得详细信息。
|
||||
|
||||
### DANet
|
||||
|
||||
请参考 [DANet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/danet) 获得详细信息。
|
||||
|
||||
### APCNet
|
||||
|
||||
请参考 [APCNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/apcnet) 获得详细信息。
|
||||
|
||||
### HRNet
|
||||
|
||||
请参考 [HRNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/hrnet) 获得详细信息。
|
||||
|
||||
### GCNet
|
||||
|
||||
请参考 [GCNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/gcnet) 获得详细信息。
|
||||
|
||||
### DMNet
|
||||
|
||||
请参考 [DMNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/dmnet) 获得详细信息。
|
||||
|
||||
### ANN
|
||||
|
||||
请参考 [ANN](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/ann) 获得详细信息。
|
||||
|
||||
### OCRNet
|
||||
|
||||
请参考 [OCRNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/ocrnet) 获得详细信息。
|
||||
|
||||
### Fast-SCNN
|
||||
|
||||
请参考 [Fast-SCNN](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/fastscnn) 获得详细信息。
|
||||
|
||||
### ResNeSt
|
||||
|
||||
请参考 [ResNeSt](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/resnest) 获得详细信息。
|
||||
|
||||
### Semantic FPN
|
||||
|
||||
请参考 [Semantic FPN](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/semfpn) 获得详细信息。
|
||||
|
||||
### PointRend
|
||||
|
||||
请参考 [PointRend](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/point_rend) 获得详细信息。
|
||||
|
||||
### MobileNetV2
|
||||
|
||||
请参考 [MobileNetV2](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/mobilenet_v2) 获得详细信息。
|
||||
|
||||
### MobileNetV3
|
||||
|
||||
请参考 [MobileNetV3](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/mobilenet_v3) 获得详细信息。
|
||||
|
||||
### EMANet
|
||||
|
||||
请参考 [EMANet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/emanet) 获得详细信息。
|
||||
|
||||
### DNLNet
|
||||
|
||||
请参考 [DNLNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/dnlnet) 获得详细信息。
|
||||
|
||||
### CGNet
|
||||
|
||||
请参考 [CGNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/cgnet) 获得详细信息。
|
||||
|
||||
### Mixed Precision (FP16) Training
|
||||
|
||||
请参考 [Mixed Precision (FP16) Training 在 BiSeNetV2 训练的样例](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/bisenetv2/bisenetv2_fcn_fp16_4x4_1024x1024_160k_cityscapes.py) 获得详细信息。
|
||||
|
||||
## 速度标定(待更新)
|
||||
|
||||
### 硬件
|
||||
|
||||
- 8 NVIDIA Tesla V100 (32G) GPUs
|
||||
- Intel(R) Xeon(R) Gold 6148 CPU @ 2.40GHz
|
||||
|
||||
### 软件环境
|
||||
|
||||
- Python 3.7
|
||||
- PyTorch 1.5
|
||||
- CUDA 10.1
|
||||
- CUDNN 7.6.03
|
||||
- NCCL 2.4.08
|
||||
|
||||
### 训练速度
|
||||
|
||||
为了公平比较,我们全部使用 ResNet-101V1c 进行标定。输入大小为 1024x512,批量样本数为 2。
|
||||
|
||||
训练速度如下表,指标为每次迭代的时间,以秒为单位,越低越快。
|
||||
|
||||
| Implementation | PSPNet (s/iter) | DeepLabV3+ (s/iter) |
|
||||
| --------------------------------------------------------------------------- | --------------- | ------------------- |
|
||||
| [MMSegmentation](https://github.com/open-mmlab/mmsegmentation) | **0.83** | **0.85** |
|
||||
| [SegmenTron](https://github.com/LikeLy-Journey/SegmenTron) | 0.84 | 0.85 |
|
||||
| [CASILVision](https://github.com/CSAILVision/semantic-segmentation-pytorch) | 1.15 | N/A |
|
||||
| [vedaseg](https://github.com/Media-Smart/vedaseg) | 0.95 | 1.25 |
|
||||
|
||||
注意:DeepLabV3+ 的输出步长为 8。
|
||||
102
Seg_All_In_One_MMSeg/docs/zh_cn/modelzoo_statistics.md
Normal file
102
Seg_All_In_One_MMSeg/docs/zh_cn/modelzoo_statistics.md
Normal file
@@ -0,0 +1,102 @@
|
||||
# 模型库统计数据
|
||||
|
||||
- 论文数量: 47
|
||||
|
||||
- ALGORITHM: 36
|
||||
- BACKBONE: 11
|
||||
|
||||
- 模型数量: 612
|
||||
|
||||
- \[ALGORITHM\] [ANN](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/ann) (16 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [APCNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/apcnet) (12 ckpts)
|
||||
|
||||
- \[BACKBONE\] [BEiT](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/beit) (2 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [BiSeNetV1](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/bisenetv1) (11 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [BiSeNetV2](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/bisenetv2) (4 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [CCNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/ccnet) (16 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [CGNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/cgnet) (2 ckpts)
|
||||
|
||||
- \[BACKBONE\] [ConvNeXt](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/convnext) (6 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [DANet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/danet) (16 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [DeepLabV3](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/deeplabv3) (41 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [DeepLabV3+](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/deeplabv3plus) (42 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [DMNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/dmnet) (12 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [DNLNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/dnlnet) (12 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [DPT](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/dpt) (1 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [EMANet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/emanet) (4 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [EncNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/encnet) (12 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [ERFNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/erfnet) (1 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [FastFCN](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/fastfcn) (12 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [Fast-SCNN](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/fastscnn) (1 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [FCN](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/fcn) (41 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [GCNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/gcnet) (16 ckpts)
|
||||
|
||||
- \[BACKBONE\] [HRNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/hrnet) (37 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [ICNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/icnet) (12 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [ISANet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/isanet) (16 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [K-Net](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/knet) (7 ckpts)
|
||||
|
||||
- \[BACKBONE\] [MAE](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/mae) (1 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [Mask2Former](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/mask2former) (13 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [MaskFormer](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/maskformer) (4 ckpts)
|
||||
|
||||
- \[BACKBONE\] [MobileNetV2](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/mobilenet_v2) (8 ckpts)
|
||||
|
||||
- \[BACKBONE\] [MobileNetV3](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/mobilenet_v3) (4 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [NonLocal Net](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/nonlocal_net) (16 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [OCRNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/ocrnet) (24 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [PointRend](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/point_rend) (4 ckpts)
|
||||
|
||||
- \[BACKBONE\] [PoolFormer](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/poolformer) (5 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [PSANet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/psanet) (16 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [PSPNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/pspnet) (54 ckpts)
|
||||
|
||||
- \[BACKBONE\] [ResNeSt](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/resnest) (8 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [SegFormer](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/segformer) (13 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [Segmenter](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/segmenter) (5 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [Semantic FPN](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/sem_fpn) (4 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [SETR](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/setr) (7 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [STDC](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/stdc) (4 ckpts)
|
||||
|
||||
- \[BACKBONE\] [Swin Transformer](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/swin) (6 ckpts)
|
||||
|
||||
- \[BACKBONE\] [Twins](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/twins) (12 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [UNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/unet) (25 ckpts)
|
||||
|
||||
- \[ALGORITHM\] [UPerNet](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/upernet) (16 ckpts)
|
||||
|
||||
- \[BACKBONE\] [Vision Transformer](https://github.com/open-mmlab/mmsegmentation/blob/master/configs/vit) (11 ckpts)
|
||||
125
Seg_All_In_One_MMSeg/docs/zh_cn/notes/faq.md
Normal file
125
Seg_All_In_One_MMSeg/docs/zh_cn/notes/faq.md
Normal file
@@ -0,0 +1,125 @@
|
||||
# 常见问题解答(FAQ)
|
||||
|
||||
我们在这里列出了使用时的一些常见问题及其相应的解决方案。 如果您发现有一些问题被遗漏,请随时提 PR 丰富这个列表。 如果您无法在此获得帮助,请使用 [issue 模板](https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/.github/ISSUE_TEMPLATE/error-report.md/)创建问题,但是请在模板中填写所有必填信息,这有助于我们更快定位问题。
|
||||
|
||||
## 安装
|
||||
|
||||
兼容的 MMSegmentation 和 MMCV 版本如下。请安装正确版本的 MMCV 以避免安装问题。
|
||||
|
||||
| MMSegmentation version | MMCV version | MMEngine version | MMClassification (optional) version | MMDetection (optional) version |
|
||||
| :--------------------: | :----------------------------: | :---------------: | :---------------------------------: | :----------------------------: |
|
||||
| dev-1.x branch | mmcv >= 2.0.0 | MMEngine >= 0.7.4 | mmpretrain>=1.0.0rc7 | mmdet >= 3.0.0 |
|
||||
| main branch | mmcv >= 2.0.0 | MMEngine >= 0.7.4 | mmpretrain>=1.0.0rc7 | mmdet >= 3.0.0 |
|
||||
| 1.2.2 | mmcv >= 2.0.0 | MMEngine >= 0.7.4 | mmpretrain>=1.0.0rc7 | mmdet >= 3.0.0 |
|
||||
| 1.2.1 | mmcv >= 2.0.0 | MMEngine >= 0.7.4 | mmpretrain>=1.0.0rc7 | mmdet >= 3.0.0 |
|
||||
| 1.2.0 | mmcv >= 2.0.0 | MMEngine >= 0.7.4 | mmpretrain>=1.0.0rc7 | mmdet >= 3.0.0 |
|
||||
| 1.1.2 | mmcv >= 2.0.0 | MMEngine >= 0.7.4 | mmpretrain>=1.0.0rc7 | mmdet >= 3.0.0 |
|
||||
| 1.1.1 | mmcv >= 2.0.0 | MMEngine >= 0.7.4 | mmpretrain>=1.0.0rc7 | mmdet >= 3.0.0 |
|
||||
| 1.1.0 | mmcv >= 2.0.0 | MMEngine >= 0.7.4 | mmpretrain>=1.0.0rc7 | mmdet >= 3.0.0 |
|
||||
| 1.0.0 | mmcv >= 2.0.0rc4 | MMEngine >= 0.7.1 | mmcls==1.0.0rc6 | mmdet >= 3.0.0 |
|
||||
| 1.0.0rc6 | mmcv >= 2.0.0rc4 | MMEngine >= 0.5.0 | mmcls>=1.0.0rc0 | mmdet >= 3.0.0rc6 |
|
||||
| 1.0.0rc5 | mmcv >= 2.0.0rc4 | MMEngine >= 0.2.0 | mmcls>=1.0.0rc0 | mmdet>=3.0.0rc6 |
|
||||
| 1.0.0rc4 | mmcv == 2.0.0rc3 | MMEngine >= 0.1.0 | mmcls>=1.0.0rc0 | mmdet>=3.0.0rc4, \<=3.0.0rc5 |
|
||||
| 1.0.0rc3 | mmcv == 2.0.0rc3 | MMEngine >= 0.1.0 | mmcls>=1.0.0rc0 | mmdet>=3.0.0rc4, \<=3.0.0rc5 |
|
||||
| 1.0.0rc2 | mmcv == 2.0.0rc3 | MMEngine >= 0.1.0 | mmcls>=1.0.0rc0 | mmdet>=3.0.0rc4, \<=3.0.0rc5 |
|
||||
| 1.0.0rc1 | mmcv >= 2.0.0rc1, \<=2.0.0rc3> | MMEngine >= 0.1.0 | mmcls>=1.0.0rc0 | Not required |
|
||||
| 1.0.0rc0 | mmcv >= 2.0.0rc1, \<=2.0.0rc3> | MMEngine >= 0.1.0 | mmcls>=1.0.0rc0 | Not required |
|
||||
|
||||
如果您已经安装了版本不合适的 mmcv,请先运行`pip uninstall mmcv`卸载已安装的 mmcv,如您先前安装的为 mmcv-full(存在于 OpenMMLab 1.x),请运行`pip uninstall mmcv-full`进行卸载。
|
||||
|
||||
- 如出现 "No module named 'mmcv'"
|
||||
1. 使用`pip uninstall mmcv`卸载环境中现有的 mmcv
|
||||
2. 按照[安装说明](../get_started.md)安装对应的 mmcv
|
||||
|
||||
## 如何获知模型训练时需要的显卡数量
|
||||
|
||||
- 看模型的 config 文件命名。可以参考[了解配置文件](../user_guides/1_config.md)中的`配置文件命名风格`部分。比如,对于名字为`segformer_mit-b0_8xb1-160k_cityscapes-1024x1024.py`的 config 文件,`8xb1`代表训练其对应的模型需要的卡数为 8,每张卡中的 batch size 为 1。
|
||||
- 看模型的 log 文件。点开该模型的 log 文件,并在其中搜索`nGPU`,在`nGPU`后的数字个数即训练时所需的卡数。比如,在 log 文件中搜索`nGPU`得到`nGPU 0,1,2,3,4,5,6,7`的记录,则说明训练该模型需要使用八张卡。
|
||||
|
||||
## auxiliary head 是什么
|
||||
|
||||
简单来说,这是一个提高准确率的深度监督技术。在训练阶段,`decode_head`用于输出语义分割的结果,`auxiliary_head` 只是增加了一个辅助损失,其产生的分割结果对你的模型结果没有影响,仅在在训练中起作用。您可以阅读这篇[论文](https://arxiv.org/pdf/1612.01105.pdf)了解更多信息。
|
||||
|
||||
## 运行测试脚本时如何输出绘制分割掩膜的图像
|
||||
|
||||
在测试脚本中,我们提供了`--out`参数来控制是否输出保存预测的分割掩膜图像。您可以运行以下命令输出测试结果:
|
||||
|
||||
```shell
|
||||
python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} --out ${OUTPUT_DIR}
|
||||
```
|
||||
|
||||
更多用例细节可查阅[文档](https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/docs/zh_cn/user_guides/4_train_test.md#%E6%B5%8B%E8%AF%95%E5%B9%B6%E4%BF%9D%E5%AD%98%E5%88%86%E5%89%B2%E7%BB%93%E6%9E%9C),[PR #2712](https://github.com/open-mmlab/mmsegmentation/pull/2712) 以及[迁移文档](https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/docs/zh_cn/migration/interface.md#%E6%B5%8B%E8%AF%95%E5%90%AF%E5%8A%A8)了解相关说明。
|
||||
|
||||
## 如何处理二值分割任务?
|
||||
|
||||
MMSegmentation 使用 `num_classes` 和 `out_channels` 来控制模型最后一层 `self.conv_seg` 的输出。更多细节可以参考 [这里](https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/mmseg/models/decode_heads/decode_head.py)。
|
||||
|
||||
`num_classes` 应该和数据集本身类别个数一致,当是二值分割时,数据集只有前景和背景两类,所以 `num_classes` 为 2. `out_channels` 控制模型最后一层的输出的通道数,通常和 `num_classes` 相等,但当二值分割时候,可以有两种处理方法, 分别是:
|
||||
|
||||
- 设置 `out_channels=2`,在训练时以 Cross Entropy Loss 作为损失函数,在推理时使用 `F.softmax()` 归一化 logits 值,然后通过 `argmax()` 得到每个像素的预测结果。
|
||||
|
||||
- 设置 `out_channels=1`,在训练时以 Binary Cross Entropy Loss 作为损失函数,在推理时使用 `F.sigmoid()` 和 `threshold` 得到预测结果,`threshold` 默认为 0.3。
|
||||
|
||||
对于实现上述两种计算二值分割的方法,需要在 `decode_head` 和 `auxiliary_head` 的配置里修改。下面是对样例 [pspnet_unet_s5-d16.py](https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/configs/_base_/models/pspnet_unet_s5-d16.py) 做出的对应修改。
|
||||
|
||||
- (1) `num_classes=2`, `out_channels=2` 并在 `CrossEntropyLoss` 里面设置 `use_sigmoid=False`。
|
||||
|
||||
```python
|
||||
decode_head=dict(
|
||||
type='PSPHead',
|
||||
in_channels=64,
|
||||
in_index=4,
|
||||
num_classes=2,
|
||||
out_channels=2,
|
||||
loss_decode=dict(
|
||||
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
|
||||
auxiliary_head=dict(
|
||||
type='FCNHead',
|
||||
in_channels=128,
|
||||
in_index=3,
|
||||
num_classes=2,
|
||||
out_channels=2,
|
||||
loss_decode=dict(
|
||||
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)),
|
||||
```
|
||||
|
||||
- (2) `num_classes=2`, `out_channels=1` 并在 `CrossEntropyLoss` 里面设置 `use_sigmoid=True`.
|
||||
|
||||
```python
|
||||
decode_head=dict(
|
||||
type='PSPHead',
|
||||
in_channels=64,
|
||||
in_index=4,
|
||||
num_classes=2,
|
||||
out_channels=1,
|
||||
loss_decode=dict(
|
||||
type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0)),
|
||||
auxiliary_head=dict(
|
||||
type='FCNHead',
|
||||
in_channels=128,
|
||||
in_index=3,
|
||||
num_classes=2,
|
||||
out_channels=1,
|
||||
loss_decode=dict(
|
||||
type='CrossEntropyLoss', use_sigmoid=True, loss_weight=0.4)),
|
||||
```
|
||||
|
||||
## `reduce_zero_label` 的作用
|
||||
|
||||
数据集中 `reduce_zero_label` 参数类型为布尔类型,默认为 False,它的功能是为了忽略数据集 label 0。具体做法是将 label 0 改为 255,其余 label 相应编号减 1,同时 decode head 里将 255 设为 ignore index,即不参与 loss 计算。
|
||||
以下是 `reduce_zero_label` 具体实现逻辑:
|
||||
|
||||
```python
|
||||
if self.reduce_zero_label:
|
||||
# avoid using underflow conversion
|
||||
gt_semantic_seg[gt_semantic_seg == 0] = 255
|
||||
gt_semantic_seg = gt_semantic_seg - 1
|
||||
gt_semantic_seg[gt_semantic_seg == 254] = 255
|
||||
```
|
||||
|
||||
关于您的数据集是否需要使用 reduce_zero_label,有以下两类情况:
|
||||
|
||||
- 例如在 [Potsdam](https://github.com/open-mmlab/mmsegmentation/blob/1.x/docs/en/user_guides/2_dataset_prepare.md#isprs-potsdam) 数据集上,有 0-不透水面、1-建筑、2-低矮植被、3-树、4-汽车、5-杂乱,六类。但该数据集提供了两种 RGB 标签,一种为图像边缘处有黑色像素的标签,另一种是没有黑色边缘的标签。对于有黑色边缘的标签,在 [dataset_converters.py](https://github.com/open-mmlab/mmsegmentation/blob/dev-1.x/tools/dataset_converters/potsdam.py)中,其将黑色边缘转换为 label 0,其余标签分别为 1-不透水面、2-建筑、3-低矮植被、4-树、5-汽车、6-杂乱,那么此时,就应该在数据集 [potsdam.py](https://github.com/open-mmlab/mmsegmentation/blob/ff95416c3b5ce8d62b9289f743531398efce534f/mmseg/datasets/potsdam.py#L23) 中将`reduce_zero_label=True`。如果使用的是没有黑色边缘的标签,那么 mask label 中只有 0-5,此时就应该使`reduce_zero_label=False`。需要结合您的实际情况来使用。
|
||||
- 例如在第 0 类为 background 类别的数据集上,如果您最终是需要将背景和您的其余类别分开时,是不需要使用`reduce_zero_label`的,此时在数据集中应该将其设置为`reduce_zero_label=False`
|
||||
|
||||
**注意:** 使用 `reduce_zero_label` 请确认数据集原始类别个数,如果只有两类,需要关闭 `reduce_zero_label` 即设置 `reduce_zero_label=False`。
|
||||
75
Seg_All_In_One_MMSeg/docs/zh_cn/overview.md
Normal file
75
Seg_All_In_One_MMSeg/docs/zh_cn/overview.md
Normal file
@@ -0,0 +1,75 @@
|
||||
# 概述
|
||||
|
||||
本章节向您介绍 MMSegmentation 框架以及语义分割相关的基本概念。我们还提供了关于 MMSegmentation 的详细教程链接。
|
||||
|
||||
## 什么是语义分割?
|
||||
|
||||
语义分割是将图像中属于同一目标类别的部分聚类在一起的任务。它也是一种像素级预测任务,因为图像中的每一个像素都将根据类别进行分类。该任务的一些示例基准有 [Cityscapes](https://www.cityscapes-dataset.com/benchmarks/), [PASCAL VOC](http://host.robots.ox.ac.uk/pascal/VOC/voc2012/) 和 [ADE20K](https://groups.csail.mit.edu/vision/datasets/ADE20K/) 。通常用平均交并比 (Mean IoU) 和像素准确率 (Pixel Accuracy) 这两个指标来评估模型。
|
||||
|
||||
## 什么是 MMSegmentation?
|
||||
|
||||
MMSegmentation 是一个工具箱,它为语义分割任务的统一实现和模型评估提供了一个框架,并且高质量实现了常用的语义分割方法和数据集。
|
||||
|
||||
MMSeg 主要包含了 apis, structures, datasets, models, engine, evaluation 和 visualization 这七个主要部分。
|
||||
|
||||
- **apis** 提供了模型推理的高级api
|
||||
|
||||
- **structures** 提供了分割任务的数据结构 `SegDataSample`
|
||||
|
||||
- **datasets** 支持用于语义分割的多种数据集
|
||||
|
||||
- **transforms** 包含多种数据增强变换
|
||||
|
||||
- **models** 是分割器最重要的部分,包含了分割器的不同组件
|
||||
|
||||
- **segmentors** 定义了所有分割模型类
|
||||
- **data_preprocessors** 用于预处理模型的输入数据
|
||||
- **backbones** 包含各种骨干网络,可将图像映射为特征图
|
||||
- **necks** 包含各种模型颈部组件,用于连接分割头和骨干网络
|
||||
- **decode_heads** 包含各种分割头,将特征图作为输入,并预测分割结果
|
||||
- **losses** 包含各种损失函数
|
||||
|
||||
- **engine** 是运行时组件的一部分,扩展了 [MMEngine](https://github.com/open-mmlab/mmengine) 的功能
|
||||
|
||||
- **optimizers** 提供了优化器和优化器封装
|
||||
- **hooks** 提供了 runner 的各种钩子
|
||||
|
||||
- **evaluation** 提供了评估模型性能的不同指标
|
||||
|
||||
- **visualization** 分割结果的可视化工具
|
||||
|
||||
## 如何使用本指南?
|
||||
|
||||
以下是详细步骤,将带您一步步学习如何使用 MMSegmentation :
|
||||
|
||||
1. 有关安装说明,请参阅 [开始你的第一步](get_started.md)。
|
||||
|
||||
2. 对于初学者来说,MMSegmentation 是开始语义分割之旅的最好选择,因为这里实现了许多 SOTA 模型以及经典的模型 [model](model_zoo.md) 。另外,将各类组件和高级 API 結合使用,可以更便捷的执行分割任务。关于 MMSegmentation 的基本用法,请参考下面的教程:
|
||||
|
||||
- [配置](user_guides/1_config.md)
|
||||
- [数据预处理](user_guides/2_dataset_prepare.md)
|
||||
- [推理](user_guides/3_inference.md)
|
||||
- [训练和测试](user_guides/4_train_test.md)
|
||||
|
||||
3. 如果你想了解 MMSegmentation 工作的基本类和功能,请参考下面的教程来深入研究:
|
||||
|
||||
- [数据流](advanced_guides/data_flow.md)
|
||||
- [结构](advanced_guides/structures.md)
|
||||
- [模型](advanced_guides/models.md)
|
||||
- [数据集](advanced_guides/datasets.md)
|
||||
- [评估](advanced_guides/evaluation.md)
|
||||
|
||||
4. MMSegmentation 也为用户自定义和一些前沿的研究提供了教程,请参考下面的教程来建立你自己的分割项目:
|
||||
|
||||
- [添加新的模型](advanced_guides/add_models.md)
|
||||
- [添加新的数据集](advanced_guides/add_datasets.md)
|
||||
- [添加新的 transform](advanced_guides/add_transforms.md)
|
||||
- [自定义 runtime](advanced_guides/customize_runtime.md)
|
||||
|
||||
5. 如果您更熟悉 MMSegmentation v0.x , 以下是 MMSegmentation v0.x 迁移到 v1.x 的文档
|
||||
|
||||
- [迁移](migration/index.rst)
|
||||
|
||||
## 参考来源
|
||||
|
||||
- https://paperswithcode.com/task/semantic-segmentation/codeless#task-home
|
||||
67
Seg_All_In_One_MMSeg/docs/zh_cn/stat.py
Normal file
67
Seg_All_In_One_MMSeg/docs/zh_cn/stat.py
Normal file
@@ -0,0 +1,67 @@
|
||||
#!/usr/bin/env python
|
||||
# Copyright (c) OpenMMLab. All rights reserved.
|
||||
import functools as func
|
||||
import glob
|
||||
import os.path as osp
|
||||
import re
|
||||
|
||||
import numpy as np
|
||||
|
||||
url_prefix = 'https://github.com/open-mmlab/mmsegmentation/blob/master/'
|
||||
|
||||
files = sorted(glob.glob('../../configs/*/README.md'))
|
||||
|
||||
stats = []
|
||||
titles = []
|
||||
num_ckpts = 0
|
||||
|
||||
for f in files:
|
||||
url = osp.dirname(f.replace('../../', url_prefix))
|
||||
|
||||
with open(f) as content_file:
|
||||
content = content_file.read()
|
||||
|
||||
title = content.split('\n')[0].replace('#', '').strip()
|
||||
ckpts = {
|
||||
x.lower().strip()
|
||||
for x in re.findall(r'https?://download.*\.pth', content)
|
||||
if 'mmsegmentation' in x
|
||||
}
|
||||
if len(ckpts) == 0:
|
||||
continue
|
||||
|
||||
_papertype = [
|
||||
x for x in re.findall(r'<!--\s*\[([A-Z]*?)\]\s*-->', content)
|
||||
]
|
||||
assert len(_papertype) > 0
|
||||
papertype = _papertype[0]
|
||||
|
||||
paper = {(papertype, title)}
|
||||
|
||||
titles.append(title)
|
||||
num_ckpts += len(ckpts)
|
||||
statsmsg = f"""
|
||||
\t* [{papertype}] [{title}]({url}) ({len(ckpts)} ckpts)
|
||||
"""
|
||||
stats.append((paper, ckpts, statsmsg))
|
||||
|
||||
allpapers = func.reduce(lambda a, b: a.union(b), [p for p, _, _ in stats])
|
||||
msglist = '\n'.join(x for _, _, x in stats)
|
||||
|
||||
papertypes, papercounts = np.unique([t for t, _ in allpapers],
|
||||
return_counts=True)
|
||||
countstr = '\n'.join(
|
||||
[f' - {t}: {c}' for t, c in zip(papertypes, papercounts)])
|
||||
|
||||
modelzoo = f"""
|
||||
# 模型库统计数据
|
||||
|
||||
* 论文数量: {len(set(titles))}
|
||||
{countstr}
|
||||
|
||||
* 模型数量: {num_ckpts}
|
||||
{msglist}
|
||||
"""
|
||||
|
||||
with open('modelzoo_statistics.md', 'w') as f:
|
||||
f.write(modelzoo)
|
||||
3
Seg_All_In_One_MMSeg/docs/zh_cn/switch_language.md
Normal file
3
Seg_All_In_One_MMSeg/docs/zh_cn/switch_language.md
Normal file
@@ -0,0 +1,3 @@
|
||||
## <a href='https://mmsegmentation.readthedocs.io/en/latest/'>English</a>
|
||||
|
||||
## <a href='https://mmsegmentation.readthedocs.io/zh_CN/latest/'>简体中文</a>
|
||||
577
Seg_All_In_One_MMSeg/docs/zh_cn/user_guides/1_config.md
Normal file
577
Seg_All_In_One_MMSeg/docs/zh_cn/user_guides/1_config.md
Normal file
@@ -0,0 +1,577 @@
|
||||
# 教程1:了解配置文件
|
||||
|
||||
我们将模块化和继承性设计融入到我们的配置文件系统中,方便进行各种实验。如果您想查看配置文件,你可以运行 `python tools/misc/print_config.py /PATH/TO/CONFIG` 来查看完整的配置文件。你也可以通过传递参数 `--cfg-options xxx.yyy=zzz` 来查看更新的配置信息。
|
||||
|
||||
## 配置文件的结构
|
||||
|
||||
在 `config/_base_ ` 文件夹下面有4种基本组件类型: 数据集(dataset),模型(model),训练策略(schedule)和运行时的默认设置(default runtime)。许多模型都可以很容易地通过组合这些组件进行实现,比如 DeepLabV3,PSPNet。使用 `_base_` 下的组件构建的配置信息叫做原始配置 (primitive)。
|
||||
|
||||
对于同一个文件夹下的所有配置文件,建议**只有一个**对应的**原始配置文件**。所有其他的配置文件都应该继承自这个原始配置文件,从而保证每个配置文件的最大继承深度为 3。
|
||||
|
||||
为了便于理解,我们建议社区贡献者从现有的方法继承。例如,如果您在 DeepLabV3 基础上进行了一些修改,用户可以先通过指定 `_base_ = ../deeplabv3/deeplabv3_r50-d8_4xb2-40k_cityscapes-512x1024.py` 继承基本的 DeepLabV3 结构,然后在配置文件中修改必要的字段。
|
||||
|
||||
如果你正在构建一个全新的方法,它不与现有的任何方法共享基本组件,您可以在`config`下创建一个新的文件夹`xxxnet` ,详细文档请参考[mmengine](https://mmengine.readthedocs.io/en/latest/tutorials/config.html)。
|
||||
|
||||
## 配置文件命名风格
|
||||
|
||||
我们遵循以下格式来命名配置文件,建议社区贡献者遵循相同的风格。
|
||||
|
||||
```text
|
||||
{algorithm name}_{model component names [component1]_[component2]_[...]}_{training settings}_{training dataset information}_{testing dataset information}
|
||||
```
|
||||
|
||||
配置文件的文件名分为五个部分,组成文件名每一个部分和组件之间都用`_`连接,每个部分或组件中的每个单词都要用`-`连接。
|
||||
|
||||
- `{algorithm name}`: 算法的名称,如 `deeplabv3`, `pspnet` 等。
|
||||
- `{model component names}`: 算法中使用的组件名称,如主干(backbone)、解码头(head)等。例如,`r50-d8 `表示使用ResNet50主干网络,并使用主干网络的8倍下采样输出作为下一级的输入。
|
||||
- `{training settings}`: 训练时的参数设置,如 `batch size`、数据增强(augmentation)、损失函数(loss)、学习率调度器(learning rate scheduler)和训练轮数(epochs/iterations)。例如: `4xb4-ce-linearlr-40K` 意味着使用4个gpu,每个gpu4个图像,使用交叉熵损失函数(CrossEntropy),线性学习率调度程序,训练40K iterations。
|
||||
一些缩写:
|
||||
- `{gpu x batch_per_gpu}`: GPU数量和每个GPU的样本数。`bN ` 表示每个GPU的batch size为N,如 `8xb2` 为8个gpu x 每个gpu2张图像的缩写。如果未提及,则默认使用 `4xb4 `。
|
||||
- `{schedule}`: 训练计划,选项有`20k`,`40k`等。`20k ` 和 `40k` 分别表示20000次迭代(iterations)和40000次迭代(iterations)。
|
||||
- `{training dataset information}`: 训练数据集名称,如 `cityscapes `, `ade20k ` 等,以及输入分辨率。例如: `cityscapes-768x768 `表示使用 `cityscapes` 数据集进行训练,输入分辨率为`768x768 `。
|
||||
- `{testing dataset information}` (可选): 测试数据集名称。当您的模型在一个数据集上训练但在另一个数据集上测试时,请将测试数据集名称添加到此处。如果没有这一部分,则意味着模型是在同一个数据集上进行训练和测试的。
|
||||
|
||||
## PSPNet 的一个例子
|
||||
|
||||
为了帮助用户熟悉对这个现代语义分割系统的完整配置文件和模块,我们对使用ResNet50V1c作为主干网络的PSPNet的配置文件作如下的简要注释和说明。要了解更详细的用法和每个模块对应的替换方法,请参阅API文档。
|
||||
|
||||
```python
|
||||
_base_ = [
|
||||
'../_base_/models/pspnet_r50-d8.py', '../_base_/datasets/cityscapes.py',
|
||||
'../_base_/default_runtime.py', '../_base_/schedules/schedule_40k.py'
|
||||
] # 我们可以在基本配置文件的基础上 构建新的配置文件
|
||||
crop_size = (512, 1024)
|
||||
data_preprocessor = dict(size=crop_size)
|
||||
model = dict(data_preprocessor=data_preprocessor)
|
||||
```
|
||||
|
||||
`_base_/models/pspnet_r50-d8.py`是使用ResNet50V1c作为主干网络的PSPNet的基本模型配置文件。
|
||||
|
||||
```python
|
||||
# 模型设置
|
||||
norm_cfg = dict(type='SyncBN', requires_grad=True) # 分割框架通常使用 SyncBN
|
||||
data_preprocessor = dict( # 数据预处理的配置项,通常包括图像的归一化和增强
|
||||
type='SegDataPreProcessor', # 数据预处理的类型
|
||||
mean=[123.675, 116.28, 103.53], # 用于归一化输入图像的平均值
|
||||
std=[58.395, 57.12, 57.375], # 用于归一化输入图像的标准差
|
||||
bgr_to_rgb=True, # 是否将图像从 BGR 转为 RGB
|
||||
pad_val=0, # 图像的填充值
|
||||
seg_pad_val=255) # 'gt_seg_map'的填充值
|
||||
model = dict(
|
||||
type='EncoderDecoder', # 分割器(segmentor)的名字
|
||||
data_preprocessor=data_preprocessor,
|
||||
pretrained='open-mmlab://resnet50_v1c', # 加载使用 ImageNet 预训练的主干网络
|
||||
backbone=dict(
|
||||
type='ResNetV1c', # 主干网络的类别,更多细节请参考 mmseg/models/backbones/resnet.py
|
||||
depth=50, # 主干网络的深度,通常为 50 和 101
|
||||
num_stages=4, # 主干网络状态(stages)的数目
|
||||
out_indices=(0, 1, 2, 3), # 每个状态(stage)产生的特征图输出的索引
|
||||
dilations=(1, 1, 2, 4), # 每一层(layer)的空心率(dilation rate)
|
||||
strides=(1, 2, 1, 1), # 每一层(layer)的步长(stride)
|
||||
norm_cfg=norm_cfg, # 归一化层(norm layer)的配置项
|
||||
norm_eval=False, # 是否冻结 BN 里的统计项
|
||||
style='pytorch', # 主干网络的风格,'pytorch' 意思是步长为2的层为 3x3 卷积, 'caffe' 意思是步长为2的层为 1x1 卷积
|
||||
contract_dilation=True), # 当空洞率 > 1, 是否压缩第一个空洞层
|
||||
decode_head=dict(
|
||||
type='PSPHead', # 解码头(decode head)的类别。可用选项请参 mmseg/models/decode_heads
|
||||
in_channels=2048, # 解码头的输入通道数
|
||||
in_index=3, # 被选择特征图(feature map)的索引
|
||||
channels=512, # 解码头中间态(intermediate)的通道数
|
||||
pool_scales=(1, 2, 3, 6), # PSPHead 平均池化(avg pooling)的规模(scales)。 细节请参考文章内容
|
||||
dropout_ratio=0.1, # 进入最后分类层(classification layer)之前的 dropout 比例
|
||||
num_classes=19, # 分割前景的种类数目。 通常情况下,cityscapes 为19,VOC为21,ADE20k 为150
|
||||
norm_cfg=norm_cfg, # 归一化层的配置项
|
||||
align_corners=False, # 解码过程中调整大小(resize)的 align_corners 参数
|
||||
loss_decode=dict( # 解码头(decode_head)里的损失函数的配置项
|
||||
type='CrossEntropyLoss', # 分割时使用的损失函数的类别
|
||||
use_sigmoid=False, # 分割时是否使用 sigmoid 激活
|
||||
loss_weight=1.0)), # 解码头的损失权重
|
||||
auxiliary_head=dict(
|
||||
type='FCNHead', # 辅助头(auxiliary head)的种类。可用选项请参考 mmseg/models/decode_heads
|
||||
in_channels=1024, # 辅助头的输入通道数
|
||||
in_index=2, # 被选择的特征图(feature map)的索引
|
||||
channels=256, # 辅助头中间态(intermediate)的通道数
|
||||
num_convs=1, # FCNHead 里卷积(convs)的数目,辅助头中通常为1
|
||||
concat_input=False, # 在分类层(classification layer)之前是否连接(concat)输入和卷积的输出
|
||||
dropout_ratio=0.1, # 进入最后分类层(classification layer)之前的 dropout 比例
|
||||
num_classes=19, # 分割前景的种类数目。 通常情况下,cityscapes 为19,VOC为21,ADE20k 为150
|
||||
norm_cfg=norm_cfg, # 归一化层的配置项
|
||||
align_corners=False, # 解码过程中调整大小(resize)的 align_corners 参数
|
||||
loss_decode=dict( # 辅助头(auxiliary head)里的损失函数的配置项
|
||||
type='CrossEntropyLoss', # 分割时使用的损失函数的类别
|
||||
use_sigmoid=False, # 分割时是否使用 sigmoid 激活
|
||||
loss_weight=0.4)), # 辅助头损失的权重,默认设置为0.4
|
||||
# 模型训练和测试设置项
|
||||
train_cfg=dict(), # train_cfg 当前仅是一个占位符
|
||||
test_cfg=dict(mode='whole')) # 测试模式,可选参数为 'whole' 和 'slide'. 'whole': 在整张图像上全卷积(fully-convolutional)测试。 'slide': 在输入图像上做滑窗预测
|
||||
```
|
||||
|
||||
`_base_/datasets/cityscapes.py`是数据集的基本配置文件。
|
||||
|
||||
```python
|
||||
# 数据集设置
|
||||
dataset_type = 'CityscapesDataset' # 数据集类型,这将被用来定义数据集
|
||||
data_root = 'data/cityscapes/' # 数据的根路径
|
||||
crop_size = (512, 1024) # 训练时的裁剪大小
|
||||
train_pipeline = [ # 训练流程
|
||||
dict(type='LoadImageFromFile'), # 第1个流程,从文件路径里加载图像
|
||||
dict(type='LoadAnnotations'), # 第2个流程,对于当前图像,加载它的标注图像
|
||||
dict(type='RandomResize', # 调整输入图像大小(resize)和其标注图像的数据增广流程
|
||||
scale=(2048, 1024), # 图像裁剪的大小
|
||||
ratio_range=(0.5, 2.0), # 数据增广的比例范围
|
||||
keep_ratio=True), # 调整图像大小时是否保持纵横比
|
||||
dict(type='RandomCrop', # 随机裁剪当前图像和其标注图像的数据增广流程
|
||||
crop_size=crop_size, # 随机裁剪的大小
|
||||
cat_max_ratio=0.75), # 单个类别可以填充的最大区域的比
|
||||
dict(type='RandomFlip', # 翻转图像和其标注图像的数据增广流程
|
||||
prob=0.5), # 翻转图像的概率
|
||||
dict(type='PhotoMetricDistortion'), # 光学上使用一些方法扭曲当前图像和其标注图像的数据增广流程
|
||||
dict(type='PackSegInputs') # 打包用于语义分割的输入数据
|
||||
]
|
||||
test_pipeline = [
|
||||
dict(type='LoadImageFromFile'), # 第1个流程,从文件路径里加载图像
|
||||
dict(type='Resize', # 使用调整图像大小(resize)增强
|
||||
scale=(2048, 1024), # 图像缩放的大小
|
||||
keep_ratio=True), # 在调整图像大小时是否保留长宽比
|
||||
# 在' Resize '之后添加标注图像
|
||||
# 不需要做调整图像大小(resize)的数据变换
|
||||
dict(type='LoadAnnotations'), # 加载数据集提供的语义分割标注
|
||||
dict(type='PackSegInputs') # 打包用于语义分割的输入数据
|
||||
]
|
||||
train_dataloader = dict( # 训练数据加载器(dataloader)的配置
|
||||
batch_size=2, # 每一个GPU的batch size大小
|
||||
num_workers=2, # 为每一个GPU预读取数据的进程个数
|
||||
persistent_workers=True, # 在一个epoch结束后关闭worker进程,可以加快训练速度
|
||||
sampler=dict(type='InfiniteSampler', shuffle=True), # 训练时进行随机洗牌(shuffle)
|
||||
dataset=dict( # 训练数据集配置
|
||||
type=dataset_type, # 数据集类型,详见mmseg/datassets/
|
||||
data_root=data_root, # 数据集的根目录
|
||||
data_prefix=dict(
|
||||
img_path='leftImg8bit/train', seg_map_path='gtFine/train'), # 训练数据的前缀
|
||||
pipeline=train_pipeline)) # 数据处理流程,它通过之前创建的train_pipeline传递。
|
||||
val_dataloader = dict(
|
||||
batch_size=1, # 每一个GPU的batch size大小
|
||||
num_workers=4, # 为每一个GPU预读取数据的进程个数
|
||||
persistent_workers=True, # 在一个epoch结束后关闭worker进程,可以加快训练速度
|
||||
sampler=dict(type='DefaultSampler', shuffle=False), # 训练时不进行随机洗牌(shuffle)
|
||||
dataset=dict( # 测试数据集配置
|
||||
type=dataset_type, # 数据集类型,详见mmseg/datassets/
|
||||
data_root=data_root, # 数据集的根目录
|
||||
data_prefix=dict(
|
||||
img_path='leftImg8bit/val', seg_map_path='gtFine/val'), # 测试数据的前缀
|
||||
pipeline=test_pipeline)) # 数据处理流程,它通过之前创建的test_pipeline传递。
|
||||
test_dataloader = val_dataloader
|
||||
# 精度评估方法,我们在这里使用 IoUMetric 进行评估
|
||||
val_evaluator = dict(type='IoUMetric', iou_metrics=['mIoU'])
|
||||
test_evaluator = val_evaluator
|
||||
```
|
||||
|
||||
`_base_/schedules/schedule_40k.py`
|
||||
|
||||
```python
|
||||
# optimizer
|
||||
optimizer = dict(type='SGD', # 优化器种类,更多细节可参考 https://github.com/open-mmlab/mmengine/blob/main/mmengine/optim/optimizer/default_constructor.py
|
||||
lr=0.01, # 优化器的学习率,参数的使用细节请参照对应的 PyTorch 文档
|
||||
momentum=0.9, # 动量大小 (Momentum)
|
||||
weight_decay=0.0005) # SGD 的权重衰减 (weight decay)
|
||||
optim_wrapper = dict(type='OptimWrapper', # 优化器包装器(Optimizer wrapper)为更新参数提供了一个公共接口
|
||||
optimizer=optimizer, # 用于更新模型参数的优化器(Optimizer)
|
||||
clip_grad=None) # 如果 'clip_grad' 不是None,它将是 ' torch.nn.utils.clip_grad' 的参数。
|
||||
# 学习策略
|
||||
param_scheduler = [
|
||||
dict(
|
||||
type='PolyLR', # 调度流程的策略,同样支持 Step, CosineAnnealing, Cyclic 等. 请从 https://github.com/open-mmlab/mmengine/blob/main/mmengine/optim/scheduler/lr_scheduler.py 参考 LrUpdater 的细节
|
||||
eta_min=1e-4, # 训练结束时的最小学习率
|
||||
power=0.9, # 多项式衰减 (polynomial decay) 的幂
|
||||
begin=0, # 开始更新参数的时间步(step)
|
||||
end=40000, # 停止更新参数的时间步(step)
|
||||
by_epoch=False) # 是否按照 epoch 计算训练时间
|
||||
]
|
||||
# 40k iteration 的训练计划
|
||||
train_cfg = dict(type='IterBasedTrainLoop', max_iters=40000, val_interval=4000)
|
||||
val_cfg = dict(type='ValLoop')
|
||||
test_cfg = dict(type='TestLoop')
|
||||
# 默认钩子(hook)配置
|
||||
default_hooks = dict(
|
||||
timer=dict(type='IterTimerHook'), # 记录迭代过程中花费的时间
|
||||
logger=dict(type='LoggerHook', interval=50, log_metric_by_epoch=False), # 从'Runner'的不同组件收集和写入日志
|
||||
param_scheduler=dict(type='ParamSchedulerHook'), # 更新优化器中的一些超参数,例如学习率
|
||||
checkpoint=dict(type='CheckpointHook', by_epoch=False, interval=4000), # 定期保存检查点(checkpoint)
|
||||
sampler_seed=dict(type='DistSamplerSeedHook')) # 用于分布式训练的数据加载采样器
|
||||
```
|
||||
|
||||
in `_base_/default_runtime.py`
|
||||
|
||||
```python
|
||||
# 将注册表的默认范围设置为mmseg
|
||||
default_scope = 'mmseg'
|
||||
# environment
|
||||
env_cfg = dict(
|
||||
cudnn_benchmark=True,
|
||||
mp_cfg=dict(mp_start_method='fork', opencv_num_threads=0),
|
||||
dist_cfg=dict(backend='nccl'),
|
||||
)
|
||||
log_level = 'INFO'
|
||||
log_processor = dict(by_epoch=False)
|
||||
load_from = None # 从文件中加载检查点(checkpoint)
|
||||
resume = False # 是否从已有的模型恢复
|
||||
```
|
||||
|
||||
这些都是用于训练和测试PSPNet的配置文件,要加载和解析它们,我们可以使用[MMEngine](https://github.com/open-mmlab/mmengine)实现的[Config](https://mmengine.readthedocs.io/en/latest/tutorials/config.html)。
|
||||
|
||||
```python
|
||||
from mmengine.config import Config
|
||||
|
||||
cfg = Config.fromfile('configs/pspnet/pspnet_r50-d8_4xb2-40k_cityscapes-512x1024.py')
|
||||
print(cfg.train_dataloader)
|
||||
```
|
||||
|
||||
```shell
|
||||
{'batch_size': 2,
|
||||
'num_workers': 2,
|
||||
'persistent_workers': True,
|
||||
'sampler': {'type': 'InfiniteSampler', 'shuffle': True},
|
||||
'dataset': {'type': 'CityscapesDataset',
|
||||
'data_root': 'data/cityscapes/',
|
||||
'data_prefix': {'img_path': 'leftImg8bit/train',
|
||||
'seg_map_path': 'gtFine/train'},
|
||||
'pipeline': [{'type': 'LoadImageFromFile'},
|
||||
{'type': 'LoadAnnotations'},
|
||||
{'type': 'RandomResize',
|
||||
'scale': (2048, 1024),
|
||||
'ratio_range': (0.5, 2.0),
|
||||
'keep_ratio': True},
|
||||
{'type': 'RandomCrop', 'crop_size': (512, 1024), 'cat_max_ratio': 0.75},
|
||||
{'type': 'RandomFlip', 'prob': 0.5},
|
||||
{'type': 'PhotoMetricDistortion'},
|
||||
{'type': 'PackSegInputs'}]}}
|
||||
```
|
||||
|
||||
`cfg `是`mmengine.config.Config `的一个实例。它的接口与dict对象相同,也允许将配置值作为属性访问。更多信息请参见[MMEngine](https://github.com/open-mmlab/mmengine)中的[config tutorial](https://mmengine.readthedocs.io/en/latest/tutorials/config.html)。
|
||||
|
||||
## FAQ
|
||||
|
||||
### 忽略基础配置文件里的一些字段
|
||||
|
||||
有时,您可以设置`_delete_=True `来忽略基本配置文件中的某些字段。您可以参考[MMEngine](https://github.com/open-mmlab/mmengine)中的[config tutorial](https://mmengine.readthedocs.io/en/latest/tutorials/config.html)来获得一些简单的指导。
|
||||
|
||||
例如,在MMSegmentation中,如果您想在下面的配置文件`pspnet.py `中修改PSPNet的主干网络:
|
||||
|
||||
```python
|
||||
norm_cfg = dict(type='SyncBN', requires_grad=True)
|
||||
model = dict(
|
||||
type='EncoderDecoder',
|
||||
pretrained='torchvision://resnet50',
|
||||
backbone=dict(
|
||||
type='ResNetV1c',
|
||||
depth=50,
|
||||
num_stages=4,
|
||||
out_indices=(0, 1, 2, 3),
|
||||
dilations=(1, 1, 2, 4),
|
||||
strides=(1, 2, 1, 1),
|
||||
norm_cfg=norm_cfg,
|
||||
norm_eval=False,
|
||||
style='pytorch',
|
||||
contract_dilation=True),
|
||||
decode_head=dict(
|
||||
type='PSPHead',
|
||||
in_channels=2048,
|
||||
in_index=3,
|
||||
channels=512,
|
||||
pool_scales=(1, 2, 3, 6),
|
||||
dropout_ratio=0.1,
|
||||
num_classes=19,
|
||||
norm_cfg=norm_cfg,
|
||||
align_corners=False,
|
||||
loss_decode=dict(
|
||||
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)))
|
||||
```
|
||||
|
||||
用以下代码加载并解析配置文件`pspnet.py`:
|
||||
|
||||
```python
|
||||
from mmengine.config import Config
|
||||
|
||||
cfg = Config.fromfile('pspnet.py')
|
||||
print(cfg.model)
|
||||
```
|
||||
|
||||
```shell
|
||||
{'type': 'EncoderDecoder',
|
||||
'pretrained': 'torchvision://resnet50',
|
||||
'backbone': {'type': 'ResNetV1c',
|
||||
'depth': 50,
|
||||
'num_stages': 4,
|
||||
'out_indices': (0, 1, 2, 3),
|
||||
'dilations': (1, 1, 2, 4),
|
||||
'strides': (1, 2, 1, 1),
|
||||
'norm_cfg': {'type': 'SyncBN', 'requires_grad': True},
|
||||
'norm_eval': False,
|
||||
'style': 'pytorch',
|
||||
'contract_dilation': True},
|
||||
'decode_head': {'type': 'PSPHead',
|
||||
'in_channels': 2048,
|
||||
'in_index': 3,
|
||||
'channels': 512,
|
||||
'pool_scales': (1, 2, 3, 6),
|
||||
'dropout_ratio': 0.1,
|
||||
'num_classes': 19,
|
||||
'norm_cfg': {'type': 'SyncBN', 'requires_grad': True},
|
||||
'align_corners': False,
|
||||
'loss_decode': {'type': 'CrossEntropyLoss',
|
||||
'use_sigmoid': False,
|
||||
'loss_weight': 1.0}}}
|
||||
```
|
||||
|
||||
`ResNet`和`HRNet`使用不同的关键字构建,编写一个新的配置文件`hrnet.py`,如下所示:
|
||||
|
||||
```python
|
||||
_base_ = 'pspnet.py'
|
||||
norm_cfg = dict(type='SyncBN', requires_grad=True)
|
||||
model = dict(
|
||||
pretrained='open-mmlab://msra/hrnetv2_w32',
|
||||
backbone=dict(
|
||||
_delete_=True,
|
||||
type='HRNet',
|
||||
norm_cfg=norm_cfg,
|
||||
extra=dict(
|
||||
stage1=dict(
|
||||
num_modules=1,
|
||||
num_branches=1,
|
||||
block='BOTTLENECK',
|
||||
num_blocks=(4, ),
|
||||
num_channels=(64, )),
|
||||
stage2=dict(
|
||||
num_modules=1,
|
||||
num_branches=2,
|
||||
block='BASIC',
|
||||
num_blocks=(4, 4),
|
||||
num_channels=(32, 64)),
|
||||
stage3=dict(
|
||||
num_modules=4,
|
||||
num_branches=3,
|
||||
block='BASIC',
|
||||
num_blocks=(4, 4, 4),
|
||||
num_channels=(32, 64, 128)),
|
||||
stage4=dict(
|
||||
num_modules=3,
|
||||
num_branches=4,
|
||||
block='BASIC',
|
||||
num_blocks=(4, 4, 4, 4),
|
||||
num_channels=(32, 64, 128, 256)))))
|
||||
```
|
||||
|
||||
用以下代码加载并解析配置文件`hrnet.py`:
|
||||
|
||||
```python
|
||||
from mmengine.config import Config
|
||||
cfg = Config.fromfile('hrnet.py')
|
||||
print(cfg.model)
|
||||
```
|
||||
|
||||
```shell
|
||||
{'type': 'EncoderDecoder',
|
||||
'pretrained': 'open-mmlab://msra/hrnetv2_w32',
|
||||
'backbone': {'type': 'HRNet',
|
||||
'norm_cfg': {'type': 'SyncBN', 'requires_grad': True},
|
||||
'extra': {'stage1': {'num_modules': 1,
|
||||
'num_branches': 1,
|
||||
'block': 'BOTTLENECK',
|
||||
'num_blocks': (4,),
|
||||
'num_channels': (64,)},
|
||||
'stage2': {'num_modules': 1,
|
||||
'num_branches': 2,
|
||||
'block': 'BASIC',
|
||||
'num_blocks': (4, 4),
|
||||
'num_channels': (32, 64)},
|
||||
'stage3': {'num_modules': 4,
|
||||
'num_branches': 3,
|
||||
'block': 'BASIC',
|
||||
'num_blocks': (4, 4, 4),
|
||||
'num_channels': (32, 64, 128)},
|
||||
'stage4': {'num_modules': 3,
|
||||
'num_branches': 4,
|
||||
'block': 'BASIC',
|
||||
'num_blocks': (4, 4, 4, 4),
|
||||
'num_channels': (32, 64, 128, 256)}}},
|
||||
'decode_head': {'type': 'PSPHead',
|
||||
'in_channels': 2048,
|
||||
'in_index': 3,
|
||||
'channels': 512,
|
||||
'pool_scales': (1, 2, 3, 6),
|
||||
'dropout_ratio': 0.1,
|
||||
'num_classes': 19,
|
||||
'norm_cfg': {'type': 'SyncBN', 'requires_grad': True},
|
||||
'align_corners': False,
|
||||
'loss_decode': {'type': 'CrossEntropyLoss',
|
||||
'use_sigmoid': False,
|
||||
'loss_weight': 1.0}}}
|
||||
```
|
||||
|
||||
`_delete_=True` 将用新的键去替换 `backbone` 字段内所有旧的键。
|
||||
|
||||
### 使用配置文件里的中间变量
|
||||
|
||||
配置文件中会使用一些中间变量,例如数据集(datasets)字段里的 `train_pipeline`/`test_pipeline`。 需要注意的是,在子配置文件里修改中间变量时,您需要再次传递这些变量给对应的字段。例如,我们想改变在训练或测试PSPNet时采用的多尺度策略 (multi scale strategy),`train_pipeline`/`test_pipeline` 是我们需要修改的中间变量。
|
||||
|
||||
```python
|
||||
_base_ = '../pspnet/pspnet_r50-d8_4xb4-40k_cityscpaes-512x1024.py'
|
||||
crop_size = (512, 1024)
|
||||
img_norm_cfg = dict(
|
||||
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
|
||||
train_pipeline = [
|
||||
dict(type='LoadImageFromFile'),
|
||||
dict(type='LoadAnnotations'),
|
||||
dict(type='RandomResize',
|
||||
img_scale=(2048, 1024),
|
||||
ratio_range=(1., 2.),
|
||||
keep_ration=True),
|
||||
dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
|
||||
dict(type='RandomFlip', flip_ratio=0.5),
|
||||
dict(type='PhotoMetricDistortion'),
|
||||
dict(type='PackSegInputs'),
|
||||
]
|
||||
test_pipeline = [
|
||||
dict(type='LoadImageFromFile'),
|
||||
dict(type='Resize',
|
||||
scale=(2048, 1024),
|
||||
keep_ratio=True),
|
||||
dict(type='LoadAnnotations'),
|
||||
dict(type='PackSegInputs')
|
||||
]
|
||||
train_dataset=dict(
|
||||
type=dataset_type,
|
||||
data_root=data_root,
|
||||
data_prefix=dict(
|
||||
img_path='leftImg8bit/train', seg_map_path='gtFine/train'),
|
||||
pipeline=train_pipeline)
|
||||
test_dataset=dict(
|
||||
type=dataset_type,
|
||||
data_root=data_root,
|
||||
data_prefix=dict(
|
||||
img_path='leftImg8bit/val', seg_map_path='gtFine/val'),
|
||||
pipeline=test_pipeline)
|
||||
train_dataloader = dict(dataset=train_dataset)
|
||||
val_dataloader = dict(dataset=test_dataset)
|
||||
test_dataloader = val_dataloader
|
||||
```
|
||||
|
||||
我们首先需要定义新的 `train_pipeline`/`test_pipeline` 然后传递到 `dataset` 里。
|
||||
|
||||
类似的,如果我们想从 `SyncBN` 切换到 `BN` 或者 `MMSyncBN`,我们需要替换配置文件里的每一个 `norm_cfg`。
|
||||
|
||||
```python
|
||||
_base_ = '../pspnet/pspnet_r50-d8_4xb4-40k_cityscpaes-512x1024.py'
|
||||
norm_cfg = dict(type='BN', requires_grad=True)
|
||||
model = dict(
|
||||
backbone=dict(norm_cfg=norm_cfg),
|
||||
decode_head=dict(norm_cfg=norm_cfg),
|
||||
auxiliary_head=dict(norm_cfg=norm_cfg))
|
||||
```
|
||||
|
||||
## 通过脚本参数修改配置文件
|
||||
|
||||
在[training script](https://github.com/open-mmlab/mmsegmentation/blob/1.x/tools/train.py)和[testing script](https://github.com/open-mmlab/mmsegmentation/blob/1.x/tools/test.py)中,我们支持脚本参数 `--cfg-options`,它可以帮助用户覆盖所使用的配置中的一些设置,`xxx=yyy` 格式的键值对将合并到配置文件中。
|
||||
|
||||
例如,这是一个简化的脚本 `demo_script.py `:
|
||||
|
||||
```python
|
||||
import argparse
|
||||
|
||||
from mmengine.config import Config, DictAction
|
||||
|
||||
def parse_args():
|
||||
parser = argparse.ArgumentParser(description='Script Example')
|
||||
parser.add_argument('config', help='train config file path')
|
||||
parser.add_argument(
|
||||
'--cfg-options',
|
||||
nargs='+',
|
||||
action=DictAction,
|
||||
help='override some settings in the used config, the key-value pair '
|
||||
'in xxx=yyy format will be merged into config file. If the value to '
|
||||
'be overwritten is a list, it should be like key="[a,b]" or key=a,b '
|
||||
'It also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]" '
|
||||
'Note that the quotation marks are necessary and that no white space '
|
||||
'is allowed.')
|
||||
args = parser.parse_args()
|
||||
return args
|
||||
|
||||
def main():
|
||||
args = parse_args()
|
||||
|
||||
cfg = Config.fromfile(args.config)
|
||||
if args.cfg_options is not None:
|
||||
cfg.merge_from_dict(args.cfg_options)
|
||||
|
||||
print(cfg)
|
||||
|
||||
if __name__ == '__main__':
|
||||
main()
|
||||
```
|
||||
|
||||
一个配置文件示例 `demo_config.py` 如下所示:
|
||||
|
||||
```python
|
||||
backbone = dict(
|
||||
type='ResNetV1c',
|
||||
depth=50,
|
||||
num_stages=4,
|
||||
out_indices=(0, 1, 2, 3),
|
||||
dilations=(1, 1, 2, 4),
|
||||
strides=(1, 2, 1, 1),
|
||||
norm_eval=False,
|
||||
style='pytorch',
|
||||
contract_dilation=True)
|
||||
```
|
||||
|
||||
运行 `demo_script.py`:
|
||||
|
||||
```shell
|
||||
python demo_script.py demo_config.py
|
||||
```
|
||||
|
||||
```shell
|
||||
Config (path: demo_config.py): {'backbone': {'type': 'ResNetV1c', 'depth': 50, 'num_stages': 4, 'out_indices': (0, 1, 2, 3), 'dilations': (1, 1, 2, 4), 'strides': (1, 2, 1, 1), 'norm_eval': False, 'style': 'pytorch', 'contract_dilation': True}}
|
||||
```
|
||||
|
||||
通过脚本参数修改配置:
|
||||
|
||||
```shell
|
||||
python demo_script.py demo_config.py --cfg-options backbone.depth=101
|
||||
```
|
||||
|
||||
```shell
|
||||
Config (path: demo_config.py): {'backbone': {'type': 'ResNetV1c', 'depth': 101, 'num_stages': 4, 'out_indices': (0, 1, 2, 3), 'dilations': (1, 1, 2, 4), 'strides': (1, 2, 1, 1), 'norm_eval': False, 'style': 'pytorch', 'contract_dilation': True}}
|
||||
```
|
||||
|
||||
- 更新列表/元组的值。
|
||||
|
||||
如果要更新的值是一个 list 或 tuple。例如,需要在配置文件 `demo_config.py ` 的 `backbone ` 中设置 `stride =(1,2,1,1) `。
|
||||
如果您想更改这个键,你可以用两种方式进行指定:
|
||||
|
||||
1. `--cfg-options backbone.strides="(1, 1, 1, 1)"`. 注意引号 " 是支持 list/tuple 数据类型所必需的。
|
||||
|
||||
```shell
|
||||
python demo_script.py demo_config.py --cfg-options backbone.strides="(1, 1, 1, 1)"
|
||||
```
|
||||
|
||||
```shell
|
||||
Config (path: demo_config.py): {'backbone': {'type': 'ResNetV1c', 'depth': 50, 'num_stages': 4, 'out_indices': (0, 1, 2, 3), 'dilations': (1, 1, 2, 4), 'strides': (1, 1, 1, 1), 'norm_eval': False, 'style': 'pytorch', 'contract_dilation': True}}
|
||||
```
|
||||
|
||||
2. `--cfg-options backbone.strides=1,1,1,1`. 注意,在指定的值中**不允许**有空格。
|
||||
|
||||
另外,如果原来的类型是tuple,通过这种方式修改后会自动转换为list。
|
||||
|
||||
```shell
|
||||
python demo_script.py demo_config.py --cfg-options backbone.strides=1,1,1,1
|
||||
```
|
||||
|
||||
```shell
|
||||
Config (path: demo_config.py): {'backbone': {'type': 'ResNetV1c', 'depth': 50, 'num_stages': 4, 'out_indices': (0, 1, 2, 3), 'dilations': (1, 1, 2, 4), 'strides': [1, 1, 1, 1], 'norm_eval': False, 'style': 'pytorch', 'contract_dilation': True}}
|
||||
```
|
||||
|
||||
```{note}
|
||||
这种修改方法仅支持修改string、int、float、boolean、None、list和tuple类型的配置项。
|
||||
具体来说,对于list和tuple类型的配置项,它们内部的元素也必须是上述七种类型之一。
|
||||
```
|
||||
802
Seg_All_In_One_MMSeg/docs/zh_cn/user_guides/2_dataset_prepare.md
Normal file
802
Seg_All_In_One_MMSeg/docs/zh_cn/user_guides/2_dataset_prepare.md
Normal file
@@ -0,0 +1,802 @@
|
||||
# 教程2:准备数据集
|
||||
|
||||
我们建议将数据集根目录符号链接到 `$MMSEGMENTATION/data`。
|
||||
如果您的目录结构不同,您可能需要更改配置文件中相应的路径。
|
||||
对于中国境内的用户,我们也推荐通过开源数据平台 [OpenDataLab](https://opendatalab.com/) 来下载dsdl标准数据,以获得更好的下载和使用体验,这里有一个下载dsdl数据集并进行训练的案例[DSDLReadme](../../../configs/dsdl/README.md),欢迎尝试。
|
||||
|
||||
```none
|
||||
mmsegmentation
|
||||
├── mmseg
|
||||
├── tools
|
||||
├── configs
|
||||
├── data
|
||||
│ ├── cityscapes
|
||||
│ │ ├── leftImg8bit
|
||||
│ │ │ ├── train
|
||||
│ │ │ ├── val
|
||||
│ │ ├── gtFine
|
||||
│ │ │ ├── train
|
||||
│ │ │ ├── val
|
||||
│ ├── VOCdevkit
|
||||
│ │ ├── VOC2012
|
||||
│ │ │ ├── JPEGImages
|
||||
│ │ │ ├── SegmentationClass
|
||||
│ │ │ ├── ImageSets
|
||||
│ │ │ │ ├── Segmentation
|
||||
│ │ ├── VOC2010
|
||||
│ │ │ ├── JPEGImages
|
||||
│ │ │ ├── SegmentationClassContext
|
||||
│ │ │ ├── ImageSets
|
||||
│ │ │ │ ├── SegmentationContext
|
||||
│ │ │ │ │ ├── train.txt
|
||||
│ │ │ │ │ ├── val.txt
|
||||
│ │ │ ├── trainval_merged.json
|
||||
│ │ ├── VOCaug
|
||||
│ │ │ ├── dataset
|
||||
│ │ │ │ ├── cls
|
||||
│ ├── ade
|
||||
│ │ ├── ADEChallengeData2016
|
||||
│ │ │ ├── annotations
|
||||
│ │ │ │ ├── training
|
||||
│ │ │ │ ├── validation
|
||||
│ │ │ ├── images
|
||||
│ │ │ │ ├── training
|
||||
│ │ │ │ ├── validation
|
||||
│ ├── coco_stuff10k
|
||||
│ │ ├── images
|
||||
│ │ │ ├── train2014
|
||||
│ │ │ ├── test2014
|
||||
│ │ ├── annotations
|
||||
│ │ │ ├── train2014
|
||||
│ │ │ ├── test2014
|
||||
│ │ ├── imagesLists
|
||||
│ │ │ ├── train.txt
|
||||
│ │ │ ├── test.txt
|
||||
│ │ │ ├── all.txt
|
||||
│ ├── coco_stuff164k
|
||||
│ │ ├── images
|
||||
│ │ │ ├── train2017
|
||||
│ │ │ ├── val2017
|
||||
│ │ ├── annotations
|
||||
│ │ │ ├── train2017
|
||||
│ │ │ ├── val2017
|
||||
│ ├── CHASE_DB1
|
||||
│ │ ├── images
|
||||
│ │ │ ├── training
|
||||
│ │ │ ├── validation
|
||||
│ │ ├── annotations
|
||||
│ │ │ ├── training
|
||||
│ │ │ ├── validation
|
||||
│ ├── DRIVE
|
||||
│ │ ├── images
|
||||
│ │ │ ├── training
|
||||
│ │ │ ├── validation
|
||||
│ │ ├── annotations
|
||||
│ │ │ ├── training
|
||||
│ │ │ ├── validation
|
||||
│ ├── HRF
|
||||
│ │ ├── images
|
||||
│ │ │ ├── training
|
||||
│ │ │ ├── validation
|
||||
│ │ ├── annotations
|
||||
│ │ │ ├── training
|
||||
│ │ │ ├── validation
|
||||
│ ├── STARE
|
||||
│ │ ├── images
|
||||
│ │ │ ├── training
|
||||
│ │ │ ├── validation
|
||||
│ │ ├── annotations
|
||||
│ │ │ ├── training
|
||||
│ │ │ ├── validation
|
||||
| ├── dark_zurich
|
||||
| │ ├── gps
|
||||
| │ │ ├── val
|
||||
| │ │ └── val_ref
|
||||
| │ ├── gt
|
||||
| │ │ └── val
|
||||
| │ ├── LICENSE.txt
|
||||
| │ ├── lists_file_names
|
||||
| │ │ ├── val_filenames.txt
|
||||
| │ │ └── val_ref_filenames.txt
|
||||
| │ ├── README.md
|
||||
| │ └── rgb_anon
|
||||
| │ | ├── val
|
||||
| │ | └── val_ref
|
||||
| ├── NighttimeDrivingTest
|
||||
| | ├── gtCoarse_daytime_trainvaltest
|
||||
| | │ └── test
|
||||
| | │ └── night
|
||||
| | └── leftImg8bit
|
||||
| | | └── test
|
||||
| | | └── night
|
||||
│ ├── loveDA
|
||||
│ │ ├── img_dir
|
||||
│ │ │ ├── train
|
||||
│ │ │ ├── val
|
||||
│ │ │ ├── test
|
||||
│ │ ├── ann_dir
|
||||
│ │ │ ├── train
|
||||
│ │ │ ├── val
|
||||
│ ├── potsdam
|
||||
│ │ ├── img_dir
|
||||
│ │ │ ├── train
|
||||
│ │ │ ├── val
|
||||
│ │ ├── ann_dir
|
||||
│ │ │ ├── train
|
||||
│ │ │ ├── val
|
||||
│ ├── vaihingen
|
||||
│ │ ├── img_dir
|
||||
│ │ │ ├── train
|
||||
│ │ │ ├── val
|
||||
│ │ ├── ann_dir
|
||||
│ │ │ ├── train
|
||||
│ │ │ ├── val
|
||||
│ ├── iSAID
|
||||
│ │ ├── img_dir
|
||||
│ │ │ ├── train
|
||||
│ │ │ ├── val
|
||||
│ │ │ ├── test
|
||||
│ │ ├── ann_dir
|
||||
│ │ │ ├── train
|
||||
│ │ │ ├── val
|
||||
│ ├── synapse
|
||||
│ │ ├── img_dir
|
||||
│ │ │ ├── train
|
||||
│ │ │ ├── val
|
||||
│ │ ├── ann_dir
|
||||
│ │ │ ├── train
|
||||
│ │ │ ├── val
|
||||
│ ├── REFUGE
|
||||
│ │ ├── images
|
||||
│ │ │ ├── training
|
||||
│ │ │ ├── validation
|
||||
│ │ │ ├── test
|
||||
│ │ ├── annotations
|
||||
│ │ │ ├── training
|
||||
│ │ │ ├── validation
|
||||
│ │ │ ├── test
|
||||
│ ├── mapillary
|
||||
│ │ ├── training
|
||||
│ │ │ ├── images
|
||||
│ │ │ ├── v1.2
|
||||
| │ │ │ ├── instances
|
||||
| │ │ │ ├── labels
|
||||
| │ │ │ └── panoptic
|
||||
│ │ │ ├── v2.0
|
||||
| │ │ │ ├── instances
|
||||
| │ │ │ ├── labels
|
||||
| │ │ │ ├── panoptic
|
||||
| │ │ │ └── polygons
|
||||
│ │ ├── validation
|
||||
│ │ │ ├── images
|
||||
| │ │ ├── v1.2
|
||||
| │ │ │ ├── instances
|
||||
| │ │ │ ├── labels
|
||||
| │ │ │ └── panoptic
|
||||
│ │ │ ├── v2.0
|
||||
| │ │ │ ├── instances
|
||||
| │ │ │ ├── labels
|
||||
| │ │ │ ├── panoptic
|
||||
| │ │ │ └── polygons
|
||||
│ ├── bdd100k
|
||||
│ │ ├── images
|
||||
│ │ │ └── 10k
|
||||
| │ │ │ ├── test
|
||||
| │ │ │ ├── train
|
||||
| │ │ │ └── val
|
||||
│ │ └── labels
|
||||
│ │ │ └── sem_seg
|
||||
| │ │ │ ├── colormaps
|
||||
| │ │ │ │ ├──train
|
||||
| │ │ │ │ └──val
|
||||
| │ │ │ ├── masks
|
||||
| │ │ │ │ ├──train
|
||||
| │ │ │ │ └──val
|
||||
| │ │ │ ├── polygons
|
||||
| │ │ │ │ ├──sem_seg_train.json
|
||||
| │ │ │ │ └──sem_seg_val.json
|
||||
| │ │ │ └── rles
|
||||
| │ │ │ │ ├──sem_seg_train.json
|
||||
| │ │ │ │ └──sem_seg_val.json
|
||||
│ ├── nyu
|
||||
│ │ ├── images
|
||||
│ │ │ ├── train
|
||||
│ │ │ ├── test
|
||||
│ │ ├── annotations
|
||||
│ │ │ ├── train
|
||||
│ │ │ ├── test
|
||||
│ ├── HSIDrive20
|
||||
│ │ ├── images
|
||||
│ │ │ ├── train
|
||||
│ │ │ ├── validation
|
||||
│ │ │ ├── test
|
||||
│ │ ├── annotations
|
||||
│ │ │ ├── train
|
||||
│ │ │ ├── validation
|
||||
│ │ │ ├── test
|
||||
```
|
||||
|
||||
## 用 MIM 下载数据集
|
||||
|
||||
通过使用 [OpenXLab](https://openxlab.org.cn/datasets),您可以直接下载开源数据集。通过平台的搜索功能,您可以快速轻松地找到他们正在寻找的数据集。使用平台上的格式化数据集,您可以高效地跨数据集执行任务。
|
||||
|
||||
如果您使用 MIM 下载,请确保版本大于 v0.3.8。您可以使用以下命令进行更新、安装、登录和数据集下载:
|
||||
|
||||
```shell
|
||||
# upgrade your MIM
|
||||
pip install -U openmim
|
||||
|
||||
# install OpenXLab CLI tools
|
||||
pip install -U openxlab
|
||||
# log in OpenXLab
|
||||
openxlab login
|
||||
|
||||
# download ADE20K by MIM
|
||||
mim download mmsegmentation --dataset ade20k
|
||||
```
|
||||
|
||||
## Cityscapes
|
||||
|
||||
Cityscapes [官方网站](https://www.cityscapes-dataset.com/)可以下载 Cityscapes 数据集,按照官网要求注册并登陆后,数据可以在[这里](https://www.cityscapes-dataset.com/downloads/)找到。
|
||||
|
||||
按照惯例,`**labelTrainIds.png` 用于 cityscapes 训练。
|
||||
我们提供了一个基于 [cityscapesscripts](https://github.com/mcordts/cityscapesScripts) 的[脚本](https://github.com/open-mmlab/mmsegmentation/blob/1.x/tools/dataset_converters/cityscapes.py)用于生成 `**labelTrainIds.png`。
|
||||
|
||||
```shell
|
||||
# --nproc 表示 8 个转换进程,也可以省略。
|
||||
python tools/dataset_converters/cityscapes.py data/cityscapes --nproc 8
|
||||
```
|
||||
|
||||
## Pascal VOC
|
||||
|
||||
Pascal VOC 2012 可从[此处](http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar)下载。
|
||||
此外,Pascal VOC 数据集的最新工作通常利用额外的增强数据,可以在[这里](http://www.eecs.berkeley.edu/Research/Projects/CS/vision/grouping/semantic_contours/benchmark.tgz)找到。
|
||||
|
||||
如果您想使用增强的 VOC 数据集,请运行以下命令将增强数据的标注转换为正确的格式。
|
||||
|
||||
```shell
|
||||
# --nproc 表示 8 个转换进程,也可以省略。
|
||||
python tools/dataset_converters/voc_aug.py data/VOCdevkit data/VOCdevkit/VOCaug --nproc 8
|
||||
```
|
||||
|
||||
请参考[拼接数据集文档](../advanced_guides/add_datasets.md#拼接数据集)及 [voc_aug 配置示例](../../../configs/_base_/datasets/pascal_voc12_aug.py)以详细了解如何将它们拼接并合并训练。
|
||||
|
||||
## ADE20K
|
||||
|
||||
ADE20K 的训练和验证集可以从这个[链接](http://data.csail.mit.edu/places/ADEchallenge/ADEChallengeData2016.zip)下载。
|
||||
如果需要下载测试数据集,可以在[官网](http://host.robots.ox.ac.uk/)注册后,下载[测试集](http://host.robots.ox.ac.uk:8080/eval/downloads/VOC2010test.tar)。
|
||||
|
||||
## Pascal Context
|
||||
|
||||
Pascal Context 的训练和验证集可以从[此处](http://host.robots.ox.ac.uk/pascal/VOC/voc2010/VOCtrainval_03-May-2010.tar)下载。注册后,您也可以从[此处](http://host.robots.ox.ac.uk:8080/eval/downloads/VOC2010test.tar)下载测试集。
|
||||
|
||||
从原始数据集中抽出部分数据作为验证集,您可以从[此处](https://codalabuser.blob.core.windows.net/public/trainval_merged.json)下载 trainval_merged.json 文件。
|
||||
|
||||
请先安装 [Detail](https://github.com/zhanghang1989/detail-api) 工具然后运行以下命令将标注转换为正确的格式。
|
||||
|
||||
```shell
|
||||
python tools/dataset_converters/pascal_context.py data/VOCdevkit data/VOCdevkit/VOC2010/trainval_merged.json
|
||||
```
|
||||
|
||||
## COCO Stuff 10k
|
||||
|
||||
数据可以通过 wget 在[这里](http://calvin.inf.ed.ac.uk/wp-content/uploads/data/cocostuffdataset/cocostuff-10k-v1.1.zip)下载。
|
||||
|
||||
对于 COCO Stuff 10k 数据集,请运行以下命令下载并转换数据集。
|
||||
|
||||
```shell
|
||||
# 下载
|
||||
mkdir coco_stuff10k && cd coco_stuff10k
|
||||
wget http://calvin.inf.ed.ac.uk/wp-content/uploads/data/cocostuffdataset/cocostuff-10k-v1.1.zip
|
||||
|
||||
# 解压
|
||||
unzip cocostuff-10k-v1.1.zip
|
||||
|
||||
# --nproc 表示 8 个转换进程,也可以省略。
|
||||
python tools/dataset_converters/coco_stuff10k.py /path/to/coco_stuff10k --nproc 8
|
||||
```
|
||||
|
||||
按照惯例,`/path/to/coco_stuff164k/annotations/*2014/*_labelTrainIds.png` 中的 mask 标注用于 COCO Stuff 10k 的训练和测试。
|
||||
|
||||
## COCO Stuff 164k
|
||||
|
||||
对于 COCO Stuff 164k 数据集,请运行以下命令下载并转换增强的数据集。
|
||||
|
||||
```shell
|
||||
# 下载
|
||||
mkdir coco_stuff164k && cd coco_stuff164k
|
||||
wget http://images.cocodataset.org/zips/train2017.zip
|
||||
wget http://images.cocodataset.org/zips/val2017.zip
|
||||
wget http://calvin.inf.ed.ac.uk/wp-content/uploads/data/cocostuffdataset/stuffthingmaps_trainval2017.zip
|
||||
|
||||
# 解压
|
||||
unzip train2017.zip -d images/
|
||||
unzip val2017.zip -d images/
|
||||
unzip stuffthingmaps_trainval2017.zip -d annotations/
|
||||
|
||||
# --nproc 表示 8 个转换进程,也可以省略。
|
||||
python tools/dataset_converters/coco_stuff164k.py /path/to/coco_stuff164k --nproc 8
|
||||
```
|
||||
|
||||
按照惯例,`/path/to/coco_stuff164k/annotations/*2017/*_labelTrainIds.png` 中的 mask 标注用于 COCO Stuff 164k 的训练和测试。
|
||||
|
||||
此数据集的详细信息可在[此处](https://github.com/nightrome/cocostuff#downloads)找到。
|
||||
|
||||
## CHASE DB1
|
||||
|
||||
CHASE DB1 的训练和验证集可以从[此处](https://staffnet.kingston.ac.uk/~ku15565/CHASE_DB1/assets/CHASEDB1.zip)下载。
|
||||
|
||||
请运行以下命令,准备 CHASE DB1 数据集:
|
||||
|
||||
```shell
|
||||
python tools/dataset_converters/chase_db1.py /path/to/CHASEDB1.zip
|
||||
```
|
||||
|
||||
该脚本将自动调整数据集目录结构,使其满足 MMSegmentation 数据集加载要求。
|
||||
|
||||
## DRIVE
|
||||
|
||||
按照[官网](https://drive.grand-challenge.org/)要求,注册并登陆后,便可以下载 DRIVE 的训练和验证数据集。
|
||||
|
||||
要将 DRIVE 数据集转换为 MMSegmentation 的格式,请运行以下命令:
|
||||
|
||||
```shell
|
||||
python tools/dataset_converters/drive.py /path/to/training.zip /path/to/test.zip
|
||||
```
|
||||
|
||||
该脚本将自动调整数据集目录结构,使其满足 MMSegmentation 数据集加载要求。
|
||||
|
||||
## HRF
|
||||
|
||||
请下载 [health.zip](https://www5.cs.fau.de/fileadmin/research/datasets/fundus-images/healthy.zip)、[glaucoma.zip](https://www5.cs.fau.de/fileadmin/research/datasets/fundus-images/glaucoma.zip)、[diabetic_retinopathy.zip](https://www5.cs.fau.de/fileadmin/research/datasets/fundus-images/diabetic_retinopathy.zip)、[healthy_manualsegm.zip](https://www5.cs.fau.de/fileadmin/research/datasets/fundus-images/healthy_manualsegm.zip)、[glaucoma_manualsegm.zip](https://www5.cs.fau.de/fileadmin/research/datasets/fundus-images/glaucoma_manualsegm.zip) 和 [diabetic_retinopathy_manualsegm.zip](https://www5.cs.fau.de/fileadmin/research/datasets/fundus-images/diabetic_retinopathy_manualsegm.zip),无需解压,可以直接运行以下命令,准备 HRF 数据集:
|
||||
|
||||
```shell
|
||||
python tools/dataset_converters/hrf.py /path/to/healthy.zip /path/to/healthy_manualsegm.zip /path/to/glaucoma.zip /path/to/glaucoma_manualsegm.zip /path/to/diabetic_retinopathy.zip /path/to/diabetic_retinopathy_manualsegm.zip
|
||||
```
|
||||
|
||||
该脚本将自动调整数据集目录结构,使其满足 MMSegmentation 数据集加载要求。
|
||||
|
||||
## STARE
|
||||
|
||||
请下载 [stare images.tar](http://cecas.clemson.edu/~ahoover/stare/probing/stare-images.tar)、[labels-ah.tar](http://cecas.clemson.edu/~ahoover/stare/probing/labels-ah.tar) 和 [labels-vk.tar](http://cecas.clemson.edu/~ahoover/stare/probing/labels-vk.tar),无需解压,可以直接运行以下命令,准备 STARE 数据集:
|
||||
|
||||
```shell
|
||||
python tools/dataset_converters/stare.py /path/to/stare-images.tar /path/to/labels-ah.tar /path/to/labels-vk.tar
|
||||
```
|
||||
|
||||
该脚本将自动调整数据集目录结构,使其满足 MMSegmentation 数据集加载要求。
|
||||
|
||||
## Dark Zurich
|
||||
|
||||
由于我们只支持在此数据集上的模型测试,因此您只需要下载并解压[验证数据集](https://data.vision.ee.ethz.ch/csakarid/shared/GCMA_UIoU/Dark_Zurich_val_anon.zip)。
|
||||
|
||||
## Nighttime Driving
|
||||
|
||||
由于我们只支持在此数据集上的模型测试,因此您只需要下载并解压[验证数据集](http://data.vision.ee.ethz.ch/daid/NighttimeDriving/NighttimeDrivingTest.zip)。
|
||||
|
||||
## LoveDA
|
||||
|
||||
数据可以从[此处](https://drive.google.com/drive/folders/1ibYV0qwn4yuuh068Rnc-w4tPi0U0c-ti?usp=sharing)下载 LaveDA 数据集。
|
||||
|
||||
或者可以从 [zenodo](https://zenodo.org/record/5706578#.YZvN7SYRXdF) 下载。下载后,无需解压,直接运行以下命令:
|
||||
|
||||
```shell
|
||||
# 下载 Train.zip
|
||||
wget https://zenodo.org/record/5706578/files/Train.zip
|
||||
# 下载 Val.zip
|
||||
wget https://zenodo.org/record/5706578/files/Val.zip
|
||||
# 下载 Test.zip
|
||||
wget https://zenodo.org/record/5706578/files/Test.zip
|
||||
```
|
||||
|
||||
请对于 LoveDA 数据集,请运行以下命令调整数据集目录。
|
||||
|
||||
```shell
|
||||
python tools/dataset_converters/loveda.py /path/to/loveDA
|
||||
```
|
||||
|
||||
可将模型对 LoveDA 的测试集的预测结果上传至到数据集[测试服务器](https://codalab.lisn.upsaclay.fr/competitions/421),查看评测结果。
|
||||
|
||||
有关 LoveDA 的更多详细信息,可查看[此处](https://github.com/Junjue-Wang/LoveDA).
|
||||
|
||||
## ISPRS Potsdam
|
||||
|
||||
[Potsdam](https://www.isprs.org/education/benchmarks/UrbanSemLab/2d-sem-label-potsdam.aspx) 城市语义分割数据集用于 2D 语义分割竞赛 —— Potsdam。
|
||||
|
||||
数据集可以在竞赛[主页](https://www.isprs.org/education/benchmarks/UrbanSemLab/default.aspx)上请求获得。
|
||||
这里也提供了[BaiduNetdisk](https://pan.baidu.com/s/1K-cLVZnd1X7d8c26FQ-nGg?pwd=mseg),提取码:mseg、 [Google Drive](https://drive.google.com/drive/folders/1w3EJuyUGet6_qmLwGAWZ9vw5ogeG0zLz?usp=sharing)以及[OpenDataLab](https://opendatalab.com/ISPRS_Potsdam/download)。
|
||||
实验中需要下载 '2_Ortho_RGB.zip' 和 '5_Labels_all_noBoundary.zip'。
|
||||
|
||||
对于 Potsdam 数据集,请运行以下命令调整数据集目录。
|
||||
|
||||
```shell
|
||||
python tools/dataset_converters/potsdam.py /path/to/potsdam
|
||||
```
|
||||
|
||||
在我们的默认设置中,将生成 3456 张图像用于训练和 2016 张图像用于验证。
|
||||
|
||||
## ISPRS Vaihingen
|
||||
|
||||
[Vaihingen](https://www.isprs.org/education/benchmarks/UrbanSemLab/2d-sem-label-vaihingen.aspx) 城市语义分割数据集用于 2D 语义分割竞赛 —— Vaihingen。
|
||||
|
||||
数据集可以在竞赛[主页](https://www.isprs.org/education/benchmarks/UrbanSemLab/default.aspx)上请求获得。
|
||||
这里也提供了[BaiduNetdisk](https://pan.baidu.com/s/109D3WLrLafsuYtLeerLiiA?pwd=mseg),提取码:mseg 、 [Google Drive](https://drive.google.com/drive/folders/1w3NhvLVA2myVZqOn2pbiDXngNC7NTP_t?usp=sharing)。
|
||||
实验中需要下载 'ISPRS_semantic_labeling_Vaihingen.zip' 和 'ISPRS_semantic_labeling_Vaihingen_ground_truth_eroded_COMPLETE.zip'。
|
||||
|
||||
对于 Vaihingen 数据集,请运行以下命令调整数据集目录。
|
||||
|
||||
```shell
|
||||
python tools/dataset_converters/vaihingen.py /path/to/vaihingen
|
||||
```
|
||||
|
||||
在我们的默认设置(`clip_size`=512, `stride_size`=256)中,将生成 344 张图像用于训练和 398 张图像用于验证。
|
||||
|
||||
## iSAID
|
||||
|
||||
iSAID 数据集可从 [DOTA-v1.0](https://captain-whu.github.io/DOTA/dataset.html) 下载训练/验证/测试数据集的图像数据,
|
||||
|
||||
并从 [iSAID](https://captain-whu.github.io/iSAID/dataset.html)下载训练/验证数据集的标注数据。
|
||||
|
||||
该数据集是航空图像实例分割和语义分割任务的大规模数据集。
|
||||
|
||||
下载 iSAID 数据集后,您可能需要按照以下结构进行数据集准备。
|
||||
|
||||
```none
|
||||
├── data
|
||||
│ ├── iSAID
|
||||
│ │ ├── train
|
||||
│ │ │ ├── images
|
||||
│ │ │ │ ├── part1.zip
|
||||
│ │ │ │ ├── part2.zip
|
||||
│ │ │ │ ├── part3.zip
|
||||
│ │ │ ├── Semantic_masks
|
||||
│ │ │ │ ├── images.zip
|
||||
│ │ ├── val
|
||||
│ │ │ ├── images
|
||||
│ │ │ │ ├── part1.zip
|
||||
│ │ │ ├── Semantic_masks
|
||||
│ │ │ │ ├── images.zip
|
||||
│ │ ├── test
|
||||
│ │ │ ├── images
|
||||
│ │ │ │ ├── part1.zip
|
||||
│ │ │ │ ├── part2.zip
|
||||
```
|
||||
|
||||
```shell
|
||||
python tools/dataset_converters/isaid.py /path/to/iSAID
|
||||
```
|
||||
|
||||
在我们的默认设置(`patch_width`=896, `patch_height`=896, `overlap_area`=384)中,将生成 33978 张图像用于训练和 11644 张图像用于验证。
|
||||
|
||||
## LIP(Look Into Person) dataset
|
||||
|
||||
该数据集可以从[此页面](https://lip.sysuhcp.com/overview.php)下载。
|
||||
|
||||
请运行以下命令来解压数据集。
|
||||
|
||||
```shell
|
||||
unzip LIP.zip
|
||||
cd LIP
|
||||
unzip TrainVal_images.zip
|
||||
unzip TrainVal_parsing_annotations.zip
|
||||
cd TrainVal_parsing_annotations
|
||||
unzip TrainVal_parsing_annotations.zip
|
||||
mv train_segmentations ../
|
||||
mv val_segmentations ../
|
||||
cd ..
|
||||
```
|
||||
|
||||
LIP 数据集的内容包括:
|
||||
|
||||
```none
|
||||
├── data
|
||||
│ ├── LIP
|
||||
│ │ ├── train_images
|
||||
│ │ │ ├── 1000_1234574.jpg
|
||||
│ │ │ ├── ...
|
||||
│ │ ├── train_segmentations
|
||||
│ │ │ ├── 1000_1234574.png
|
||||
│ │ │ ├── ...
|
||||
│ │ ├── val_images
|
||||
│ │ │ ├── 100034_483681.jpg
|
||||
│ │ │ ├── ...
|
||||
│ │ ├── val_segmentations
|
||||
│ │ │ ├── 100034_483681.png
|
||||
│ │ │ ├── ...
|
||||
```
|
||||
|
||||
## Synapse dataset
|
||||
|
||||
此数据集可以从[此页面](https://www.synapse.org/#!Synapse:syn3193805/wiki/)下载。
|
||||
|
||||
遵循 [TransUNet](https://arxiv.org/abs/2102.04306) 的数据准备设定,将原始训练集(30 次扫描)拆分为新的训练集(18 次扫描)和验证集(12 次扫描)。请运行以下命令来准备数据集。
|
||||
|
||||
```shell
|
||||
unzip RawData.zip
|
||||
cd ./RawData/Training
|
||||
```
|
||||
|
||||
然后创建 `train.txt` 和 `val.txt` 以拆分数据集。
|
||||
|
||||
根据 TransUnet,以下是数据集的划分。
|
||||
|
||||
train.txt
|
||||
|
||||
```none
|
||||
img0005.nii.gz
|
||||
img0006.nii.gz
|
||||
img0007.nii.gz
|
||||
img0009.nii.gz
|
||||
img0010.nii.gz
|
||||
img0021.nii.gz
|
||||
img0023.nii.gz
|
||||
img0024.nii.gz
|
||||
img0026.nii.gz
|
||||
img0027.nii.gz
|
||||
img0028.nii.gz
|
||||
img0030.nii.gz
|
||||
img0031.nii.gz
|
||||
img0033.nii.gz
|
||||
img0034.nii.gz
|
||||
img0037.nii.gz
|
||||
img0039.nii.gz
|
||||
img0040.nii.gz
|
||||
```
|
||||
|
||||
val.txt
|
||||
|
||||
```none
|
||||
img0008.nii.gz
|
||||
img0022.nii.gz
|
||||
img0038.nii.gz
|
||||
img0036.nii.gz
|
||||
img0032.nii.gz
|
||||
img0002.nii.gz
|
||||
img0029.nii.gz
|
||||
img0003.nii.gz
|
||||
img0001.nii.gz
|
||||
img0004.nii.gz
|
||||
img0025.nii.gz
|
||||
img0035.nii.gz
|
||||
```
|
||||
|
||||
synapse 数据集的内容包括:
|
||||
|
||||
```none
|
||||
├── Training
|
||||
│ ├── img
|
||||
│ │ ├── img0001.nii.gz
|
||||
│ │ ├── img0002.nii.gz
|
||||
│ │ ├── ...
|
||||
│ ├── label
|
||||
│ │ ├── label0001.nii.gz
|
||||
│ │ ├── label0002.nii.gz
|
||||
│ │ ├── ...
|
||||
│ ├── train.txt
|
||||
│ ├── val.txt
|
||||
```
|
||||
|
||||
然后,使用此命令转换 synapse 数据集。
|
||||
|
||||
```shell
|
||||
python tools/dataset_converters/synapse.py --dataset-path /path/to/synapse
|
||||
```
|
||||
|
||||
注意,MMSegmentation 的默认评估指标(例如 mean dice value)是在 2D 切片图像上计算的,这与 [TransUNet](https://arxiv.org/abs/2102.04306) 等一些论文中的 3D 扫描结果是不同的。
|
||||
|
||||
## REFUGE
|
||||
|
||||
在 [REFUGE Challenge](https://refuge.grand-challenge.org) 官网上注册并下载 [REFUGE 数据集](https://refuge.grand-challenge.org/REFUGE2Download)。
|
||||
|
||||
然后,解压 `REFUGE2.zip`,原始数据集的内容包括:
|
||||
|
||||
```none
|
||||
├── REFUGE2
|
||||
│ ├── REFUGE2
|
||||
│ │ ├── Annotation-Training400.zip
|
||||
│ │ ├── REFUGE-Test400.zip
|
||||
│ │ ├── REFUGE-Test-GT.zip
|
||||
│ │ ├── REFUGE-Training400.zip
|
||||
│ │ ├── REFUGE-Validation400.zip
|
||||
│ │ ├── REFUGE-Validation400-GT.zip
|
||||
│ ├── __MACOSX
|
||||
```
|
||||
|
||||
请运行以下命令转换 REFUGE 数据集:
|
||||
|
||||
```shell
|
||||
python tools/convert_datasets/refuge.py --raw_data_root=/path/to/refuge/REFUGE2/REFUGE2
|
||||
```
|
||||
|
||||
脚本会将目录结构转换如下:
|
||||
|
||||
```none
|
||||
│ ├── REFUGE
|
||||
│ │ ├── images
|
||||
│ │ │ ├── training
|
||||
│ │ │ ├── validation
|
||||
│ │ │ ├── test
|
||||
│ │ ├── annotations
|
||||
│ │ │ ├── training
|
||||
│ │ │ ├── validation
|
||||
│ │ │ ├── test
|
||||
```
|
||||
|
||||
包含 400 张用于训练的图像、400 张用于验证的图像和 400 张用于测试的图像,这与 REFUGE 2018 数据集相同。
|
||||
|
||||
## Mapillary Vistas Datasets
|
||||
|
||||
- Mapillary Vistas [官方网站](https://www.mapillary.com/dataset/vistas) 可以下载 Mapillary Vistas 数据集,按照官网要求注册并登陆后,数据可以在[这里](https://www.mapillary.com/dataset/vistas)找到。
|
||||
|
||||
- Mapillary Vistas 数据集使用 8-bit with color-palette 来存储标签。不需要进行转换操作。
|
||||
|
||||
- 假设您已将数据集 zip 文件放在 `mmsegmentation/data/mapillary` 中
|
||||
|
||||
- 请运行以下命令来解压数据集。
|
||||
|
||||
```bash
|
||||
cd data/mapillary
|
||||
unzip An-ZjB1Zm61yAZG0ozTymz8I8NqI4x0MrYrh26dq7kPgfu8vf9ImrdaOAVOFYbJ2pNAgUnVGBmbue9lTgdBOb5BbKXIpFs0fpYWqACbrQDChAA2fdX0zS9PcHu7fY8c-FOvyBVxPNYNFQuM.zip
|
||||
```
|
||||
|
||||
- 解压后,您将获得类似于此结构的 Mapillary Vistas 数据集。语义分割 mask 标签在 `labels` 文件夹中。
|
||||
|
||||
```none
|
||||
mmsegmentation
|
||||
├── mmseg
|
||||
├── tools
|
||||
├── configs
|
||||
├── data
|
||||
│ ├── mapillary
|
||||
│ │ ├── training
|
||||
│ │ │ ├── images
|
||||
│ │ │ ├── v1.2
|
||||
| │ │ │ ├── instances
|
||||
| │ │ │ ├── labels
|
||||
| │ │ │ └── panoptic
|
||||
│ │ │ ├── v2.0
|
||||
| │ │ │ ├── instances
|
||||
| │ │ │ ├── labels
|
||||
| │ │ │ ├── panoptic
|
||||
| │ │ │ └── polygons
|
||||
│ │ ├── validation
|
||||
│ │ │ ├── images
|
||||
| │ │ ├── v1.2
|
||||
| │ │ │ ├── instances
|
||||
| │ │ │ ├── labels
|
||||
| │ │ │ └── panoptic
|
||||
│ │ │ ├── v2.0
|
||||
| │ │ │ ├── instances
|
||||
| │ │ │ ├── labels
|
||||
| │ │ │ ├── panoptic
|
||||
| │ │ │ └── polygons
|
||||
```
|
||||
|
||||
- 您可以在配置中使用 `MapillaryDataset_v1` 和 `Mapillary Dataset_v2` 设置数据集版本。
|
||||
在此处 [V1.2](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/_base_/datasets/mapillary_v1.py) 和 [V2.0](https://github.com/open-mmlab/mmsegmentation/blob/main/configs/_base_/datasets/mapillary_v2.py) 查看 Mapillary Vistas 数据集配置文件
|
||||
|
||||
## LEVIR-CD
|
||||
|
||||
[LEVIR-CD](https://justchenhao.github.io/LEVIR/) 大规模遥感建筑变化检测数据集。
|
||||
|
||||
数据集可以在[主页](https://justchenhao.github.io/LEVIR/)上请求获得。
|
||||
|
||||
数据集的补充版本可以在[主页](https://github.com/S2Looking/Dataset)上请求获得。
|
||||
|
||||
请下载数据集的补充版本,然后解压 `LEVIR-CD+.zip`,数据集的内容包括:
|
||||
|
||||
```none
|
||||
│ ├── LEVIR-CD+
|
||||
│ │ ├── train
|
||||
│ │ │ ├── A
|
||||
│ │ │ ├── B
|
||||
│ │ │ ├── label
|
||||
│ │ ├── test
|
||||
│ │ │ ├── A
|
||||
│ │ │ ├── B
|
||||
│ │ │ ├── label
|
||||
```
|
||||
|
||||
对于 LEVIR-CD 数据集,请运行以下命令无重叠裁剪影像:
|
||||
|
||||
```shell
|
||||
python tools/dataset_converters/levircd.py --dataset-path /path/to/LEVIR-CD+ --out_dir /path/to/LEVIR-CD
|
||||
```
|
||||
|
||||
裁剪后的影像大小为256x256,与原论文保持一致。
|
||||
|
||||
## BDD100K
|
||||
|
||||
- 可以从[官方网站](https://bdd-data.berkeley.edu/) 下载 BDD100K数据集(语义分割任务主要是10K数据集),按照官网要求注册并登陆后,数据可以在[这里](https://bdd-data.berkeley.edu/portal.html#download)找到。
|
||||
|
||||
- 图像数据对应的名称是是`10K Images`, 语义分割标注对应的名称是`Segmentation`
|
||||
|
||||
- 下载后,可以使用以下代码进行解压
|
||||
|
||||
```bash
|
||||
unzip ~/bdd100k_images_10k.zip -d ~/mmsegmentation/data/
|
||||
unzip ~/bdd100k_sem_seg_labels_trainval.zip -d ~/mmsegmentation/data/
|
||||
```
|
||||
|
||||
就可以得到以下文件结构了:
|
||||
|
||||
```none
|
||||
mmsegmentation
|
||||
├── mmseg
|
||||
├── tools
|
||||
├── configs
|
||||
├── data
|
||||
│ ├── bdd100k
|
||||
│ │ ├── images
|
||||
│ │ │ └── 10k
|
||||
| │ │ │ ├── test
|
||||
| │ │ │ ├── train
|
||||
| │ │ │ └── val
|
||||
│ │ └── labels
|
||||
│ │ │ └── sem_seg
|
||||
| │ │ │ ├── colormaps
|
||||
| │ │ │ │ ├──train
|
||||
| │ │ │ │ └──val
|
||||
| │ │ │ ├── masks
|
||||
| │ │ │ │ ├──train
|
||||
| │ │ │ │ └──val
|
||||
| │ │ │ ├── polygons
|
||||
| │ │ │ │ ├──sem_seg_train.json
|
||||
| │ │ │ │ └──sem_seg_val.json
|
||||
| │ │ │ └── rles
|
||||
| │ │ │ │ ├──sem_seg_train.json
|
||||
| │ │ │ │ └──sem_seg_val.json
|
||||
```
|
||||
|
||||
## NYU
|
||||
|
||||
- 您可以从 [这个链接](https://drive.google.com/file/d/1wC-io-14RCIL4XTUrQLk6lBqU2AexLVp/view?usp=share_link) 下载 NYU 数据集
|
||||
|
||||
- 下载完成后,您可以使用 [tools/dataset_converters/nyu.py](/tools/dataset_converters/nyu.py) 脚本来解压和组织数据到所需的格式
|
||||
|
||||
```bash
|
||||
python tools/dataset_converters/nyu.py nyu.zip
|
||||
```
|
||||
|
||||
## HSI Drive 2.0
|
||||
|
||||
- 您可以从以下位置下载 HSI Drive 2.0 数据集 [here](https://ipaccess.ehu.eus/HSI-Drive/#download) 刚刚向 gded@ehu.eus 发送主题为“下载 HSI-Drive”的电子邮件后 您将收到解压缩文件的密码.
|
||||
|
||||
- 下载后,按照以下说明解压:
|
||||
|
||||
```bash
|
||||
7z x -p"password" ./HSI_Drive_v2_0_Phyton.zip
|
||||
|
||||
mv ./HSIDrive20 path_to_mmsegmentation/data
|
||||
mv ./HSI_Drive_v2_0_release_notes_Python_version.md path_to_mmsegmentation/data
|
||||
mv ./image_numbering.pdf path_to_mmsegmentation/data
|
||||
```
|
||||
|
||||
- 解压后得到:
|
||||
|
||||
```none
|
||||
mmsegmentation
|
||||
├── mmseg
|
||||
├── tools
|
||||
├── configs
|
||||
├── data
|
||||
│ ├── HSIDrive20
|
||||
│ │ ├── images
|
||||
│ │ │ ├── training
|
||||
│ │ │ ├── validation
|
||||
│ │ │ ├── test
|
||||
│ │ ├── annotations
|
||||
│ │ │ ├── training
|
||||
│ │ │ ├── validation
|
||||
│ │ │ ├── test
|
||||
│ │ ├── images_MF
|
||||
│ │ │ ├── training
|
||||
│ │ │ ├── validation
|
||||
│ │ │ ├── test
|
||||
│ │ ├── RGB
|
||||
│ │ ├── training_filenames.txt
|
||||
│ │ ├── validation_filenames.txt
|
||||
│ │ ├── test_filenames.txt
|
||||
│ ├── HSI_Drive_v2_0_release_notes_Python_version.md
|
||||
│ ├── image_numbering.pdf
|
||||
```
|
||||
244
Seg_All_In_One_MMSeg/docs/zh_cn/user_guides/3_inference.md
Normal file
244
Seg_All_In_One_MMSeg/docs/zh_cn/user_guides/3_inference.md
Normal file
@@ -0,0 +1,244 @@
|
||||
# 教程3:使用预训练模型推理
|
||||
|
||||
MMSegmentation 在 [Model Zoo](../Model_Zoo.md) 中为语义分割提供了预训练的模型,并支持多个标准数据集,包括 Cityscapes、ADE20K 等。
|
||||
本说明将展示如何使用现有模型对给定图像进行推理。
|
||||
关于如何在标准数据集上测试现有模型,请参阅本[指南](./4_train_test.md)
|
||||
|
||||
MMSegmentation 为用户提供了数个接口,以便轻松使用预训练的模型进行推理。
|
||||
|
||||
- [教程3:使用预训练模型推理](#教程3使用预训练模型推理)
|
||||
- [推理器](#推理器)
|
||||
- [基本使用](#基本使用)
|
||||
- [初始化](#初始化)
|
||||
- [可视化预测结果](#可视化预测结果)
|
||||
- [模型列表](#模型列表)
|
||||
- [推理 API](#推理-api)
|
||||
- [mmseg.apis.init_model](#mmsegapisinit_model)
|
||||
- [mmseg.apis.inference_model](#mmsegapisinference_model)
|
||||
- [mmseg.apis.show_result_pyplot](#mmsegapisshow_result_pyplot)
|
||||
|
||||
## 推理器
|
||||
|
||||
在 MMSegmentation 中,我们提供了最**方便的**方式 `MMSegInferencer` 来使用模型。您只需 3 行代码就可以获得图像的分割掩膜。
|
||||
|
||||
### 基本使用
|
||||
|
||||
以下示例展示了如何使用 `MMSegInferencer` 对单个图像执行推理。
|
||||
|
||||
```
|
||||
>>> from mmseg.apis import MMSegInferencer
|
||||
>>> # 将模型加载到内存中
|
||||
>>> inferencer = MMSegInferencer(model='deeplabv3plus_r18-d8_4xb2-80k_cityscapes-512x1024')
|
||||
>>> # 推理
|
||||
>>> inferencer('demo/demo.png', show=True)
|
||||
```
|
||||
|
||||
可视化结果应如下所示:
|
||||
|
||||
<div align="center">
|
||||
<img src='https://user-images.githubusercontent.com/76149310/221507927-ae01e3a7-016f-4425-b966-7b19cbbe494e.png' />
|
||||
</div>
|
||||
|
||||
此外,您可以使用 `MMSegInferencer` 来处理一个包含多张图片的 `list`:
|
||||
|
||||
```
|
||||
# 输入一个图片 list
|
||||
>>> images = [image1, image2, ...] # image1 可以是文件路径或 np.ndarray
|
||||
>>> inferencer(images, show=True, wait_time=0.5) # wait_time 是延迟时间,0 表示无限
|
||||
|
||||
# 或输入图像目录
|
||||
>>> images = $IMAGESDIR
|
||||
>>> inferencer(images, show=True, wait_time=0.5)
|
||||
|
||||
# 保存可视化渲染彩色分割图和预测结果
|
||||
# out_dir 是保存输出结果的目录,img_out_dir 和 pred_out_dir 为 out_dir 的子目录
|
||||
# 以保存可视化渲染彩色分割图和预测结果
|
||||
>>> inferencer(images, out_dir='outputs', img_out_dir='vis', pred_out_dir='pred')
|
||||
```
|
||||
|
||||
推理器有一个可选参数 `return_datasamples`,其默认值为 False,推理器的返回值默认为 `dict` 类型,包括 'visualization' 和 'predictions' 两个 key。
|
||||
如果 `return_datasamples=True` 推理器将返回 [`SegDataSample`](../advanced_guides/structures.md) 或其列表。
|
||||
|
||||
```
|
||||
result = inferencer('demo/demo.png')
|
||||
# 结果是一个包含 'visualization' 和 'predictions' 两个 key 的 `dict`
|
||||
# 'visualization' 包含彩色分割图
|
||||
print(result['visualization'].shape)
|
||||
# (512, 683, 3)
|
||||
|
||||
# 'predictions' 包含带有标签索引的分割掩膜
|
||||
print(result['predictions'].shape)
|
||||
# (512, 683)
|
||||
|
||||
result = inferencer('demo/demo.png', return_datasamples=True)
|
||||
print(type(result))
|
||||
# <class 'mmseg.structures.seg_data_sample.SegDataSample'>
|
||||
|
||||
# 输入一个图片 list
|
||||
results = inferencer(images)
|
||||
# 输出为列表
|
||||
print(type(results['visualization']), results['visualization'][0].shape)
|
||||
# <class 'list'> (512, 683, 3)
|
||||
print(type(results['predictions']), results['predictions'][0].shape)
|
||||
# <class 'list'> (512, 683)
|
||||
|
||||
results = inferencer(images, return_datasamples=True)
|
||||
# <class 'list'>
|
||||
print(type(results[0]))
|
||||
# <class 'mmseg.structures.seg_data_sample.SegDataSample'>
|
||||
```
|
||||
|
||||
### 初始化
|
||||
|
||||
`MMSegInferencer` 必须使用 `model` 初始化,该 `model` 可以是模型名称或一个 `Config`,甚至可以是配置文件的路径。
|
||||
模型名称可以在模型的元文件(configs/xxx/metafile.yaml)中找到,比如 maskformer 的一个模型名称是 `maskformer_r50-d32_8xb2-160k_ade20k-512x512`,如果输入模型名称,模型的权重将自动下载。以下是其他输入参数:
|
||||
|
||||
- weights(str,可选)- 权重的路径。如果未指定,并且模型是元文件中的模型名称,则权重将从元文件加载。默认为 None。
|
||||
- classes(list,可选)- 输入类别用于结果渲染,由于分割模型的预测结构是标签索引的分割图,`classes` 是一个相应的标签索引的类别列表。若 classes 没有定义,可视化工具将默认使用 `cityscapes` 的类别。默认为 None。
|
||||
- palette(list,可选)- 输入调色盘用于结果渲染,它是对应分类的配色列表。若 palette 没有定义,可视化工具将默认使用 `cityscapes` 的调色盘。默认为 None。
|
||||
- dataset_name(str,可选)- [数据集名称或别名](https://github.com/open-mmlab/mmsegmentation/blob/main/mmseg/utils/class_names.py#L302-L317),可视化工具将使用数据集的元信息,如类别和配色,但 `classes` 和 `palette` 具有更高的优先级。默认为 None。
|
||||
- device(str,可选)- 运行推理的设备。如果无,则会自动使用可用的设备。默认为 None。
|
||||
- scope(str,可选)- 模型的作用域。默认为 'mmseg'。
|
||||
|
||||
### 可视化预测结果
|
||||
|
||||
`MMSegInferencer` 有4个用于可视化预测的参数,您可以在初始化推理器时使用它们:
|
||||
|
||||
- show(bool)- 是否弹出窗口显示图像。默认为 False。
|
||||
- wait_time(float)- 显示的间隔。默认值为 0。
|
||||
- img_out_dir(str)- `out_dir` 的子目录,用于保存渲染有色分割掩膜,因此如果要保存预测掩膜,则必须定义 `out_dir`。默认为 `vis`。
|
||||
- opacity(int,float)- 分割掩膜的透明度。默认值为 0.8。
|
||||
|
||||
这些参数的示例请参考[基本使用](#基本使用)
|
||||
|
||||
### 模型列表
|
||||
|
||||
在 MMSegmentation 中有一个非常容易列出所有模型名称的方法
|
||||
|
||||
```
|
||||
>>> from mmseg.apis import MMSegInferencer
|
||||
# models 是一个模型名称列表,它们将自动打印
|
||||
>>> models = MMSegInferencer.list_models('mmseg')
|
||||
```
|
||||
|
||||
## 推理 API
|
||||
|
||||
### mmseg.apis.init_model
|
||||
|
||||
从配置文件初始化一个分割器。
|
||||
|
||||
参数:
|
||||
|
||||
- config(str,`Path` 或 `mmengine.Config`)- 配置文件路径或配置对象。
|
||||
- checkpoint(str,可选)- 权重路径。如果为 None,则模型将不会加载任何权重。
|
||||
- device(str,可选)- CPU/CUDA 设备选项。默认为 'cuda:0'。
|
||||
- cfg_options(dict,可选)- 用于覆盖所用配置中的某些设置的选项。
|
||||
|
||||
返回值:
|
||||
|
||||
- nn.Module:构建好的分割器。
|
||||
|
||||
示例:
|
||||
|
||||
```python
|
||||
from mmseg.apis import init_model
|
||||
|
||||
config_path = 'configs/pspnet/pspnet_r50-d8_4xb2-40k_cityscapes-512x1024.py'
|
||||
checkpoint_path = 'checkpoints/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth'
|
||||
|
||||
# 初始化不带权重的模型
|
||||
model = init_model(config_path)
|
||||
|
||||
# 初始化模型并加载权重
|
||||
model = init_model(config_path, checkpoint_path)
|
||||
|
||||
# 在 CPU 上的初始化模型并加载权重
|
||||
model = init_model(config_path, checkpoint_path, 'cpu')
|
||||
```
|
||||
|
||||
### mmseg.apis.inference_model
|
||||
|
||||
使用分割器推理图像。
|
||||
|
||||
参数:
|
||||
|
||||
- model(nn.Module)- 加载的分割器
|
||||
- imgs(str,np.ndarray 或 list\[str/np.ndarray\])- 图像文件或加载的图像
|
||||
|
||||
返回值:
|
||||
|
||||
- `SegDataSample` 或 list\[`SegDataSample`\]:如果 imgs 是列表或元组,则返回相同长度的列表类型结果,否则直接返回分割结果。
|
||||
|
||||
**注意:** [SegDataSample](https://github.com/open-mmlab/mmsegmentation/blob/1.x/mmseg/structures/seg_data_sample.py) 是 MMSegmentation 的数据结构接口,用作不同组件之间的接口。`SegDataSample` 实现抽象数据元素 `mmengine.structures.BaseDataElement`,请参阅 [MMEngine](https://github.com/open-mmlab/mmengine) 中的数据元素[文档](https://mmengine.readthedocs.io/zh_CN/latest/advanced_tutorials/data_element.html)了解更多信息。
|
||||
|
||||
`SegDataSample` 中的参数分为几个部分:
|
||||
|
||||
- `gt_sem_seg`(`PixelData`)- 语义分割的标注。
|
||||
- `pred_sem_seg`(`PixelData`)- 语义分割的预测。
|
||||
- `seg_logits`(`PixelData`)- 模型最后一层的输出结果。
|
||||
|
||||
**注意:** [PixelData](https://github.com/open-mmlab/mmengine/blob/main/mmengine/structures/pixel_data.py) 是像素级标注或预测的数据结构,请参阅 [MMEngine](https://github.com/open-mmlab/mmengine) 中的 PixelData [文档](https://mmengine.readthedocs.io/en/latest/advanced_tutorials/data_element.html)了解更多信息。
|
||||
|
||||
示例:
|
||||
|
||||
```python
|
||||
from mmseg.apis import init_model, inference_model
|
||||
|
||||
config_path = 'configs/pspnet/pspnet_r50-d8_4xb2-40k_cityscapes-512x1024.py'
|
||||
checkpoint_path = 'checkpoints/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth'
|
||||
img_path = 'demo/demo.png'
|
||||
|
||||
|
||||
model = init_model(config_path, checkpoint_path)
|
||||
result = inference_model(model, img_path)
|
||||
```
|
||||
|
||||
### mmseg.apis.show_result_pyplot
|
||||
|
||||
在图像上可视化分割结果。
|
||||
|
||||
参数:
|
||||
|
||||
- model(nn.Module)- 加载的分割器。
|
||||
- img(str 或 np.ndarray)- 图像文件名或加载的图像。
|
||||
- result(`SegDataSample`)- SegDataSample 预测结果。
|
||||
- opacity(float)- 绘制分割图的不透明度。默认值为 `0.5`,必须在 `(0,1]` 范围内。
|
||||
- title(str)- pyplot 图的标题。默认值为 ''。
|
||||
- draw_gt(bool)- 是否绘制 GT SegDataSample。默认为 `True`。
|
||||
- draw_pred(draws_pred)- 是否绘制预测 SegDataSample。默认为 `True`。
|
||||
- wait_time(float)- 显示的间隔,0 是表示“无限”的特殊值。默认为 `0`。
|
||||
- show(bool)- 是否展示绘制的图像。默认为 `True`。
|
||||
- save_dir(str,可选)- 为所有存储后端保存的文件路径。如果为 `None`,则后端存储将不会保存任何数据。
|
||||
- out_file(str,可选)- 输出文件的路径。默认为 `None`。
|
||||
|
||||
返回值:
|
||||
|
||||
- np.ndarray:通道为 RGB 的绘制图像。
|
||||
|
||||
示例:
|
||||
|
||||
```python
|
||||
from mmseg.apis import init_model, inference_model, show_result_pyplot
|
||||
|
||||
config_path = 'configs/pspnet/pspnet_r50-d8_4xb2-40k_cityscapes-512x1024.py'
|
||||
checkpoint_path = 'checkpoints/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth'
|
||||
img_path = 'demo/demo.png'
|
||||
|
||||
|
||||
# 从配置文件和权重文件构建模型
|
||||
model = init_model(config_path, checkpoint_path, device='cuda:0')
|
||||
|
||||
# 推理给定图像
|
||||
result = inference_model(model, img_path)
|
||||
|
||||
# 展示分割结果
|
||||
vis_image = show_result_pyplot(model, img_path, result)
|
||||
|
||||
# 保存可视化结果,输出图像将在 `workdirs/result.png` 路径下找到
|
||||
vis_iamge = show_result_pyplot(model, img_path, result, out_file='work_dirs/result.png')
|
||||
|
||||
# 修改展示图像的时间,注意 0 是表示“无限”的特殊值
|
||||
vis_image = show_result_pyplot(model, img_path, result, wait_time=5)
|
||||
```
|
||||
|
||||
**注意:** 如果当前设备没有图形用户界面,建议将 `show` 设置为 `False`,并指定 `out_file` 或 `save_dir` 来保存结果。如果您想在窗口上显示结果,则不需要特殊设置。
|
||||
317
Seg_All_In_One_MMSeg/docs/zh_cn/user_guides/4_train_test.md
Normal file
317
Seg_All_In_One_MMSeg/docs/zh_cn/user_guides/4_train_test.md
Normal file
@@ -0,0 +1,317 @@
|
||||
# 教程4:使用现有模型进行训练和测试
|
||||
|
||||
MMSegmentation 支持在多种设备上训练和测试模型。如下文,具体方式分别为单GPU、分布式以及计算集群的训练和测试。通过本教程,您将知晓如何用 MMSegmentation 提供的脚本进行训练和测试。
|
||||
|
||||
## 在单GPU上训练和测试
|
||||
|
||||
### 在单GPU上训练
|
||||
|
||||
`tools/train.py` 文件提供了在单GPU上部署训练任务的方法。
|
||||
|
||||
基础用法如下:
|
||||
|
||||
```shell
|
||||
python tools/train.py ${配置文件} [可选参数]
|
||||
```
|
||||
|
||||
- `--work-dir ${工作路径}`: 重新指定工作路径
|
||||
- `--amp`: 使用自动混合精度计算
|
||||
- `--resume`: 从工作路径中保存的最新检查点文件(checkpoint)恢复训练
|
||||
- `--cfg-options ${需更覆盖的配置}`: 覆盖已载入的配置中的部分设置,并且 以 xxx=yyy 格式的键值对 将被合并到配置文件中。
|
||||
比如: '--cfg-option model.encoder.in_channels=6', 更多细节请看[指导](./1_config.md#Modify-config-through-script-arguments)。
|
||||
|
||||
下面是对于多GPU测试的可选参数:
|
||||
|
||||
- `--launcher`: 执行器的启动方式。允许选择的参数值有 `none`, `pytorch`, `slurm`, `mpi`。特别的,如果设置为none,测试将非分布式模式下进行。
|
||||
- `--local_rank`: 分布式中进程的序号。如果没有指定,默认设置为0。
|
||||
|
||||
**注意:** 命令行参数 `--resume` 和在配置文件中的参数 `load_from` 的不同之处:
|
||||
|
||||
`--resume` 只决定是否继续使用工作路径中最新的检查点,它常常用于恢复被意外打断的训练。
|
||||
|
||||
`load_from` 会明确指定被载入的检查点文件,且训练迭代器将从0开始,通常用于微调模型。
|
||||
|
||||
如果您希望从指定的检查点上恢复训练您可以使用:
|
||||
|
||||
```python
|
||||
python tools/train.py ${配置文件} --resume --cfg-options load_from=${检查点}
|
||||
```
|
||||
|
||||
**在 CPU 上训练**: 如果机器没有 GPU,则在 CPU 上训练的过程是与单GPU训练一致的。如果机器有 GPU 但是不希望使用它们,我们只需要在训练前通过以下方式关闭 GPU 训练功能。
|
||||
|
||||
```shell
|
||||
export CUDA_VISIBLE_DEVICES=-1
|
||||
```
|
||||
|
||||
然后运行[上方](###在单GPU上训练)脚本。
|
||||
|
||||
### 在单GPU上测试
|
||||
|
||||
`tools/test.py` 文件提供了在单 GPU 上启动测试任务的方法。
|
||||
|
||||
基础用法如下:
|
||||
|
||||
```shell
|
||||
python tools/test.py ${配置文件} ${模型权重文件} [可选参数]
|
||||
```
|
||||
|
||||
这个工具有几个可选参数,包括:
|
||||
|
||||
- `--work-dir`: 如果指定了路径,结果会保存在该路径下。如果没有指定则会保存在 `work_dirs/{配置文件名}` 路径下.
|
||||
- `--show`: 当 `--show-dir` 没有指定时,可以使用该参数,在程序运行过程中显示预测结果。
|
||||
- `--show-dir`: 绘制了分割掩膜图片的存储文件夹。如果指定了该参数,则可视化的分割掩膜将被保存到 `work_dir/timestamp/{指定路径}`.
|
||||
- `--wait-time`: 多次可视化结果的时间间隔。当 `--show` 为激活状态时发挥作用。默认为2。
|
||||
- `--cfg-options`: 如果被具体指定,以 xxx=yyy 形式的键值对将被合并入配置文件中。
|
||||
|
||||
**在CPU上测试**: 如果机器没有GPU,则在CPU上训练的过程是与单GPU训练一致的。如果机器有GPU,但是不希望使用它们,我们只需要在训练前通过以下方式关闭GPUs训练功能。
|
||||
|
||||
```shell
|
||||
export CUDA_VISIBLE_DEVICES=-1
|
||||
```
|
||||
|
||||
然后运行[上方](###在单GPU上测试)脚本。
|
||||
|
||||
## 多GPU、多机器上训练和测试
|
||||
|
||||
### 在多GPU上训练
|
||||
|
||||
OpenMMLab2.0 通过 `MMDistributedDataParallel`实现 **分布式** 训练。
|
||||
|
||||
`tools/dist_train.sh` 文件提供了在在多GPU上部署训练任务的方法。
|
||||
|
||||
基础用法如下:
|
||||
|
||||
```shell
|
||||
sh tools/dist_train.sh ${配置文件} ${GPU数量} [可选参数]
|
||||
```
|
||||
|
||||
可选参数与[上方](###在单GPU上训练)相同并且还增加了可以指定gpu数量的参数。
|
||||
|
||||
示例:
|
||||
|
||||
```shell
|
||||
# 模型训练的检查点和日志保存在这个路径下: WORK_DIR=work_dirs/pspnet_r50-d8_4xb4-80k_ade20k-512x512/
|
||||
# 如果工作路径没有被设定,它将会被自动生成。
|
||||
sh tools/dist_train.sh configs/pspnet/pspnet_r50-d8_4xb4-80k_ade20k-512x512.py 8 --work-dir work_dirs/pspnet_r50-d8_4xb4-80k_ade20k-512x512
|
||||
```
|
||||
|
||||
**注意**: 在训练过程中,检查点和日志保存在`work_dirs/`下的配置文件的相同文件夹结构下。
|
||||
不推荐自定义的工作路径,因为评估脚本依赖于源自配置文件名的路径。如果您希望将权重保存在其他地方,请用符号链接,例如:
|
||||
|
||||
```shell
|
||||
ln -s ${您的工作路径} ${MMSEG 路径}/work_dirs
|
||||
```
|
||||
|
||||
### 在多GPU上测试
|
||||
|
||||
`tools/dist_test.sh` 文件提供了在多GPU上启动测试任务的方法。
|
||||
|
||||
基础用法如下:
|
||||
|
||||
```shell
|
||||
sh tools/dist_test.sh ${配置文件} ${检查点文件} ${GPU数量} [可选参数]
|
||||
```
|
||||
|
||||
可选参数与[上方](###在单GPU上测试)相同并且增加了可以指定 gpu 数量的参数。
|
||||
|
||||
示例:
|
||||
|
||||
```shell
|
||||
./tools/dist_test.sh configs/pspnet/pspnet_r50-d8_4xb2-40k_cityscapes-512x1024.py \
|
||||
checkpoints/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth 4
|
||||
```
|
||||
|
||||
### 在单台机器上启动多个任务
|
||||
|
||||
如果您在单个机器上运行多个任务,比如:在8卡GPU的单个机器上执行2个各需4卡GPU的训练任务,您需要为每个任务具体指定不同端口(默认29500),从而避免通讯冲突。否则,会有报错信息——`RuntimeError: Address already in use`(运行错误:地址被使用)。
|
||||
|
||||
如果您使用 `dist_train.sh` 来启动训练任务,您可以通过环境变量 `PORT` 设置端口。
|
||||
|
||||
```shell
|
||||
CUDA_VISIBLE_DEVICES=0,1,2,3 PORT=29500 sh tools/dist_train.sh ${配置文件} 4
|
||||
CUDA_VISIBLE_DEVICES=4,5,6,7 PORT=29501 sh tools/dist_train.sh ${配置文件} 4
|
||||
```
|
||||
|
||||
### 在多台机器上训练
|
||||
|
||||
MMSegmentation 的分布式训练依赖 `torch.distributed`。
|
||||
因此, 可以通过 PyTorch 的 [运行工具 launch utility](https://pytorch.org/docs/stable/distributed.html#launch-utility) 来进行分布式训练。
|
||||
|
||||
如果您启动的多台机器简单地通过以太网连接,您可以直接运行下方命令:
|
||||
|
||||
在第一个机器上:
|
||||
|
||||
```shell
|
||||
NNODES=2 NODE_RANK=0 PORT=${主节点端口} MASTER_ADDR=${主节点地址} sh tools/dist_train.sh ${配置文件} ${GPUS}
|
||||
```
|
||||
|
||||
在第二个机器上:
|
||||
|
||||
```shell
|
||||
NNODES=2 NODE_RANK=1 PORT=${主节点端口} MASTER_ADDR=${主节点地址} sh tools/dist_train.sh ${配置文件} ${GPUS}
|
||||
```
|
||||
|
||||
通常,如果您没有使用像无限带宽一类的高速网络,这个会过程比较慢。
|
||||
|
||||
## 通过 Slurm 管理任务
|
||||
|
||||
[Slurm](https://slurm.schedmd.com/) 是一个很好的计算集群作业调度系统。
|
||||
|
||||
### 通过 Slurm 在集群上训练
|
||||
|
||||
在一个由Slurm管理的集群上,您可以使用`slurm_train.sh`来启动训练任务。它同时支持单节点和多节点的训练。
|
||||
|
||||
基础用法如下:
|
||||
|
||||
```shell
|
||||
[GPUS=${GPUS}] sh tools/slurm_train.sh ${分区} ${任务名} ${配置文件} [可选参数]
|
||||
```
|
||||
|
||||
下方是一个通过名为 `dev` 的 Slurm 分区,调用4个 GPU 来训练 PSPNet,并设置工作路径为共享文件系统。
|
||||
|
||||
```shell
|
||||
GPUS=4 sh tools/slurm_train.sh dev pspnet configs/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes.py --work-dir work_dir/pspnet
|
||||
```
|
||||
|
||||
您可以检查 [源码](../../../tools/slurm_train.sh) 来查看全部的参数和环境变量。
|
||||
|
||||
### 通过 Slurm 在集群上测试
|
||||
|
||||
与训练任务相同, MMSegmentation 提供 `slurm_test.sh` 文件来启动测试任务。
|
||||
|
||||
基础用法如下:
|
||||
|
||||
```shell
|
||||
[GPUS=${GPUS}] sh tools/slurm_test.sh ${分区} ${任务名} ${配置文件} ${检查点文件} [可选参数]
|
||||
```
|
||||
|
||||
您可以通过 [源码](../../../tools/slurm_test.sh) 来查看全部的参数和环境变量。
|
||||
|
||||
**注意:** 使用 Slurm 时,需要设置端口,可从以下方式中选取一种。
|
||||
|
||||
1. 我们更推荐的通过`--cfg-options`设置端口,因为这不会改变原始配置:
|
||||
|
||||
```shell
|
||||
GPUS=4 GPUS_PER_NODE=4 sh tools/slurm_train.sh ${分区} ${任务名} config1.py ${工作路径} --cfg-options env_cfg.dist_cfg.port=29500
|
||||
GPUS=4 GPUS_PER_NODE=4 sh tools/slurm_train.sh ${任务名} ${工作路径} config2.py ${工作路径} --cfg-options env_cfg.dist_cfg.port=29501
|
||||
```
|
||||
|
||||
2. 通过修改配置文件设置不同的通讯端口:
|
||||
|
||||
在 `config1.py`中:
|
||||
|
||||
```python
|
||||
enf_cfg = dict(dist_cfg=dict(backend='nccl', port=29500))
|
||||
```
|
||||
|
||||
在 `config2.py`中:
|
||||
|
||||
```python
|
||||
enf_cfg = dict(dist_cfg=dict(backend='nccl', port=29501))
|
||||
```
|
||||
|
||||
然后您可以通过 config1.py 和 config2.py 同时启动两个任务:
|
||||
|
||||
```shell
|
||||
CUDA_VISIBLE_DEVICES=0,1,2,3 GPUS=4 sh tools/slurm_train.sh ${分区} ${任务名} config1.py ${工作路径}
|
||||
CUDA_VISIBLE_DEVICES=4,5,6,7 GPUS=4 sh tools/slurm_train.sh ${分区} ${任务名} config2.py ${工作路径}
|
||||
```
|
||||
|
||||
3. 在命令行中通过环境变量 `MASTER_PORT` 设置端口 :
|
||||
|
||||
```shell
|
||||
CUDA_VISIBLE_DEVICES=0,1,2,3 GPUS=4 MASTER_PORT=29500 sh tools/slurm_train.sh ${分区} ${任务名} config1.py ${工作路径}
|
||||
CUDA_VISIBLE_DEVICES=4,5,6,7 GPUS=4 MASTER_PORT=29501 sh tools/slurm_train.sh ${分区} ${任务名} config2.py ${工作路径}
|
||||
```
|
||||
|
||||
## 测试并保存分割结果
|
||||
|
||||
### 基础使用
|
||||
|
||||
当需要保存测试输出的分割结果,用 `--out` 指定分割结果输出路径
|
||||
|
||||
```shell
|
||||
python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} --out ${OUTPUT_DIR}
|
||||
```
|
||||
|
||||
以保存模型 `fcn_r50-d8_4xb4-80k_ade20k-512x512` 在 ADE20K 验证数据集上的结果为例:
|
||||
|
||||
```shell
|
||||
python tools/test.py configs/fcn/fcn_r50-d8_4xb4-80k_ade20k-512x512.py ckpt/fcn_r50-d8_512x512_80k_ade20k_20200614_144016-f8ac5082.pth --out work_dirs/format_results
|
||||
```
|
||||
|
||||
或者通过配置文件定义 `output_dir`。例如在 `configs/fcn/fcn_r50-d8_4xb4-80k_ade20k-512x512.py` 添加 `test_evaluator` 定义:
|
||||
|
||||
```python
|
||||
test_evaluator = dict(type='IoUMetric', iou_metrics=['mIoU'], output_dir='work_dirs/format_results')
|
||||
```
|
||||
|
||||
然后执行相同功能的命令不需要再使用 `--out`:
|
||||
|
||||
```shell
|
||||
python tools/test.py configs/fcn/fcn_r50-d8_4xb4-80k_ade20k-512x512.py ckpt/fcn_r50-d8_512x512_80k_ade20k_20200614_144016-f8ac5082.pth
|
||||
```
|
||||
|
||||
当测试的数据集没有提供标注,评测时没有真值可以参与计算,因此需要设置 `format_only=True`,
|
||||
同时需要修改 `test_dataloader`,由于没有标注,我们需要在数据增强变换中删掉 `dict(type='LoadAnnotations')`,以下是一个配置示例:
|
||||
|
||||
```python
|
||||
test_evaluator = dict(
|
||||
type='IoUMetric',
|
||||
iou_metrics=['mIoU'],
|
||||
format_only=True,
|
||||
output_dir='work_dirs/format_results')
|
||||
test_dataloader = dict(
|
||||
batch_size=1,
|
||||
num_workers=4,
|
||||
persistent_workers=True,
|
||||
sampler=dict(type='DefaultSampler', shuffle=False),
|
||||
dataset=dict(
|
||||
type = 'ADE20KDataset'
|
||||
data_root='data/ade/release_test',
|
||||
data_prefix=dict(img_path='testing'),
|
||||
# 测试数据变换中没有加载标注
|
||||
pipeline=[
|
||||
dict(type='LoadImageFromFile'),
|
||||
dict(type='Resize', scale=(2048, 512), keep_ratio=True),
|
||||
dict(type='PackSegInputs')
|
||||
]))
|
||||
```
|
||||
|
||||
然后执行测试命令:
|
||||
|
||||
```shell
|
||||
python tools/test.py configs/fcn/fcn_r50-d8_4xb4-80k_ade20k-512x512.py ckpt/fcn_r50-d8_512x512_80k_ade20k_20200614_144016-f8ac5082.pth
|
||||
```
|
||||
|
||||
### 测试 Cityscapes 数据集并保存输出分割结果
|
||||
|
||||
推荐使用 `CityscapesMetric` 来保存模型在 Cityscapes 数据集上的测试结果,以下是一个配置示例:
|
||||
|
||||
```python
|
||||
test_evaluator = dict(
|
||||
type='CityscapesMetric',
|
||||
format_only=True,
|
||||
keep_results=True,
|
||||
output_dir='work_dirs/format_results')
|
||||
test_dataloader = dict(
|
||||
batch_size=1,
|
||||
num_workers=4,
|
||||
persistent_workers=True,
|
||||
sampler=dict(type='DefaultSampler', shuffle=False),
|
||||
dataset=dict(
|
||||
type='CityscapesDataset',
|
||||
data_root='data/cityscapes/',
|
||||
data_prefix=dict(img_path='leftImg8bit/test'),
|
||||
pipeline=[
|
||||
dict(type='LoadImageFromFile'),
|
||||
dict(type='Resize', scale=(2048, 1024), keep_ratio=True),
|
||||
dict(type='PackSegInputs')
|
||||
]))
|
||||
```
|
||||
|
||||
然后执行相同的命令,例如:
|
||||
|
||||
```shell
|
||||
python tools/test.py configs/fcn/fcn_r18-d8_4xb2-80k_cityscapes-512x1024.py ckpt/fcn_r18-d8_512x1024_80k_cityscapes_20201225_021327-6c50f8b4.pth
|
||||
```
|
||||
243
Seg_All_In_One_MMSeg/docs/zh_cn/user_guides/5_deployment.md
Normal file
243
Seg_All_In_One_MMSeg/docs/zh_cn/user_guides/5_deployment.md
Normal file
@@ -0,0 +1,243 @@
|
||||
# 教程5:模型部署
|
||||
|
||||
# MMSegmentation 模型部署
|
||||
|
||||
- [教程5:模型部署](#教程5模型部署)
|
||||
- [MMSegmentation 模型部署](#mmsegmentation-模型部署)
|
||||
- [安装](#安装)
|
||||
- [安装 mmseg](#安装-mmseg)
|
||||
- [安装 mmdeploy](#安装-mmdeploy)
|
||||
- [模型转换](#模型转换)
|
||||
- [模型规范](#模型规范)
|
||||
- [模型推理](#模型推理)
|
||||
- [后端模型推理](#后端模型推理)
|
||||
- [SDK 模型推理](#sdk-模型推理)
|
||||
- [模型支持列表](#模型支持列表)
|
||||
- [注意事项](#注意事项)
|
||||
|
||||
______________________________________________________________________
|
||||
|
||||
[MMSegmentation](https://github.com/open-mmlab/mmsegmentation/tree/main) 又称`mmseg`,是一个基于 PyTorch 的开源对象分割工具箱。它是 [OpenMMLab](https://openmmlab.com/) 项目的一部分。
|
||||
|
||||
## 安装
|
||||
|
||||
### 安装 mmseg
|
||||
|
||||
请参考[官网安装指南](https://mmsegmentation.readthedocs.io/en/latest/get_started.html)。
|
||||
|
||||
### 安装 mmdeploy
|
||||
|
||||
mmdeploy 有以下几种安装方式:
|
||||
|
||||
**方式一:** 安装预编译包
|
||||
|
||||
请参考[安装概述](https://mmdeploy.readthedocs.io/zh_CN/latest/get_started.html#mmdeploy)
|
||||
|
||||
**方式二:** 一键式脚本安装
|
||||
|
||||
如果部署平台是 **Ubuntu 18.04 及以上版本**, 请参考[脚本安装说明](../01-how-to-build/build_from_script.md),完成安装过程。
|
||||
比如,以下命令可以安装 mmdeploy 以及配套的推理引擎——`ONNX Runtime`.
|
||||
|
||||
```shell
|
||||
git clone --recursive -b main https://github.com/open-mmlab/mmdeploy.git
|
||||
cd mmdeploy
|
||||
python3 tools/scripts/build_ubuntu_x64_ort.py $(nproc)
|
||||
export PYTHONPATH=$(pwd)/build/lib:$PYTHONPATH
|
||||
export LD_LIBRARY_PATH=$(pwd)/../mmdeploy-dep/onnxruntime-linux-x64-1.8.1/lib/:$LD_LIBRARY_PATH
|
||||
```
|
||||
|
||||
**说明**:
|
||||
|
||||
- 把 `$(pwd)/build/lib` 添加到 `PYTHONPATH`,目的是为了加载 mmdeploy SDK python 包 `mmdeploy_runtime`,在章节 [SDK模型推理](#sdk模型推理)中讲述其用法。
|
||||
- 在[使用 ONNX Runtime推理后端模型](#后端模型推理)时,需要加载自定义算子库,需要把 ONNX Runtime 库的路径加入环境变量 `LD_LIBRARY_PATH`中。
|
||||
|
||||
**方式三:** 源码安装
|
||||
|
||||
在方式一、二都满足不了的情况下,请参考[源码安装说明](../01-how-to-build/build_from_source.md) 安装 mmdeploy 以及所需推理引擎。
|
||||
|
||||
## 模型转换
|
||||
|
||||
你可以使用 [tools/deploy.py](https://github.com/open-mmlab/mmdeploy/tree/main/tools/deploy.py) 把 mmseg 模型一键式转换为推理后端模型。
|
||||
该工具的详细使用说明请参考[这里](https://github.com/open-mmlab/mmdeploy/tree/main/docs/en/02-how-to-run/convert_model.md#usage).
|
||||
|
||||
以下,我们将演示如何把 `unet` 转换为 onnx 模型。
|
||||
|
||||
```shell
|
||||
cd mmdeploy
|
||||
|
||||
# download unet model from mmseg model zoo
|
||||
mim download mmsegmentation --config unet-s5-d16_fcn_4xb4-160k_cityscapes-512x1024 --dest .
|
||||
|
||||
# convert mmseg model to onnxruntime model with dynamic shape
|
||||
python tools/deploy.py \
|
||||
configs/mmseg/segmentation_onnxruntime_dynamic.py \
|
||||
unet-s5-d16_fcn_4xb4-160k_cityscapes-512x1024.py \
|
||||
fcn_unet_s5-d16_4x4_512x1024_160k_cityscapes_20211210_145204-6860854e.pth \
|
||||
demo/resources/cityscapes.png \
|
||||
--work-dir mmdeploy_models/mmseg/ort \
|
||||
--device cpu \
|
||||
--show \
|
||||
--dump-info
|
||||
```
|
||||
|
||||
转换的关键之一是使用正确的配置文件。项目中已内置了各后端部署[配置文件](https://github.com/open-mmlab/mmdeploy/tree/main/configs/mmseg)。
|
||||
文件的命名模式是:
|
||||
|
||||
```
|
||||
segmentation_{backend}-{precision}_{static | dynamic}_{shape}.py
|
||||
```
|
||||
|
||||
其中:
|
||||
|
||||
- **{backend}:** 推理后端名称。比如,onnxruntime、tensorrt、pplnn、ncnn、openvino、coreml 等等
|
||||
- **{precision}:** 推理精度。比如,fp16、int8。不填表示 fp32
|
||||
- **{static | dynamic}:** 动态、静态 shape
|
||||
- **{shape}:** 模型输入的 shape 或者 shape 范围
|
||||
|
||||
在上例中,你也可以把 `unet` 转为其他后端模型。比如使用`segmentation_tensorrt-fp16_dynamic-512x1024-2048x2048.py`,把模型转为 tensorrt-fp16 模型。
|
||||
|
||||
```{tip}
|
||||
当转 tensorrt 模型时, --device 需要被设置为 "cuda"
|
||||
```
|
||||
|
||||
## 模型规范
|
||||
|
||||
在使用转换后的模型进行推理之前,有必要了解转换结果的结构。 它存放在 `--work-dir` 指定的路路径下。
|
||||
|
||||
上例中的`mmdeploy_models/mmseg/ort`,结构如下:
|
||||
|
||||
```
|
||||
mmdeploy_models/mmseg/ort
|
||||
├── deploy.json
|
||||
├── detail.json
|
||||
├── end2end.onnx
|
||||
└── pipeline.json
|
||||
```
|
||||
|
||||
重要的是:
|
||||
|
||||
- **end2end.onnx**: 推理引擎文件。可用 ONNX Runtime 推理
|
||||
- \***.json**: mmdeploy SDK 推理所需的 meta 信息
|
||||
|
||||
整个文件夹被定义为**mmdeploy SDK model**。换言之,**mmdeploy SDK model**既包括推理引擎,也包括推理 meta 信息。
|
||||
|
||||
## 模型推理
|
||||
|
||||
### 后端模型推理
|
||||
|
||||
以上述模型转换后的 `end2end.onnx` 为例,你可以使用如下代码进行推理:
|
||||
|
||||
```python
|
||||
from mmdeploy.apis.utils import build_task_processor
|
||||
from mmdeploy.utils import get_input_shape, load_config
|
||||
import torch
|
||||
|
||||
deploy_cfg = 'configs/mmseg/segmentation_onnxruntime_dynamic.py'
|
||||
model_cfg = './unet-s5-d16_fcn_4xb4-160k_cityscapes-512x1024.py'
|
||||
device = 'cpu'
|
||||
backend_model = ['./mmdeploy_models/mmseg/ort/end2end.onnx']
|
||||
image = './demo/resources/cityscapes.png'
|
||||
|
||||
# read deploy_cfg and model_cfg
|
||||
deploy_cfg, model_cfg = load_config(deploy_cfg, model_cfg)
|
||||
|
||||
# build task and backend model
|
||||
task_processor = build_task_processor(model_cfg, deploy_cfg, device)
|
||||
model = task_processor.build_backend_model(backend_model)
|
||||
|
||||
# process input image
|
||||
input_shape = get_input_shape(deploy_cfg)
|
||||
model_inputs, _ = task_processor.create_input(image, input_shape)
|
||||
|
||||
# do model inference
|
||||
with torch.no_grad():
|
||||
result = model.test_step(model_inputs)
|
||||
|
||||
# visualize results
|
||||
task_processor.visualize(
|
||||
image=image,
|
||||
model=model,
|
||||
result=result[0],
|
||||
window_name='visualize',
|
||||
output_file='./output_segmentation.png')
|
||||
```
|
||||
|
||||
### SDK 模型推理
|
||||
|
||||
你也可以参考如下代码,对 SDK model 进行推理:
|
||||
|
||||
```python
|
||||
from mmdeploy_runtime import Segmentor
|
||||
import cv2
|
||||
import numpy as np
|
||||
|
||||
img = cv2.imread('./demo/resources/cityscapes.png')
|
||||
|
||||
# create a classifier
|
||||
segmentor = Segmentor(model_path='./mmdeploy_models/mmseg/ort', device_name='cpu', device_id=0)
|
||||
# perform inference
|
||||
seg = segmentor(img)
|
||||
|
||||
# visualize inference result
|
||||
## random a palette with size 256x3
|
||||
palette = np.random.randint(0, 256, size=(256, 3))
|
||||
color_seg = np.zeros((seg.shape[0], seg.shape[1], 3), dtype=np.uint8)
|
||||
for label, color in enumerate(palette):
|
||||
color_seg[seg == label, :] = color
|
||||
# convert to BGR
|
||||
color_seg = color_seg[..., ::-1]
|
||||
img = img * 0.5 + color_seg * 0.5
|
||||
img = img.astype(np.uint8)
|
||||
cv2.imwrite('output_segmentation.png', img)
|
||||
```
|
||||
|
||||
除了python API,mmdeploy SDK 还提供了诸如 C、C++、C#、Java等多语言接口。
|
||||
你可以参考[样例](https://github.com/open-mmlab/mmdeploy/tree/main/demo)学习其他语言接口的使用方法。
|
||||
|
||||
## 模型支持列表
|
||||
|
||||
| Model | TorchScript | OnnxRuntime | TensorRT | ncnn | PPLNN | OpenVino |
|
||||
| :-------------------------------------------------------------------------------------------------------- | :---------: | :---------: | :------: | :--: | :---: | :------: |
|
||||
| [FCN](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/fcn) | Y | Y | Y | Y | Y | Y |
|
||||
| [PSPNet](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/pspnet)[\*](#static_shape) | Y | Y | Y | Y | Y | Y |
|
||||
| [DeepLabV3](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/deeplabv3) | Y | Y | Y | Y | Y | Y |
|
||||
| [DeepLabV3+](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/deeplabv3plus) | Y | Y | Y | Y | Y | Y |
|
||||
| [Fast-SCNN](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/fastscnn)[\*](#static_shape) | Y | Y | Y | N | Y | Y |
|
||||
| [UNet](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/unet) | Y | Y | Y | Y | Y | Y |
|
||||
| [ANN](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/ann)[\*](#static_shape) | Y | Y | Y | N | N | N |
|
||||
| [APCNet](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/apcnet) | Y | Y | Y | Y | N | N |
|
||||
| [BiSeNetV1](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/bisenetv1) | Y | Y | Y | Y | N | Y |
|
||||
| [BiSeNetV2](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/bisenetv2) | Y | Y | Y | Y | N | Y |
|
||||
| [CGNet](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/cgnet) | Y | Y | Y | Y | N | Y |
|
||||
| [DMNet](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/dmnet) | ? | Y | N | N | N | N |
|
||||
| [DNLNet](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/dnlnet) | ? | Y | Y | Y | N | Y |
|
||||
| [EMANet](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/emanet) | Y | Y | Y | N | N | Y |
|
||||
| [EncNet](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/encnet) | Y | Y | Y | N | N | Y |
|
||||
| [ERFNet](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/erfnet) | Y | Y | Y | Y | N | Y |
|
||||
| [FastFCN](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/fastfcn) | Y | Y | Y | Y | N | Y |
|
||||
| [GCNet](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/gcnet) | Y | Y | Y | N | N | N |
|
||||
| [ICNet](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/icnet)[\*](#static_shape) | Y | Y | Y | N | N | Y |
|
||||
| [ISANet](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/isanet)[\*](#static_shape) | N | Y | Y | N | N | Y |
|
||||
| [NonLocal Net](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/nonlocal_net) | ? | Y | Y | Y | N | Y |
|
||||
| [OCRNet](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/ocrnet) | Y | Y | Y | Y | N | Y |
|
||||
| [PointRend](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/point_rend)[\*](#static_shape) | Y | Y | Y | N | N | N |
|
||||
| [Semantic FPN](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/sem_fpn) | Y | Y | Y | Y | N | Y |
|
||||
| [STDC](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/stdc) | Y | Y | Y | Y | N | Y |
|
||||
| [UPerNet](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/upernet)[\*](#static_shape) | N | Y | Y | N | N | N |
|
||||
| [DANet](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/danet) | ? | Y | Y | N | N | Y |
|
||||
| [Segmenter](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/segmenter)[\*](#static_shape) | N | Y | Y | Y | N | Y |
|
||||
| [SegFormer](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/segformer)[\*](#static_shape) | ? | Y | Y | N | N | Y |
|
||||
| [SETR](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/setr) | ? | Y | N | N | N | Y |
|
||||
| [CCNet](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/ccnet) | ? | N | N | N | N | N |
|
||||
| [PSANet](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/psanet) | ? | N | N | N | N | N |
|
||||
| [DPT](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/dpt) | ? | N | N | N | N | N |
|
||||
|
||||
## 注意事项
|
||||
|
||||
- 所有 mmseg 模型仅支持 "whole" 推理模式。
|
||||
|
||||
- <i id=“static_shape”>PSPNet,Fast-SCNN</i> 仅支持静态输入,因为多数推理框架的 [nn.AdaptiveAvgPool2d](https://github.com/open-mmlab/mmsegmentation/blob/0c87f7a0c9099844eff8e90fa3db5b0d0ca02fee/mmseg/models/decode_heads/psp_head.py#L38) 不支持动态输入。
|
||||
|
||||
- 对于仅支持静态形状的模型,应使用静态形状的部署配置文件,例如 `configs/mmseg/segmentation_tensorrt_static-1024x2048.py`
|
||||
|
||||
- 对于喜欢部署模型生成概率特征图的用户,将 `codebase_config = dict(with_argmax=False)` 放在部署配置中就足够了。
|
||||
372
Seg_All_In_One_MMSeg/docs/zh_cn/user_guides/deploy_jetson.md
Normal file
372
Seg_All_In_One_MMSeg/docs/zh_cn/user_guides/deploy_jetson.md
Normal file
@@ -0,0 +1,372 @@
|
||||
# 将 MMSeg 模型调优及部署到 NVIDIA Jetson 平台教程
|
||||
|
||||
- 请先查阅[MMSegmentation 模型部署](https://github.com/open-mmlab/mmsegmentation/blob/main/docs/zh_cn/user_guides/5_deployment.md)文档。
|
||||
- **本教程所用 mmsegmentation 版本: v1.1.2**
|
||||
- **本教程所用 NVIDIA Jetson 设备: NVIDIA Jetson AGX Orin 64G**
|
||||
|
||||
<div align="center">
|
||||
<img src="https://github.com/AI-Tianlong/Useful-Tools/assets/50650583/b5466cfd-71a9-4e06-9823-c253a97d57b5" alt="Smiley face" width="50%">
|
||||
</div>
|
||||
|
||||
## 1 配置 [mmsegmentation](https://github.com/open-mmlab/mmsegmentation)
|
||||
|
||||
- 根据[安装和验证](https://github.com/open-mmlab/mmsegmentation/blob/main/docs/zh_cn/get_started.md)文档,完成开发 [mmsegmentation](https://github.com/open-mmlab/mmsegmentation) 所需的 [`pytorch`](https://pytorch.org/get-started/locally/)、[`mmcv`](https://github.com/open-mmlab/mmcv)、[`mmengine`](https://github.com/open-mmlab/mmengine) 等环境依赖安装。
|
||||
- 从 GitHub 使用 git clone 命令完成 [mmsegmentation](https://github.com/open-mmlab/mmsegmentation) 下载。网络不好的同学,可通过 [MMSeg GitHub](https://github.com/open-mmlab/mmsegmentation) 页面进行 zip 的下载。
|
||||
```bash
|
||||
git clone https://github.com/open-mmlab/mmsegmentation.git
|
||||
```
|
||||
- 使用 `pip install -v -e.` 命令动态安装 mmsegmentation 。
|
||||
```bash
|
||||
cd mmsegmentation
|
||||
pip install -v -e .
|
||||
```
|
||||
提示成功安装后,可通过 `pip list` 命令查看到 mmsegmentation 已通过本地安装方式安装到了您的环境中。
|
||||

|
||||
|
||||
## 2 准备您的数据集
|
||||
|
||||
- 本教程使用遥感图像语义分割数据集 [potsdam](https://github.com/open-mmlab/mmsegmentation/blob/main/docs/zh_cn/user_guides/2_dataset_prepare.md#isprs-potsdam) 作为示例。
|
||||
- 根据 [potsdam 数据准备](https://github.com/open-mmlab/mmsegmentation/blob/main/docs/zh_cn/user_guides/2_dataset_prepare.md#isprs-potsdam)文档,进行数据集下载及 MMSeg 格式的准备。
|
||||
- 数据集介绍: potsdam 数据集是以德国一个典型的历史城市 Potsdam 命名的,该城市有着大建筑群、狭窄的街道和密集的建筑结构。 potsdam 数据集包含 38 幅 6000x6000 像素的图像,空间分辨率为 5cm,数据集的示例如下图:
|
||||

|
||||
|
||||
## 3 从 config 页面下载模型的 pth 权重文件
|
||||
|
||||
这里以 [`deeplabv3plus_r101-d8_4xb4-80k_potsdam-512x512.py`](../../configs/deeplabv3plus/deeplabv3plus_r101-d8_4xb4-80k_potsdam-512x512.py) 配置文件举例,在 [configs](https://github.com/open-mmlab/mmsegmentation/tree/main/configs/deeplabv3plus#potsdam) 页面下载权重文件,
|
||||

|
||||
|
||||
## 4 通过 [OpenMMLab deployee](https://platform.openmmlab.com/deploee) 以交互式方式进行模型转换及测速
|
||||
|
||||
### 4.1 模型转换
|
||||
|
||||
在该部分中,[OpenMMLab 官网](https://platform.openmmlab.com/deploee)提供了模型转换及模型测速的交互界面,无需任何代码,即可通过选择对应选项完成模型 ONNX 格式`xxxx.onnx` 和 TensorRT `.engine`格式的转换。
|
||||
如您的自定义 config 文件中有相对引用关系,如:
|
||||
|
||||
```python
|
||||
# xxxx.py
|
||||
_base_ = [
|
||||
'../_base_/models/deeplabv3plus_r50-d8.py',
|
||||
'../_base_/datasets/potsdam.py',
|
||||
'../_base_/default_runtime.py',
|
||||
'../_base_/schedules/schedule_80k.py'
|
||||
]
|
||||
```
|
||||
|
||||
您可以使用以下代码消除相对引用关系,以生成完整的 config 文件。
|
||||
|
||||
```python
|
||||
import mmengine
|
||||
|
||||
mmengine.Config.fromfile("configs/deeplabv3plus/deeplabv3plus_r101-d8_4xb4-80k_potsdam-512x512.py").dump("My_config.py")
|
||||
```
|
||||
|
||||
使用上述代码后,您能够看到,在`My_config.py`包含着完整的配置文件,无相对引用。这时,上传模型 config 至网页内对应处。
|
||||
|
||||
#### 创建转换任务
|
||||
|
||||
按照下图提示及自己的需求,创建转换任务并提交。
|
||||
|
||||
<div align="center">
|
||||
<img src="https://github.com/AI-Tianlong/Useful-Tools/assets/50650583/4918d2f9-d63c-480f-97f1-054529770cfd" alt="NVIDIA-Jetson" width="80%">
|
||||
</div>
|
||||
|
||||
### 4.2 模型测速
|
||||
|
||||
在完成模型转换后可通过**模型测速**界面,完成在真实设备上的模型测速。
|
||||
|
||||
#### 创建测速任务
|
||||
|
||||
<div align="center">
|
||||
<img src="https://github.com/AI-Tianlong/Useful-Tools/assets/50650583/27340556-c81a-4ce3-8560-2c4727d3355e" alt="NVIDIA-Jetson" width="100%">
|
||||
</div>
|
||||
|
||||
<div align="center">
|
||||
<img src="https://github.com/AI-Tianlong/Useful-Tools/assets/50650583/6f4fc3a9-ba9d-4829-8407-ed1470ba7bf3" alt="NVIDIA-Jetson" width="100%">
|
||||
</div>
|
||||
|
||||
测速完成后,可在页面生成完整的测速报告。[查看测速报告示例](https://openmmlab-deploee.oss-cn-shanghai.aliyuncs.com/tmp/profile_speed/4352f5.txt)
|
||||
|
||||
## 5 通过 OpenMMLab mmdeploy 以命令行将模型转换为ONNX格式
|
||||
|
||||
该部分可以通过 mmdeploy 库对 mmseg 训练好的模型进行推理格式的转换。这里给出一个示例,具体文档可见[ mmdeploy 模型转换文档](../../docs/zh_cn/user_guides/5_deployment.md)。
|
||||
|
||||
### 5.1 通过源码构建 mmdeploy 库
|
||||
|
||||
在您安装 mmsegmentation 库的虚拟环境下,通过 `git clone`命令从 GitHub 克隆 [mmdeploy](https://github.com/open-mmlab/mmdeploy)
|
||||
|
||||
### 5.2 模型转换
|
||||
|
||||
如您的 config 中含有相对引用,仍需进行消除,如[4.1 模型转换](#4.1-模型转换)所述,
|
||||
进入 mmdeploy 文件夹,执行以下命令,即可完成模型转换。
|
||||
|
||||
```bash
|
||||
python tools/deploy.py \
|
||||
configs/mmseg/segmentation_onnxruntime_static-512x512.py \
|
||||
../atl_config.py \
|
||||
../deeplabv3plus_r18-d8_512x512_80k_potsdam_20211219_020601-75fd5bc3.pth \
|
||||
../2_13_1024_5488_1536_6000.png \
|
||||
--work-dir ../atl_models \
|
||||
--device cpu \
|
||||
--show \
|
||||
--dump-info
|
||||
```
|
||||
|
||||
```bash
|
||||
# 使用方法
|
||||
python ./tools/deploy.py \
|
||||
${部署配置文件路径} \
|
||||
${模型配置文件路径} \
|
||||
${模型权重路径} \
|
||||
${输入图像路径} \
|
||||
--work-dir ${用来保存日志和模型文件路径} \
|
||||
--device ${cpu/cuda:0} \
|
||||
--show \ # 是否显示检测的结果
|
||||
--dump-info # 是否输出 SDK 信息
|
||||
|
||||
```
|
||||
|
||||
执行成功后,您将能够看到以下提示,即为转换成功。
|
||||
|
||||
```bash
|
||||
10/08 17:40:44 - mmengine - INFO - visualize pytorch model success.
|
||||
10/08 17:40:44 - mmengine - INFO - All process success.
|
||||
```
|
||||
|
||||
<div align="center">
|
||||
<img src="https://github.com/AI-Tianlong/Useful-Tools/assets/50650583/b752ccf8-903f-4ad3-ad7c-74fc25cb89a5" alt="NVIDIA-Jetson" width="400">
|
||||
</div>
|
||||
|
||||
# 6 在 Jetson 平台进行转换及部署
|
||||
|
||||
## 6.1 环境准备
|
||||
|
||||
参考[如何在 Jetson 模组上安装 MMDeploy](https://github.com/open-mmlab/mmdeploy/blob/main/docs/zh_cn/01-how-to-build/jetsons.md)文档,完成在 Jetson 上的环境准备工作。
|
||||
**注**:安装 Pytorch,可查阅 [NVIDIA Jetson Pytorch 安装文档](https://github.com/open-mmlab/mmdeploy/blob/main/docs/zh_cn/01-how-to-build/jetsons.md)安装最新的 Pytorch。
|
||||
|
||||
### 6.1.1 创建虚拟环境
|
||||
|
||||
```bash
|
||||
conda create -n {您虚拟环境的名字} python={python版本}
|
||||
```
|
||||
|
||||
### 6.1.2 虚拟环境内安装Pytorch
|
||||
|
||||
<font color="red">注意:</font>这里不要安装最新的 pytorch 2.0,因为 pyTorch 1.11 是最后一个使用 USE_DISTRIBUTED 构建的wheel,否则会在用mmdeploy进行模型转换的时候提示`AttributeError: module 'torch.distributed' has no attribute 'ReduceOp'`的错误。参考以下链接:https://forums.developer.nvidia.com/t/module-torch-distributed-has-no-attribute-reduceop/256581/6
|
||||
下载`torch-1.11.0-cp38-cp38-linux_aarch64.whl`并安装
|
||||
|
||||
```bash
|
||||
pip install torch-1.11.0-cp38-cp38-linux_aarch64.whl
|
||||
```
|
||||
|
||||
执行以上命令后,您将能看到以下提示,即为安装成功。
|
||||
|
||||
```bash
|
||||
Processing ./torch-1.11.0-cp38-cp38-linux_aarch64.whl
|
||||
Requirement already satisfied: typing-extensions in /home/sirs/miniconda3/envs/openmmlab/lib/python3.8/site-packages (from torch==1.11.0) (4.7.1)
|
||||
Installing collected packages: torch
|
||||
Successfully installed torch-1.11.0
|
||||
```
|
||||
|
||||
### 6.1.3 将 Jetson Pack 自带的 tensorrt 拷贝至虚拟环境下
|
||||
|
||||
请参考[配置 TensorRT](https://github.com/open-mmlab/mmdeploy/blob/main/docs/zh_cn/01-how-to-build/jetsons.md#%E9%85%8D%E7%BD%AE-tensorrt)。
|
||||
JetPack SDK 自带 TensorRT。 但是为了能够在 Conda 环境中成功导入,我们需要将 TensorRT 拷贝进先前创建的 Conda 环境中。
|
||||
|
||||
```bash
|
||||
export PYTHON_VERSION=`python3 --version | cut -d' ' -f 2 | cut -d'.' -f1,2`
|
||||
cp -r /usr/lib/python${PYTHON_VERSION}/dist-packages/tensorrt* ~/miniconda/envs/{您的虚拟环境名字}/lib/python${PYTHON_VERSION}/site-packages/
|
||||
```
|
||||
|
||||
### 6.1.4 安装 MMCV
|
||||
|
||||
通过`mim install mmcv`或从源码对其进行编译。
|
||||
|
||||
```bash
|
||||
pip install openmim
|
||||
mim install mmcv
|
||||
```
|
||||
|
||||
或者从源码对其进行编译。
|
||||
|
||||
```bash
|
||||
sudo apt-get install -y libssl-dev
|
||||
git clone https://github.com/open-mmlab/mmcv.git
|
||||
cd mmcv
|
||||
pip install -e .
|
||||
```
|
||||
|
||||
<font color="red">注:pytorch版本发生变动后,需要重新编译mmcv。</font>
|
||||
|
||||
### 6.1.5 安装 ONNX
|
||||
|
||||
<font color="red">注:以下方式二选一</font>
|
||||
|
||||
- conda
|
||||
```bash
|
||||
conda install -c conda-forge onnx
|
||||
```
|
||||
- pip
|
||||
```bash
|
||||
python3 -m pip install onnx
|
||||
```
|
||||
|
||||
### 6.1.6 安装 ONNX Runtime
|
||||
|
||||
根据网页 [ONNX Runtime](https://elinux.org/Jetson_Zoo#ONNX_Runtime) 选择合适的ONNX Runtime版本进行下载安装。
|
||||
示例:
|
||||
|
||||
```bash
|
||||
# Install pip wheel
|
||||
$ pip3 install onnxruntime_gpu-1.10.0-cp38-cp38-linux_aarch64.whl
|
||||
|
||||
```
|
||||
|
||||
## 6.2 在 Jetson AGX Orin 进行模型转换及推理
|
||||
|
||||
### 6.2.1 ONNX 模型转换
|
||||
|
||||
同[4.1 模型转换](#4.1-模型转换)相同,在 Jetson 平台下进入安装好的虚拟环境,以及mmdeploy 目录,进行模型ONNX转换。
|
||||
|
||||
```bash
|
||||
python tools/deploy.py \
|
||||
configs/mmseg/segmentation_onnxruntime_static-512x512.py \
|
||||
../atl_config.py \
|
||||
../deeplabv3plus_r18-d8_512x512_80k_potsdam_20211219_020601-75fd5bc3.pth \
|
||||
../2_13_3584_2560_4096_3072.png \
|
||||
--work-dir ../atl_models \
|
||||
--device cpu \
|
||||
--show \
|
||||
--dump-info
|
||||
|
||||
```
|
||||
|
||||
<font color="red">注:</font> 如果报错提示内容:
|
||||
|
||||
```none
|
||||
AttributeError: module 'torch.distributed' has no attribute 'ReduceOp'
|
||||
```
|
||||
|
||||
可参考以下链接进行解决:https://forums.developer.nvidia.com/t/module-torch-distributed-has-no-attribute-reduceop/256581/6,即安装 pytorch 1.11.0 版本。
|
||||
|
||||
转换成功后,您将会看到如下信息以及包含 ONNX 模型的文件夹:
|
||||
|
||||
```bash
|
||||
10/09 19:58:22 - mmengine - INFO - visualize pytorch model success.
|
||||
10/09 19:58:22 - mmengine - INFO - All process success.
|
||||
```
|
||||
|
||||
<div align="center">
|
||||
<img src="https://github.com/AI-Tianlong/Useful-Tools/assets/50650583/d68f1cf6-0e80-4261-91a3-6046b17de146" alt="NVIDIA-Jetson" width="400">
|
||||
<img src="https://github.com/AI-Tianlong/Useful-Tools/assets/50650583/70470a39-6a4f-4fd5-a06d-9b9d59a768ef" alt="NVIDIA-Jetson" width="160">
|
||||
</div>
|
||||
|
||||
### 6.2.2 TensorRT 模型转换
|
||||
|
||||
更换部署trt配置文件,进行 TensorRT 模型转换。
|
||||
|
||||
```bash
|
||||
python tools/deploy.py \
|
||||
configs/mmseg/segmentation_tensorrt_static-512x512.py \
|
||||
../atl_config.py \
|
||||
../deeplabv3plus_r18-d8_512x512_80k_potsdam_20211219_020601-75fd5bc3.pth \
|
||||
../2_13_3584_2560_4096_3072.png \
|
||||
--work-dir ../atl_trt_models \
|
||||
--device cuda:0 \
|
||||
--show \
|
||||
--dump-info
|
||||
|
||||
```
|
||||
|
||||
转换成功后您将看到以下信息及 TensorRT 模型文件夹:
|
||||
|
||||
```bash
|
||||
10/09 20:15:50 - mmengine - INFO - visualize pytorch model success.
|
||||
10/09 20:15:50 - mmengine - INFO - All process success.
|
||||
```
|
||||
|
||||
<div align="center">
|
||||
<img src="https://github.com/AI-Tianlong/Useful-Tools/assets/50650583/2ac1428f-b787-4fdd-beaf-6397e5b21e33" alt="NVIDIA-Jetson" width="340">
|
||||
<img src="https://github.com/AI-Tianlong/Useful-Tools/assets/50650583/70470a39-6a4f-4fd5-a06d-9b9d59a768ef" alt="NVIDIA-Jetson" width="200">
|
||||
</div>
|
||||
|
||||
## 6.3 模型测速
|
||||
|
||||
执行以下命令完成模型测速,详细内容请查看[ profiler ](https://github.com/open-mmlab/mmdeploy/blob/main/docs/zh_cn/02-how-to-run/useful_tools.md#profiler)
|
||||
|
||||
```bash
|
||||
python tools/profiler.py \
|
||||
${DEPLOY_CFG} \
|
||||
${MODEL_CFG} \
|
||||
${IMAGE_DIR} \
|
||||
--model ${MODEL} \
|
||||
--device ${DEVICE} \
|
||||
--shape ${SHAPE} \
|
||||
--num-iter ${NUM_ITER} \
|
||||
--warmup ${WARMUP} \
|
||||
--cfg-options ${CFG_OPTIONS} \
|
||||
--batch-size ${BATCH_SIZE} \
|
||||
--img-ext ${IMG_EXT}
|
||||
```
|
||||
|
||||
示例:
|
||||
|
||||
```bash
|
||||
python tools/profiler.py \
|
||||
configs/mmseg/segmentation_tensorrt_static-512x512.py \
|
||||
../atl_config.py \
|
||||
../atl_demo_img \
|
||||
--model /home/sirs/AI-Tianlong/OpenMMLab/atl_trt_models/end2end.engine \
|
||||
--device cuda:0 \
|
||||
--shape 512x512 \
|
||||
--num-iter 100
|
||||
```
|
||||
|
||||
测速结果
|
||||
|
||||

|
||||
|
||||
## 6.4 模型推理
|
||||
|
||||
根据[6.2.2](#6.2.2-TensorRT-模型转换)中生成的TensorRT模型文件夹,进行模型推理。
|
||||
|
||||
```python
|
||||
from mmdeploy.apis.utils import build_task_processor
|
||||
from mmdeploy.utils import get_input_shape, load_config
|
||||
import torch
|
||||
|
||||
deploy_cfg='./mmdeploy/configs/mmseg/segmentation_tensorrt_static-512x512.py'
|
||||
model_cfg='./atl_config.py'
|
||||
device='cuda:0'
|
||||
backend_model = ['./atl_trt_models/end2end.engine']
|
||||
image = './atl_demo_img/2_13_2048_1024_2560_1536.png'
|
||||
|
||||
# read deploy_cfg and model_cfg
|
||||
deploy_cfg, model_cfg = load_config(deploy_cfg, model_cfg)
|
||||
|
||||
# build task and backend model
|
||||
task_processor = build_task_processor(model_cfg, deploy_cfg, device)
|
||||
model = task_processor.build_backend_model(backend_model)
|
||||
|
||||
# process input image
|
||||
input_shape = get_input_shape(deploy_cfg)
|
||||
model_inputs, _ = task_processor.create_input(image, input_shape)
|
||||
|
||||
# do model inference
|
||||
with torch.no_grad():
|
||||
result = model.test_step(model_inputs)
|
||||
|
||||
# visualize results
|
||||
task_processor.visualize(
|
||||
image=image,
|
||||
model=model,
|
||||
result=result[0],
|
||||
window_name='visualize',
|
||||
output_file='./output_segmentation.png')
|
||||
```
|
||||
|
||||
即可得到推理结果:
|
||||
|
||||
<div align="center">
|
||||
<img src="https://github.com/AI-Tianlong/Useful-Tools/assets/50650583/d0ae1fa8-e223-4b3f-b699-6bfa8db38133" alt="NVIDIA-Jetson" width="40%">
|
||||
<img src="https://github.com/AI-Tianlong/Useful-Tools/assets/50650583/6d999cbe-2101-4e1b-b4a9-13115c9d1928" alt="NVIDIA-Jetson" width="40%">
|
||||
</div>
|
||||
21
Seg_All_In_One_MMSeg/docs/zh_cn/user_guides/index.rst
Normal file
21
Seg_All_In_One_MMSeg/docs/zh_cn/user_guides/index.rst
Normal file
@@ -0,0 +1,21 @@
|
||||
训练 & 测试
|
||||
**************
|
||||
|
||||
.. toctree::
|
||||
:maxdepth: 1
|
||||
|
||||
1_config.md
|
||||
2_dataset_prepare.md
|
||||
3_inference.md
|
||||
4_train_test.md
|
||||
|
||||
实用工具
|
||||
*************
|
||||
|
||||
.. toctree::
|
||||
:maxdepth: 2
|
||||
|
||||
visualization.md
|
||||
useful_tools.md
|
||||
deployment.md
|
||||
visualization_feature_map.md
|
||||
368
Seg_All_In_One_MMSeg/docs/zh_cn/user_guides/useful_tools.md
Normal file
368
Seg_All_In_One_MMSeg/docs/zh_cn/user_guides/useful_tools.md
Normal file
@@ -0,0 +1,368 @@
|
||||
## 常用工具(待更新)
|
||||
|
||||
除了训练和测试的脚本,我们在 `tools/` 文件夹路径下还提供许多有用的工具。
|
||||
|
||||
### 计算参数量(params)和计算量( FLOPs) (试验性)
|
||||
|
||||
我们基于 [flops-counter.pytorch](https://github.com/sovrasov/flops-counter.pytorch)
|
||||
提供了一个用于计算给定模型参数量和计算量的脚本。
|
||||
|
||||
```shell
|
||||
python tools/get_flops.py ${CONFIG_FILE} [--shape ${INPUT_SHAPE}]
|
||||
```
|
||||
|
||||
您将得到如下的结果:
|
||||
|
||||
```none
|
||||
==============================
|
||||
Input shape: (3, 2048, 1024)
|
||||
Flops: 1429.68 GMac
|
||||
Params: 48.98 M
|
||||
==============================
|
||||
```
|
||||
|
||||
**注意**: 这个工具仍然是试验性的,我们无法保证数字是正确的。您可以拿这些结果做简单的实验的对照,在写技术文档报告或者论文前您需要再次确认一下。
|
||||
|
||||
(1) 计算量与输入的形状有关,而参数量与输入的形状无关,默认的输入形状是 (1, 3, 1280, 800);
|
||||
(2) 一些运算操作,如 GN 和其他定制的运算操作没有加入到计算量的计算中。
|
||||
|
||||
### 发布模型
|
||||
|
||||
在您上传一个模型到云服务器之前,您需要做以下几步:
|
||||
(1) 将模型权重转成 CPU 张量;
|
||||
(2) 删除记录优化器状态 (optimizer states)的相关信息;
|
||||
(3) 计算检查点文件 (checkpoint file) 的哈希编码(hash id)并且将哈希编码加到文件名中。
|
||||
|
||||
```shell
|
||||
python tools/publish_model.py ${INPUT_FILENAME} ${OUTPUT_FILENAME}
|
||||
```
|
||||
|
||||
例如,
|
||||
|
||||
```shell
|
||||
python tools/publish_model.py work_dirs/pspnet/latest.pth psp_r50_hszhao_200ep.pth
|
||||
```
|
||||
|
||||
最终输出文件将是 `psp_r50_512x1024_40ki_cityscapes-{hash id}.pth`。
|
||||
|
||||
### 导出 ONNX (试验性)
|
||||
|
||||
我们提供了一个脚本来导出模型到 [ONNX](https://github.com/onnx/onnx) 格式。被转换的模型可以通过工具 [Netron](https://github.com/lutzroeder/netron)
|
||||
来可视化。除此以外,我们同样支持对 PyTorch 和 ONNX 模型的输出结果做对比。
|
||||
|
||||
```bash
|
||||
python tools/pytorch2onnx.py \
|
||||
${CONFIG_FILE} \
|
||||
--checkpoint ${CHECKPOINT_FILE} \
|
||||
--output-file ${ONNX_FILE} \
|
||||
--input-img ${INPUT_IMG} \
|
||||
--shape ${INPUT_SHAPE} \
|
||||
--rescale-shape ${RESCALE_SHAPE} \
|
||||
--show \
|
||||
--verify \
|
||||
--dynamic-export \
|
||||
--cfg-options \
|
||||
model.test_cfg.mode="whole"
|
||||
```
|
||||
|
||||
各个参数的描述:
|
||||
|
||||
- `config` : 模型配置文件的路径
|
||||
- `--checkpoint` : 模型检查点文件的路径
|
||||
- `--output-file`: 输出的 ONNX 模型的路径。如果没有专门指定,它默认是 `tmp.onnx`
|
||||
- `--input-img` : 用来转换和可视化的一张输入图像的路径
|
||||
- `--shape`: 模型的输入张量的高和宽。如果没有专门指定,它将被设置成 `test_pipeline` 的 `img_scale`
|
||||
- `--rescale-shape`: 改变输出的形状。设置这个值来避免 OOM,它仅在 `slide` 模式下可以用
|
||||
- `--show`: 是否打印输出模型的结构。如果没有被专门指定,它将被设置成 `False`
|
||||
- `--verify`: 是否验证一个输出模型的正确性 (correctness)。如果没有被专门指定,它将被设置成 `False`
|
||||
- `--dynamic-export`: 是否导出形状变化的输入与输出的 ONNX 模型。如果没有被专门指定,它将被设置成 `False`
|
||||
- `--cfg-options`: 更新配置选项
|
||||
|
||||
**注意**: 这个工具仍然是试验性的,目前一些自定义操作还没有被支持
|
||||
|
||||
### 评估 ONNX 模型
|
||||
|
||||
我们提供 `tools/deploy_test.py` 去评估不同后端的 ONNX 模型。
|
||||
|
||||
#### 先决条件
|
||||
|
||||
- 安装 onnx 和 onnxruntime-gpu
|
||||
|
||||
```shell
|
||||
pip install onnx onnxruntime-gpu
|
||||
```
|
||||
|
||||
- 参考 [如何在 MMCV 里构建 tensorrt 插件](https://mmcv.readthedocs.io/en/latest/tensorrt_plugin.html#how-to-build-tensorrt-plugins-in-mmcv) 安装TensorRT (可选)
|
||||
|
||||
#### 使用方法
|
||||
|
||||
```bash
|
||||
python tools/deploy_test.py \
|
||||
${CONFIG_FILE} \
|
||||
${MODEL_FILE} \
|
||||
${BACKEND} \
|
||||
--out ${OUTPUT_FILE} \
|
||||
--eval ${EVALUATION_METRICS} \
|
||||
--show \
|
||||
--show-dir ${SHOW_DIRECTORY} \
|
||||
--cfg-options ${CFG_OPTIONS} \
|
||||
--eval-options ${EVALUATION_OPTIONS} \
|
||||
--opacity ${OPACITY} \
|
||||
```
|
||||
|
||||
各个参数的描述:
|
||||
|
||||
- `config`: 模型配置文件的路径
|
||||
- `model`: 被转换的模型文件的路径
|
||||
- `backend`: 推理的后端,可选项:`onnxruntime`, `tensorrt`
|
||||
- `--out`: 输出结果成 pickle 格式文件的路径
|
||||
- `--format-only` : 不评估直接给输出结果的格式。通常用在当您想把结果输出成一些测试服务器需要的特定格式时。如果没有被专门指定,它将被设置成 `False`。 注意这个参数是用 `--eval` 来 **手动添加**
|
||||
- `--eval`: 评估指标,取决于每个数据集的要求,例如 "mIoU" 是大多数据集的指标而 "cityscapes" 仅针对 Cityscapes 数据集。注意这个参数是用 `--format-only` 来 **手动添加**
|
||||
- `--show`: 是否展示结果
|
||||
- `--show-dir`: 涂上结果的图像被保存的文件夹的路径
|
||||
- `--cfg-options`: 重写配置文件里的一些设置,`xxx=yyy` 格式的键值对将被覆盖到配置文件里
|
||||
- `--eval-options`: 自定义的评估的选项, `xxx=yyy` 格式的键值对将成为 `dataset.evaluate()` 函数的参数变量
|
||||
- `--opacity`: 涂上结果的分割图的透明度,范围在 (0, 1\] 之间
|
||||
|
||||
#### 结果和模型
|
||||
|
||||
| 模型 | 配置文件 | 数据集 | 评价指标 | PyTorch | ONNXRuntime | TensorRT-fp32 | TensorRT-fp16 |
|
||||
| :--------: | :---------------------------------------------: | :--------: | :------: | :-----: | :---------: | :-----------: | :-----------: |
|
||||
| FCN | fcn_r50-d8_512x1024_40k_cityscapes.py | cityscapes | mIoU | 72.2 | 72.2 | 72.2 | 72.2 |
|
||||
| PSPNet | pspnet_r50-d8_512x1024_40k_cityscapes.py | cityscapes | mIoU | 77.8 | 77.8 | 77.8 | 77.8 |
|
||||
| deeplabv3 | deeplabv3_r50-d8_512x1024_40k_cityscapes.py | cityscapes | mIoU | 79.0 | 79.0 | 79.0 | 79.0 |
|
||||
| deeplabv3+ | deeplabv3plus_r50-d8_512x1024_40k_cityscapes.py | cityscapes | mIoU | 79.6 | 79.5 | 79.5 | 79.5 |
|
||||
| PSPNet | pspnet_r50-d8_769x769_40k_cityscapes.py | cityscapes | mIoU | 78.2 | 78.1 | | |
|
||||
| deeplabv3 | deeplabv3_r50-d8_769x769_40k_cityscapes.py | cityscapes | mIoU | 78.5 | 78.3 | | |
|
||||
| deeplabv3+ | deeplabv3plus_r50-d8_769x769_40k_cityscapes.py | cityscapes | mIoU | 78.9 | 78.7 | | |
|
||||
|
||||
**注意**: TensorRT 仅在使用 `whole mode` 测试模式时的配置文件里可用。
|
||||
|
||||
### 导出 TorchScript (试验性)
|
||||
|
||||
我们同样提供一个脚本去把模型导出成 [TorchScript](https://pytorch.org/docs/stable/jit.html) 格式。您可以使用 pytorch C++ API [LibTorch](https://pytorch.org/docs/stable/cpp_index.html) 去推理训练好的模型。
|
||||
被转换的模型能被像 [Netron](https://github.com/lutzroeder/netron) 的工具来可视化。此外,我们还支持 PyTorch 和 TorchScript 模型的输出结果的比较。
|
||||
|
||||
```shell
|
||||
python tools/pytorch2torchscript.py \
|
||||
${CONFIG_FILE} \
|
||||
--checkpoint ${CHECKPOINT_FILE} \
|
||||
--output-file ${ONNX_FILE}
|
||||
--shape ${INPUT_SHAPE}
|
||||
--verify \
|
||||
--show
|
||||
```
|
||||
|
||||
各个参数的描述:
|
||||
|
||||
- `config` : pytorch 模型的配置文件的路径
|
||||
- `--checkpoint` : pytorch 模型的检查点文件的路径
|
||||
- `--output-file`: TorchScript 模型输出的路径,如果没有被专门指定,它将被设置成 `tmp.pt`
|
||||
- `--input-img` : 用来转换和可视化的输入图像的路径
|
||||
- `--shape`: 模型的输入张量的宽和高。如果没有被专门指定,它将被设置成 `512 512`
|
||||
- `--show`: 是否打印输出模型的追踪图 (traced graph),如果没有被专门指定,它将被设置成 `False`
|
||||
- `--verify`: 是否验证一个输出模型的正确性 (correctness),如果没有被专门指定,它将被设置成 `False`
|
||||
|
||||
**注意**: 目前仅支持 PyTorch>=1.8.0 版本
|
||||
|
||||
**注意**: 这个工具仍然是试验性的,一些自定义操作符目前还不被支持
|
||||
|
||||
例子:
|
||||
|
||||
- 导出 PSPNet 在 cityscapes 数据集上的 pytorch 模型
|
||||
|
||||
```shell
|
||||
python tools/pytorch2torchscript.py configs/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes.py \
|
||||
--checkpoint checkpoints/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth \
|
||||
--output-file checkpoints/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pt \
|
||||
--shape 512 1024
|
||||
```
|
||||
|
||||
### 导出 TensorRT (试验性)
|
||||
|
||||
一个导出 [ONNX](https://github.com/onnx/onnx) 模型成 [TensorRT](https://developer.nvidia.com/tensorrt) 格式的脚本
|
||||
|
||||
先决条件
|
||||
|
||||
- 按照 [ONNXRuntime in mmcv](https://mmcv.readthedocs.io/en/latest/deployment/onnxruntime_op.html) 和 [TensorRT plugin in mmcv](https://github.com/open-mmlab/mmcv/blob/master/docs/en/deployment/tensorrt_plugin.md) ,用 ONNXRuntime 自定义运算 (custom ops) 和 TensorRT 插件安装 `mmcv-full`
|
||||
- 使用 [pytorch2onnx](#convert-to-onnx-experimental) 将模型从 PyTorch 转成 ONNX
|
||||
|
||||
使用方法
|
||||
|
||||
```bash
|
||||
python ${MMSEG_PATH}/tools/onnx2tensorrt.py \
|
||||
${CFG_PATH} \
|
||||
${ONNX_PATH} \
|
||||
--trt-file ${OUTPUT_TRT_PATH} \
|
||||
--min-shape ${MIN_SHAPE} \
|
||||
--max-shape ${MAX_SHAPE} \
|
||||
--input-img ${INPUT_IMG} \
|
||||
--show \
|
||||
--verify
|
||||
```
|
||||
|
||||
各个参数的描述:
|
||||
|
||||
- `config` : 模型的配置文件
|
||||
- `model` : 输入的 ONNX 模型的路径
|
||||
- `--trt-file` : 输出的 TensorRT 引擎的路径
|
||||
- `--max-shape` : 模型的输入的最大形状
|
||||
- `--min-shape` : 模型的输入的最小形状
|
||||
- `--fp16` : 做 fp16 模型转换
|
||||
- `--workspace-size` : 在 GiB 里的最大工作空间大小 (Max workspace size)
|
||||
- `--input-img` : 用来可视化的图像
|
||||
- `--show` : 做结果的可视化
|
||||
- `--dataset` : Palette provider, 默认为 `CityscapesDataset`
|
||||
- `--verify` : 验证 ONNXRuntime 和 TensorRT 的输出
|
||||
- `--verbose` : 当创建 TensorRT 引擎时,是否详细做信息日志。默认为 False
|
||||
|
||||
**注意**: 仅在全图测试模式 (whole mode) 下测试过
|
||||
|
||||
## 其他内容
|
||||
|
||||
### 打印完整的配置文件
|
||||
|
||||
`tools/print_config.py` 会逐字逐句的打印整个配置文件,展开所有的导入。
|
||||
|
||||
```shell
|
||||
python tools/print_config.py \
|
||||
${CONFIG} \
|
||||
--graph \
|
||||
--cfg-options ${OPTIONS [OPTIONS...]} \
|
||||
```
|
||||
|
||||
各个参数的描述:
|
||||
|
||||
- `config` : pytorch 模型的配置文件的路径
|
||||
- `--graph` : 是否打印模型的图 (models graph)
|
||||
- `--cfg-options`: 自定义替换配置文件的选项
|
||||
|
||||
### 对训练日志 (training logs) 画图
|
||||
|
||||
`tools/analyze_logs.py` 会画出给定的训练日志文件的 loss/mIoU 曲线,首先需要 `pip install seaborn` 安装依赖包。
|
||||
|
||||
```shell
|
||||
python tools/analyze_logs.py xxx.log.json [--keys ${KEYS}] [--legend ${LEGEND}] [--backend ${BACKEND}] [--style ${STYLE}] [--out ${OUT_FILE}]
|
||||
```
|
||||
|
||||
示例:
|
||||
|
||||
- 对 mIoU, mAcc, aAcc 指标画图
|
||||
|
||||
```shell
|
||||
python tools/analyze_logs.py log.json --keys mIoU mAcc aAcc --legend mIoU mAcc aAcc
|
||||
```
|
||||
|
||||
- 对 loss 指标画图
|
||||
|
||||
```shell
|
||||
python tools/analyze_logs.py log.json --keys loss --legend loss
|
||||
```
|
||||
|
||||
### 转换其他仓库的权重
|
||||
|
||||
`tools/model_converters/` 提供了若干个预训练权重转换脚本,支持将其他仓库的预训练权重的 key 转换为与 MMSegmentation 相匹配的 key。
|
||||
|
||||
#### ViT Swin MiT Transformer 模型
|
||||
|
||||
- ViT
|
||||
|
||||
`tools/model_converters/vit2mmseg.py` 将 timm 预训练模型转换到 MMSegmentation。
|
||||
|
||||
```shell
|
||||
python tools/model_converters/vit2mmseg.py ${SRC} ${DST}
|
||||
```
|
||||
|
||||
- Swin
|
||||
|
||||
`tools/model_converters/swin2mmseg.py` 将官方预训练模型转换到 MMSegmentation。
|
||||
|
||||
```shell
|
||||
python tools/model_converters/swin2mmseg.py ${SRC} ${DST}
|
||||
```
|
||||
|
||||
- SegFormer
|
||||
|
||||
`tools/model_converters/mit2mmseg.py` 将官方预训练模型转换到 MMSegmentation。
|
||||
|
||||
```shell
|
||||
python tools/model_converters/mit2mmseg.py ${SRC} ${DST}
|
||||
```
|
||||
|
||||
## 模型服务
|
||||
|
||||
为了用 [`TorchServe`](https://pytorch.org/serve/) 服务 `MMSegmentation` 的模型 , 您可以遵循如下流程:
|
||||
|
||||
### 1. 将 model 从 MMSegmentation 转换到 TorchServe
|
||||
|
||||
```shell
|
||||
python tools/mmseg2torchserve.py ${CONFIG_FILE} ${CHECKPOINT_FILE} \
|
||||
--output-folder ${MODEL_STORE} \
|
||||
--model-name ${MODEL_NAME}
|
||||
```
|
||||
|
||||
**注意**: ${MODEL_STORE} 需要设置为某个文件夹的绝对路径
|
||||
|
||||
### 2. 构建 `mmseg-serve` 容器镜像 (docker image)
|
||||
|
||||
```shell
|
||||
docker build -t mmseg-serve:latest docker/serve/
|
||||
```
|
||||
|
||||
### 3. 运行 `mmseg-serve`
|
||||
|
||||
请查阅官方文档: [使用容器运行 TorchServe](https://github.com/pytorch/serve/blob/master/docker/README.md#running-torchserve-in-a-production-docker-environment)
|
||||
|
||||
为了在 GPU 环境下使用, 您需要安装 [nvidia-docker](https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/install-guide.html). 若在 CPU 环境下使用,您可以忽略添加 `--gpus` 参数。
|
||||
|
||||
示例:
|
||||
|
||||
```shell
|
||||
docker run --rm \
|
||||
--cpus 8 \
|
||||
--gpus device=0 \
|
||||
-p8080:8080 -p8081:8081 -p8082:8082 \
|
||||
--mount type=bind,source=$MODEL_STORE,target=/home/model-server/model-store \
|
||||
mmseg-serve:latest
|
||||
```
|
||||
|
||||
阅读关于推理 (8080), 管理 (8081) 和指标 (8082) APIs 的 [文档](https://github.com/pytorch/serve/blob/072f5d088cce9bb64b2a18af065886c9b01b317b/docs/rest_api.md) 。
|
||||
|
||||
### 4. 测试部署
|
||||
|
||||
```shell
|
||||
curl -O https://raw.githubusercontent.com/open-mmlab/mmsegmentation/master/resources/3dogs.jpg
|
||||
curl http://127.0.0.1:8080/predictions/${MODEL_NAME} -T 3dogs.jpg -o 3dogs_mask.png
|
||||
```
|
||||
|
||||
得到的响应将是一个 ".png" 的分割掩码.
|
||||
|
||||
您可以按照如下方法可视化输出:
|
||||
|
||||
```python
|
||||
import matplotlib.pyplot as plt
|
||||
import mmcv
|
||||
plt.imshow(mmcv.imread("3dogs_mask.png", "grayscale"))
|
||||
plt.show()
|
||||
```
|
||||
|
||||
看到的东西将会和下图类似:
|
||||
|
||||

|
||||
|
||||
然后您可以使用 `test_torchserve.py` 比较 torchserve 和 pytorch 的结果,并将它们可视化。
|
||||
|
||||
```shell
|
||||
python tools/torchserve/test_torchserve.py ${IMAGE_FILE} ${CONFIG_FILE} ${CHECKPOINT_FILE} ${MODEL_NAME}
|
||||
[--inference-addr ${INFERENCE_ADDR}] [--result-image ${RESULT_IMAGE}] [--device ${DEVICE}]
|
||||
```
|
||||
|
||||
示例:
|
||||
|
||||
```shell
|
||||
python tools/torchserve/test_torchserve.py \
|
||||
demo/demo.png \
|
||||
configs/fcn/fcn_r50-d8_512x1024_40k_cityscapes.py \
|
||||
checkpoint/fcn_r50-d8_512x1024_40k_cityscapes_20200604_192608-efe53f0d.pth \
|
||||
fcn
|
||||
```
|
||||
173
Seg_All_In_One_MMSeg/docs/zh_cn/user_guides/visualization.md
Normal file
173
Seg_All_In_One_MMSeg/docs/zh_cn/user_guides/visualization.md
Normal file
@@ -0,0 +1,173 @@
|
||||
# 可视化
|
||||
|
||||
MMSegmentation 1.x 提供了简便的方式监控训练时的状态以及可视化在模型预测时的数据。
|
||||
|
||||
## 训练状态监控
|
||||
|
||||
MMSegmentation 1.x 使用 TensorBoard 来监控训练时候的状态。
|
||||
|
||||
### TensorBoard 的配置
|
||||
|
||||
安装 TensorBoard 的过程可以按照 [官方安装指南](https://www.tensorflow.org/install) ,具体的步骤如下:
|
||||
|
||||
```shell
|
||||
pip install tensorboardX
|
||||
pip install future tensorboard
|
||||
```
|
||||
|
||||
在配置文件 `default_runtime.py` 的 `vis_backend` 中添加 `TensorboardVisBackend`。
|
||||
|
||||
```python
|
||||
vis_backends = [dict(type='LocalVisBackend'),
|
||||
dict(type='TensorboardVisBackend')]
|
||||
visualizer = dict(
|
||||
type='SegLocalVisualizer', vis_backends=vis_backends, name='visualizer')
|
||||
```
|
||||
|
||||
### 检查 TensorBoard 中的标量
|
||||
|
||||
启动训练实验的命令如下
|
||||
|
||||
```shell
|
||||
python tools/train.py configs/pspnet/pspnet_r50-d8_4xb4-80k_ade20k-512x512.py --work-dir work_dir/test_visual
|
||||
```
|
||||
|
||||
开始训练后找到 `work_dir` 中的 `vis_data` 路径,例如:本次特定测试的 vis_data 路径如下所示:
|
||||
|
||||
```shell
|
||||
work_dirs/test_visual/20220810_115248/vis_data
|
||||
```
|
||||
|
||||
vis_data 路径中的标量文件包括了学习率、损失函数和 data_time 等,还记录了指标结果,您可以参考 MMEngine 中的 [记录日志教程](https://mmengine.readthedocs.io/zh_CN/latest/advanced_tutorials/logging.html) 中的日志教程来帮助记录自己定义的数据。 Tensorboard 的可视化结果使用下面的命令执行:
|
||||
|
||||
```shell
|
||||
tensorboard --logdir work_dirs/test_visual/20220810_115248/vis_data
|
||||
```
|
||||
|
||||
## 数据和结果的可视化
|
||||
|
||||
### 模型测试或验证期间的可视化数据样本
|
||||
|
||||
MMSegmentation 提供了 `SegVisualizationHook` ,它是一个可以用于可视化 ground truth 和在模型测试和验证期间的预测分割结果的[钩子](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/hook.html) 。 它的配置在 `default_hooks` 中,更多详细信息请参见 [执行器教程](https://mmengine.readthedocs.io/zh_CN/latest/tutorials/runner.html)。
|
||||
|
||||
例如,在 `_base_/schedules/schedule_20k.py` 中,修改 `SegVisualizationHook` 配置,将 `draw` 设置为 `True` 以启用网络推理结果的存储,`interval` 表示预测结果的采样间隔, 设置为 1 时,将保存网络的每个推理结果。 `interval` 默认设置为 50:
|
||||
|
||||
```python
|
||||
default_hooks = dict(
|
||||
timer=dict(type='IterTimerHook'),
|
||||
logger=dict(type='LoggerHook', interval=50, log_metric_by_epoch=False),
|
||||
param_scheduler=dict(type='ParamSchedulerHook'),
|
||||
checkpoint=dict(type='CheckpointHook', by_epoch=False, interval=2000),
|
||||
sampler_seed=dict(type='DistSamplerSeedHook'),
|
||||
visualization=dict(type='SegVisualizationHook', draw=True, interval=1))
|
||||
|
||||
```
|
||||
|
||||
启动训练实验后,可视化结果将在 validation loop 存储到本地文件夹中,或者在一个数据集上启动评估模型时,预测结果将存储在本地。本地的可视化的存储结果保存在 `$WORK_DIRS/vis_data` 下的 `vis_image` 中,例如:
|
||||
|
||||
```shell
|
||||
work_dirs/test_visual/20220810_115248/vis_data/vis_image
|
||||
```
|
||||
|
||||
另外,如果在 `vis_backends` 中添加 `TensorboardVisBackend` ,如 [TensorBoard 的配置](###TensorBoard的配置),我们还可以运行下面的命令在 TensorBoard 中查看它们:
|
||||
|
||||
```shell
|
||||
tensorboard --logdir work_dirs/test_visual/20220810_115248/vis_data
|
||||
```
|
||||
|
||||
### 可视化单个数据样本
|
||||
|
||||
如果你想可视化单个样本数据,我们建议使用 `SegLocalVisualizer` 。
|
||||
|
||||
`SegLocalVisualizer`是继承自 MMEngine 中`Visualizer` 类的子类,适用于 MMSegmentation 可视化,有关`Visualizer`的详细信息请参考在 MMEngine 中的[可视化教程](https://mmengine.readthedocs.io/zh_CN/latest/advanced_tutorials/visualization.html) 。
|
||||
|
||||
以下是一个关于 `SegLocalVisualizer` 的示例,首先你可以使用下面的命令下载这个案例中的数据:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://user-images.githubusercontent.com/24582831/189833109-eddad58f-f777-4fc0-b98a-6bd429143b06.png" width="70%"/>
|
||||
</div>
|
||||
|
||||
```shell
|
||||
wget https://user-images.githubusercontent.com/24582831/189833109-eddad58f-f777-4fc0-b98a-6bd429143b06.png --output-document aachen_000000_000019_leftImg8bit.png
|
||||
wget https://user-images.githubusercontent.com/24582831/189833143-15f60f8a-4d1e-4cbb-a6e7-5e2233869fac.png --output-document aachen_000000_000019_gtFine_labelTrainIds.png
|
||||
```
|
||||
|
||||
然后你可以找到他们本地的路径和使用下面的脚本文件对其进行可视化:
|
||||
|
||||
```python
|
||||
import mmcv
|
||||
import os.path as osp
|
||||
import torch
|
||||
|
||||
# `PixelData` 是 MMEngine 中用于定义像素级标注或预测的数据结构。
|
||||
# 请参考下面的MMEngine数据结构教程文件:
|
||||
# https://mmengine.readthedocs.io/zh_CN/latest/advanced_tutorials/data_element.html#pixeldata
|
||||
|
||||
from mmengine.structures import PixelData
|
||||
|
||||
# `SegDataSample` 是在 MMSegmentation 中定义的不同组件之间的数据结构接口,
|
||||
# 它包括 ground truth、语义分割的预测结果和预测逻辑。
|
||||
# 详情请参考下面的 `SegDataSample` 教程文件:
|
||||
# https://github.com/open-mmlab/mmsegmentation/blob/1.x/docs/en/advanced_guides/structures.md
|
||||
|
||||
from mmseg.structures import SegDataSample
|
||||
from mmseg.visualization import SegLocalVisualizer
|
||||
|
||||
out_file = 'out_file_cityscapes'
|
||||
save_dir = './work_dirs'
|
||||
|
||||
image = mmcv.imread(
|
||||
osp.join(
|
||||
osp.dirname(__file__),
|
||||
'./aachen_000000_000019_leftImg8bit.png'
|
||||
),
|
||||
'color')
|
||||
sem_seg = mmcv.imread(
|
||||
osp.join(
|
||||
osp.dirname(__file__),
|
||||
'./aachen_000000_000019_gtFine_labelTrainIds.png' # noqa
|
||||
),
|
||||
'unchanged')
|
||||
sem_seg = torch.from_numpy(sem_seg)
|
||||
gt_sem_seg_data = dict(data=sem_seg)
|
||||
gt_sem_seg = PixelData(**gt_sem_seg_data)
|
||||
data_sample = SegDataSample()
|
||||
data_sample.gt_sem_seg = gt_sem_seg
|
||||
|
||||
seg_local_visualizer = SegLocalVisualizer(
|
||||
vis_backends=[dict(type='LocalVisBackend')],
|
||||
save_dir=save_dir)
|
||||
|
||||
# 数据集的元信息通常包括类名的 `classes` 和
|
||||
# 用于可视化每个前景颜色的 `palette` 。
|
||||
# 所有类名和调色板都在此文件中定义:
|
||||
# https://github.com/open-mmlab/mmsegmentation/blob/1.x/mmseg/utils/class_names.py
|
||||
|
||||
seg_local_visualizer.dataset_meta = dict(
|
||||
classes=('road', 'sidewalk', 'building', 'wall', 'fence',
|
||||
'pole', 'traffic light', 'traffic sign',
|
||||
'vegetation', 'terrain', 'sky', 'person', 'rider',
|
||||
'car', 'truck', 'bus', 'train', 'motorcycle',
|
||||
'bicycle'),
|
||||
palette=[[128, 64, 128], [244, 35, 232], [70, 70, 70],
|
||||
[102, 102, 156], [190, 153, 153], [153, 153, 153],
|
||||
[250, 170, 30], [220, 220, 0], [107, 142, 35],
|
||||
[152, 251, 152], [70, 130, 180], [220, 20, 60],
|
||||
[255, 0, 0], [0, 0, 142], [0, 0, 70],
|
||||
[0, 60, 100], [0, 80, 100], [0, 0, 230],
|
||||
[119, 11, 32]])
|
||||
|
||||
# 当`show=True`时,直接显示结果,
|
||||
# 当 `show=False`时,结果将保存在本地文件夹中。
|
||||
|
||||
seg_local_visualizer.add_datasample(out_file, image,
|
||||
data_sample, show=False)
|
||||
```
|
||||
|
||||
可视化后的图像结果和它的对应的 ground truth 图像可以在 `./work_dirs/vis_data/vis_image/` 路径找到,文件名字是:`out_file_cityscapes_0.png` :
|
||||
|
||||
<div align=center>
|
||||
<img src="https://user-images.githubusercontent.com/24582831/189835713-c0534054-4bfa-4b75-9254-0afbeb5ff02e.png" width="70%"/>
|
||||
</div>
|
||||
|
||||
如果你想知道更多的关于可视化的使用指引,你可以参考 MMEngine 中的[可视化教程](<[https://mmengine.readthedocs.io/en/latest/advanced_tutorials/visualization.html](https://github.com/open-mmlab/mmengine/blob/main/docs/zh_cn/advanced_tutorials/visualization.md)>)
|
||||
@@ -0,0 +1,201 @@
|
||||
# wandb记录特征图可视化
|
||||
|
||||
MMSegmentation 1.x 提供了 Weights & Biases 的后端支持,方便对项目代码结果的可视化和管理。
|
||||
|
||||
## Wandb的配置
|
||||
|
||||
安装 Weights & Biases 的过程可以参考 [官方安装指南](https://docs.wandb.ai/quickstart),具体的步骤如下:
|
||||
|
||||
```shell
|
||||
pip install wandb
|
||||
wandb login
|
||||
```
|
||||
|
||||
在 `vis_backend` 中添加 `WandbVisBackend`。
|
||||
|
||||
```python
|
||||
vis_backends=[dict(type='LocalVisBackend'),
|
||||
dict(type='TensorboardVisBackend'),
|
||||
dict(type='WandbVisBackend')]
|
||||
```
|
||||
|
||||
## 测试数据和结果及特征图的可视化
|
||||
|
||||
`SegLocalVisualizer` 是继承自 MMEngine 中 `Visualizer` 类的子类,适用于 MMSegmentation 可视化,有关 `Visualizer` 的详细信息请参考在 MMEngine 中的[可视化教程](https://mmengine.readthedocs.io/zh_CN/latest/advanced_tutorials/visualization.html) 。
|
||||
|
||||
以下是一个关于 `SegLocalVisualizer` 的示例,首先你可以使用下面的命令下载这个案例中的数据:
|
||||
|
||||
<div align=center>
|
||||
<img src="https://user-images.githubusercontent.com/24582831/189833109-eddad58f-f777-4fc0-b98a-6bd429143b06.png" width="70%"/>
|
||||
</div>
|
||||
|
||||
```shell
|
||||
wget https://user-images.githubusercontent.com/24582831/189833109-eddad58f-f777-4fc0-b98a-6bd429143b06.png --output-document aachen_000000_000019_leftImg8bit.png
|
||||
wget https://user-images.githubusercontent.com/24582831/189833143-15f60f8a-4d1e-4cbb-a6e7-5e2233869fac.png --output-document aachen_000000_000019_gtFine_labelTrainIds.png
|
||||
|
||||
wget https://download.openmmlab.com/mmsegmentation/v0.5/ann/ann_r50-d8_512x1024_40k_cityscapes/ann_r50-d8_512x1024_40k_cityscapes_20200605_095211-049fc292.pth
|
||||
|
||||
```
|
||||
|
||||
```python
|
||||
# Copyright (c) OpenMMLab. All rights reserved.
|
||||
from argparse import ArgumentParser
|
||||
from typing import Type
|
||||
|
||||
import mmcv
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
|
||||
from mmengine.model import revert_sync_batchnorm
|
||||
from mmengine.structures import PixelData
|
||||
from mmseg.apis import inference_model, init_model
|
||||
from mmseg.structures import SegDataSample
|
||||
from mmseg.utils import register_all_modules
|
||||
from mmseg.visualization import SegLocalVisualizer
|
||||
|
||||
|
||||
class Recorder:
|
||||
"""record the forward output feature map and save to data_buffer."""
|
||||
|
||||
def __init__(self) -> None:
|
||||
self.data_buffer = list()
|
||||
|
||||
def __enter__(self, ):
|
||||
self._data_buffer = list()
|
||||
|
||||
def record_data_hook(self, model: nn.Module, input: Type, output: Type):
|
||||
self.data_buffer.append(output)
|
||||
|
||||
def __exit__(self, *args, **kwargs):
|
||||
pass
|
||||
|
||||
|
||||
def visualize(args, model, recorder, result):
|
||||
seg_visualizer = SegLocalVisualizer(
|
||||
vis_backends=[dict(type='WandbVisBackend')],
|
||||
save_dir='temp_dir',
|
||||
alpha=0.5)
|
||||
seg_visualizer.dataset_meta = dict(
|
||||
classes=model.dataset_meta['classes'],
|
||||
palette=model.dataset_meta['palette'])
|
||||
|
||||
image = mmcv.imread(args.img, 'color')
|
||||
|
||||
seg_visualizer.add_datasample(
|
||||
name='predict',
|
||||
image=image,
|
||||
data_sample=result,
|
||||
draw_gt=False,
|
||||
draw_pred=True,
|
||||
wait_time=0,
|
||||
out_file=None,
|
||||
show=False)
|
||||
|
||||
# add feature map to wandb visualizer
|
||||
for i in range(len(recorder.data_buffer)):
|
||||
feature = recorder.data_buffer[i][0] # remove the batch
|
||||
drawn_img = seg_visualizer.draw_featmap(
|
||||
feature, image, channel_reduction='select_max')
|
||||
seg_visualizer.add_image(f'feature_map{i}', drawn_img)
|
||||
|
||||
if args.gt_mask:
|
||||
sem_seg = mmcv.imread(args.gt_mask, 'unchanged')
|
||||
sem_seg = torch.from_numpy(sem_seg)
|
||||
gt_mask = dict(data=sem_seg)
|
||||
gt_mask = PixelData(**gt_mask)
|
||||
data_sample = SegDataSample()
|
||||
data_sample.gt_sem_seg = gt_mask
|
||||
|
||||
seg_visualizer.add_datasample(
|
||||
name='gt_mask',
|
||||
image=image,
|
||||
data_sample=data_sample,
|
||||
draw_gt=True,
|
||||
draw_pred=False,
|
||||
wait_time=0,
|
||||
out_file=None,
|
||||
show=False)
|
||||
|
||||
seg_visualizer.add_image('image', image)
|
||||
|
||||
|
||||
def main():
|
||||
parser = ArgumentParser(
|
||||
description='Draw the Feature Map During Inference')
|
||||
parser.add_argument('img', help='Image file')
|
||||
parser.add_argument('config', help='Config file')
|
||||
parser.add_argument('checkpoint', help='Checkpoint file')
|
||||
parser.add_argument('--gt_mask', default=None, help='Path of gt mask file')
|
||||
parser.add_argument('--out-file', default=None, help='Path to output file')
|
||||
parser.add_argument(
|
||||
'--device', default='cuda:0', help='Device used for inference')
|
||||
parser.add_argument(
|
||||
'--opacity',
|
||||
type=float,
|
||||
default=0.5,
|
||||
help='Opacity of painted segmentation map. In (0, 1] range.')
|
||||
parser.add_argument(
|
||||
'--title', default='result', help='The image identifier.')
|
||||
args = parser.parse_args()
|
||||
|
||||
register_all_modules()
|
||||
|
||||
# build the model from a config file and a checkpoint file
|
||||
model = init_model(args.config, args.checkpoint, device=args.device)
|
||||
if args.device == 'cpu':
|
||||
model = revert_sync_batchnorm(model)
|
||||
|
||||
# show all named module in the model and use it in source list below
|
||||
for name, module in model.named_modules():
|
||||
print(name)
|
||||
|
||||
source = [
|
||||
'decode_head.fusion.stages.0.query_project.activate',
|
||||
'decode_head.context.stages.0.key_project.activate',
|
||||
'decode_head.context.bottleneck.activate'
|
||||
]
|
||||
source = dict.fromkeys(source)
|
||||
|
||||
count = 0
|
||||
recorder = Recorder()
|
||||
# registry the forward hook
|
||||
for name, module in model.named_modules():
|
||||
if name in source:
|
||||
count += 1
|
||||
module.register_forward_hook(recorder.record_data_hook)
|
||||
if count == len(source):
|
||||
break
|
||||
|
||||
with recorder:
|
||||
# test a single image, and record feature map to data_buffer
|
||||
result = inference_model(model, args.img)
|
||||
|
||||
visualize(args, model, recorder, result)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
main()
|
||||
|
||||
```
|
||||
|
||||
将上述代码保存为 feature_map_visual.py,在终端执行如下代码
|
||||
|
||||
```shell
|
||||
python feature_map_visual.py ${图像} ${配置文件} ${检查点文件} [可选参数]
|
||||
```
|
||||
|
||||
样例
|
||||
|
||||
```shell
|
||||
python feature_map_visual.py \
|
||||
aachen_000000_000019_leftImg8bit.png \
|
||||
configs/ann/ann_r50-d8_4xb2-40k_cityscapes-512x1024.py \
|
||||
ann_r50-d8_512x1024_40k_cityscapes_20200605_095211-049fc292.pth \
|
||||
--gt_mask aachen_000000_000019_gtFine_labelTrainIds.png
|
||||
```
|
||||
|
||||
可视化后的图像结果和它的对应的 feature map图像会出现在wandb账户中
|
||||
|
||||
<div align=center>
|
||||
<img src="https://user-images.githubusercontent.com/76149310/217520321-647f5bf9-eef2-446d-a9e8-5ca7b621d500.png">
|
||||
</div>
|
||||
Reference in New Issue
Block a user